CVPR2025 | 半监督学习 | 有效协同主动学习和半监督学习高效降低成本
CVPR2025 | 半监督学习 | 有效协同主动学习和半监督学习高效降低成本
CVPR2025 | 半监督学习 | 有效协同主动学习和半监督学习高效降低成本

论文信息
题目:Towards Cost-Effective Learning: A Synergy of Semi-Supervised and Active Learning
出版:CVPR2025
日期:2025-06
第一作者:Tianxiang Yin
通讯作者: Ningzhong Liu
单位:南京航空航天大学等
原文链接:https://ieeexplore.ieee.org/document/11094509
一、总结
1.1 概述
-What is the problem
主动学习 (Active Learning, AL) 和半监督学习 (Semi-Supervised Learning, SSL) 的共同目标是降低数据标注成本, 但各自采用不同途径: AL 侧重于选择性标注高价值样本, SSL 则侧重于利用未标注数据提升模型性能。
本研究要解决的核心问题: 尽管直觉上 AL 和 SSL 可以互补, 但实际结合时存在框架层面的根本差异, 导致直接整合困难。
当前的半监督主动学习 (Semi-Supervised Active Learning, SSAL) 方法存在两大不足:
- 缺乏坚实的理论基础,
- 往往针对特定 SSL 算法定制 AL 策略, 而非实现 AL 和 SSL 领域的深度通用整合
这限制了 SSAL 的灵活性和可扩展性, 无法充分利用 AL 和 SSL 各自的最新技术进展。
-What is the work
理论层面: 本文将 AL 目标引入主流基于伪标签的 SSL 框架的整体风险公式中, 从理论角度澄清了 SSAL 与传统 AL 在样本选择策略上的关键区别, 为方法设计提供了理论基础。
方法层面: 提出了一种特征重新对齐模块, 该模块通过聚类和一致性约束, 对齐未标注数据在不同增强视图下的特征表示, 旨在解决 AL 和 SSL 结合时的特征不一致问题。
-Results
实验证明, 所提模块能实现 AL 和 SSL 领域最先进方法的灵活组合, 显著提升算法效率。
这表明该方法具有实用价值, 能够推动 SSAL 向更通用、高效的方向发展, 为实际应用提供支持。
1.2 创新点
1.2.1. 理论创新
- 建立了半监督主动学习的统一风险分析框架,将SSL整体风险分解为泛化误差、训练误差和半监督误差
- 将半监督误差进一步拆分为伪误差和边界误差,证明它们分别对应AL样本选择中的多样性和不确定性策略。
- 分析发现,标注数据稀疏导致特征聚类效果差,而增强视图差异增大不确定性评估误差,这阻碍了AL与SSL的有效集成。
1.2.2. 方法创新
- 提出特征重新对齐模块,包含相似性损失和对比损失双机制
- 设计差异化特征队列管理策略,强增强队列保留历史信息,弱增强队列实时更新
- 相似性损失提升未标注数据与标注数据在特征空间中的聚类效果,直接减少了伪标签的分配错误,间接降低了伪误差的根源
- 对比损失通过减少视图间变异性的干扰,提升了不确定性估计的准确性,从而优化边界误差的评估。
- 二者协同优化:相似性损失确保特征空间的结构性(降低伪误差),而对比损失保证不确定性测量的可靠性(降低边界误差)。这
1.3 主要成就
- 对主流SSL框架中的风险损失进行了全面的理论分析,并融入了AL目标。分析确定了SSAL风险上界的两个关键误差项,分别对应主动学习中的两个主要目标。
- 基于理论发现,提出了一个特征重新对齐模块,弥合了AL和SSAL之间的差距。该模块可以无缝集成到现有的使用强-弱增强的SSL框架中,并能与各种AL算法有效结合。
- 在实验部分,通过将该模块与两种代表性SSL算法(FreeMatch和FixMatch)以及多种AL算法结合,证明了所提模块的实际有效性。大量实验验证了该模块促进了SSL和AL方法的高效集成,显著提升了性能。
1.4 核心思想
本文通过理论分析揭示AL与SSL结合的根本瓶颈,提出特征重新对齐模块作为通用桥梁,使两种范式能够有效协同,实现真正的成本高效学习。
二、研究目标及解决方案
- 主动学习和半监督学习可以互补以实现成本高效的学习,有方法多为特定SSL算法定制AL策略,缺乏通用整合框架
⟹\Longrightarrow⟹ 进行主动学习和半监督学习互补的理论分析并开发一个通用整合框架
- 理论分析发现半监督学习中的伪误差和边界误差对应于主动学习样本选择中的两种主要策略:基于多样性的策略和基于不确定性的策略
⟹\Longrightarrow⟹ 研究表明,半监督学习中:
- 伪误差衡量了弱增强视图下的伪标签与真实标签的类别一致性差异。
- 边界误差衡量强增强视图下,模型对真实类别的预测概率与最大预测概率的差距。
- 结合主动学习进一步分析得出:基于多样性的方法可以减轻伪误差,而基于不确定性的方法可以减少边界误差
- 进一步分析发现主动学习中的多样性策略和不确定性策略结合半监督学习时产生对应的两个挑战:标注数据极少时聚类效果差、强增强视图的特征差异大
⟹\Longrightarrow⟹ 为解决这些问题,引入了特征重新对齐模块。
- 为解决聚类不足的问题,借鉴无监督学习的见解,显式地对未标注数据进行聚类。
- 为解决强增强视图间特征差异大的问题,使用弱增强特征作为强增强特征的代理进行不确定性估计。
三、研究背景以及问题陈述
1)深度学习依赖标注数据:虽然深度学习取得重大进展,但其成功建立在大量高质量标注数据基础上,导致标注成本高昂。
尽管获取未标注数据的成本在下降,但这些数据的标注仍然需要大量人力成本。因此,在实际应用中,数据标注的高成本仍然是一个亟待解决的关键问题。
2)AL和SSL的互补性:AL通过选择性标注减少成本,SSL通过利用未标注数据提升性能,二者结合有望实现成本高效学习。
具体来说,AL通过选择有价值的样本进行标注,同时忽略贡献较小或无贡献的样本,从而最大化标注样本的信息价值。另一方面,SSL直接利用大量未标注数据来探索其中包含的信息。
鉴于它们的互补优势,一种自然策略是将AL和SSL结合,以实现更成本高效的学习。一种有前景的方法是将SSL过程集成到迭代式AL框架中:最初,使用一小部分标注样本和大量未标注数据,通过SSL算法训练模型。训练完成后,AL算法从未标注数据中选择信息量最大的样本进行标注。这些新标注的样本随后被添加到标注数据集中,并重新应用SSL,从而迭代地优化模型。
3)当前结合方法的不足:简单的AL和SSL集成未能达到预期效果,现有方法多为特定SSL算法定制AL策略,缺乏通用整合框架。
在本文中,首先分析了当前主流基于伪标签的SSL框架中的整体风险损失 (overall risk loss),然后将AL目标纳入该框架,从理论角度审视了SSAL和AL在样本选择策略上的关键差异。
通过分析发现,SSAL风险损失的上界受到两类误差的影响:伪误差和边界误差 (pseudo error and margin error)。这些误差直接对应于AL样本选择中的两种主要策略:基于多样性的策略(diversity-based, 关注样本代表性)和基于不确定性的策略(uncertainty-based, 关注样本信息量)。
然而,直接将这两种选择策略应用于SSAL会面临两个问题。
1)多样性策略的局限性:依赖聚类假设,在标注数据极少时模型难以学习区分性特征,导致聚类效果差。
第一个挑战来自基于多样性的方法,这类方法严重依赖于聚类假设,即假设同一类别的样本表现出高度相似性。这一假设只有在模型已经充分学习到每个类别的特征时才能成立。然而,在标注数据有限的情况下,每个类别可能只有少数几个标注样本,导致模型难以学习到具有区分性的特征,聚类效果往往较弱,从而使得基于多样性的选择在SSAL中表现不佳。
解决方案:为解决聚类不足的问题,借鉴无监督学习的见解,显式地对未标注数据进行聚类。在SSL训练过程中,为所有标注数据的强增强和弱增强视图维护两个特征队列。利用强增强特征,识别与未标注数据相似的标注数据,并使用相似性损失函数对齐它们的弱增强特征。
2)不确定性策略的挑战:强增强视图的特征差异大,直接影响不确定性评估的准确性。
第二个问题涉及基于不确定性的策略,这类策略理想情况下应应用于样本的强增强视图。然而,同一样本在不同强增强视图下的特征差异有时会很大,这给准确评估样本不确定性带来了困难。
解决方案:为解决强增强视图间特征差异大的问题,使用弱增强特征作为强增强特征的代理进行不确定性估计。通过对强增强和弱增强特征施加约束,确保弱增强特征能够有效近似强增强特征,从而实现更准确的不确定性评估。
四、研究方法详解
4.1 SSL基础
在半监督学习(SSL)框架中,设有一个标注数据集 L={xil,yil}i=1NlL =\{x^l_i, y^l_i\}^{N_l}_{i=1}L={xil,yil}i=1Nl 和一个未标注数据集 U={xju}j=1NuU =\{x^u_j\}^{N_u}_{j=1}U={xju}j=1Nu$,其中 $NlN_lNl 和 NuN_uNu 分别表示标注和未标注数据集中的样本数量,且 Nl<<NuN_l << N_uNl<<Nu。标注数据的监督损失定义为:
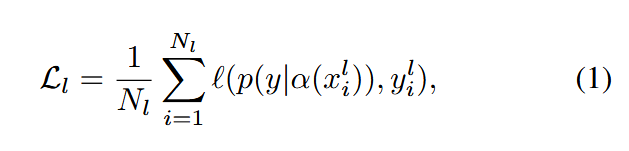
其中 ℓℓℓ 表示损失函数(通常为交叉熵损失),p(⋅) 表示模型的输出概率,α(⋅) 表示弱数据增强。对于未标注数据,当前主流SSL方法采用强-弱数据增强策略。具体而言,对于未标注样本 xjux^u_jxju,同时应用弱增强 α(xju)α(x^u_j)α(xju) 和强增强 A(xju)A(x^u_j)A(xju)。伪标签基于弱增强视图生成,并用于强增强视图的训练。未标注数据的损失函数定义如下:
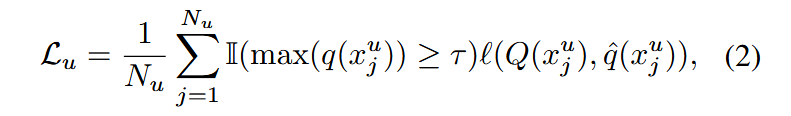
其中 q(⋅) 和 Q(⋅) 分别是 p(y∣α(xju))p(y|α(x^u_j))p(y∣α(xju)) 和 p(y∣A(xju))p(y|A(x^u_j))p(y∣A(xju)) 的简写, q^(xju)\hat{q}(x^u_j)q^(xju) 表示从 q(xju)q(x^u_j)q(xju) 得到的伪标签,τττ 为过滤阈值。各种SSL方法对此基本公式进行了改进,例如采用动态阈值 τdynamicτ_{dynamic}τdynamic、校正弱视图中的预测概率、应用不同的强增强等,但其核心思想仍基于公式(2),即利用强-弱增强策略计算未标注数据的损失。
4.2 问题形式化
本研究考虑输入空间X和标签空间 Y={1,2,...,K}Y = \{1, 2, ..., K\}Y={1,2,...,K} 上的多类分类问题。标注数据集 LLL 和未标注数据集 UUU 均从同一分布 Z=X×YZ = X × YZ=X×Y 中采样。具体地,标注数据集表示为 L={xil,yil}i=1NlL =\{x^l_i, y^l_i\}^{N_l}_{i=1}L={xil,yil}i=1Nl,未标注数据集表示为 U={xju,y^ju}j=1NuU=\{x^u_j, \hat{y}^u_j\}^{N_u}_{j=1}U={xju,y^ju}j=1Nu,其中 y^ju\hat{y}^u_jy^ju 是由 xjux^u_jxju 的弱增强视图生成的伪标签(可能正确或错误)。
记 ΘalΘ_{al}Θal 和 ΘsslΘ_{ssl}Θssl 分别为AL和SSL算法。
SSAL的目标是通过 ΘalΘ_{al}Θal 识别一个子集 S⊂US ⊂ US⊂U 进行标注,随后应用 ΘsslΘ_{ssl}Θssl 利用更新后的标注和未标注数据集以最大化模型性能。然而, ΘalΘ_{al}Θal 和 ΘsslΘ_{ssl}Θssl 之间的固有差异常导致集成效果不佳。本文旨在弥合AL与SSAL之间的差距,提升 ΘalΘ_{al}Θal 和 ΘsslΘ_{ssl}Θssl 结合的有效性。
4.3 理论分析
为了清晰表示未标注样本的真实标签情况,定义一个理想数据集 U∗={xju,yju}j=1NuU^{∗}=\{x^u_j, y^u_j\}^{N_u}_{j=1}U∗={xju,yju}j=1Nu,其中 yjuy^u_jyju 表示未标注样本 xjux^u_jxju 的真实标签。同时定义实际训练数据集 DDD,它结合了所有标注和未标注样本,即 D=L∪U={xil,yil}i=1Nl∪{xju,y^ju}j=1NuD = L ∪ U =\{x^l_i, y^l_i\}^{N_l}_{i=1}∪\{x^u_j, \hat{y}^u_j\}^{N_u}_{j=1}D=L∪U={xil,yil}i=1Nl∪{xju,y^ju}j=1Nu。此外,定义一个理想数据集 D∗D^{∗}D∗,它包含所有标注样本及其真实标签,表示为 D∗=L∪U∗={xil,yil}i=1Nl∪{xju,yju}j=1NuD^{∗}=L ∪ U^{∗} =\{x^l_i, y^l_i\}^{N_l}_{i=1}∪\{x^u_j, y^u_j\}^{N_u}_{j=1}D∗=L∪U∗={xil,yil}i=1Nl∪{xju,yju}j=1Nu。
在SSL算法的训练过程中,模型在数据集D上训练,得到的模型记为 fDf_DfD。该模型诱导出一个标签函数 hDh_DhD,定义为:
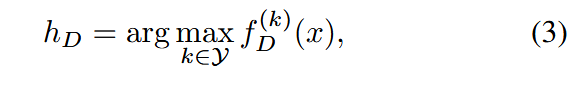
其中 fD(k)f^{(k)}_DfD(k) 表示网络的第k个输出值。
分析从SSL框架的风险开始。在整个分布 ZZZ 上,模型的风险可以分解为三部分:泛化误差、训练误差和半监督误差。这种分解可以表示为

公式(4)中,Ex,y∼pZE_{x,y∼pZ}Ex,y∼pZ 代表在真实数据分布 ZZZ 上的期望
1∣D∗∣∑(x,y)∈D∗l(x,y;fD)\frac{1}{\left | D^{*} \right | } {\textstyle \sum_{(x,y)\in D^{*}}l(x,y;f_D)}∣D∗∣1∑(x,y)∈D∗l(x,y;fD) 代表在理想数据集上的平均损失
1∣D∣∑(x,y)∈Dl(x,y;fD)\frac{1}{\left | D \right | } {\textstyle \sum_{(x,y)\in D}l(x,y;f_D)}∣D∣1∑(x,y)∈Dl(x,y;fD) 代表在实际训练数据集上的平均损失
- 泛化误差:衡量模型在真实分布与理想数据集上的表现差异
- 训练误差:反映模型对训练数据(含伪标签)的拟合程度
- 半监督误差:专门刻画由伪标签错误引入的误差,衡量理想数据集与实际训练数据集之间的损失差异
Huan Xu and Shie Mannor. Robustness and generalization. Mach. Learn., 86(3):391–423, 2012.
上述文献中的研究从理论上证明了深度网络的泛化误差存在上界,且在训练过程中深度网络能够很好地拟合给定数据集,使得训练误差相对较小。因此,本研究主要关注公式(4)中的半监督误差,该误差主要由未标注数据中存在的错误伪标签引起。
假设经过充分训练后,标注数据L的损失值为0,则半监督误差可简化为:
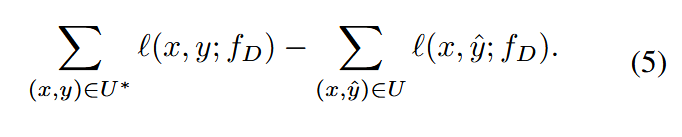
U∗U^{∗}U∗ 表示包含真实标签的未标注数据集,UUU 表示包含伪标签的未标注数据集。
引入常用的交叉熵损失函数,并将 A(x)A(x)A(x) 和 $α(x) $ 简记为 xsx_sxs 和 xwx_wxw,分别表示弱增强和强增强视图
公式(5)可以推导为:
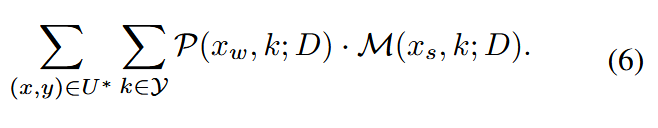
kkk 是类别索引, Y={1,2,...,K}Y = \{1, 2, ..., K\}Y={1,2,...,K} 是类别集合。
伪误差:P(xw,k;D)=∣I(y=k)−I(hD(xw)=k)∣P(x_w, k; D) = | \mathbb{I} (y = k) − \mathbb{I}(h_D(x_w) = k)|P(xw,k;D)=∣I(y=k)−I(hD(xw)=k)∣ ,其中 hD=argmaxk∈YfD(k)(x)h_D=argmax_{k \in Y}f^{(k)}_D(x)hD=argmaxk∈YfD(k)(x) 是弱增强视图的预测标签。它衡量了伪标签 hD(xw)h_D(x_w)hD(xw) 与真实标签 yyy 在类别 kkk 上的一致性差异。
边界误差:M(xs,k;D)=fD(max)(xs)−fD(k)(xs)M(x_s, k; D) = f^{(max)}_D(x_s)− f^{(k)}_D(x_s)M(xs,k;D)=fD(max)(xs)−fD(k)(xs) ,衡量在强增强视图 xsx_sxs 下,模型对真实类别 kkk 的预测概率与最大预测概率的差距。值越大表示模型对该类别的置信度越低,不确定性越高。
SSL框架中AL的目标是找到一个子集 S⊂US ⊂ US⊂U,以最小化:
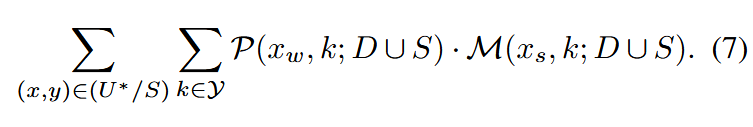
为简化分析,考虑选择单个样本x∈U,旨在同时减少伪误差和边界误差。这两类误差分别对应于AL中基于多样性和基于不确定性的采样策略。下面对此进行分析。
对于伪误差,假设具有较高特征相似度的样本更可能属于同一类别。设 zjuz^u_jzju 表示未标注样本 xjux^u_jxju 的特征,z∗lz^l_*z∗l 表示其最近邻标注样本 (x∗l,y∗l).(x^l_∗, y^l_∗).(x∗l,y∗l). 的特征。若使用 y∗ly^l_*y∗l 作为 xjux^u_jxju 的伪标签,则 zjuz^u_jzju 的整体分布为 η(zju)η(z^u_j)η(zju),经验分布为 η(z∗l)η(z^l_*)η(z∗l)。
未标注样本 (xju,yju)(x^u_j, y^u_j)(xju,yju) 的伪误差的期望表达及其上界可表示为:
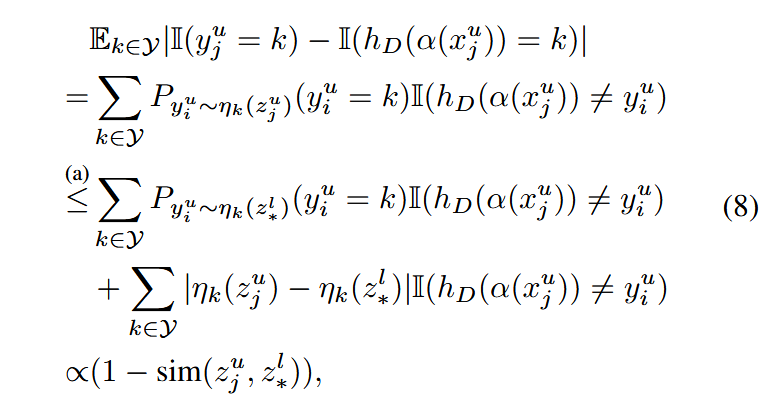
Christopher Berlind and Ruth Urner. Active nearest neighbors in changing environments. In International Conference on Machine Learning, volume 37, pages 1870–1879, 2015.
其中sim(⋅)表示余弦相似度。上式中的记号(a)指代上述文献研究中的推断。
因此,伪误差与特征相似度负相关,表明相似度增加会减少伪误差。AL减少伪误差的目标是找到:
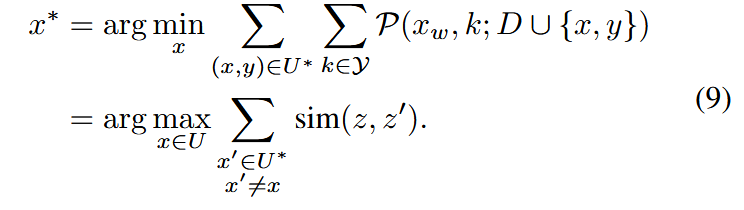
公式(9)意味着在未标注数据集中寻找最具代表性的样本,这一目标与基于多样性的方法一致。
对于边界误差,它评估了在强增强下网络预测类别与真实标签之间的输出差异。当未标注样本的伪标签等于其真实标签时,伪误差为0。因此只需考虑伪标签不正确 I(hD(xw)≠y)\mathbb{I}(h_D(x_w) \not= y)I(hD(xw)=y) 时的边界误差。为最小化公式(7),需要在U中找到具有最大边界误差的样本并将其加入S。如前一节所述,SSL使得强增强预测逐渐接近伪标签,因此在半监督训练结束时,强增强下的预测 hD(xs)h_D(x_s)hD(xs) 将与伪标签 hD(xw)h_D(x_w)hD(xw) 一致。于是,对于一个真实标签为y、伪标签为y^=hD(xw)\hat{y}=h_D(x_w)y^=hD(xw) 的未标注数据x,当 y^≠y\hat{y} \not= yy^=y 时的半监督误差为:
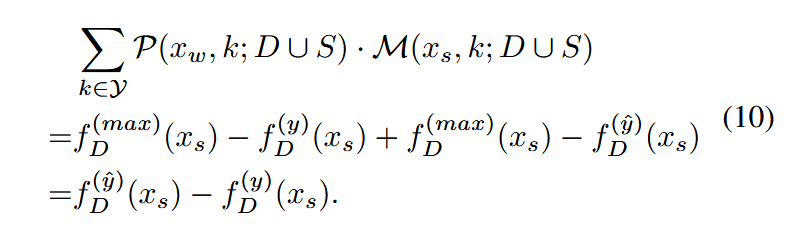
该公式表示预测类别与其真实标签类别概率之间的差异。值越高表明分配给非真实标签的概率相对较高,意味着样本包含更多信息。此样本选择方法与基于不确定性的方法目标一致。
根据以上分析,基于多样性的方法可以减轻伪误差,而基于不确定性的方法可以减少边界误差。
尽管SSAL下的样本选择策略与AL密切相关,但二者存在两个关键差异,导致AL和SSL算法的结合效果不佳。
第一个差异是标注样本的数量。虽然AL通常使用相对较少的标注样本进行训练,但每个类别通常有多个样本。相比之下,SSL通常每个类别仅使用一两个标注样本。这种差异导致聚类效果不佳,进而使得在SSAL中应用基于多样性的方法时样本选择效果不理想。
第二个关键差异在于增强视图。AL方法通常在弱增强下进行样本选择,而上述分析表明SSAL需要在强增强下进行基于不确定性的选择。然而,同一样本在不同强增强下的变异性可能很大,这种变异性使得准确评估样本信息量变得困难。为解决这些问题,引入了特征重新对齐模块,这将在后续章节中详细描述。
4.4 整体框架
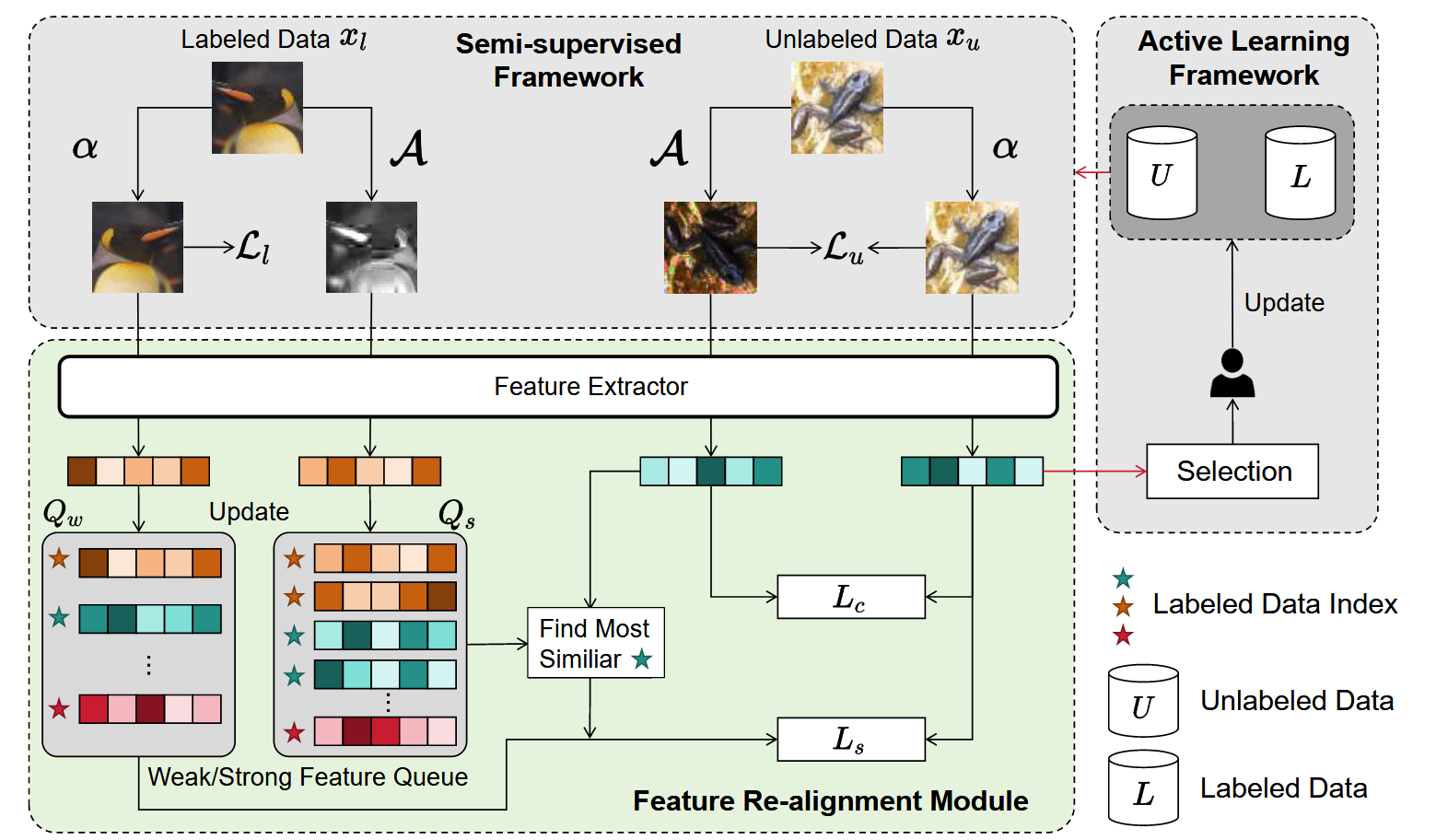
图1。算法开始时,使用初始标记数据集L和未标记数据集U来训练模型,并由SSL算法和特征重新对齐模块模块指导。
在特征重新对齐模块中,计算未标记数据的损失Lu时,引入了两个额外的损失函数:相似度损失函数Ls和对比损失函数Lc。
模型训练后,在弱增强下,通过各种样本选择策略从未标记数据集中选取样本。
图1展示了提出的整体框架,该框架通过特征重新对齐模块将AL和SSL集成起来。
该过程与标准AL类似,但有一个关键区别:在模型训练过程中,使用SSL框架替代了标准的监督训练模式。
需要强调的是,AL框架内的样本选择策略和SSL框架内的学习策略都是灵活的,允许融入各自领域的最先进算法。这种协同作用使整个算法能够利用性能最佳的技术,从而提升整体性能。
4.5 Feature Re-alignment Module
根据先前的理论分析,已识别出在测量样本代表性和不确定性方面AL和SSAL之间的关键差异。特征重新对齐模块是为了解决主动学习(AL)与半监督学习(SSL)结合时的关键矛盾而设计的创新组件。
该模块基于理论分析发现的两个核心问题:
- 一是标注数据稀缺导致特征聚类效果差,影响基于多样性的样本选择;
- 二是强增强视图的变异性干扰不确定性评估。
为解决这些问题,本文提出一个特征重新对齐模块,该模块包括一个相似性损失函数 LsL_sLs 和一个对比损失函数 LcL_cLc ,通过双损失机制实现特征空间的重构优化。
4.5.1 Similarity Loss Function LsL_sLs
相似性损失函数 LsL_sLs 。基于先前分析,在评估样本代表性时,期望未标注数据的特征表现出强聚类模式。
在SSL中,标注数据稀疏,仅依赖监督学习通常无法产生满意的聚类结果。
为解决此问题,引入一个相似性损失函数,在弱增强下显式地对未标注数据进行聚类。这有助于提高同一类别潜在样本之间的特征相似性,从而提升样本代表性测量的效率。
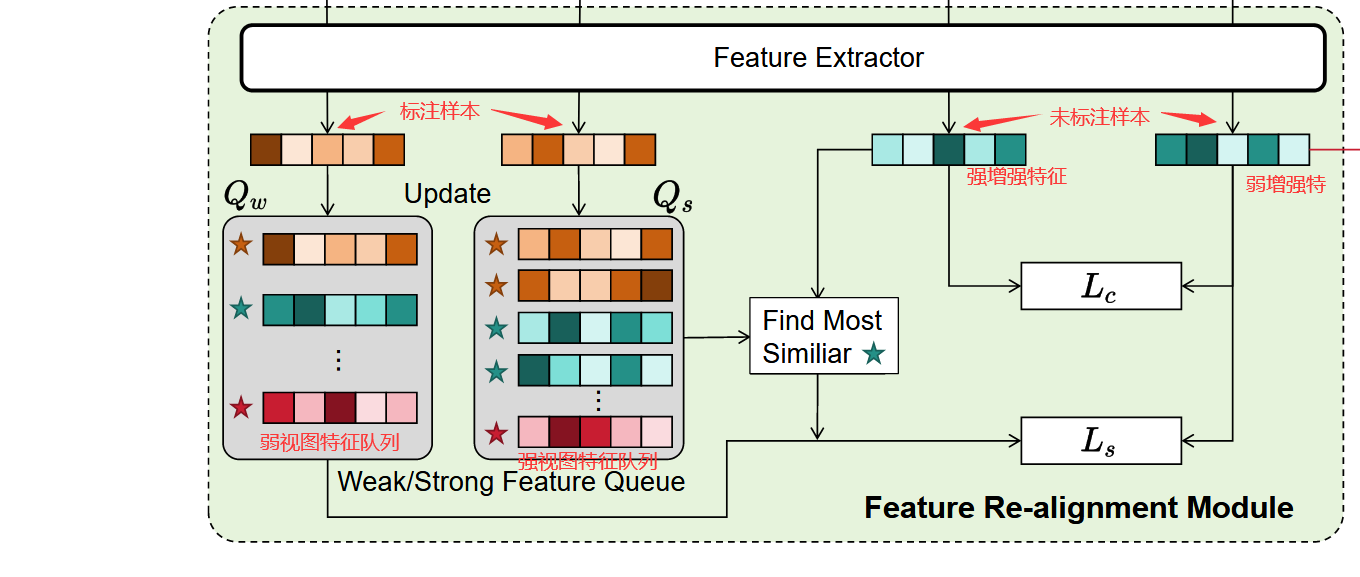
相似性损失函数专门针对伪误差优化,通过建立特征聚类增强机制来提升样本代表性。
该方法基于无监督学习的见解,即同一类别的样本在特定强增强下将表现出高相似性。基于此,在强增强下识别每个未标注样本最相似的标注样本,并使用弱增强计算特征相似性损失。通过最小化相似性损失,增强同一类别样本间的特征相似性,促进基于代表性准则选择样本时伪误差的减少。
该函数采用动态特征队列管理策略,维护标注样本的强增强和弱增强特征队列。在SSL框架中计算标注数据损失 LlL_lLl 时,为弱增强和强增强视图创建两个特征队列:弱视图特征队列 Qw={qi,wl}i=1NlQ_w = \{q^l_{i,w}\}^{N_l}_{i=1}Qw={qi,wl}i=1Nl 和强视图特征队列 Qs={qi,s,tl}i=1NlQ_s = \{q^l_{i,s,t}\}^{N_l}_{i=1}Qs={qi,s,tl}i=1Nl,其中1≤t≤T1 ≤ t ≤ T1≤t≤T 表示每个样本的特征队列长度。在每个训练迭代中,弱视图队列 QwQ_wQw 中的旧特征被新生成的弱增强特征整体替换,而对于强视图队列 QsQ_sQs 采用滚动替换,丢弃最早的特征并添加最新的强增强特征。
计算相似性损失时,首先提取未标注数据 xjux^u_jxju 的强增强视图特征 zj,suz^u_{j,s}zj,su 和弱增强视图特征 zj,wuz^u_{j,w}zj,wu。然后计算 zj,suz^u_{j,s}zj,su 与标注数据强增强视图特征队列 QsQ_sQs 中每个特征的相似性,基于以下公式选择最相似的标注样本 xi∗lx^l_{i∗}xi∗l:
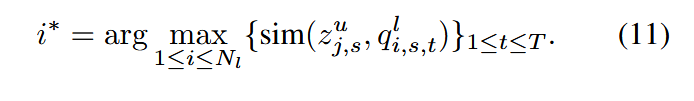
接着,计算 zj,wuz^u_{j,w}zj,wu 与 QwQ_wQw 中对应弱增强特征 qi∗,wlq^l_{i∗,w}qi∗,wl 的相似性,并将其作为相似性损失:
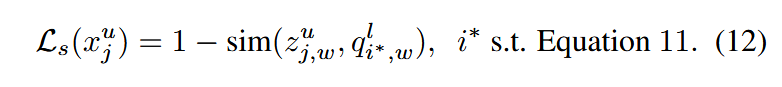
通过引入相似性损失函数 LsL_sLs,可以使同一类别样本的特征更接近,从而在基于代表性准则选择样本后有效最小化伪误差。
4.5.2 Contrastive Loss Function LcL_cLc
当处理边界误差时,需要在强增强视图下对其进行评估。然而,强增强视图之间的变异性导致网络输出存在显著差异。
为解决此问题,通过对齐两种视图的特征,使用弱增强视图来近似强增强的分类边界。
首先,定义强增强和弱增强视图之间的特征距离为:
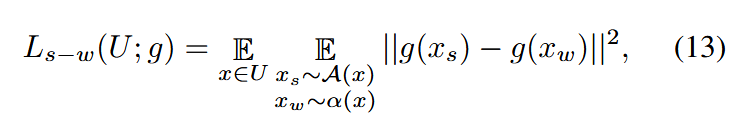
其中g是特征提取器。将公式6中样本x的边界误差记为 ∆m(x;g)∆_m(x; g)∆m(x;g),并表示为:
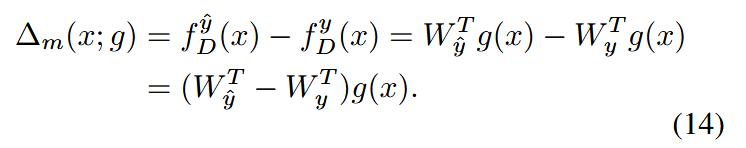
目标是用弱增强视图的 ∆m(xw;g)∆_m(x_w; g)∆m(xw;g) 来近似强增强视图的 ∆m(xs;g)∆_m(x_s; g)∆m(xs;g)。定义它们之间的差距 ∆s−w∆_{s−w}∆s−w 如下
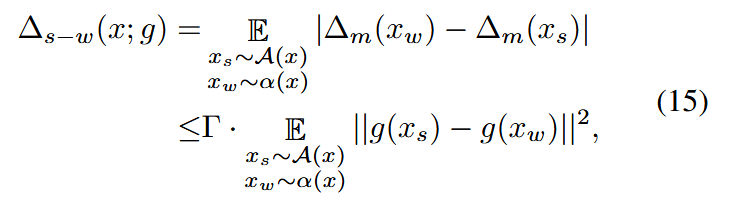
其中 KaTeX parse error: Got function '\hat' with no arguments as subscript at position 11: Γ = ||W^T_\̲h̲a̲t̲{y} − W_y^T||^2。此外,定义数据集U上强增强和弱增强视图的距离差如下:
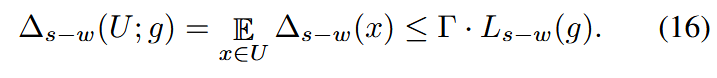
现在可以得出结论,∆s−w(U;g)∆_{s−w}(U ; g)∆s−w(U;g) 的上界由 Ls−w(U;g)L_{s−w}(U ; g)Ls−w(U;g)决定。
假设g生成的特征维度为d且均归一化到模1,采用一种不变特征方法,用以下对比损失约束模型:
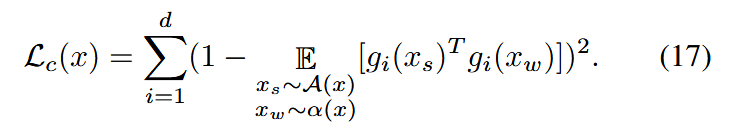
该公式表示约束同一样本在强增强和弱增强视图下生成特征的同一维度以确保一致性。然后,数据集U上的整体损失函数为
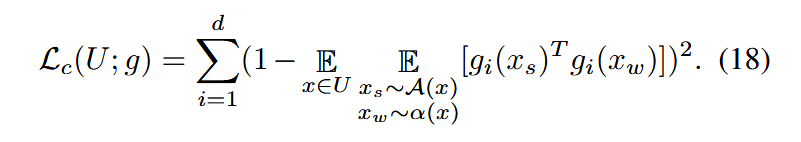
通过公式19的简单推导,可以理解 Ls−w(U;g)L_{s−w}(U ; g)Ls−w(U;g) 的上界由此损失决定:
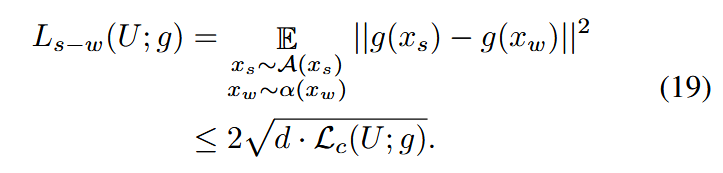
通过优化对比损失 Lc(x)L_c(x)Lc(x),减少强增强和弱增强之间边界误差的差距,促进基于不确定性的方法在弱增强视图上的应用
五、实验与分析
5.1 实验设置
使用CIFAR-100和TinyImagenet数据集。这两个数据集分别包含100和200个类别。
每个类别中随机选择一或两个样本作为初始标注数据集,在后续每轮中选择相同数量的样本。具体而言,表1中的#100表示初始数据集大小为100个样本。
本研究中所有实验仅执行一次选择迭代。
对于SSL算法,选择了经典的FixMatch和FreeMatch。
对于主动学习算法,使用了四种方法:CoreSet、AlphaMix、ActiveFT和Noise。
此外,使用ViT作为分类模型,并利用了框架提供的预训练权重。
5.2 结果分析
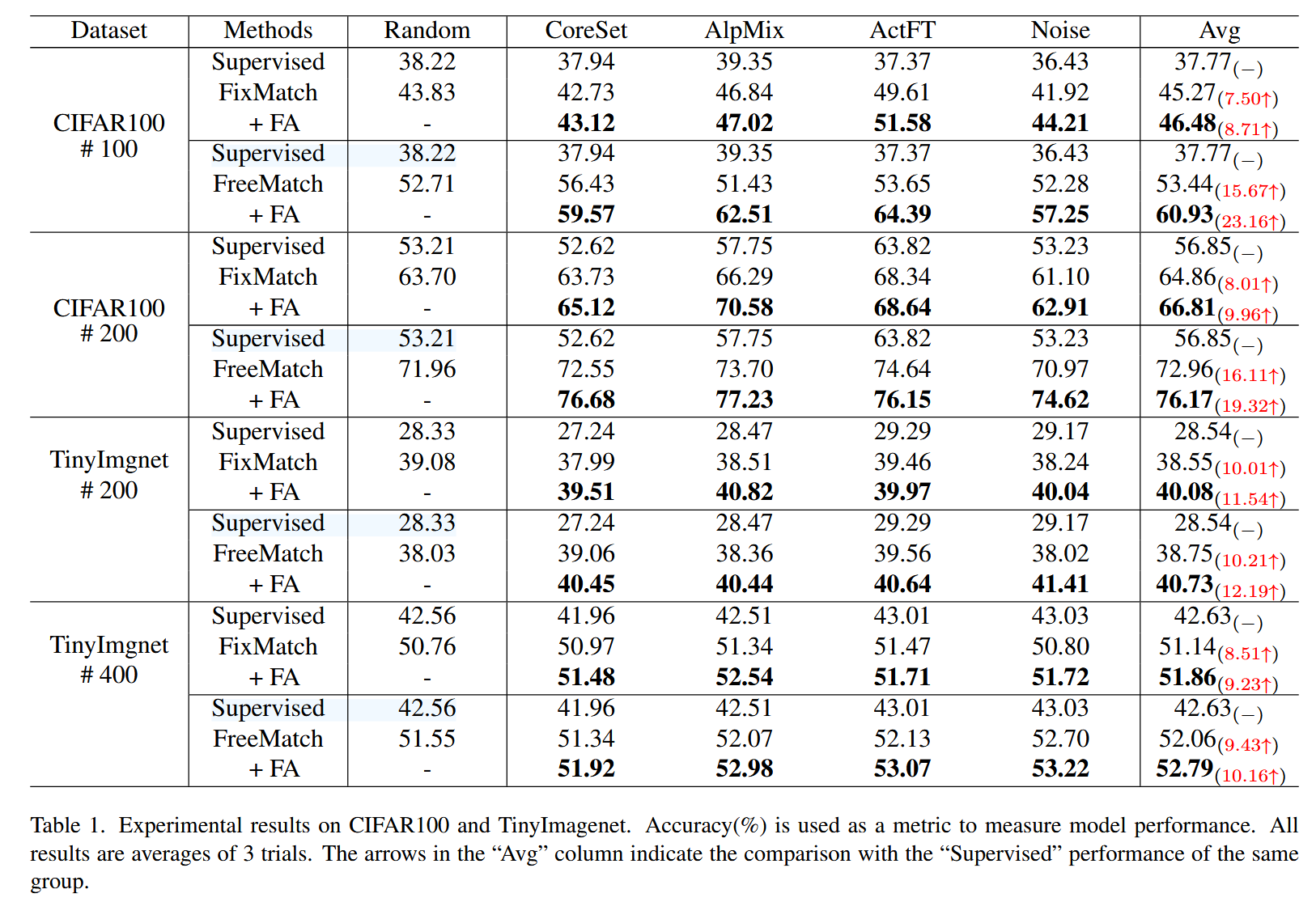
总体实验结果如表1所示。共进行了32组对比实验,每组实验将一种AL方法与三种训练策略结合:监督学习、SSL和SSL+FA。
其中,"监督学习"代表仅使用标注数据的标准监督学习;
第二行(FixMatch和FreeMatch)展示了使用SSL训练策略的结果;
第三行"+FA"表示在SSL基础上加入了提出的特征对齐模块。
最后一列"Avg"值代表了每行中四种AL方法的平均值,反映了不同SSL设置下与AL结合的平均性能。
结果表明,在引入提出的模块后,所有情况下的最终性能均得到提升。
值得注意的是,直接在SSL中应用AL有时表现不如随机选择。例如,在CIFAR100#100设置下使用FreeMatch SSL算法时,AL样本选择算法如AlpMix(51.43%)和Noise(52.28%)的性能低于随机选择(52.71%)。然而,在加入提出的FA模块后,相比随机选择性能显示出显著提升。这进一步验证了特征对齐模块的有效性。
5.3 消融研究
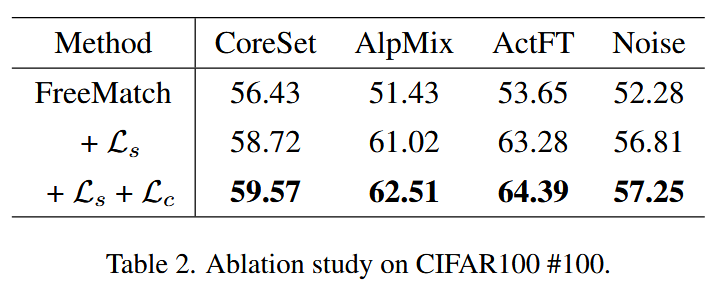
本文提出的特征对齐模块包含两个关键损失函数,即对比损失Lc和相似性损失Ls。为验证该模块的有效性,在CIFAR100#100设置下使用FreeMatch SSL算法进行了消融实验。实验结果如表2所示。两个损失函数均对性能提升有贡献,实验结果进一步证明了这两个损失函数的有效性
5.4 超参数设置
本方法中有一个超参数T,代表强增强视图队列的长度。T值越大意味着队列包含更多的强增强视图。根据自监督学习的一些研究结果,更多的强增强通常会导致同一类别内两个不同样本之间的特征相似度更高。因此,T值对算法性能有重要影响。
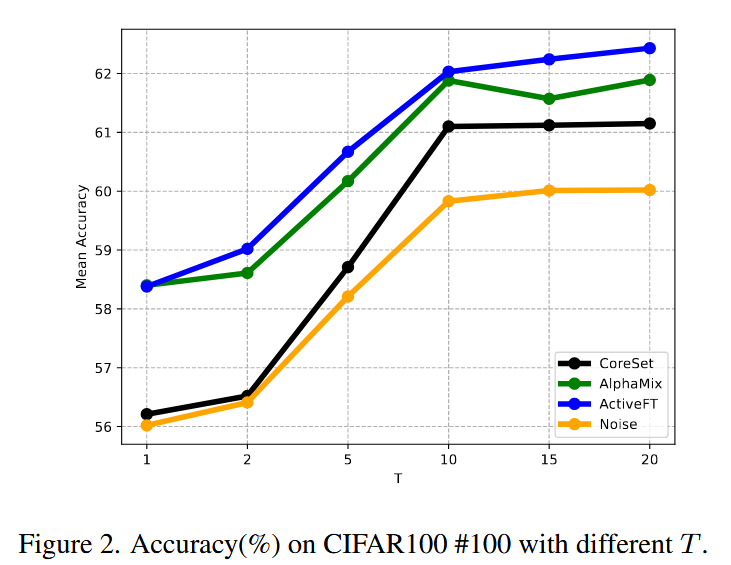
图2展示了在CIFAR100#100设置下使用FreeMatch SSL算法时,不同T值对多种主动学习算法的结果。可以观察到,随着T值的增加,算法性能有所提升。当T为1时,仅使用单个强增强数据进行未标注数据聚类。由于强增强视图下样本特征变化较大,当T较小时聚类效果通常较差。然而,随着T的增加,队列中保存的样本不同强增强视图数量逐渐增加,算法性能得到提升。但当T大于10时,性能提升不再显著,反而需要更多GPU内存。因此,选择T的最优参数为10。
5.5 相似性损失函数的效果

图3:无标签数据特征分布的可视化。同一种颜色表示样本类别相同。
(a) 使用相似性损失函数时的特征分布。(b) 表示没有相似性损失函数的特征分布。
本节对相似性损失函数Ls进行了实验验证。在CIFAR100#100设置下使用FreeMatch算法训练模型,并利用t-SNE可视化未标注数据前30个类别的特征分布。为便于直观解释,随机选择其中5个类别并用不同颜色标注。结果表明,相似性损失函数的引入使得特征分布更加集中,聚类性能显著提升,这与本文的动机很好地吻合。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)