【YOLO11-MM 多模态目标检测】交叉CrossTransformerFusion特征融合、抛弃Concat、实现全局把控
本文提出了一种基于交叉注意力Transformer(CrossTransformer)的多模态目标检测框架YOLO11-MM,重点研究红外与可见光特征的深度融合策略。通过设计多层堆叠的交叉注意力编码器,实现了跨模态特征的全局交互与动态校准,在FLIR等数据集上有效提升了复杂场景下的检测性能。文章详细阐述了模块的核心思想、结构设计及工程实现方案,包括特征序列化、多头交叉注意力机制和位置编码等关键技术
摘要
本文提出了一种基于交叉注意力Transformer(CrossTransformer)的多模态目标检测框架YOLO11-MM,重点研究红外与可见光特征的深度融合策略。通过设计多层堆叠的交叉注意力编码器,实现了跨模态特征的全局交互与动态校准,在FLIR等数据集上有效提升了复杂场景下的检测性能。文章详细阐述了模块的核心思想、结构设计及工程实现方案,包括特征序列化、多头交叉注意力机制和位置编码等关键技术。实验结果表明,该方法相比传统特征拼接融合方式具有更好的性能表现,为多模态目标检测提供了一种高效可落地的解决方案。
目录
2.1、核心思想(Cross Transformer × YOLO11-MM × 多模态场景)
2.2、突出贡献(Cross Transformer 在 YOLO11-MM 中的作用)
2.3、优势特点(FLIR / M3FD / LLVIP 多数据集实战表现)
一、引言
本文围绕 YOLO11-MM 多模态目标检测框架 的结构改进与性能优化展开研究,重点探讨通过引入 Cross Transformer(交叉注意力 Transformer),实现红外(Infrared)与可见光(Visible)特征之间的高效交互与深度融合,从而提升模型在复杂场景下的目标检测鲁棒性与整体准确性。
在具体实现层面,本文系统分析了 Cross Transformer 在红外–可见光特征融合中的应用方式与插入位置,旨在探索一种兼顾性能与效率的多模态融合策略。基于多组对比实验,本文采用 中期融合(Middle Fusion) 作为主要实现方案,重点研究交叉注意力机制在多尺度特征层级中的介入时机对特征表达能力及最终检测性能的影响,使模型能够在不同语义层级上实现更加充分和有效的信息交互。
需要特别说明的是,本文实验所采用的数据集为 FLIR 数据集的子集,而非完整 FLIR 数据集。在进行实验复现或进一步扩展研究时,读者需注意数据划分与配置设置上的差异,以避免因数据规模或分布不一致而导致的结果偏差。希望本文的研究思路与工程实践经验,能够为多模态目标检测领域的研究者与工程实践者提供具有参考价值的技术借鉴与实现范式。
二、交叉注意力 (Cross Transformer)
2.1、核心思想(Cross Transformer × YOLO11-MM × 多模态场景)
在 YOLO11-MM 多模态目标检测框架中,引入 交叉注意力 Transformer(Cross Transformer) 的核心思想在于:通过显式建模红外(Infrared)与可见光(Visible)特征之间的跨模态依赖关系,实现信息互补而非简单叠加,从而提升复杂场景下的特征判别能力。
与自注意力仅在单一模态内部建模不同,Cross Transformer 采用“双路输入、双向交互”的结构设计,将红外与可见光特征分别映射为 Query / Key / Value,在多头注意力机制下完成跨模态对齐与信息重标定。结合位置编码(Positional Encoding),该模块不仅关注通道语义层面的互补关系,还能够在空间维度上对齐目标区域。在 FLIR、M3FD 和 LLVIP 等典型多模态数据集中,这种跨模态显式交互机制能够有效缓解单一模态在夜间、低照度或复杂背景下感知能力不足的问题。
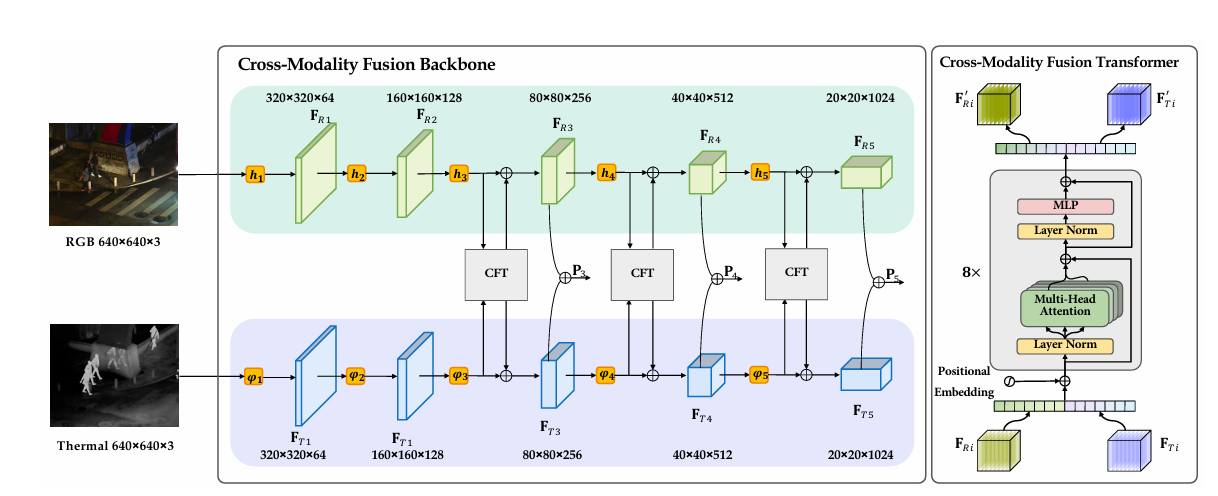
2.2、突出贡献(Cross Transformer 在 YOLO11-MM 中的作用)
Cross Transformer 在 YOLO11-MM 框架中的突出贡献,在于将多模态融合从“特征级拼接”提升为“关系级建模”,为红外–可见光目标检测提供了一种更具表达力和可解释性的融合范式。
从结构上看,该模块通过多层堆叠的交叉注意力编码器,使两种模态在多个语义层级上反复交互和校准,逐步消除模态间的语义偏差;从工程实现角度看,其模块化设计(Embedding + Positional Encoding + 多层 Cross-Attention)便于插入 YOLO11-MM 的 中期融合(Middle Fusion)阶段,在保证检测性能提升的同时,避免了在高分辨率特征层直接引入 Transformer 带来的计算爆炸问题。
2.3、优势特点(FLIR / M3FD / LLVIP 多数据集实战表现)
从多数据集实验与工程实践的角度来看,Cross Transformer 在 YOLO11-MM 框架中展现出以下几个显著优势特点。
首先,在 FLIR 数据集 上,交叉注意力机制能够抑制红外模态中的背景热噪声,并利用可见光中的几何与纹理信息进行校正,使模型在夜间与复杂光照条件下保持稳定检测性能。其次,在 M3FD 遥感多模态数据集 中,多头交叉注意力对大尺度变化与复杂场景具有更强的建模能力,有助于提升对多尺度目标的整体感知能力。再次,在 LLVIP 数据集 中,Cross Transformer 能够在低照度环境下动态调整两种模态的权重分配,使模型更加聚焦于对行人检测最有判别力的区域。
此外,相较于全局自注意力或早期全模态融合方式,Cross Transformer 在计算复杂度与性能收益之间取得了更优平衡,具备较好的工程可落地性。整体来看,该模块为 YOLO11-MM 在多模态目标检测任务中提供了一种稳定、高效且具有良好泛化能力的跨模态融合方案。
2.4 代码说明:
"""
CTF: Cross-Transformer-based fusion modules for image-image (图-图) multimodal tasks.
导出类(对外公开使用):
- CrossTransformerFusion:用于两路 [B,C,H,W] 特征的跨模态 Transformer 编码与融合,输出 [B,2C,H,W]
- MultiHeadCrossAttention:底层多头交叉注意力(序列级 [B,N,C] 输入),供高级/自定义编排使用
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import init
class MultiHeadCrossAttention(nn.Module):
"""Multi-Head Cross Attention - 多头交叉注意力机制
【核心创新】:
MultiHeadCrossAttention实现了CTF框架的核心交叉注意力机制,专门设计用于可见光和红外模态间的
深度交互。通过"独立QKV投影+交叉计算"的策略,每个模态都拥有独立的查询-键-值映射,
但注意力计算采用跨模态方式,实现了真正的跨模态信息交换。
【解决的问题】:
1. 传统注意力的单模态局限性:标准自注意力只能捕获单模态内部的依赖关系
2. 跨模态信息交互不充分:简单的特征拼接无法建立深层的跨模态依赖
3. 多头注意力的模态适配问题:需要为不同模态设计专门的注意力机制
4. 长距离跨模态依赖建模:传统卷积方法难以捕获全局的跨模态关联
【工作机制】:
1. 独立QKV投影系统:为每个模态构建专属的注意力组件
- 可见光模态:query_vis, key_vis, value_vis独立的线性投影
- 红外模态:query_inf, key_inf, value_inf独立的线性投影
- 保持模态特异性,避免不同模态特征的直接混合
2. 多头并行处理:增强表示能力的分解策略
- 将model_dim分解为num_heads个头,每头head_dim维度
- 每个头关注不同的特征子空间和交互模式
- 并行计算提高效率,多样化交互模式提高表达能力
3. 交叉注意力计算:核心的跨模态交互机制
- 可见光查询关注红外键值:Q_vis × K_inf^T → 注意力权重 → 加权V_inf
- 红外查询关注可见光键值:Q_inf × K_vis^T → 注意力权重 → 加权V_vis
- 缩放因子(head_dim^-0.5)确保注意力分数的稳定性
4. 头合并与输出投影:多头信息的整合
- 将多个头的输出拼接回完整的model_dim维度
- 通过独立的输出投影(fc_out_vis, fc_out_inf)进行最终变换
- 为每个模态提供专门的输出处理
【设计优势】:
- 跨模态对称性:两个模态都能从对方获得注意力增强
- 模态独立性:每个模态保持自己的QKV参数空间
- 多头多样性:不同头捕获不同类型的跨模态交互
- 全局建模:能够建立任意位置间的跨模态依赖关系
"""
def __init__(self, model_dim, num_heads):
super(MultiHeadCrossAttention, self).__init__()
self.num_heads = num_heads
self.head_dim = model_dim // num_heads
assert (self.head_dim * num_heads == model_dim), "model_dim must be divisible by num_heads"
# Linear maps for visual modality
self.query_vis = nn.Linear(model_dim, model_dim)
self.key_vis = nn.Linear(model_dim, model_dim)
self.value_vis = nn.Linear(model_dim, model_dim)
# Linear maps for infrared modality
self.query_inf = nn.Linear(model_dim, model_dim)
self.key_inf = nn.Linear(model_dim, model_dim)
self.value_inf = nn.Linear(model_dim, model_dim)
# Output projections
self.fc_out_vis = nn.Linear(model_dim, model_dim)
self.fc_out_inf = nn.Linear(model_dim, model_dim)
def forward(self, vis, inf):
batch_size, seq_length, model_dim = vis.shape
# Q/K/V for visual
Q_vis = self.query_vis(vis)
K_vis = self.key_vis(vis)
V_vis = self.value_vis(vis)
# Q/K/V for infrared
Q_inf = self.query_inf(inf)
K_inf = self.key_inf(inf)
V_inf = self.value_inf(inf)
# reshape for multi-head: B, N, C -> B, heads, N, head_dim
def reshape_heads(x):
return x.view(batch_size, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
Q_vis = reshape_heads(Q_vis)
K_vis = reshape_heads(K_vis)
V_vis = reshape_heads(V_vis)
Q_inf = reshape_heads(Q_inf)
K_inf = reshape_heads(K_inf)
V_inf = reshape_heads(V_inf)
# cross attention scores
scale = (self.head_dim ** -0.5)
scores_vis_inf = torch.matmul(Q_vis, K_inf.transpose(-1, -2)) * scale
scores_inf_vis = torch.matmul(Q_inf, K_vis.transpose(-1, -2)) * scale
attn_inf = torch.softmax(scores_vis_inf, dim=-1)
attn_vis = torch.softmax(scores_inf_vis, dim=-1)
out_inf = torch.matmul(attn_inf, V_inf)
out_vis = torch.matmul(attn_vis, V_vis)
# merge heads
out_vis = out_vis.transpose(1, 2).contiguous().view(batch_size, seq_length, model_dim)
out_inf = out_inf.transpose(1, 2).contiguous().view(batch_size, seq_length, model_dim)
out_vis = self.fc_out_vis(out_vis)
out_inf = self.fc_out_inf(out_inf)
return out_vis, out_inf
class FeedForward(nn.Module):
"""Feed Forward Network - 前馈网络
【核心创新】:
FeedForward实现了CTF中的position-wise前馈网络,作为Transformer架构的重要组成部分,
提供了非线性变换和特征增强能力。该模块采用经典的"扩展-压缩"结构,
在Transformer的注意力机制基础上进一步提升特征的表达能力。
【解决的问题】:
1. 注意力机制的线性局限:纯注意力机制缺乏足够的非线性变换能力
2. 特征表达能力不足:需要额外的非线性变换来增强特征表达
3. 维度变换需求:在保持输入输出维度一致的同时提供更大的参数空间
4. 过拟合控制:需要适当的正则化机制防止模型过拟合
【工作机制】:
1. 维度扩展:增加特征表达的参数空间
- 第一层线性变换:model_dim → hidden_dim
- 通常hidden_dim = 4 × model_dim,提供更大的表达空间
- 为非线性变换提供充足的参数容量
2. 非线性激活:引入非线性变换能力
- ReLU激活函数提供非线性变换
- 简单高效的激活函数,计算开销小
- 有助于模型学习复杂的特征表示
3. 正则化处理:防止过拟合的关键机制
- Dropout层进行随机失活正则化
- 在训练时随机置零部分神经元
- 提高模型的泛化能力
4. 维度压缩:恢复原始特征维度
- 第二层线性变换:hidden_dim → model_dim
- 将扩展后的特征重新映射到原始维度
- 保持与残差连接的维度一致性
【设计优势】:
- 非线性增强:为线性注意力机制补充非线性变换能力
- 参数高效:通过维度控制平衡表达能力和计算效率
- 正则化内置:Dropout提供内置的正则化能力
- 结构简洁:经典的FFN结构,易于理解和实现
"""
def __init__(self, model_dim, hidden_dim, dropout=0.1):
super(FeedForward, self).__init__()
self.fc1 = nn.Linear(model_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, model_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
class PositionalEncoding(nn.Module):
"""Positional Encoding - 位置编码
【核心创新】:
PositionalEncoding为CTF框架提供了位置感知能力,解决了Transformer架构中位置信息缺失的问题。
通过正弦余弦函数构建的位置编码,为序列中的每个位置提供独特且稳定的位置标识,
使模型能够理解和利用空间位置信息。
【解决的问题】:
1. Transformer位置无关性:纯注意力机制无法感知序列中元素的位置关系
2. 空间结构信息丢失:将2D特征图flatten为序列时丢失了空间布局信息
3. 绝对位置编码需求:需要为每个位置提供唯一的位置标识
4. 长序列泛化能力:位置编码需要能够处理不同长度的序列
【工作机制】:
1. 三角函数位置编码:经典的正弦余弦位置编码方案
- 偶数维度使用sin函数:PE(pos,2i) = sin(pos/10000^(2i/d_model))
- 奇数维度使用cos函数:PE(pos,2i+1) = cos(pos/10000^(2i/d_model))
- 不同频率的正弦余弦波为不同位置提供独特编码
2. 频率设计:多尺度位置感知
- div_term控制不同维度的频率
- 低频分量捕获长距离位置关系
- 高频分量捕获短距离位置关系
- 10000作为基数提供合适的频率范围
3. 位置编码注册:高效的缓存机制
- 将位置编码注册为buffer,不参与梯度更新
- 预计算max_len长度的位置编码矩阵
- 运行时直接索引,避免重复计算
4. 位置信息融合:加法融合策略
- 将位置编码直接加到输入特征上
- 保持特征维度不变,仅添加位置信息
- Dropout进行正则化,防止位置编码过拟合
【设计优势】:
- 位置唯一性:每个位置都有独特的编码表示
- 计算高效:预计算位置编码,运行时无需重复计算
- 泛化能力强:三角函数编码可以处理训练时未见过的位置
- 相对位置感知:三角函数的性质使模型能够学习相对位置关系
"""
def __init__(self, model_dim, dropout, max_len=6400):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, model_dim, 2) * -(torch.log(torch.tensor(10000.0)) / model_dim))
pe = torch.zeros(max_len, model_dim)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1), :]
return self.dropout(x)
class TransformerEncoderLayer(nn.Module):
"""Transformer Encoder Layer - Transformer编码层
【核心创新】:
TransformerEncoderLayer是CTF的基本处理单元,将交叉注意力机制与前馈网络整合为完整的编码层。
该模块实现了"交叉注意力→残差连接→前馈网络→残差连接"的标准Transformer架构,
专门针对多模态场景进行了优化,为深层跨模态特征学习提供基础构建块。
【解决的问题】:
1. 深层网络训练困难:深层网络容易出现梯度消失和梯度爆炸问题
2. 特征表达层次不足:单层处理无法学习复杂的特征表示
3. 多模态信息整合:需要有效整合交叉注意力和前馈网络的能力
4. 训练稳定性:需要确保深层网络的训练稳定性
【工作机制】:
1. 交叉注意力处理:跨模态信息交互的核心
- 通过MultiHeadCrossAttention进行跨模态特征交互
- 两个模态分别获得来自对方的注意力增强
- 实现深层的跨模态依赖关系建模
2. 第一次残差连接与标准化:稳定训练的关键
- 残差连接:output = input + attention_output
- LayerNorm进行标准化,稳定训练过程
- 确保梯度能够有效传播到深层网络
3. 前馈网络处理:非线性特征变换
- 通过FeedForward进行position-wise的非线性变换
- 为每个位置独立进行特征增强
- 补充注意力机制的线性变换局限
4. 第二次残差连接与标准化:完整的残差结构
- 再次进行残差连接和LayerNorm
- 形成完整的Pre-Norm Transformer结构
- 确保深层网络的训练稳定性
【设计优势】:
- 残差学习:残差连接解决深层网络训练困难问题
- 层标准化:LayerNorm提供训练稳定性和收敛速度
- 模块化设计:注意力和前馈网络的清晰分离
- 多模态适配:专门针对双模态输入进行优化
"""
def __init__(self, model_dim, num_heads, hidden_dim, dropout=0.1):
super(TransformerEncoderLayer, self).__init__()
self.cross_attention = MultiHeadCrossAttention(model_dim, num_heads)
self.norm1 = nn.LayerNorm(model_dim)
self.ff = FeedForward(model_dim, hidden_dim, dropout)
self.norm2 = nn.LayerNorm(model_dim)
def forward(self, vis, inf):
attn_out_vis, attn_out_inf = self.cross_attention(vis, inf)
vis = self.norm1(vis + attn_out_vis)
inf = self.norm1(inf + attn_out_inf)
ff_out_vis = self.ff(vis)
ff_out_inf = self.ff(inf)
vis = self.norm2(vis + ff_out_vis)
inf = self.norm2(inf + ff_out_inf)
return vis, inf
class TransformerEncoder(nn.Module):
"""Transformer Encoder - Transformer编码器
【核心创新】:
TransformerEncoder构建了完整的多层Transformer编码体系,整合了特征嵌入、位置编码和多层编码处理。
作为CTF的核心组件,该模块实现了从原始特征到深层跨模态表示的端到端学习,
通过多层堆叠实现了复杂的跨模态特征学习和表示能力。
【解决的问题】:
1. 浅层特征表示局限:单层处理无法学习复杂的跨模态表示
2. 输入维度适配问题:输入特征维度与模型内部维度可能不一致
3. 特征缩放问题:需要适当的特征缩放保证训练稳定性
4. 深层特征学习:需要通过多层堆叠学习层次化的特征表示
【工作机制】:
1. 特征嵌入与缩放:输入特征的预处理
- 线性嵌入层将input_dim映射到model_dim
- 特征缩放:乘以sqrt(model_dim)进行缩放
- Xavier初始化的变体,有助于训练稳定性
- 为不同维度的输入提供统一的表示空间
2. 位置编码注入:空间位置信息的引入
- 通过PositionalEncoding添加位置信息
- 使模型能够理解序列中的位置关系
- 弥补注意力机制位置无关性的不足
3. 多层编码处理:深层特征学习的核心
- 通过num_layers个TransformerEncoderLayer进行堆叠
- 每层都进行跨模态交叉注意力和前馈处理
- 逐层学习更抽象和复杂的跨模态表示
- 深层网络捕获更复杂的特征依赖关系
4. 端到端学习:统一的特征学习框架
- 整个编码器支持端到端的梯度传播
- 所有组件联合优化,学习最优的特征表示
- 为多模态融合任务提供高质量的特征表示
【设计优势】:
- 深层学习:多层堆叠实现复杂特征学习
- 维度灵活:支持不同输入维度到统一表示空间的映射
- 位置感知:内置位置编码提供空间感知能力
- 端到端优化:整个编码器支持联合优化学习
"""
def __init__(self, input_dim, model_dim, num_heads, num_layers, hidden_dim, dropout=0.1):
super(TransformerEncoder, self).__init__()
self.embedding = nn.Linear(input_dim, model_dim)
self.positional_encoding = PositionalEncoding(model_dim, dropout)
self.layers = nn.ModuleList([
TransformerEncoderLayer(model_dim, num_heads, hidden_dim, dropout) for _ in range(num_layers)
])
def forward(self, vis, inf):
vis = self.embedding(vis) * torch.sqrt(torch.tensor(self.embedding.out_features, dtype=torch.float32))
inf = self.embedding(inf) * torch.sqrt(torch.tensor(self.embedding.out_features, dtype=torch.float32))
vis = self.positional_encoding(vis)
inf = self.positional_encoding(inf)
for layer in self.layers:
vis, inf = layer(vis, inf)
return vis, inf
class CrossTransformerFusion(nn.Module):
"""Cross-Transformer Fusion - 跨模态Transformer融合
【核心创新】:
CrossTransformerFusion是CTF框架的顶层融合组件,实现了完整的"2D→序列→Transformer→2D→拼接"融合流程。
该模块创新性地将2D卷积特征图转换为序列,利用Transformer的全局建模能力进行跨模态交互,
再将增强后的序列特征重构为2D特征图并拼接,为多模态目标检测提供高质量的融合特征。
【解决的问题】:
1. 卷积特征的局部性限制:传统卷积操作只能捕获局部特征关系
2. 多模态全局交互不足:缺乏有效机制建立全局的跨模态依赖关系
3. 2D与序列处理的转换:需要在2D空间特征与1D序列特征间有效转换
4. 特征融合的深度不足:传统融合方法缺乏足够的深度和复杂性
【工作机制】:
1. 2D到序列的转换:空间特征的序列化
- 将输入的[B,C,H,W]特征图重塑为[B,H×W,C]序列
- permute操作调整维度顺序:(B,C,H,W)→(B,H,W,C)→(B,N,C)
- 将每个空间位置看作序列中的一个token
- 为Transformer处理准备标准的序列输入格式
2. 跨模态Transformer编码:深度特征交互
- 通过TransformerEncoder进行多层跨模态特征学习
- 每个空间位置都能与其他所有位置进行跨模态交互
- 建立全局的跨模态依赖关系和特征增强
- 充分利用Transformer的长距离建模能力
3. 序列到2D的重构:空间结构的恢复
- 将Transformer输出的[B,N,C]序列重构为[B,H,W,C]
- 再次permute恢复为[B,C,H,W]的标准特征图格式
- 保持原始的空间分辨率和结构信息
- 为后续卷积操作提供标准输入格式
4. 通道级特征拼接:多模态信息整合
- 将两个模态的增强特征在通道维度拼接
- 输出维度从[B,C,H,W]扩展到[B,2C,H,W]
- 包含两个模态的完整信息和交互增强结果
- 为后续网络层提供丰富的融合特征表示
【设计优势】:
- 全局建模:Transformer提供全局的跨模态交互能力
- 深度融合:多层处理实现深层的特征融合
- 结构保持:维持原始特征图的空间结构信息
- 灵活适配:可以处理任意分辨率的输入特征图
"""
def __init__(self, input_dim, num_heads=2, num_layers=1, dropout=0.1):
super(CrossTransformerFusion, self).__init__()
self.hidden_dim = input_dim * 2
self.model_dim = input_dim
self.encoder = TransformerEncoder(input_dim, self.model_dim, num_heads, num_layers, self.hidden_dim, dropout)
def forward(self, x):
vis, inf = x[0], x[1]
B, C, H, W = vis.shape
vis = vis.permute(0, 2, 3, 1).reshape(B, -1, C)
inf = inf.permute(0, 2, 3, 1).reshape(B, -1, C)
vis_out, inf_out = self.encoder(vis, inf)
vis_out = vis_out.view(B, H, W, -1).permute(0, 3, 1, 2)
inf_out = inf_out.view(B, H, W, -1).permute(0, 3, 1, 2)
out = torch.cat((vis_out, inf_out), dim=1)
return out
三、逐步手把手添加Cross Transformer
3.1 第一步
在 ultralytics/nn 目录下面,新建一个叫 fusion的文件夹,然后在里面分别新建一个.py 文件,把注意力模块的“核心代码”粘进去。
注意🔸 如果你使用我完整的项目代码,这个 fusion文件夹已经有了、里面的模块也是有的,直接使用进行训练和测试,如果没有你只需要在里面新建一个 py 文件或直接修改已有的即可,如下图所示。
3.2 第二步
第二步:在该目录下新建一个名为 __init__.py 的 Python 文件(如果使用的是我项目提供的工程,该文件一般已经存在,无需重复创建),然后在该文件中导入我们自定义的注意力EMA,具体写法如下图所示。
3.3 第三步
第三步:找到 ultralytics/nn/tasks.py 文件,在其中完成我们模块的导入和注册(如果使用的是我提供的项目工程,该文件已自带,无需新建)。具体书写方式如下图所示
3.4 第四步
第四步:找到 ultralytics/nn/tasks.py 文件,在 parse_model 方法中加入对应配置即可,具体书写方式如下图所示。
elif m in frozenset({CrossTransformerFusion, MultiHeadCrossAttention}):
c2, args = _parse_two_input_equal_attn(m, f, args, ch, i)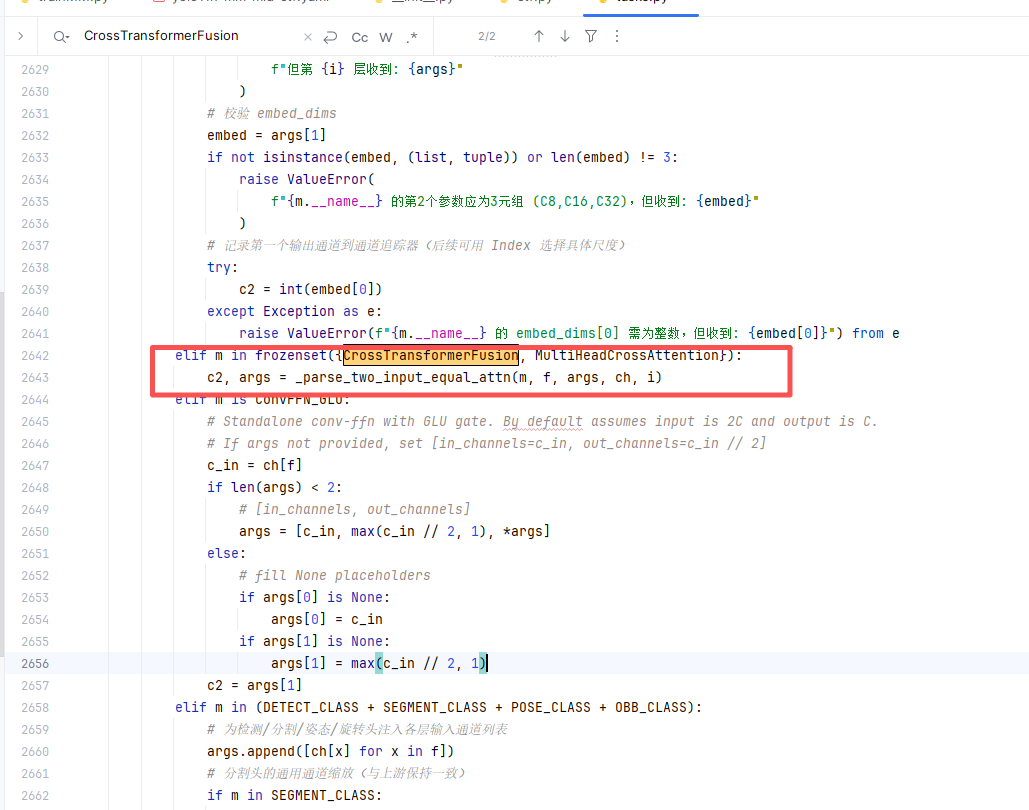
四 完整yaml
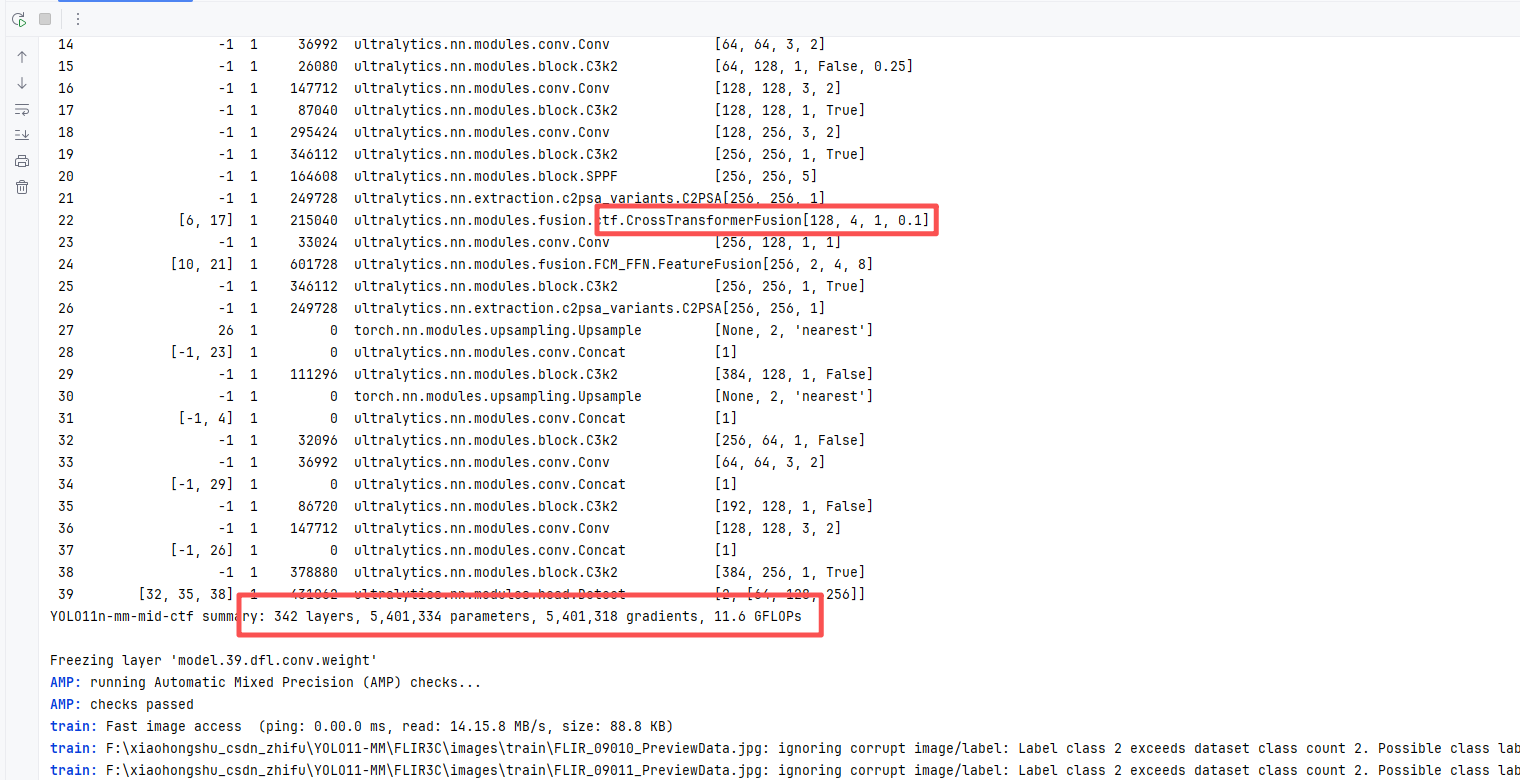
训练信息:summary: 342 layers, 5,401,334 parameters, 5,401,318 gradients, 11.6 GFLOPs
# Ultralytics YOLOMM 🚀 Mid-Fusion (CTF Test)
# 目的:在中层特征(P4/P5)验证 CrossTransformerFusion 的跨模态交互能力
# 备注:CTF 输出为 2C(通道拼接),此处在 P4 侧用 1x1 Conv 压回到原通道数,便于与后续 FPN/Detect 对齐。
nc: 80
scales:
# [depth, width, max_channels]
n: [0.50, 0.25, 1024]
s: [0.50, 0.50, 1024]
m: [0.50, 1.00, 512]
l: [1.00, 1.00, 512]
x: [1.00, 1.50, 512]
backbone:
# ========== RGB路径 (层0-10) ==========
- [-1, 1, Conv, [64, 3, 2], 'RGB'] # 0-P1/2 RGB起始
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]] # 2
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 (RGB_P3)
- [-1, 2, C3k2, [512, False, 0.25]] # 4
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]] # 6 (RGB_P4)
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]] # 8
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10 (RGB_P5)
# ========== X路径 (层11-21) ==========
- [-1, 1, Conv, [64, 3, 2], 'X'] # 11-P1/2 X起始
- [-1, 1, Conv, [128, 3, 2]] # 12-P2/4
- [-1, 2, C3k2, [256, False, 0.25]] # 13
- [-1, 1, Conv, [256, 3, 2]] # 14-P3/8 (X_P3)
- [-1, 2, C3k2, [512, False, 0.25]] # 15
- [-1, 1, Conv, [512, 3, 2]] # 16-P4/16
- [-1, 2, C3k2, [512, True]] # 17 (X_P4)
- [-1, 1, Conv, [1024, 3, 2]] # 18-P5/32
- [-1, 2, C3k2, [1024, True]] # 19
- [-1, 1, SPPF, [1024, 5]] # 20
- [-1, 2, C2PSA, [1024]] # 21 (X_P5)
# ========== P4/P5 融合 ==========
# P4: 使用 CTF(跨模态Transformer编码)→ 输出2C → 1x1压回原通道
- [[6, 17], 1, CrossTransformerFusion, [null, 4, 1, 0.1]] # 22: dim自动=左支C, heads=4, layers=1
- [-1, 1, Conv, [512, 1, 1]] # 23: Fused_P4
# P5: 保持参考模板的 FeatureFusion,隔离变量便于对比
- [[10, 21], 1, FeatureFusion, [null, 2, 4, 8]] # 24
- [-1, 2, C3k2, [1024, True]] # 25
- [-1, 1, C2PSA, [1024]] # 26 (Fused_P5)
head:
# 自顶向下路径 (FPN)
- [26, 1, nn.Upsample, [None, 2, "nearest"]] # 27 Fused_P5 上采样
- [[-1, 23], 1, Concat, [1]] # 28 + Fused_P4
- [-1, 2, C3k2, [512, False]] # 29
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 30
- [[-1, 4], 1, Concat, [1]] # 31 + RGB_P3(4)
- [-1, 2, C3k2, [256, False]] # 32 (P3/8)
# 自底向上路径 (PAN)
- [-1, 1, Conv, [256, 3, 2]] # 33
- [[-1, 29], 1, Concat, [1]] # 34
- [-1, 2, C3k2, [512, False]] # 35 (P4/16)
- [-1, 1, Conv, [512, 3, 2]] # 36
- [[-1, 26], 1, Concat, [1]] # 37
- [-1, 2, C3k2, [1024, True]] # 38 (P5/32)
- [[32, 35, 38], 1, Detect, [nc]] # 39 Detect(P3, P4, P5)
五 训练代码和结果
5.1 模型训练代码
import warnings
from ultralytics import YOLOMM
# 1. 可选:屏蔽 timm 的未来弃用警告(不影响训练,仅减少控制台噪音)
warnings.filterwarnings(
"ignore",
category=FutureWarning,
message="Importing from timm.models.layers is deprecated, please import via timm.layers"
)
if __name__ == "__main__":
# 2. 加载多模态模型配置(RGB + IR)
# 这里使用官方提供的 yolo11n-mm-mid 配置,你也可以换成自己的 yaml
model = YOLOMM("ultralytics/cfg/models/FFT/yolo11n-mm-mid-ctf.yaml")
# 3. 启动训练
model.train(
data="FLIR3C/data.yaml", # 多模态数据集配置(上一节已经编写)
epochs=10, # 训练轮数,实际实验中建议 100+ 起步
batch=4, # batch size,可根据显存大小调整
imgsz=640, # 输入分辨率(默认 640),可与数据集分辨率统一
device=0, # 指定 GPU id,CPU 训练可写 "cpu"
workers=4, # dataloader 线程数(Windows 一般 0~4 比较稳)
project="runs/mm_exp", # 训练结果保存根目录
name="rtdetrmm_flir3c", # 当前实验名,对应子目录名
# resume=True, # 如需从中断的训练继续,可打开此项
# patience=30, # 早停策略,连降若干轮 mAP 不提升则停止
# modality="X", # 模态消融参数(默认由 data.yaml 中的 modality_used 决定)
# cache=True, # 启用图片缓存,加快 IO(内存足够时可打开)
)
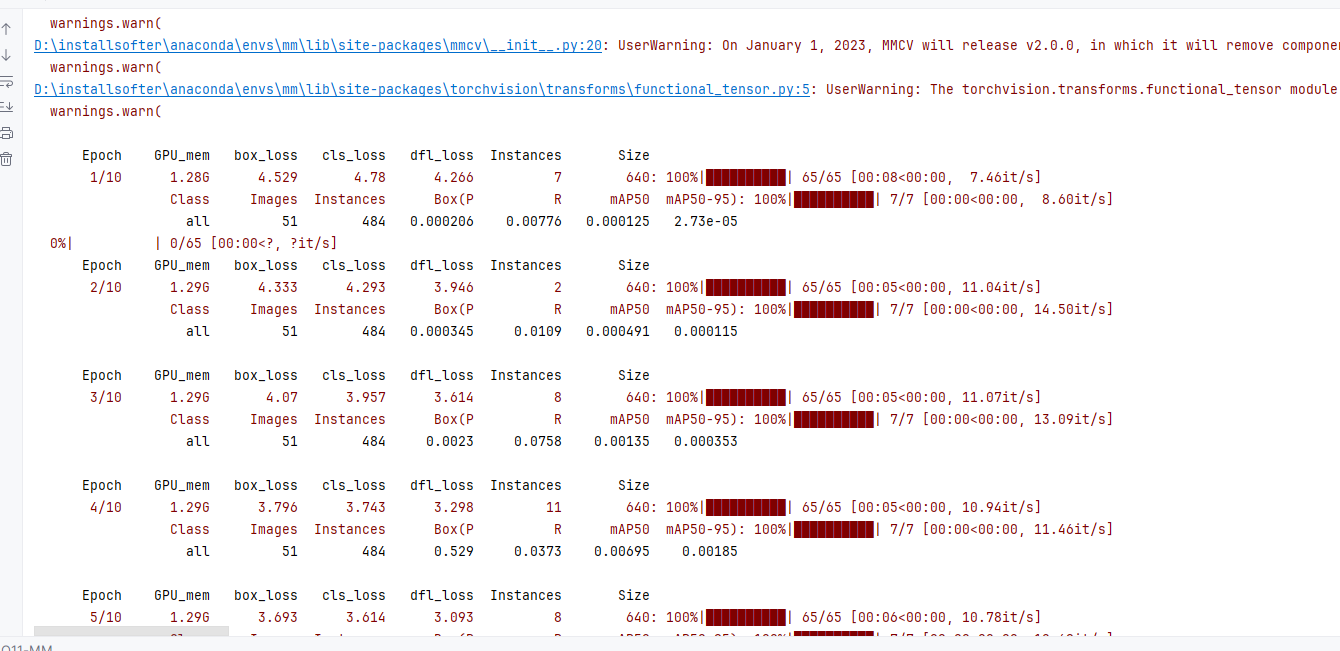
5.2 模型训练结果

六 总结
到这里,本文的正式内容就告一段落啦。
最后也想郑重向大家推荐我的专栏 「YOLO11-MM 多模态目标检测」。目前专栏整体以实战为主,每一篇都是我亲自上手验证后的经验沉淀。后续我也会持续跟进最新顶会的前沿工作进行论文复现,并对一些经典方法及改进机制做系统梳理和补充。
✨如果这篇文章对你哪怕只有一丝帮助,欢迎订阅本专栏、关注我,并私信联系,我会拉你进入 「YOLO11-MM 多模态目标检测」技术交流群 QQ 群~
你的支持,就是我持续输出的最大动力!✨

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 16
16 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)