nlp处理技术-文章分类java实现方案
项目背景:为了解决采集的文章,智能进行文章分类因为本人是java代码,看java jar比较爽。于是选择了fasttext4j ( facebook开发源代码,底层是c++,做的jar)业务实现流程1:采集一个目标文章网站, 文章内容+栏目id2:整理数据样本。把mysql数据转移到File。作为fasttext4j的数据样本。样本数据如图,本人花了3小时下载的模...
项目背景:为了解决采集的文章,智能进行文章分类
因为本人是java代码,看java jar比较爽。
于是选择了fasttext4j ( facebook开发源代码,底层是c++,做的jar)
业务实现流程
1:采集一个目标文章网站, 文章内容+栏目id
2:整理数据样本。把mysql数据转移到File。作为fasttext4j的数据样本。
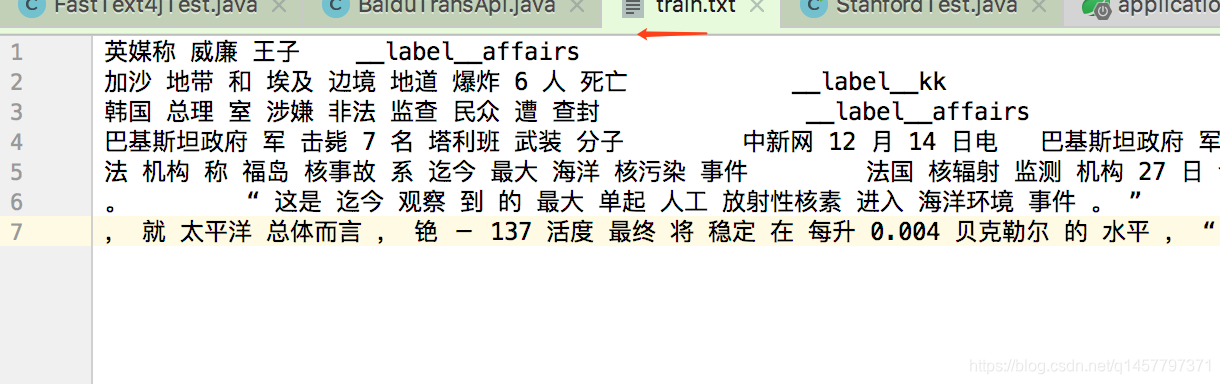
样本数据如图,本人花了3小时下载的模板。 中文分词参数,一行一篇文章。 然后一行最后面是__label__xx 文章分类编号
3:用fasttext进行训练
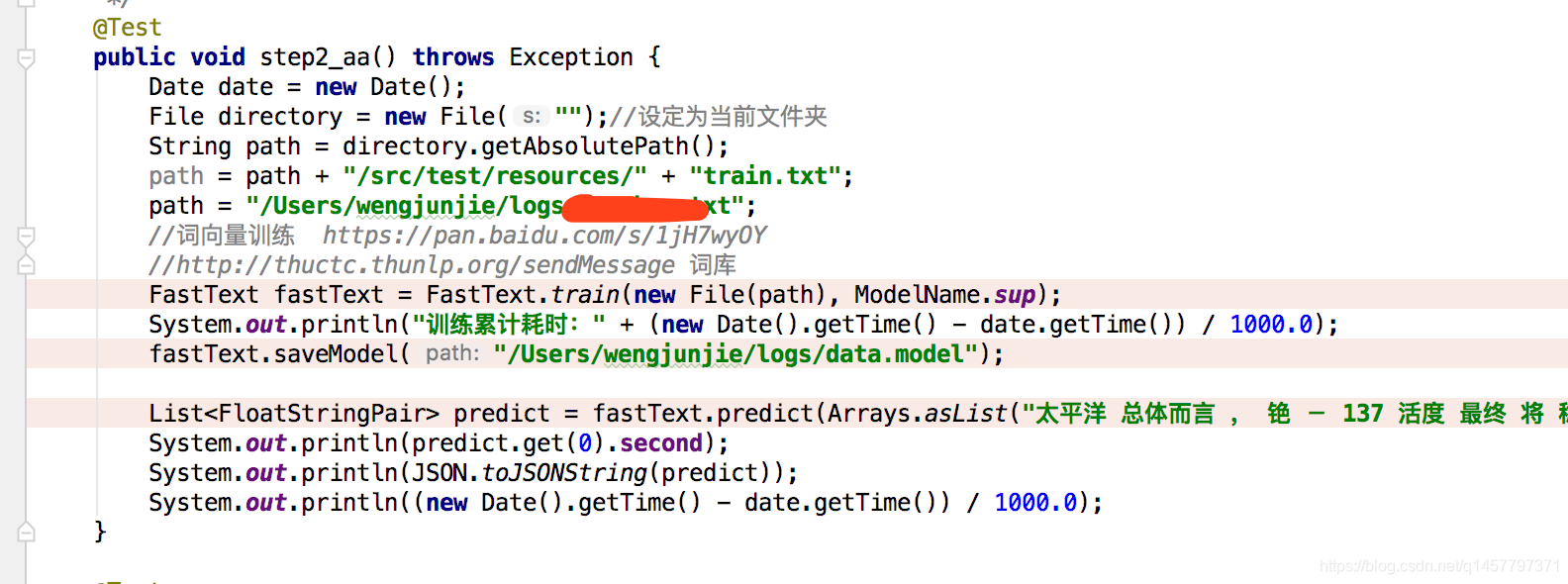
注:请使用ModelName.sup 的训练模式, 而不是用词向量,后面这种方式生成模型。
4:第一次生成模型很麻烦,900片文章,预计在2分钟左右。以后直接调用模型即可。

5:predict预测
现在遇到的问题
数据样本不均匀的时候,然后==》一篇文章参数进来,智能匹配到5的概率很大
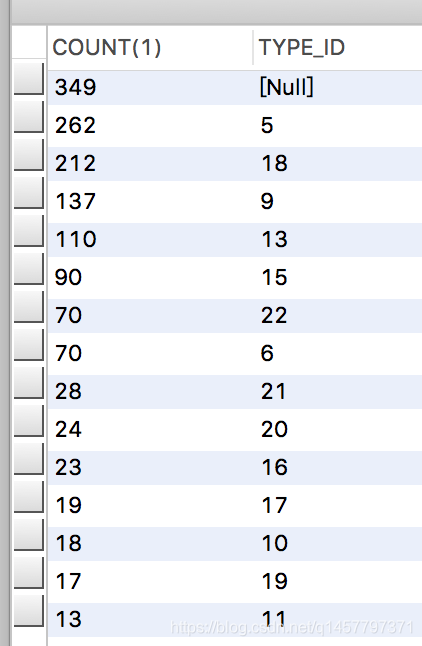
当前的解决方案,为了不同类目的样本一致,随机取13篇文章,再跑模型训练,你会怎么去处理呢?
本人微信:liuxia8_com 一起学习NLP处理技术。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)