论文分享|融合粒球视觉空间表征增强面部表情识别:实现视觉特征与空间特征的提取融合
论文信息
论文标题:
Fusion of Granular-Ball Visual Spatial Representations for Enhanced Facial Expression Recognition
论文作者:
Shuaiyu Liu, Qiyao Shen, Yunxi Wang, Yazhou Ren and Guoyin Wang
期刊:
IJCAI2025 International Joint Conference on Artificial Intelligence 2025

引言
随着人工智能技术的快速发展,通过面部表情理解人类情绪已成为构建智能系统的重要任务。面部表情是人类表达情感的一种非语言方式,如果机器能够读懂这些“无声信号”,就能与人类进行更自然的互动。研究表明,面部表情的变化由大脑传递的情绪信号引起,面部肌肉运动导致表情组件或器官的形态发生变化,从而形成不同的表情。例如,当一个人生气时,眼睛会明显变大、瞳孔变小、眉毛下垂等,这些变化不仅是直观的视觉表达,还具有内在的空间结构差异,如组件间的相对位置和形状变化。
然而,绝大多数研究在面部表情识别(FER)中忽略了空间信息的挖掘,或未能有效利用这些信息。虽然基于深度学习的表情识别方法取得了较好效果,但大多数方法仍然专注于提取视觉特征,而直接舍弃面部表情的空间结构信息。随着图神经网络(GNN)的出现,越来越多研究尝试利用其优势提取视觉特征的空间结构信息。然而,这些方法传递给 GNN 的输入大多是经过 CNN 或 Transformer 主干从图像中提取的非图结构化特征,导致图像本身的空间信息在骨干网络处理中大量丢失。
针对这一问题,本文引入多粒度球(multigranularity balls)方法,将表情表示为具有丰富空间信息的图结构,相比传统由数万个像素点组成的图像,这种表示由有限的边和点组成,减少冗余数据,同时增强空间结构信息。基于此,文章提出了组件分离与空间自举融合方法(CS-SBF),通过表示提取网络(REN)、表示分离网络(RSN)和表示融合网络(RFN)将面部表情分解为不同组件,并利用空间信息指导视觉特征融合。此外,通过bootstrap 对齐损失解决组件特征在融合过程中出现的不对齐问题,最终采用分类头进行表情识别。
实验结果显示,CS-SBF 方法在多个真实和野生数据集上的识别精度表现优异,其中在 Oulu-CASIA 和 SAMM 数据集上的准确率分别达到了 97.34% 和 96.74%,显著优于现有先进方法。
SPRING

一、研究方法


本文提出的面部表情识别方法主要由三个核心模块组成:表示提取网络(REN)、表示分离网络(RSN)和表示融合网络(RFN),整体方法称为组件分离与空间自举融合(CS-SBF)。该方法通过多粒度球将二维面部图像转换为空间图结构,从而增强图像中的空间信息,并有效提升 FER 精度。
本文的核心创新点:
1、多粒度球表示与图结构:
(1)核心思想:将面部图像转换为节点-边图结构,每个球表示一个局部区域(眼睛、鼻子、嘴巴等)。
(2)流程:
1、图像分解为不同尺度的局部球。
2、节点与边构建,保留局部与全局空间信息。
3、多尺度图叠加形成多层图结构。
4、节点特征初始化为球内像素或视觉特征向量。
2、表示提取网络(REN):
(1)目标:提取基础视觉与空间表示特征。
(2)流程:
1、将多粒度球图输入 REN 主干网络。
2、通过卷积或图卷积层提取节点特征。
3、输出基础特征,为组件分离网络提供输入。
REN采用双流设计,对输入的图像和图结构进行分别提取,用VREN处理图像,提取视觉特征;用SREN处理图结构,提取空间特征。此外引入注意力引导模块AGM:通过视觉特征VREN引导空间特征SREN的注意力区域,解决双流对齐问题。
3、表示分离网络(RSN):
(1)目标:将基础特征分解为组件级视觉与空间特征。
(2)模块组成:
(a)视觉表示分离网络(VRSN):提取每个组件的视觉特征。
(b)空间表示分离网络(SRSN):提取每个组件的空间特征。
(3)流程:基础特征输入 VRSN 和 SRSN,生成组件级视觉与空间特征图,为融合网络提供输入。
4、表示融合网络(RFN):
(1)功能:利用组件空间特征引导视觉特征融合,形成最终面部表情表示。
(2)关键设计:
1、组件视觉特征与空间特征结合。
2、Bootstrap 对齐损失(LBA)解决融合错位问题。
3、融合特征通过 ReLU + 全连接层进行分类预测。
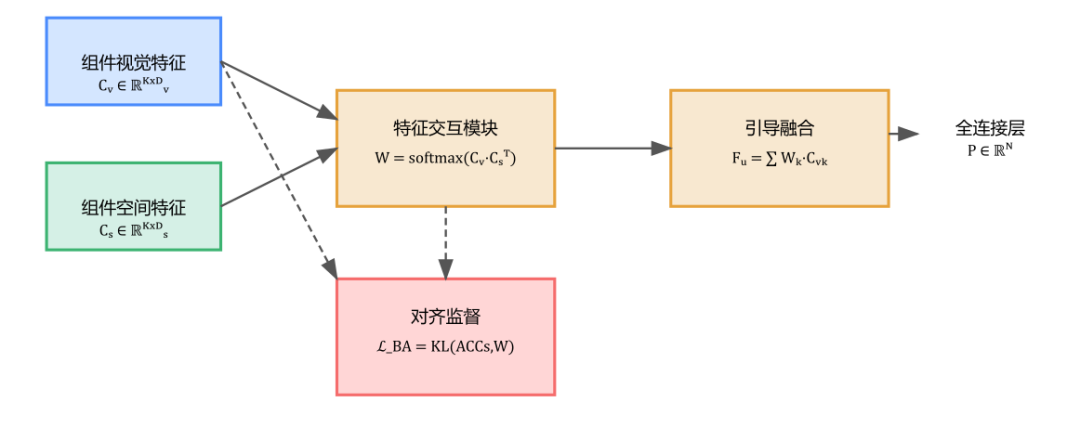
图1:表示融合网络(RFN)结构图
利用空间特征引导视觉特征的融合,通过自适应权重(反映组件变化程度)提升融合效果,再利用LBA损失函数,解决组件特征对齐问题,确保空间和视觉特征的一致性。
【数据集】
数据集与实验设计
1、数据集:FERPlus、AffectNet、RAF-DB、SFEW、Oulu-CASIA、SAMM。
(1)包含自然表情、遮挡及不同姿态的面部图像。
(2)表情标签包括生气、快乐、悲伤等。
2、数据预处理:
(1)人脸对齐与裁剪,标准化尺寸。
(2)多粒度球表示转换为节点与边图结构。
(3)构建多层图结构保留局部与全局空间信息。
3、实验模式:
(1)单流模式:仅使用视觉或空间特征。
(2)双流模式:同时使用视觉与空间特征,RFN 中组件级融合。
4、对比实验:
(1)与 CNN/Transformer 方法对比。
(2)消融实验验证模块有效性:VRSN、SRSN、RFN 及 Bootstrap 对齐损失的贡献。
5、评价指标:识别准确率。
01
【多粒度球表示与图结构】
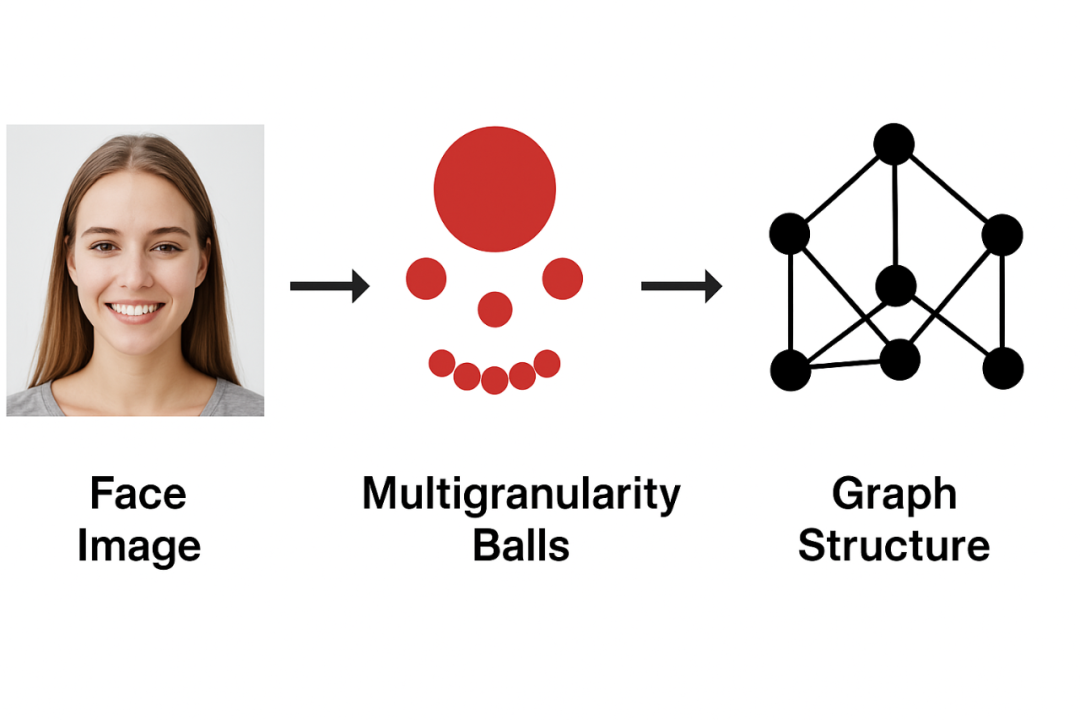
图2:面部图像 → 多粒度球 → 图结构
1、核心思想:将面部图像划分为多尺度矩阵区域,每个区域作为图节点,相邻区域建立边。
2、优势:相比传统图表示方法,GBR 保留了空间信息(形状、密度、相对位置、相对距离),并可通过多粒度而非单尺度来丰富表示。
3、噪声处理:节点数随分辨率和图像复杂度增长,如 384×384 的图像可能产生近 10000 个节点。使用下采样合并节点,保留关键区域并减少噪声节点。
注:粒球的特点:
(1)多粒度:粒球大小可以动态进行调整,大粒球覆盖均匀区域,小粒球保留细节。
(2)结构化表示:将图像转换为图结构。
02
【表示提取网络(REN】
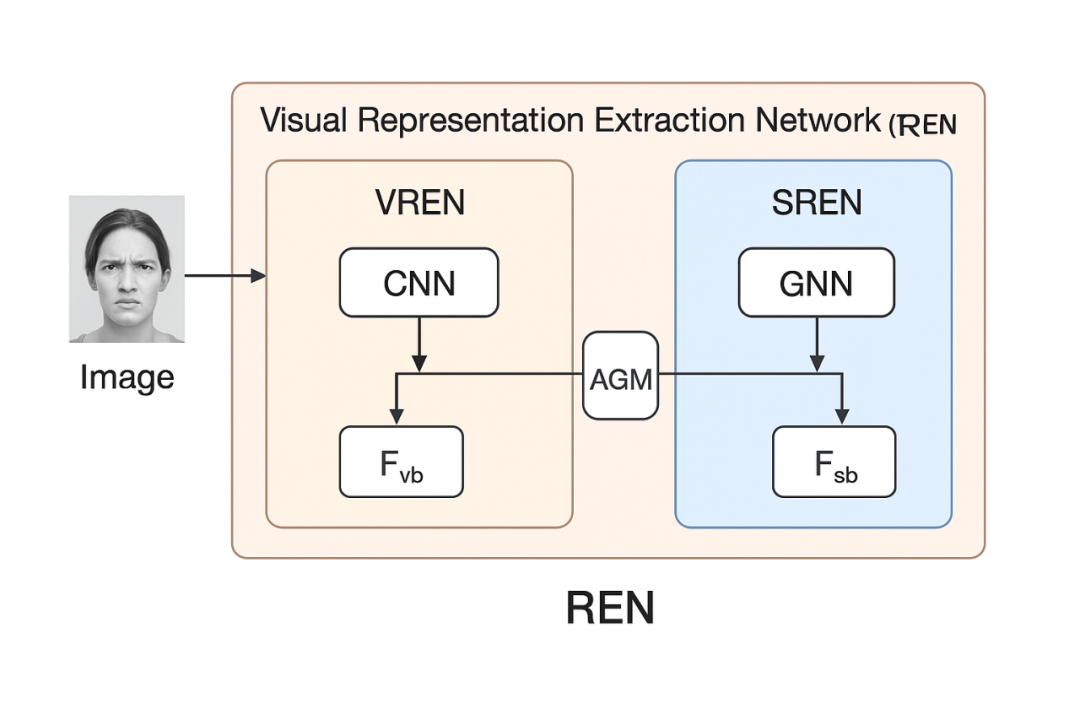
图3:REN流程图
1、VREN(视觉表示提取网络):专注从原始像素空间中提取局部纹理和颜色模式等视觉特征。
2、SREN(空间表示提取网络):基于图结构捕捉区域间的空间关系和结构依赖。
3、AGM(注意力引导模块):以视觉分支的注意力为“参考地图”,引导空间分支将注意力集中在对应的关键区域,从而减少模态间的错位。
REN采用双流设计,对输入的图像和图结构进行分别提取,用VREN处理图像,提取视觉特征;用SREN处理图结构,提取空间特征。此外引入注意力引导模块AGM:通过视觉特征VREN引导空间特征SREN的注意力区域,解决双流对齐问题。
这种“先独立建模,再通过注意力对齐”的策略,使得两种模态的特征能够高效融合,为后续的组件分离打下基础。
03
【表示分离网络(RSN)】
图4:RSN的流程图
RSN 的目标是将全局特征拆解为具有明确语义的面部组件表示:
1、将F_vb 和 F_sb 分别拆解为 K 个组件特征 (C_vk, C_sk),每个组件对应面部的特定结构区域。
2、使用 Sigmoid 作为非线性激活,使每个组件特征在训练中逐渐专注于不同的区域。
3、引入 ploid 函数增强注意力响应,保证组件更聚焦于情绪相关的动态变化部位。
这种基于”区域归属”的分离方法,不仅提升了特征的可解释性,也为后续的组件级权重分配提供了基础。
04
【表示融合网络(RFN)】
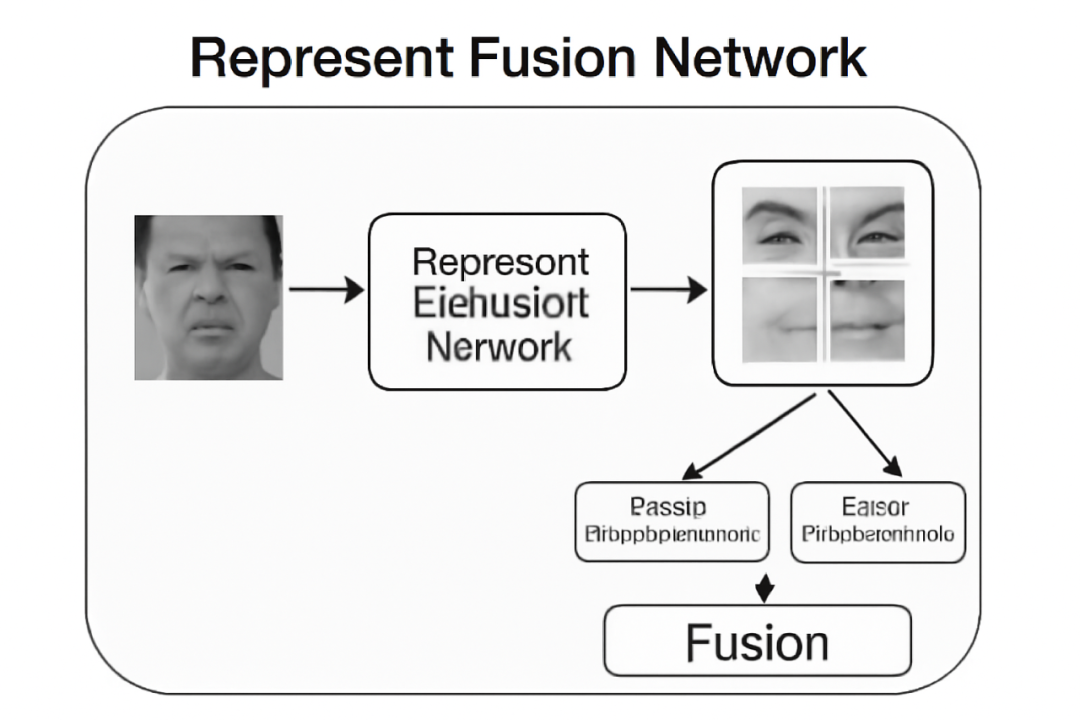
图5:RFN的流程图
RFN 的设计理念是“用结构变化指导视觉融合”:
1、通过空间特征 C_sk 计算各组件的结构变化幅度,生成自适应权重向量 W。
2、利用权重 W 对视觉组件特征 C_vk 进行加权融合,得到最终特征 F_u。
3、在训练中引入 Bootstrap Alignment Loss (L_BA),保证不同样本的组件位置对齐,提高权重计算的稳定性与泛化性。
这种机制让模型在融合时能够自动“挑重点”,更关注那些表情变化显著的区域。
CS-SBF 采用端到端训练,联合优化两个目标:
1、分类损失 L_cls:交叉熵损失,确保最终输出的表情预测准确。
2、Bootstrap 对齐损失 L_BA:正则化不同样本的组件位置分布,提升权重分配的鲁棒性。
最终优化目标为:L = L_cls + λ * L_BA
其中 λ 用于平衡两部分损失的重要性。
通过这种双重优化,CS-SBF 能够在复杂场景下保持高识别率,同时具备良好的跨数据集泛化能力。
SPRING

二、相关实验


【数据集】
本文实验使用了多个广泛使用的面部表情识别(FER)数据集,分别是:
-
Oulu-CASIA 数据集:
(1)包含来自 6 类 情绪的面部表情图像,包含 64913 张图像,分辨率为 320×240。
(2)该数据集提供了不同实验条件下的表情图像,适用于训练和验证 FER 模型。
-
SAMM 数据集:
包含 11816 张来自 7 类 情绪的微表情图像,分辨率为 960×650,用于测试 FER 模型在微表情检测中的表现。
-
FER-2013 数据集:
(1)包含 35886 张来自9 类情绪的面部表情图像,分辨率为 48×48。
(2)是广泛用于 FER 任务的标准数据集,适合多类情绪的训练与验证。
在实验中,所有图像都经过了 多颗粒球体表示(Multi-Granularity Ball Representation)处理,转换成图形数据,并进行了下采样以适应模型处理需求。
数据预处理阶段,所有图像和图形数据均进行了尺寸调整,统一调整为 224×224,以便于模型训练。实验中,采用了 4 折交叉验证,计算了各数据库下的平均准确率,并分别在全通道网络和核心通道网络下进行对比。
01
【实验细节】
本文所有模型均在 PyTorch 框架下实现,图构建使用 Spearman 相关系数,图卷积模块使用 Chebyshev 多项式近似。
图神经网络结构包括两层 GCN,每层节点特征维度分别设为 64 和 32。
通道卷积模块采用 1D 卷积,卷积核数量与选中通道数量一致。
所有网络均采用交叉熵损失训练,优化器使用Adam,初始学习率0.001;
训练过程中 batch size 为 64,训练轮数设为 100;
在CWGCN中,通道选择比例设置k=0.6,即保留top60%的关键通道。
02
【数据库】
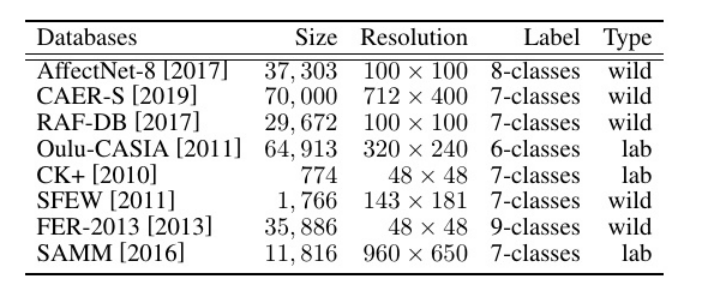
表1:所 有 数 据 库 的 详 细 信 息
这些数据集广泛用于情绪识别任务,包含不同种类和大小的样本,适用于多类情绪的训练与验证。实验使用 4 折交叉验证来进行模型训练与评估,实验采用 准确率 和 UF1(无偏F1分数)作为主要评价指标。
【实验设置】
1、数据预处理:所有的图像和图形数据都经过尺寸调整和数据增强,最终统一调整为 224×224,适配模型输入。
2、训练配置:
(1)初始学习率:0.0001,优化器为Adam。
(2)Batch size为16,训练轮数设为40。
(3)对于不同的网络架构和模型,使用了多种不同的卷积网络(如swinT-base)和图卷积网络(如GCN)来提取特征。
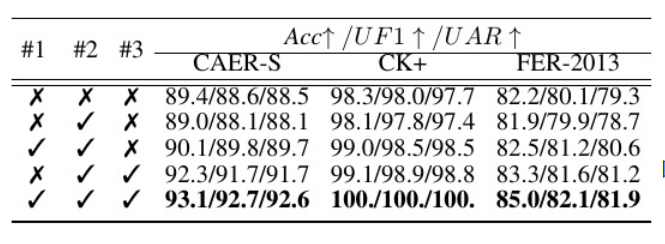
表 2 展示了CS-SBF方法在AGM、SRSN和LBA三个重要模块的消融研究结果。实验通过逐步添加这些模块,观察其对模型性能的影响。
实验结果解析:
1、在CAER-S数据集上,加入所有模块后,模型的准确率从89.4%提升至93.1%,F1分数和召回率也大幅提升。
2、在CK+ 数据集上,所有模块加入后,模型表现出100%的完美准确率,展现出模块的重要性。
3、在 FER-2013数据集上,尽管数据更复杂,加入所有模块后,准确率依然达到了85.0%,证明了该方法在复杂任务中的有效性。
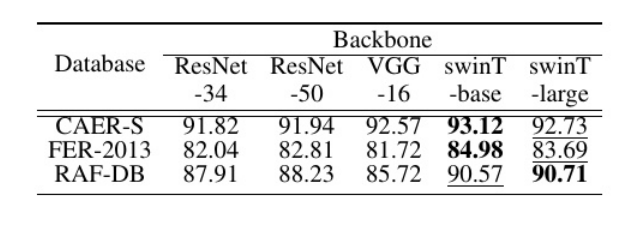
表 3 比较了VREN模型在不同骨干网络上的表现,涉及的骨干网络包括 ResNet-34、ResNet-50、VGG-16 和 swinT-base、swinT-large
分析与结论:
1、swinT-base在CAER-S数据集 上达到了93.12%的准确率,远超其他传统骨干网络。
2、在FER-2013数据集中,swinT-base也表现优异,准确率为84.98%,相较于ResNet和VGG网络,性能提升明显。
3、swinT-base在RAF-DB数据集上的表现为90.57%,也显示出强大的泛化能力,适用于多个数据集。
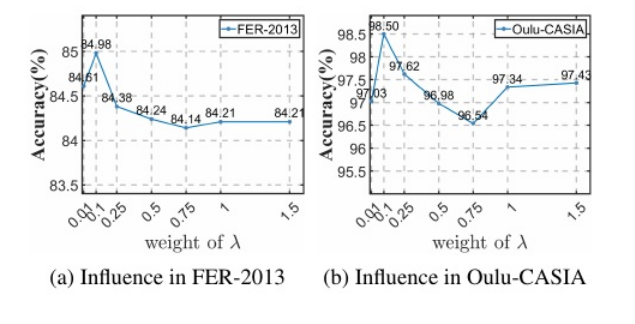
图6:展示了λ权重对模型在FER-2013和Oulu-CASIA数据集上的准确率影响
(a)FER-2013 数据集
1、分析:随着λ权重从0.01增加到0.25,准确率逐渐上升,达到 84.98%;但在λ = 0.5 时,准确率下降至 84.14%,之后基本持平。
2、总结:较小的λ 权重 更有利于准确性,λ = 0.01至 0.25时最佳。
(b)Oulu-CASIA数据集
1、分析:随着λ权重增大,准确率从97.43%提升至 98.50%,但当 λ 超过0.5 后,准确率开始下降。
2、总结:适当增大λ 权重有助于提升性能,λ = 0.5时效果最好。
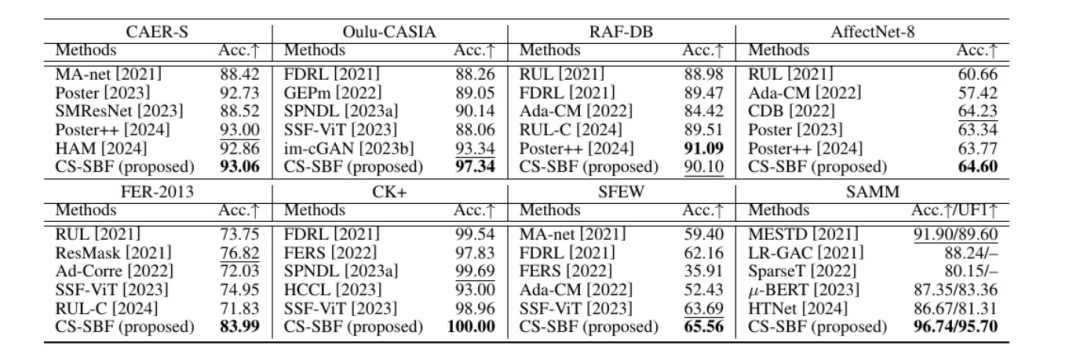
表4:不同方法在几个公共FER数据库测试集上的性能比较
通过对比不同方法在多个数据集上的表现,CS-SBF方法在多个数据集上都取得了显著的成果:
1、在CK+ 数据集上,CS-SBF达到了100%的完美准确率,领先其他方法。
2、在 Oulu-CASIA、RAF-DB和SAMM数据集上,CS-SBF也展现了优异的表现。
3、相对而言,CS-SBF方法在一些复杂数据集(如FER-2013 和 SFEW)中表现稳定,尽管有些方法在特定数据集上略占优势。

总结
本文提出的CS-SBF(Component Separation and Space Bootstrap Fusion) 方法在面部表情识别(FER)领域取得了显著的成果。通过精确设计的视觉表示和空间表示融合技术,CS-SBF 在多个公开数据集上的表现都超越了现有的主流方法,尤其是在CK+和SAMM数据集上取得了 100% 和 96.74%的准确率。
关键贡献:
1、粒球表示(Granular-Ball Representation):通过对图像进行多层次、颗粒化的表示,充分利用了空间信息的细节。
2、模块创新设计:本文通过引入Attention Guidance Module (AGM)、Space Represent Separation Network (SRSN)和Bootstrap Alignment Loss (LBA) 模块,进一步增强了模型对关键特征的学习能力,尤其在复杂数据集上表现稳定。
3、实验验证与消融分析:通过详细的实验对比,验证了每个模块对模型性能的贡献,证明了该方法在多个情绪识别任务中具有很强的适应性。
优势:
1、跨数据集的优异性能:无论是FER-2013,还是Oulu-CASIA,CS-SBF都展现出了卓越的性能,尤其在CK+ 数据集上达到了完美的识别率。
2、高效的模块设计:通过细致的消融实验分析,表明各个模块在提取面部表情特征中的关键作用。
未来展望:
虽然CS-SBF方法已在多个标准数据集上取得了优异成绩,但在真实世界应用中,模型在极端环境下的稳定性和对不同人群的适应性仍需进一步优化。
编辑:蒼山 | 审核:世外居士
遇见春天

扫码关注
IT进阶之旅

▼
过往曾经
▼

你有在看吗↓

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)