AI大模型教程(干货满满):从零基础入门到精通Qwen3-Embedding,建议收藏反复学习!
数据集下载地址:训练集(train.csv)验证集(dev.csv)测试集(test.csv)34,3344,3163,861。
本文详细介绍了使用Qwen3-Embedding-0.6B模型通过Lora微调实现语义相似性判断任务的完整流程。包括模型改造、蚂蚁金融语义相似度数据集处理、微调训练过程及测试。实验显示模型在验证集上达到83.17%准确率和83.16%的F1值,略低于chinese-roberta-wwm-ext模型。文章提供了从数据预处理到模型训练的全过程代码,适合大模型微调学习者参考。
一、语义相似性判断任务
语义相似性判断任务 或者 文本语义等价任务,说白了,就是让模型来判断两个句子是不是在说同一个意思。就像我们人类有时候会说两句话来表达同一个想法。应用场景,例如在搜索引擎中,能帮助系统理解用户查询与网页内容之间的深层语义关联,即便两者用词不同也能精准判断;还有在智能客服场景下,它可以判断用户问题与知识库中的标准答案是否意图一致,从而快速给出准确回复等。
在本专栏的前面文章有实验过使用 hfl/chinese-roberta-wwm-ext 模型,微调语义相似性判断任务,最终在验证集上表现为:准确率 85.1485 ,F1:85.1480 ,文章地址如下:
基于 Roberta 微调训练句子语义等价识别任务
小毕超,公众号:狂热JAVA小毕超基于 Roberta 微调训练句子语义等价识别任务
本文则基于开源的 Qwen3-Embedding-0.6B 模型进行 Lora 微调的方式,实现语义相似性判断任务,实验下 Qwen3-Embedding 模型做下游 NLU 任务的效果如何,数据集同样采用 蚂蚁金融语义相似度数据集。
下面实验所使用的主要依赖版本如下:
torch==2.6.0transformers==4.51.3peft==0.12.0
模型改造
预训练模型下载地址:
https://modelscope.cn/models/Qwen/Qwen3-Embedding-0.6B
Lora 模型修改,采用 huggingface 中的 PEFT 框架实现,主要针对 Qwen3-Embedding-0.6B 模型自注意力层的 q_proj、 k_proj、 v_proj 做降维升维操作,操作方式如下所示:
from transformers import AutoModelfrom peft import LoraConfig, get_peft_model, TaskTypemodel_name = "Qwen/Qwen3-Embedding-0.6B"model = AutoModel.from_pretrained(model_name)peft_config = LoraConfig( task_type=TaskType.SEQ_CLS, target_modules=["q_proj", "k_proj", "v_proj"], inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1 )model = get_peft_model(model, peft_config)model.print_trainable_parameters()print(model)
输出结果:
trainable params: 1,605,632 || all params: 597,382,144 || trainable%: 0.2688PeftModelForSequenceClassification( (base_model): LoraModel( (model): Qwen3Model( (embed_tokens): Embedding(151669, 1024) (layers): ModuleList( (0-27): 28 x Qwen3DecoderLayer( (self_attn): Qwen3Attention( (q_proj): lora.Linear( (base_layer): Linear(in_features=1024, out_features=2048, bias=False) (lora_dropout): ModuleDict( (default): Dropout(p=0.1, inplace=False) ) (lora_A): ModuleDict( (default): Linear(in_features=1024, out_features=8, bias=False) ) (lora_B): ModuleDict( (default): Linear(in_features=8, out_features=2048, bias=False) ) (lora_embedding_A): ParameterDict() (lora_embedding_B): ParameterDict() (lora_magnitude_vector): ModuleDict() ) (k_proj): lora.Linear( (base_layer): Linear(in_features=1024, out_features=1024, bias=False) (lora_dropout): ModuleDict( (default): Dropout(p=0.1, inplace=False) ) (lora_A): ModuleDict( (default): Linear(in_features=1024, out_features=8, bias=False) ) (lora_B): ModuleDict( (default): Linear(in_features=8, out_features=1024, bias=False) ) (lora_embedding_A): ParameterDict() (lora_embedding_B): ParameterDict() (lora_magnitude_vector): ModuleDict() ) (v_proj): lora.Linear( (base_layer): Linear(in_features=1024, out_features=1024, bias=False) (lora_dropout): ModuleDict( (default): Dropout(p=0.1, inplace=False) ) (lora_A): ModuleDict( (default): Linear(in_features=1024, out_features=8, bias=False) ) (lora_B): ModuleDict( (default): Linear(in_features=8, out_features=1024, bias=False) ) (lora_embedding_A): ParameterDict() (lora_embedding_B): ParameterDict() (lora_magnitude_vector): ModuleDict() ) (o_proj): Linear(in_features=2048, out_features=1024, bias=False) (q_norm): Qwen3RMSNorm((128,), eps=1e-06) (k_norm): Qwen3RMSNorm((128,), eps=1e-06) ) (mlp): Qwen3MLP( (gate_proj): Linear(in_features=1024, out_features=3072, bias=False) (up_proj): Linear(in_features=1024, out_features=3072, bias=False) (down_proj): Linear(in_features=3072, out_features=1024, bias=False) (act_fn): SiLUActivation() ) (input_layernorm): Qwen3RMSNorm((1024,), eps=1e-06) (post_attention_layernorm): Qwen3RMSNorm((1024,), eps=1e-06) ) ) (norm): Qwen3RMSNorm((1024,), eps=1e-06) (rotary_emb): Qwen3RotaryEmbedding() ) ))
整体可训练参数仅占总参数量的 0.2688%, 从网络结构上可以看出,每一层的 q_proj、 k_proj、 v_proj 都增加了 lora_A 和 lora_B 通过降维再升维的方式,影响原始模型的效果。
数据集介绍
数据集下载地址:
https://modelscope.cn/datasets/modelscope/afqmc
数据量统计:
| 训练集(train.csv) | 验证集(dev.csv) | 测试集(test.csv) |
|---|---|---|
| 34,334 | 4,316 | 3,861 |
数据集格式如下所示:
sentence1,sentence2,label,id蚂蚁借呗等额还款可以换成先息后本吗,借呗有先息到期还本吗,0,0蚂蚁花呗说我违约一次,蚂蚁花呗违约行为是什么,0,1帮我看一下本月花呗账单有没有结清,下月花呗账单,0,2蚂蚁借呗多长时间综合评估一次,借呗得评估多久,0,3我的花呗账单是***,还款怎么是***,我的花呗,月结出来说让我还***元,我自己算了一下详细名单我应该还***元,1,4蚂蚁借呗的额度可以从申请不,蚂蚁借呗节假日可以借款吗,0,5
其中标签"1"表示sentence1与sentence2具有相似的含义;而标签"0"则表示两者含义不同。
这里可以统计下 train.csv 的 Token 数分布,以便后面训练时指定一个合理的 max_length:
from transformers import AutoTokenizerimport matplotlib.pyplot as pltimport pandas as pdplt.rcParams['font.sans-serif'] = ['SimHei']# 获取Token数def get_num_tokens(file_path, tokenizer): input_num_tokens = [] df = pd.read_csv(file_path) for index, row in df.iterrows(): sentence1 = row["sentence1"] sentence2 = row["sentence2"] tokens = len(tokenizer(sentence1, sentence2)["input_ids"]) input_num_tokens.append(tokens) return input_num_tokens# 计算分布def count_intervals(num_tokens, interval): max_value = max(num_tokens) intervals_count = {} for lower_bound in range(0, max_value + 1, interval): upper_bound = lower_bound + interval count = len([num for num in num_tokens if lower_bound <= num < upper_bound]) intervals_count[f"{lower_bound}-{upper_bound}"] = count return intervals_countdef main(): model_path = "Qwen/Qwen3-Embedding-0.6B" train_data_path = "dataset/train.csv" tokenizer = AutoTokenizer.from_pretrained(model_path) input_num_tokens = get_num_tokens(train_data_path, tokenizer) intervals_count = count_intervals(input_num_tokens, 20) print(intervals_count) x = [k for k, v in intervals_count.items()] y = [v for k, v in intervals_count.items()] plt.figure(figsize=(8, 6)) bars = plt.bar(x, y) plt.title('训练集Token分布情况') plt.ylabel('数量') for bar in bars: yval = bar.get_height() plt.text(bar.get_x() + bar.get_width() / 2, yval, int(yval), va='bottom') plt.show()if __name__ == '__main__': main()
```
数据集 `Token`量主要都分布在 `20-60` 之间,整体来看后面 `max_length` 可以设置为 `64` 。
二、微调训练
------
构建 `classify_qwen_dataset.py`
```plaintext
# -*- coding: utf-8 -*-from torch.utils.data import Datasetimport torchimport numpy as npimport pandas as pdclass ClassifyDataset(Dataset): def __init__(self, tokenizer, data_path, max_length) -> None: super().__init__() self.tokenizer = tokenizer self.max_length = max_length self.data = [] if data_path: df = pd.read_csv(data_path) for index, row in df.iterrows(): sentence1 = row["sentence1"] sentence2 = row["sentence2"] label = row["label"] self.data.append({ "sentence1": sentence1, "sentence2": sentence2, "label": label, }) print("data load , size:", len(self.data)) def preprocess(self, sentence1, sentence2, label): encoding = self.tokenizer.encode_plus( sentence1, sentence2, max_length=self.max_length, truncation=True, padding="max_length", return_tensors="pt" ) input_ids = encoding["input_ids"].squeeze() attention_mask = encoding["attention_mask"].squeeze() return input_ids, attention_mask, label def __getitem__(self, index): item_data = self.data[index] input_ids, attention_mask, label = self.preprocess(**item_data) return { "input_ids": torch.LongTensor(np.array(input_ids)), "attention_mask": torch.LongTensor(np.array(attention_mask)), "label": torch.LongTensor([label]) } def __len__(self): return len(self.data)
微调训练:
# -*- coding: utf-8 -*-import os.pathimport torchfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriterimport transformersfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationfrom classify_qwen_dataset import ClassifyDatasetfrom tqdm import tqdmimport time, sysfrom sklearn.metrics import f1_scorefrom peft import LoraConfig, get_peft_model, TaskTypetransformers.logging.set_verbosity_error()def train_model(model, train_loader, val_loader, optimizer, device, num_epochs, model_output_dir, scheduler, writer): batch_step = 0 best_f1 = 0.0 for epoch in range(num_epochs): time1 = time.time() model.train() for index, data in enumerate(tqdm(train_loader, file=sys.stdout, desc="Train Epoch: " + str(epoch))): input_ids = data['input_ids'].to(device) attention_mask = data['attention_mask'].to(device) label = data['label'].to(device) # 前向传播 outputs = model( input_ids=input_ids, attention_mask=attention_mask, labels=label ) loss = outputs.loss # 反向传播,计算当前梯度 loss.backward() # 更新网络参数 optimizer.step() # 清空过往梯度 optimizer.zero_grad() writer.add_scalar('Loss/train', loss, batch_step) batch_step += 1 # 100轮打印一次 loss if index % 100 == 0 or index == len(train_loader) - 1: time2 = time.time() tqdm.write( f"{index}, epoch: {epoch} -loss: {str(loss)} ; lr: {optimizer.param_groups[0]['lr']} ;each step's time spent: {(str(float(time2 - time1) / float(index + 0.0001)))}") # 验证 model.eval() accuracy, val_loss, f1 = validate_model(model, device, val_loader) writer.add_scalar('Loss/val', val_loss, epoch) writer.add_scalar('Accuracy/val', accuracy, epoch) writer.add_scalar('F1/val', f1, epoch) print(f"val loss: {val_loss} , val accuracy: {accuracy}, f1: {f1}, epoch: {epoch}") # 学习率调整 scheduler.step(f1) # 保存最优模型 if f1 > best_f1: best_f1 = f1 best_model_path = os.path.join(model_output_dir, "best") print("Save Best Model To ", best_model_path, ", epoch: ", epoch) model.save_pretrained(best_model_path) # 保存当前模型 last_model_path = os.path.join(model_output_dir, "last") print("Save Last Model To ", last_model_path, ", epoch: ", epoch) model.save_pretrained(last_model_path)def validate_model(model, device, val_loader): running_loss = 0.0 correct = 0 total = 0 y_true = [] y_pred = [] with torch.no_grad(): for _, data in enumerate(tqdm(val_loader, file=sys.stdout, desc="Validation Data")): input_ids = data['input_ids'].to(device) attention_mask = data['attention_mask'].to(device) label = data['label'].to(device) outputs = model( input_ids=input_ids, attention_mask=attention_mask, labels=label ) loss = outputs.loss logits = outputs['logits'] total += label.size(0) predicted = logits.max(-1, keepdim=True)[1] correct += predicted.eq(label.view_as(predicted)).sum().item() running_loss += loss.item() y_true.extend(label.cpu().numpy()) y_pred.extend(predicted.cpu().numpy()) f1 = f1_score(y_true, y_pred, average='macro') return correct / total * 100, running_loss / len(val_loader), f1 * 100def main(): # 基础模型位置 model_name = "Qwen/Qwen3-Embedding-0.6B" # 训练集 & 验证集 train_dataset_path = "dataset/train.csv" val_dataset_path = "dataset/dev.csv" max_length = 64 num_classes = 2 epochs = 15 batch_size = 128 lr = 1e-4 model_output_dir = "output" logs_dir = "logs" # 设备 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 加载分词器和模型 tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=num_classes) if model.config.pad_token_id is None: model.config.pad_token_id = tokenizer.pad_token_id peft_config = LoraConfig( task_type=TaskType.SEQ_CLS, target_modules=["q_proj", "k_proj", "v_proj"], inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1 ) model = get_peft_model(model, peft_config) model.print_trainable_parameters() print("Start Load Train Data...") train_params = { "batch_size": batch_size, "shuffle": True, "num_workers": 0, } training_set = ClassifyDataset(tokenizer, train_dataset_path, max_length) training_loader = DataLoader(training_set, **train_params) print("Start Load Validation Data...") val_params = { "batch_size": batch_size, "shuffle": False, "num_workers": 0, } val_set = ClassifyDataset(tokenizer, val_dataset_path, max_length) val_loader = DataLoader(val_set, **val_params) # 日志记录 writer = SummaryWriter(logs_dir) # 优化器 optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr) # 学习率调度器,连续两个周期没有改进,学习率调整为当前的0.8 scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'max', patience=2, factor=0.8) model = model.to(device) # 开始训练 print("Start Training...") train_model( model=model, train_loader=training_loader, val_loader=val_loader, optimizer=optimizer, device=device, num_epochs=epochs, model_output_dir=model_output_dir, scheduler=scheduler, writer=writer ) writer.close()if __name__ == '__main__': main()
训练过程如下:
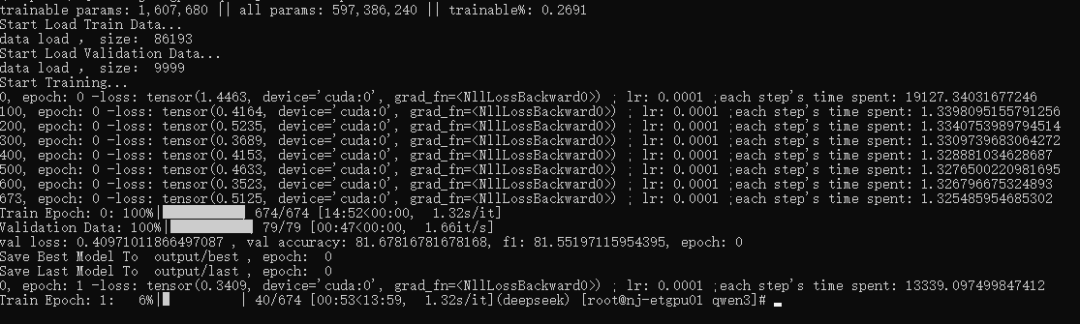
在 batch_size 在 128 的情况下,显存占用约 30.6G,如果你运行显存不足可适当缩小 batch_size 的大小,或者改为梯度累积的方式减少显存需求:
训练结束,在 dev 验证集上最好的表现 loss 为 0.4412,准确率为 83.17 ,F1:83.16 :
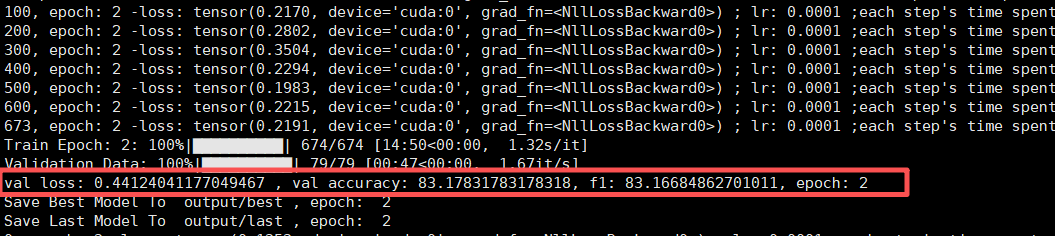
相比于之前用 chinese-roberta-wwm-ext 微调的效果略微逊色一些,之前的效果为准确率 85.1485 ,F1:85.1480
你也可以通过 tensorboard 查看你训练过程趋势:
tensorboard --logdir=logs --bind_all
在 浏览器访问 http:ip:6006/
三、模型使用测试
# -*- coding: utf-8 -*-import jsonfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationimport torchimport pandas as pddef main(): base_path = "Qwen/Qwen3-Embedding-0.6B" model_path = "output/best" test_path = "dataset/test.csv" max_length = 64 num_classes = 2 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") tokenizer = AutoTokenizer.from_pretrained(base_path) model = AutoModelForSequenceClassification.from_pretrained(model_path, num_labels=num_classes) model.to(device) classify = { 0: "语义不相关", 1: "语义相似" } df = pd.read_csv(test_path) for index, row in df.iterrows(): sentence1 = row["sentence1"] sentence2 = row["sentence2"] encoding = tokenizer.encode_plus( sentence1, sentence2, max_length=max_length, return_tensors="pt" ) input_ids = encoding["input_ids"].to(device) attention_mask = encoding["attention_mask"].to(device) outputs = model( input_ids=input_ids, attention_mask=attention_mask ) logits = outputs['logits'] predicted = logits.max(-1, keepdim=True)[1].item() print(f"{sentence1} - {sentence2} >>> {classify[predicted]}")if __name__ == '__main__': main()
```

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 12
12 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)