利用GDELT数据集预测(Predicting Social Unrest Using GDELT-论文翻译)
摘要:社会动荡是某些事件和社会因素造成社会普遍不满的负面后果。 我们想利用机器学习(随机森林、助推和神经网络)的力量来解释和预测何时会发生巨大的社会动荡事件(巨大的社会动荡事件是维基百科页面“美国内乱事件清单”所承认的重大社会动荡事件)。 我们审查并发现,在一次此类事件----桑德拉·布兰德的死亡----以及随后发生重大内乱的其他类似事件之后,以负面情绪发表的新闻文章数量有所增加。 我们...

摘要:社会动荡是某些事件和社会因素造成社会普遍不满的负面后果。 我们想利用机器学习(随机森林、助推和神经网络)的力量来解释和预测何时会发生巨大的社会动荡事件(巨大的社会动荡事件是维基百科页面“美国内乱事件清单”所承认的重大社会动荡事件)。 我们审查并发现,在一次此类事件----桑德拉·布兰德的死亡----以及随后发生重大内乱的其他类似事件之后,以负面情绪发表的新闻文章数量有所增加。 我们使用从谷歌的GDELT(全球事件、语言和音调数据库)表中获取的新闻文章作为一种媒介,研究导致美利坚合众国州和县两级大规模动乱的社会因素和事件。 为了能够识别和预测县一级的社会动荡,可以部署方案/应用程序来抵消其不利影响。 本文试图解决这一任务,即识别、理解和预测何时可能发生社会动荡。
关键词:社会动荡·新闻媒体·GDELT·主题·事件·随机森林·阿达促进随机森林·LSTM
- 导言
社会动荡可能对社会极为有害,特别是当它升级为暴乱和暴力示威时。 当地社区首当其冲受到影响,并可能对其社会经济发展产生持久影响。大量的研究已经深入到使用社交媒体数据来检测社会动荡;大多数围绕Twitter[2]、Tumblr[4]、Face book和一些研究是使用谷歌的GDELT事件表[5]进行的。 我们的工作重点是探索和分析新闻媒体数据,以检测社会动荡。 新闻媒体数据包含了丰富的洞察力,可以用来研究我们社会中发生的各种社会因素和事件。 通过孤立导致社会动荡的因素的潜在趋势,我们可以利用这种力量来警告公众不良社会事件的危险即将来临。 对这些数据的分析使我们能够确定与给定区域密切相关的某些主题和事件。 如果我们能够建立一个能够发现何时何地发生社会动乱事件并提醒有关当局采取必要行动的系统,那将是真正了不起的。防止事件一起发生,或为人民提供适当的安全措施。 通过开发能够利用新闻媒体数据充分预测社会动荡的机器学习模型,并通过减少与跟踪和跟踪此类事件相关的人工努力,我们可以更接近实现这一系统。
以前的研究[5]使用GDELT的事件表建立了一个基于隐马尔可夫模型(HMMs)的框架来预测与国家不稳定有关的指标。 在更细粒度的地理级别上确定这些指标,可以使政府采取有针对性的外联方案、分配更多执法资源或发展预警系统等形式的有重点和有效的行动。 基于这些假设,我们决定将我们的研究重点放在不仅发生在州一级,而且发生在县一级(在毗连的美国内)的巨大社会动荡事件上.我们假设,2015年在巴尔的摩发生的大骚乱,2016年在密尔沃基和夏洛特发生的大骚乱有一个种族歧视因素,与达科他州接入管道有关的抗议有与环境相关的因素,这与新闻文章中显示一个地区建筑动乱水平的情绪恶化有关。 我们还假设,一个与威胁、胁迫、攻击、抗议和其他形式的不赞成行为升级有关的事件发生较多的地区可能会遭受更高程度的社会动荡。
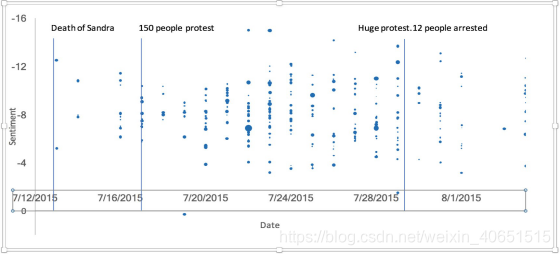
我们选择了一个这样的事件,桑德拉·布兰的死亡,来检验我们的假设,使用GDELT的全球知识图(GKG)和事件表来监测世界各地的印刷、广播和网络新闻媒体。 桑德拉在监狱中的死亡引起了重大的内乱,因为联邦调查局的调查显示,所需的政策没有得到遵守。 在她14岁去世后 第4条 2015年7月的讨论随着情绪的恶化而增加,直到影响消退。 29日发生了以抗议形式的大规模骚乱事件第4条2015年7月。 这confirmed我们的假设,即新闻反映了社会,可以用来检测建筑动荡。 图1描述了讨论这一事件的文章的情绪如何随着时间的推移而变化,在SandraBland的死亡情况下。 泡沫的大小代表新闻中事件的提及;Y轴包含情感值,X轴是时间线。
2.相关工作
本文的重点是利用新闻媒体来预测美国县州两级的社会动荡。 在利用社交媒体预测社会动荡方面做了大量工作。 [1]使用社交信息来预测社会动荡。 [2]致力于自动预测动乱,并filtering大量推文,以确定与动乱有关的推文。 [3]重点通过分析Tumblr的大规模微博流,发现新出现的内乱事件。 [4]提出了一个事件预测模型,利用Twitter中的活动级联来预测拉丁美洲三个国家:巴西、墨西哥和委内瑞拉的抗议事件。 [5]利用来自GDELT事件流中时间突发模式的新闻媒体的信息来揭示东南亚five国家潜在的事件发展机制。 我们的研究旨在测量社会中普遍存在的社会因素,使用GDELT的GK G表以及从GDELT的事件表中收集的事件类型,这些事件可能导致巨大的社会动荡。 我们的主要贡献是考虑到社会的全面情况,以预测县一级的动荡程度,而以前的工作是研究更大的地理区域。 我们预测美国2918个县的动乱程度,这可能是打击抗议活动不良影响的efficient工具。
3.数据
3.1 关于GDEL
GDELT是由谷歌维护的事件、位置和音调的全球数据库。 它包含自1979年以来以100多种语言从广播、印刷和网络新闻来源挖掘的结构化数据。 它连接了与世界各地发生的事件相关的人、组织、地点、主题和情感。 它通过媒体的眼睛来描述社会行为,使它成为衡量社会因素和检验我们假设的理想数据源。 我们使用了两个GDELT表,全球知识图(GKG)和事件表。
GDELT的GKG捕捉了世界各地发生的事情,它的背景是什么,谁参与其中,以及世界对它的感觉;每一天。 在它包含的27个fields中,我们使用了以下四个:位置、日期、主题和相关的情感。 位置field包含新闻文章中找到的所有位置,文档的平均音调与其相关联。 日期格式为-YYYY MMDD。 我们将472个感兴趣的主题分为以下四类-犯罪、经济、环境和健康。 这样做是为了观察哪一类影响动乱的升级。 以下是一些主题的说明性例子-犯罪主题的例子包括武装冲突、逮捕、危害人类罪;经济主题包括民主、宪法和联盟;环境主题包括毁林和气候变化;健康主题包括疾病。
GDELT事件表以CAMEO格式(冲突和调解事件观察)记录两个行为者和Actor1对Actor2采取的行动。 事件表包含58个fields。 我们使用了SQLDATE、事件根代码、NumMents、AvgTone和位置fields。 SQLDATE是MMDD格式YYYY日期。 事件根代码是事件所属的根级类别。 Num Mentions是在所有源文档中提到一个事件的总数,这有助于衡量一个事件的重要性。 AvgTone是包含一个或多个事件提及的所有文档的平均音调(评分范围从−100(极为负)到+100(极为正)。 地点是文章中提到的所有地点的城市、州、国家描述。 使用的客套事件代码包括失望、威胁、抗议、胁迫和攻击,因为我们假设这些事件类型更有可能导致巨大的社会动荡。
3.2 社会无保障活动来源
维基百科被用来识别2015-2017年美国的重大社会动荡事件,这些事件在整篇论文中被称为“巨大的社会动荡事件”。 这些事件是利用各种新闻来源verified的。
3.3 绘制地图
这里的映射是美国的时间和位置表示。 映射点有两个属性-位置和时间。 不同的地点在不同的时间点有不同的行为。 因此,每天取样本点对模型进行训练和测试。 考虑了一个月的样本窗口,使用了一个月的绩效窗口。 值一、三和六个月的观察窗口也被使用(图1)。 2)。 以2015-2017年期间所有日期的2918个县为样本点。 数据包含1,049,840个点。 如果在数据点的性能窗口中发生了不安定事件,则将其标记为事件点。 其他数据点标记为非vent点。 不幸事件是从2015年至2017年期间美国重大动乱事件列表中identified的,这些事件是用维基百科中的位置和时间属性提取的。 训练模型的最终数据包含1265个事件点。 没有点被随机抽样到8735,以创建一个平衡的数据集。

3.4 数据提取
当GDELT每fifteen分钟添加一篇新闻文章时,每篇文章都被简洁地作为一行发送到GDELT表中。 进行了一些处理步骤来表示具有所需格式的位置和时间属性的GDELT数据。 GK G表包含7.4TB的数据和事件表包含127GB的数据. 我们使用谷歌大查询子集这些数据为美国获取数据,并进行清洁活动,以收集主题和事件代码的条目感兴趣。 稍后,我们将主题表和事件表存储在Google云存储中,并使用PySpark执行下面概述的清洁步骤。 GDELT将文章中讨论的所有主题作为一个条目放在一行中. 我们把这些主题分成单独的条目。我们所针对的主题以多种方式展示,它们要么与其他主题隔离,要么与其他主题结合。 例如,农业是我们感兴趣的主题之一;有一些条目要求农业specifically,然后有一些条目将农业与农业和粮食等其他主题结合起来。 我们需要收集农业存在的所有实例,因此我们创建了一个包含每个感兴趣主题的所有可能组合的映射,以确保我们捕获所有的可能性,而不仅仅是感兴趣主题的确切匹配..
在GDELT表格中field的位置有城市/地标、州和国家一级的格式。 市到县测绘用于提取县级数据.. 改进这一绘图工作也将使我们能够在县一级收集更准确的信息。 在县和州两级的地方都有各自的观点。 对于创建的映射的每个数据点,我们捕获了样本日期前一、三和六个月的以下特征:感兴趣主题发生的总次数(G KG表)、与主题相关的总体情绪(G KG表)、提及感兴趣的客套事件代码的总次数(事件表)以及与它们相关的Tone和(事件表)。 共从GDELT表中提取了1446个特征。
4 方法
4.1架构
在发生巨大的社会动荡事件之前,可能会发生一些不同类别的事件和广泛的社会因素/主题。 使用从维基百科捕获的社会动荡事件(并与各种新闻来源交叉引用),我们创建了一个映射,如前面在Sect中所描述的。 3.32015-2017年期间所有动乱事件点和非最不严重事件点。 发生重大社会动荡的地点和时间被标记为事件点,其余数据点被标记为非事件点。 利用这种映射,我们从GDELT的清洗表中收集数据。
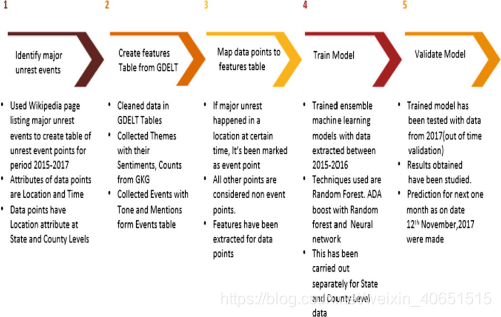
我们使用2015-2016年期间捕获的1446个特征作为培训数据,对数据进行了机器学习模型的培训。 为了捕捉特征内的变异如何随着时间的推移影响社会动荡,我们使用了一个LSTM模型,其中33个特征(1446个)被identified为解释社会动荡的最significant因素(基于随机森林分析的结果)。 然后,我们对2017年数据上的模型进行了过时验证。 结果和指标已经在接下来的章节中进行了分析和讨论。 此外,我们还预测,截至12日,下个月的社会动荡将加剧 第4条 2017年11月。 为了实现这一点,我们收集2015年1月至11日的数据 第4条 并于2017年11月训练机器学习模型,预测社会动荡的程度.. 然后,我们identified动乱程度最高的县,在完成绩效期后,我们通过阅读新闻文章,用该县实际发生的事件验证了我们的预测结果。 图3将我们的研究框架总结为一个图表。
4.2 方法概述
随机森林。 随机森林是集合学习技术的一种形式,可用于classification和回归问题。 它们通过在训练时构建多个决策树来操作,并根据一个投票机制输出一个预测的类,该投票机制考虑到决策树过程中每个分裂中最常见的类。 随机森林执行隐式特征选择,并提供特征重要性,这将帮助我们理解在构建巨大动荡事件中具有最significant影响的特征。 拥有一个具有多个特征变量的大数据集,我们应用这种技术建立了我们的模型。
AdaBoost与随机森林助推。 ADA Boost是针对不太容易出现overfitting问题的classification问题开发的Boost算法。 因此,我们探索了这一技术。
神经网络。 Artificial神经网络是受大脑生物神经网络启发的计算系统。 神经网络在finding数据中的非线性关系方面表现得特别好。 我们使用神经网络来分析我们的数据中是否存在这样的模式。长期短期记忆网络。 长短期记忆网络是一种特殊的神经网络,称为递归神经网络(RNNs).. 它们能够学习数据序列中的长期依赖关系。 为了捕捉特征的时间变化及其对社会动荡事件的影响,我们使用从随机森林特征重要性获得的33个最significant特征进行了初步的LS TM模型。 这可以在未来进一步发展。
5.实验及结果
5.1特征描述
从GKG和Event表中提取了1446个特征。 利用随机森林模型得到的特征重要性来find顶级特征列表。 其中一些是武装冲突、逮捕、冲突和暴力、犯罪和联盟腐败、宪法、经济民主。 为了可视化特征如何随着时间的推移而变化,在州一级分析了Dakota访问管道动荡事件,下面将讨论这个问题。考虑从样本日期t到t-1前一个月的特征值为F T-1 从t-2到t-3的值为F T-3 从t-5到t-6的值为F t-6 。 让特征的百分比从F变化 T-3 到F T-1 表示为P2和特征F的百分比变化 t-6 到F T-3 代表为P1
P.2 ¼ F T-1 -FT-3 ×100 ð1Þ
P.1 ¼ F T-3 -F t-6 ×100 ð2Þ
图4是在事件点和nonevent点随时间变化的情况下,特征变化多少的比较,这是从P1到P2值变化的比较。 为了说明这一变化,使用了犯罪武装冲突特征,可以看出,在事件点的情况下,该特征与非事件点相比变化很大。 许多顶级功能就是这样。 图5描述了不同的重要特征在specific动乱事件中的变化。 随着重大动荡事件的临近,特征值的百分比变化更高(P2>P1)。 还可以观察到,特征环境的石油数量有很高的变化,从−69.2%到19.75%,表明新闻文章增加了对在一个巨大的动乱事件发生之前谈论石油的文章的报道(达科塔访问管道骚乱事件)。
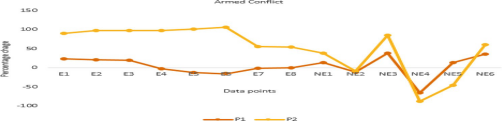
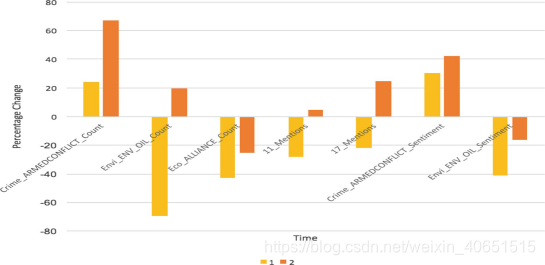
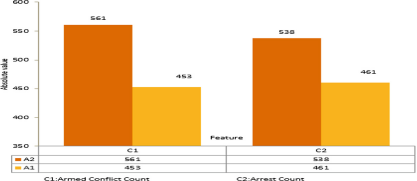
图6代表了绝对值中的相同现象,可以观察到,随着社会动荡事件的增加,围绕因素的讨论量增加(A2>A1)。
A.2 ¼F T-1 —F T-3 ð3Þ
A.1 ¼F T-3 —F t-6 ð4Þ
为了捕捉特征的这一时间变化,使用LS TM(长短期记忆网络)运行了一个初步模型,使用33个被随机森林列为重要特征来解释社会动荡。 使用的特征:不赞成事件提及和语气,威胁事件提及和语气,抗议事件提及和语气,与抗议、武装冲突和冲突主题相关的叙述和情感暴力。 得到的结果如下(表1)。 这种性能可以通过增加考虑的特征来增强。
表1. LSTM结
|
回收 |
精密精密精密 |
F1得分 |
|
0.78 |
0.38 |
0.51 |
5.2 衡量标准
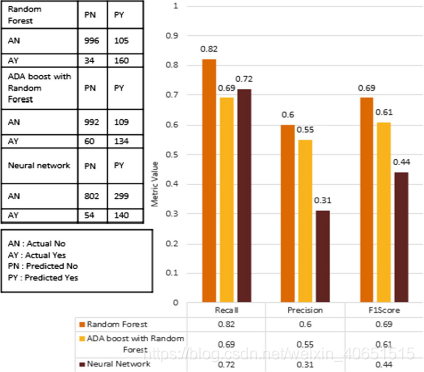
如果一个非事件点被我们的模型标记为事件点,则它是假阳性。 如果一个实际的事件点没有被我们的模型检测到,它是一个假阴性。 misclassification的百分比取决于建模过程中使用的概率阈值。 如果选择一个较小的截止值,nonevent点也可能跨越阈值并导致假阳性,如果选择更大的截止值,一些事件点可能无法满足标记。 将选择一个最佳切断。 我们选择了一个阈值,它最大限度地增加了发现的事件点的数量,同时试图减少错误警报的数量。 在该州获得的结果(图1)。 7)和县(图)。 下面讨论8)层次。 下面讨论的度量仅在过时的验证集上进行估计。
随机森林。 90%的Nevent点被正确地标记为Nevent。 10%的非事件点被错误地标记为属于假阳性的事件点。 82%的事件点被正确地标记为动乱事件。 18%的事件点被错误地标记为非事件点,属于假否定。 F1分是精度和召回的调和均值. 对于随机森林模型-精度为0.6,召回率为0.82,F1得分为0.69。
神经网络。 72%的Nevent点被正确地标记为Nevent。 28%的nevent点被错误地标记为事件点,这些事件点属于假阳性。 72%的事件点被正确地标记为动乱事件。 28%的事件点被错误地标记为非事件点,属于假阴性。 采用神经网络模型,精度为0.31,召回率为0.72,F1得分为0.44。
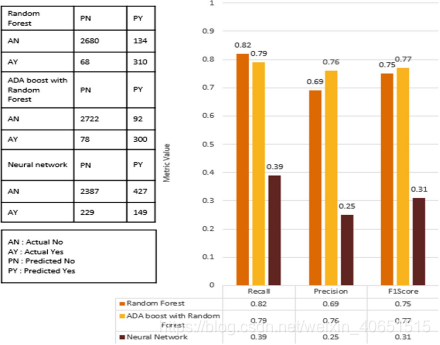
县级城市衡量成果
随机森林。 95%的Nevent点被正确地标记为Nevent。 5%的非事件点被错误地标记为属于假阳性的事件点。 82%的事件点被正确地标记为动乱事件。 18%的事件点被错误地标记为非事件点,属于假否定。 使用随机森林,精度为0.69,召回率为0.82,F1得分为0.75。
神经网络。 84%的Nevent点被正确地标记为Nevent。 16%的nevent点被错误地标记为事件点,这些点属于假阳性。 39%的事件点被正确地标记为动乱事件。61%的事件点被错误地标记为非事件点,属于假阴性。 采用神经网络模型,精度为0.25,召回率为0.39,F1分数为0.31。 从结果可以明显看出,随机森林在州和县两级的F1分均表现良好
为了执行过时的验证,维基百科2017年巨大社会动荡事件的数据被认为是测试一个在2015-2016年数据上训练的模型。 这包括与特朗普总统有关的骚乱事件、五一节对政府的抗议、对米洛斯·扬诺普洛斯演讲的抗议以及由于警察不当行为而引起的抗议。 这些事件大多是由于领导人和政府的活动使公众感到越来越不满。 这些主题的价值在下面的段落中分析了四个类别,事件(E)、无事件(N)、假阳性(F P)和假阴性(FN)。 在相关地区发生实际动乱事件之前,新闻中观察到大量关于领导人和政府主题的负面谈话。 此外,还观察到大量的谈话,这些地点都是假的实证,这可能有助于确定动乱正在沸腾的地区。 在没有任何要点的情况下,很少有讨论。 主题领导平均被讨论次数为事件组17174次,非事件组373次,假阳性组4554次,假阴性组123次。 主题总政府平均讨论次数为事件组6614次,非事件组162次,假阳性组1684次,假阴性组51次.. 与地方政府相关的平均情绪−为事件组1.6,非事件组−0.9,假阳性组1.8,假阴性组0.3。 假阴性病例有较低的值,如非出点,因此 没有被模型检测到。 下文将讨论对选定的决策树清单所作的观察,以了解misclassified案件的潜在根源。
基于与武装冲突、抗议和价格有关的情绪、与反对和胁迫有关的计数的条件在事件和非事件点的分离中起着突出的作用。 如果某一特定地点的利益关系发生了超过681次关于政府被携带的谈话,而社会上持续存在的关于武装冲突的负面情绪超过-1.82次,而与胁迫和不赞成有关的事件分别发生超过3116次和23078次,那么它就被标记为动乱事件的嫌疑人。假正分析。 以下观察也是通过审查决策树中如何执行决策行动来获得的。 14%的假阳性病例发生在重大动乱事件发生后。 因此,这种模式可能会考虑到骚乱事件后发生的大量讨论,作为社会不满的一种衡量标准。 85%的假阳性案件与武装冲突和抗议有关。 48%的假阳性病例具有较大的胁迫和民主计数值,这与事件点有关。 如果某一地点具有与特定因素相关的消极情绪,该地点的管理员可以在这些地区采取行动。假阴性分析。 61%的假阴性有较少的计数与特征,如不赞成和胁迫。 40%的假阴性没有必要的负面情绪与价格等特征相关。
5.4预测未来一个月的不稳定
我们使用了2015年1月至11月11日的GDELT数据 第4条 2017年训练模型,并预测下个月动乱程度高的最高可疑州县(11月12日) 第4条 2017年至12月12日 第4条 2017)。 在完成表演期后,我们通过新闻文章来find是否真的发生了动乱事件,findings列在相应的表格下面(表2和表3)。
表2 国家一级的预测。
|
国家名称 |
概率分数 |
|
佛罗里达 |
0.964 |
|
加利福尼亚 |
0.961 |
|
亚利桑那州 |
0.950 |
|
华盛顿 |
0.945 |
数百人于2017年11月21日在佛罗里达抗议海地的裁决。 2017年11月26日,佛罗里达州也发生了反特朗普的抗议活动。 加州奥克兰市12月5日至12月11日发生了3000名工人的罢工。 在华盛顿观察到一些抗议,反对净中立,共和党税收法案,液化天然气工厂。 截至12月12日,亚利桑那州尚未verified重大抗议活动。
表3 县一级的预测。
|
县名 |
国家名称 |
概率分数 |
|
费城 |
宾夕法尼亚州 |
0.167 |
|
旧金山 |
加利福尼亚 |
0.166 |
|
达拉斯 |
德克萨斯州 |
0.166 |
|
马尔科帕 |
亚利桑那州 |
0.166 |
|
洛杉矶 |
加利福尼亚 |
0.163 |
|
厨师 |
伊利诺伊州 |
0.162 |
|
Bexar |
德克萨斯州 |
0.162 |
|
迈阿密-戴德 |
佛罗里达 |
0.160 |
被监禁的说唱歌手Meek Mill的数百名支持者于11月13日聚集在费城刑事司法中心外,随后在费城进行了36447次逮捕后,在观察期6个月内,费城进行了超过36447次讨论,负面情绪为4.1−和2191698次提到与不同意登记有关的事件。 虽然在Maricopa的表演窗口期间没有发生重大动乱事件,但2017年8月23日,成千上万的人在凤凰城抗议特朗普。 这种模式可能已经感受到公众对行政管理的紧张。 11月24日,芝加哥库克县的数百人在黑色星期五举行抗议。 数千名抗议者参加了2018年1月20日在芝加哥举行的妇女集会。 这些事件发生在库克县发表horrific情绪为-5.2的关于侵犯人权的新闻文章之后。 一些团体,如SEIU,FANM,2018年1月12日在迈阿密戴德县的小海地抗议政策和不尊重政府对移民社区,如海地人。 在这之前,新闻中发生了负面讨论,−3.5关于仇恨言论,2.1关于迈阿密戴德政府。 据我们所知,洛杉矶、Bexar和达拉斯没有发生重大动乱事件。
6. 结论
由于GDELT每15分钟从各种新闻来源收集新闻,事件在世界各地不断记录。 这基本上可以用作研究感兴趣事件的跟踪器;特别是巨大的社会动荡事件。 衡量社会的变化,因为它涉及到一个specific事件,以及在其之后发生的事件,是衡量各地区社会动荡程度的一个伟大工具。 在我们的论文中,使用机器学习技术研究了与社会动荡有关的主题和事件,试图确定州和县一级在不久的将来可能发生社会动荡的地区。 difficult手动跟踪影响社会动荡的所有因素,并了解它们在不同地区的变化情况,但这项任务更容易通过机器学习和大量的社交记录(新闻媒体)来实现..正如上文各节所讨论的,在发生社会动乱事件之前,遭受上述事件之害的地区一般都会看到就某些事件发表大量负面新闻的趋势
论文下载链接:1. 2018_PredictingSocialUnrestUsingGDELT.pdf-深度学习文档类资源-CSDN下载
2.https://link.springer.com/chapter/10.1007%2F978-3-319-96133-0_8

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)