通过自主车辆实现水下声学跟踪的多智能体强化学习扩展
自主车辆(AV)为科学任务提供了成本效益高的解决方案,例如水下追踪。最近,强化学习(RL)作为一种在复杂海洋环境中控制AV的强大方法崭露头角。然而,将这些技术扩展到车队——这对于多目标跟踪或快速、不可预测运动的目标至关重要——带来了显著的计算挑战。多智能体强化学习(MARL)以样本效率低下而闻名,尽管像Gazebo的LRAUV这样高保真度的模拟器可以提供比实时快100倍的单机器人模拟,但它们对多车
Matteo Gallici、Ivan Masmitja 和 Mario Martín
摘要
自主车辆(AV)为科学任务提供了成本效益高的解决方案,例如水下追踪。最近,强化学习(RL)作为一种在复杂海洋环境中控制AV的强大方法崭露头角。然而,将这些技术扩展到车队——这对于多目标跟踪或快速、不可预测运动的目标至关重要——带来了显著的计算挑战。多智能体强化学习(MARL)以样本效率低下而闻名,尽管像Gazebo的LRAUV这样高保真度的模拟器可以提供比实时快100倍的单机器人模拟,但它们对多车场景没有显著的速度提升,使得MARL训练变得不切实际。为了解决这些限制,我们提出了一种迭代蒸馏方法,将高保真度模拟转移到简化的、GPU加速的环境中,同时保留了高级动态特性。这种方法通过并行化实现了相对于Gazebo高达30,000倍的速度提升,从而通过端到端GPU加速实现了高效训练。此外,我们引入了一种基于Transformer的新架构(TransfMAPPO),该架构学习与智能体和目标数量无关的多智能体策略,显著提高了样本效率。经过完全在GPU上进行的大规模课程学习后,我们在Gazebo中进行了广泛的评估,结果表明,即使在存在多个快速移动目标的情况下,我们的方法在长时间内仍能将跟踪误差保持在5米以下。这项工作弥合了大规模MARL训练与高保真部署之间的差距,为真实世界海洋任务中的自主舰队控制提供了一个可扩展的框架。
I. 引言
水下跟踪(UT)对于推进海洋研究任务至关重要,例如跟踪海洋物种和海洋现象 [1, 2],使用自主水下车辆(AUV)进行大规模数据收集 [3],以及管理海洋保护区 [4]。然而,水下通信系统面临诸如可靠性低和带宽不足等挑战,因为GPS无效 [5]。使用AUV或自主水面车辆(ASV)进行声学跟踪提供了一个有前景的解决方案,相比传统的固定设备,提高了效率并降低了成本 [2, 3]。然而,诸如不可靠通信、复杂环境动态和能量约束等问题需要先进的运动规划来增强AV的跟踪能力。
强化学习(RL)使AV能够通过试错学习最优导航规划,提供了
M. G. 来自KEMLG研究小组,Universitat Politècnica de Catalunya Barcelona,西班牙。gallici@cs.upc.edu
I. M. 来自Instituto de Ciencias del Mar, Consejo Superior de Investigaciones Científicas,巴塞罗那,西班牙。masmitja@icm.csic.es
M. M. 来自KEMLG研究小组,Universitat Politècnica de Catalunya,以及巴塞罗那超级计算中心的HPAI小组,巴塞罗那,西班牙。mmartin@cs.upc.edu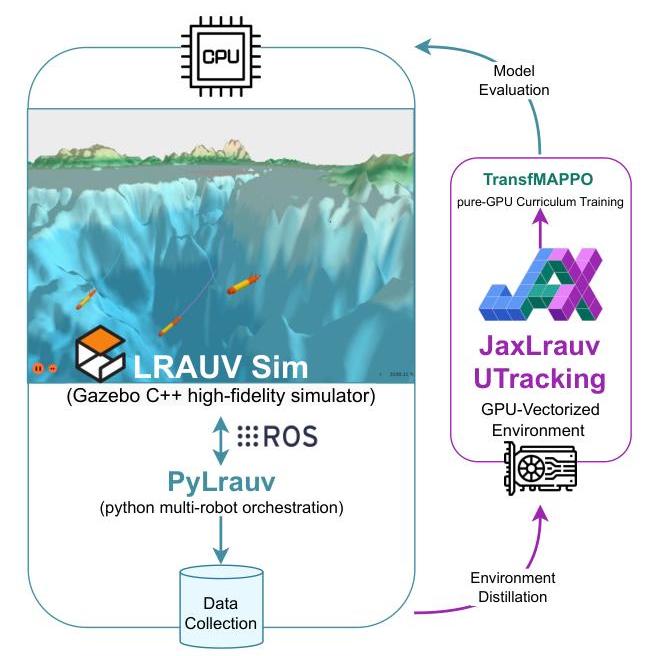
图1:我们的训练和评估管道概述。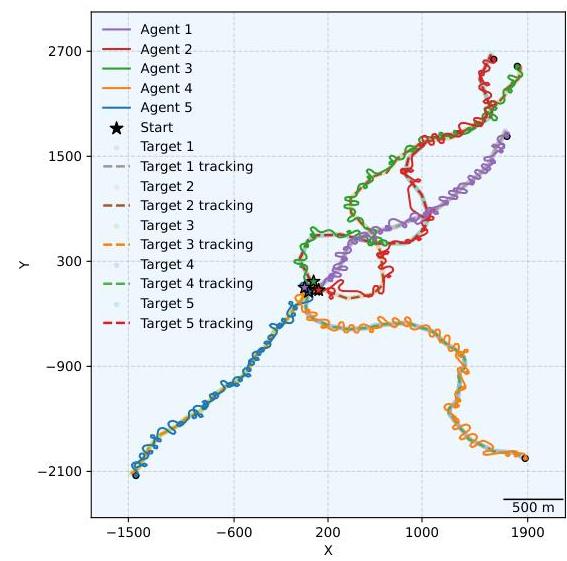
图2:五个在GPU简化环境中训练的智能体在Gazebo模拟器中跟随五个快速移动的目标数公里。视频:https://mttga.github.io/posts/pylrauv/images/5v5.gif
相比预编程方法,动态响应环境条件 [6]。最近的工作 [7] 展示了RL的潜力,通过在模拟器中训练一个Soft Actor-Critic(SAC)智能体,使用仅距离声学数据控制ASV跟踪水下目标。尽管成功,但该模型仅限于以适度速度(最高为智能体速度的0.3倍)线性移动的单一目标。
将这种方法扩展到更复杂的场景需要多智能体系统。多智能体强化学习(MARL)可以通过共享从不同位置同时收集的跟踪数据,学习最佳协作跟踪策略。然而,在海洋中部署这样一个复杂系统需要初步的广泛测试。像Gazebo的长距离AUV模拟器(LRAUV Sim)[8] 这样的模拟器,建模了流体力学、声学通信和海洋传感器,是这一阶段的关键工具。不幸的是,LRAUV Sim在多机器人模拟中只能提供比实时快10倍的速度提升,并且其基于C++的控制方式使与RL方法的集成复杂化,这意味着MARL无法直接应用于此类模拟器。
为了推进用于水下跟踪的多智能体系统,我们做出了以下贡献:
- PyL rauv 1{ }^{1}1 : 一个开源Python包,使用ROS2 [9] 通过类似Gym的接口控制LRAUV Sim。PyL rauv 可以无缝控制和观察可变数量的智能体和目标,同时通过Gazebo确保高保真度模拟。它还支持在真实任务中的直接部署。
-
- 环境蒸馏:一种使用JAX创建简化的、GPU加速的环境的方法,相对于Gazebo实现高达30,000倍的速度提升,允许在几分钟内训练有效的策略。我们将此蒸馏环境集成到流行的MARL库JaxMARL [10] 2{ }^{2}2 中,允许快速训练同时保持与PyL rauv的高层次等效性。
-
- TransfMAPPO:一种新方法将Transformers集成到MAPPO [11] 中,以训练独立于环境中实体数量的策略。TransfMAPPO 启用了课程学习(CL)管道,在复杂的多智能体场景中学习稳健的策略,而传统从零开始的方法如MAPPO在这种情况下无效。
-
- 高保真评估:我们通过在GPU上纯粹训练TransfMAPPO 并在高保真模拟中使用PyL rauv进行测试来证明我们管道的有效性:我们训练的模型可以以目标速度的0.8倍跟踪无规则移动的目标,并同时跟踪多个目标。我们开源了TransfMAPPO权重,以便在LRAUV Sim和真实任务中使用PyL rauv。
- 1{ }^{1}1 https://github.com/mttga/pyl rauv
- 2{ }^{2}2 https://github.com/FLAIROx/JaxMARL
II. 相关工作
早期关于使用自主车辆进行水下跟踪的研究依赖于传统的AV控制策略 [5, 12],更近期的工作则结合强化学习(RL)来提高导航和跟踪的鲁棒性 [7]。然而,这些研究主要集中在单智能体场景或具有有限目标动态的环境中。
MARL作为RL的自然扩展,用于学习协作策略,但其样本效率低下和可扩展性仍然具有挑战性。基于Transformer的方法,如TransfQMix [13],通过利用专门的Transformer模块解耦策略学习与实体数量的关系,原则上可以在逐步更具挑战性的多智能体场景中训练相同的网络。我们的TransfMAPPO架构受到TransfQMix的启发,但由于其与并行化环境的天然兼容性,使用MAPPO而不是DQN [14] 作为RL主干。此外,TransfMAPPO不使用集中式超网络,而是使用集中式批评家,简化了模型结构。最后,TransfMAPPO也适用于连续动作空间,而TransfQMix仅限于离散动作空间。
像JaxMARL [10]这样的框架展示了GPU加速MARL的好处,尽管是在相对简单的环境中,而像IsaacGym [15]这样的包提供了更高级的基于GPU的真实机器人仿真,但不提供必要的水动力模型和通信协议以弥合模拟到真实的差距。
我们的管道可以与基于模型的RL [16, 17, 18]相关联,后者旨在学习世界模型以改进和加速RL训练。我们的方法从高保真模拟器创建简化的、GPU加速的物理模型,但不是专注于世界模型与现实世界的逐步对齐,而是关注在不同的时间尺度上相对于更复杂的模拟器保留高级动态特性。此外,我们的蒸馏环境不受我们的学习算法访问,这通常是基于模型的RL的情况;相反,我们只是在上面使用无模型RL。
III. 背景
A. 使用自主车辆进行水下跟踪
使用自主车辆进行水下声学跟踪属于Range Only Single Beacon (ROSB) 定位技术家族 [19, 20],该技术使用随时间收集的仅距离声学观测来定位目标。对于静态目标,三边测量问题可以通过最小二乘法(LS)算法线性化,该算法假设静态条件并在目标移动时产生误差 [21]。对于动态场景,粒子滤波器(PF)使用贝叶斯估计,用加权粒子表示潜在的目标状态,并根据运动模型更新并通过测量似然性重新采样 [22, 23]。
B. 多智能体强化学习
合作多智能体任务被形式化为去中心化部分可观测马尔可夫决策过程(Dec-POMDP)[24],由元组 G=G=G= ⟨S,U,P,r,Z,O,n,γ⟩\langle S, \mathbf{U}, P, r, Z, O, n, \gamma\rangle⟨S,U,P,r,Z,O,n,γ⟩ 定义,其中 SSS 是全局状态空间,
U=Un\mathbf{U}=U^{n}U=Un 是 nnn 个智能体的联合动作空间(每个智能体选择动作 ua∈Uu^{a} \in Uua∈U),P(s′∣s,u)P\left(s^{\prime} \mid s, \mathbf{u}\right)P(s′∣s,u) 是状态转移函数,r(s,u)r(s, \mathbf{u})r(s,u) 是共享奖励函数,ZZZ 是每个智能体的观测空间,O(s,a)O(s, a)O(s,a) 定义智能体 aaa 的观测 za∈Zz^{a} \in Zza∈Z,γ∈[0,1)\gamma \in[0,1)γ∈[0,1) 是折扣因子。在每个时间步,智能体 aaa 接收局部观测 za=O(s,a)z^{a}=O(s, a)za=O(s,a) 并维护动作-观测历史 τa=(z0a,u0a,…,zta)∈T\tau^{a}=\left(z_{0}^{a}, u_{0}^{a}, \ldots, z_{t}^{a}\right) \in \mathcal{T}τa=(z0a,u0a,…,zta)∈T。智能体的策略 πa(ua∣τa):T×U→[0,1]\pi^{a}\left(u^{a} \mid \tau^{a}\right): \mathcal{T} \times U \rightarrow[0,1]πa(ua∣τa):T×U→[0,1] 将该历史映射到动作分布。智能体集体旨在最大化预期折现回报 E[∑t=0∞γtrt]\mathbb{E}\left[\sum_{t=0}^{\infty} \gamma^{t} r_{t}\right]E[∑t=0∞γtrt]。MARL中的关键范式是集中训练分散执行(CTDE)[25],智能体在训练期间利用集中信息但在执行期间独立行动。这允许使用集中式批评家来估计价值函数 V(s)V(s)V(s) 使用全局状态 sss,而策略 πa\pi^{a}πa 保持分散,仅依赖于局部历史 τa\tau^{a}τa。
MAPPO [11] 将近端策略优化(PPO)[26] 扩展到多智能体设置。每个智能体的策略(演员)πθa\pi_{\theta}^{a}πθa 和集中价值函数(批评家)VϕV_{\phi}Vϕ 联合优化。演员使用剪裁代理目标更新:
LCLIP(θ)=Et{min(ρt(θ)A^t,clip(ρt(θ),1−ϵ,1+ϵ)A^t)}\mathcal{L}^{C L I P}(\theta)=\mathbb{E}_{t}\left\{\min \left(\rho_{t}(\theta) \hat{A}_{t}, \operatorname{clip}\left(\rho_{t}(\theta), 1-\epsilon, 1+\epsilon\right) \hat{A}_{t}\right)\right\}LCLIP(θ)=Et{min(ρt(θ)A^t,clip(ρt(θ),1−ϵ,1+ϵ)A^t)},
其中 ρt(θ)=πθ(nt(τt)πθmin(nt(τt)\rho_{t}(\theta)=\frac{\pi_{\theta}\left(n_{t}\left(\tau_{t}\right)\right.}{\pi_{\theta_{\min }}\left(n_{t}\left(\tau_{t}\right)\right.}ρt(θ)=πθmin(nt(τt)πθ(nt(τt) 是概率比率,A^t\hat{A}_{t}A^t 是优势估计值,ϵ\epsilonϵ 是剪裁超参数。批评家最小化时间差误差:
LVF(ϕ)=Et[(Vϕ(st)−R^t)2] \mathcal{L}^{V F}(\phi)=\mathbb{E}_{t}\left[\left(V_{\phi}\left(s_{t}\right)-\hat{R}_{t}\right)^{2}\right] LVF(ϕ)=Et[(Vϕ(st)−R^t)2]
其中 R^t\hat{R}_{t}R^t 是折扣回报。在执行期间,仅使用演员,实现分散控制。
IV. 方法
A. PyLrauv
PyLrauv 通过利用ROS 2 [9] 提供了一个Python接口给LRAUV Sim。这是通过将一组额外的通信处理器集成到官方的Gazebo C++库,ros_gz 3{ }^{3}3 中实现的。这种集成允许使用python通过rclpy 4{ }^{4}4 控制LRAUV机器人。我们开发了一套Python控制器,用于向Gazebo中的LRAUV车辆发送命令并观察它们发布的状态。由于实际的LRAUV车辆使用相同的技术,因此PyLrauv提供的控制器也可以用来控制真实的LRAUV机器人。以类似于Gym的方式控制在Gazebo中模拟的多个车辆非常简单,如下代码所示:
from pylrauv import UTrackingEnv
env = UTrackingEnv(num_agents=2, num_targets=2)
obs, state = env.reset()
actions = {‘agent_1’: 0, ‘agent_2’: 0}
obs, state, reward, done = env.step(actions, step_time=30)
B. UTracking 环境
UTrackingEnv 是一个类似Gym的环境,管理智能体和目标命令、通信、跟踪以及RL任务如观测构建和奖励计算。智能体通过Gazebo LRAUV声学通讯插件进行通信,并使用LRAUV距离方位插件收集目标距离。在一个回合的开始,智能体被生成在海面上,目标则在随机深度,确保每个实体之间至少有50米的距离,最多200米。智能体和目标都是LRAUV车辆。在我们的实验中,每一步持续30秒,在这期间智能体监听来自目标的距离信号,并在结束时广播它们的位置和观测给其他智能体。每个智能体为其跟踪的每个目标维护自己的跟踪模型(LS或PF),并使用收到的所有信息进行更新。这确保了系统的真正分散化。目标在二维空间中被跟踪,因为深度通常已知 [7]。
a) 观测空间:在步骤阶段结束时,智能体接收它们对环境的部分观测,其中包括与其他所有实体在三维空间中的相对距离。对于其他智能体,这些距离使用它们接收到的信息(如果可用)计算,而对于目标,这些距离则从它们自己的跟踪模块生成的跟踪预测中计算。[7] 将范围观测纳入观测向量中,这可能有助于,但也可能导致智能体过度拟合到训练动态并忽略跟踪信息。为防止这种情况,我们将观测限制为跟踪衍生值,确保智能体依赖于跟踪数据及其固有的错误。环境还返回环境的全局状态,包括每个实体的真实三维位置、速度和方向。
b) 奖励函数:我们定义了两种可能的奖励函数。跟踪奖励旨在减少全局跟踪误差。设 eie_{i}ei 表示目标 iii 的跟踪误差,ϵmin\epsilon_{\min }ϵmin 表示系统的理想误差,nϵmax\mathrm{n} \epsilon_{\max }nϵmax 表示最大奖励误差,并定义该目标的奖励为指数衰减函数:
ritracking ={1,ei<ϵminexp(−2t1−t),ϵmin≤ei≤ϵmax0,ei>ϵmax r_{i}^{\text {tracking }}=\left\{\begin{array}{ll} 1, & e_{i}<\epsilon_{\min } \\ \exp \left(-\frac{2 t}{1-t}\right), & \epsilon_{\min } \leq e_{i} \leq \epsilon_{\max } \\ 0, & e_{i}>\epsilon_{\max } \end{array}\right. ritracking =⎩ ⎨ ⎧1,exp(−1−t2t),0,ei<ϵminϵmin≤ei≤ϵmaxei>ϵmax
其中 t=(ei−ϵmin)/(ϵmax−ϵmin)t=\left(e_{i}-\epsilon_{\min }\right) /\left(\epsilon_{\max }-\epsilon_{\min }\right)t=(ei−ϵmin)/(ϵmax−ϵmin)。我们设定 ϵmin=10 m\epsilon_{\min }=10 \mathrm{~m}ϵmin=10 m 和 ϵmax=50 m\epsilon_{\max }=50 \mathrm{~m}ϵmax=50 m。指数衰减鼓励精确跟踪,并更清楚地区分接近理想跟踪误差的状态。跟随奖励基于智能体相对于目标的适当分布。该奖励鼓励智能体在目标间的完美分布,这已知是当 NNN 个智能体需要跟随(足够快的)NNN 个目标时的最佳策略。对于目标 iii,如果它与任何智能体之间的最小距离 did_{i}di 小于指定阈值 dmind_{\min }dmin,则认为目标成功被跟随。奖励计算为
rifollow =I{di≤dmin} r_{i}^{\text {follow }}=\mathbb{I}\left\{d_{i} \leq d_{\min }\right\} rifollow =I{di≤dmin}
3{ }^{3}3 https://github.com/gazebosim/ros_gz
4{ }^{4}4 https://github.com/ros2/rclpy
在我们的实验中,阈值设定为50米(快速目标为100米)。在两种情况下,系统的全局奖励由下式给出
r=1N∑i=1Nri r=\frac{1}{N} \sum_{i=1}^{N} r_{i} r=N1i=1∑Nri
其中 NNN 是要跟踪的目标数量,即奖励按目标数量归一化,始终处于区间 [0,1][0,1][0,1] 内,以便学习的价值函数可以在具有不同目标数量的情景之间转移。此外,如果任意两个智能体之间的距离低于最小有效距离 dsafe d_{\text {safe }}dsafe ,则始终应用碰撞惩罚,即 r=r=r= -1 如果 mint∈f{dij}<dsafe \min _{t \in f}\left\{d_{i j}\right\}<d_{\text {safe }}mint∈f{dij}<dsafe -
c) 动作空间:为了简化我们的多智能体系统的动作空间,我们保持智能体的速度恒定,并允许它们仅控制舵。舵被离散化为五个值,对应于从 -0.24 到 0.24 弧度的等距角度。智能体只能调整到下一个最近的两个角度,防止方向的突然变化。
d) 终止:当达到最大步数时,回合结束。环境不会在发生碰撞或丢失目标时截断,因为我们实验观察到截断回合会导致训练不稳定。
为什么UTracking是一个困难的环境?
- 部分可观测性:智能体仅能在450米范围内通过噪声声学信号检测目标,并依赖间歇性和不稳定的通信(1500米范围)共享跟踪数据。
-
- 随机性:传感器噪声、通信中断、环境扰动和不可预测的目标运动放大了不确定性。
-
- 协调挑战:智能体必须几乎完美地协调,特别是在跟踪多个快速移动目标时,缺乏协调可能导致迅速失去目标。
-
- 长时间跨度:小时级任务(相当于数千步)要求学习延迟后果的动作,这在多智能体场景中由于其非平稳性可能很困难。此外,它们需要对跟踪模型中的误差累积具有鲁棒性。
C. 环境蒸馏:JaxLraux UTracking
LRAUV Sim 在毫秒级别模拟LRAUV机器人的动态。然而,LRAUV车辆每隔几秒到几分钟才采取一次动作。此外,我们感兴趣的跟踪任务持续数小时。因此,以更大的时间尺度模拟环境状态会很有益处。正式地说,我们感兴趣的是在给定当前机器人位置 pt\mathbf{p}_{t}pt、绝对速度 vvv 和舵角 γ\gammaγ 的情况下,经过时间间隔 δt\delta_{t}δt 后在二维平面中的新位置 pt+1∈R2\mathbf{p}_{t+1} \in \mathbb{R}^{2}pt+1∈R2。与其重新发明轮子并重建Gazebo已经提供的准确物理模型,我们希望近似机器人
航向的变化 δψ\delta_{\psi}δψ 以使用简化的轨迹模型,即 pt+1=pt+vδt[cos(ψt+δψ),sin(ψt+δψ)]\mathbf{p}_{t+1}=\mathbf{p}_{t}+v \delta_{t}\left[\cos \left(\psi_{t}+\delta_{\psi}\right), \sin \left(\psi_{t}+\delta_{\psi}\right)\right]pt+1=pt+vδt[cos(ψt+δψ),sin(ψt+δψ)]。固定 vvv 和 δt\delta_{t}δt,我们针对舵角 θ(γ)\theta(\gamma)θ(γ) 参数化 δγ\delta_{\gamma}δγ。为了近似 θ(γ)\theta(\gamma)θ(γ),我们遵循一个迭代蒸馏过程:我们在PyLraux中收集轨迹,建立简化模型,训练一个智能体在该模型上,然后使用训练好的智能体收集新数据以改进模型蒸馏。我们发现,使用一组线性模型的集合可以将 θ(γ)\theta(\gamma)θ(γ) 近似为平均绝对误差低于0.015弧度,全局 R2R^{2}R2 分数为0.99。如此简单的模型无法捕捉长期依赖性,并且在自回归生成长轨迹时会发散。然而,它在较短的轨迹上表现良好,并且比例如LSTM快得多。为了提高系统的鲁棒性,我们引入了标准偏差为0.02弧度的高斯噪声,迫使训练好的智能体处理轨迹不确定性。此外,我们为智能体配备了递归机制。我们发现,在简化环境中以这种方式训练的策略可以直接转移到Gazebo。
其余环境,包括测量噪声、通信丢失的概率、部分可观测性和碰撞处理,均按照收集的数据统计手动实现。最终的简化环境在JAX中实现,以启用端到端的基于GPU的RL管道,并称为JaxLraux UTracking。表I展示了在不同配置的智能体和目标下的加速情况。这些加速使得在短短10分钟内即可训练出一个单目标跟踪模型,该模型可直接部署在LRAUV Sim中。
表I:蒸馏环境获得的加速情况。
| 配置 | Pylraux | JaxLraux 1 Env | JaxLraux 128 Env | JaxLraux 1024 Env | |||
|---|---|---|---|---|---|---|---|
| SPS | SPS | 加速 | SPS | 加速 | SPS | 加速 | |
| 1A,1T | 2.7 | 1289 | 477 | 68508 | 25352 | 81686 | 30229\mathbf{3 0 2 2 9}30229 |
| 2A,2T | 1.0 | 1068 | 1084 | 19712 | 20017 | 21534 | 21867 |
| 3A,3T | 0.4 | 1053 | 2439 | 9128 | 21139 | 9786 | 22663 |
| 4A,4T | 0.3 | 1020 | 3571 | 5180 | 18125 | 5450 | 19070 |
| 5A,5T | 0.2 | 936 | 4751 | 3469 | 17607 | 3574 | 18142 |
D. 向量化粒子滤波器
虽然PF代表了水下跟踪的最先进方法,但其计算开销使其在训练中效率低下,尤其是在多智能体场景中。为此,[7] 建议在训练中使用最小二乘法(LS),并将PF保留用于测试。然而,LS仅对静态或缓慢移动的目标稳定,限制了其对更快目标的可扩展性,并可能加剧MARL固有的非平稳性。为了实现高效训练,我们在JAX中实现了一个PF,利用vmap进行GPU并行化。通过嵌套vmapped函数,在训练中我们一次性更新所有目标、智能体和平行环境中的粒子,将速度损失降低到仅比LS慢 30%30 \%30%。如图3所示,使用LS训练对于移动速度超过智能体速度三分之一的目标失败,而PF保持稳定。
E. TransfMAPPO
训练多智能体系统的复杂性通常随着涉及的智能体数量增加而增加。为了解决这个问题,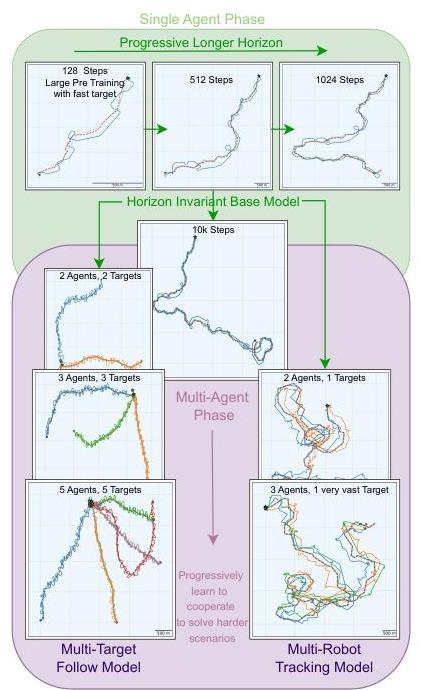
图3:使用粒子滤波器或最小二乘法训练智能体跟随以不同速度移动的目标。
我们引入了TransfMAPPO,灵感来源于TransfQMix [13],它保留了后者的概念核心,但使用PPO作为RL骨干而非DQN,因为PPO更适合矢量化环境。在TransfMAPPO中,我们实施了一个Transformer演员和批评家,它们处理描述观测实体的特征作为通过自我注意力学习的协调潜在图的顶点。由此产生的策略和价值函数因此不受所观测实体数量的影响,允许进行如子章节IV-F所述的课程学习。如图4所示,TransfMAPPO架构概览。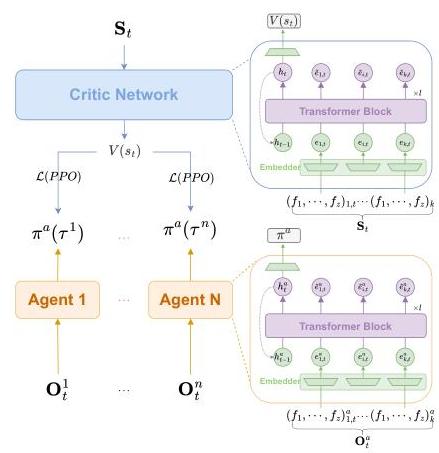
图4:TransfMAPPO架构概览。
F. 课程学习
利用我们的基于Transformer的架构,我们采用课程学习逐步从单智能体策略学习多智能体通用策略(见图5)。我们从一个大的预训练阶段开始,在这个阶段中,我们训练一个单独的智能体以最大化第IV-A小节中描述的跟踪奖励,针对一个快速移动的目标(其速度的0.6倍)。我们训练了 10910^{9}109 步骤,相当于
1.5天的计算(在Gazebo中需要几个月)。在这个阶段,我们在重置环境之前保持一个短的时间跨度(128步),因为它显著有助于学习。由此产生的策略能够以低于35米的误差跟踪快速目标,但它无法推广到更长的时间跨度。因此,我们在逐渐更长的回合中微调策略(256、512和1024步),共 10710^{7}107 步骤,直到我们观察到策略可以完美地跟踪一个快速目标超过10k步,相当于3.4天的实际时间跟踪。
从这个时间跨度不变的基础模型出发,我们过渡到多智能体阶段,在这里我们微调策略以完成协作任务。特别是,我们考虑了两种情景:(1) nnn 个智能体跟踪 nnn 个目标,我们使用跟随奖励,以及 (2) nnn 个智能体跟踪一个非常快速的目标(其速度的0.8倍),最大化与单智能体阶段相同的跟踪奖励。鉴于这两种情景提出了不同的协作和信用分配问题,我们重置了批评家参数,并为两个多智能体微调分支保持了两组单独的微调智能体,分别得到最终的多目标跟随模型和多机器人跟踪模型。在两种情况下,我们都微调模型以与逐渐更多的智能体协作(最多分别为5和3个),最多 20820^{8}208 步骤。我们观察到,这两个最终模型都能够与可变数量的智能体协作。在这个阶段,我们还注意到保持长环境时间跨度会对训练产生负面影响,因此我们将时间跨度缩短回256步。不幸的是,尽管结果的多智能体跟踪模型保留了预训练单智能体模型的时间跨度不变性,但多目标跟随模型相较于前者失去了部分不变性。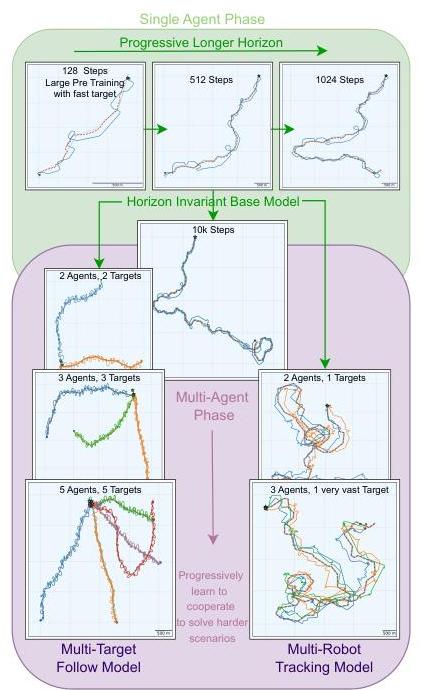
图5:我们的课程学习程序概览。
V. 实验
所有的训练都在MareNostrum 555^{5}55 的单个H100 GPU上完成,而Gazebo模拟实验则运行在Intel Sapphire Rapids 8460Y CPU上。所有回合回报都按时间跨度长度归一化,以在区间 [0,1][0,1][0,1] 内展示。所有训练结果都在5个种子上取平均值,除了课程模型。所有表示智能体轨迹的图表都是使用Gazebo模拟器中收集的数据生成的。
A. 多机器人跟踪
我们的课程方法的有效性在图6中得以展示,我们在该图中比较了微调模型以完成跟踪非常快速目标(智能体速度的0.8倍)的任务与从头开始在同一任务上训练的结果。课程学习的优越性能也在减少的跟踪误差中显而易见。在同一图表中,我们还包括了单智能体PPO的训练曲线,其回报不到多智能体系统的二分之一。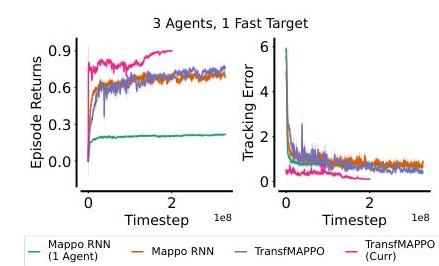
图6:训练多个智能体以跟踪非常快速的目标。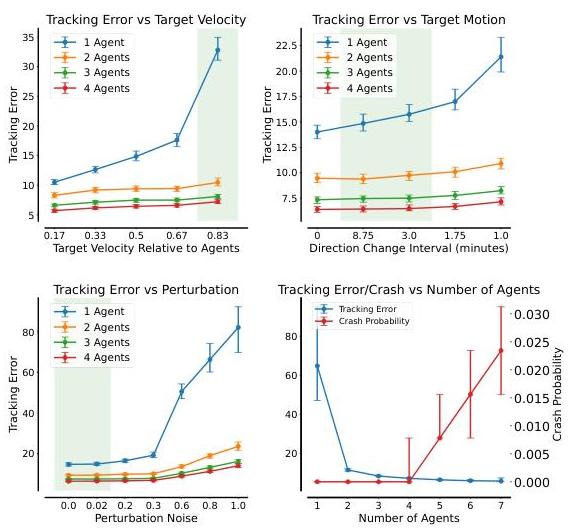
图7:多机器人跟踪评估。高亮区域表示训练中看到的值。
为了验证我们基于TransfMAPPO的最终多机器人跟踪模型,我们使用JaxLraux 图10进行全面验证分析。验证阶段的每个数据点都是在1000个回合中取平均值,每个回合长度为256步,跟踪目标的速度为智能体速度的0.5倍(除非另有说明)。具体来说,我们测试了在三种条件下跟踪误差如何受到影响:(1) 当目标移动更快时,(2) 当其运动变得更不可预测(由方向变化频率定义),以及 (3) 当智能体的运动受到干扰(模拟外部力量如洋流)。在最后一个子图中,我们展示了多智能体系统的性能如何自然地随着用于跟踪目标的智能体数量增加而扩展。值得注意的是,即使只使用2个智能体也能显著增强系统的鲁棒性,相比于单智能体方法。我们还强调,跟踪误差随着智能体数量的增加单调下降,3个智能体是最佳点,在保持最佳跟踪性能的同时实现可忽略的碰撞概率。
B. 多目标跟踪
同样,我们的课程方法在多目标跟踪场景中相比从头开始训练MAPPO取得了显著的优势。在图8中,我们展示了从头开始训练MAPPO以跟踪中速目标(最多为智能体速度的0.5倍)的训练曲线。MAPPO只能勉强学会在2智能体-2目标场景中跟随一半的目标,而我们的课程方法平均在5智能体-5目标场景中成功跟踪超过90%的目标。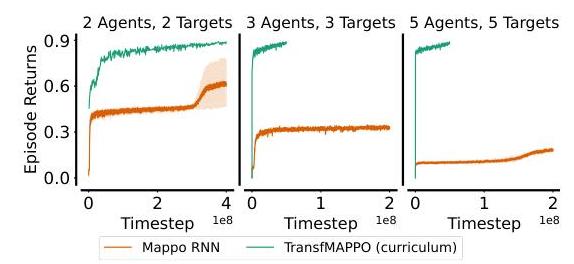
图8:训练多个智能体以跟随快速目标。
为了进一步测试TransfMAPPO的有效性,我们在一个更简单的配置中从头开始训练它与MAPPO,其中目标移动更慢(智能体速度的0.3倍)且更可预测。在这种情况下,TransfMAPPO和MAPPO在2个智能体时取得相似的分数,但MAPPO在3个智能体时性能显著下降。令人惊讶的是,即使从头开始训练,TransfMAPPO在5智能体-5目标场景中也非常有效地学习,确认了通过使用Transformers解耦合作策略所获得的样本效率。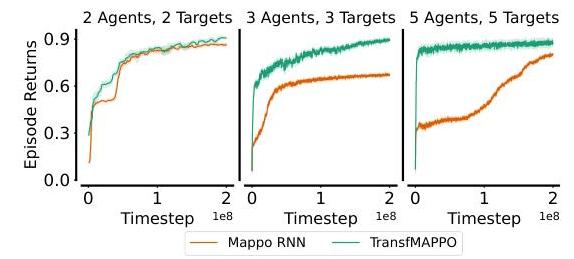
图9:训练多个智能体以跟随较慢的目标。
C. Gazebo中的结果
我们在Gazebo中进行了一系列最终实验,以评估训练好的智能体在高保真度
模拟环境中的性能。我们使用课程训练结束时获得的模型收集了50个回合的数据。具体来说,我们进行了以下测试:
- 使用单个机器人在JaxLrav中训练10分钟,跟踪一个慢速目标(0.3倍智能体速度)300步。
- 使用我们的时间跨度不变基础模型,跟踪一个快速目标(0.6倍智能体速度)1000步(相当于超过8小时的实际时间跟踪)。
- 使用3个智能体的多机器人跟踪微调模型,跟踪一个非常快速的目标(0.8倍智能体速度)1000步。
- 使用多目标模型,同时跟踪3个以0.5倍智能体速度移动的目标300步。
- 使用多目标模型,同时跟踪5个以0.5倍智能体速度移动的目标300步。
对于多目标实验,我们将步数减少到300,因为模拟多个机器人在Gazebo中的计算负担较大。这些实验的结果见表II。我们的研究发现,即使只有10分钟的训练,我们也能够开发出一个有效的模型,能够在不丢失目标的情况下保持目标跟踪。多机器人跟踪模型在跟踪非常快速的目标时实现了有希望的平均跟踪误差3米。这种性能明确优于跟踪较慢目标的单智能体跟踪器。值得注意的是,使用多个机器人时,智能体-目标的平均距离增加,反映了机器人在目标空间中的更广泛分布。多目标模型的表现符合预期,单个地标丢失的概率仅为5%。然而,多智能体模型表现出更高的碰撞概率。这一问题可能归因于模型仅在每30秒训练一次以避免碰撞,这可能导致Gazebo中的步间碰撞。这突显了未来工作的一个关键领域,即在将其部署到真实世界的海洋任务之前,增强系统的安全性。
表II:Gazebo中的实验结果
| 配置 | 平均智能体-目标距离 | 平均跟踪误差 | 碰撞概率(%) | 最后概率(%) |
|---|---|---|---|---|
| 1A,ST (Row, 1000 m Train) | 59.00±32.2959.00 \pm 32.2959.00±32.29 | 3.89 ±3.7\pm 3.7±3.7 | 0.00 | 0.00 |
| 1A,ST (Row, 121,05 ±62.11\pm 62.11±62.11 | 121.05±62.11121.05 \pm 62.11121.05±62.11 | 20.33±28.3820.33 \pm 28.3820.33±28.38 | 0.00 | 0.16 |
| 3A,ST (Noy Fair) | 117.64±89.83117.64 \pm 89.83117.64±89.83 | 3.85±6.17\mathbf{3 . 8 5} \pm 6.173.85±6.17 | 15.32 | 0.00\mathbf{0 . 0 0}0.00 |
| 3A,ST (Moderate) | 45.30±26.1145.30 \pm 26.1145.30±26.11 | 5.35 ±4.88\pm 4.88±4.88 | 5.00 | 5.00 |
| 5A,ST (Moderate) | 49.24±30.9249.24 \pm 30.9249.24±30.92 | 4.25 ±4.57\pm 4.57±4.57 | 10.00 | 5.26 |
VI. 结论
我们介绍了一种在水下跟踪背景下扩展多智能体强化学习(MARL)的方法,展示了如何可以在纯GPU上高效训练MARL模型并将其部署到高保真度模拟器中,而在其他情况下MARL训练可能会极其昂贵或不可行。尽管此方法在环境蒸馏阶段依赖于手动调整,但我们的整体管道为缩小MARL的模拟到现实差距提供了一个有希望的方向。这项工作的自然下一步是增强多智能体系统的安全性,并在真实世界的海洋任务中进行测试。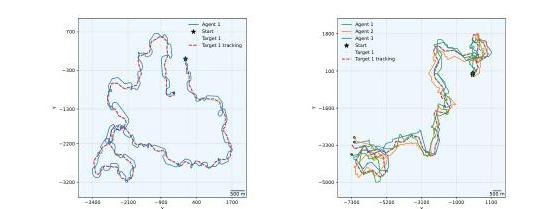
图10:在Gazebo中收集的多智能体回合。(a):单智能体跟踪,目标速度为智能体速度的0.66倍。视频。(b):多智能体跟踪,目标速度为智能体速度的0.88倍。视频。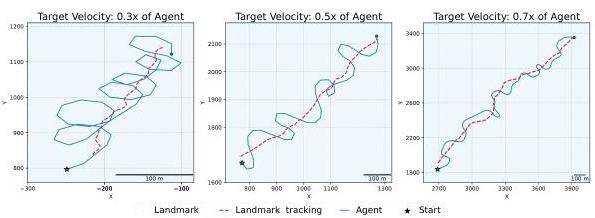
图11:根据目标速度的智能体轨迹。注意智能体轨迹曲率的变化以最优地跟踪移动的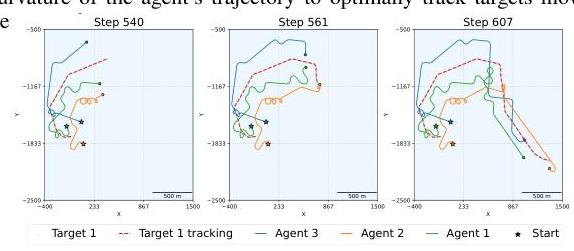
图12:跟踪非常快速目标时的协作。注意智能体如何在目标快速改变方向时相互等待以免丢失目标。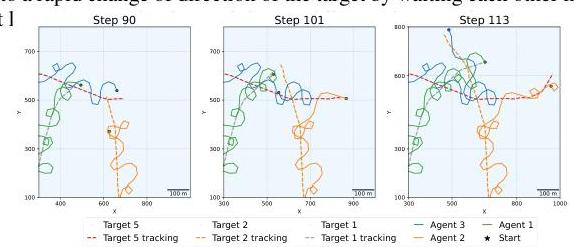
图13:多目标设置中的协作。注意智能体如何通过画圈等待其他智能体通过来解决“交通”问题,并且一个目标动态地从智能体3重新分配给智能体1。
致谢
本工作感谢西班牙科学、创新和大学部(BITER-ECO:PID2020-114732RBC31)的支持。本工作是DIGI4ECO的一部分,该项目得到了欧盟Horizon Europe计划的资助,资助协议编号为101112883。I. M. 获得了MCIN/AEI/10.13039/501100011033和FSE+的财政支持,资助协议编号为RYC2022038056-I。M. G. 部分由FPI-UPC Santander奖学金FPIUPC.93资助。本工作还感谢’Severo Ochoa Centre of Excellence’认证(CEX2019-000928-S)和巴塞罗那超级计算机中心的支持。
参考文献
[1] Nikolaos D Zarokanellos 等人。“阿尔博兰海的前沿动态:1. 使用水下滑翔机观测的阿尔梅里亚-奥兰前沿的连贯3D路径”。载于:《地球物理研究杂志:海洋》127.3 (2022),e2021JC017405。
[2] Ivan Masmitja 等人。“用于深海底层渔业资源声学跟踪的移动机器人平台”。载于:《科学机器人》5.48 (2020),eabc3701。
[3] Yanwu Zhang 等人。“用于海洋深层叶绿素最大值微生物拉格朗日研究的协调自主机器人系统”。载于:《科学机器人》6.50 (2021),eabb9138。DOI: 10 . 1126 / scirobotics.abb9138。
[4] Maria Vigo 等人。“地中海深水环境中挪威龙虾 Nephrops norvegicus 的空间生态学:设计无捕捞海洋保护区的含义”。载于:《海洋生态学进展系列》674 (2021),第173-188页。
[5] John Heidemann, Milica Stojanovic 和 Michele Zorzi。“水下传感器网络:应用、进展与挑战”。载于:《皇家学会哲学汇刊 A:数学、物理和工程科学》370.1958 (2012),第158-175页。
[6] David Cote 等人。“表征雪蟹 (Chionoecetes opilio) 在悉尼湾(加拿大新斯科舍省)的运动:使用多尺度声学遥测的合作方法”。载于:《加拿大渔业和水生科学杂志》76.2 (2019),第334-346页。
[7] I. Masmitja 等人。“使用强化学习动态机器人跟踪水下目标”。载于:《科学机器人》8.80 (2023),eade7811。DOI: 10 . 1126 / scirobotics.ade7811。
[8] Timothy R. Player 等人。“从概念到实地测试:使用高保真比实时快的模拟器加速多AUV任务开发”。载于:2023年IEEE国际机器人与自动化会议 (ICRA)。IEEE,2023年5月,第3102-3108页。DOI: 10.1109/icra48891.2023.10160447。
[9] Steven Macenski 等人。“机器人操作系统2:设计、架构及其在野外的应用”。载于:《科学机器人》7.66 (2022),eabm6074。DOI: 10 . 1126 / scirobotics.abm6074。
[10] Alexander Rutherford 等人。“JaxMARL:JAX中的多智能体强化学习环境”。载于:arXiv预印本 arXiv:2311.10090 (2023)。
[11] Chao Yu 等人。“PPO在合作多智能体游戏中的惊人有效性”。载于:(2022)。arXiv: 2103.01955 [cs.LG]。URL: https://arxiv.org/ abs/2103.01955。
[12] João Almeida, Carlos Silvestre 和 António Pascoal。“使用事件触发和自触发广播的多智能体系统同步”。载于:《IEEE自动控制汇刊》62.9 (2017),第4741-4746页。DOI: 10.1109/TAC.2017.2671029。
[13] Matteo Gallici, Mario Martin 和 Ivan Masmitja。“TransfQMix:用于利用多智能体强化学习问题图结构的Transformer”。载于:2023年国际自主代理和多智能体系统会议论文集。AAMAS '23。英国伦敦:
International Foundation for Autonomous Agents and Multiagent Systems,2023,第1679-1687页。
[14] Hado Van Hasselt, Arthur Guez 和 David Silver。“具有双Q学习的深度强化学习”。载于:AAAI人工智能会议论文集。卷30。1。2016。
[15] Viktor Makoviychuk 等人。Isaac Gym:用于机器人学习的高性能基于GPU的物理仿真。2021。arXiv: 2108.10470 [cs.R0]。URL: https://arxiv.org/abs/2108.10470。
[16] Lukasz Kaiser 等人。基于模型的强化学习应用于Atari。2024。arXiv: 1903 . 00374 [cs.LG]。URL: https://arxiv.org/abs/1903. 00374。
[17] Lars Buesing 等人。“强化学习中快速生成模型的学习与查询”。载于:arXiv预印本 arXiv:1802.03006 (2018)。
[18] Vincent Micheli, Eloi Alonso 和 François Fleuret。“Transformers是样本高效的模型”。载于:arXiv预印本 arXiv:2209.00588 (2022)。
[19] Edwin Olson, John J. Leonard 和 Seth Teller。“鲁棒的仅距离信标定位”。载于:《IEEE海洋工程杂志》31.4 (2006),第949-958页。
[20] Jake D. Quenzer 和 Kristi A. Morgansen。“仅距离水下车辆定位中的基于可观测性的控制”。载于:2014年美国控制会议。2014,第4702-4707页。DOI: 10.1109/ACC. 2014. 6859032。
[21] Alex Alcocer Penas。“用于机器人水下车辆的定位和导航系统”。博士论文,高等技术学院 (2009)。
[22] Jake D Quenzer 和 Kristi A Morgansen。“仅距离水下车辆定位中的基于可观测性的控制”。载于:2014年美国控制会议。IEEE。2014,第4702-4707页。
[23] Edwin Olson, John J Leonard 和 Seth Teller。“鲁棒的仅距离信标定位”。载于:《IEEE海洋工程杂志》31.4 (2006),第949-958页。
[24] Frans A Oliehoek 和 Christopher Amato。去中心化部分可观测马尔可夫决策过程的简明介绍。Springer,2016。
[25] Tabish Rashid 等人。QMIX:深度多智能体强化学习中的单调价值函数分解。2018。arXiv: 1803.11485 [cs.LG]。URL: https://arxiv.org/abs/1803.11485。
[26] John Schulman 等人。近端策略优化算法。2017。arXiv: 1707.06347 [cs.LG]。URL: https://arxiv.org/abs/1707.06347。
[27] Matteo Gallici 等人。简化深度时间差学习。2024。arXiv: 2407.04811 [cs.LG]。URL: https://arxiv.org/abs/2407.04811。
参考论文:https://arxiv.org/pdf/2505.08222

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)