记录大模型应用开发过程中遇到的问题
undefined 当前分组 default 下对于模型 gpt-3.5-turbo 无可用渠道 (request id: 2024100809061365160529568802677)ollama默认会开启CPU+GPU混合运行的方式来运行模型,不需要特别配置,前提是电脑上配置了显卡驱动、CUAD、cuDNN。
一、fastgpt篇
1、关联知识库报错
如果关联上知识库之后报错:
undefined 当前分组 default 下对于模型 gpt-3.5-turbo 无可用渠道 (request id: 2024100809061365160529568802677)
检查一下知识库搜索配置,在问题优化栏目,是否将模型设置为qwen:7b,如图: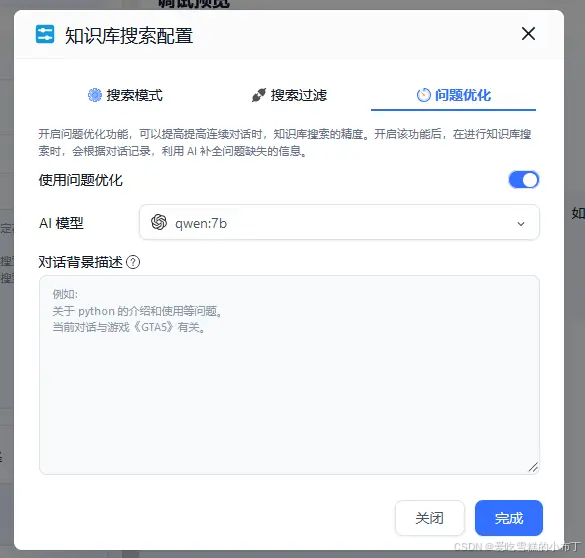
2、调用接口
调用fastgpt的openapi接口的时候,传参的方式和结构需要注意,有时候提示不存在该知识库,不是接口的问题,是传参的方式不对。
2、ollama篇
1、常用命令
下载模型:
ollama pull model_name
启动模型(若模型不存在,那么会先下载模型,然后再运行):
ollama run model_name
删除模型:
ollama rm model_name
查看下载的模型:
ollama list
查看模型信息 :
ollama show model_name
查看当前运行的模型:
ollama ps
启动模型(以qwen2:7b为例):
ollama run qwen2:7b
停止模型:
ollama stop qwen:7b
2、ollama如何使用GPU来运行模型
ollama默认会开启CPU+GPU混合运行的方式来运行模型,不需要特别配置,前提是电脑上配置了显卡驱动、CUAD、cuDNN。
3、ollama默认下载的模型都是经过量化之后的版本,如果想使用非量化的版本,只能自己手动下载模式,然后使用ollama来手动链接下载的模型,就是将模型注册到ollama的意思
4、ollama可以运行的embedding模型
ollama其实正常是不能运行嵌入模型的,只能运行大语言模型,但是有一些可以运行,如下:
ollama run mofanke/acge_text_embedding
ollama run shaw/dmeta-embedding-zh
ollama run herald/dmeta-embedding-zh
三、xinference篇
1、xinference部署文档
文档中使用的是Mac系统,如果使用Windows系统的话,需要注意,在运行xinference的时候,把命令的0.0.0.0改成127.0.0.1,否则会报错,因为windows不会识别0.0.0.0为localhost
2、xinference的模型不能运行在GPU上
我一开始就是不能将xinference下载的模型运行在GPU上,我的CUDA和cuDNN都配好了,用ollama能运行在GPU上,但是xinference不能。我偶然的解决方法是,看下面的文章:
https://zhuanlan.zhihu.com/p/718236214
只需要看安装pytorch环境那里就够了,按照对应的CUDA版本执行相应的命令,我的模型就能运行在GPU上了。
四、oneapi篇
1、oneapi不能接入重排模型
oneapi不支持接入重排模型,想要在fastgpt里面使用重排模型的话,需要在config.json中直接配置重排模型的地址,只需要修改前面的ip即可,后面的v1/rerank是标准格式。
特别注意:配置重排模型的时候,只能配置一个,因为好像不能选择使用哪个重排模型,默认选择第一个。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)