多模态大模型入门必学:一文搞懂CLIP算法核心原理,看到就是赚到,建议收藏!!
文章详细介绍了多模态大模型的基础算法CLIP(Contrastive Language-Image Pretraining)。通过对比学习,CLIP将图像和文本特征映射到同一语义空间,实现跨模态检索和零样本分类。文章以图文匹配和图像分类为例,详解了CLIP架构、zero-shot应用及训练思路,展示了如何通过文本和图像编码器将不同模态数据直接比较,为多模态应用奠定基础。
前言
多模态Multimodal,这个大方向可以认为是目前大语言模型的终极形态。
下面我尝试用一篇文章,将多模态背后的算法原理讲清楚。
其中包括6个部分:
1.什么是多模态?
2.CLIP算法从何而来?
3.一个经典案例
4.CLIP架构图详解
5.使用CLIP进行zero-shot
6.CLIP的训练思路
1.什么是多模态?
先来看一些简单的场景:
左侧是一个图像,右侧是一段文字:
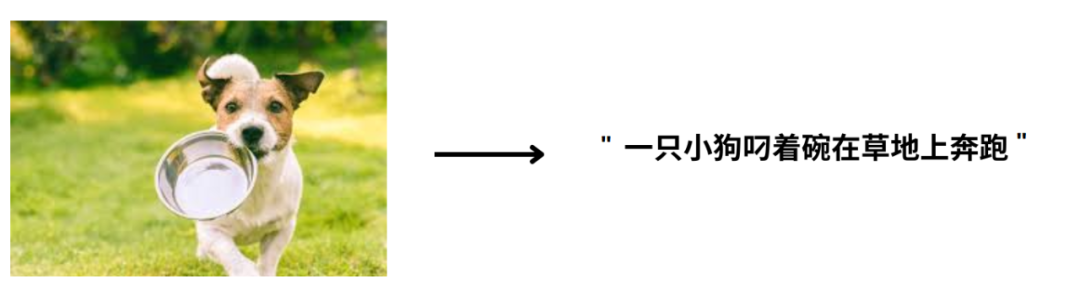
我们如何设计一个模型model,输入图像后,生成图像的文字描述呢?

或者输入一段文字描述,通过模型,生成符合文字描述的图像呢?
这两个问题:
前者是图生文问题,最典型的项目是VQA视觉问答;
后者是文生图问题,最典型的项目是Stable Diffusion图像生成。
图生文和文生图都是经典的多模态问题。
目前所有多模态应用,都起源于一个经典的多模态算法:
CLIP:Contrastive Language–Image Pretraining
语言-图像对比预训练算法。
可以认为,没学过CLIP,就没学过多模态。
下图是CLIP模型论文中的示意图,同学们可以整体先浏览一下:

今天我们就要深入讨论CLIP算法。
2.CLIP算法从何而来?
CLIP算法,于2021年,由OpenAI提出。
不得不说,OpenAI确实是AI行业的领导者和先锋。
在算法设计和产品应用的方方面面;
我们仍然有太多的东西需要向OpenAI学习。
虽然不能说多模态这个方向就是OpenAI提出的,
但可以说,因为OpenAI提出了CLIP算法,才使得多模态的概念真正落地到实处。
我们用一句话描述CLIP算法:
CLIP通过对比学习的方式;
将图像特征向量与文本特征向量映射到同一个的语义空间中;
从而建立图像和文本之间的联系。
我估计大部分同学一开始是理解不了上面斜体字的内容的;
“啥是对比学习”?
“啥是图像特征向量”?
“啥是文本特征向量”?
“啥是同一个的语义空间”?
…
3.一个经典案例
下面我们基于一个非常经典的例子;
感受一下CLIP算法的神奇之处。
假设有10个图像,这10个图像的文件名都是随机字母和数字。

如何通过一个句子“a dog on the grass”,找到与句子最匹配的图像呢?
由于图像的名称没有任何规律;
因此我们无法使用文本与图像名称匹配的方式,实现图片搜索。
我们需要基于图像本身包含的特征信息,进行搜索或匹配。
这时就要使用到CLIP架构了。
在CLIP架构中,有两种编码器:
文本编码器和图像编码器。
示意图如下:
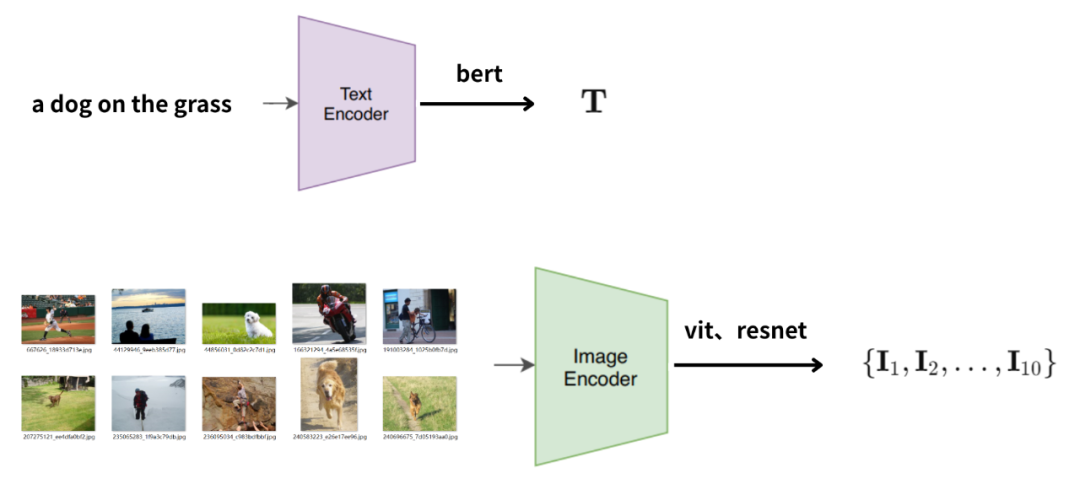
示意图描述了将一段文本描述和10张图片;
分别输入到文本编码器和图像编码器中,进行特征提取。
“a dog on the grass”的提取结果是向量T。
10张图片的提取结果是向量I1到I10。
关于文本编码器和图像编码器的设计,有很多方案:
例如,文本编码器可以使用bert;
图像编码器可以是vit或者resnet等等。
这些都是基础的Transformer或CNN架构。
文本编码器会计算出一条文本,定义为向量T;
图像编码器会计算出10个图像,定义为向量I1到I10。
接着,通过CLIP我们可以会将文本向量T和10个图像向量I;
映射到同一个d维实数空间中:
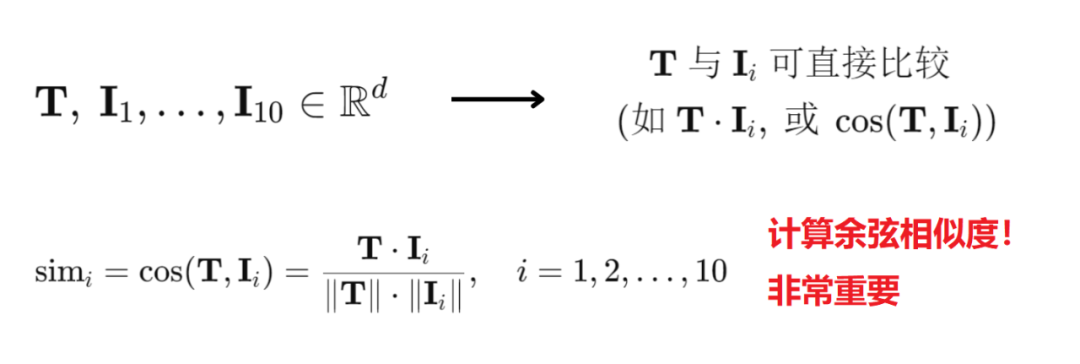
这样文本向量T和图像向量I1到I10之间,就可以直接进行比较或计算了。
在比较两个向量是否相似时,需要使用到一个数学常识:
余弦相似度。
这个概念我就不扩展来说了。
计算出T与I1到I10之间的余弦相似度simi后;
也就是T·I1、T·I2等等到T·I10,这些值;
然后将这些相似度排序。
最后选择排名靠前且达到一定相似度阈值的图片I;
就是基于文本T的查找结果了。
举个例子来说明上面的描述:

在上面的示意图中:
T·I3、T·I7、T·I10;
这三个余弦相似度最高,且达到一定数值;
那么第3张、第7张、第10张,这三张图;
就是文本a dog on the grass的查找结果。
4.CLIP架构图详解
那么如何将任意文本和图像,映射到同一个特征空间中;
使得文本和图片建立直接的语义联系呢?
这就是CLIP多模态模型需要解决的问题。
下面我们根据CLIP的架构图进行理解。
架构图出自字CLIP算法的原始论文:
Learning Transferable Visual Models From Natural Language Supervision
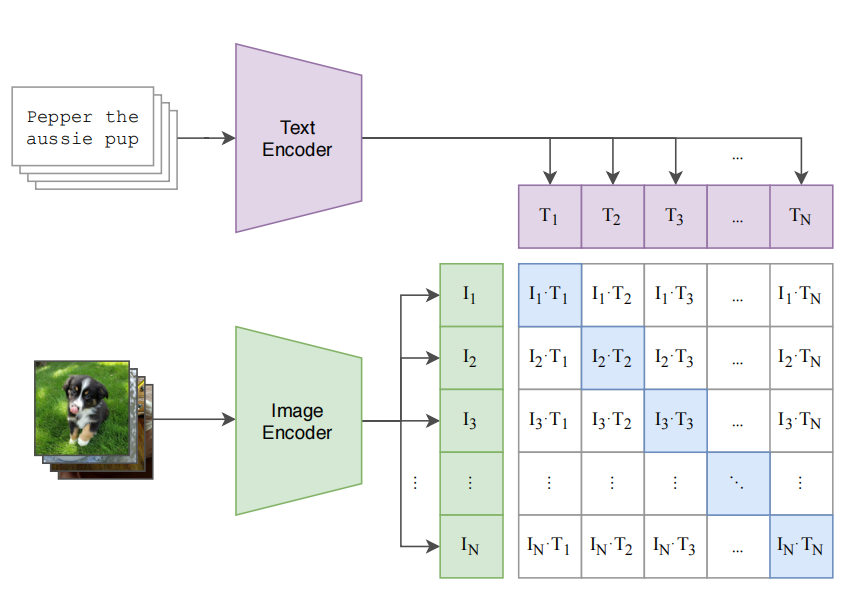
下面我们要仔细观察CLIP模型的结构示意图!
1)首先观察架构图中的数据
左上角是N个文本描述:
最上方的描述是“Pepper the aussie pup.”;
意思是“澳洲牧羊犬”。
左下角是N个文本描述对应的N个图像:
最上方是一只小狗在草地上;
可以看到文本描述和图像是一一对应的。
2)接着是文本和图像的编码器
紫色的文本编码器Text Encoder;
绿色的图像编码器Image Encoder;
前者将N个文本描述进行特征提取,得到T1到TN;
后者将N个图像进行特征提取,得到I1到IN。
3)结构图的右下方是一个N×N的矩阵
表示了N个图像向量和N个文本向量的点击运算;
对应了N个图像和N个文本的相似度。
例如,在矩阵的第1行中:
I1·T1表示了第1张图和第1个文本描述的点积;
即图片1和文本1的相似度。
这个矩阵中的数据表示了CLIP模型的训练数据。
其中对角线上的向量,I1·T1、I2·T2等等到IN·TN;
可以看做是正样本;
其余非对角线的向量是负样本;
其中具体的细节我们后面详细讨论。
5.使用CLIP进行zero-shot
实际上,CLIP模型中的参数:
就是文本编码器Text Encoder与图像编码器Image Encoder中的参数。
训练CLIP模型,就是分别训练文本编码器和图像编码器。
当完成CLIP模型的训练后;
我们就可以使用文本编码器和图像编码器;
分别对文本和图像进行计算,从而将文本和图像映射到同一个空间中。
这也是使用CLIP模型进行推理的过程。
关于CLIP模型的使用,有一个经典的案例:
zero-shot零样本分类任务。
接下来我们就讨论:
当完成CLIP的训练后,如何使用CLIP进行推理;
下图展示了使用CLIP进行zero-shot零样本分类任务的过程。

下面的讲解都围绕着上面的示意图展开来说明。
首先定义一些类别标签,例如plane、car、dog等等。
然后通过这些类别标签,构造对应的文本描述。
例如,A photo of a {},{}中的词是类别标签。
这样我们就构造出不同标签对应的描述文本。
有多少个类别,就构造多少个句子描述。
接着,将每个类别对应的句子描述,输入到紫色的文本编码器中;
计算出图中对应的向量T1、T2等等到TN。
此时我们要对一张狗的图像进行分类:
那么就将该图像输入到绿色的图像编码器后;
计算它的特征向量I1。
接着计算向量I1与所有标签对应的句子描述T1到TN的点击运算。
计算出的结果是:
I1·T1、I2·T2等等到I1·TN;
它们表示了这张狗的图像与所有类别描述文本的相似度。
我们会发现蓝色标记的I1·T3的值最大;
这就说明I1和T3最相似。
因为T3的语义信息是“A photo of a dog”;
那么就说明图像I1就是一张狗的图像;
因此最终dog,就是该图像的分类结果。
6.CLIP的训练思路
CLIP模型会基于大量的图像和文本对;
通过对比学习的预训练方法;
学习到一个图像与文本共享的语义空间。
在这个空间中,图像和文本的嵌入向量可以直接进行比较;
从而实现跨模态检索、零样本分类等任务。
为了理解CLIP的训练思路,
我们需要充分理解架构图中的N×N的矩阵:
对于这个N×N的矩阵:
矩阵的行是N个图像;
矩阵的列是N个文本描述。
矩阵整体表示了N张图像和N个文本描述之间的关系。
其中N表示了是梯度下降时所使用的小批量的数量。
例如,假设有10万条训练数据,即10万条文本图像对。
如果使用小批量梯度下降算法训练CLIP:
例如设置小批量的数量batch_size=128;
那么架构图中的相似度矩阵的大小N,就是128。
我们继续观察这个矩阵:
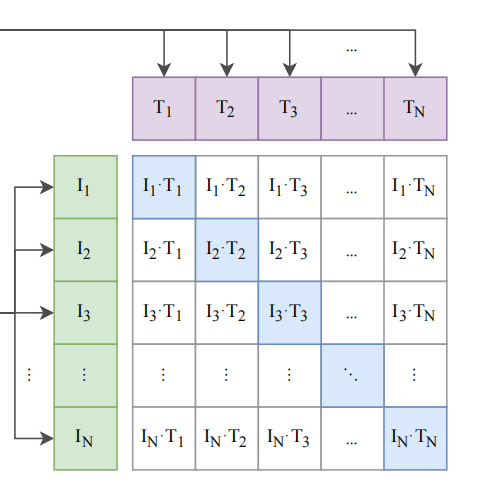
因为N张图对应了N个文本描述;
每一对图和文本,表达了相同的“语义”。
这就说明:
第1张图和第1个文本描述匹配;
第2张图和第2个文本描述匹配;
…
第N张图应该和第N个文本描述匹配。
也就是对角线上的元素表示了匹配的文本和图像;
非对角线上的元素表示了不匹配的文本和图像。
将N×N的矩阵抽象为下面这个表格:
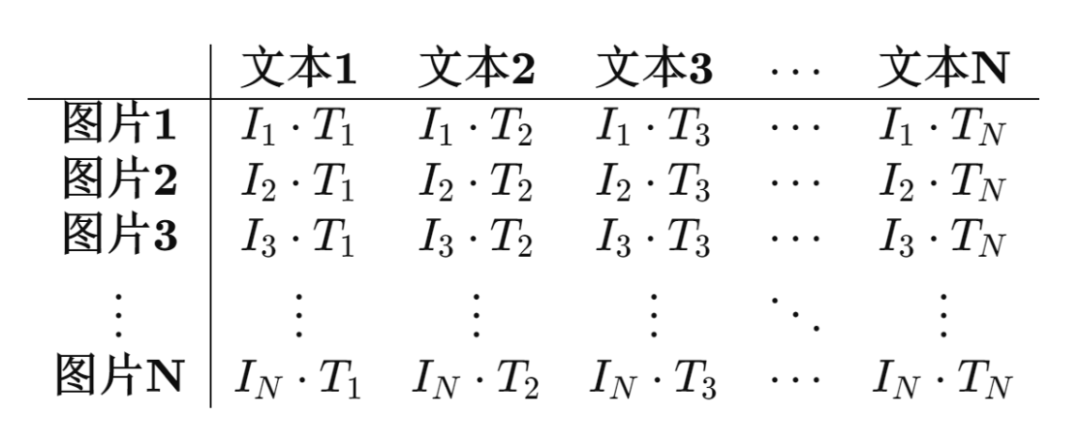
此时就引出了CLIP模型的训练思路。
当图像和文本匹配时:
那么它们的向量是相似的;
否则它们的向量不相似。
因此我们希望对角线上的元素:
I1·T1;
I2·T2;
…;
IN·TN;
这些向量点积表示的余弦值,应该尽可能接近1。
非对角线上的向量乘积,表示的是不匹配的图像和文本;
因此这些乘积的值应该尽可能接近0。
按照这样的思路:
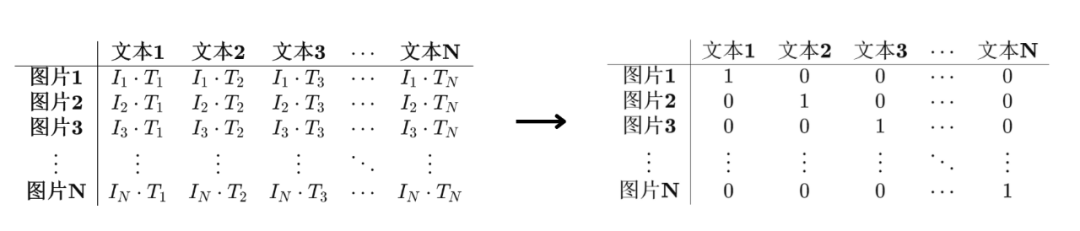
我们将匹配的图像和文本对的向量乘积看做是正样本;
将不匹配的图像和文本对的向量乘积看做是负样本;
进行模型的训练。
也就是说,当完成CLIP模型的训练后;
新的文本或者图像进入文本编码器和图像编码器的计算;
可以使得匹配的文本和图像对的向量乘积接近1;
不匹配的文本和图像对的向量乘积接近0。
举个例子,N=3:

图中包括了3个图文对。
图像向量是I1、I2、I3;
文本向量是T1、T2、T3;
此时得到了一个3×3大小的相似度矩阵。
我们会将(I1, T1)、(I2, T2)、(I3, T3);
这三组图像文本对,看做是正样本,标记为1;
其余图像文本对组合,看做是负样本,标记为0;
使用这些样本训练CLIP模型。
完成训练后:
3×3矩阵对角线上的元素会接近1,其余元素接近0。
最终我们就会训练出:

可以将文本和图像统一到同一个向量空间中的:
文本编码器和图像编码器。
也就是说,未来多模态模型在使用时;
使用的是两种模态的编码器。
说到这,今天的讲解也就结束了。
大家是不是已经了解了,多模态最核心的思想呢?
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 19
19 0
0- 0



 已为社区贡献107条内容
已为社区贡献107条内容

所有评论(0)