主流抠图算法trimap-based/free
抠图类任务目前是基础类任务,是我们不需要去训练的,目前开源的抠图类算法很多,包括通用抠图,头部抠图,物体抠图,人像抠图,视频抠图这些目前都是有相当丰富的开源接口可以使用,通常来说,最多需要finetune一次,基本拿来即用,在基础的ai项目上,其实有很多项目都不需要在训练了,比如说目前的行人识别,行人骨骼点识别,人脸识别等很多项目主要是在部署这块,包括后处理逻辑的开发和多平台的移植这块,算法侧的训
GitHub - JizhiziLi/matting-survey: Deep Image Matting: A Comprehensive SurveyDeep Image Matting: A Comprehensive Survey. Contribute to JizhiziLi/matting-survey development by creating an account on GitHub. https://github.com/JizhiziLi/matting-survey数据集介绍 - Matting and Segmentation_supervisely person dataset-CSDN博客文章浏览阅读3.5k次,点赞6次,收藏15次。文章目录1. Matting(抠图)1.1 Image(图片)(1) PPM-100(2) 爱分割 - matting_human_datasets(3) Adobe Image Matting Dataset(AIM)(4) Alpha Matting(5) Distinctions-646 (D646)(6) AIM-500(7) DUTS1.2 Video(视频)2. Segmentation(分割)2.1 Image(图片)(1) SuperviselyPersonDataset(SPD)2.2 V_supervisely person dataset
https://github.com/JizhiziLi/matting-survey数据集介绍 - Matting and Segmentation_supervisely person dataset-CSDN博客文章浏览阅读3.5k次,点赞6次,收藏15次。文章目录1. Matting(抠图)1.1 Image(图片)(1) PPM-100(2) 爱分割 - matting_human_datasets(3) Adobe Image Matting Dataset(AIM)(4) Alpha Matting(5) Distinctions-646 (D646)(6) AIM-500(7) DUTS1.2 Video(视频)2. Segmentation(分割)2.1 Image(图片)(1) SuperviselyPersonDataset(SPD)2.2 V_supervisely person dataset https://blog.csdn.net/qq_41731861/article/details/121927295抠图gt是0-1之间的,分割gt是0和1的,当然多类别还可以是更多,方法主要是基于trimap-based和trimap-free的,trimap-based的普遍效果要好一点,目前公司线上服务其实也是trimap-based,宽泛的trimap-based,即基于先验信息的,包括trimap,mask,bg,pose等。抠图中的trimap还是很重要的,从原图中产生trimap是不太可能的,所以必须要产生trimap图去精准控制边缘的产生,先用一个分割或者显著图检测的方法产生trimap,然后基于trimap去产生真正的alpha,不过trimap生成的有问题,第二步也有问题,虽然第二步是产生alpha的直接步骤,但是其实第一步的trimap也很关键,传统trimap-based的方法也需要线上手动的去产生trimap,体验很不好。从dim这样的方法来看,也许基于trimap的方法也不需要那么复杂。1.基于精确的trimap,trimap越精细,二阶段越轻松;2.基于粗糙的trimap,trimap-based的方法能力越强。我倾向于第一种思路,第二种有个致命点,就是一旦trimap损害就完蛋了,trimap损坏之后,不管怎么监督,都很能去扣,而且第一种思路,如果一阶段的精确的trimap能生成好,直接用显著性检测的方法就能产生很好的alpha图。
https://blog.csdn.net/qq_41731861/article/details/121927295抠图gt是0-1之间的,分割gt是0和1的,当然多类别还可以是更多,方法主要是基于trimap-based和trimap-free的,trimap-based的普遍效果要好一点,目前公司线上服务其实也是trimap-based,宽泛的trimap-based,即基于先验信息的,包括trimap,mask,bg,pose等。抠图中的trimap还是很重要的,从原图中产生trimap是不太可能的,所以必须要产生trimap图去精准控制边缘的产生,先用一个分割或者显著图检测的方法产生trimap,然后基于trimap去产生真正的alpha,不过trimap生成的有问题,第二步也有问题,虽然第二步是产生alpha的直接步骤,但是其实第一步的trimap也很关键,传统trimap-based的方法也需要线上手动的去产生trimap,体验很不好。从dim这样的方法来看,也许基于trimap的方法也不需要那么复杂。1.基于精确的trimap,trimap越精细,二阶段越轻松;2.基于粗糙的trimap,trimap-based的方法能力越强。我倾向于第一种思路,第二种有个致命点,就是一旦trimap损害就完蛋了,trimap损坏之后,不管怎么监督,都很能去扣,而且第一种思路,如果一阶段的精确的trimap能生成好,直接用显著性检测的方法就能产生很好的alpha图。
1.Trimap-based
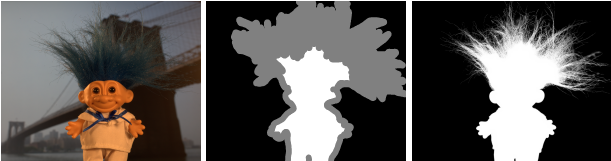
0/128/255,前景/未知/背景。
1.1 Deep image matting adobe 2017
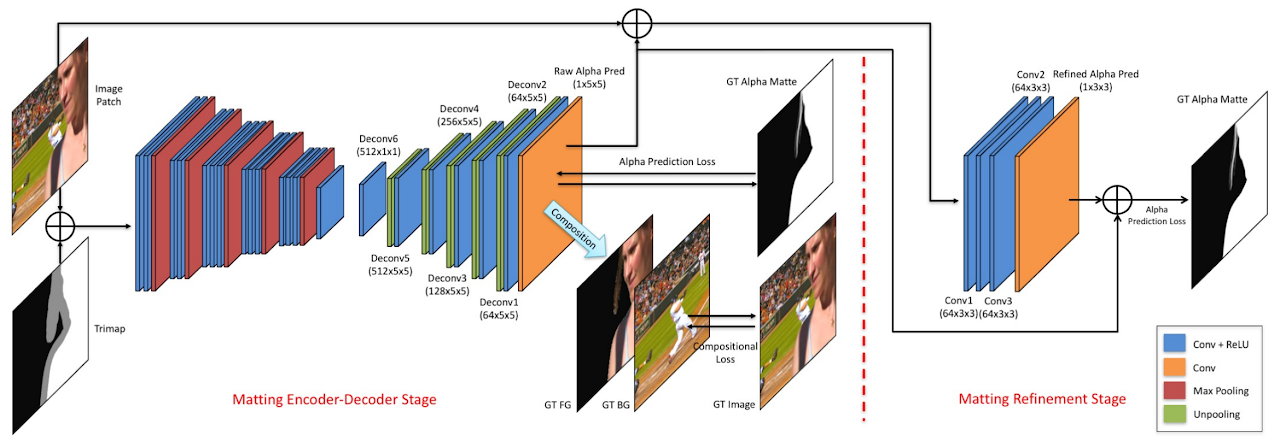

首个端到端alpha预测网络,粗略-精细抠图思路。提出了Composition-1k数据集,将精细标注的前景和不同背景融合,得到了45500训练图像和1000测试图像。
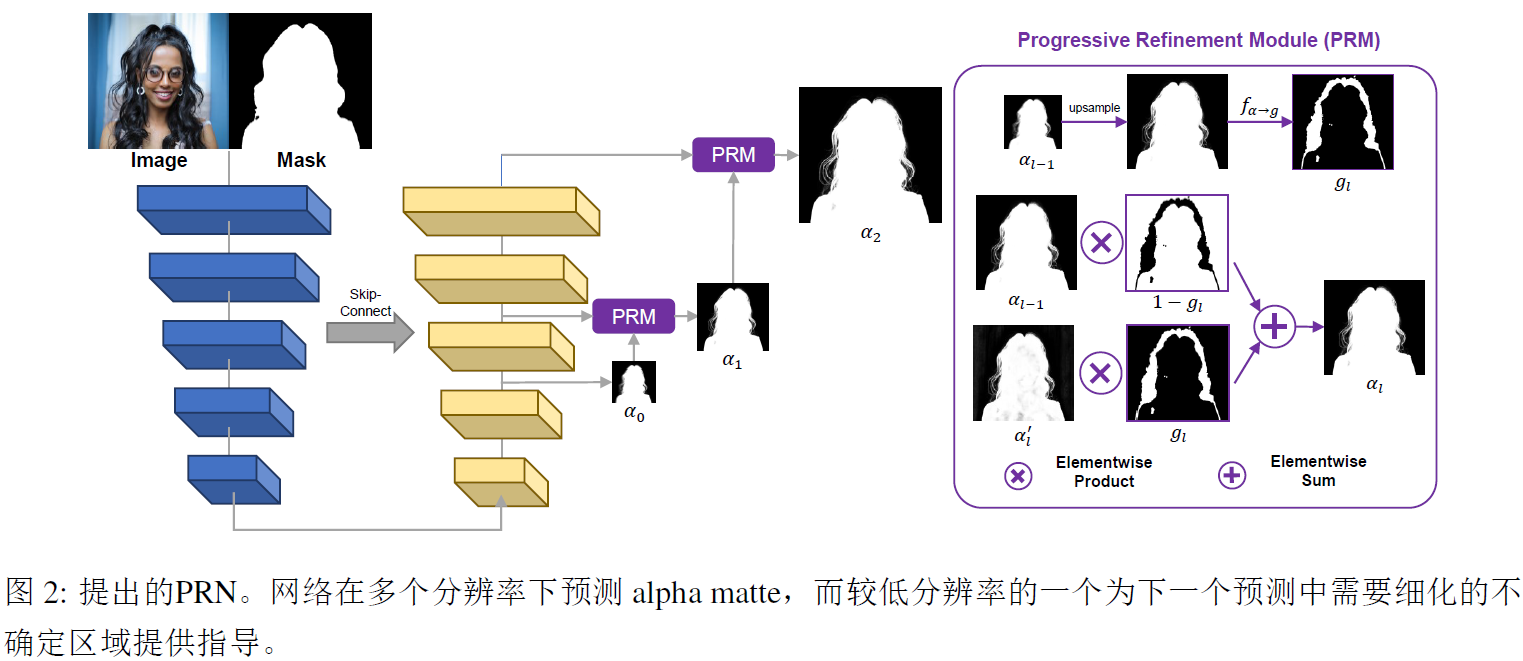
1.2 MGMatting
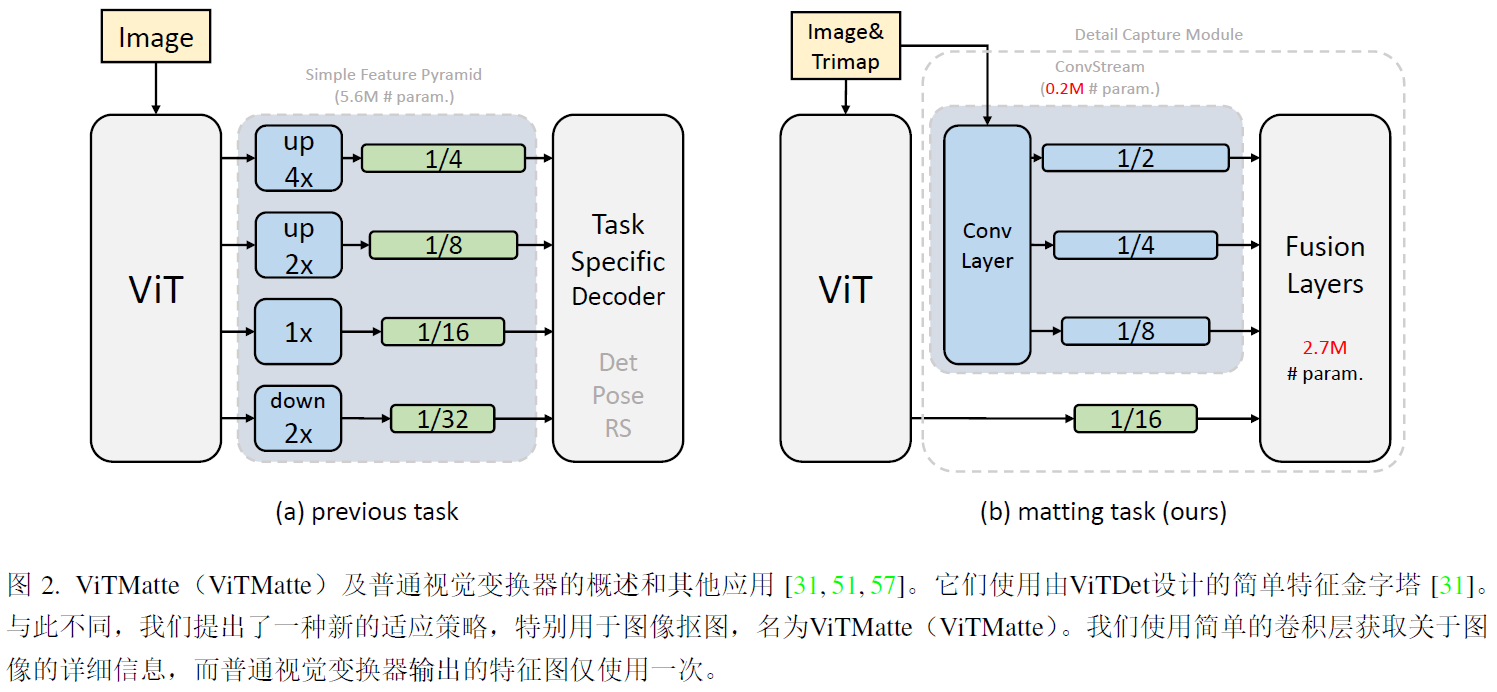
1.5 Matteformer
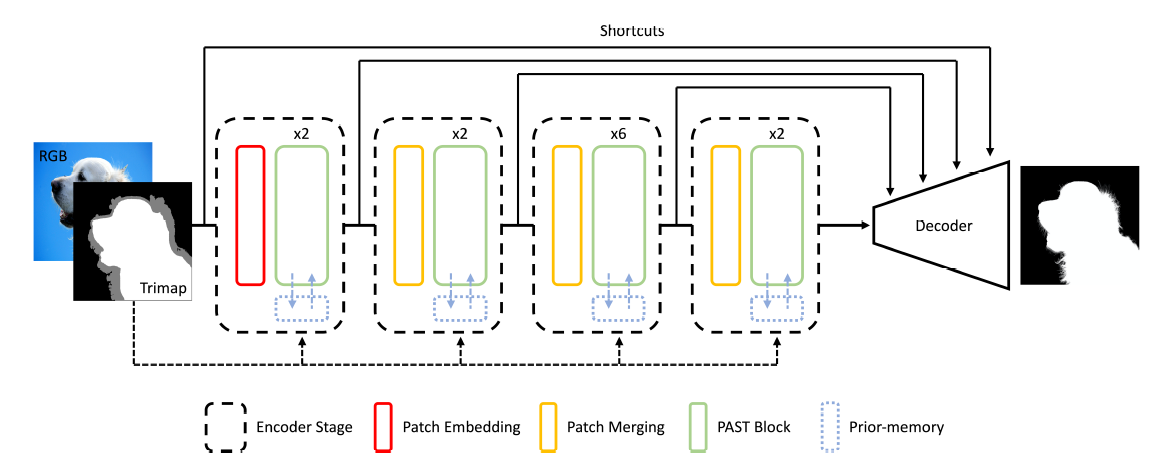
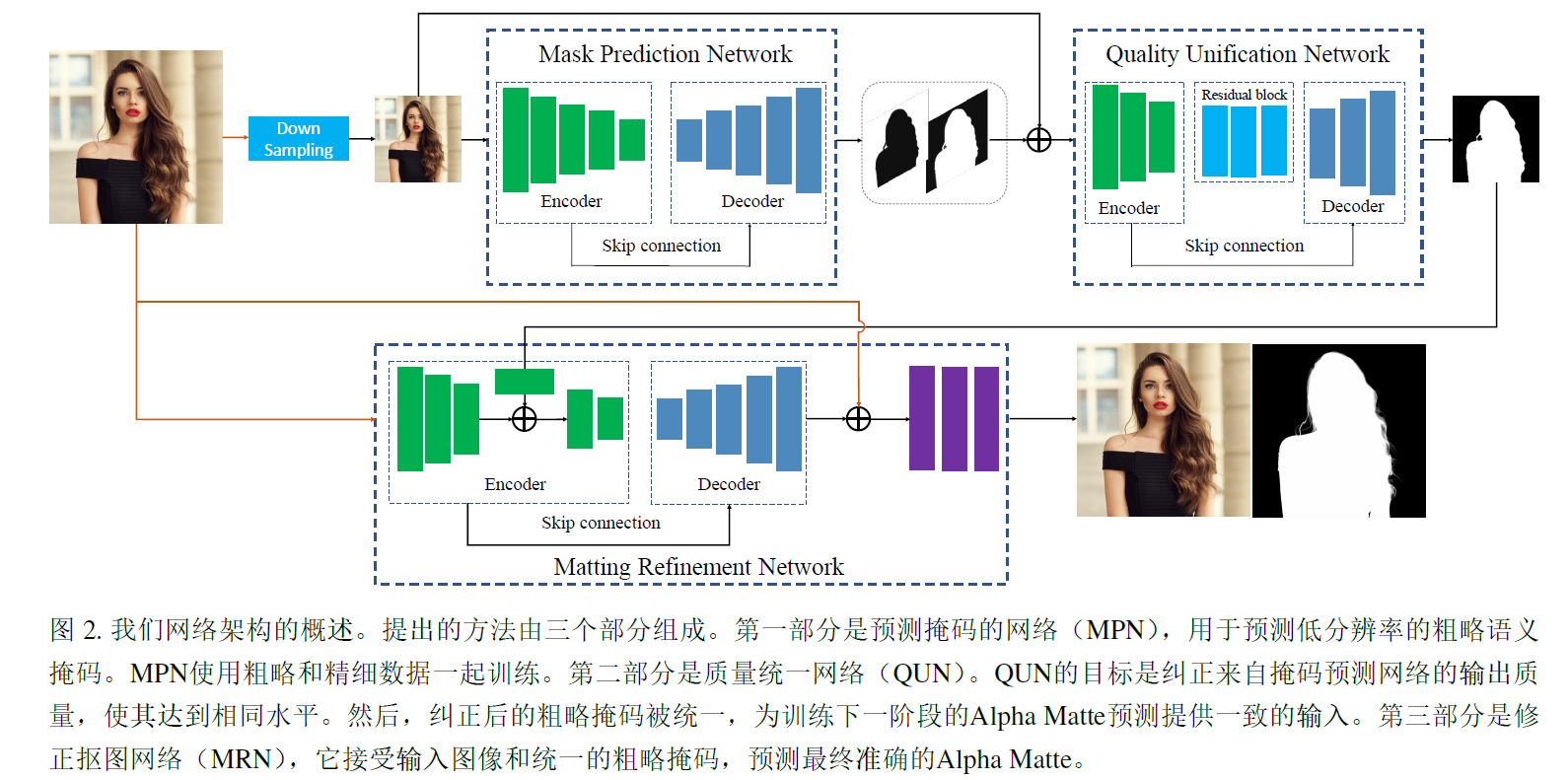
2.1 Semantic Huaman Matting
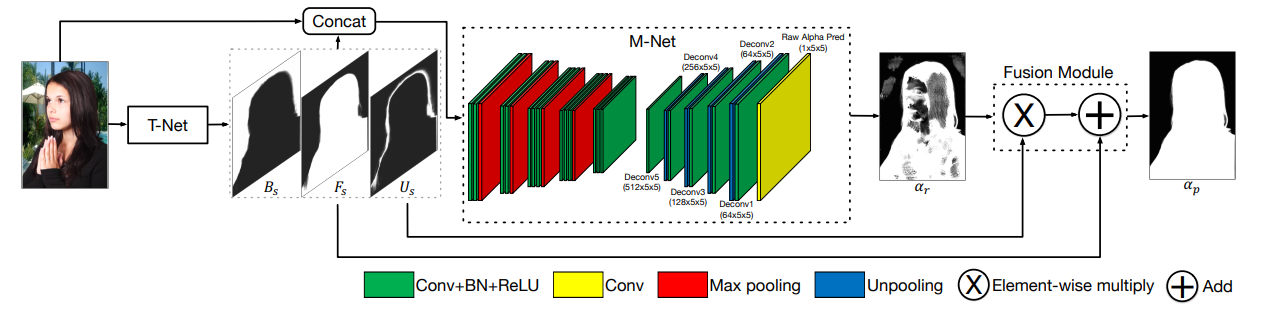
Semantic human matting-CSDN博客文章浏览阅读283次。将3通道图像与来自TNet的3通道图串联作为6通道输入,DIM使用3通道图和1通道trimap(1,0.5,0表示前景,未知区域和背景)作为4通道输入,6通道输入和4通道输入几乎有相同的性能,MNet有13个卷积层和4个最大池化层,编码器网络和VGG16相同,VGG16的conv1是3个输入通道,MNet有6个输入通道,每个卷积层后面添加了批归一化,移除了conv6和deconv6.TNet预训练,膨胀alpha生成trimap,400x400;扮演着语义分割的角色,输出3通道图,PSPNet50.https://blog.csdn.net/u012193416/article/details/136393841?spm=1001.2014.3001.5501 T-Net对像素三分类得到trimap,与图像concat得到六通道输入到M-Net,M-Net通过encoder-decoder得到较为粗糙的alpha,最后将T-Net和M-Net的输出送入到融合模块Fusion Module中,得到精确的alpha。三个损失,分类损失,alpha损失和组合损失。
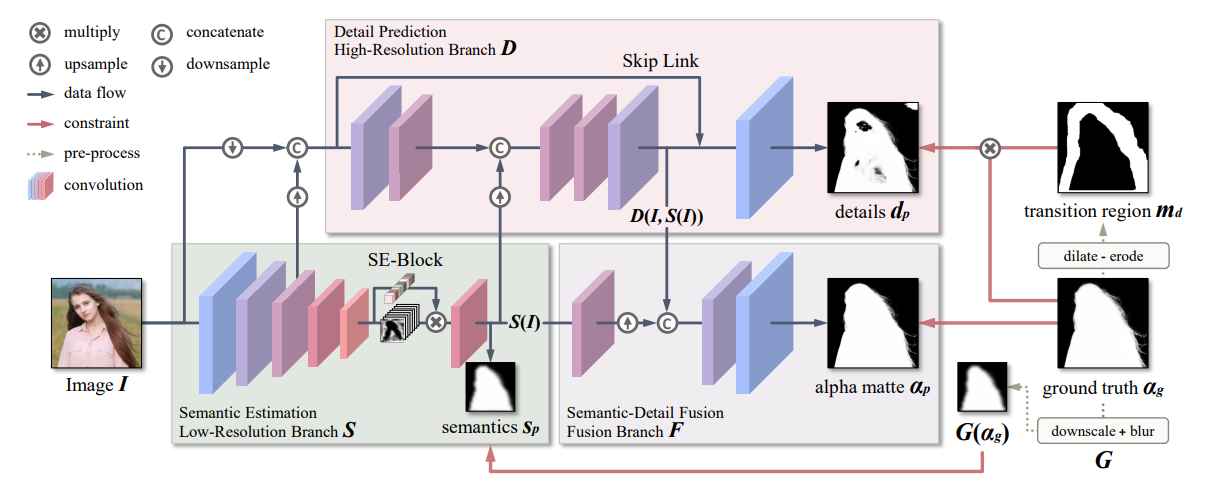
2.2 Modnet
网络更擅长学习单一任务,因此拆分了三个子任务,S/D/F三个模块,以63fps在512x512下,实测还是很快的。
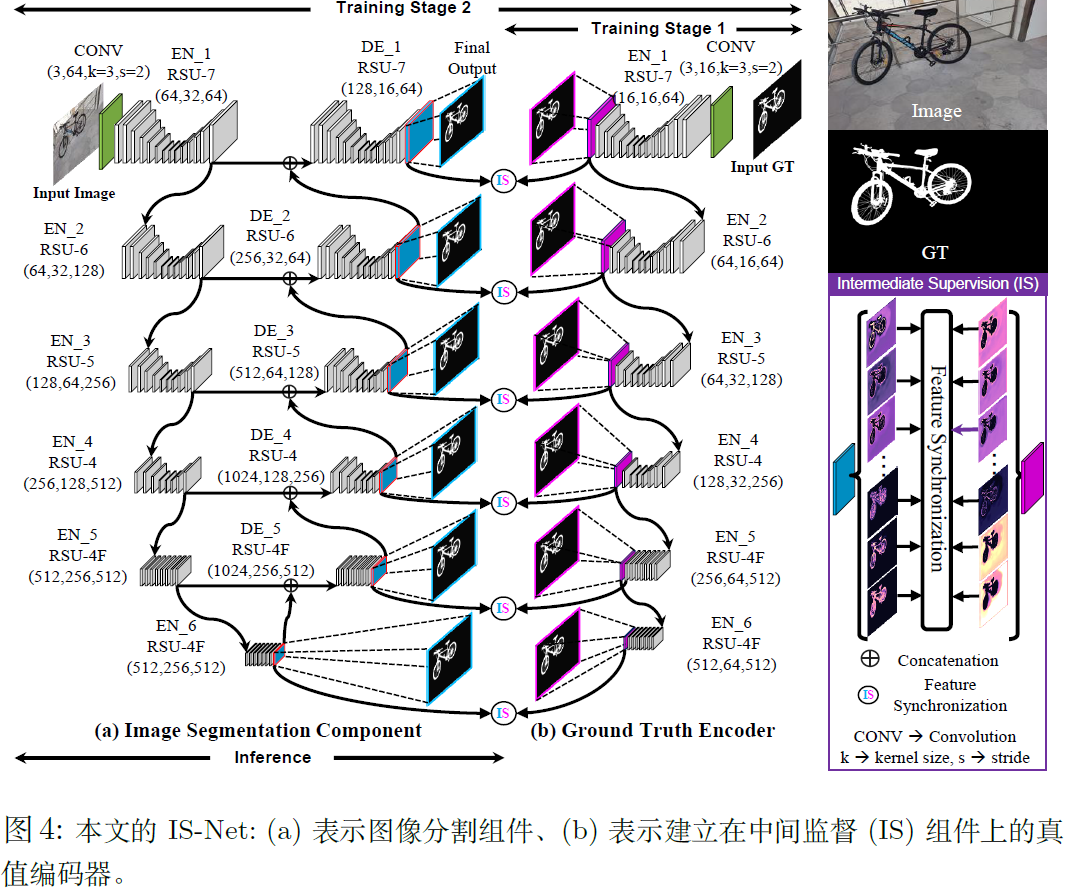
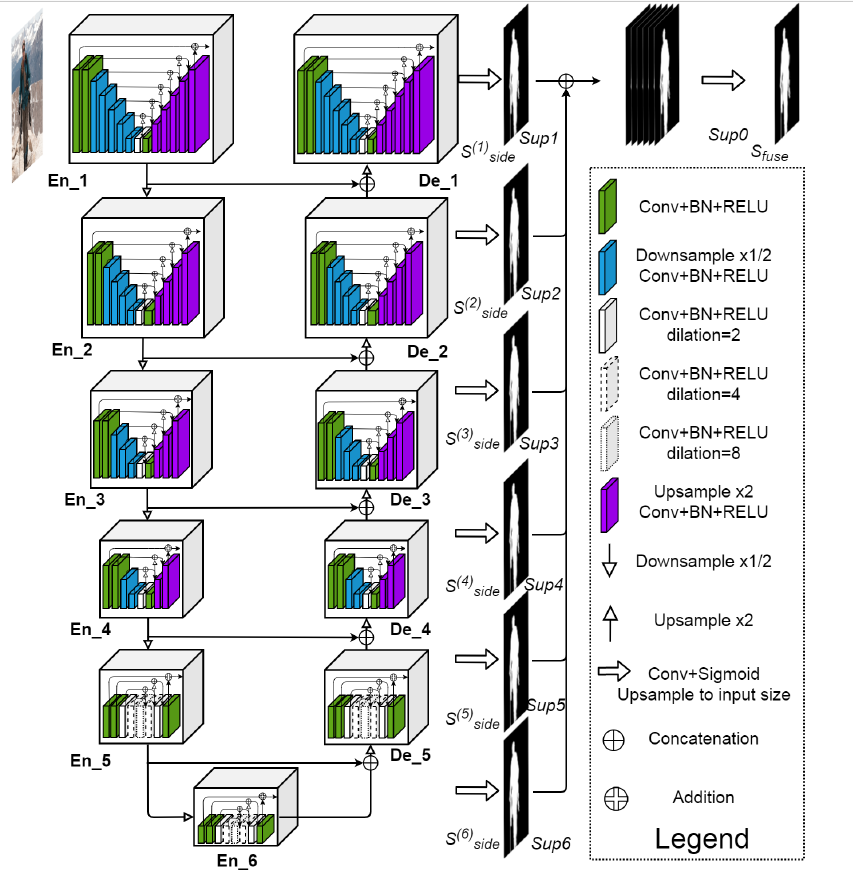
Highly accurate dichotomous image segmentation-CSDN博客文章浏览阅读384次,点赞4次,收藏8次。在图像分割组件Fsg中,在生成概率图之前,图像I被转换为一组高维中间特征图,每个特征图与其对应的GT中间特征图具有相同的维度,接着,中间监督通过高维特征一致性损失,对中间特征进行监督。大多数模型在训练集上容易过度拟合,可以对给定的深度网络的中间输出进行监督,通过神经网络的最后一层特征图而产生的单通道概率图,然而将高维特征转换为单通道概率图本质上是一种降维操作,不可避免的丢失关键信息。使用GIMP对每张图进行像素级精度手动标记,平均每张图图像的标记时间约30分钟,有些图像的标记时间长达10h。https://blog.csdn.net/u012193416/article/details/136326141?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22136326141%22%2C%22source%22%3A%22u012193416%22%7DISNet由一个GT编码器,一个图像分割组件和一个中间监督策略组成。GT encoder(27.7MB)用于将GT编码到高维空间,然后对分割组件进行中间监督,同时,Image Segmentation Component(176.6MB),具有捕获精细结构并处理大尺寸(1024x1024)输入的能力,选择u2net作为图像分割组件,u2net最初为小尺寸320x320的显著图检测设计,不能直接处理1024x1024的图,本文采用u2net的结构,在其第一个编码器阶段之前增加一个输入卷积层,输入卷积层为普通卷积层,核大小为3x3,步长为2,给定一个1024x1024x3的图,输入卷积层首先将其转换为一个特征映射512x512x64,然后将其输入到u2net中,输入通道更改为64。
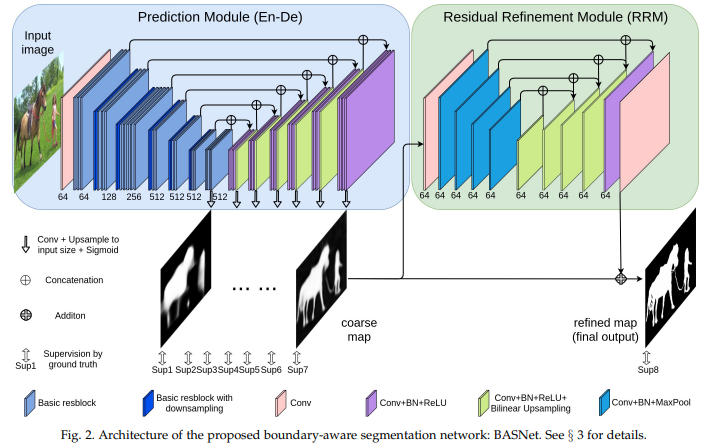
2.6 u2net
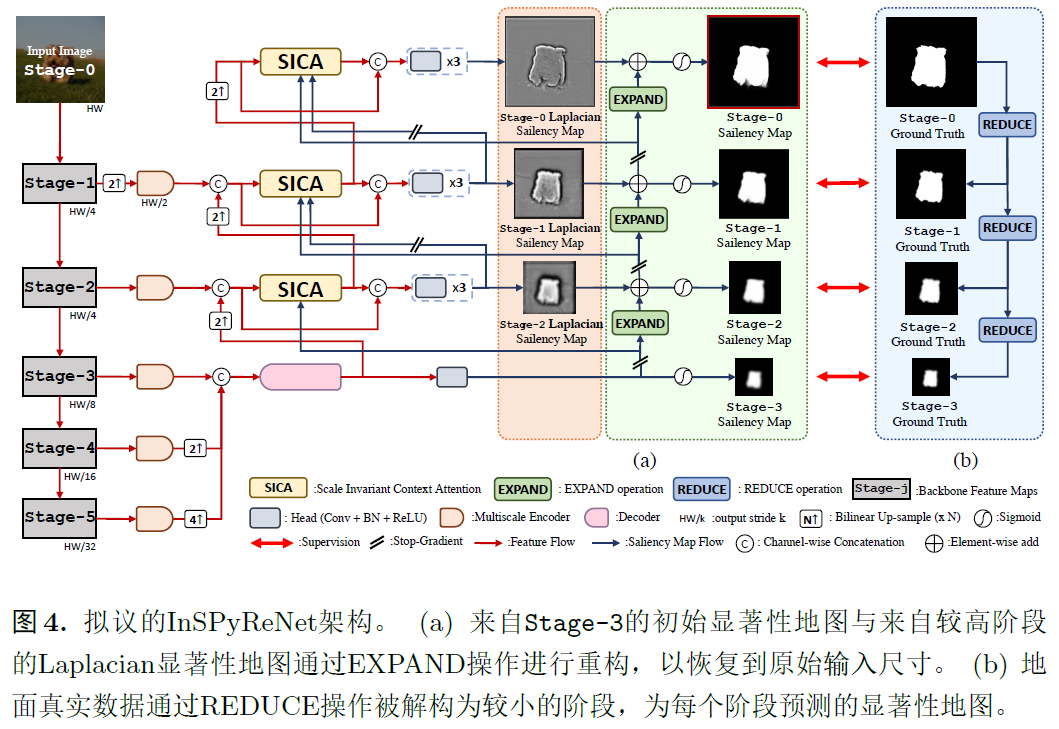
3.1 Adobe Image Matting Datasets DIM数据,RGB+Trimap方法必用的数据集

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 20
20 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)