YOLOv8 超详细小白教程(毕设必看)——Windows、PyCharm +conda+ LabelImg +GPU训练自己数据集训练
目录
YOLOv8 超详细小白教程(毕设必看)——Windows、PyCharm +conda+ LabelImg +GPU训练自己数据集训练
二、GPU 环境配置(Windows + NVIDIA CUDA)
2. 启动 LabelImg,在cmd中输入labelimg
YOLOv8 超详细小白教程(毕设必看)——Windows、PyCharm +conda+ LabelImg +GPU训练自己数据集训练
YOLOv8 是 Ultralytics 最新推出的目标检测与实例分割模型,训练速度快、效果好,非常适合毕业设计。本文将从 环境安装、GPU 配置、PyCharm 使用、LabelImg 数据标注、训练自己数据集 全流程详细讲解,让小白也能轻松上手。
一、PyCharm 安装(保姆级)
1. 下载与安装
-
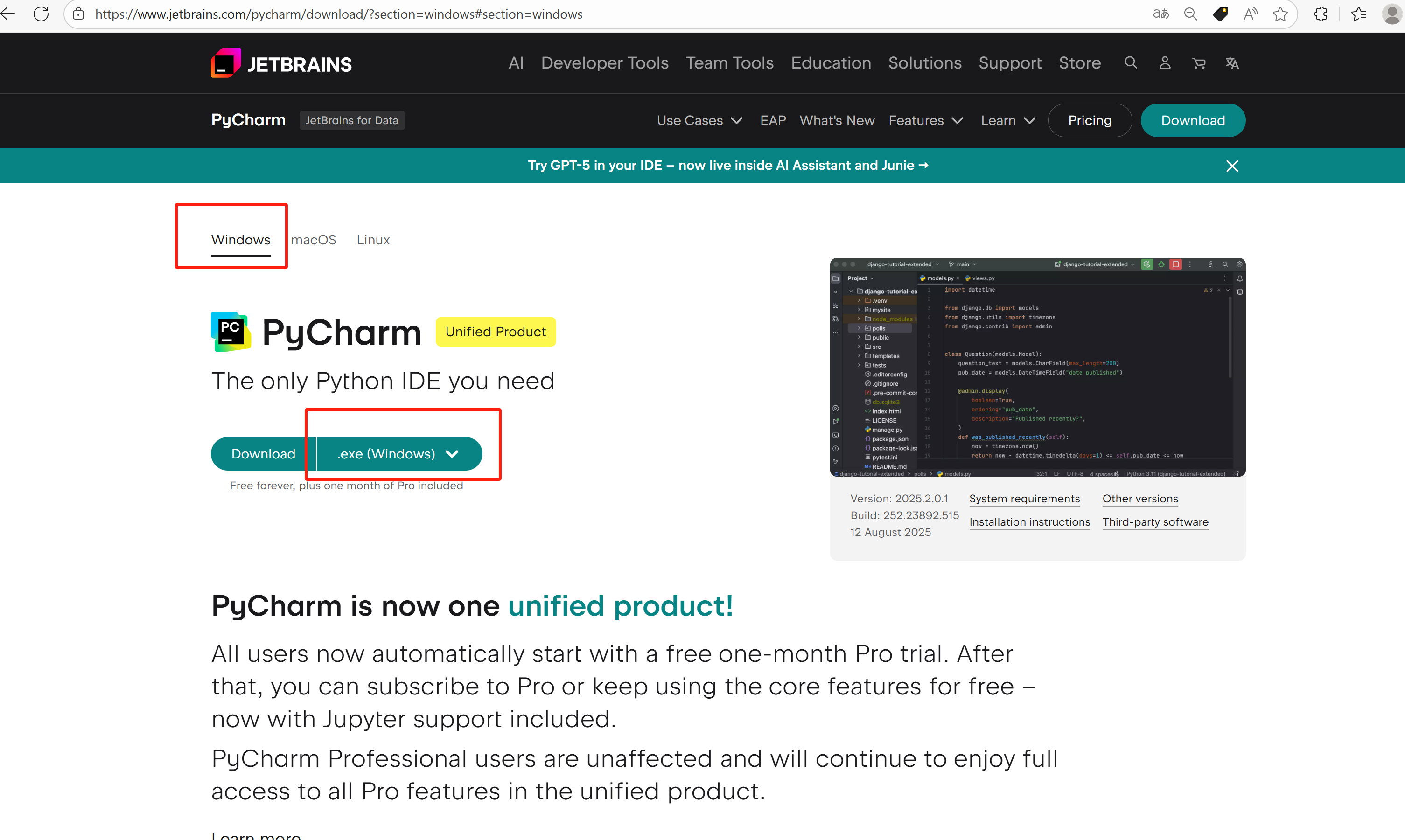
访问官网:Download PyCharm: The Python IDE for data science and web development by JetBrains
-
下载 Community(免费)或 Professional 版本
-
双击安装包 → Next → 选择路径 → 勾选“Add to PATH”和“Create Desktop Shortcut” → Install → Finish
2. 配置 Python 环境(conda创建虚拟环境)
桌面右击,在终端打开。输入下面指令
conda create -n yolov8 python=3.8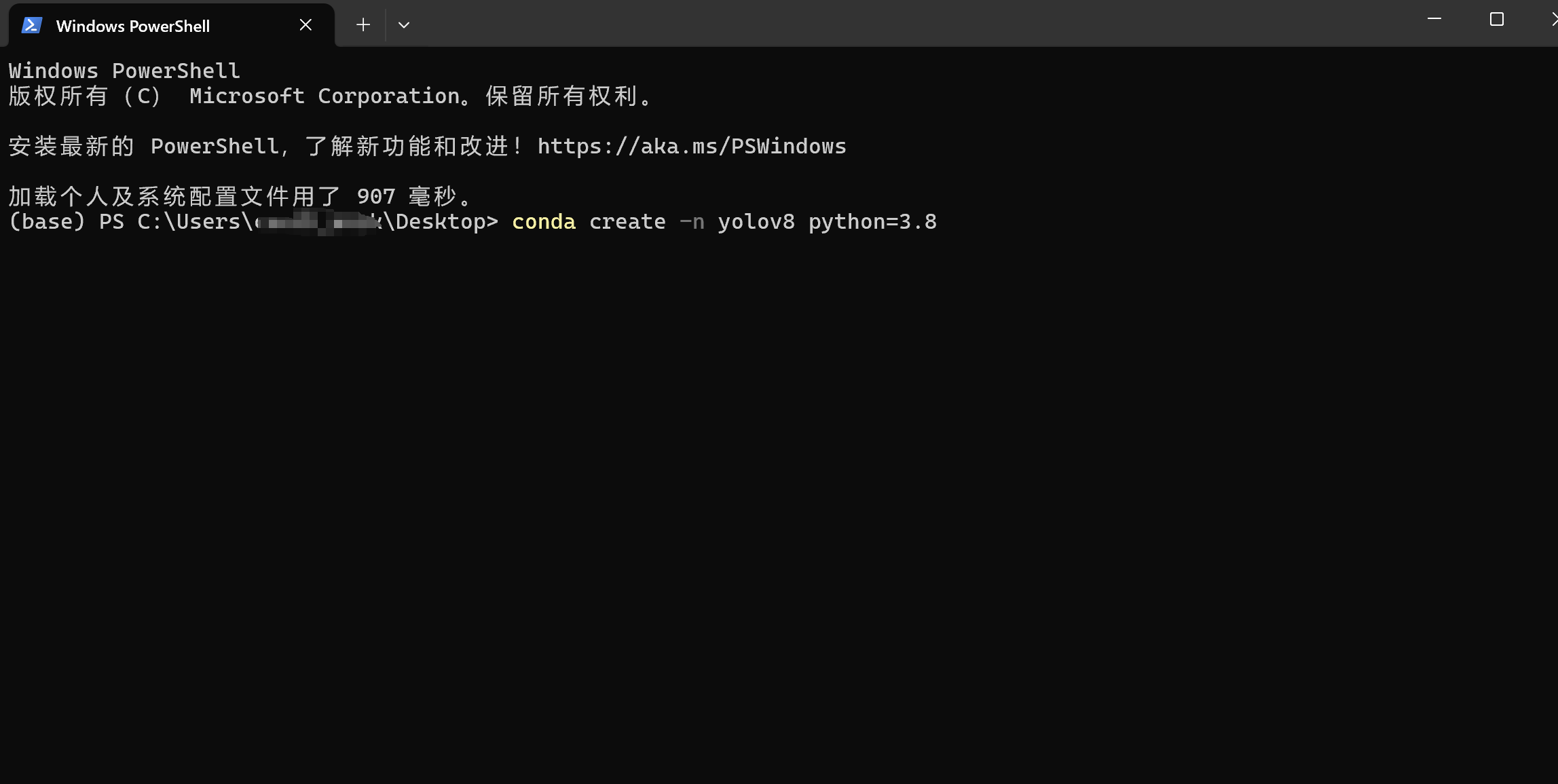
conda activate yolov8pip install ultralytics==8.0.73我用的是8.0.73的版本,和我其他项目关联比较深。太新的版本,有时候兼容性有问题。
3. 下载yolov8源码,在pycharm中进行配置
源码地址:https://github.com/ultralytics/ultralytics/tree/v8.0.73
-
打开 PyCharm →
File → Settings → Project → Python Interpreter → Add -
选择 Conda Environment(推荐 GPU 环境用 conda)或 System Interpreter
-
安装必要库(可后续用 pip 安装 YOLOv8、torch 等)
下载好解压之后用pycharm进行打开,然后把interpreter设置为刚刚创建的虚拟环境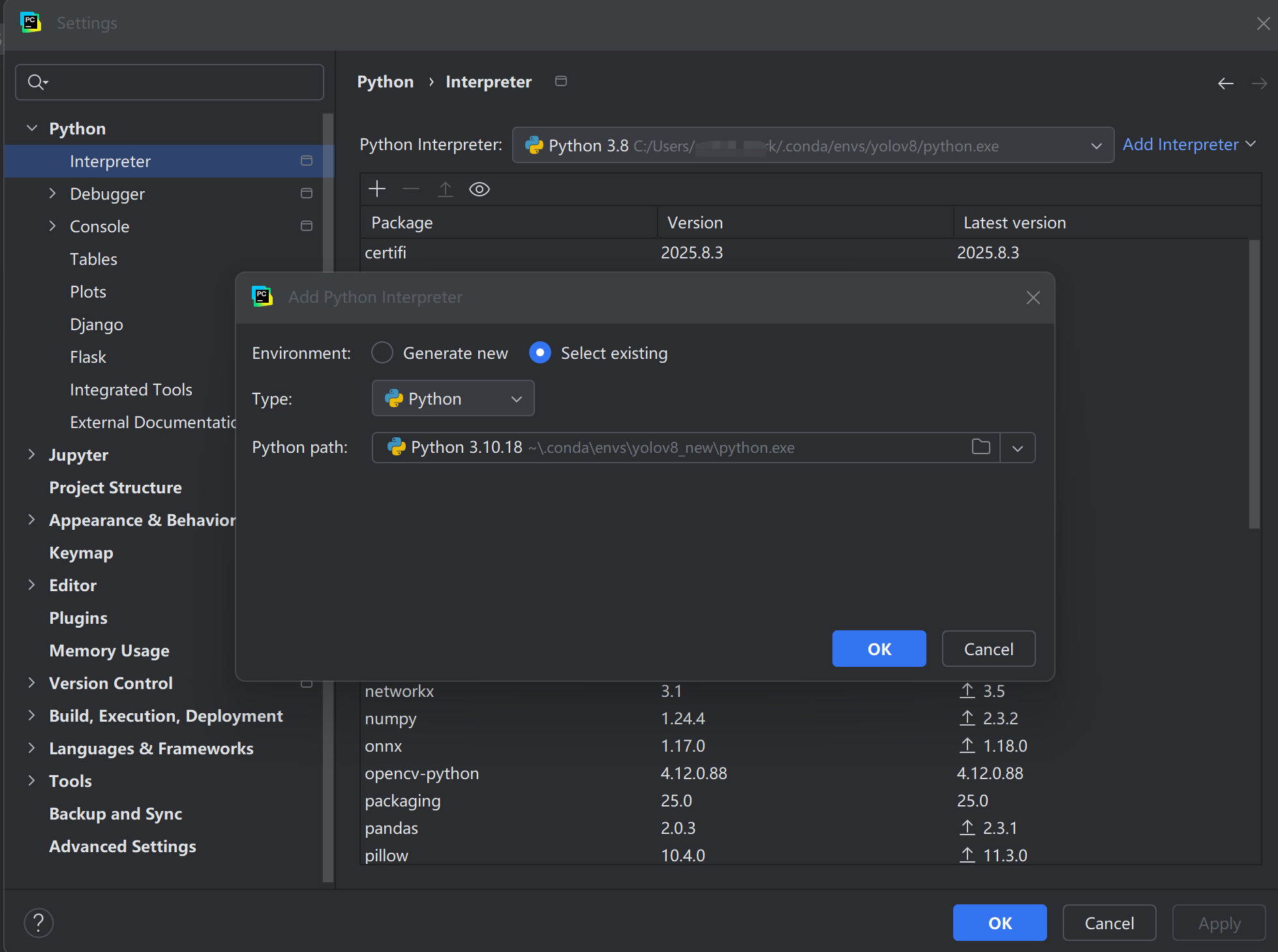
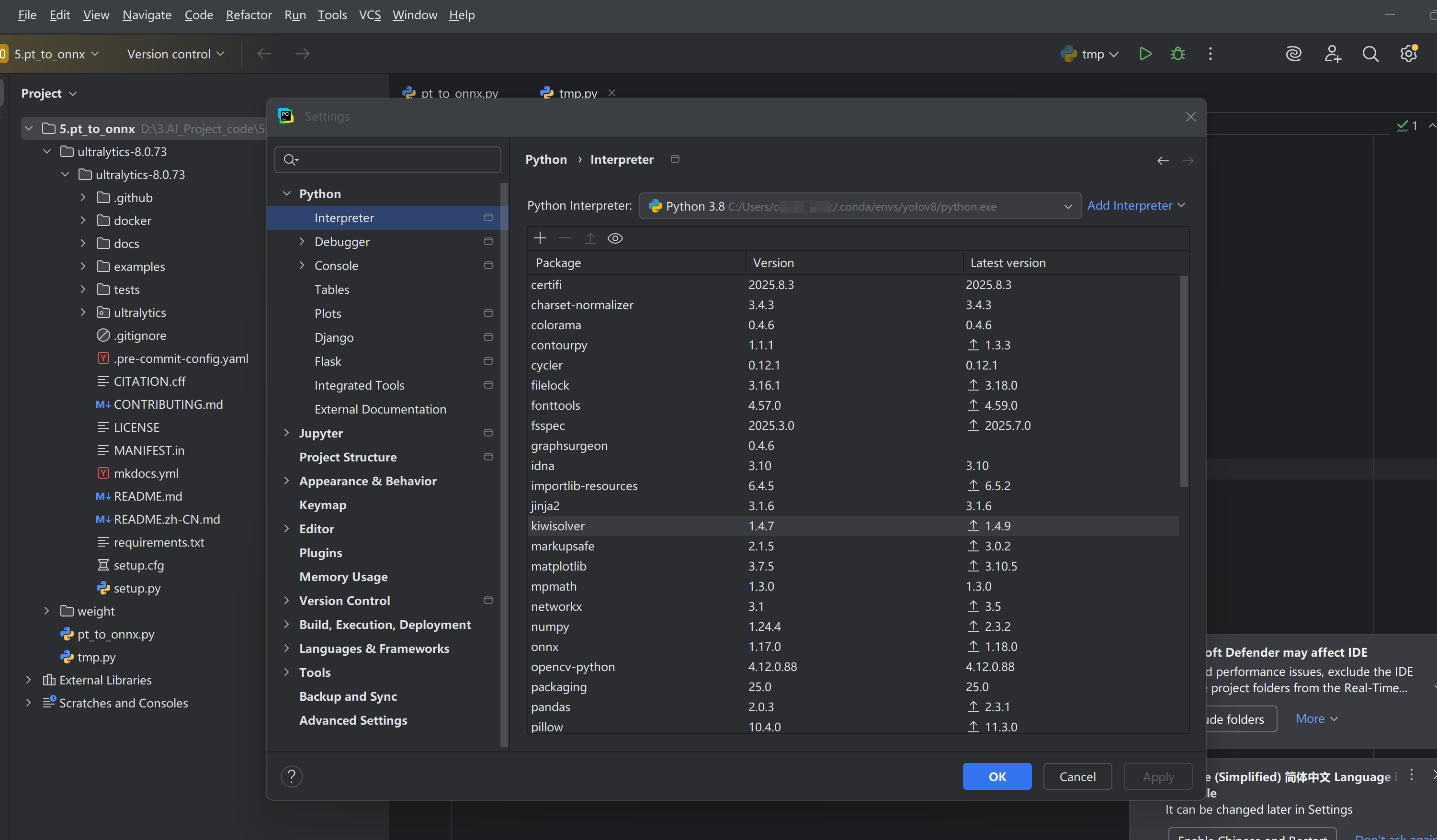
安装验证
新建一个python文件
from ultralytics import YOLO
model = YOLO('yolov8n.pt') # 加载官方预训练模型
model.info() # 查看模型信息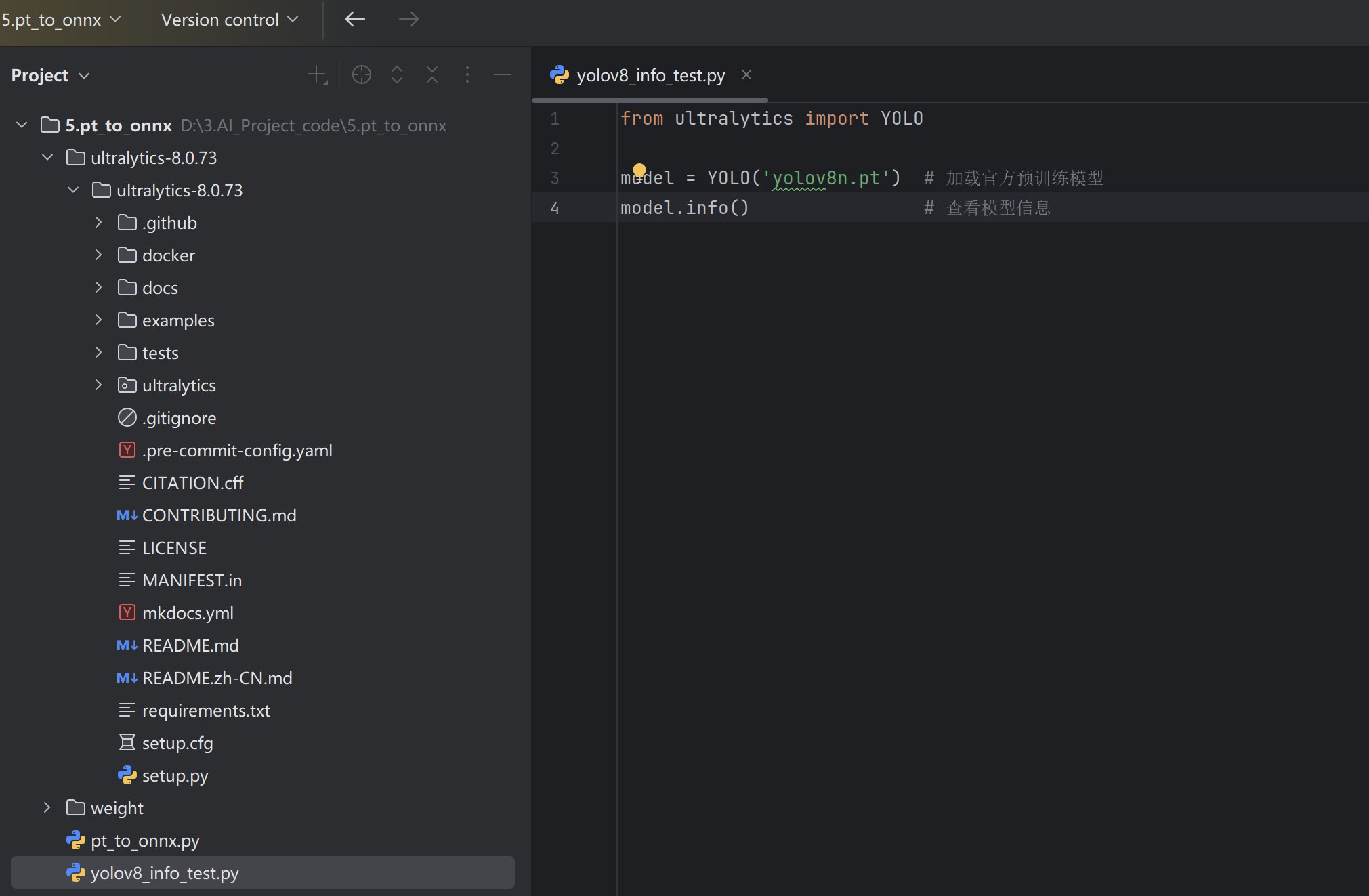 这里面的yolov8n.pt是预训练权重。
这里面的yolov8n.pt是预训练权重。
预训练权重的下载:源码下载界面中的docs/tasks/detect文件中往下翻,找到yolovn8的预训练权重,点击下载,然后把下载好的文件放在项目代码的根目录下。
二、GPU 环境配置(Windows + NVIDIA CUDA)
YOLOv8 可以使用 GPU 提升训练速度,以下是详细步骤:
1. 检查 GPU
在命令行输入:
nvidia-smi
如果显示显卡信息,说明 GPU 驱动正常。
2. 安装 CUDA & cuDNN(参考上一篇博客)
参考地址:【保姆级】在Windows系统环境下安装CUDA 11.8和cuDNN v8.9.0的详细指南,配套tensorrt8.6使用-CSDN博客
-
下载对应显卡的 CUDA Toolkit
-
下载 cuDNN,并解压到 CUDA 安装目录
-
配置系统环境变量:
-
CUDA_HOME→ CUDA 安装路径 -
PATH→ 添加bin文件夹
-
-
验证:
nvcc -V
3. 安装 GPU 版 PyTorch
访问 Get Started
选择 CUDA 版本,复制命令安装,例如:
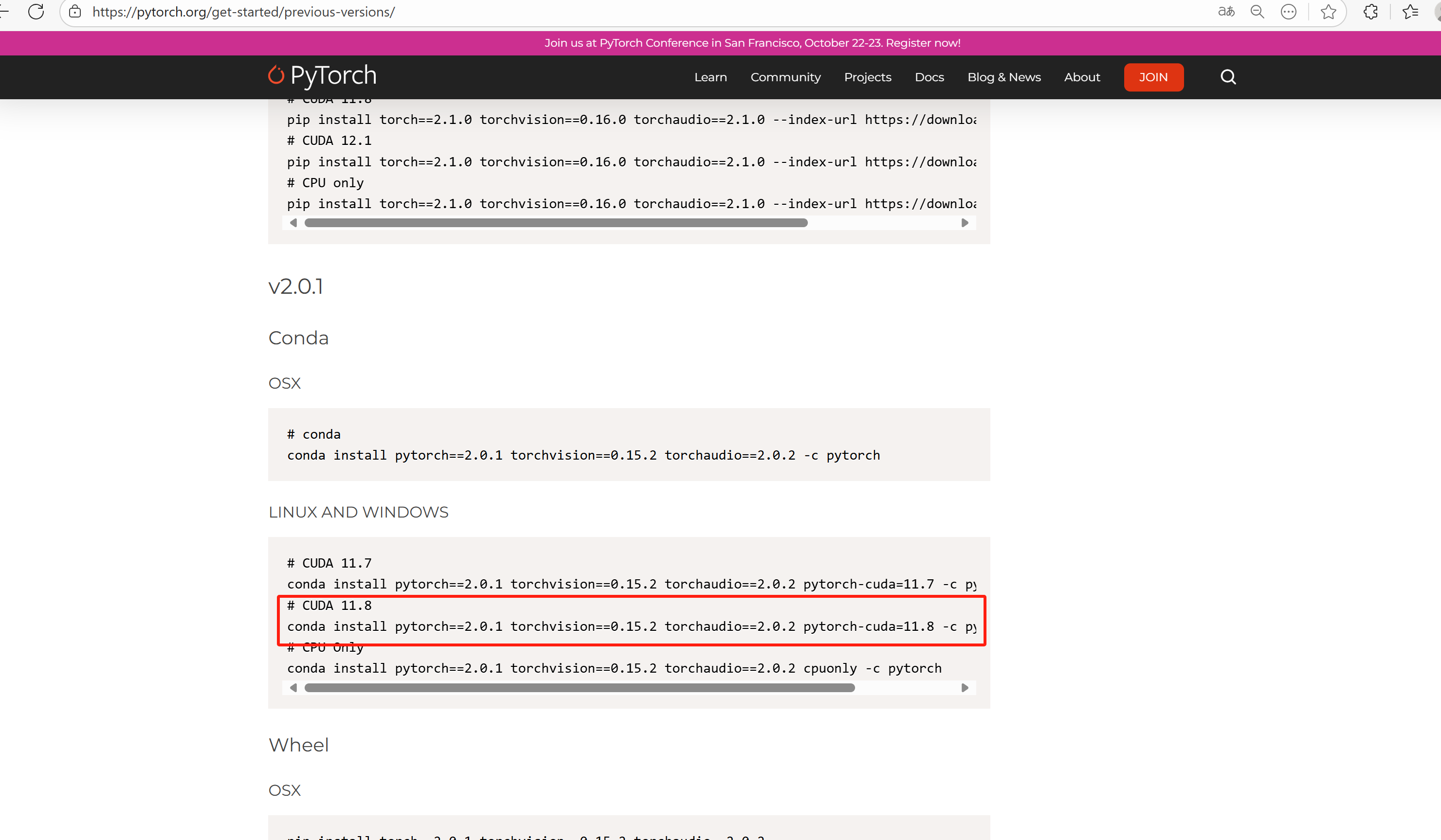 我选择的是pytorch==2.0.1,cuda11.8。
我选择的是pytorch==2.0.1,cuda11.8。
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
三、LabelImg 标注(标注自己数据集)
1. 安装 LabelImg
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple2. 启动 LabelImg,在cmd中输入labelimg
labelimg
-
选择图片文件夹 → 标注目标 → 保存为VOC格式
-
注意标注类别要统一(训练时类别名需和 YAML 一致)
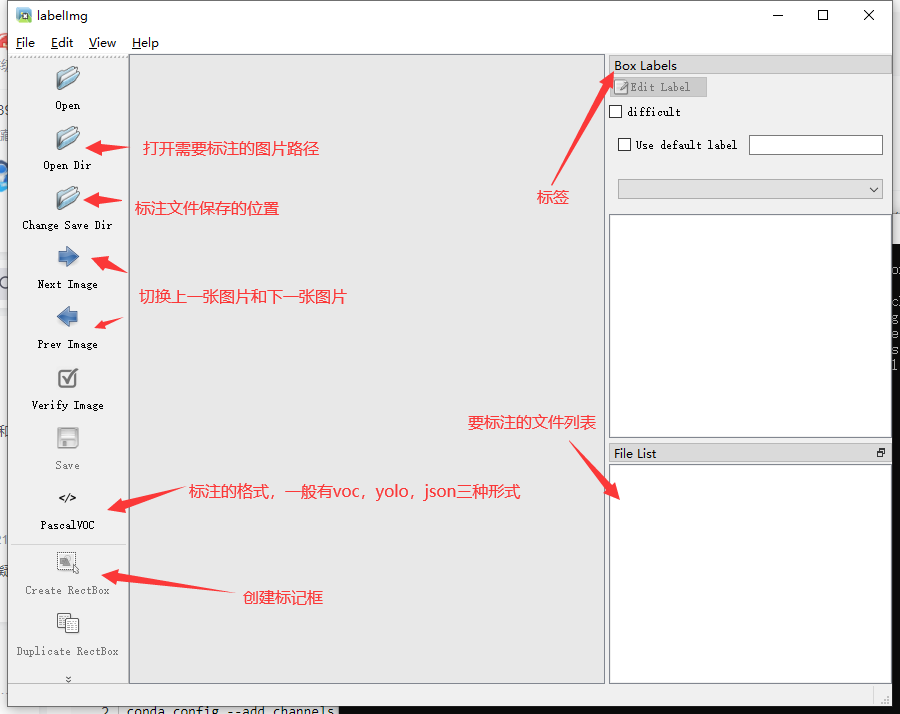
打开后,我们自己设置一下
在View中勾选Auto Save mode
 接下来我们打开需要标注的图片文件夹
接下来我们打开需要标注的图片文件夹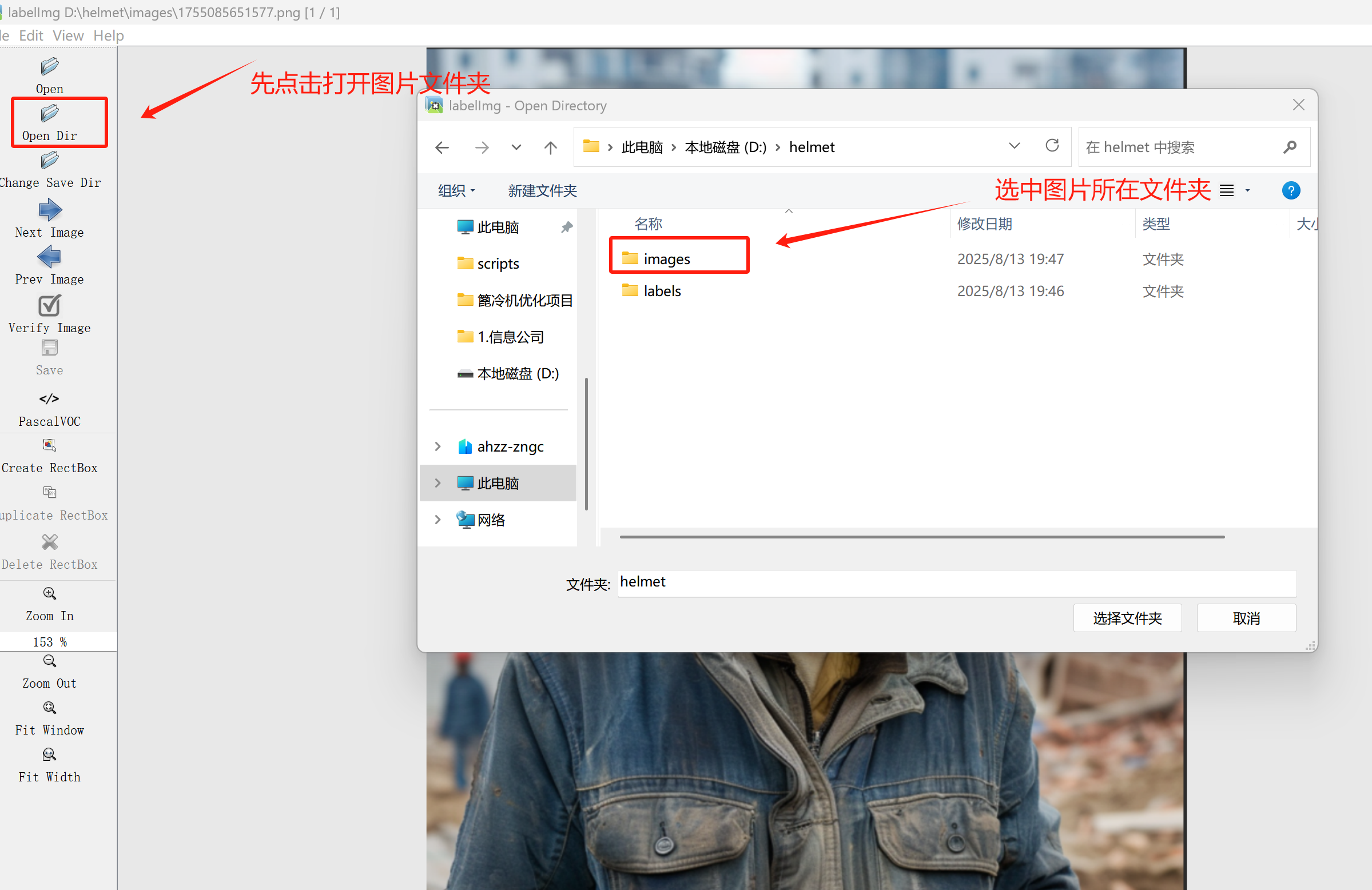
并设置标注文件保存的目录(上图中的Change Save Dir)
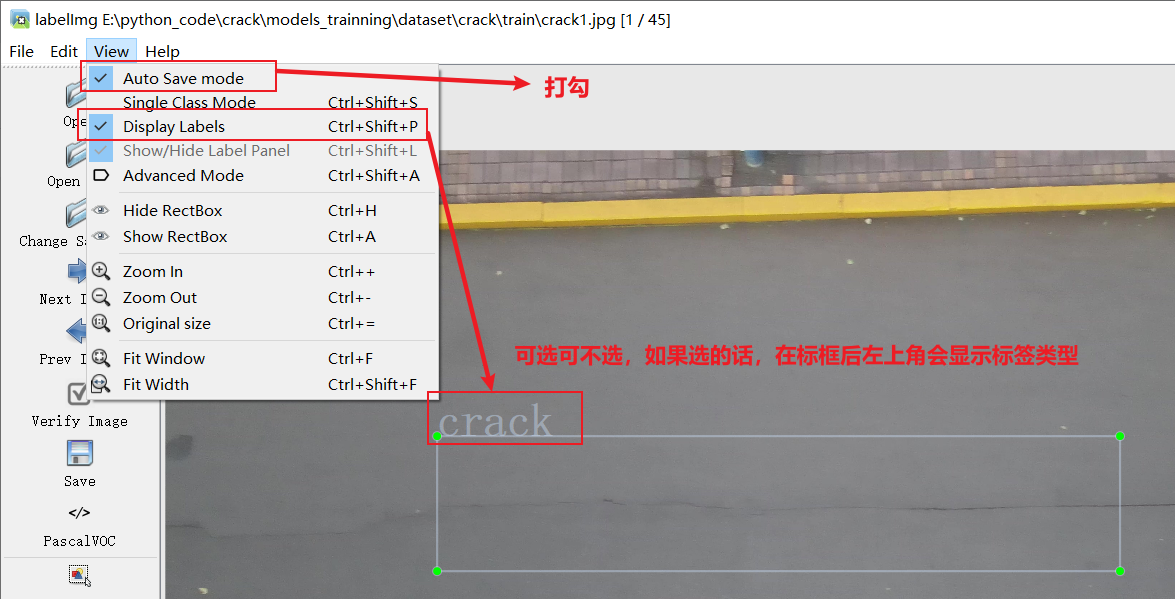
接下来就开始标注,画框,标记目标的label,然后d切换到下一张继续标注,不断重复重复。

-
一般使用W和D ,这里大家可以去试试,用上快捷键后,标注速度肯定会得到提升。
3. 转换为 YOLO 格式
如果打标签的时候,直接选择的yolo,就可以直接用。不用转换,如果是其他格式,在这里就需要转换一下。
4. 整理数据集结构
YOLOv8 数据集推荐结构:
dataset/
├── images/
│ ├── train/
│ └── val/
├── labels/
│ ├── train/
│ └── val/
四、自定义 YOLOv8 数据集训练
1. 创建数据集 YAML 文件
dataset.yaml:
train: dataset/images/train
val: dataset/images/val
nc: 3 # 类别数
names: ['cat', 'dog', 'person'] # 类别名称
2. 开始训练
方法一:bash
yolo detect train data=dataset.yaml model=yolov8n.pt epochs=100 imgsz=640 batch=16 device=0
参数说明:
-
model=yolov8n.pt→ 预训练模型 -
epochs→ 训练轮数 -
imgsz→ 输入图片尺寸 -
batch→ 每批大小 -
device=0→ 使用 GPU 0
方法二:创建train_helmet.py文件(推荐)
首先把自己的数据集,新增一个yaml文件。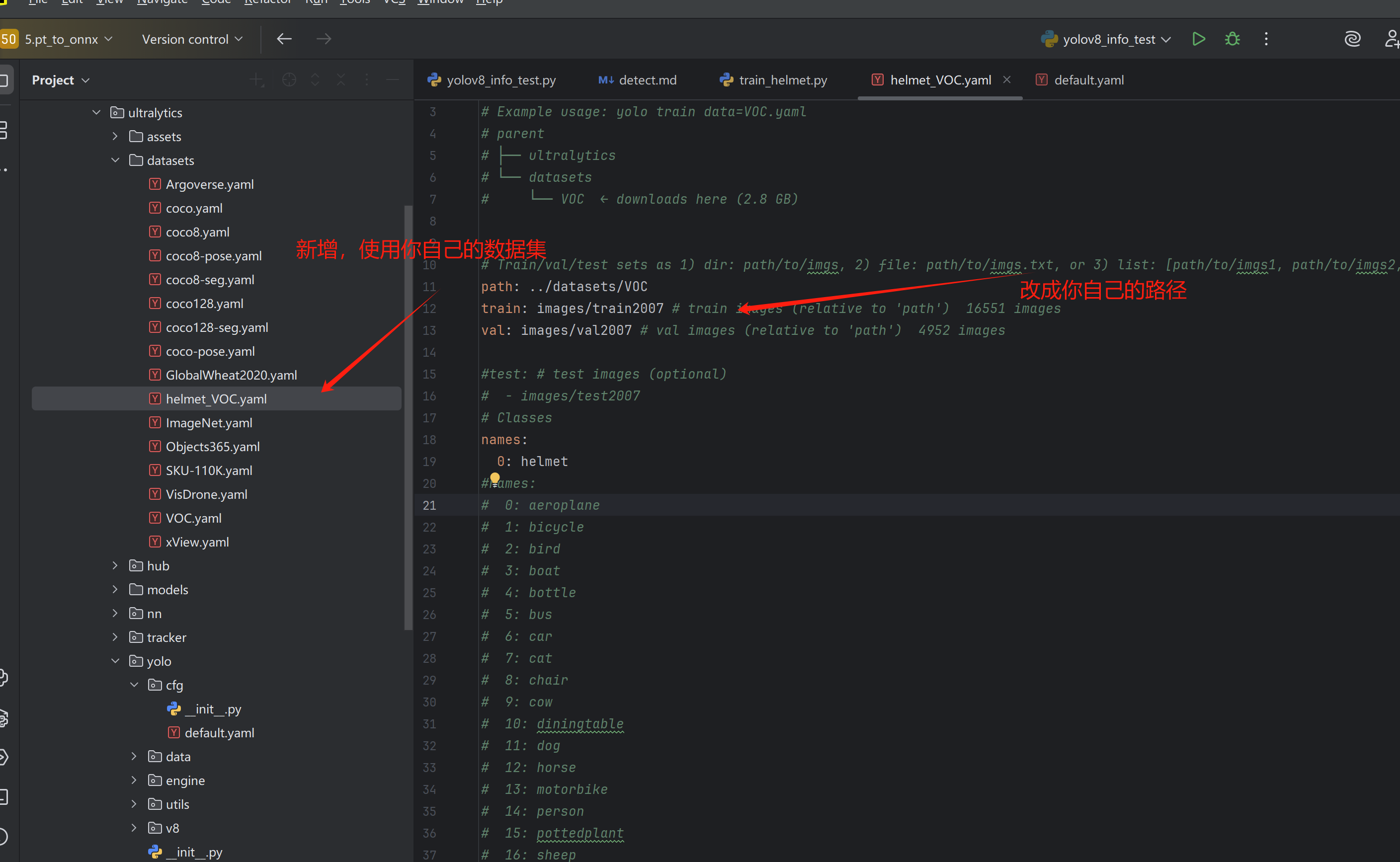
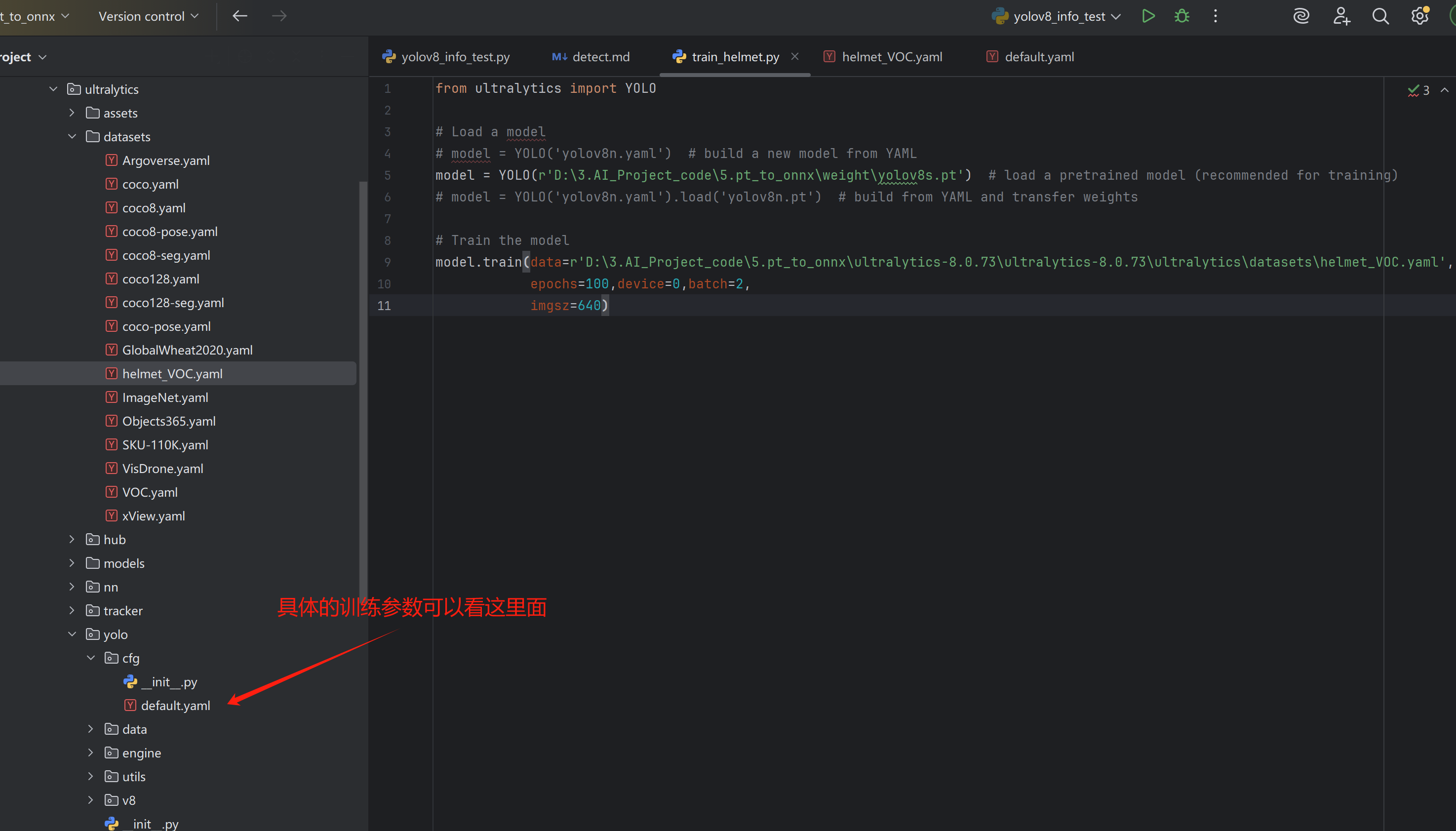
3. 查看训练效果
训练完成后,PyTorch 会生成 runs/detect/train 文件夹:
-
weights/→ 模型权重 -
results.png→ 训练曲线 -
labels/→ 推理结果
五、模型推理(验证效果)
from ultralytics import YOLO
model = YOLO('runs/detect/train/weights/best.pt')
model.predict('test.jpg', show=True) # 在图片上显示预测结果
六、小贴士 & 注意事项
-
GPU 显存小 → 使用
yolov8n.pt或减小 batch -
LabelMe 标注类别统一,文件名不要有中文
-
Windows 用户注意路径分隔符,最好用
/ -
训练前确认 CUDA 与 PyTorch 对应版本匹配
七、总结
本文覆盖了从 PyCharm 安装、GPU 配置、LabelMe 标注到 YOLOv8 自定义训练 的完整流程,小白也可以快速上手毕设项目。掌握这套流程,你就能在自己的数据集上进行目标检测和实例分割训练。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 47
47 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)