朝向城市空间中的自主无人机视觉目标搜索:基准与代理方法学
城市环境中的空中视觉目标搜索(AVOS)任务要求无人驾驶飞行器(UAVs)自主使用视觉和文本线索搜索并识别目标物体,而无需外部引导。现有方法在复杂的城市环境中表现不佳,原因是冗余的语义处理、相似物体的区分困难以及探索-利用困境。为弥补这一差距并支持AVOS任务,我们引入CityAVOS,这是首个针对常见城市物体自主搜索的基准数据集。该数据集包含六个物体类别的2,420个任务,难度级别各异,能够全面
纪亚泰
数字智能国家重点实验室
建模与仿真
中国长沙
刘北丹
数字智能国家重点实验室
建模与仿真
中国长沙
秋四航,胡跃
数字智能国家重点实验室
建模与仿真
中国长沙
朱正秋
数字智能国家重点实验室
建模与仿真
中国长沙
zhuzhengqiu12@nudt.edu.cn
高晨
清华大学电子工程系 北京,中国
尹全军
数字智能国家重点实验室
建模与仿真
中国长沙
赵勇
数字智能国家重点实验室
建模与仿真
中国长沙
赵一浩
清华大学电子工程系
北京,中国
李勇
清华大学电子工程系
北京,中国
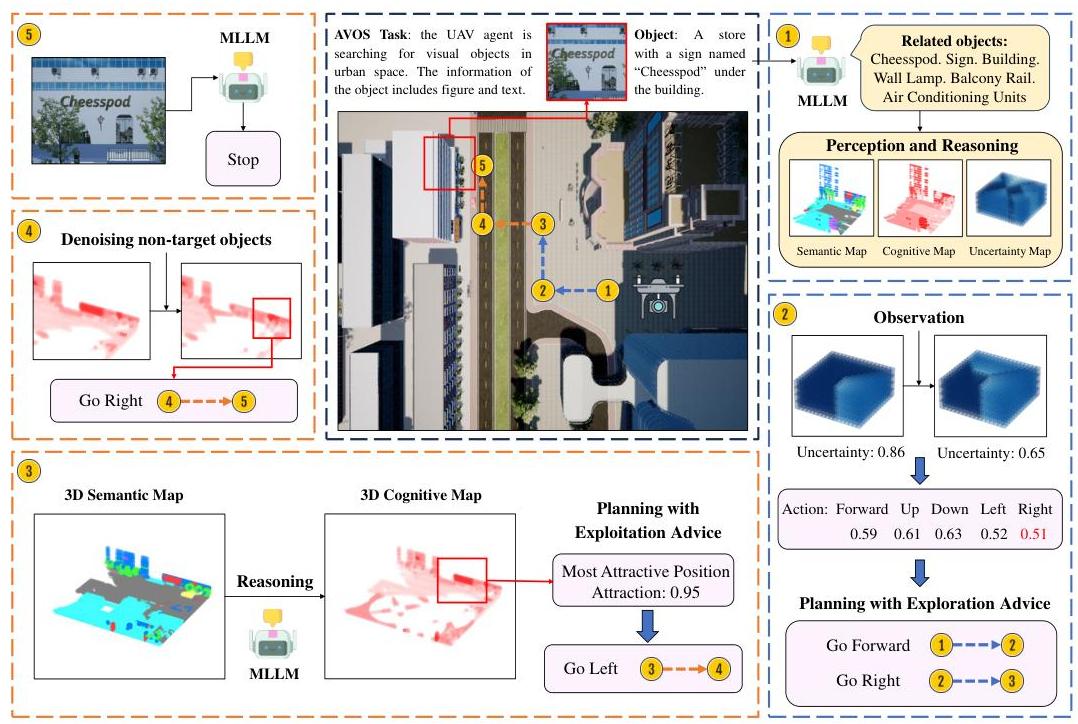
图1:在不熟悉的城区环境中执行AVOS任务的UAV示例。在搜索过程中,UAV代理感知周围的城市环境,并推理目标物体的潜在位置。在步骤1和2中,代理计划探索未知空间的动作。在步骤3和4中,代理在认知地图中吸引力最高的区域进行搜索。最后,在步骤5中,代理找到目标物体并停止。
摘要
城市环境中的空中视觉目标搜索(AVOS)任务要求无人驾驶飞行器(UAVs)自主使用视觉和文本线索搜索并识别目标物体,而无需外部引导。现有方法在复杂的城市环境中表现不佳,原因是冗余的语义处理、相似物体的区分困难以及探索-利用困境。为弥补这一差距并支持AVOS任务,我们引入CityAVOS,这是首个针对常见城市物体自主搜索的基准数据集。该数据集包含六个物体类别的2,420个任务,难度级别各异,能够全面评估UAV代理的搜索能力。为解决AVOS任务,我们还提出了PRPSearcher(感知-推理-规划搜索者),这是一种由多模态大型语言模型(MLLMs)驱动的新颖代理方法,模仿人类的三层认知结构。具体来说,PRPSearcher构建了三种专用地图:以物体为中心的动态语义地图,增强空间感知;基于语义吸引力值的3D认知地图,用于目标推理;以及3D不确定性地图,用于平衡探索-利用搜索。此外,我们的方法结合了一种降噪机制,以减轻相似物体的干扰,并利用灵感促进思考(IPT)提示机制进行自适应动作规划。在CityAVOS上的实验结果表明,PRPSearcher在成功率和搜索效率方面均优于现有基线(平均:+37.69% SR,+28.96% SPL,-30.69% MSS,-46.40% NE)。尽管表现令人鼓舞,但与人类相比的性能差距突显了在AVOS任务中需要更好的语义推理和空间探索能力。这项工作为未来的实体目标搜索奠定了基础。数据集和源代码可在https://anonymous.4open.science/r/CityAVOS-3DF8获得。
关键词
城市实体智能,空中视觉目标搜索,多模态语言模型,空间推理
1 引言
无人驾驶飞行器(UAVs)在城市环境中的物体搜索任务中得到了广泛应用。显著的应用案例包括物流系统中的最后一英里配送[27]和应急响应场景中的搜索操作[42]。传统的基于UAV的物体搜索解决方案通常利用元启发式或深度强化学习方法通过优化飞行路径规划来提高搜索效率[16, 35]。然而,动态视觉观察的潜力往往被忽视。最近在实体智能方面的进展使基于多模态大型语言模型(MLLMs)的UAV代理能够在视觉理解、认知推理和动作决策方面表现出类似人类的熟练程度[20]。因此,传统的物体搜索任务正在向空中视觉物体搜索(AVOS)任务转变,其中UAVs需要在不熟悉的城区环境中自主寻找视觉物体,仅使用提供的线索(例如,图像、文本描述或两者兼有)而无需任何导航辅助或外部指令。
目前,城市空间中的AVOS任务研究仍处于起步阶段。类似于AVOS的任务包括
视觉-语言导航(VLN)[17]和目标导航任务[6, 7],这些任务都利用动态视觉输入来指导连续动作决策。VLN任务通常需要精细的导航指令来完成特定轨迹,已从室内[45]扩展到室外场景,如AerialVLN [19]、OpenUAV [28]和EmbodiedCity [13]。相比之下,AVOS任务缺乏这种精细的导航指令,而是依赖于目标物体的描述。此外,目标导航和AVOS任务具有相同的任务格式,都是旨在未知区域中定位特定物体。然而,当前关于目标导航的大多数研究主要集中在室内场景[31, 32]。
本文探讨城市空间中的AVOS任务,与先前的研究相比面临三个独特的挑战:
- 复杂且丰富的物体语义对空间感知的环境表示构成挑战:现有方法主要依赖点云或语义网格地图进行空间感知,但由于复杂城市环境中冗余的语义信息,它们在计算效率和制图准确性上往往不足。因此,迫切需要设计适用于城市环境的新型语义制图方法,既计算高效又准确。
- 相似物体的视觉相似性对目标推理和识别构成挑战:城市场景中常常存在多个相似的物体,如商店、广告牌和汽车,由于其视觉相似性,远程区分较为困难。准确识别通常需要更近的观察。因此,关键挑战在于在目标推理过程中减轻这些视觉相似但错误的目标的干扰。
- 广阔的城市空间和复杂的空间结构对动作规划构成挑战:在大而复杂的城市环境中,建筑物、树木和其他遮挡物可能在代理构建的语义地图中造成视觉盲点。这导致了一个难题:仅搜索语义目标会忽略未探索的区域,而广泛探索通常是低效的。因此,平衡动作规划中的探索-利用困境是一个挑战。
作为第一步,我们开发了一个基准数据集CityAVOS,用于评估代理在AVOS任务中的表现。表1总结了该数据集与其他基准数据集的区别。CityAVOS数据集将六个目标类型分类,并定义了三个搜索难度级别。任务数据集涉及一个UAV代理在复杂场景中搜索和识别常见城市目标,这些目标由图像和文本描述共同描述,场景特征是复杂的语义信息和空间结构。值得注意的是,UAV代理没有引导指令,需要执行零样本自主搜索。因此,该数据集评估了它们在无其他协助的情况下自主搜索不熟悉城市区域的能力。
为了解决AVOS任务,我们介绍了PRPSearcher(感知-推理-规划UAV搜索者),这是一种由MLLM驱动的新型代理方法,旨在模仿人类三层认知架构,用于城市空间中视觉物体的自主搜索,如图1所示。在感知阶段,PRPSearcher提取与物体相关的语义以构建以物体为中心的3D动态语义地图。该地图具有以物体为中心的语义分割和动态语义标签更新机制,
表1:CityAVOS与现有基准的对比。表格中间分界线以上的数据集是地面数据集,以下的是空中数据集。Ntask N_{\text {task }}Ntask : 任务数量。Ntrai N_{\text {trai }}Ntrai : 总轨迹数。Path Len: 轨迹的平均长度,以米为单位。
| 地点 | Ntask N_{\text {task }}Ntask | Ntrai N_{\text {trai }}Ntrai | Path Len. | 任务类型 | 无指令 | |
|---|---|---|---|---|---|---|
| R2R [1] | 室内(地面) | 1020 | 7189 | 10.0 | 导航 | ×\times× |
| Reverie [22] | 室内(地面) | 4944 | 7000 | 10.0 | 导航 | ×\times× |
| ProcTHOR [8] | 室内(地面) | 10 K | - | - | 物体导航 | ✓\checkmark✓ |
| HM3DSem [36] | 室内(地面) | 142646 | - | - | 物体导航 | ✓\checkmark✓ |
| AerialVLN [19] | 城市(空中) | 8446 | 8446 | 661.8 | 导航 | ×\times× |
| CityNav [17] | 城市(空中) | - | 32637 | 545 | 导航 | ×\times× |
| EmbodiedCity [13] | 城市(空中) | - | 99.7 K | - | 导航 | ×\times× |
| OpenUAV [28] | 城市(空中) | - | 12149 | 255 | 导航 | ×\times× |
| Openfly [14] | 城市(空中) | 3 K | 100 K | 99.1 | 导航 | ×\times× |
| CityAVOS (Ours) | 城市(空中) | 2420 | 2420 | 174.7 | 物体搜索 | ✓\checkmark✓ |
从而提高了映射效率和准确性。此外,PRPSearcher 构建并更新了3D不确定性地图,以测量环境被探索的程度。在推理阶段,基于“吸引力值”(由 MLLM 推导出的物体语义对 UAV 代理的吸引力强度)创建了3D认知地图。此外,我们设计了一种去噪机制以消除非目标物体的影响。在规划阶段,我们根据认知地图和不确定性地图生成探索和利用建议。此外,我们引入了灵感促进思考(IPT)提示机制,以帮助代理在决策过程中实现探索和利用之间的平衡。结果显示 PRPSearcher 在 CityAVOS 任务中实现了 53.50% 的 SR 和 40.57% 的 SPL,显著超越了基线方法的性能。
本工作的贡献总结如下:
- 据我们所知,我们首次为城市空间中的 AVOS 任务引入了基准数据集,即 CityAVOS。
-
- 受人类三层次认知的启发,我们提出了一种基于 MLLM 的代理方法来解决 AVOS 任务。这是通过构建三种类型的地图——语义地图、认知地图和不确定性地图——来增强代理的空间感知、目标推理和动作规划能力实现的。
-
- 实验结果表明,我们的方法在应对 AVOS 任务时优于现有的基线方法。然而,与人类表现的差距突显了未来研究改进城市空间中实体目标搜索的语义推理和空间探索的机会。
2 相关工作
2.1 室内物体导航
随着Matterport3D [5]、HM3D [24]和Gibson [34]等模拟器和数据集的出现,室内导航和搜索研究取得了显著进展[7, 23, 29, 38]。早期端到端方法[11, 18]直接将观察映射到动作,但计算成本较高。为了缓解这一问题,Chaplot等人[6]提出了一种基于图的模块化方法,将其与学习方法相结合,减少了资源需求。针对零样本物体导航,Gadre等人[12]研究了CLIP on Wheels (CoW)框架和基准。最近,大型语言模型(LLMs)已被广泛应用于室内物体导航方法[3, 9, 39]。例如,L3MVN[40]使用LLMs进行常识推理以提高物体搜索效率,而ESC[46]则从预训练模型中转移知识以实现开放世界物体导航。VoroNav[32]展示了一种语义探索框架,其中LLM利用拓扑和语义数据确定导航航点。
然而,这些研究主要集中在室内场景,限制了它们在城市环境中的AVOS任务中的直接应用。然而,它们的语义映射和认知推理方法提供了有用的见解。这些方法启发我们开发模仿人类认知的户外探索技术,以提高代理的空间感知、目标推理和动作规划能力。
2.2 城市物体搜索
传统的城市物体搜索方法[16, 35]通常依赖于诸如元启发式[33]等优化算法生成搜索路径。一些其他方法结合了图神经网络[41]和深度强化学习[30]来解决这个问题。然而,这些方法往往缺乏有效处理或结合视觉物体信息的能力。最近在实体智能和大型语言模型(LLMs)方面的进展显著推动了城市物体搜索方法的发展。例如,Doschl等人[10]提出了Say-REAPEx,这是一个基于LLM的在线规划框架,用于从规划过程中修剪与目标无关的动作。为了增强LLM在城市背景下的可解释性,NEUSIS[4]整合了神经符号方法以辅助环境推理。这一进展得到了城市实体环境和数据集的快速演化的补充,如AerialVLN[19],它提供了一个近现实的3D模拟器,涵盖25个城市规模场景,以及用于实体智能评估的基准平台EmbodiedCity[13]。其他户外实体任务平台如OpenUAV[28]、CityNav[17]和AeroVerse[37]也促进了先进城市物体搜索方法的发展。
然而,专门针对城市环境的AVOS基准仍然明显缺失,以及相应的有效基线模型。因此,这项工作贡献了一个全面的AVOS任务基准数据集,以及一个用于城市环境中自主视觉搜索的有效MLLM代理基线。
图2:CityAVOS六类物体示例及数据集统计。
3 CityAVOS 数据集
在本节中,我们首先定义AVOS任务。然后,我们介绍用于开发CityAVOS数据集的模拟环境,并概述数据集收集和验证的过程。
3.1 任务定义
在AVOS任务i中,UAV代理需要探索一个陌生的城市环境,并搜索具有任务信息Gi的视觉物体。在每个步骤t中,代理感知其当前姿态Pt=[pos_t, ori_t]下的RGB图像Vt和深度图像Dt。通过观察Ot=(Vt, Dt, Pt),代理建立对视觉物体的估计Et。然后,采用搜索策略π(at | Gi, Et)生成动作at。代理根据观察决定是否成功搜索和定位目标。最后,当代理执行停止动作时,搜索任务结束。
3.2 数据集收集
我们在EmbodiedCity[13]基础上开发CityAVOS,这是一个基于Unreal Engine 5.3的平台,具备高保真度的城市街道、建筑物、树木、车辆和行人的模拟[44]。通过集成AirSim [26],该平台提供了一个真实的城市环境中评估自主UAV性能的环境。利用这个环境,我们定义了六个不同的搜索场景(例如,街道、社区、公园),面积从5,600到82,800平方米不等。为了将这些场景适应于AVOS任务,我们在场景中嵌入了特定的可识别物体。
数据集收集过程包括三个主要阶段,涉及人工操作员和自动化算法。第一阶段是原始轨迹生成,包括场景划定、目标选择和路径收集。第二阶段是任务补充,涉及分配代理的初始姿态并细化相应任务描述。最后,数据集经过验证和过滤以确保质量和一致性。更多细节见附录A.1。
3.3 数据集统计
为进一步探索提出的CityAVOS数据集,我们从三个方面展示其特性:
- 任务构建:CityAVOS中的每个任务构建为:G=(id, e, H, I, T, P_object, P_0),其中id表示AVOS任务的身份,e是物体存在的场景,H表示任务的难度,I表示物体的视觉信息(图像),T表示物体的文本信息,P_object是物体的位置,P_0是UAV代理的初始姿态(包括3D位置和方向)。
-
- 物体类别:CityAVOS数据集包含2,420个AVOS任务及其对应的轨迹,这些任务涉及以下六种类别的物体:建筑、车辆、商店、广告牌、标志和设施。这些类别的任务分布如图2右上角所示。
-
- 任务难度:数据集中的任务分为三个难度级别:简单、中等和困难。对于简单任务,代理需要在一个小规模场景中定位唯一物体。中等任务涉及代理在一个大规模场景中搜索唯一物体。困难任务要求代理在一个大规模场景中识别非唯一目标。有关难度分类的具体细节见附录A.1。图2右下角展示了相应难度级别的分布。
4 代理方法
4.1 概述
图3展示了所提出的PRPSearcher用于AVOS任务的概述,包括三个主要阶段:空间感知、目标推理和动作规划。(1)在感知阶段,UAV代理通过使用MLLM推理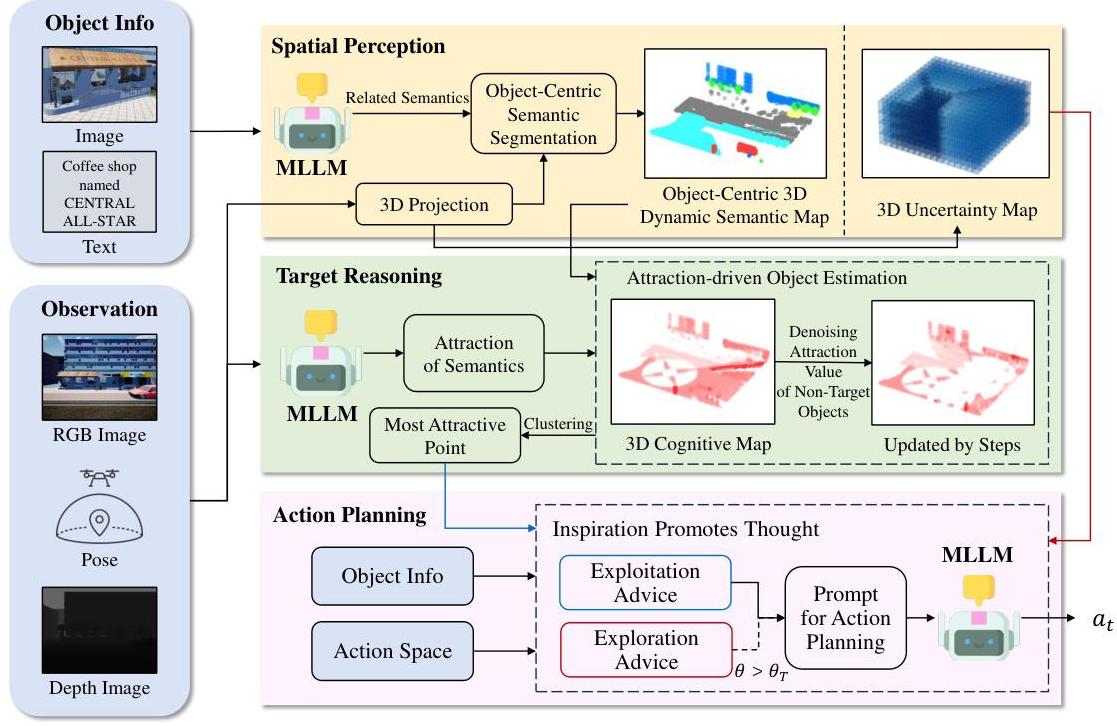
图3:代理方法-PRPSearcher的概述。
关于目标相关物体并提取相应语义,从而创建以物体为中心的3D动态语义地图。这实现了以物体为中心的语义分割并降低了语义映射的计算成本。此外,我们采用动态更新机制以提高语义网格内的映射精度。为了量化当前步骤中环境的探索程度,PRPSearcher还基于UAV的可见区域更新3D不确定性地图。(2)在推理阶段,UAV代理使用3D认知地图估计目标的位置。由MLLM创建的地图围绕“吸引力”概念展开。“吸引力”衡量一个物体的语义对UAV代理的吸引力程度,基于该物体对找到目标的有用性。通过在地图中聚类高吸引力网格,代理估计目标的可能位置以指导其搜索计划。为确保准确性,降噪机制减轻了与目标无关物体的影响。最后,(3)在规划阶段,我们引入了灵感促进思考提示机制以指导UAV代理的动作规划。此机制将目标位置估计输入提示作为“利用建议”,引导代理的搜索和目标识别。通过从3D不确定性地图中选择性添加“探索建议”以平衡“灵感”,鼓励探索未知区域的同时利用已知区域。
4.2 基于空间感知的以物体为中心的3D动态语义地图构建
为了表示城市环境中的语义分布,我们基于视觉观测和UAV姿态构建了一个以物体为中心的3D动态语义地图(3D-grid形式)。
以物体为中心的语义分割。对于每个任务i,我们使用MLLM基于
任务信息(包括图像I_i和文本描述T_i)推断目标相关物体并获取相关语义元素:
Esi=MLLM(Promptrel,Ii,Ti) E_{s}^{i}=\operatorname{MLLM}\left(\operatorname{Prompt}_{r e l}, I_{i}, T_{i}\right) Esi=MLLM(Promptrel,Ii,Ti)
其中Promptrel\operatorname{Prompt}_{r e l}Promptrel是输入给MLLM以生成E_s的提示。提示的详细信息可以在附录A.2中找到。这些元素被集成到分割提示中,目的是消除与目标物体无关的语义。语义分割过程定义如下:
Ss=Segment(Esi,V) S_{s}=\operatorname{Segment}\left(E_{s}^{i}, V\right) Ss=Segment(Esi,V)
其中V是从观察中获取的RGB图像,S_s表示语义分割的结果,包括每个语义元素的掩码、框和标签。Segment()代表Ground-SAM模型[2]的语义分割过程。
3D动态语义地图。假设相机内参矩阵为K \in \mathbb{R}^{3 \times 3},外参矩阵为[R \mid r] \in \mathbb{R}^{3 \times 4},其中R为旋转矩阵,r为平移向量。对于深度图像D中的每个像素(u, v),其世界坐标(X, Y, Z)可以通过以下公式计算:
[XYZ]=R−1(K−1[u⋅D(u,v)v⋅D(u,v)D(u,v)]−r) \left[\begin{array}{l} X \\ Y \\ Z \end{array}\right]=R^{-1}\left(K^{-1}\left[\begin{array}{c} u \cdot D(u, v) \\ v \cdot D(u, v) \\ D(u, v) \end{array}\right]-r\right) XYZ =R−1 K−1 u⋅D(u,v)v⋅D(u,v)D(u,v) −r
将世界空间划分为规则网格,每个网格大小为\Delta x \times \Delta y \times \Delta z。对于每个像素(u, v),其世界坐标(X, Y, Z)对应于网格索引(i, j, k):
i=⌊X−xminΔx⌋,j=⌊Y−yminΔy⌋,k=⌊Z−zminΔz⌋ i=\left\lfloor\frac{X-x_{\min }}{\Delta x}\right\rfloor, \quad j=\left\lfloor\frac{Y-y_{\min }}{\Delta y}\right\rfloor, \quad k=\left\lfloor\frac{Z-z_{\min }}{\Delta z}\right\rfloor i=⌊ΔxX−xmin⌋,j=⌊ΔyY−ymin⌋,k=⌊ΔzZ−zmin⌋
其中\left[x_{\min }, x_{\max }\right] \times\left[y_{\min }, y_{\max }\right] \times\left[z_{\min }, z_{\max }\right]是场景空间的边界。
对于每个网格(i, j, k),我们统计它包含的所有像素的语义标签,并选择出现频率最高的语义标签作为该网格的语义表示:
Si,j,k=argmaxc∈En∑(u,v)∈ pixels in (i,j,k)I(L(u,v)=c) S_{i, j, k}=\arg \max _{c \in E_{n}} \sum_{(u, v) \in \text { pixels in }(i, j, k)} \mathbb{I}(L(u, v)=c) Si,j,k=argc∈Enmax(u,v)∈ pixels in (i,j,k)∑I(L(u,v)=c)
其中\mathbb{I}(\cdot)是指示函数,L(u, v)是存储在语义分割结果S_u中的像素(u, v)的语义,c是语义类别。
4.3 基于吸引力的目标估计
基于3D动态语义地图,我们通过构建3D认知地图来表示代理对目标位置的估计。此外,应用去噪机制以消除非目标物体在搜索过程中的干扰。
3D认知地图。3D认知地图C是一个与语义地图S大小相等的3D网格地图。我们使用MLLM来衡量物体的语义对UAV代理的吸引力强度。对于每个语义类别c,吸引力值计算如下:
A(s)=MLLM(Promptatt ,Ii,Ti) A(s)=\operatorname{MLLM}\left(\operatorname{Prompt}_{\text {att }}, I_{i}, T_{i}\right) A(s)=MLLM(Promptatt ,Ii,Ti)
通过计算语义地图中每个网格(i, j, k)的吸引力值A(S_{i, j, k}),我们可以将这些值分配给认知地图中相应的网格:
Ci,j,k=A(Si,j,k) C_{i, j, k}=A\left(S_{i, j, k}\right) Ci,j,k=A(Si,j,k)
去噪机制。创建一个镜像认知地图C’以跟踪每个网格是否已被UAV代理识别。C’中每个网格的状态表示如下:
- C’(i, j, k)=1。网格(i, j, k)尚未被识别。
-
- C’(i, j, k)=0。网格(i, j, k)已被识别。
当UAV代理执行观察动作时,它利用当前位置和视角来确定认知地图中哪些网格单元是可见的。对于每个可见网格(i, j, k),如果它在由代理步长定义的距离范围内,则在镜像认知地图C’中将其更新为已识别:C’(i, j, k)=0。
- C’(i, j, k)=0。网格(i, j, k)已被识别。
为了通过滤除已识别区域的噪声来提高认知地图的质量,我们应用了镜像认知地图的去噪过程,公式如下:
Ci,j,k=Ci,j,k⋅C′(i,j,k) C_{i, j, k}=C_{i, j, k} \cdot C^{\prime}(i, j, k) Ci,j,k=Ci,j,k⋅C′(i,j,k)
4.4 E-E 平衡动作规划
为了以更高的效率和成功率找到目标,我们需要在动作规划中实现探索-利用平衡。
3D 不确定性地图。3D不确定性地图也是一个三维网格地图,其中每个单元格(i, j, k)与一个不确定性值U_{i, j, k} \in[0,1]相关联。搜索开始时,所有单元格的不确定性值均为1,表示完全不确定。
UAV代理在位置p=(X, Y, Z)和方向o=(o_x, o_y, o_z)处执行观察。基于当前位置和方向,计算可见网格单元集合V。对于每个可见单元格(i, j, k) \in V,根据距离减弱其不确定性U_{i, j, k}。不同面的单元格不确定性独立计算。减弱函数f(d)定义如下:
f(d)=e−α⋅d f(d)=e^{-\alpha \cdot d} f(d)=e−α⋅d
其中d=\sqrt{(X-x_i)2+(Y-y_j)2+(Z-z_k)^2}是从网格单元(i, j, k)到代理位置p的欧几里得距离,\alpha是减弱系数,控制不确定性随距离减小的速度。因此,更新后的不确定性为:
Ui,j,knew =Ui,j,kold ⋅f(d) U_{i, j, k}^{\text {new }}=U_{i, j, k}^{\text {old }} \cdot f(d) Ui,j,knew =Ui,j,kold ⋅f(d)
每次代理执行观察时,重复上述过程,并按以下方式更新3D不确定性地图:
Ui,j,knew ={Ui,j,kold ⋅f(d) if (i,j,k)∈VUi,j,kold otherwise U_{i, j, k}^{\text {new }}=\left\{\begin{array}{ll} U_{i, j, k}^{\text {old }} \cdot f(d) & \text { if }(i, j, k) \in \mathcal{V} \\ U_{i, j, k}^{\text {old }} & \text { otherwise } \end{array}\right. Ui,j,knew ={Ui,j,kold ⋅f(d)Ui,j,kold if (i,j,k)∈V otherwise
探索建议。鉴于广阔的城市空间,UAV代理需要探索更多未知区域以获取与目标相关的信息。为了用3D不确定性地图建模探索过程,我们定义了一个奖励函数,该函数量化了代理动作空间中每个潜在动作所能实现的不确定性减少总量。动作的奖励是3D不确定性地图中所有网格单元的总不确定性减少量。
动作a的奖励\operatorname{Reward}(a)定义如下。设\mathcal{A}是代理可用的所有可能动作的集合。对于每个动作a \in \mathcal{A},代理预测执行该动作后的新位置\mathbf{p}{a}和方向\mathbf{o}{a}。基于\mathbf{p}{a}和\mathbf{o}{a},计算可见网格单元集合\mathcal{V}_{a}。然后,\operatorname{Reward}(a)计算如下:
Reward(a)=∑(i,j,k)∈Va(Ui,j,kold −Ui,j,knew ) \operatorname{Reward}(a)=\sum_{(i, j, k) \in \mathcal{V}_{a}}\left(U_{i, j, k}^{\text {old }}-U_{i, j, k}^{\text {new }}\right) Reward(a)=(i,j,k)∈Va∑(Ui,j,kold −Ui,j,knew )
其中U_{i, j, k}^{\text {new }}是执行动作a后网格单元(i, j, k)的更新不确定性,由公式10计算得出。
最大化奖励的动作可以表述为:
aexploration ∗=argmaxa∈AReward(a) a_{\text {exploration }}^{*}=\arg \max _{a \in \mathcal{A}} \operatorname{Reward}(a) aexploration ∗=arga∈AmaxReward(a)
其中a_{\text {exploration }}^{*}是代理的探索建议。
利用建议。3D认知地图反映了这些语义元素对搜索对象的“吸引力”。吸引力值最高的区域是最有可能的目标物体位置。设\mathcal{G}为高相关网格的集合,定义为:
G={(i,j,k)∣Ci,j,k=max(Ci,j,k)} \mathcal{G}=\left\{(i, j, k) \mid C_{i, j, k}=\max \left(C_{i, j, k}\right)\right\} G={(i,j,k)∣Ci,j,k=max(Ci,j,k)}
通过使用DBSCAN聚类方法[25],可以识别出几个集群\mathcal{C}{1}, \mathcal{C}{2}, \ldots, \mathcal{C}{n}作为高相关区域。对于最大的集群\mathcal{C}{m},计算中心点\mathbf{p}{m}=\left(X{m}, Y_{m}, Z_{m}\right)作为利用过程的目标点。导航到点\mathbf{p}{m}的动作a{\text {exploitation }}^{*}是为UAV代理生成的利用建议。
基于IPT的E-E平衡规划。在搜索任务中,探索涉及在不熟悉的环境中搜索以收集新信息,而利用依赖于现有知识来估计目标物体的位置。在这两种模式之间取得最佳平衡是一项关键挑战,因为通常很难确定代理应基于探索还是利用建议行动。当人类搜索物体时,他们通常先考虑目标最可能的位置,然后彻底调查这些区域。在此过程中,经常会自发地产生“还有一个地方我没检查过”的想法——这种灵感有助于避免遗漏潜在位置。这种行为反映了人类认知中探索和利用之间的自然平衡。受此见解的启发,我们通过提出IPT提示机制复制了这一认知过程,该机制刺激UAV代理的“灵感”思维,以实现平衡的探索-利用(E&E)策略。提示的例子见附录A.2。
该机制将利用建议作为长期指导整合到代理的动作规划提示中。这些建议将持续引导代理寻找和识别已知物体。相反,探索建议将以“灵感”的形式选择性地纳入提示中。在搜索过程中有几种情况,代理应优先采取探索策略:初始搜索阶段或搜索陷入局部最优时。为此,我们引入阈值\theta来评估探索动作的好处是否足够显著。当好处超过该阈值时,探索建议将被添加到规划提示中,提醒代理将其重点转向探索未知空间。
\operatorname{Prompt}{\text {plan }}=\operatorname{Advice}{\text {exploit }}+I\left(\operatorname{Reward}\left(a^{}\right)>\theta\right) \cdot \operatorname{Advice}_{\text {explore }}
其中I()是布尔函数,当\operatorname{Reward}\left(a{*}\right)>\theta为真时,I\left(\operatorname{Reward}\left(a{}\right)>\theta\right)=1,否则I\left(\operatorname{Reward}\left(a^{*}\right)>\theta\right)=0。
参数\theta相关的数值实验可以在第5.3节找到。
5 实验
5.1 实验设置
评估指标。我们采用了四个标准指标来衡量性能,即成功率(SR)、路径长度加权成功率(SPL)[32]、平均搜索步骤(MSS)[43]和导航误差(NE)[19, 23]。这四个指标的详细信息可以在附录A.3.1中找到。SR计算代理在预定义成功阈值(20米)内终止并成功识别目标的事件百分比。SPL衡量导航效率为实际路径长度与最优路径长度的逆比,权重为成功率。路径长度计算为连续动作间的累积距离。MSS常用于物体搜索任务,表示代理在每个事件中采取的平均动作数。NE衡量代理最终位置与目标物体真实位置之间的欧几里得距离。
实施细节。对于PRPSearcher,输入图像被调整为640 * 480以方便处理,并使用了一些常用的MLLMs(如GPT-4o和Qwen-vl-max)在空间感知、目标推理和动作规划阶段进行视觉分析和推理。实验使用的数据集是CityAVOS,平台是修改过的EmbodiedCity用于AVOS。由于API限制,从CityAVOS数据集中随机选择了605个任务(25%)进行广泛的实验。
基线。我们的基线比较使用了过去两年中的物体搜索研究,涵盖了室内外研究。此外,考虑到AVOS任务的新兴性质,我们补充了基础方法以确保全面的性能评估。
- 随机探索(RE):代理随机选择一个动作执行,直到选择“停止”动作。
-
- 边界探索(FBE):一种纯粹的边界探索方法,忽略语义信息[23]。
-
- L3MVN:L3MVN [40]记录边界图边界上的语义信息,并利用LLMs确定优先进行物体搜索的边界。
-
- WMNav:WMNav [21]构建好奇心值图以预测目标出现的可能性。选择最高值的方向并发送到导航策略模块。
-
- STMR:STMR [15]将地标相关的语义掩码提取到俯视图中以进行动作预测。
-
- 人类代理:UAV的动作由一个人类参与者根据从UAV获得的实时观察结果确定。五名具有无人机操作经验的研究生参与了实验,但他们都不熟悉城市环境。结果反映了参与者的平均表现。
- 为了将基线室内物体搜索方法适应于城市户外环境,我们对这些方法进行了一些调整,包括但不限于输入匹配和将2D结构转换为3D结构。对于户外研究,SayREAPEx [10]和NEUSS [4]代表了与物体搜索相关的最新研究。然而,由于这些方法目前未开源且关键组件难以复制,我们已将它们排除在基线之外。此外,对于如OpenUAV [28]和OpenFly [14]等基准,它们提出的方法基于自己的训练模型,不适用于AVOS任务。因此,这些方法也被排除在基线之外。
更多关于实验实施和结果的细节可以在附录A.3中找到。
5.2 与最先进的方法比较
如表2所示,我们提出的方法在所有难度的任务中显著优于基线方法(平均:+37.69% SR,+28.96% SPL,-30.69% MSS,和-46.40% NE),证明了所设计机制和构建地图的有效性。然而,与人类表现的差距表明,现有MLLMs的推理能力和本工作中设计的其他机制仍不足以与人类操作员匹敌。可以得到一些观察结果:
- 基本方法。随机探索方法和基于边界的探索方法在各种难度的任务中表现不佳。由于这两种方法都是盲目空间探索
- 表2:CityAVOS基准上与最先进的基线性能比较。
| 方法 | 简单任务 | | | | 中等任务 | | | | 困难任务 | | | | 总任务 | | | |
| :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: |
| | SR ↑ | MSS ↓ | SPL ↑ | NE ↓ | SR ↑ | MSS ↓ | SPL ↑ | NE ↓ | SR ↑ | MSS ↓ | SPL ↑ | NE ↓ | SR ↑ | MSS ↓ | SPL ↑ | NE ↓ |
| 人类 | 85.45 | 17.40 | 76.58 | 20.74 | 72.16 | 17.76 | 68.31 | 56.50 | 67.68 | 15.94 | 56.71 | 31.43 | 78.68 | 17.26 | 70.92 | 32.90 |
| RE | 10.30 | 49.35 | 6.90 | 89.00 | 3.98 | 62.07 | 1.82 | 198.23 | 7.07 | 97.75 | 3.69 | 133.96 | 7.93 | 60.97 | 4.90 | 131.41 |
| FBE | 13.64 | 39.47 | 10.04 | 97.48 | 9.66 | 58.85 | 7.67 | 194.71 | 5.05 | 60.93 | 3.81 | 198.38 | 11.07 | 48.62 | 8.33 | 142.33 |
| L3MVN | 26.82 | 34.51 | 21.54 | 87.89 | 7.09 |60.02 | 4.06 | 190.34 | 7.21 | 59.68 | 3.94 | 180.84 | 17.87 | 46.05 | 13.57 | 132.90 | 0.62 | 38.54 | 18.05 | 75.06 | 5.42 | 69.86 | 3.19 | 164.69 | 12.17 | 77.35 | 8.72 | 110.79 | 14.82| 54.02 | 12.20 | 106.99 |
| STMR | 32.68 | 34.25 | 23.86 | 66.07 | 21.52 | 55.68 | 13.9 | 138.66 | 19.91 | 60.19 | 11.96 | 89.41 | 27.35 | 44.70 | 19.03 | 91.33 |
| PRPSearcher无利用 | 16.36 | 38.87 | 13.25 | 95.25 | 3.41 | 59.61 | 2.11 | 165.28 | 3.03 | 61.66 | 2.38 | 101.06 | 10.41 | 48.63 | 8.23 | 116.57 |
| PRPSearcher无探索 | 60.47 | 30.22 | 47.89 | 50.19 | 39.68 | 45.86 | 35.09 | 129.47 | 28.52 | 46.08 | 16.68 | 92.36 | 49.19 | 37.37 | 39.06 | 80.16 |
| PRPSearcher | 66.32 | 28.85 | 49.82 | 43.62 | 42.89 | 41.33 | 36.68 | 98.35 | 29.62 | 45.84 | 16.65 | 76.13 | 53.50 | 35.26 | 40.57 | 64.86 |
方法。由于这些方法是盲空间探索方法,它们的表现反映了AVOS任务不能通过基本的空间探索模式解决。
- 室内方法。尽管室内方法的成功率不高,但与基本方法相比有显著改进。L3MVN方法在简单难度任务集上比基本方法提高了成功率为13.18%13.18 \%13.18%。WMNav方法通过好奇心机制在困难任务中表现出良好的性能。这些结果不仅突出了语义理解对AVOS任务的重要性,也反映了室内方法在城市环境中的局限性。
-
- 室外方法。STMR方法在基线中表现最佳,除了人类代理。STMR通过在空中构建俯视图来促进户外语义信息的存储。同时,它增强了基于推理链的代理动作规划能力。因此,在中等和困难任务中的成功率分别可达21.52%21.52 \%21.52%和19.91%19.91 \%19.91%。这一结果反映了代理推理能力在高难度任务中的重要性。
-
- 人类代理。人类代理在所有任务分类中表现最佳,这得益于人类天生强大的视觉理解和顺序动作决策能力。随着任务难度的增加,人类代理的表现略有下降,这表明人类成功完成AVOS任务也面临一定挑战。提出的PRPSearcher在成功率方面达到了人类水平的68%68 \%68%,这说明了该方法的先进性,同时也暗示了在AVOS任务上进一步提高性能的潜力。
总体而言,与基线模型的比较显示,在语义提取过程中排除冗余物体信息的干扰并有效区分类似目标物体对于提高搜索效率至关重要。此外,在AVOS任务中实现较高的成功率取决于在探索和利用之间找到最佳平衡。
- 人类代理。人类代理在所有任务分类中表现最佳,这得益于人类天生强大的视觉理解和顺序动作决策能力。随着任务难度的增加,人类代理的表现略有下降,这表明人类成功完成AVOS任务也面临一定挑战。提出的PRPSearcher在成功率方面达到了人类水平的68%68 \%68%,这说明了该方法的先进性,同时也暗示了在AVOS任务上进一步提高性能的潜力。
5.3 消融研究
以物体为中心的3D动态语义地图的效果。为了展示本文提出的以物体为中心的3D动态语义地图对代理空间感知的贡献,我们进行了消融实验,并设计了两种其他语义分割提示:自由提示和人工设计。
表3:PRPSearcher的以物体为中心的3D动态语义地图的消融研究。
| 方法 | 总体 | ||||
|---|---|---|---|---|---|
| SR ↑ | MSS ↓ | SPL ↑ | NE ↓ | ||
| 自由提示 | 50.52 | 37.89 | 38.11 | 84.03 | |
| 人工设计 | 38.46 | 41.41 | 30.27 | 105.68 | |
| 以物体为中心 | 53.50\mathbf{5 3 . 5 0}53.50 | 35.20\mathbf{3 5 . 2 0}35.20 | 40.57\mathbf{4 0 . 5 7}40.57 | 64.86\mathbf{6 4 . 8 6}64.86 |
前者不对语义分割模型提供提示,允许模型自行确定分割目标。后者涉及人工主动设置提示,而不针对不同任务进行进一步调整。表3中的实验结果显示,人工设计的语义分割提示取得了最差的实验结果,自由提示的表现略低于我们的方法。在设计语义分割提示时,我们使用数据集的目标分类标签作为语义分割模型的输入。这导致语义地图中的语义过于丰富,某种程度上干扰了代理的判断。同样,当使用语义分割模型进行自主分割时,也会引入大量非目标物体的语义,降低了搜索效率和成功率。
探索和利用设计的影响。本文提出的方法通过向代理提供探索建议和利用建议来实现动作规划中的平衡。具体来说,探索建议来源于3D不确定性地图,而利用建议则来自3D认知地图。因此,这次消融实验旨在验证这两种地图设计的贡献。实验结果如表2所示。即使没有探索建议,PRPSearcher w/o exploration方法仍然保持较高性能,但SR和SPL都有所下降。相反,PRPSearcher w/o exploitation方法表现较差,但仍优于FBE方法。这进一步证明了语义理解对AVOS(自主视觉物体搜索)任务的重要性。同时,上述实验结果确认了本文提出方法的有效性。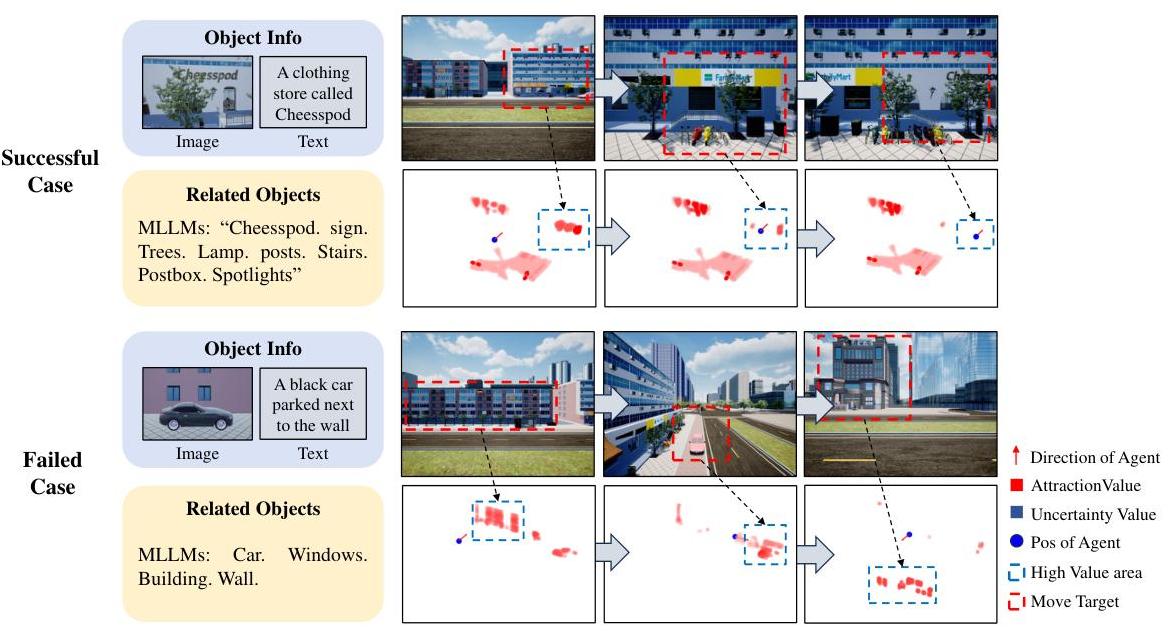
图4:PRPSearcher在两个情节中的两个选定案例。一个是成功的案例,展示了我们的方法如何有效地找到并识别目标,相较于基线模型的优势。另一个是失败的案例,突显了我们的方法在视觉推理能力上的局限性,与人类代理相比。
表4:PRPSearcher的IPT提示机制的消融研究。
| θT\theta_{T}θT | SR | MSS | SPL | NE | NθN_{\theta}Nθ |
|---|---|---|---|---|---|
| 1 | 49.19 | 37.37 | 39.06 | 80.16 | 0 |
| 0.5 | 49.38 | 38.44 | 38.83 | 78.62 | 0 |
| 0.2 | 51.38 | 35.3 | 39.89 | 67.78 | 4.37 |
| 0.1 | 53.5 | 35.26 | 40.57 | 64.86 | 8.62 |
| 0.05 | 43.99 | 41.71 | 32.48 | 89.47 | 26.09 |
| 0.02 | 38.2 | 44.59 | 30.05 | 97.58 | 44.59 |
| 0 | 38.37 | 44.82 | 29.9 | 95.11 | 44.82 |
IPT提示机制的影响。IPT提示机制旨在平衡代理的动作规划中的探索和利用。此机制中的一个关键参数,记为θT\theta_{T}θT,控制提供给代理的探索建议频率。我们进行了数值实验以评估不同θT\theta_{T}θT值的影响,结果总结在表4中。当θT=0.5\theta_{T}=0.5θT=0.5或θT=1\theta_{T}=1θT=1时,代理收到的探索提示数量降至零(Nθ=0)\left(N_{\theta}=0\right)(Nθ=0),由于缺乏探索指导,性能下降。相反,当θT=0\theta_{T}=0θT=0时,代理在每个决策步骤都会收到探索建议,这压倒了其决策过程,显著降低了成功率(SR)。通过这些实验,我们确定θT=0.1\theta_{T}=0.1θT=0.1为最佳设置,有效使代理在动作规划中实现探索和利用之间的平衡。
不同MLLMs的影响。由于PRPSearcher是一种基于MLLM的代理方法,我们进一步评估了不同MLLMs在AVOS任务中的能力,如表5所示。实验结果显示,PRPSearcher在不同的MLLMs(多模态语言模型)负载下表现出良好的搜索性能。在三个MLLMs中,glm-4v-plus的成功率(SR)和路径长度成功率(SPL)最差,但在导航效率(NE)方面表现最佳。通过分析搜索过程,我们发现GPT-4-o引导的搜索者可以在一定距离成功识别目标物体,而glm-4v-plus需要代理靠近目标物体才能成功识别,这降低了NE。
表5:PRPSearcher的MLLMs消融研究。
| 方法 | 总体 | |||
|---|---|---|---|---|
| SR ↑ | MSS ↓ | SPL ↑ | NE ↓ | |
| Qwen-vl-max | 51.68 | 36.07 | 40.09 | 63.62 |
| glm-4v-plus | 48.32 | 38.04 | 39.56 | 61.68\mathbf{6 1 . 6 8}61.68 |
| GPT4-o | 53.50\mathbf{5 3 . 5 0}53.50 | 35.20\mathbf{3 5 . 2 0}35.20 | 40.57\mathbf{4 0 . 5 7}40.57 | 64.86 |
5.4 案例研究
如图4所示,我们展示了一个成功的案例和一个失败的案例。在成功的案例中,基于MLLM的代理根据目标信息进行推理以识别相关物体,然后用于构建语义地图和认知地图以进行搜索。最初,代理基于探索建议观察周围环境。随后,它识别场景中存在的
树木和标志,赋予它们吸引力值(分别为0.95和0.9)。在3D认知地图的利用建议指导下,代理搜索了一排带有树木的商店。得益于去噪机制,代理能够沿着这排商店进行搜索,并最终找到目标。在这个案例中,去噪机制确保代理保持专注,忽略相似的商店并成功找到目标。关键在于,将场景中的树木与目标关联起来提高了效率,通过引导搜索到正确区域。
在一个典型的失败案例中,目标是“停靠在墙边的一辆黑色汽车”。由于目标图像中的视觉信息稀疏,对此图像的推理仅得出少数语义线索:“汽车、窗户、建筑、墙壁。” 因此,PRPSearcher最初提示UAV代理朝环境中的建筑物移动。在验证遇到的车辆不正确后,UAV代理遵循探索建议探索空间,随后发现了更多建筑物。然而,最终由于搜索超出了步数限制,搜索未能成功。值得注意的是,在所有评估的基线方法中,只有人类代理和FBE方法定位到了目标。这个案例强调了PRPSearcher在空间探索效率方面的局限性,并突显了其相对于人类能力的空间语义推理差距。
6 结论
在这项研究中,我们介绍了一种相对未被探索的无人机复杂城市环境中自主视觉目标搜索(AVOS)任务。我们形式化了AVOS任务并引入了CityAVOS,这是首个专门的基准数据集,包含多样化的城市物体和场景,便于标准化评估。为了解决这个任务,我们提出了一个新的代理方法,即PRPSearcher,它开创了一个三层认知架构,模仿人类的感知、推理和规划,通过专门的语义、认知和不确定性地图实现。此外,我们引入了一个IPT提示机制,以指导无人机代理在动作规划过程中平衡探索和利用。实验结果表明,PRPSearcher在搜索效率和成功率方面明显优于现有方法。这项工作代表了在复杂城市空间中实现实体无人机目标搜索能力的重要一步。未来,我们将尝试通过结合人机协作或多代理策略进一步改进PRPSearcher,以处理更复杂的AVOS任务(例如长视野多目标搜索)。
参考文献
[1] Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünderhauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. 2018. 视觉与语言导航:在真实环境中解释可视基础导航指令。IEEE计算机视觉与模式识别会议论文集。3674-3683。
[2] Walid Bousselham, Felix Petersen, Vittorio Ferrari, and Hilde Kuehne. 2024. 地面一切:视觉语言变压器中出现的定位属性。IEEE/CVF计算机视觉与模式识别会议论文集。3828-3837。
[3] Wenzhe Cai, Siyuan Huang, Guangran Cheng, Yuxing Long, Peng Gao, Changyin Sun, and Hao Dong. 2024. 像素引导导航技能:通过像素引导导航技能连接零样本物体导航和基础模型。2024 IEEE国际机器人与自动化会议(ICRA)论文集。IEEE, 5228-5234。
[4] Zhixi Cai, Cristian Rojas Cardenas, Kevin Leo, Chenyuan Zhang, Kal Backman, Hanbing Li, Boying Li, Mahsia Ghorbanali, Stavya Datta, Lizhen Qu, et al. 2024.
NEUSIS:一种用于复杂无人机搜索任务的组合神经符号框架。arXiv预印本arXiv:2409.10196 (2024)。
[5] Angel Chang, Angela Dai, Thomas Fankhouser, Maciej Halter, Matthias Niesaner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. 2017. Matterport3d:从RGB-D数据学习室内环境。arXiv预印本arXiv:1709.06158 (2017)。
[6] Devendra Singh Chaplot, Dhiraj Prakashchand Gandhi, Abhinav Gupta, and Russ R Salakhutdinov. 2020. 使用目标导向的语义探索进行物体目标导航。神经信息处理系统进展33 (2020),42474258。
[7] Shizhe Chen, Thomas Chabal, Ivan Laptev, and Cordelia Schmid. 2023. 使用递归隐式地图进行物体目标导航。2023 IEEE/EST国际智能机器人与系统会议(IROS)论文集。IEEE, 7089-7096。
[8] Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Kiana Bhsani, Jordi Salvador, Winson Han, Eric Kolve, Aniruddha Kenbhavi, and Roozbeh Mottaghi. 2022. ProcTHOB:使用程序生成的大规模实体AI。神经信息处理系统进展35 (2022),5982-5994。
[9] Vishnu Sashank Deebala, James P Mullen, and Dinesh Manocha. 2023. 实体代理能否找到你的“猫形马克杯”?基于LLM的零样本物体导航。IEEE机器人与自动化快报9, 5 (2023), 4083-4090。
[10] Björn Döschl 和 Jane Jean Kiam. 2024. Say-REAPEx:一种用于搜救的LLM模块无人机在线规划框架。第二届CoRL学习有效抽象规划研讨会论文集。
[11] Heming Du, Lincheng Li, Zi Huang, and Xin Yu. 2023. 通过有效探索历史导航状态间的关系进行目标物体视觉导航。IEEE/CVF计算机视觉与模式识别会议论文集。2563-2573。
[12] Samir Yitzhak Gadre, Mitchell Wortsman, Gabriel Dharo, Ludwig Schmidt, and Shuran Song. 2023. 牧场上的奶牛:语言驱动零样本物体导航的基线与基准测试。IEEE/CVF计算机视觉与模式识别会议论文集。23171-23181。
[13] Chen Gao, Baining Zhao, Weichen Zhang, Jinzhu Mao, Jun Zhang, Zhiheng Zheng, Fanhang Man, Jianjie Fang, Zile Zhou, Jinqiang Cui, et al. 2024. EmbodiedCity:一个用于真实城市环境中实体代理的基准平台。arXiv预印本arXiv:2410.09604 (2024)。
[14] Yunpeng Gao, Chenhui Li, Zhongrui You, Junli Liu, Zhen Li, Pengan Chen, Qishi Chen, Zhonghan Tang, Liansheng Wang, Penghui Yang, et al. 2025. OpenFly:一个多功能工具链和大规模基准,用于空中视觉语言导航。arXiv预印本arXiv:2502.18041 (2025)。
[15] Yunpeng Gao, Zhigang Wang, Linglin Jing, Dong Wang, Xuelong Li, and Bin Zhao. 2024. 基于语义-拓扑-度量表示引导的LLM推理进行空中视觉与语言导航。arXiv预印本arXiv:2410.08500 (2024)。
[16] Yukai Hou, Jin Zhao, Rongqing Zhang, Xiang Cheng, and Liuqing Yang. 2023. 基于多智能体强化学习的无人机群合作目标搜索。IEEE智能交通系统汇刊9, 1 (2023), 568-578。
[17] Jungdae Lee, Taiki Miyanishi, Shubei Kurita, Koya Sakamoto, Daichi Azuma, Yutaka Matsuo, and Nakamasa Inoue. 2024. CityNav:带地理信息的语言目标空中导航数据集。arXiv预印本arXiv:2406.14240 (2024)。
[18] Dongfang Liu, Yiming Cui, Zhiwen Cao, and Yingjie Chen. 2020. 移动代理的室内导航:一种多模态视觉融合模型。2020国际神经网络联合会议(IJCNN)论文集。IEEE, 1-8。
[19] Shubo Liu, Hongsheng Zhang, Yuankui Qi, Peng Wang, Yanning Zhang, and Qi Wu. 2023. AerialVLO:无人机的视觉与语言导航。IEEE/CVF国际计算机视觉会议论文集。15384-15394。
[20] Yang Liu, Weixing Chen, Yongjie Bai, Xiaodan Liang, Guanbin Li, Wen Gao, and Liang Lin. 2024. 对齐网络空间与物理世界:实体AI的综合调查。arXiv预印本arXiv:2407.06886 (2024)。
[21] Dujun Nie, Xianda Guo, Yujun Duan, Ruijun Zhang, and Long Chen. 2025. WMNav:将视觉语言模型集成到世界模型中进行物体目标导航。arXiv预印本arXiv:2503.02247 (2025)。
[22] Yuankui Qi, Qi Wu, Peter Anderson, Xin Wang, William Yang Wang, Chunhua Shen, and Anton van den Hengel. 2020. Reverie:真实室内环境中的远程实体视觉指代表达。IEEE/CVF计算机视觉与模式识别会议论文集。9982-9991。
[23] Santhosh Kumar Ramakrishnan, Devendra Singh Chaplot, Ziad Al-Halah, Jitendra Malik, and Kristen Grauman. 2022. Poni:无交互学习的物体目标导航潜在函数。IEEE/CVF计算机视觉与模式识别会议论文集。18890-18900。
[24] Santhosh K Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alex Clegg, John Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, et al. 2021. Habitat-Matterport 3D数据集(HM3D):1000个大规模3D环境用于实体AI。arXiv预印本arXiv:2109.08238 (2021)。
[25] Erich Schubert, Jörg Sander, Martin Ester, Hans Peter Kriegel, and Xiaowei Xu. 2017. DBSCAN重访,再重访:为什么以及如何您应该(仍然)使用DBSCAN。ACM数据库系统事务(TODS) 42, 3 (2017), 1-21。
[26] Shital Shah, Debadeepta Dey, Chris Lovett, and Ashish Kapoor. 2018. Airsim:高保真视觉和物理模拟用于自动驾驶车辆。现场和服务机器人:第11届国际会议结果。Springer, 621-635。
[27] Ruifeng She and Yanfeng Ouyang. 2021. 在低空拥堵空气条件下基于无人机的最后一英里配送效率。交通运输研究部分C:新兴技术122 (2021), 102878。
[28] Xiangyu Wang, Donglin Yang, Zajin Wang, Hohin Kwan, Jinyu Chen, Wenjun Wu, Hongsheng Li, Yue Liao, and Si Liu. 2024. 朝向真实的无人机视觉语言导航:平台、基准和方法学。arXiv预印本arXiv:2410.07087 (2024)。
[29] Erik Wijmans, Abhishek Kadian, Ari Morcos, Stefan Lee, Irfan Essa, Devi Parikh, Manolis Savva, and Dhruv Batra. 2019. DD-PPO:从25亿帧中学习近乎完美的点目标导航器。arXiv预印本arXiv:1911.00357 (2019)。
[30] Chunxue Wu, Bobo Ju, Yan Wu, Xiao Lin, Nuisue Xiong, Guangquan Xu, Hongyan Li, and Xuefeng Liang. 2019. 基于深度强化学习的复杂灾难场景下的无人机自主目标搜索。IEEE Access 7 (2019), 117227-117245。
[31] Jie Wu, Tianshui Chen, Lishan Huang, Hefeng Wu, Guanbin Li, Ling Tian, and Liang Lin. 2020. 主动物体搜索。第28届ACM国际多媒体会议论文集。973-981。
[32] Pengying Wu, Yao Mu, Bingxian Wu, Yi Hou, Ji Ma, Shanghang Zhang, and Chang Liu. 2024. Voronav:基于大型语言模型的零样本物体导航的Voronoi方法。arXiv预印本arXiv:2401.02695 (2024)。
[33] Yan Wu, Mingtao Nie, Xiaolei Ma, Yicong Guo, and Xiaoxiong Liu. 2023. 基于协同进化算法的多无人机合作路径规划。无人机7, 10 (2023), 606。
[34] Fei Xia, Amir R Zamir, Zhiyang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. 2018. Gibson Env:实体代理的真实世界感知。IEEE计算机视觉与模式识别会议论文集。9068-9079。
[35] Linjie Xing, Xiaoyan Fan, Yaxin Dong, Zenghui Xiong, Lin Xing, Yang Yang, Haicheng Bai, and Chengjiang Zhou. 2022. 基于YOLOv5的多无人机搜救合作系统。国际灾害风险降低杂志76 (2022), 102972。
[36] Karmesh Yadav, Ram Ramrakhya, Santhosh Kumar Ramakrishnan, Theo Gervet, John Turner, Aaron Gokaslan, Noah Maestre, Angel Xuan Chung, Dhruv Batra, Manolis Savva, et al. 2023. Habitat-Matterport 3D语义数据集。IEEE/CVF计算机视觉与模式识别会议论文集。4927-4936。
[37] Fanglong Yao, Yuanchang Yue, Youzhi Liu, Xian Sun, and Kun Fu. 2024. AeroVerse:用于模拟、预训练、微调和评估航空航天实体世界模型的无人机代理基准套件。arXiv预印本arXiv:2408.15511 (2024)。
[38] Joel Ye, Dhruv Batra, Abhishek Das, and Erik Wijmans. 2021. 辅助任务和探索实现物体目标导航。IEEE/CVF国际计算机视觉会议论文集。16117-16126。
[39] Bangguo Yu, Hamidreza Kasaei, and Ming Cao. 2023. Co-NavGPT:使用大型语言模型进行多机器人协作视觉语义导航。arXiv预印本arXiv:2310.07937 (2023)。
[40] Bangguo Yu, Hamidreza Kasaei, and Ming Cao. 2023. LTMVN:利用大型语言模型进行视觉目标导航。2023 IEEE/RSJ智能机器人与系统国际会议(IROS)论文集。IEEE, 3554-3560。
[41] Jie Zhang, Mingxuan Li, Yitai Xu, Hua He, Qun Li, and Tao Wang. 2025. StrucGCN:结构增强的图卷积网络用于图嵌入。信息融合117 (2025), 102893。
[42] Nan Zhao, Weidang Lu, Min Sheng, Yunfei Chen, Jie Tang, F Richard Yu, and Kai-Kit Wong. 2019. 灾难中的无人机辅助应急网络。IEEE无线通信26, 1 (2019), 45-51。
[43] Yong Zhao, Bin Chen, XiangHan Wang, Zhengqiu Zhu, Yiduo Wang, Guangquan Cheng, Rui Wang, Rongxiao Wang, Ming He, and Yu Liu. 2022. 一种基于深度强化学习的源定位搜索方法。信息科学588 (2022), 67-81。
[44] Yong Zhao, Kai Xu, Zhengqiu Zhu, Yue Hu, Zhiheng Zheng, Yingfeng Chen, Yatai Ji, Chen Gao, Yong Li, and Jincai Huang. 2025. CityEQS:城市空间中实体问答基准上的分层LLM代理。arXiv预印本arXiv:2302.12532 (2025)。
[45] Gengze Zhou, Yicong Hong, and Qi Wu. 2024. NavGPT:在视觉与语言导航中使用大型语言模型进行显式推理。AAAI人工智能会议论文集,第38卷。7641-7649。
[46] Kaiwen Zhou, Kaizhi Zheng, Connor Pryor, Yilin Shen, Hongxia Jin, Lise Getoor, and Xin Eric Wang. 2023. ESC:使用软常识约束进行零样本物体导航的探索。机器学习国际会议论文集。PMLR, 42829-42842。
A 附录
在此附录中,我们提供了有关数据集、方法和实验程序及结果的详细信息,以增强读者对我们工作的理解。
A. 数据集详情
CityAVOS数据集的收集过程可描述如下。
- 环境修改:我们在EmbodiedCity中修改了城市环境,引入了专门为AVOS任务设计的目标物体。
-
- 场景划定:定义场景边界并根据整体场景范围和目标物体尺寸确定步长。在场景内设置搜索任务的起点。
-
- 任务生成:识别和定位目标物体。捕捉每个目标及其周围环境的图像。准备相应的目标描述并根据难度进行分类。任务示例如图5所示。
-
- 轨迹收集:开发Python脚本来控制无人机并启用自动化轨迹获取。
-
- 手动验证:每条轨迹都经过手动审查以识别和过滤出错误路径。任何错误轨迹都重新手动生成。

图5:CityAVOS数据集中的任务。
表6:基于任务难度的任务分类和依据。
| 任务难度 | 简单 | 中等 | 困难 |
|---|---|---|---|
| 任务属性 | 易于搜索和易于识别 | 难以搜索和易于识别 | 难以搜索和难以识别 |
| 场景大小 | 小 | 大 | 大 |
| 目标唯一性 | 唯一 | 唯一 | 非唯一 |
| 任务数量 | 1320 | 720 | 380 |
| 任务示例 | 在这条街上寻找 安全商店 |
在公园附近寻找中国工商银行 | 在这个社区中寻找停车位旁边的垃圾站 |
表6显示了分类规则和任务示例。我们旨在通过这三个不同难度级别全面评估代理识别目标的能力,
在AVOS任务中探索空间并进行认知推理。具体来说,在简单任务中,物体在小场景中是唯一的,要求代理具备基本的语义理解和空间探索能力。在中等任务中,物体在大场景中是唯一的,要求代理高效地探索空间。在困难任务中,物体在大场景中是非唯一的,要求代理根据物体及其周围环境的特征进行全面推理和决策。
A.2 PRPSearcher方法详情
以物体为中心的语义分割细节。为语义分割模型准备一段分割提示有助于在分割过程中控制语义范围。以物体为中心的语义分割首先利用MLLM推断与目标物体相关的语义,然后将相关语义输入分割模型。这种方法有效减少了后续语义地图构建过程中的计算复杂度。用于此过程的MLLM提示Prompt t_{rel}如图6所示。
你正在操作一架无人机在城市空间中搜索视觉目标。你正在寻找的目标是图像中的[object_text]。图像中有哪些明显的物体(最多10个)可以帮助我从远处定位位置?请只返回物体,用句号(.)分隔。
示例1:
object_text : 名为Cheesupod的服装店
响应:
Cheesupod招牌.树.路灯杆.楼梯.邮箱.聚光灯.
示例2:
object_text : 名为Family Mart的商店
响应:
FamilyMart招牌.树.窗.围栏.黄色面板.绿色面板.购物袋
图6:相关语义提示。
3D认知地图中的吸引力细节。3D认知地图反映了场景语义对代理的吸引力,本质上源于语义与目标物体的相关性。为了获得语义及其对应的吸引力,代理需要使用MLLM进行推理。用于此推理过程的提示如图7所示。
行动规划细节。在我们的方法中,代理的行动规划由MLLM引导,相应的提示如图8所示。吸引力分数用作采用利用建议的概率提示,而提示中探索建议的频率由参数θ调节以实现IPT机制。在行动规划过程中,基于当前视角的RGB图像,MLLM代理还需要确定是否已找到目标物体并相应执行停止动作。
方法工作流程细节。为了更好地理解我们的方法,我们在图9中展示了工作流程。在开始物体搜索之前,基于给定的物体信息,MLLM代理进行推理以识别与目标相关的物体。
你正在操作一架无人机在城市空间中搜索视觉目标,你正在寻找的目标是图像中的[object_test]。请分析以下物体[object_semantics]与搜索目标的相关性,并给出0到1之间的分数(保留两位小数)。”在分析相关性时,请依次考虑被评分的物体/螺钉中是否存在搜索目标的可能性。0表示完全不可能,1表示高度可能。分数要求在0和1之间均匀分布。仅返回分数数字,用逗号分隔,不要包含任何其他词语。
示例1:
object_test: 名为Cheesupod的服装店
object_semantics: ‘黄色面板’, ‘围栏’, ‘窗’, ‘树’
响应: [0.75, 0.25, 1.0, 0.5]
示例2:
object_test: 名为Cheesupod的服装店
object_semantics: ‘招牌’
响应: [0.75]
图7:3D认知地图提示。
你正在操作一架无人机在城市空间中搜索视觉目标。对于每一步,你将收到以下输入:
-Image_RGB_input: 表示你当前视图的RGB图像,这是第一张图像。 -Image_object: 你要搜索的物体的图像,这是第二张图像。 -Object_: 上一步生成的答案。
首先,检查第二张图像中的搜索目标是否出现在第一张图像中。如果是,请直接返回’Stop’;如果不是,请继续思考。
接下来,请根据以下8个动作中的一个进行选择,遵循指南:[上, 下, 前进, 左转, 右转, 向左走, 向右走]
指南:
- 利用建议:选择动作[利用建议]将帮助你以[吸引力值]的概率接近目标。
-
- 认为这一步是你调整视角的最后一步,所以选择最紧急的动作。
-
- 如果前进会撞到墙上,请勿选择前进。
-
- 如果概率足够高,请根据利用建议移动。如果不够,请参考探索建议,也可以根据自己的想法行动。
-
- 利用建议:选择动作[利用建议]帮助你探索周围的环境。
- 仅返回你选择的动作名称。
图8:行动规划提示。
在搜索过程中,无人机持续从其当前位置捕获RGB图像和深度图。代理首先使用这些视觉输入更新3D动态语义地图。这包括对RGB图像进行语义分割,其中预先识别的相关物体作为Grounded SAM的提示以产生以物体为中心的语义分割结果。然后将得到的掩码和标签与深度数据融合以计算世界坐标,用于动态更新语义地图。
然后,代理通过进一步推理构建3D认知地图。它评估观察到的语义元素与目标物体的相关性,为每个物体分配吸引力值,量化物体在场景中吸引代理注意力的程度。通过将这些吸引力值映射到其相应的语义元素,代理形成3D认知地图。同时,无人机更新3D不确定性地图,减少当前视野内区域的不确定性值。
最后,生成利用建议(来自认知地图)和探索建议(来自不确定性地图)。这些输出通过IPT提示机制整合,以有效引导代理的动作规划。
A.3 实验详情
A.3.1 指标。四个指标的公式如下所示。考虑一个包含q次实验结果的集合ER={er_1, er_2, \ldots er_q},其中每个元素er_i是一个四元组er_i={fs_i, ss_i, tl_i, fp_i}。这里,fs_i是一个布尔标志,fs_i=1表示UAV在第i次实验中成功定位目标物体,否则fs_i=0。变量ss_i表示采取的搜索步骤数,tl_i表示搜索轨迹长度,fp_i表示第i次实验中搜索停止时UAV的最终位置。对于这一组实验结果ER,SR和MSS可以使用以下公式计算:
SR=∑i=1qfsi/qMSS=∑i=1qssi/q \begin{aligned} S R & =\sum_{i=1}^{q} f s_{i} / q \\ M S S & =\sum_{i=1}^{q} s s_{i} / q \end{aligned} SRMSS=i=1∑qfsi/q=i=1∑qssi/q
给定目标位置的真实值tp*和搜索轨迹长度的真实值tl*,SPL和NE可以计算为:
NE=∑i=1q∥fpi−fpi∗∥/qSPL=SR⋅∑i=1qtli/tli∗ \begin{aligned} N E & =\sum_{i=1}^{q}\left\|f p_{i}-f p_{i}^{*}\right\| / q \\ S P L & =S R \cdot \sum_{i=1}^{q} t l_{i} / t l_{i}^{*} \end{aligned} NESPL=i=1∑q∥fpi−fpi∗∥/q=SR⋅i=1∑qtli/tli∗
A.3.2 基线。
- 随机探索(RE):在搜索过程的每一步,UAV从动作空间中随机选择一个可行动作。如果动作使UAV保持在场景边界内并避免与任何障碍物碰撞,则该动作被认为是可行的。UAV继续使用视觉输入检测目标物体的存在,并在成功识别后执行“停止”动作。
-
- 边界探索(FBE):UAV持续向前移动,直到接近环境边界或遇到障碍物。然后它进行转向操作,沿边界继续搜索。鉴于环境的三维性质,引入随机垂直运动以增强搜索过程。
-
- L3MVN:我们在该算法中使用了GPT-4o作为LLM和VLM。由于原始算法是为二维空间中的室内环境设计的,因此在适应代码以用于三维城市环境时修改了相应的二维组件。具体来说,我们用三维语义地图替换了二维语义地图,并将其与边界地图集成。此外,我们调整了全局策略以更好地适应CityAVOS任务。
-
- WMNav:我们在该算法中使用Gemini 1.5 Pro作为VLM。由于我们的环境中UAV只能获得第一人称视角图像,我们相应地修改了WMNav算法以确保比较实验的公平性。具体来说,算法被调整为基于第一人称视觉输入进行预测,并从该视角构建好奇心值图。
-
- STMR:我们在该算法中使用了GPT-4o作为LLM和VLM。由于该算法的代码尚未开源,我们根据对论文中技术方法的理解重现了该算法。
-
- 人类代理:在算法执行的每一步,我们向人类参与者展示了目标物体的图像及其相应的文本描述。基于无人机的第一人称视角,参与者被要求从预定义的可能动作集中选择一个动作。当参与者认为目标已被定位时,他们选择“停止”动作以终止当前任务。
- A.3.3 实验配置。我们的代码在Python 3.9环境中执行。实验在配备Intel i7-14700KF CPU和NVIDIA GeForce RTX 4070 Ti SUPER GPU的Windows 10平台上进行。
- A.3.4 大型模型配置。本实验中使用的所有MLLMs均通过API调用访问。API端点如下:GPT-40 (https://openai.com/index/hello-gpt-4o/),QwenVL-Max (https://dashscope-intl.aliyuncs.com),以及GLM-4V-Plus (https://open.bigmodel.cn/api/paas/v4/chat/completions)。
- A.3.5 案例研究。以下是所选情节的说明运行情况。在图10和图11中,我们可以观察到基于观察的认知地图和不确定性地图的映射过程。
案例1:在此情景中,分配给UAV代理的任务是在城市环境中搜索名为CENTRAL ALL-STAR的咖啡店,这是一个相对简单的搜索案例。在第二步中,代理识别出建筑物底部的一排商店,并在其3D认知地图中为此区域分配了高吸引力值。在利用建议的指导下,代理朝此区域前进。靠近后,它成功识别出目标物体并执行“停止”动作。随后的验证确认了检测的正确性,搜索任务被视为成功。
案例2:相比之下,第二个案例涉及更复杂的搜索任务,其中UAV代理需要找到位于建筑物前的中国海关标志。如图所示,代理最初检测到附近建筑物底部的多个标志。然而,由于距离限制的分辨率,它无法立即确定它们与目标的相关性。因此,代理导航至这些高吸引力区域进行更近距离的检查。利用去噪机制,代理能够有效地过滤掉无关物体。在后续的搜索步骤中,代理采用探索建议,调查之前未访问的区域。最终,代理成功识别出目标标志。尽管此任务相比案例1需要更多的搜索步骤,但目标仍被成功定位,证明了所提方法的鲁棒性。
参考论文:https://arxiv.org/pdf/2505.08765

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 24
24 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)