更少参数更高精度!复旦开源:结合YOLO-World与Mamba实现开放词汇检测
开放词汇检测(OVD)旨在检测超出预定义类别集的对象。作为将YOLO系列融入OVD的先锋模式,YOLO世界非常适合优先考虑速度和效率的场景。然而,其颈部特征融合机制导致了二次复杂度和有限的引导感受野,从而影响了其性能。为了解决这些限制,我们提出了曼巴-YOLO-世界,一种新的基于YOLO的OVD模型,采用建议的曼巴融合路径聚合网络(曼巴融合-PAN)作为其颈部架构。
0. 论文信息
标题:Mamba-YOLO-World: Marrying YOLO-World with Mamba for Open-Vocabulary Detection
作者:Haoxuan Wang, Qingdong He, Jinlong Peng, Hao Yang, Mingmin Chi, Yabiao Wang
机构:复旦大学、腾讯优图、上海交通大学、中山复旦联合创新中心
原文链接:https://arxiv.org/abs/2409.08513
代码链接:https://github.com/Xuan-World/Mamba-YOLO-World
1. 引言
目标检测作为计算机视觉中的一项基础任务,在自动驾驶、个人电子设备、医疗保健和安全等众多领域发挥着至关重要的作用。传统方法在目标检测方面取得了显著进展。然而,这些模型都是在封闭集数据集上进行训练的,限制了它们对预定义类别(例如,COCO数据集中的80个类别)的检测能力。为了克服这一限制,开放词汇检测(OVD)作为一种新兴任务应运而生,它要求模型能够检测超出预定义类别集的对象。
之前的一些OVD工作尝试利用预训练视觉语言模型(VLMs)的固有图像-文本对齐能力。然而,这些VLMs主要是在图像-文本级别上进行训练的,因此在区域-文本级别上缺乏对齐能力。近期工作,如MDETR、GLIP、DetClip、Grounding DINO、mm-Grounding-DINO和YOLO-World,将OVD重新定义为视觉语言预训练任务,利用传统目标检测器直接在大规模数据集上学习区域-文本级别的开放词汇对齐能力。
根据上述相关工作,将传统目标检测器转换为OVD模型的关键在于实现一种适应于模型现有颈部结构的视觉-语言特征融合机制,如YOLO-World中的VL-PAN和Grounding-DINO中的Feature-Enhancer。作为将YOLO系列融入OVD的开创性模型,YOLO-World非常适合于速度和效率优先的场景部署。尽管如此,其性能仍受到VL-PAN特征融合机制的制约。
具体来说,VL-PAN在文本到图像特征融合流中采用了最大sigmoid视觉通道注意力机制,在图像到文本融合流中采用了多头交叉注意力机制,这导致了几个局限性。首先,由于跨模态注意力机制,两个融合流的复杂度都随着图像大小和文本长度的乘积呈二次方增加。其次,VL-PAN缺乏全局引导的感受野。一方面,文本到图像融合流仅生成一个缺乏像素级空间指导的视觉通道权重向量;另一方面,图像到文本融合流仅允许图像信息单独指导每个单词,无法利用文本描述中的上下文信息。
为解决上述限制,我们引入了Mamba-YOLO-World,这是一种新颖的基于YOLO的OVD模型,采用我们提出的MambaFusion路径聚合网络(MambaFusion-PAN)作为其颈部架构。最近,作为新兴的状态空间模型(SSM),Mamba已证明其能够避免二次复杂度并捕获全局感受野。然而,简单地在Mamba中连接多模态特征会导致O(N+M)的复杂度,该复杂度与连接序列的长度成正比增加,这在OVD的大词汇量情况下尤为成问题。受此启发,我们在MambaFusion-PAN中提出了基于状态空间模型的特征融合机制。我们使用mamba隐藏状态作为不同模态之间特征融合的中介,这带来了O(N+1)的复杂度,并提供了全局引导的感受野。
2. 摘要
开放词汇检测(OVD)旨在检测超出预定义类别集的对象。作为将YOLO系列融入OVD的先锋模式,YOLO世界非常适合优先考虑速度和效率的场景。然而,其颈部特征融合机制导致了二次复杂度和有限的引导感受野,从而影响了其性能。为了解决这些限制,我们提出了曼巴-YOLO-世界,一种新的基于YOLO的OVD模型,采用建议的曼巴融合路径聚合网络(曼巴融合-PAN)作为其颈部架构。具体来说,我们介绍了一种创新的基于状态空间模型的特征融合机制,该机制由并行引导的选择性扫描算法和串行引导的选择性扫描算法组成,具有线性复杂度和全局引导的感受野。它利用多模态输入序列和mamba隐藏状态来指导选择性扫描过程。实验表明,我们的模型在COCO和LVIS基准测试中,在零射击和微调设置方面都优于原始的YOLO世界,同时保持了可比较的参数和失败次数。此外,它以更少的参数和触发器超越了现有的最先进的OVD方法。
3. 效果展示
图1中的可视化结果表明,我们的Mamba-YOLO-World在所有尺寸变体上在准确性和泛化能力方面都显著优于YOLO-World。

4. 主要贡献
我们的贡献可以总结如下:
• 我们提出了Mamba-YOLO-World,这是一种新颖的基于YOLO的OVD模型,采用我们提出的MambaFusion-PAN作为其颈部架构。
• 我们引入了一种基于状态空间模型的特征融合机制,包括并行引导选择性扫描算法和串行引导选择性扫描算法,具有O(N+1)的复杂度和全局引导的感受野。推荐课程:面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
• 实验表明,我们的模型在保持相当参数和浮点运算次数(FLOPs)的同时,优于原始的YOLO-World,并且以更少的参数和FLOPs超越了现有的最先进OVD方法。
5. 方法
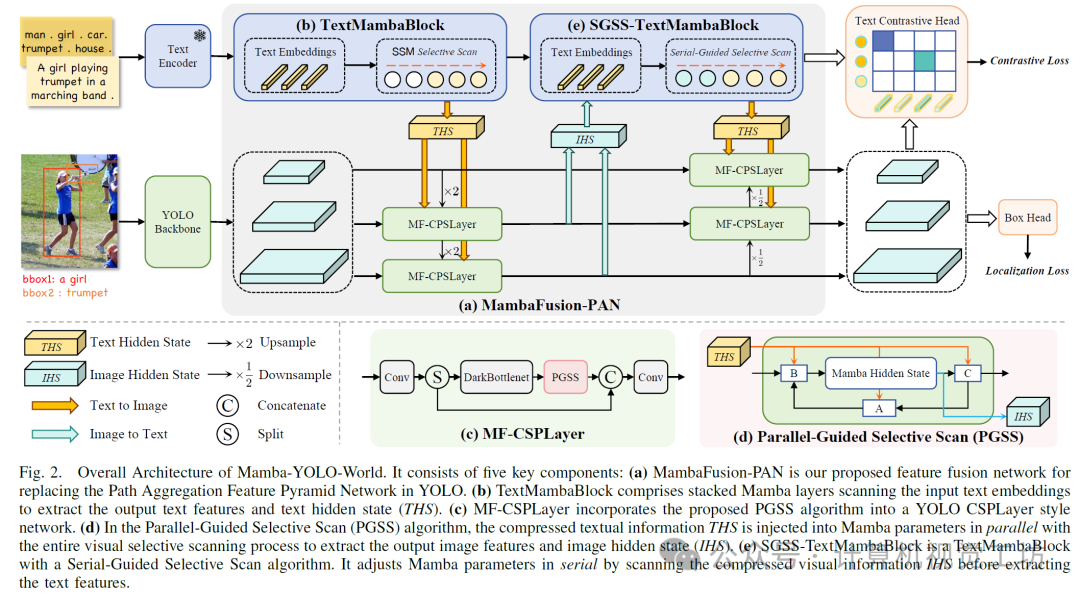
Mamba-YOLO-World 主要基于 YOLOv8进行开发,其模型主干包括 Darknet 骨干网络和 CLIP文本编码器,模型的颈部采用我们提出的 MambaFusion-PAN,模型的头部则包括文本对比分类头和边界框回归头,如图 2 所示。
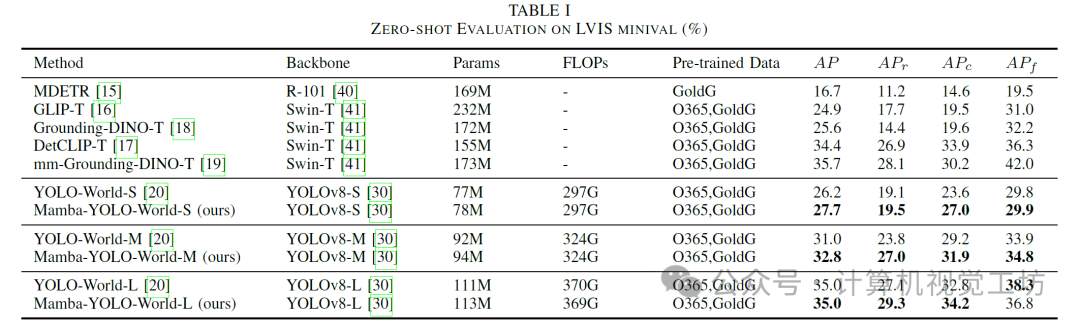
6. 实验结果
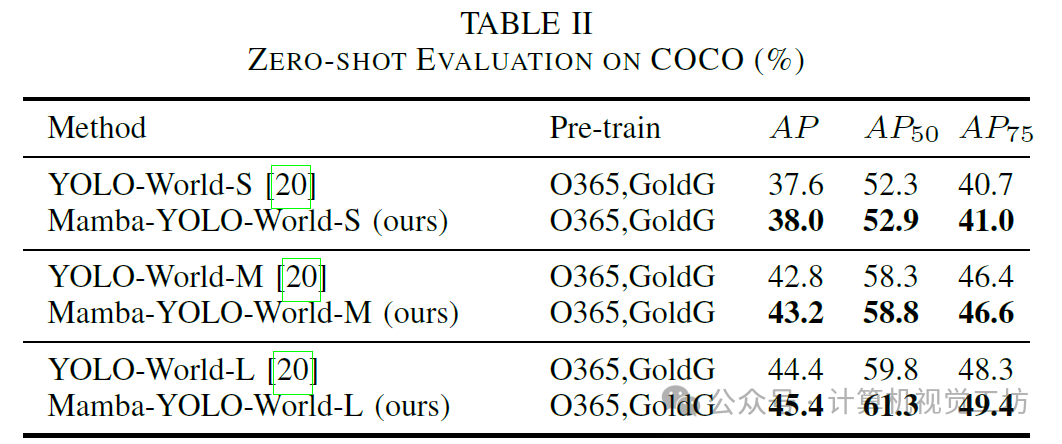
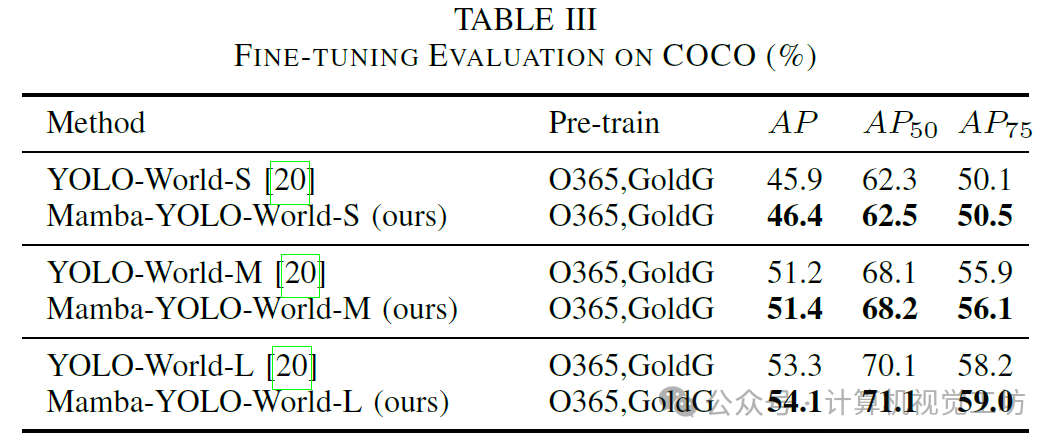
7. 总结 & 未来工作
在本文中,我们提出了用于开放词汇目标检测的 Mamba-YOLO-World。我们引入了一种创新的基于状态空间模型的特征融合机制,并将其集成到 MambaFusion-PAN 中。实验结果表明,Mamba-YOLO-World 在具有可比参数和浮点运算次数(FLOPs)的情况下,性能优于原始的 YOLOWorld。我们希望这项工作能为多模态 Mamba 架构带来新的见解,并鼓励对开放词汇视觉任务进行更深入的研究。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
1V1论文辅导-3D视觉工坊提供顶会论文的课题如下:


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 21
21 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)