CVPR 2025|XLRS-Bench:你的多模态大语言模型能否理解超大尺寸超高分辨率遥感影像?
多模态大语言模型(MLLMs)的突破性进展,亟需新基准定量评估其能力、揭示局限并指明研究方向。但在遥感(RS)领域,因遥感影像超高分辨率、语义关联复杂,现有基准存在图像尺寸远小于真实场景、标注质量有限、评估维度不全等问题,评估面临挑战。为此,本文提出综合基准 XLRS-Bench,用于评估 MLLMs 在超高分辨率遥感场景的感知与推理能力。其拥有已知最大平均图像尺寸(8500×8500 像素),样

论文地址:https://arxiv.org/pdf/2503.23771
文章目录
一、论文信息
- 题目:XLRS-Bench: Could Your Multimodal LLMs Understand Extremely Large UItra-High-Resolution Remote Sensing Imagery?
- 作者:Fengxiang Wang, Hongzhen Wang2,Zonghao Guo,Di Wang, Yulin Wang,Mingshuo Chen,Qiang Ma, Long Lan,Wenjing Yang,Jing Zhang3, Zhiyuan Liu,Maosong Sun
- 单位:College of Computer Science and Technology, National University of Defense Technology, China
Tsinghua University, China
School of Computer Science, Wuhan University, China
Beijing University of Posts and Telecommunications, China
Zhongguancun Academy, China
School of Artificial Intelligence, Wuhan University, China - 会议:CVPR 2025(IEEE/CVF 计算机视觉与模式识别会议)
- 代码地址:https://xlrs-bench.github.io/
二、论文摘要
多模态大语言模型(MLLMs)的突破性进展,亟需新基准定量评估其能力、揭示局限并指明研究方向。但在遥感(RS)领域,因遥感影像超高分辨率、语义关联复杂,现有基准存在图像尺寸远小于真实场景、标注质量有限、评估维度不全等问题,评估面临挑战。
为此,本文提出综合基准 XLRS-Bench,用于评估 MLLMs 在超高分辨率遥感场景的感知与推理能力。其拥有已知最大平均图像尺寸(8500×8500 像素),样本经人工精心标注并辅以新型半自动描述生成器。该基准含 16 个子任务,覆盖 10 种感知能力与 6 种推理能力,聚焦真实世界决策及时空变化捕捉相关的高级认知过程。评估显示,通用及遥感专用 MLLMs 在实际遥感应用中仍需优化,XLRS-Bench 已开源,助力更强遥感领域 MLLMs 研发。
三、论文创新点
XLRS-Bench 基准
XLRS-Bench 基准用于评估 MLLMs 在超高分辨率遥感场景下 16 个子任务的感知与推理能力。
XLRS-Bench 基准的构建及典型示例
我们首先收集了 1400 幅真实世界的超高分辨率遥感影像,平均尺寸达 8500×8500 像素,其中 530 幅来自检测数据集(从 DOTA-v2选取 270 幅 4096×4096 像素影像和 210 幅 7360×4912 像素影像,从 ITCVD选取 50 幅 3744×5616 像素影像),500 幅来自分割数据集(从 MiniFrance 选取 457 幅 10000×10000 像素影像,从 Toronto 选取 13 幅 11500×7500 像素影像,从 Potsdam 选取 30 幅 6000×6000 像素影像),370幅来自变化检测任务(从 HRSCD 选取 185 组(370 幅)10000×10000 像素影像)。研究表明,基于 GPT 的工具可能会在基准中引入偏差,导致同类模型表现虚高,影响基准的严谨性与真实场景评估能力。为解决这一问题,本文由经过培训的标注人员纯人工扩充问题集,未借助 GPT 工具;同时,为最大限度减少设计偏差,采用交叉验证机制并组建外部评审团队:3 个标注组(每组 15 人)相互交叉验证,10 名具备多模态大语言模型(MLLMs)研究经验的专家组成评审团队,负责解决争议问题并验证题目设计合理性,确保所有问题均能真实评估模型能力。最终,XLRS-Bench 包含 45,942 条标注,覆盖 10 项感知能力指标和 6 项推理能力指标,其中包括 32,389 个问答对、12,619 个视觉定位样本和 934 条详细图像描述。
除定位和描述类任务外,其余各级能力对应的视觉问答对均采用多选题形式构建。每个问答对 P i = ( Q i , C i , I i , T i ) P_i=(Q_i, C_i, I_i, T_i) Pi=(Qi,Ci,Ii,Ti) 包含:问题 Q i Q_i Qi、选项集合 C i C_i Ci(2≤n≤4 个选项)、关联影像 I i I_i Ii 及正确答案 T i T_i Ti 。
XLRS-Bench评估视觉定位能力时,为每个目标精心设计参考语句,通过颜色、形状、位置、尺寸、相对空间属性等独特特征,确保目标可被独立精准识别;在 “基于条件的视觉定位” 任务中,标注人员利用影像细节设计包含状态约束、地理细节等的具体条件描述。所有视觉定位标注均由视觉问答(VQA)组的标注与质控团队完成,全程保障人工标注的高质量。
对于描述类任务,本文采用半自动流程生成影像的文本标注。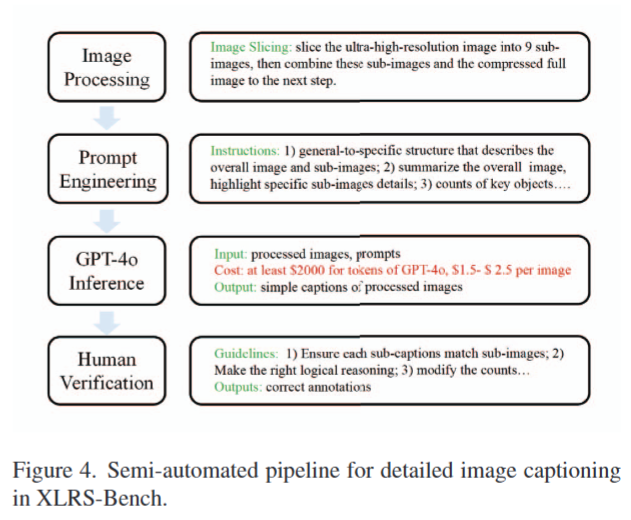
- 图像处理(Image Processing):将超高分辨率影像切分为 9 个子影像,再结合压缩后的整幅影像,作为后续输入。
- 提示词工程(Prompt Engineering):设计提示词,要求描述遵循 “从整体到局部” 的结构,既要概述整幅影像,也要突出子影像细节,同时统计关键目标数量。
- GPT-4o 推理(GPT-4o Inference):输入处理后的影像与提示词,生成初步描述;成本较高(1000 幅影像需超 2000 美元,单幅约 1.5-2.5 美元)。
- 人工验证(Human Verification):人工校准描述,确保子影像描述与内容匹配、逻辑推理正确、目标计数准确,最终得到正确标注。
该流程兼顾了 GPT 的效率与人工的准确性,解决了超高分辨率影像描述的细节丢失与质量问题。
下图为XLRS-Bench 基准的典型示例。
- Overall Land Use Classification(全局土地利用分类)
Q(英文):Select some overall Land Use Classification that best represent types of land use in the picture. Make sure to include all types present in the image.
Q(中文):选择最能代表图中土地利用类型的全局土地利用分类,确保涵盖图中所有存在的类型。
选项:
A: Highway(公路)
B: Single-unit residential building(独栋住宅建筑)
C: Multi-unit residential building(多单元住宅建筑)
D: Dock(码头)
2.Recognitional Land Use Classification(局部土地利用分类)
Q(英文):Select the land type for the area circled in red in the image.
Q(中文):选择图中红色圈出区域的土地类型。
选项:
A: Single-unit residential building(独栋住宅建筑)
B: Shopping center(购物中心)
C: Interchange(立交桥)
D: Impoverished residential area(贫困住宅区)
3.Anomaly Detection(异常检测)
Q(英文):How is the state of the river in the picture? Is there any congestion or flooding occurring?
Q(中文):图中河流的状态如何?是否出现拥堵或泛滥情况?
选项:
A: Yes, due to the large number of boats on it, it has caused congestion in the river.(是,因河上船只数量多,导致河流拥堵)
B: No, there aren’t many boats on the river now and the traffic is very smooth.(否,当前河上船只不多,通行非常顺畅)
4.Environmental Condition Reasoning(环境条件推理)
Q(英文):Based on satellite imagery, this area is already relatively developed. Can leisure facilities such as a sports field or a children’s playground be added?
Q(中文):基于卫星影像,该区域已相对发达,能否新增运动场或儿童游乐场等休闲设施?
选项:
A: Leisure facilities, sports fields, or children’s playgrounds can be added in a larger open space, providing good place for local residents to relax and entertain themselves.(可在较大开放空间新增休闲设施、运动场或儿童游乐场,为当地居民提供放松娱乐的场所)
5.Object Classification(目标分类)
Q(英文):Identify the object category within a given reference bounding box from satellite and aerial imagery. bounding box:[433, 868, 236, 255]
Q(中文):从卫星与航空影像中,识别给定参考边界框内的目标类别。bounding box:[433, 868, 236, 255]
选项:
A: White Parking Lot(白色停车场)
B: Green Grassland(绿色草地)
C: Green Roofed Boat(绿色屋顶船只)
D: White Roof(白色屋顶)
6.Counting with Complex Reasoning(复杂推理计数)
Q(英文):How many groups of containers are there on the dock in the top left corner of the picture?
Q(中文):图左上角码头区域有多少组集装箱?
选项:
A: Ten(十组)
B: Eleven(十一组)
C: Twelve(十二组)
D: Thirteen(十三组)
7.Object Color(目标颜色)
Q(英文):Determine the color of an object based on a given reference boundary box. bounding box:[726,1976,1764,1831]
Q(中文):基于给定参考边界框,判断物体的颜色。bounding box:[726,1976,1764,1831]
选项:
A: Blue(蓝色)
B: Green(绿色)
C: Red(红色)
D: Yellow(黄色)
8.Condition-based Visual Grounding(基于条件的视觉定位)
Q(英文):The transport ship docked next to the pier with numerous containers.
Q(中文):停靠在集装箱密集码头旁的运输船。
选项:
A: <1709> <1040> <2345> <1300>(对应影像内的定位坐标)
9.Object Motion State(目标运动状态)
Q(英文):Determine whether an object is in motion based on a given reference bounding box. bounding box:[769, 3650, 873, 3276]
Q(中文):基于给定参考边界框,判断物体是否处于运动状态。bounding box:[769, 3650, 873, 3276]
选项:
A: Yes(是)
B: No(否)
10.Overall Counting(全局计数)
Q(英文):How many boats are there in the entire picture?
Q(中文):整张图中有多少艘船只?
选项:
A: Forty-Six(四十六艘)
B: Forty-Seven(四十七艘)
C: Forty-Eight(四十八艘)
D: Forty-Nine(四十九艘)
11.Object Spatial Relationship(目标空间关系)
Q(英文):Where is the white house in the middle of the picture located relative to the boat that is sailing in the middle of the river?
Q(中文):图中间的白色房屋相对于河中航行的船只,位于哪个位置?
选项:
A: upper right(右上方)
B: upper left(左上方)
C: lower right(右下方)
D: below(下方)
12.Fine-grained Visual Grounding(细粒度视觉定位)
Q(英文):Many red-roofed houses clustered together surrounded by tall buildings in the bottom right corner of the picture.
Q(中文):图右下角区域中,多座红顶房屋聚集,且周围是高层建筑。
选项:
A: [2857, 3352, 3074, 3538](对应影像内的定位坐标)
13.Regional Counting(区域计数)
Q(英文):How many boats are there in the circled area of the picture?
Q(中文):图中圈出区域内有多少艘船只?
选项:
A: Thirty-Five(三十五艘)
B: Thirty-Six(三十六艘)
C: Thirty-Seven(三十七艘)
D: Thirty-Eight(三十八艘)
14.Route Planning(路径规划)
Q(英文):In the image. What is the best route from the green ship in the top-left corner of the image to the white warehouse in the middle of the image?
Q(中文):在图中,从左上角的绿色船只到图中间的白色仓库,最佳路线是什么?
选项:
A: Starting from the white warehouse at the dock next to the green ship, follow the path down to the right. When you encounter the blue tower, continue downwards along the road and pass through an intersection, and you will arrive at the white warehouse in the middle of the image.(从绿色船只旁码头的白色仓库出发,沿路径向右下方行进;遇到蓝色塔楼后,沿道路继续向下,穿过一个十字路口,即可到达图中间的白色仓库)
XLRS-Bench 基准的核心优势
与现有基准相比,XLRS-Bench 的核心优势包括:
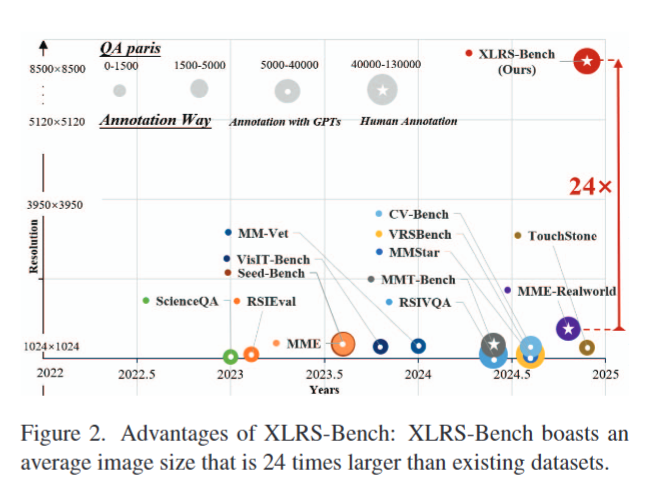
- 超高分辨率:拥有目前最大的图像尺寸,是现有数据集的 10-20 倍,平均图像尺寸达 8500×8500 像素,其中 840 幅影像分辨率达 10,000×10,000 像素;
- 高质量标注:所有标注均有人工参与并经多轮人工验证,为评估 MLLMs 在真实超高分辨率遥感场景下的性能提供了高质量基准;
- 全面的评估维度:涵盖 10 项感知指标和 6 项推理维度,包含 16 个子任务及 45,942 个问题,尤其纳入了复杂推理任务,以探究 MLLMs 在长时空遥感场景中进行规划和变化检测的潜力。且支持双语评估,可检验视觉语言模型(VLMs)在英语和中文环境下的性能。
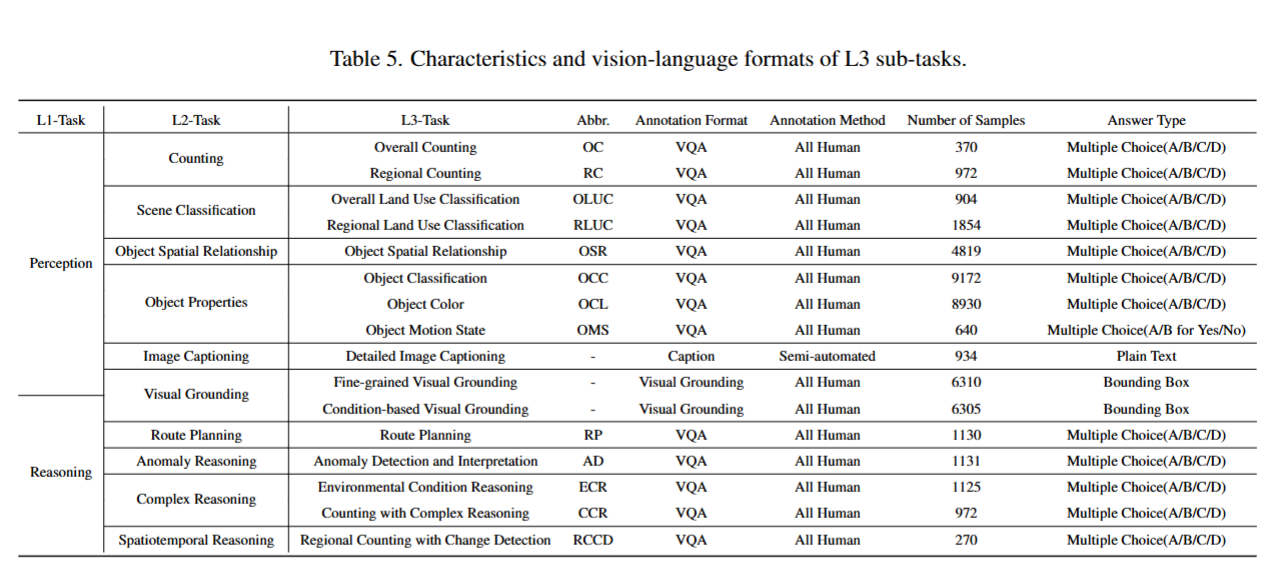
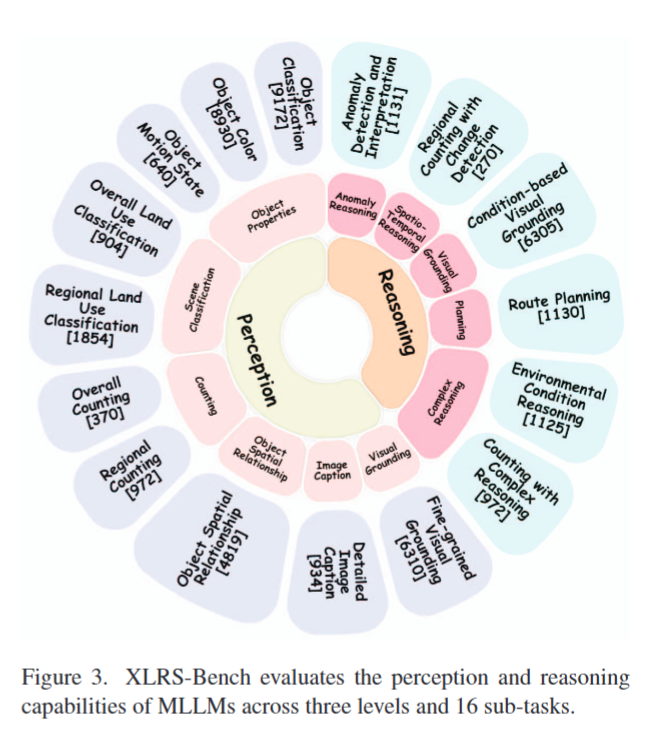
XLRS-Bench 基准的评估维度
Perception(感知能力)
- Scene Classification(场景分类):包含 “Overall Land Use Classification(全局土地利用分类,904 个样本)”“Regional Land Use Classification(区域土地利用分类,1854 个样本)”;
- Counting(计数):包含 “Overall Counting(全局计数,370 个样本)”“Regional Counting(区域计数,972 个样本)”;
- Object Properties(目标属性):包含 “Object Classification(目标分类,19172 个样本)”“Object Color(目标颜色,18930 个样本)”“Object Motion State(目标运动状态,640 个样本)”;
- Object Spatial Relationship(目标空间关系,1897 个样本);
- Visual Grounding(视觉定位):包含 “Detailed Image Caption(详细图像描述,834 个样本)”。
Reasoning(推理能力)
- Complex Reasoning(复杂推理):包含 “Environmental Condition Reasoning(环境条件推理,1125 个样本)”“Counting with Complex Reasoning(带复杂推理的计数,972 个样本)”;
- Planning(规划):包含 “Route Planning(路径规划,1130 个样本)”;
- Visual Grounding(视觉定位):包含 “Fine-grained Visual Grounding(细粒度视觉定位,16310 个样本)”“Conditional-based Visual Grounding(基于条件的视觉定位,6305 个样本)”;
- Spatio-Temporal Reasoning(时空推理):包含 “Regional Counting with Change Detection(带变化检测的区域计数,270 个样本)”;
- Anomaly Reasoning(异常推理):包含 “Anomaly Detection and Interpretation(异常检测与解读,1313 个样本)”。
四、论文动机
遥感(RS)影像已成为监测和理解人类生存环境的关键工具,推动了精准农业、城市规划、灾害评估等领域的应用发展。因此,评估 MLLMs 在该领域的性能具有重要意义。然而,遥感影像的高分辨率与复杂语义关联,使得在真实遥感场景下评估 MLLMs 极具挑战性。尽管近期已有研究提出了用于评估遥感领域 MLLM 性能的基准和指标,但这些成果在图像尺寸、人工标注、评估维度三个核心方面仍存在局限。
五、实验分析
实验设置
- 评估模型分类:涵盖三类多模态大语言模型(MLLMs),包括 Qwen2-VL、LLava-Onevision 等 7 款开源视觉语言模型(VLMs),GPT-4o、GPT-4o-mini 两款闭源模型,以及遥感专用模型 GeoChat。
- 实验条件:所有模型采用零样本设置与统一提示词,保证对比公平性;GeoChat 通过原生框架评估,其余模型均使用 LMMs-Eval 工具;附录补充开源模型架构、参数规模及额外实验结果。
评估策略
- 视觉问答(VQA)任务
每个问题设 1 个正确答案和 3 个干扰项(源自图像文本或相似内容),提升任务难度。评估二级(L-2)能力维度准确率并报告平均值,三级(L-3)结果见主要实验结果;“全局土地利用分类” 任务需预测结果与真实标签完全一致才判定正确。 - 视觉定位任务
以精确率为评估指标,基于预测边界框与真实边界框的交并比(IoU)判定,设置 0.5 和 0.7 两个阈值。 - 图像描述任务
采用 BLEU(1-4 gram)、ROUGE L、METEOR 等标准指标,所有分数以百分比形式呈现。
主要实验结果
- 视觉问答(VQA)任务
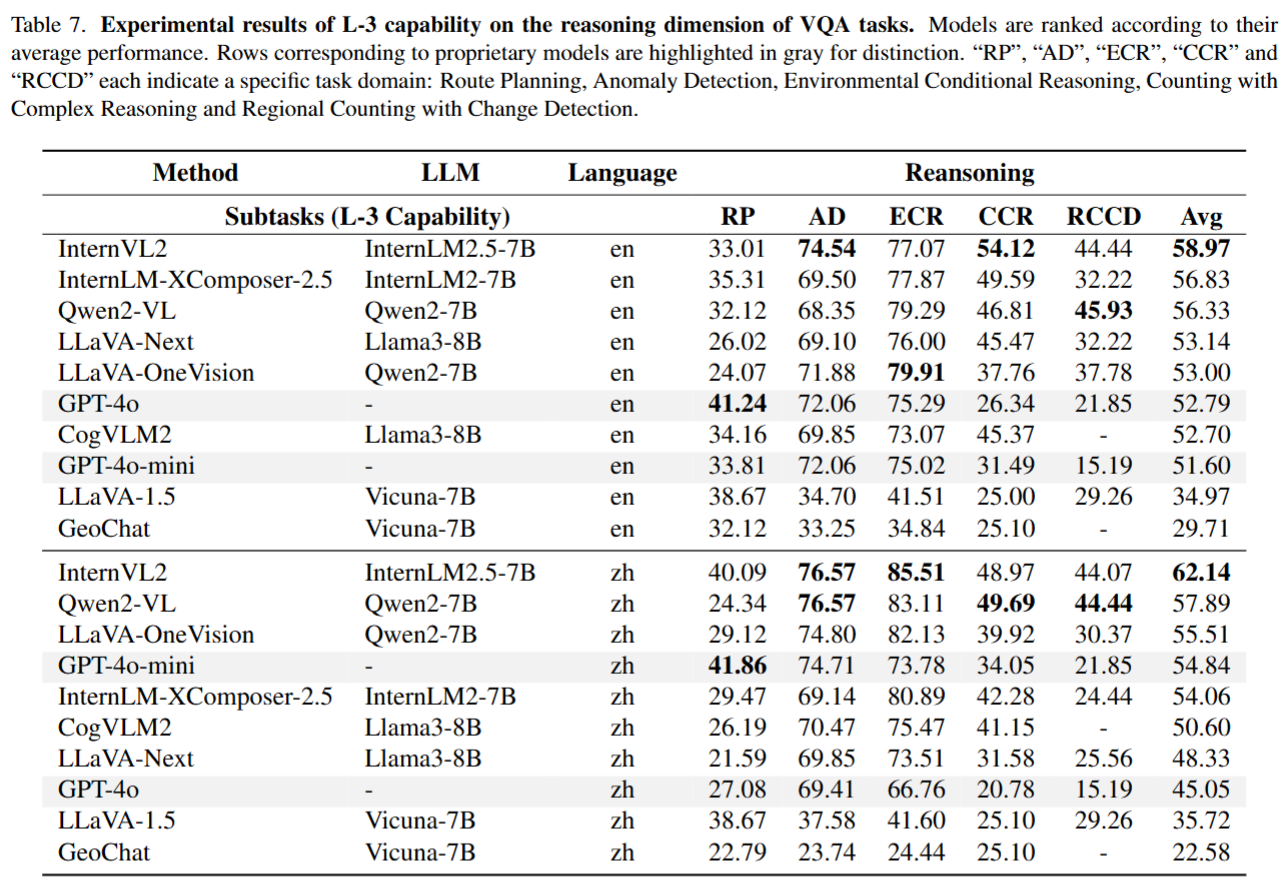
Qwen2-VL 在中英文任务中表现最优,优于多数开源模型和专有模型。
关键发现:GPT-4o 在时空推理任务中准确率低于 25%,缺乏遥感场景变化检测预训练;支持高分辨率输入的模型(如 Qwen2-VL)性能远超依赖 CLIP 编码器的模型;模型在抽象推理任务(如异常检测)中表现较好,感知密集型任务准确率仅 30%-50%。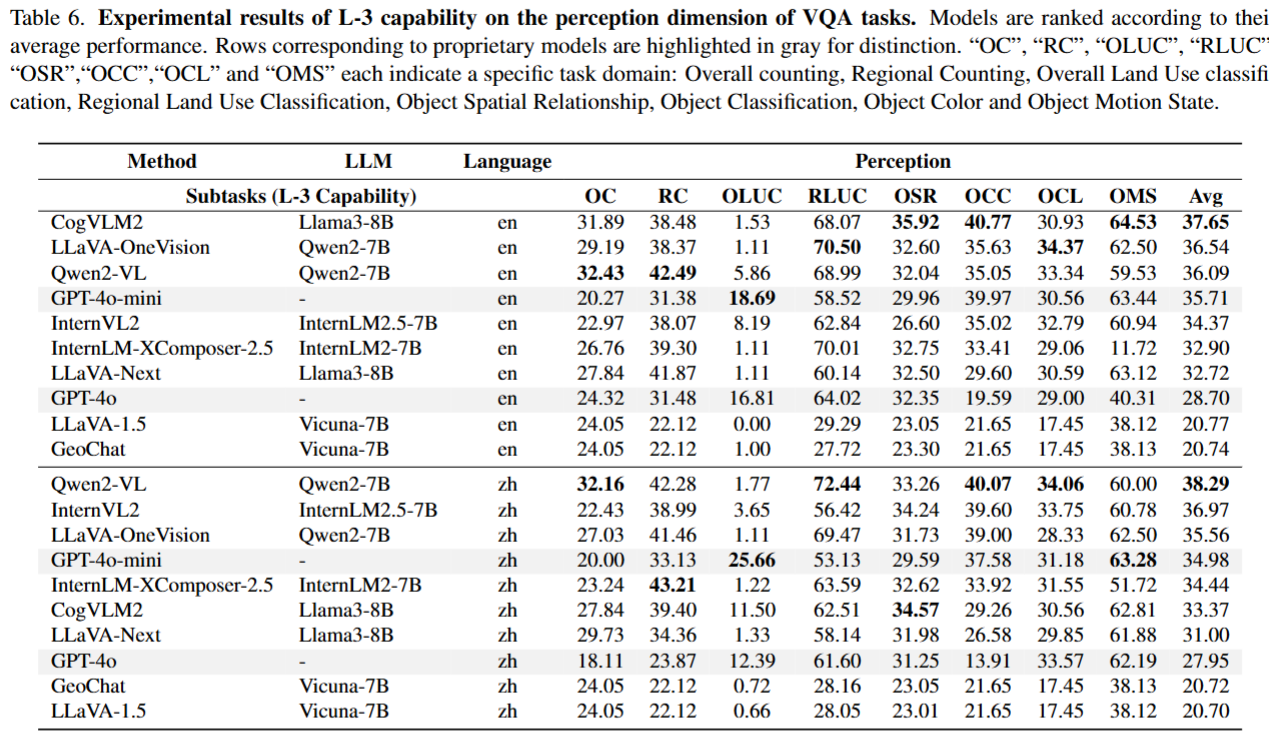
- 视觉定位任务
所有模型表现糟糕,8500×8500 分辨率下,交并比IoU=0.5 时准确率仅 3.2%,IoU=0.7 时仅 0.48%。
人工验证显示人类准确率超 90%,模型困境源于大尺寸图像中部分目标仅 5-10 像素,现有模型难以处理。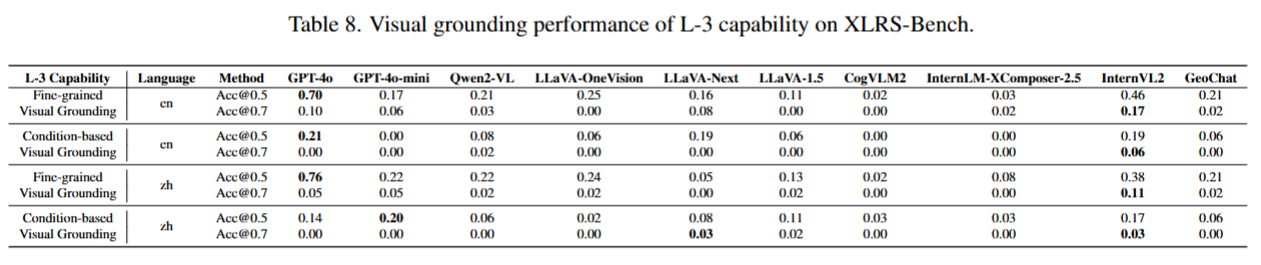
任务类型(L-3 Capability):Fine-grained Visual Grounding(细粒度视觉定位):根据文本描述定位图像中具体目标(如 “红色屋顶的小房子”)
Condition-based Visual Grounding(基于条件的视觉定位):根据复杂条件定位目标(如 “码头旁装满集装箱的运输船”)
评估指标:2 个交并比(IoU)阈值,衡量预测边界框与真实边界框的重合度
Acc@0.5:IoU≥0.5 时判定为正确(宽松标准,重合一半以上即算对)
Acc@0.7:IoU≥0.7 时判定为正确(严格标准,重合七成以上才算对)
- 图像描述任务
数据集描述平均长度为英文 379 词、中文 663 词,细节丰富。
开源模型和遥感专用模型 GeoChat 表现不佳,GPT-4o 和 GPT-4o-mini 虽无大量遥感预训练,但在长文本生成上优势显著,中文任务中仍领先。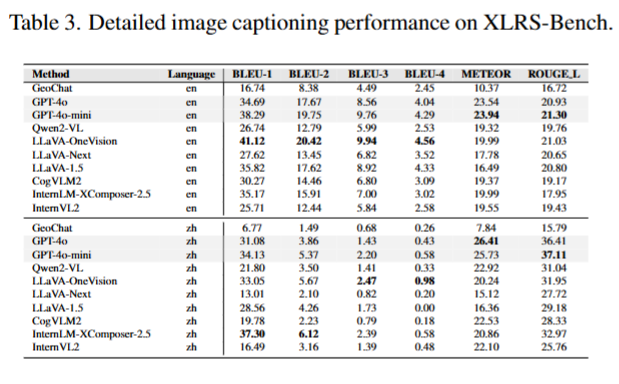
局限性
- 时空理解不足:通用模型缺乏遥感时空理解训练,专用模型未支持多图像输入,需加强领域专用训练。
- 超高分辨率处理挑战:当前模型输入限制为 4K,大尺寸图像压缩导致小型目标信息丢失,需开发遥感超分辨率专用 MLLMs。
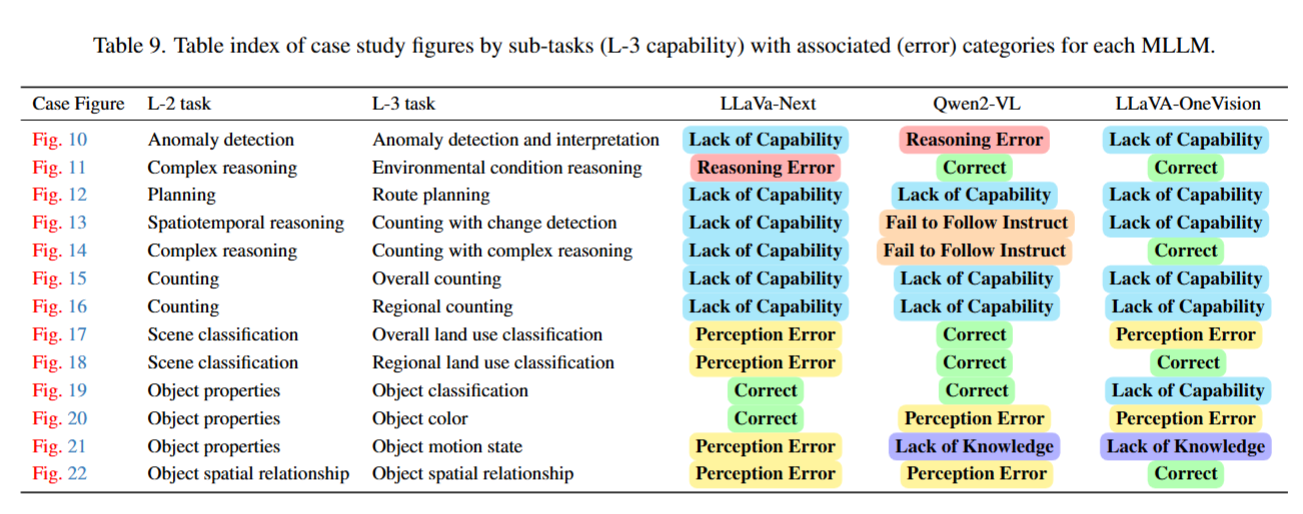
分类分析 LLaVa-Next、Qwen2-VL、LLaVA-OneVision 三款模型在各三级子任务中的错误类型(包括感知错误、推理错误、缺乏领域知识、不具备任务能力、未遵循指令五类)
六、结论与展望
在本文中,我们提出了 XLRS-Bench—— 一个用于评估多模态大语言模型(MLLMs)在超高分辨率遥感(RS)场景下感知与推理能力的综合基准。XLRS-Bench 具备迄今为止最大的平均图像尺寸、经过人工验证的高质量标注,以及涵盖三个能力层级的 16 个子任务,可提供多维度评估。该基准支持中英文双语,是目前规模最大的人工标注超高分辨率遥感视觉 - 语言数据集,在数据量和任务多样性上均超越现有基准。
XLRS-Bench 着重关注真实世界决策与时空变化检测,推动模型高级认知能力的发展。实验结果表明,当前通用型和遥感专用型多模态大语言模型在理解超高分辨率遥感影像方面仍存在不足,亟需进一步优化改进。
七、个人声明
本文仅用于学术传播和交流,内容均由作者独立整理,旨在分享作者对原论文的学习成果与心得体会,因受制于个人知识水平和理解能力,文中对原论文内容的解读可能存在不尽完善之处,最终解释权以原论文为准。如文中涉及的文字、图片及其他作品在版权或其他相关事宜上存在争议,欢迎及时与作者联系,作者将在第一时间回复并妥善处理。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)