IndexTTS2参考音频处理技巧:提升克隆准确率
本文介绍了基于星图GPU平台自动化部署indextts2-IndexTTS2 最新 V23版本的全面升级情感控制更好 构建by科哥镜像的方法,结合高质量参考音频处理技巧,显著提升语音克隆准确率。该方案适用于AI语音合成、情感化TTS应用开发等场景,助力高效构建自然流畅的个性化语音服务。
IndexTTS2参考音频处理技巧:提升克隆准确率
1. 引言
随着语音合成技术的不断演进,IndexTTS2 在最新 V23 版本中实现了全面升级,尤其在情感控制能力方面显著增强。该版本由科哥团队构建并优化,进一步提升了语音克隆的自然度与表现力。然而,高质量的语音输出不仅依赖于模型本身,更与输入的参考音频质量密切相关。
在实际使用中,许多用户发现即使使用相同的模型参数,不同参考音频生成的结果差异较大。这背后的核心原因在于:参考音频的预处理方式直接影响语音特征提取的准确性。本文将系统性地介绍如何科学处理参考音频,帮助用户最大化发挥 IndexTTS2 V23 的潜力,显著提升语音克隆的准确率和自然度。
2. 参考音频的关键影响因素
2.1 音频质量基础要求
IndexTTS2 基于深度声学建模进行语音风格迁移,其性能高度依赖输入参考音频的信噪比和清晰度。以下是推荐的技术指标:
- 采样率:建议使用 16kHz 或 24kHz(自动重采样支持,但原始质量越高越好)
- 位深:16-bit 以上
- 声道数:单声道(Mono)为佳,避免立体声引入相位干扰
- 格式:WAV 或 MP3(优先选择无损 WAV)
核心提示:低质量录音(如手机远场录制、背景嘈杂)会导致音色建模偏差,表现为“机械感”或“模糊发音”。
2.2 情感表达与语调稳定性
V23 版本增强了对情感维度的建模能力,能够捕捉细微的情绪变化(如喜悦、悲伤、严肃)。因此,参考音频中的情感一致性至关重要:
- 若目标是中性播报风格,应选择语气平稳、无明显情绪波动的音频
- 若需特定情感克隆(如客服热情语调),则参考音频必须包含对应的情感特征
- 避免在同一段参考音频中混杂多种情绪,否则模型难以收敛到统一风格
2.3 语音内容长度与信息密度
实验表明,最佳参考音频时长为 3~8 秒:
- 过短(<2s):不足以提取稳定的音色和韵律特征
- 过长(>15s):可能包含过多语义变化,导致风格漂移
同时,建议语音内容包含丰富的音素覆盖(phoneme coverage),例如:
- 包含元音 /a/, /i/, /u/ 和辅音 /p/, /t/, /k/ 等基本发音
- 推荐使用句子:“今天天气真不错,适合出去散步。”——涵盖常见汉语拼音组合
3. 参考音频预处理实践指南
3.1 噪声抑制与静音裁剪
使用开源工具 Audacity 或命令行工具 sox 对原始音频进行清洗:
# 使用 sox 降噪(先录制一段纯噪声作为噪声样本)
sox noise_sample.wav -n noiseprof profile.noise
sox input.wav output_denoised.wav noisered profile.noise 0.21
# 自动裁剪首尾静音
sox output_denoised.wav final_clean.wav silence -l 1 0.1 1% -1 0.1 1%
silence -l参数确保保留语音中间的合理停顿- 噪声抑制强度建议控制在 0.1~0.3 之间,过高会损伤人声音质
3.2 音量归一化与动态范围压缩
语音克隆对响度敏感,过低或过高的音量会影响梅尔频谱提取。推荐进行标准化处理:
from pydub import AudioSegment
import numpy as np
def normalize_audio(input_path, output_path, target_dBFS=-16):
audio = AudioSegment.from_file(input_path)
change_in_dBFS = target_dBFS - audio.dBFS
normalized = audio.apply_gain(change_in_dBFS)
normalized.export(output_path, format="wav")
# 调用示例
normalize_audio("raw.wav", "normalized.wav")
- 目标响度设为 -16 dBFS 是语音合成领域的通用标准
- 避免使用峰值归一化(peak normalization),容易造成爆音
3.3 分离人声与背景音乐(可选高级操作)
若参考音频来自视频或带背景音乐的录音,建议使用 Demucs 进行人声分离:
pip install demucs
# 分离音频
demucs --two-stems=vocals your_audio.mp3 -o output_dir/
# 输出路径:output_dir/vocals/your_audio.wav
- 处理后仅使用
vocals文件夹下的文件作为参考音频 - 此步骤可大幅提升干净度,尤其适用于影视片段提取场景
4. WebUI 使用流程与最佳实践
4.1 启动与访问界面
进入项目目录并启动服务:
cd /root/index-tts && bash start_app.sh
成功启动后,浏览器访问:
http://localhost:7860
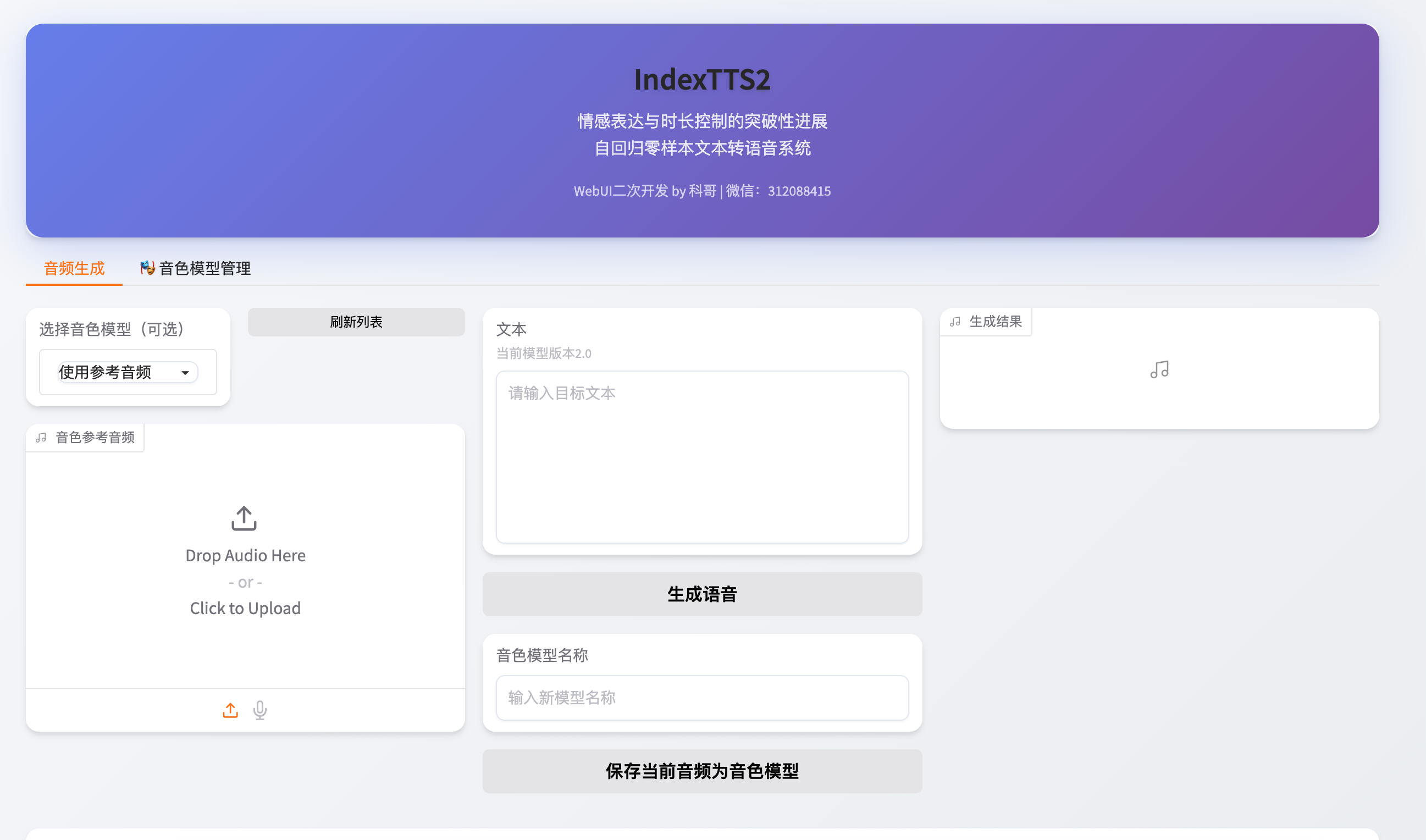
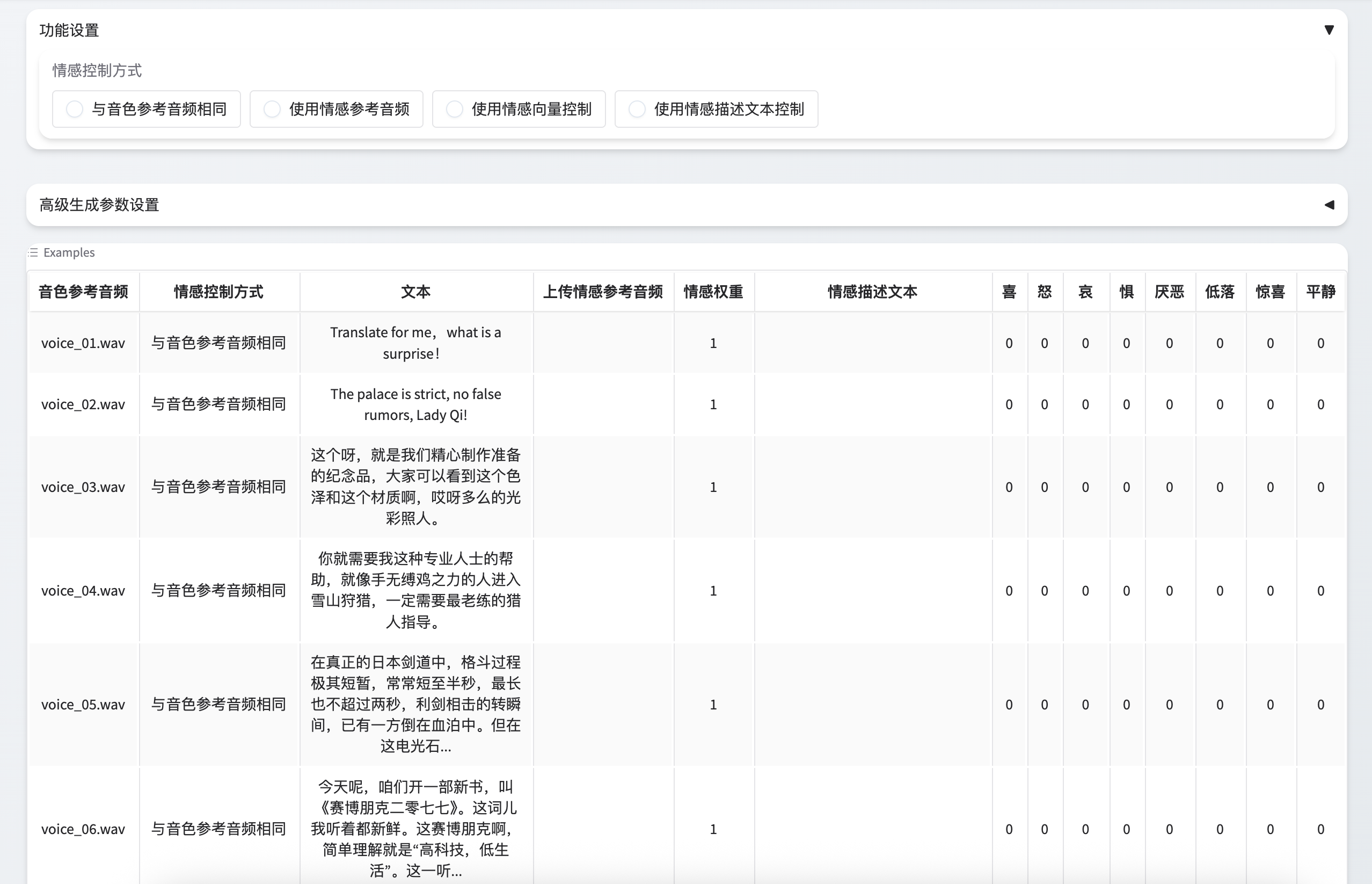
4.2 关键参数配置建议
在 WebUI 中上传预处理后的参考音频,并调整以下参数以获得最优效果:
| 参数 | 推荐值 | 说明 |
|---|---|---|
Reference Text |
准确填写参考音频文本 | 提高音素对齐精度 |
Style Text |
与输出文本一致或留空 | 控制风格迁移强度 |
Style Weight |
0.7 ~ 1.2 | 数值越大越贴近参考风格 |
Audio Length |
根据需求设定 | 长文本建议分段合成 |
经验法则:首次尝试时将
Style Weight设为 1.0,观察效果后再微调 ±0.2。
4.3 批量处理与自动化脚本(进阶)
对于高频使用场景,可通过 API 模式批量处理:
import requests
url = "http://localhost:7860/tts"
data = {
"text": "欢迎使用IndexTTS2语音合成系统",
"ref_audio_path": "/path/to/clean_reference.wav",
"ref_text": "这是一个清晰的人声录音",
"style_weight": 1.0
}
response = requests.post(url, json=data)
with open("output.wav", "wb") as f:
f.write(response.content)
- 需提前启动
webui.py并启用 API 支持 - 可结合 Shell 脚本实现每日任务自动化
5. 常见问题与避坑指南
5.1 合成语音失真或断续
可能原因:
- 参考音频信噪比过低
- 显存不足导致推理中断(检查日志是否报 CUDA OOM)
- 输入文本含有未登录词(OOV)
解决方案:
- 重新采集或清洗参考音频
- 升级至至少 4GB 显存环境
- 添加拼音标注或替换生僻字
5.2 音色偏离预期
典型表现:听起来像“另一个人”或“机器味重”
排查方向:
- 检查参考音频是否经过过度压缩(如微信语音转录)
- 确认未使用变声器或KTV模式录制
- 尝试更换更短、更集中的参考片段(3秒内)
5.3 情感表达不充分
尽管 V23 支持情感控制,但仍需注意:
- 不要期望模型“无中生有”地生成参考音频中不存在的情感
- 如需愤怒语气,请提供真实愤怒语调的参考音频
- 可通过
Style Text输入情感关键词辅助引导(如“激动地”、“温柔地说”)
6. 总结
IndexTTS2 V23 版本在情感建模和语音自然度方面取得了重要突破,但其最终表现仍高度依赖于参考音频的质量与处理方式。本文系统梳理了从音频采集、预处理到 WebUI 配置的全流程最佳实践,重点强调以下几点:
- 高质量输入是前提:使用清晰、无噪、单声道的 WAV 音频作为参考源
- 科学预处理不可少:通过降噪、归一化、静音裁剪等手段提升信噪比
- 情感一致性是关键:确保参考音频与目标输出风格匹配
- 参数调优需迭代:合理设置
Style Weight等参数,逐步逼近理想效果
遵循上述方法,用户可在现有硬件条件下显著提升语音克隆的准确率与自然度,充分发挥 IndexTTS2 的技术优势。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 8
8 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)