全面解析kubernetes(只讲干货)
Pod被删除后重建,重建Pod的网络标识也不会改变,Pod的拓扑状态按照Pod的“名字+编号”的方式固定下来,并且为每个Pod提供了一个固定且唯一的访问入口,Pod对应的DNS记录。官网文档:https://v1-30.docs.kubernetes.io/zh-cn/docs/concepts/workloads/controllers/官方文档:https://kubernetes.io/zh
安装kubernetes
环境
| 主机名 | IP | 角色 |
|---|---|---|
| harbor | 172.25.254.200 | 私有仓库 |
| k8s-master.org | 172.25.254.100 | 主节点 |
| k8s-node1.org | 172.25.254.11 | 从节点1 |
| k8s-node2.org | 172.25.254.22 | 从节点2 |
部署
同步解析
操作对象:全体主机
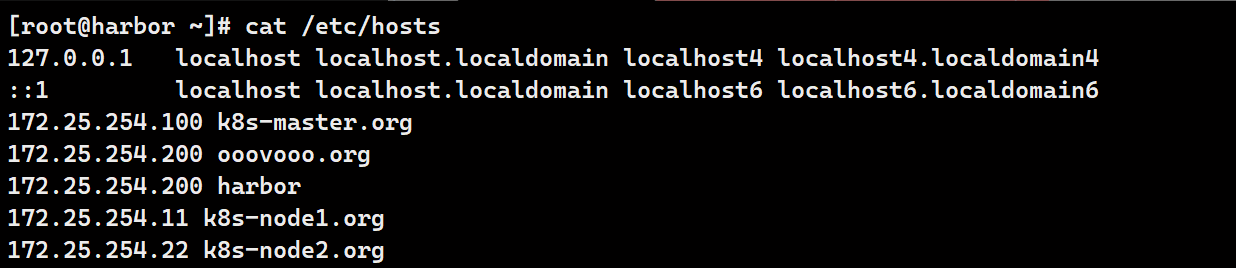
vim /etc/hosts
...
172.25.254.100 k8s-master.org
172.25.254.200 ooovooo.org
172.25.254.200 harbor
172.25.254.11 k8s-node1.org
172.25.254.22 k8s-node2.org
docker
# 均安装同一版本的Docker
vim /etc/yum.repos.d/docker.repo
[Docker]
name=Docker
baseurl=https://mirrors.aliyun.com/docker-ce/linux/rhel/9/x86_64/stable/
gpgcheck=0
enabled=1
---
yum install docker-ce -y
# 除harbor外,均设定iptables网络
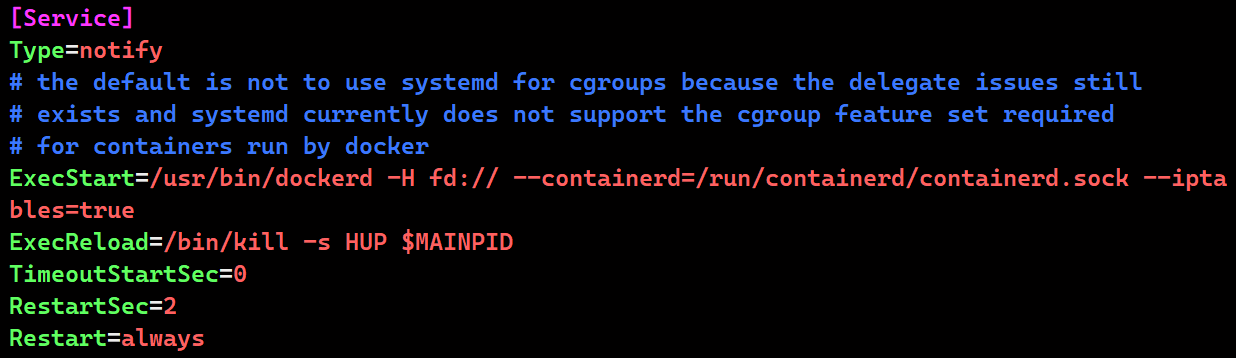
vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --iptables=true
---
# 均开启服务
systemctl enable --now docker.service
# 建立harbor认证目录(certs.d+harbor域名)
mkdir /etc/docker/certs.d/ooovooo.org/ -p
# 查看版本
docker info | grep Version

harbor
下载地址:https://github.com/goharbor/harbor/releases
下载harbor
# 下载
wget https://github.com/goharbor/harbor/releases/download/v2.5.4/harbor-offline-installer-v2.5.4.tgz
# 安装harbor
tar zxf harbor-offline-installer-v2.5.4.tgz
mv harbor /root/harbor/
cd /root/harbor/
# 生成认证
mkdir /data/docker/certs/ -p
openssl req -newkey rsa:4096 -addext "subjectAltName = DNS:ooovooo.org" -x509 -days 365 -out /data/docker/certs/ovo.org.crt -nodes -sha256 -keyout /data/docker/certs/ono.org.key
CN
Shanxi
Xi'an
ovo
kubernetes
ooovooo.org
admin@moon.org

安装及传递认证
/data/docker/certs/ — harbor仓库存放证书目录/etc/docker/certs.d/ooovooo.org/ — 登录harbor仓库时,docker默认检验证书目录
若/etc/docker/certs.d/ooovooo.org/路径下没有证书,在登录harbor时,会出现certificate signed by unknown authority错误
# 生成仓库所需认证(名字与路径均不能改变)
cp /data/docker/certs/ovo.org.crt /etc/docker/certs.d/ooovooo.org/ca.crt
# 修改认证路径
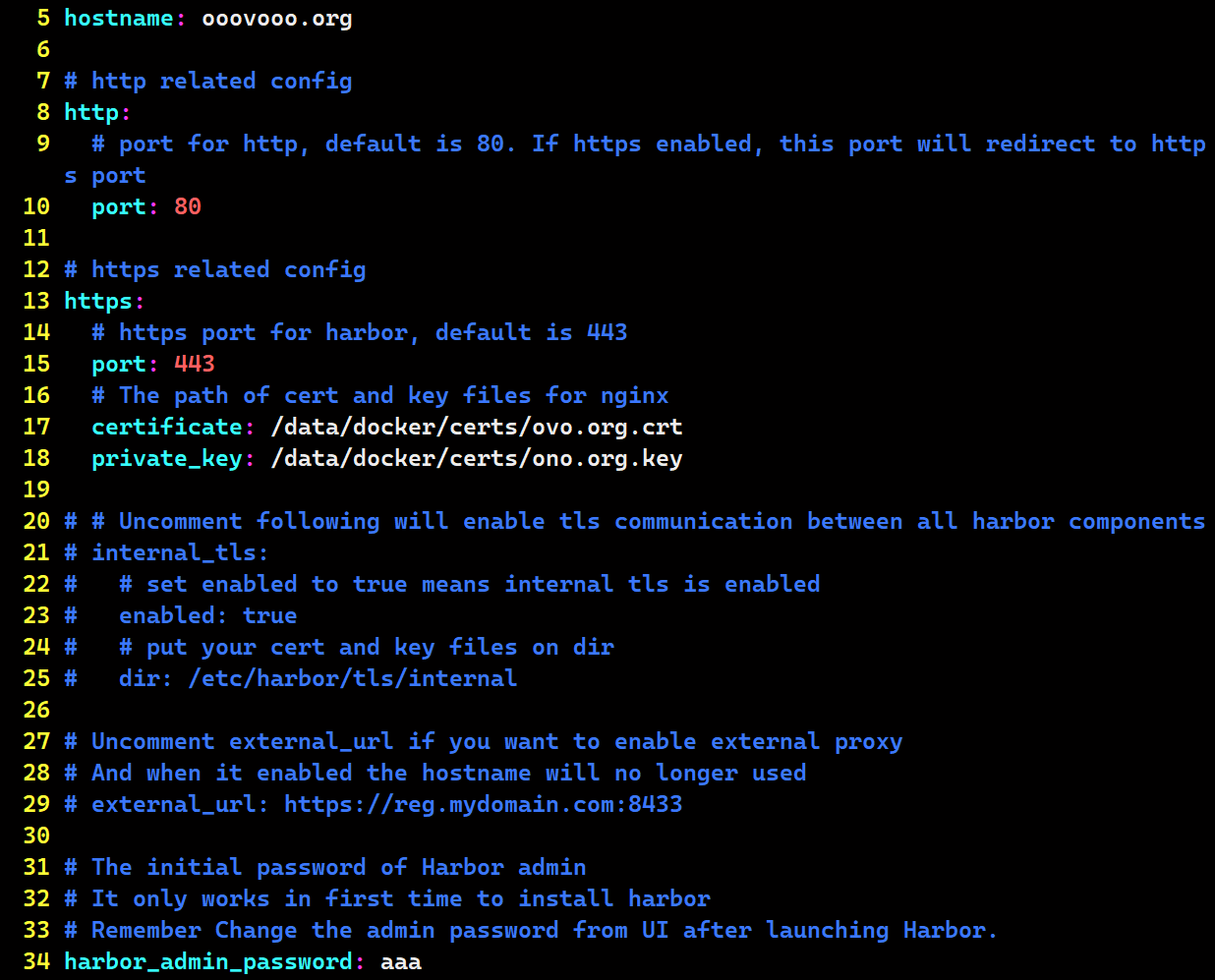
cp harbor.yml.tmpl harbor.yml
vim harbor.yml
5 hostname: ooovooo.org # 与subjectAltName = DNS:ooovooo.org保持一致
17 certificate: /data/docker/certs/ovo.org.crt
18 private_key: /data/docker/certs/ono.org.key
34 harbor_admin_password: aaa # 账户:admin 密码:aaa
---
# 开始安装
cd /root/harbor/
./install.sh --with-chartmuseum
# 若报错,请检查文件路径下是否有crt和key文件,请检查hostname是否保持一致
# 浏览器登录harbor
172.25.254.200
# 创建项目(均公开)
1.kubernetes
2.flannel
# 传递ca文件
cd /etc/docker/certs.d/ooovooo.org/
scp ca.crt root@172.25.254.100:/etc/docker/certs.d/ooovooo.org/
scp ca.crt root@172.25.254.11:/etc/docker/certs.d/ooovooo.org/
scp ca.crt root@172.25.254.22:/etc/docker/certs.d/ooovooo.org/
# 验证(kubernetes集群)
ls /etc/docker/certs.d/ooovooo.org/
# kubernetes集群登录harbor仓库
docker logout
docker login ooovooo.org -u admin
---
# harbor启停
cd /root/harbor/
docker compose stop # 停止(不删除容器和网络)
docker compose up -d # 后台模式运行
docker compose down # 停止并删除容器和网络(保留卷和镜像)
# 开机自启harbor(systemd方式管理)
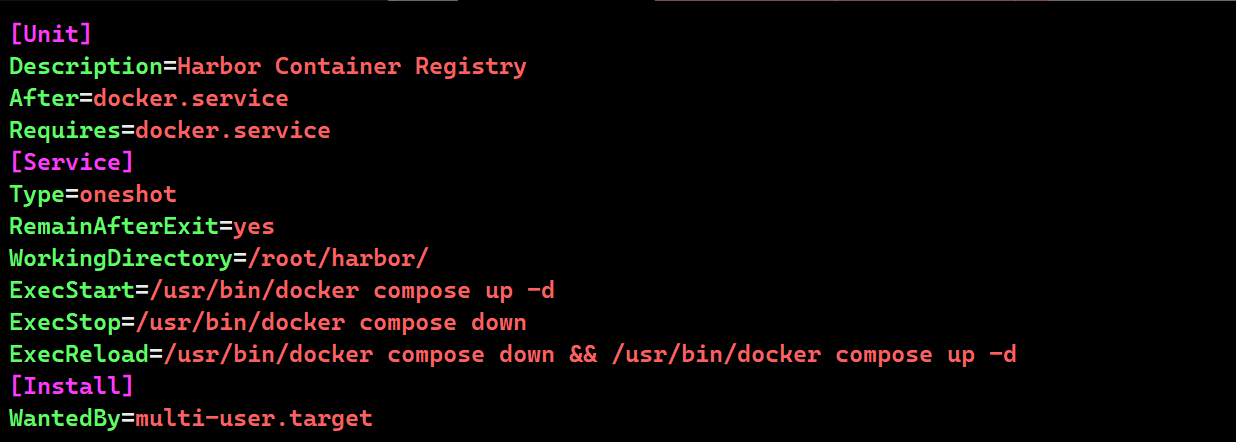
vim /etc/systemd/system/harbor.service
[Unit]
Description=Harbor Container Registry
After=docker.service
Requires=docker.service
[Service]
Type=oneshot
RemainAfterExit=yes
WorkingDirectory=/root/harbor/
ExecStart=/usr/bin/docker compose up -d
ExecStop=/usr/bin/docker compose down
ExecReload=/usr/bin/docker compose down && /usr/bin/docker compose up -d
[Install]
WantedBy=multi-user.target
# 重新加载 systemd 配置
systemctl daemon-reload
# 设置开机自启
systemctl enable harbor
# 验证
systemctl stop harbor.service
systemctl status harbor.service
docker ps -a
systemctl start harbor.service
docker ps -a
kubernetes
操作对象:kubernetes集群
前置工作
# 禁用swap
# 查看swap状态
swapon -s
vim /etc/fstab
# /dev/mapper/rl-swap ...
---
# 临时关闭
swapoff -a
# 重载配置
systemctl daemon-reload
# 彻底禁用
systemctl mask swap.target
# 验证
swapon -a

# 修改资源管理模式
vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://ooovooo.org"],
# "exec-opts": ["native.cgroupdriver=systemd"],
# "log-driver": "json-file",
# "log-opts":
# {
# "max-size": "100m"
# },
# "storage-driver": "overlay2"
}
# 注释内容,仅在主机为rhel8.x版本中做;若其他版本,请删除 , 符号
# 激活内核网络
# 开机自动激活
echo br_netfilter > /etc/modules-load.d/docker_mod.conf
# 加载模块
modprobe br_netfilter
# 优化内核文件
echo net.ipv4.ip_forward=1 >> /etc/sysctl.d/kubernetes.conf
# 若主机版本为8.x,需要额外执行下面两条
net.bridge.bridge-nf-call-ip6tables=1 >> /etc/sysctl.d/kubernetes.conf
net.bridge.bridge-nf-call-iptables=1 >> /etc/sysctl.d/kubernetes.conf
# 验证
sysctl -p /etc/sysctl.d/kubernetes.conf
# 重启docker
systemctl restart docker

安装kubernetes管理工具
vim /etc/yum.repos.d/kubernetes.repo
[Kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/rpm/
gpgcheck=0
enabled=1
---
dnf install kubelet kubeadm kubectl -y

设置kubectl命令补全
# 安装bash扩展
dnf install bash-completion -y
# 添加环境变量
echo "source <(kubectl completion bash)" >> ~/.bashrc
# 重新加载
source ~/.bashrc
# 验证
ku
# 尝试命令补齐
ku --> kube --> kubec --> kubectlc
安装cri-docker插件
操作对象:kubetnetes集群主机
kubetnetes从1.24版本开始移除dockershim
高版本需要安装cri-docker插件,才能使用docker
cri-docker下载:https://github.com/Mirantis/cri-dockerd/releases
# 获取软件包
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.14/cri-dockerd-0.3.14-3.el7.x86_64.rpm
# 传递安装包
scp /packags/libcgroup-0.41-19.el8.x86_64.rpm root@172.25.254.11:/packags/
scp /packags/libcgroup-0.41-19.el8.x86_64.rpm root@172.25.254.22:/packags/
---
scp /packags/cri-dockerd-0.3.16-3.fc35.x86_64.rpm root@172.25.254.11:/packags/
scp /packags/cri-dockerd-0.3.16-3.fc35.x86_64.rpm root@172.25.254.22:/packags/
# 均进行安装
dnf install /packags/libcgroup-0.41-19.el8.x86_64.rpm -y
dnf install /packags/cri-dockerd-0.3.16-3.fc35.x86_64.rpm -y
# 下载根容器(仅需一台主机下载、打标签、上传)
docker pull registry.aliyuncs.com/google_containers/pause:3.9
# 验证
docker images | grep pause
# 打标签
docker tag registry.aliyuncs.com/google_containers/pause:3.9 ooovooo.org/kubernetes/pause:3.9
# 上传根容器
docker push ooovooo.org/kubernetes/pause:3.9
# 指定网络插件名称及根容器(与harbor仓库路径对应!!!)
vim /lib/systemd/system/cri-docker.service
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin=cni --pod-infra-container-image=ooovooo.org/kubernetes/pause:3.9
# 开启服务
systemctl enable --now cri-docker
systemctl enable --now kubelet.service
cir-docker套接字路径:/var/run/cri-dockerd.sock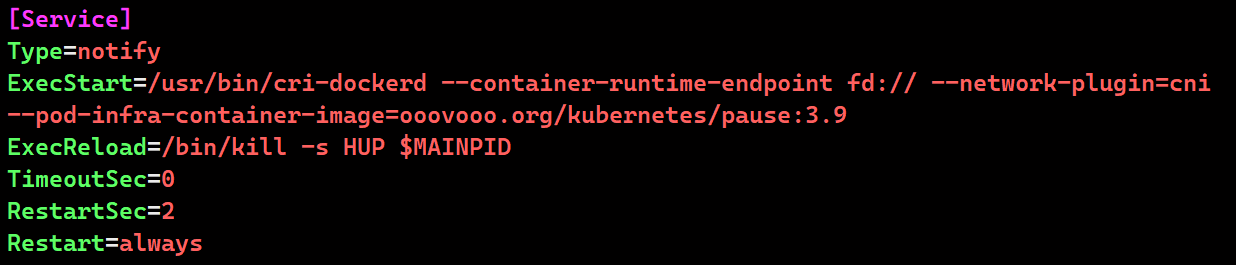
安装flannel插件
操作对象:k8s-master
flannel+yml文件下载地址:https://github.com/flannel-io/flannel/releases
flannel-cni-plugin下载地址:https://docker.aityp.com/r/docker.io/flannel/flannel-cni-plugin
# 拉取镜像
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/flannel/flannel-cni-plugin:v1.5.1-flannel1
# 打标签
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/flannel/flannel-cni-plugin:v1.5.1-flannel1 ooovooo.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
# 上传镜像
docker push ooovooo.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
---
# 获取安装包
wget https://github.com/flannel-io/flannel/releases/download/v0.25.5/flanneld-v0.25.5-amd64.docker
wget https://github.com/flannel-io/flannel/releases/download/v0.25.5/kube-flannel.yml
# 加载镜像
docker load -i flanneld-v0.25.5-amd64.docker
# 打标签
docker tag quay.io/coreos/flannel:v0.25.5-amd64 ooovooo.org/flannel/flannel:v0.25.5
# 上传镜像
docker push ooovooo.org/flannel/flannel:v0.25.5
# 配置yml文件
vim kube-flannel.yml
146 image: ooovooo.org/flannel/flannel:v0.25.5
173 image: ooovooo.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
184 image: ooovooo.org/flannel/flannel:v0.25.5
# 验证
sed -n '146p;173p;184p' kube-flannel.yml
# 记录下此yml文件的路径,初始化完成后,需要加载

拉取kubernetes镜像
操作对象:k8s-master
# 拉取kubernetes集群所需镜像
kubeadm config images pull --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.30.0 --cri-socket=unix:///var/run/cri-dockerd.sock
# 打标签
docker images | awk '/google/{ print $1":"$2}' | awk -F "/" '{system("docker tag "$0" ooovooo.org/kubernetes/"$3)}'
# 上传镜像
docker images | awk '/ooovooo.org.*kubernetes/{system("docker push "$1":"$2)}'
# 重启服务
systemctl daemon-reload
systemctl restart cri-docker
主节点初始化
主节点初始化时,内存不能低于1700MB
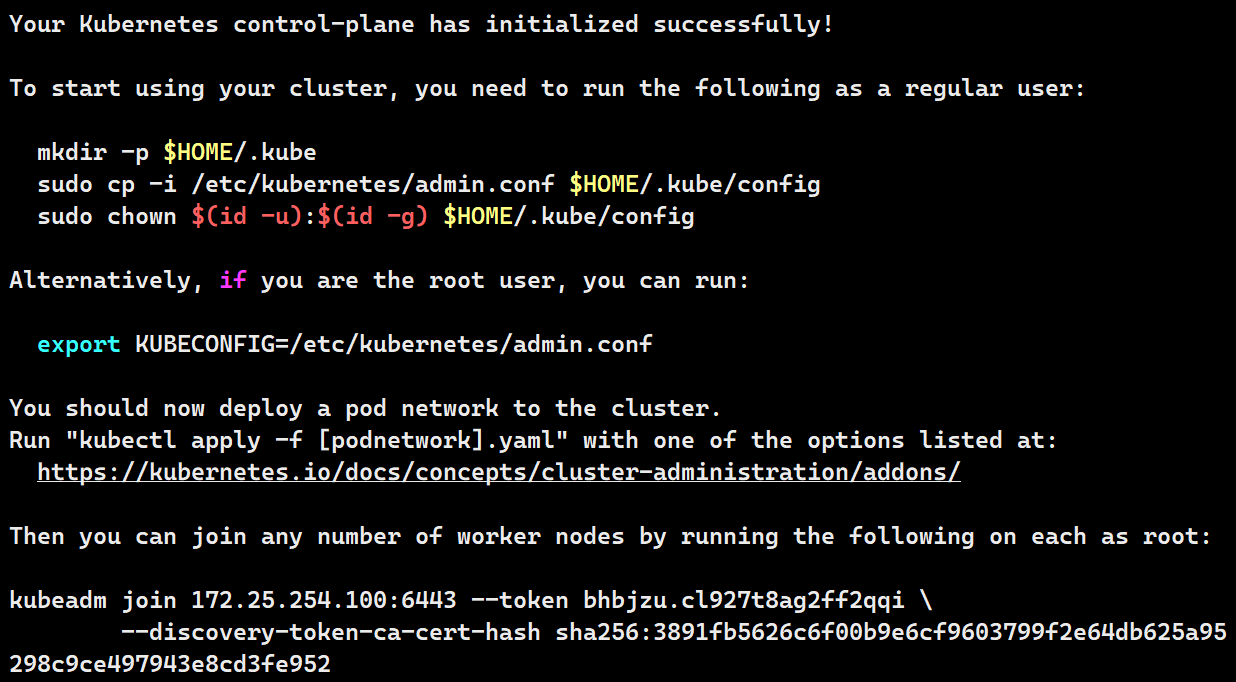
# 初始化命令
kubeadm init --pod-network-cidr=10.244.0.0/16 --image-repository ooovooo.org/kubernetes --kubernetes-version v1.30.0 --cri-socket=unix:///var/run/cri-dockerd.sock
# 初始化成功标志
Your Kubernetes control-plane has initialized successfully!
# 记录下从节点加入集群命令(记不住也没事)
kubeadm join 172.25.254.100:6443 --token bhbjzu.cl927t8ag2ff2qqi --discovery-token-ca-cert-hash sha256:3891fb5626c6f00b9e6cf9603799f2e64db625a95298c9ce497943e8cd3fe952
# 若初始化失败,请检查
1.swap是否禁用
2.kubelet服务是否启动
3.cri-docker.service,根容器路径是否正确
4.flannel插件是否启用,镜像拉取路径是否正确
# 若失败后,重新初始化,需要先执行命令
kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock
---
# 初始化成功后
# 指定主配置文件
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
# 重载配置
source ~/.bash_profile
# 获取主节点状态
kubectl get nodes
# 应用yml文件,当有新加入主机时,会自动加载此插件
kubectl apply -f kube-flannel.yml
# 等待一会后,若为ready即为成功初始化

从节点初始化
# 若不记得token
# 主节点重新生成token
kubeadm token create --print-join-command
# 从节点初始化(加上cri-docker的sock路径)
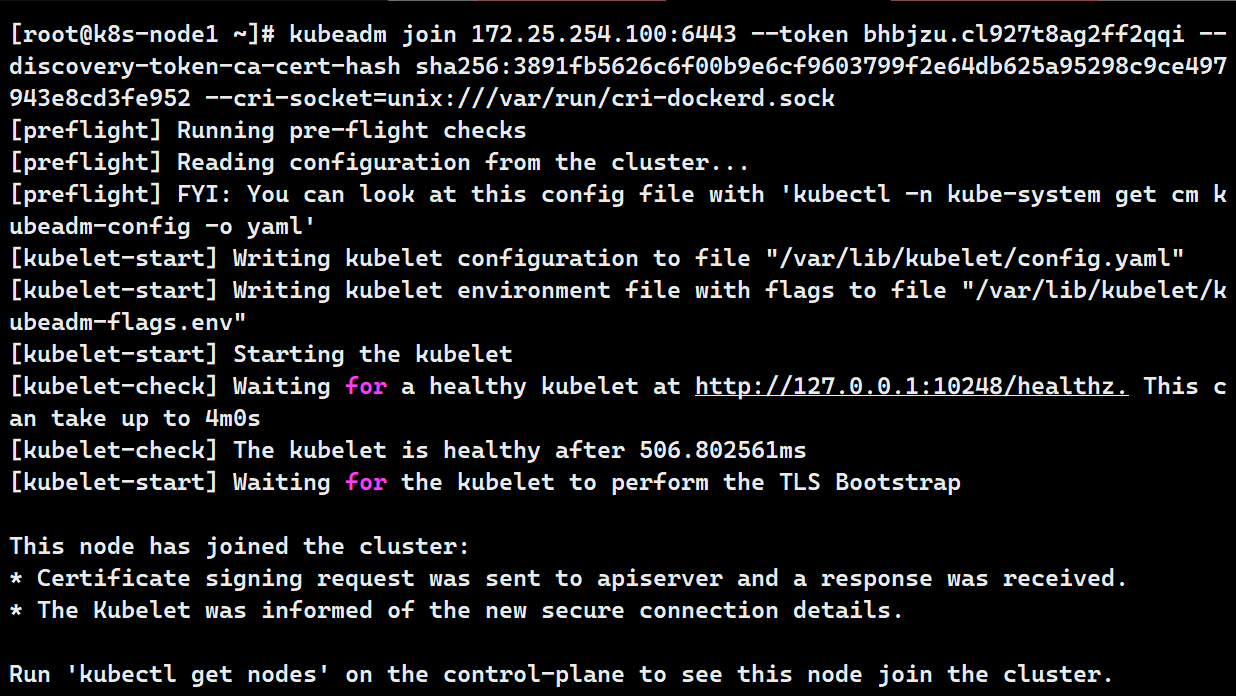
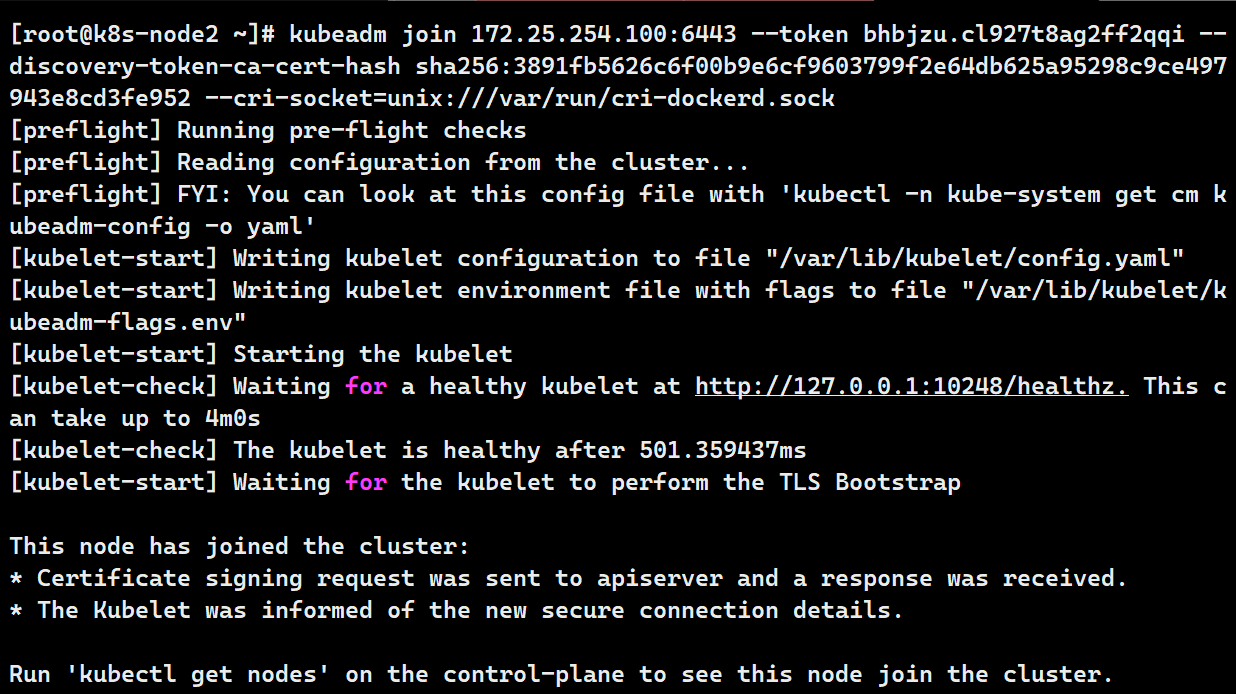
kubeadm join 172.25.254.100:6443 --token bhbjzu.cl927t8ag2ff2qqi --discovery-token-ca-cert-hash sha256:3891fb5626c6f00b9e6cf9603799f2e64db625a95298c9ce497943e8cd3fe952 --cri-socket=unix:///var/run/cri-dockerd.sock
# 初始化成功标志
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
---
# 若初始化失败,重新初始化,执行命令
# 主节点(剔除失败主机)
kubectl delete node k8s-node1.org
# 从节点
kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock
---
# 查看所有节点状态(均处于ready状态即成功)
kubectl get nodes

测试
# harbor登录harbor仓库
docker logout
docker login ooovooo.org -u admin
# 加载镜像
docker load -i nginx-latest.tar.gz
docker tag nginx:latest ooovooo.org/library/nginx:latest
docker push ooovooo.org/library/nginx:latest
# master
docker run nginx --image nginx
# 查看Pod状态
kubectl get pods -o wide
# 在k8s-node1查看镜像状态
docker ps
# 删除pod
kubectl delete pod test

Pod管理
在kubernetes中,一切皆资源
用户通过操作资源来使用kubernetes
kubernetes中最小管理单元是Pod,容器只能放在Pod中
用户通过Pod控制器来管理Pod
Pod中数据持久化是由kubernetes的存储系统实现的
Pod中的服务访问是由kubernetes的service资源实现的
资源管理
命令式对象管理:直接使用命令去操作kubernetes资源
命令式对象配置:通过命令配置和配置文件去操作kubernetes资源
声明式对象管理:通过apply命令应用配置文件去操作kubernetes资源
| 类型 | 适用环境 | 优点 | 缺点 |
|---|---|---|---|
| 命令式对象管理 | 测试 | 简单 | 只能操作活动对象,无法审计、跟踪 |
| 命令式对象配置 | 开发 | 可以审计、跟踪 | 项目大时,配置文件多,操作麻烦 |
| 声明式对象配置 | 开发 | 支持目录操作 | 意外情况下难以调试 |
命令式对象管理
kubectl是kubernetes集群的命令行工具,能通过它对集群本身进行管理
语法:kubectl [command] [type] [name] [flags]
comand:对资源执行的操作,create\delete\get
type:明确资源的类型,pod\deployment\service
name:资源创建时的名称(大小写敏感)
flags:额外的可选参数
资源类型
# 列出集群可用的资源
kubectl api-resources
| 资源分类 | 资源名称 | 缩写 | 资源作用 |
|---|---|---|---|
| 集群级别资源 | nodes | no | 集群组成部分 |
| namespaces | ns | 隔离 Pod | |
| pod 资源 | pods | po | 装载容器 |
| pod 资源控制器 | replicationcontrollers | rc | 控制 pod 资源 |
| replicasets | rs | 控制 pod 资源 | |
| deployments | deploy | 控制 pod 资源 | |
| daemonsets | ds | 控制 pod 资源 | |
| jobs | 控制 pod 资源 | ||
| cronjobs | cj | 控制 pod 资源 | |
| horizontalpodautoscalers | hpa | 控制 pod 资源 | |
| statefulsets | sts | 控制 pod 资源 | |
| 服务发现资源 | services | svc | 统一 pod 对外接口 |
| ingress | ing | 统一 pod 对外接口 | |
| 存储资源 | volumeattachments | 存储 | |
| persistentvolumes | pv | 存储 | |
| persistentvolumeclaims | pvc | 存储 | |
| 配置资源 | configmaps | cm | 配置 |
| secrets | 配置 |
常见命令
| 命令分类 | 命令 | 翻译 | 命令作用 |
|---|---|---|---|
| 基本命令 | create | 创建 | 创建一个资源 |
| edit | 编辑 | 编辑一个资源 | |
| get | 获取 | 获取一个资源 | |
| patch | 更新 | 更新一个资源 | |
| delete | 删除 | 删除一个资源 | |
| explain | 解释 | 展示资源文档 | |
| run | 运行 | 在集群中运行一个指定的镜像 | |
| expose | 暴露 | 暴露资源为 Service | |
| describe | 描述 | 显示资源内部信息 | |
| 运行和调试 | logs | 日志 | 输出容器在 pod 中的日志 |
| attach | 缠绕 | 进入运行中的容器 | |
| exec | 执行 | 执行容器中的一个命令 | |
| cp | 复制 | 在 Pod 内外复制文件 | |
| rollout | 首次展示 | 管理资源的发布 | |
| scale | 规模 | 扩(缩)容 Pod 的数量 | |
| autoscale | 自动调整 | 自动调整 Pod 的数量 | |
| 高级命令 | apply | rc | 通过文件对资源进行配置 |
| label | 标签 | 更新资源上的标签 | |
| 其他命令 | cluster-info | 集群信息 | 显示集群信息 |
| version | 版本 | 显示当前 Server 和 Client 的版本 |
基础命令
# 查看集群版本
kubectl version
# 显示集群信息
kubectl cluster-info
# 查看资源帮助
kubectl explain deployment
# 查看资源参数帮助
kubectl explain deployment.spec
# 运行时编辑资源配置
kubectl edit deployments.apps moon
# 删除资源
kubectl delete deployments.apps web
# 运行pod
kubectl run mypod --image nginx
# 查看pod状态
kubectl get pods
# 端口暴漏
kubectl expose pod mypod --port 80 --target-port 80
# 查看服务状态
kubectl get services
# 查看资源详细信息
kubectl describe pods mypod
# 查看资源具体日志
kubectl logs pods/mypod
# 运行交互式pod
kubectl run -it moon --image busybox
# 与docker类似,同时按ctrl+p+q退出但不停止pod
# 运行非交互式pod
kubectl run nginx --image nginx
# 进入可交互式容器内
kubectl attach pods/moon -it
# 在容器外部执行命令
kubectl exec -it pods/nginx /bin/bash
# 文件写入容器内
kubectl cp anaconda-ks.cfg nginx:/
# 容器文件写入主机
kubectl cp nginx:/anaconda-ks.cfg anaconda-ks.cfg
高级命令
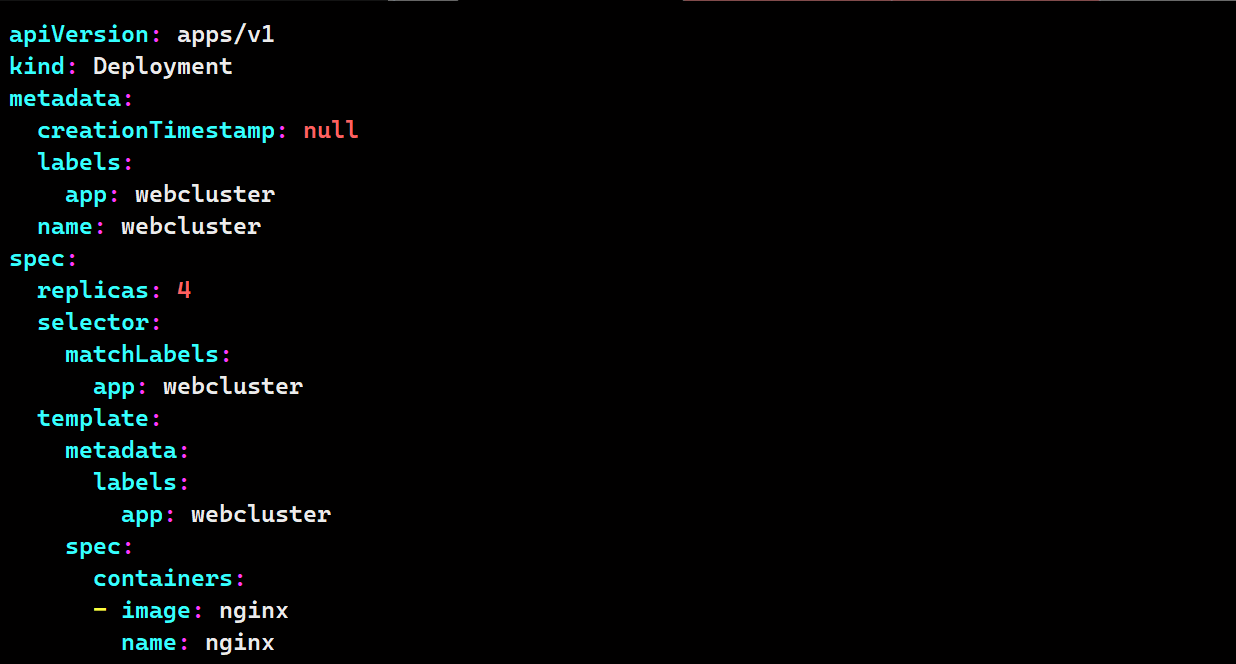
# 命令生成yaml模板文件
kubectl create deployment --image nginx webcluster --dry-run=client -o yaml > webcluster.yaml
# 通过模板制作自定义配置文件
vim webcluster.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: webcluster
name: webcluster
spec:
replicas: 4
selector:
matchLabels:
app: webcluster
template:
metadata:
labels:
app: webcluster
spec:
containers:
- image: nginx
name: nginx
# 声明式对象配置
kubectl apply -f webcluster.yml
# 获取状态
kubectl get deployments.apps
# 查看运行pod状态
kubectl get pods
# 删除方式一(推荐)
kubectl delete -f webcluster.yml
# 删除方式二(根据资源类型及名字删除)
kubectl delete deployment webcluster
# 管理资源标签
kubectl run nginx --image nginx
# 查看资源标签
kubectl get pods --show-labels
# 添加标签
kubectl label pods nginx app=lee
# 验证
kubectl get pods --show-labels
# 修改标签(--overwrite)
kubectl label pods nginx app=webcluster --overwrite
# 删除标签(-)
kubectl label pods nginx app-
自主式Pod
优点:
灵活性高、学习和调试方便、适用于特殊场景(快速验证)
缺点:
管理复杂、缺乏高级功能、可维护性差
# 查看pod
kubectl get pods
# 创建Pod
kubectl run nginx --image nginx
# 查看状态
kubectl get pods
# 查看更详细信息(IP、运行节点)
kubectl get pods -o wide
控制器管理Pod
具有高可用性和可靠性、可扩展性、版本管理和更新、声明式配置、服务发现和负载均衡、多环境一致性等优点
# 建立控制器及pod
kubectl create deployment nginxs --image nginx
# 为控制器扩容(scale\--replicas)
kubectl scale deployment nginxs --replicas 6
# 验证
kubectl get pods
# 为控制器缩容
kubectl scal deployment nginxs --replicas 2
# 验证
kubectl get pods
# 删除
kubectl delete deployment nginxs
更新pod版本
# 控制器建立pod
kubectl create deployment nginxs --image myapp:v1 --replicas 2
# 暴露端口
kubectl expose deployment nginxs --port 80 --target-port 80
# 查看控制器信息
kubectl get services
# 验证
curl 10.110.195.120
# 查看控制器版本
kubectl rollout history deployment nginxs
# 更新控制器pod
kubectl set image deployments/nginxs myapp=myapp:v2
# 验证
kubectl rollout history deployment nginxs
curl 10.110.195.120
# 版本回滚
kubectl rollout undo deployment nginxs --to-revision 1
# 验证
curl 10.110.195.120
# 删除
kubectl delete deployment nginxs
利用yaml文件部署
具有声明式配置、灵活性和可扩展性、与工具集成等优点
简单演示
单个pod内运行多个容器
# 命令生成pod模板
kubectl run moon --image myapp:v1 --dry-run=client -o yaml > moon.yml
vim moon.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: moon
name: moon
spec:
containers:
- image: nginx:latest
name: web1
- image: nginx:latest
name: web2
# 应用
kubectl apply -f moon.yml
# 获取状态
kubectl get pods
# 查看某个状态(排错)
kubectl logs moon web1
# 删除
kubectl delete -f moon.yml
需要注意的是,单个pod开启多个容器,容器之间会资源共享,使用相同的资源(如端口)会产生干扰,如上例
同个pod内的容器共用一个网络
# 修改
vim moon.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: moon
name: moon
spec:
containers:
- image: myapp:v1
name: myapp1
- image: busyboxplus:latest
name: busyboxplus
command: ["/bin/sh","-c","sleep 1000000"]
# 应用
kubectl apply -f moon.yml
# 获取状态
kubectl get pods
# 验证(在没有web服务的容器内访问localhost)
kubectl exec test -c busyboxplus -- curl -s localhost
# 删除
kubectl delete -f moon.yml
高级应用
端口映射
# 修改
vim moon.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: moon
name: moon
spec:
containers:
- image: myapp:v1
name: myapp1
ports:
- name: http
containerPort: 80
hostPort: 80
protocol: TCP
# 应用
kubectl apply -f moon.yml
# 查看状态
kubectl get pods -o wide
# 验证
curl k8s-node1.org
# 删除
kubectl delete -f moon.yml
设定容器环境变量
# 修改
vim moon.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: moon
name: moon
spec:
containers:
- image: busybox:latest
name: busybox
command: ["/bin/sh","-c","echo $NAME;sleep 3000000"]
env:
- name: NAME
value: sun
# 应用
kubectl apply -f moon.yml
# 验证
kubectl logs pods/moon busybox
# 删除
kubectl delete -f moon.yml
pod资源限制
资源限制会影响pod的Qos Class资源优先级(QoS即服务质量)
资源优先级分为Guaranteed > Burstable > BestEffort
| 资源设定 | 优先级类型 |
|---|---|
| 资源限定未设定 | BestEffort |
| 资源限定设定且最大和最小不一致 | Burstable |
| 资源限定设定且最大和最小一致 | Guaranteed |
# 修改
vim moon.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: moon
name: moon
spec:
containers:
- image: myapp:v1
name: myapp
resources:
limits:
cpu: 500m
memory: 100M
requests:
cpu: 500m
memory: 100M
# 应用
kubectl apply -f moon.yml
# 查看
kubectl get pods
# 验证
kubectl describe pods moon
容器启动管理
# 修改
vim moon.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: test
spec:
restartPolicy: Always
containers:
- image: myapp:v1
name: myapp
# 应用
kubectl apply -f moon.yml
# 查看
kubectl get pods -o wide
# 验证
kubectl delete pods moon
kubectl get pods -o wide
运行节点
# 修改
vim moon.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: moon
name: moon
spec:
nodeSelector:
kubernetes.io/hostname: k8s-node1
restartPolicy: Always
containers:
- image: myapp:v1
name: myapp
# 应用
kubectl apply -f moon.yml
#验证
kubectl get pods -o wide
共享宿主机网络
# 修改
vim moon.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: test
spec:
hostNetwork: true
restartPolicy: Always
containers:
- image: busybox:latest
name: busybox
command: ["/bin/sh","-c","sleep 100000"]
# 应用
kubectl apply -f moon.yml
# 验证
kubectl exec -it pods/moon -c busybox -- /bin/sh
ifconfig
eth0:......
Pod的生命周期
官方文档:https://kubernetes.io/zh/docs/concepts/workloads/
init容器
Pod可以有一个或多个先于应用容器启动的Init容器
init容器与其他容器的区别
- 总是运行到完成
- 必须在Pod就绪前运行完成,上一个运行完成,下一个才能开始运行
如果init容器运行失败,kubernetes会不断重启Pod,直到init容器运行成功为止
如果Pod的restartPolicy值为Nerver,则它不会重新启动
适用于:等待其他服务或资源准备就绪后,再启动当前应用,确保应用启动时所需的依赖已经满足
# 监控Pod状态
watch -n1 kubectl get pods -o wide
# 生成生成Pod
vim init-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: ovo
name: ovo
spec:
containers:
- image: myapp:v1
name: ovo
# init 容器
initContainers:
- name: init-myservice
image: busybox
command: ["sh","-c","until test -e /testfile;do echo wating for myservice; sleep 2;done"]
# 应用yaml文件
kubectl apply -f init-pod.yaml
# 验证
kubectl logs pods/ovo init-myservice
# Pod一直处于init:0/1状态,应用容器无法启动
# 生成检测文件
kubectl exec pods/init-pod -c init-myservice -- /bin/sh -c "touch /testfile"
kubectl get pods -o wide
# init运行完毕,应用容器允许运行



探针
探针由kubelet对容器执行的定期诊断
- ExecAction:在容器内执行指定命令;如果命令退出时返回码为0则认为诊断成功
- TCPSocketAction:对指定端口上的容器的IP地址进行TCP检查;如果端口打开,则诊断被认为是成功的
- HTTPGetAction:对指定的端口和路径上的容器的IP地址执行HTTP Get请求;如果响应的状态码大于等于200且小于400,则诊断被认为是成功的
每次探测的结果只有三种
- 成功:容器通过了诊断
- 失败:容器未通过诊断
- 未知:诊断失败,因此不会采取任何行动
三种探针
kubelte根据探测结果自动执行相应操作
livenessProbe(存活探针):探测容器是否正在运行;如果存活探测失败,则kubelet会杀死容器,并且容器将受到其重启策略的影响;如果容器不提供存活探针,则默认状态为Success
readinessProbe(就绪探针):探测容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与Pod匹配的所有 Service的端点中删除该Pod的IP地址;初始延迟之前的就绪状态默认为 Failure;如果容器不提供就绪探针,则默认状态为Success
startupProbe(启动探针):探测容器中的应用是否已经启动。如果提供启动探测(startup probe),则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功Success
readinessProbe与livenessProbe的区别
readinessProbe:失败后,将ip:port从对应的endpoint列表中删除
livenessProbe:失败后,将杀死容器并根据pod的重启策略选择是否重启容器
三种探针同时存在时,先执行startupProbe探针,其他探针被展示禁用,直到Pod通过startupProbe检测,在容器启动后,进行检测,如果不满足规则,则重启容器
容器只需通过一次startupProbe探针检测,后续将不再进行startupProbe检测
而其他两种探针,会定期检测,直到容器消亡才停止探测
存活探针
vim li-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: ovo
name: ovo
spec:
containers:
- image: myapp:v1
name: ovo
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 3
periodSeconds: 1
timeoutSeconds: 1
# 应用yaml文件
kubectl apply -f li-pod.yaml
# 查看pod状态,注意restart次数(0)
kubectl get pods -o wide
# 停止nginx运行,即关闭80端口
kubectl exec -it ovo -- /bin/sh
nginx -s stop
# 等待一段时间后,容器restart次数加1
kubectl get pods -o wide
# 显示80连接拒绝,探测失败,杀死容器,重启容器
kubectl describe pods
8080: connect: connection refused




就绪探针
# 创建
vim pod.yml
apiVersion: v1
kind: Pod
metadata:
labels:
name: readiness
name: readiness
spec:
containers:
- image: myapp:v1
name: myapp
readinessProbe:
httpGet:
path: /test.html
port: 80
initialDelaySeconds: 1
periodSeconds: 3
timeoutSeconds: 1
# 暴露端口
kubectl expose pod readiness --port 80 --target-port 80
# 查看
kubectl get pods
# 验证
kubectl describe pods readiness
kubectl describe services readiness
# 测试页
kubectl exec pods/readiness -c myapp -- /bin/sh -c "echo test > /usr/share/nginx/html/test.html"
# 查看
kubectl get pods
# kubectl describe services readiness
启动探针
在这里插入代码片
控制器
官网文档:https://v1-30.docs.kubernetes.io/zh-cn/docs/concepts/workloads/controllers/
自主pod:pod退出或意外关闭后不会被重新创建
控制器管理的pod:在控制器的生命周期内,始终要维持Pod的副本数目
类型
| 控制器名称 | 介绍 |
|---|---|
| Replication Controller | 比较原始的Pod控制器,已经被废弃,由ReplicaSet替代 |
| ReplicaSet | ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行(副本数量) |
| Deployment | 一个 Deployment 为 Pod 和 ReplicaSet 提供声明式的更新能力(版本更新) |
| DaemonSet | DaemonSet 确保全指定节点上运行一个 Pod 的副本 |
| StatefulSet | StatefulSet 是用来管理有状态应用的工作负载 API 对象 |
| Job | 执行批处理任务,仅执行一次任务,保证任务的一个或多个Pod成功结束 |
| CronJob | Cron Job 创建基于时间调度的 Jobs |
| HPA(Horizontal Pod Autoscaler) | 根据资源利用率自动调整service中Pod数量,实现Pod水平自动缩放(自动扩容) |
ReplicaSet控制器
ReplicaSet 是下一代的 Replication Controller,官方推荐使用ReplicaSet
# 生成yml文件
kubectl create deployment replicaset --image myapp:v1 --dry-run=client -o yaml > replicaset.yml
# 配置
vim replicaset.yml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: replicaset
spec:
replicas: 2
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v1
name: myapp
# 应用
kubectl apply -f replicaset.yml
# 查看状态
kubectl get pods --show-labels
# ReplicaSet通过标签检测pod的数量
kubectl label pod xxx app=moon --overwrite
kubectl get pods --show-labels
# 恢复标签
kubectl label pod xxx app-
kubectl get pod --show-labels
# 删除并自动维持
kubectl delete pods xxx
# 查看
kubectl get pods --show-labels
# 回收
kubectl delete -f rs-example.yml
Deployment控制器
Deployment控制器并不直接管理pod,而是通过管理ReplicaSet来间接管理Pod
# 生成yml文件
kubectl create deployment deployment --image myapp:v1 --dry-run=client -o yaml > deployment.yml
# 配置
vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v1
name: myapp
# 应用
kubectl apply -f deployment.yml
# 查看
kubectl get pods --show-labels
# 回收
kubectl delete -f deployment.yml
版本迭代
# 查看
kubectl get pods -o wide
# 设置容器版本v1
curl 10.244.2.14
# 查看
kubectl describe deployments.apps deployment
# 配置容器版本v2
vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v2
name: myapp
# 应用
kubectl apply -f deployment-example.yaml
# 查看更新过程
kubectl get pods -w
# 验证
kubectl get pods -o wide
curl 10.244.2.14
# 回收
kubectl delete -f deployment-example.yaml
本质是新建一个RS,此RS将pod重建,然后把老版本RS回收
版本回滚
# 配置
vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v1
name: myapp
# 应用
kubectl apply -f deployment.yml
# 查看
kubectl get pods -o wide
# 验证
curl 10.244.2.26
暂停及恢复
将改动做完后,执行一次更新,避免不必要的线上更新
# 暂停
kubectl rollout pause deployment deployment-example
# 配置
vim deployment-example.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-example
spec:
minReadySeconds: 5
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
replicas: 6
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: nginx
resources:
limits:
cpu: 0.5
memory: 200Mi
requests:
cpu: 0.5
memory: 200Mi
# 应用
kubectl apply -f deployment-example.yaml
# 修改和更新资源并没有触发更新
kubectl rollout history deployment deployment-example
# 取消暂停
kubectl rollout resume deployment deployment-example
# 查看更新历史
kubectl rollout history deployment deployment-example
# 回收
kubectl delete -f deployment-example.yaml
daemonset控制器
在每个节点都运行一个Pod,新增节点同样运行此Pod
随着节点的移除,Pod也会被回收
删除DaemonSet同样会回收Pod
典型用法:
运行集群存储 DaemonSet
运行日志收集 DaemonSet(ELK)
运行监控 DaemonSet(Prometheus)
# 生成文件
vim daem.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app: daem
name: daem
spec:
selector:
matchLabels:
app: daemonset
template:
metadata:
labels:
app: daemonset
spec:
containers:
- image: myapp:v1
name: myapp
# 加载yaml
kubectl daem.yaml
# 查看
kubectl get pods -o wide
# 每个节点都运行一个容器,但master不运行,因为master属于污点节点
# 修改yaml文件(设置对污点节点的容忍)
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app: daem
name: daem
spec:
tolerations:
- effect: NoSchedule
operator: Exists
selector:
matchLabels:
app: daemonset
template:
metadata:
labels:
app: daemonset
spec:
name: myapp
# 加载yaml
kubectl daem.yaml
# 查看
kubectl get pods -o wide
# 包括master节点也运行了
# 回收
kubectl delete -f daem.yaml
StatefulSet控制器
管理有状态的服务(如MySQL主从复制,依靠IP或主机名);但在Pod中,默认主机名和IP在故障后重启会改变
# 需要配合微服务中的 无头服务 进行实验
# 创建无头服务
kubectl create service clusterip web --clusterip="None" --dry-run=client -o yaml > service.yaml
vim service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: web
name: web
spec:
clusterIP: None
selector:
app: web
type: ClusterIP
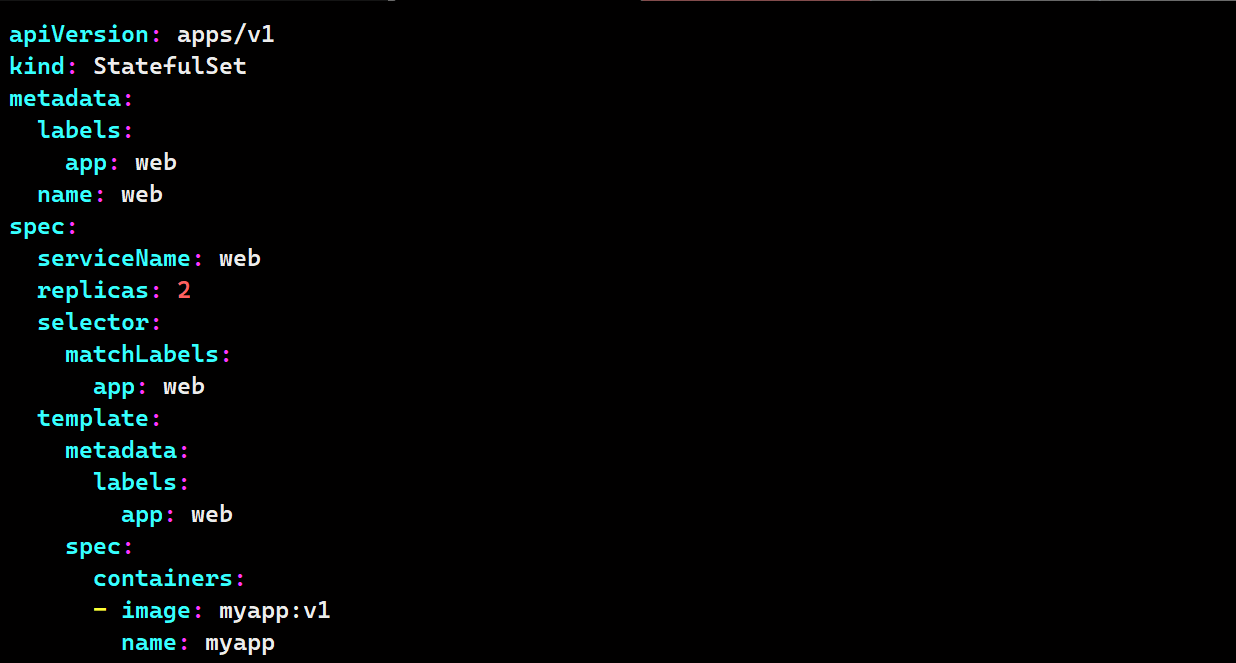
# 创建statefulset
kubectl create deployment web --image myapp:v1 --replicas 2 --dry-run=client -o yaml > web.yaml
vim web.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app: web
name: web
spec:
serviceName: web
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: myapp:v1
name: myapp
# 应用yaml
kubectl apply -f web.yaml
kubectl apply -f service.yaml
# 查看解析
dig web.default.svc.cluster.local. @10.96.0.10
dig web-0.web.default.svc.cluster.local. @10.96.0.10
dig web-1.web.default.svc.cluster.local. @10.96.0.10
# 查看主机名和IP
watch -n 1 kubectl get pods -o wide
kubectl delete pods web-1
# 回收资源
kubectl delete -f web.yaml
kubectl delete -f service.yaml

job控制器
Job主要用于负责批量处理(一次要处理指定数量任务)短暂的一次性(每个任务仅运行一次就结束)任务
vim job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
completions: 6
parallelism: 2
backoffLimit: 4
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
# 加载配置
kubectl apply -f job.yaml
# 查看日志
# 查看运行状态
kubectl get pods
# 选择运行完毕的
kubectl logs pi-6nkb2
# 显示圆周率后2000位
# 回收
kubectl delete jobs.batch pi
| 重启策略 | 功能 |
|---|---|
| OnFailure | 则job会在pod出现故障时重启容器,而不是创建pod,failed次数不变 |
| Never | job会在pod出现故障时创建新的pod,并且故障pod不会消失,也不会重启,failed次数加1 |
| Always | 一直重启,意味着job任务会重复去执行了 |
cronjob控制器
Cron Job 创建基于时间调度的 Jobs
CronJob可以在特定的时间点(反复的)去运行job任务
vim cronjob.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
# 加载yaml文件
kubectl apply -f cronjob.yaml
# 查看cronjob
kubectl get cronjobs.batch hello
# 查看运行的容器
kubectl get pods
# 查看执行情况
kubectl logs hello-29251140-44qsz hello
# 回收
kubectl delete -f cronjob.yaml
网络通信
整体架构
K8S通过CNI接口接入其他插件实现网络通讯,主流的插件有flannel,calico等
CNI插件存放位置:/etc/cni/net.d/
插件的解决方案
- 虚拟网桥:虚拟网卡,多个容器共用一个虚拟网卡进行通信
- 多路复用:MacVlan,多个容器共用一个物理网卡进行通信
- 硬件交换:SR-LOV,一个物理网卡可以虚拟出多个接口,性能最好
Pod-Pod通信
-
Pod是Kubernetes的最小调度单元,依赖**容器网络接口(CNI)**插件实现
-
每个Pod拥有独立的IP地址,且Pod间可直接通过IP通信(无需NAT)
-
CNI插件作用:为Pod分配IP,配置网络接口,设置路由或网络策略
- 常见的插件有:Calico、Flannel、WeaveNet等
-
同节点Pod通信:通过节点内部的CNI网桥转发,无需经过物理网络
-
跨节点Pod通信:由CNI插件通过路由、隧道或BGP等技术实现,具体取决于插件的网络方案(如Flannel使用VXLAN,Calico支持BGP)
Pod-Service通信
- 通过iptables或IPVS方式实现
- iptables模式:通过设置iptables规则,将ClusterIP的请求转发到后端PodIP
- IPVS模式:基于LVS实现,性能优于iptables,支持更多负载均衡算法
IPVS无法取代iptables,因为IPVS只能做负载均衡,实现不了NAT转换
集群外部-Pod通信
- iptables的MASQUERADE,即动态IP环境下的源地址转换(SNAT)
集群外部-Service通信
- NodePort、LoadBalancer、Ingress方式实现
- NodePort:在每个节点上开放一个静态端口(NodePort),外部客户端通过
节点IP:NodePort访问Service,再由Service转发到Pod - LoadBalancer:结合云服务商的负载均衡器,自动将外部流量通过负载均衡器转发到Service的NodePort
- Ingress:通常以Pod形式运行在集群中,暴露给外部(通过NodePort或LoadBalancer)
flannel网络插件
flannel插件
| 插件 | 功能 |
|---|---|
| VXLAN | Virtual Extensible LAN(虚拟可扩展局域网),是Linux本身支持的一网种网络虚拟化技术 VXLAN可以完全在内核态实现封装和解封装工作,从而通过 “隧道” 机制,构建出覆盖网络 |
| VTEP | VXLAN Tunnel End Point(虚拟隧道端点),在Flannel中 VNI的默认值是 1 这也是为什么宿主机的VTEP设备都叫 flannel.1 的原因 |
| Cni0 | 网桥设备,每创建一个 Pod 都会创建一对 veth pair 其中一端是 Pod 中的 eth0,另一端是 Cni0 网桥中的端口(网卡) |
| Flannel.1 | TUN设备(虚拟网卡),用来进行 vxlan 报文的处理(封包和解包) 不同node之间的Pod数据流量都从overlay设备以隧道的形式发送到对端 |
| Flanneld | flannel在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配 同时Flanneld监听K8s集群数据库,为flannel.1设备提供封装数据时必要的mac、ip等网络数据信息 |
flannel跨主机通信原理
- 当容器发送IP包,通过veth pair 发往cni网桥,再路由到本机的flannel.1设备进行处理
- VTEP设备之间通过二层数据帧进行通信,源VTEP设备收到原始IP包后,在上面加上一个目的MAC地址,封装成一个内部数据帧,发送给目的VTEP设备
- 内部数据桢,并不能在宿主机的二层网络传输,Linux内核还需要把它进一步封装成为宿主机的一个普通的数据帧,承载着内部数据帧通过宿主机的eth0进行传输
- Linux会在内部数据帧前面,加上一个VXLAN头,VXLAN头里有一个重要的标志叫VNI,它是VTEP识别某个数据桢是不是应该归自己处理的重要标识
- flannel.1设备只知道另一端flannel.1设备的MAC地址,却不知道对应的宿主机地址是什么。在linux内核里面,网络设备进行转发的依据,来自FDB的转发数据库,这个flannel.1网桥对应的FDB信息,是由flanneld进程维护的
- linux内核在IP包前面再加上二层数据帧头,把目标节点的MAC地址填进去,MAC地址从宿主机的ARP表获取
- 此时flannel.1设备就可以把这个数据帧从eth0发出去,再经过宿主机网络来到目标节点的eth0设备。目标主机内核网络栈会发现这个数据帧有VXLAN Header,并且VNI为1,Linux内核会对它进行拆包,拿到内部数据帧,根据VNI的值,交给本机flannel.1设备处理,flannel.1拆包,根据路由表发往cni网桥,最后到达目标容器
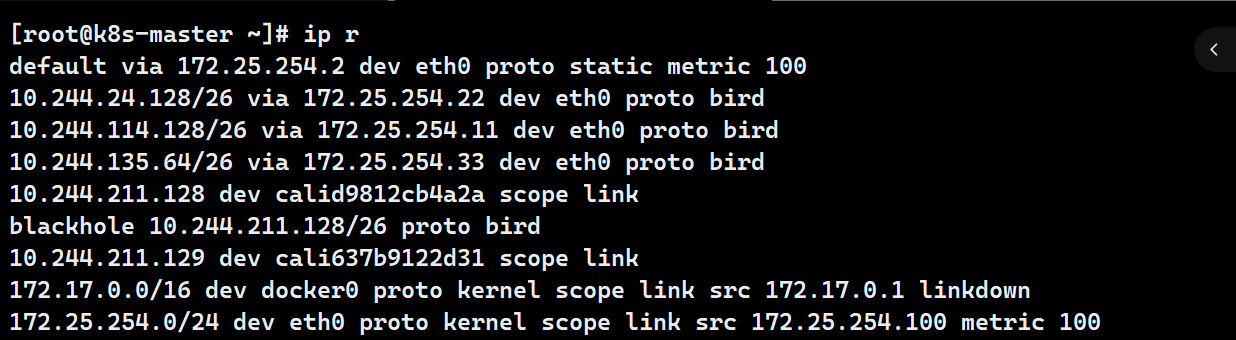
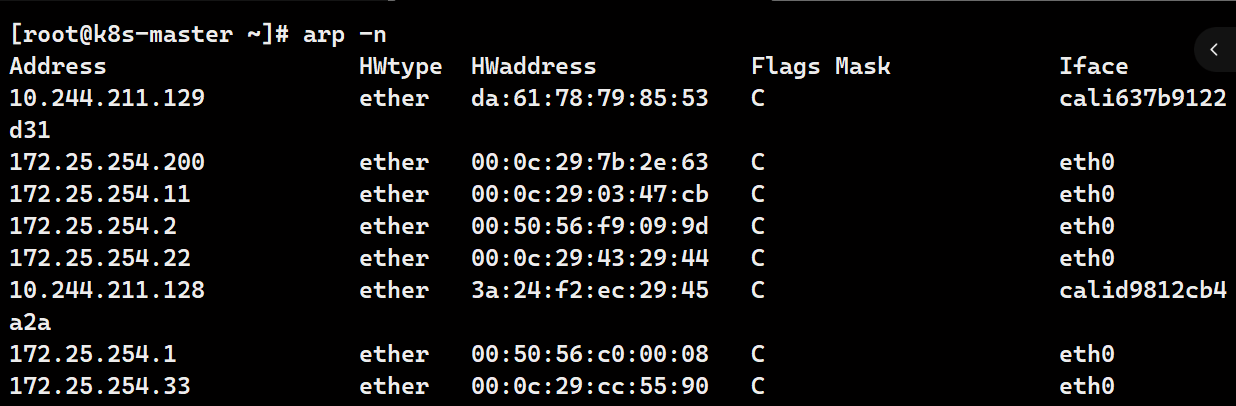
# 默认网络通信路由
ip r
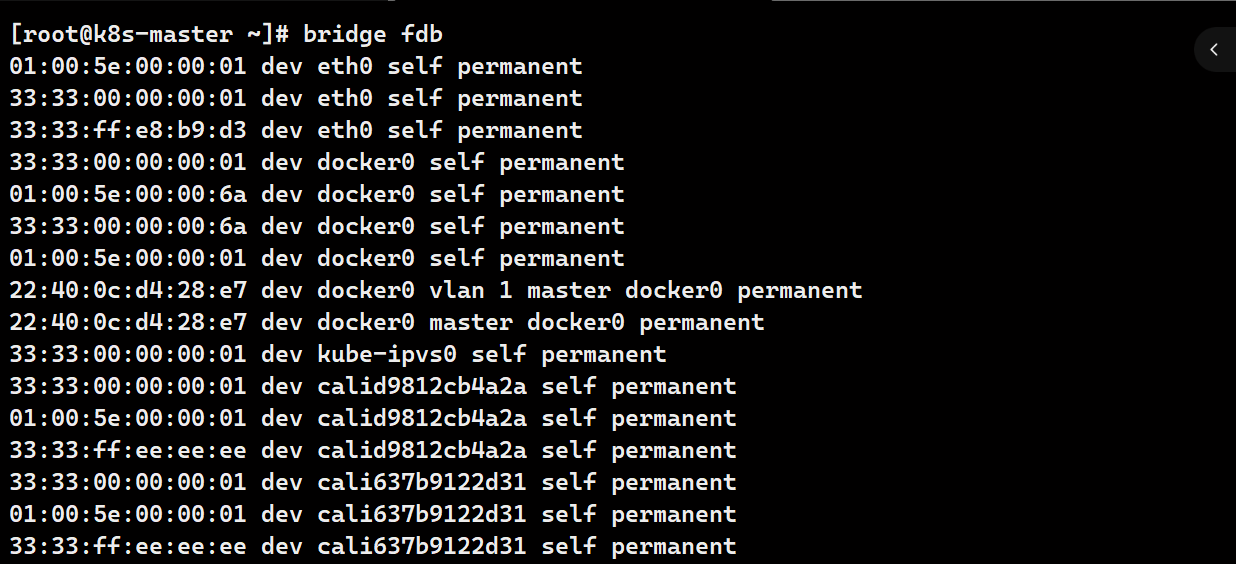
# 桥接转发数据库
bridge fdb
# arp列表
arp -n
flannel后端模式
| 网络模式 | 功能 |
|---|---|
| vxlan | 报文封装,默认模式 |
| Directrouting | 直接路由,跨网段使用vxlan,同网段使用host-gw模式 |
| host-gw | 主机网关,性能好,但只能在二层网络中,不支持跨网络 如果有成千上万的Pod,容易产生广播风暴,不推荐 |
| UDP | 性能差,不推荐 |
kubectl -n kube-flannel edit cm kube-flannel-cfg
net-conf.json: |
{
"Network": "10.244.0.0/16",
"EnableNFTables": false,
"Backend": {
# 更改内容
"Type": "host-gw"
}
}
# 重启pod
kubectl -n kube-flannel delete pod -all
# 查看网络通信路由
ip r
calico网络插件
官网:https://docs.projectcalico.org/getting-started/kubernetes/self-managed-onprem/onpremises
calico组件
calicao网络架构
calicao跨主机通信原理
calicao部署
# 删除Flannel插件
kubectl delete -f kube-flannel.yml
# 删除所有节点上flannel配置文件,避免冲突
rm -rf /etc/cni/net.d/10-flannel.conflist
# 下载部署文件
curl https://raw.githubusercontent.com/projectcalico/calico/v3.28.1/manifests/calico-typha.yaml -o calico.yaml
# 下载镜像上传至仓库
docker pull docker.io/calico/cni:v3.28.1
docker pull docker.io/calico/node:v3.28.1
docker pull docker.io/calico/kube-controllers:v3.28.1
docker pull docker.io/calico/typha:v3.28.1
# 更改yml设置
vim calico.yaml
4835 image: calico/cni:v3.28.1
4835 image: calico/cni:v3.28.1
4906 image: calico/node:v3.28.1
4932 image: calico/node:v3.28.1
5160 image: calico/kube-controllers:v3.28.1
5249 - image: calico/typha:v3.28.1
4973 - name: CALICO_IPV4POOL_VXLAN
4974 value: "Never"
4999 - name: CALICO_IPV4POOL_CIDR
5000 value: "10.244.0.0/16"
5001 - name: CALICO_AUTODETECTION_METHOD
5002 value: "interface=eth0"
kubectl apply -f calico.yaml
kubectl -n kube-system get pods
# 验证
kubectl run web --image myapp:v1
kubectl get pods -o wide
curl 10.244.169.129
调度
- 调度是指将未调度的Pod自动分配到集群中的节点的过程
- 调度器通过 kubernetes 的 watch 机制来发现集群中新创建且尚未被调度到 Node 上的 Pod
- 调度器会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行
调度原理
- 创建Pod
- 用户通过Kubernetes API创建Pod对象,并在其中指定Pod的资源需求、容器镜像等信息
- 调度器监视Pod
- Kubernetes调度器监视集群中的未调度Pod对象,并为其选择最佳的节点
- 选择节点
- 调度器通过算法选择最佳的节点,并将Pod绑定到该节点上。调度器选择节点的依据包括节点的资源使用情况、Pod的资源需求、亲和性和反亲和性等
- 绑定Pod到节点
- 调度器将Pod和节点之间的绑定信息保存在etcd数据库中,以便节点可以获取Pod的调度信息
- 节点启动Pod
- 节点定期检查etcd数据库中的Pod调度信息,并启动相应的Pod。如果节点故障或资源不足,调度器会重新调度Pod,并将其绑定到其他节点上运行
调度器种类
- 默认调度器(Default Scheduler):
- 是Kubernetes中的默认调度器,负责对新创建的Pod进行调度,并将Pod调度到合适的节点上
- 自定义调度器(Custom Scheduler):
- 是一种自定义的调度器实现,可以根据实际需求来定义调度策略和规则,以实现更灵活和多样化的调度功能
- 扩展调度器(Extended Scheduler):
- 是一种支持调度器扩展器的调度器实现,可以通过调度器扩展器来添加自定义的调度规则和策略,以实现更灵活和多样化的调度功能
- kube-scheduler是kubernetes中的默认调度器,在kubernetes运行后会自动在控制节点运行
调度方法
nodename
- nodeName 是节点选择约束的最简单方法,但一般不推荐
- 如果 nodeName 在 PodSpec 中指定了,则它优先于其他的节点选择方法
- 使用 nodeName 来选择节点的一些限制
- 如果指定的节点不存在。
- 如果指定的节点没有资源来容纳 pod,则pod 调度失败。
- 云环境中的节点名称并非总是可预测或稳定的
# 建立Pod 文件
kubectl run testpod --image myapp:v1 --dry-run=client -o yaml > pod1.yml
# 设置调度
vim pod1.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
nodeName: k8s-node2
containers:
- image: myapp:v1
name: testpod
# 建立Pod
kubectl apply -f pod1.yml
kubectl get pods -o wide
找不到节点pod会出现pending,优先级最高,其他调度方式无效
nodeselector
-
nodeSelector 是节点选择约束的最简单推荐形式
-
通过标签控制节点
-
给选择的节点添加标签:
- kubectl label nodes k8s-node1 lab=lee
-
可以给多个节点设定相同标签
# 查看节点标签
kubectl get nodes --show-labels
# 设定节点标签
kubectl label nodes k8s-node1 lab=timinglee
kubectl get nodes k8s-node1 --show-labels
# 调度设置
vim pod2.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
nodeSelector:
lab: timinglee
containers:
- image: myapp:v1
name: testpod
kubectl apply -f pod2.yml
kubectl get pods -o wide
节点标签可以给N个节点添加
affinity(亲和性)
官方文档:https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign-pod-node
- nodeSelector提供了一种非常简单的方法来将pod约束到具有特定标签的节点上
- 亲和/反亲和功能极大地扩展了你可以表达约束的类型
- 使用节点上的pod的标签来约束,而不是使用节点本身的标签,来允许哪些 pod 可以或者不可以被放置在一起
nodeAffinity(节点亲和)
- 那个节点服务指定条件就在那个节点运行
- requiredDuringSchedulingIgnoredDuringExecution 必须满足,但不会影响已经调度
- preferredDuringSchedulingIgnoredDuringExecution 倾向满足,在无法满足情况下也会调度pod
- IgnoreDuringExecution 表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,则继续运行当前的Pod。
- nodeaffinity还支持多种规则匹配条件的配置如下
| 匹配规则 | 功能 |
|---|---|
| ln | label 的值在列表内 |
| Notln | label 的值不在列表内 |
| Gt | label 的值大于设置的值,不支持Pod亲和性 |
| Lt | label 的值小于设置的值,不支持pod亲和性 |
| Exists | 设置的label 存在 |
| DoesNotExist | 设置的 label 不存在 |
# 配置
vim pod3.yml
apiVersion: v1
kind: Pod
metadata:
name: node-affinity
spec:
containers:
- name: nginx
image: nginx
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disk
operator: In
values:
- ssd
# 将pod运行在具有disk=ssd标签的k8s节点上,即pod根据节点的标签选择运行
Podaffinity(Pod的亲和)
- 那个节点有符合条件的POD就在那个节点运行
- podAffinity 主要解决POD可以和哪些POD部署在同一个节点中的问题
- podAntiAffinity主要解决POD不能和哪些POD部署在同一个节点中的问题。它们处理的是Kubernetes集群内部POD和POD之间的关系。
- Pod 间亲和与反亲和在与更高级别的集合(例如 ReplicaSets,StatefulSets,Deployments 等)一起使用时
- Pod 间亲和与反亲和需要大量的处理,这可能会显著减慢大规模集群中的调度
vim example4.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: "kubernetes.io/hostname"
kubectl get pods -o wide
Podantiaffinity(Pod反亲和)
vim example5.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
affinity:
podAntiAffinity:
# 反亲和
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: "kubernetes.io/hostname"
kubectl get pods -o wide
Taints(污点模式,禁止调度)
Taints(污点)是Node的一个属性
当节点存在Taints时,默认不会将Pod调度到此节点上
假如Pod设置Tolerations(容忍),只要Pod能根据规则容忍Node上的污点,那么K8s就会忽略节点污点,将Pod调度到此节点上
# 创建/追加(key相同时,覆盖)
kubectl taint nodes <your-nodename> key=string:effect
# 查询
kubectl describe nodes <your-nodename> | grep Taints:
# 删除
kubectl taint nodes <your-nodename> key-
其中 effect 的取值
| effect值 | 解释 |
|---|---|
| NoSchedule | 禁止新Pod调度到该节点,但不影响已在节点上运行的Pod 如果Pod没有匹配的容忍,则无法被调度到带有此污点的节点;已运行的Pod不受影响,会继续运行 |
| PreferNoSchedule | 尽量避免新Pod调度到该节点,但不是绝对禁止 K8s会优先将Pod调度到没有污点的节点;若没有其他合适节点,仍可调度到此节点(需Pod容忍此污点) |
| NoExecute | 既禁止新Pod调度,也会驱逐已运行的 Pod 如果Pod没有匹配的容忍,不仅无法调度到该节点,已在节点上运行的Pod也会被立即驱逐 |
# 建立控制器并运行
vim example6.yml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
kubectl apply -f example6.yml
kubectl get pod -o wide
# 设定污点未 NoSchedule
kubectl taint node k8s-node1 name=lee:NoSchedule
kubectl describe nodes k8s-node1 | grep Tain
# 控制器增加Pod
kubectl get pod -o wide
# 设定污点为 NoExecute
kubectl taint node k8s-node1 name=lee:NoExecute
kubectl describe nodes k8s-node1 | grep Tain
kubectl get pod -o wide
# 删除污点
kubectl taint node k8s-node1 name-
kubectl describe nodes k8s-node1 | grep Tain
tolerations(污点容忍)
- tolerations中定义的key、value、effect,要与node上设置的taint保持一直:
- 如果 operator 是 Equal ,则key与value之间的关系必须相等。
- 如果 operator 是 Exists ,value可以省略
- 如果不指定operator属性,则默认值为Equal。
- 还有两个特殊值:
- 当不指定key,再配合Exists 就能匹配所有的key与value ,可以容忍所有污点。
- 当不指定effect ,则匹配所有的effect
# 设定节点污点
kubectl taint node k8s-node1 name=lee:NoExecute
kubectl taint node k8s-node2 nodetype=bad:NoSchedule
vim example7.yml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 6
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
tolerations:
# 容忍所有污点
- operator: Exists
tolerations:
# 容忍effect为Noschedule的污点
- operator: Exists
effect: NoSchedule
tolerations:
# 容忍指定kv的NoSchedule污点
- key: nodetype
value: bad
effect: NoSchedule
微服务
内部控制器完成集群的工作负载,外部通过微服务暴露端口进行访问
Service是一组提供相同服务的Pod对外开放的接口
service默认只支持4层负载均衡能力,没有7层功能(可通过Ingress支持)
iptables调度
# 生成控制器文件
kubectl create deployment dep --image myapp:v1 --replicas 2 --dry-run=client -o yaml > dep.yaml
# 建立控制器
kubectl apply -f dep.yaml
# 生成微服务文件
kubectl expose deployment dep --port 80 --target-port 80 --dry-run=client -o yaml >> dep.yaml
# 修改yaml文件
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: dep
name: dep
spec:
replicas: 2
selector:
matchLabels:
app: dep
template:
metadata:
creationTimestamp: null
labels:
app: dep
spec:
containers:
- image: myapp:v1
name: myapp
---
apiVersion: v1
kind: Service
metadata:
labels:
app: dep
name: dep
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: dep
# 应用yaml文件
kubectl apply -f dep.yaml
# 查看微服务
kubectl get service -o wide
# 微服务默认使用iptables调度
iptables -t nat -nL
# 调度
curl 10.109.234.4/hostname.html
# 回收
kubectl delete -f dep.yaml
IPVS调度
- Service 是由 kube-proxy 组件,加上 iptables 来共同实现的
- kube-proxy 通过 iptables 处理 Service 的过程,需要在宿主机上设置相当多的 iptables 规则,如果宿主机有大量的Pod,不断刷新iptables规则,会消耗大量的CPU资源
- IPVS模式的service,可以使K8s集群支持更多量级的Pod
# 所有节点安装ipvsadm
yum install ipvsadm -y
# 修改master节点配置
kubectl -n kube-system edit cm kube-proxy
metricsBindAddress: ""
mode: "ipvs"
nftables:
# 重启Pod(回收旧的)
kubectl -n kube-system get pods | awk '/kube-proxy/{system("kubectl -n kube-system delete pods "$1)}'
# 检查
kubectl -n kube-system get pods
# 查看ipvs策略
ipvsadm -Ln
切换ipvs模式后,kube-proxy会在宿主机上添加一个虚拟网卡:kube-ipvs0,并分配所有service IP
ip a | tail
微服务类型
| 微服务类型 | 作用描述 |
|---|---|
| ClusterIP | 默认值,k8s系统给service自动分配的虚拟IP,只能在集群内部访问 |
| NodePort | 将Service通过指定的Node上的端口暴露给外部,访问任意一个NodeIP:nodePort都将路由到ClusterIP |
| LoadBalancer | 在NodePort的基础上,借助cloud provider创建一个外部的负载均衡器,并将请求转发到 NodeIP:NodePort,此模式只能在云服务器上使用 |
| ExternalName | 将服务通过 DNS CNAME 记录方式转发到指定的域名(通过 spec.externlName 设定 |
clusterip
clusterip模式只能在集群内访问,并对集群内的pod提供健康检测和自动发现功能
mv dep.yaml clu.yaml
vim clu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: dep
name: dep
spec:
replicas: 2
selector:
matchLabels:
app: dep
template:
metadata:
creationTimestamp: null
labels:
app: dep
spec:
containers:
- image: myapp:v1
name: myapp
---
apiVersion: v1
kind: Service
metadata:
labels:
app: dep
name: dep
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: dep
type: ClusterIP
# 创建后提供解析
# Pod名称.命名空间.svc.集群域名 @10.96.0.10
dig dep.default.svc.cluster.local @10.96.0.10
特殊模式headless
headless(无头服务)
对于无头 Services 并不会分配 Cluster IP,kube-proxy不会处理它们, 而且平台也不会为它们进行负载均衡和路由,集群访问通过dns解析直接指向到业务pod上的IP,所有的调度有dns单独完成
[root@k8s-master ~]# vim .yaml
---
apiVersion: v1
kind: Service
metadata:
labels:
app: timinglee
name: timinglee
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: timinglee
type: ClusterIP
clusterIP: None
[root@k8s-master ~]# kubectl delete -f timinglee.yaml
[root@k8s-master ~]# kubectl apply -f timinglee.yaml
deployment.apps/timinglee created
#测试
[root@k8s-master ~]# kubectl get services timinglee
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
timinglee ClusterIP None <none> 80/TCP 6s
[root@k8s-master ~]# dig timinglee.default.svc.cluster.local @10.96.0.10
; <<>> DiG 9.16.23-RH <<>> timinglee.default.svc.cluster.local @10.96.0.10
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 51527
;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: 81f9c97b3f28b3b9 (echoed)
;; QUESTION SECTION:
;timinglee.default.svc.cluster.local. IN A
;; ANSWER SECTION:
timinglee.default.svc.cluster.local. 20 IN A 10.244.2.14 #直接解析到pod上
timinglee.default.svc.cluster.local. 20 IN A 10.244.1.18
;; Query time: 0 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: Wed Sep 04 13:58:23 CST 2024
;; MSG SIZE rcvd: 178
#开启一个busyboxplus的pod测试
[root@k8s-master ~]# kubectl run test --image busyboxplus -it
If you don't see a command prompt, try pressing enter.
/ # nslookup timinglee-service
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: timinglee-service
Address 1: 10.244.2.16 10-244-2-16.timinglee-service.default.svc.cluster.local
Address 2: 10.244.2.17 10-244-2-17.timinglee-service.default.svc.cluster.local
Address 3: 10.244.1.22 10-244-1-22.timinglee-service.default.svc.cluster.local
Address 4: 10.244.1.21 10-244-1-21.timinglee-service.default.svc.cluster.local
/ # curl timinglee-service
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
/ # curl timinglee-service/hostname.html
timinglee-c56f584cf-b8t6m
nodeport
通过ipvs暴漏端口从而使外部主机通过master节点的对外ip:来访问pod业务
vim timinglee.yaml
---
apiVersion: v1
kind: Service
metadata:
labels:
app: timinglee-service
name: timinglee-service
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: timinglee
type: NodePort
[root@k8s-master ~]# kubectl apply -f timinglee.yaml
deployment.apps/timinglee created
service/timinglee-service created
[root@k8s-master ~]# kubectl get services timinglee-service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
timinglee-service NodePort 10.98.60.22 <none> 80:31771/TCP 8
nodeport在集群节点上绑定端口,一个端口对应一个服务
[root@k8s-master ~]# for i in {1..5}
> do
> curl 172.25.254.100:31771/hostname.html
> done
timinglee-c56f584cf-fjxdk
timinglee-c56f584cf-5m2z5
timinglee-c56f584cf-z2w4d
timinglee-c56f584cf-tt5g6
timinglee-c56f584cf-fjxdk
nodeport默认端口是30000-32767,超出会报错
[root@k8s-master ~]# vim timinglee.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: timinglee-service
name: timinglee-service
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
nodePort: 33333
selector:
app: timinglee
type: NodePort
[root@k8s-master ~]# kubectl apply -f timinglee.yaml
deployment.apps/timinglee created
The Service "timinglee-service" is invalid: spec.ports[0].nodePort: Invalid value: 33333: provided port is not in the valid range. The range of valid ports is 30000-32767
# 如果使用范围外的端口
# 需要特殊设定
vim /etc/kubernetes/manifests/kube-apiserver.yaml
- --service-node-port-range=30000-40000
添加“–service-node-port-range=“ 参数,端口范围可以自定义
修改后api-server会自动重启,等apiserver正常启动后才能操作集群
集群重启自动完成在修改完参数后全程不需要人为干预
metalLB
官网:https://metallb.universe.tf/installation/
为LoadBalancer分配vip
# 设置ipvs模式,打开
kubectl -n kube-system edit cm kube-proxy
# 回收Pod,使配置生效
kubectl -n kube-system get pods | awk '/kube-proxy/{system("kubectl -n kube-system delete pods "$1)}'
# 下载部署文件
wget https://raw.githubusercontent.com/metallb/metallb/v0.13.12/config/manifests/metallb-native.yaml
# 私有仓库创建metallb项目(公开)
# 上传metallb-native.yaml、configmap.yml、metalLB.tag.gz
# 加载镜像
docker load -i metalLB.tag.gz
# 打标签
docker tag quay.io/metallb/controller:v0.14.8 ooovooo.org/metallb/controller:v0.14.8
docker tag quay.io/metallb/speaker:v0.14.8 ooovooo.org/metallb/speaker:v0.14.8
# 上传镜像
docker push ooovooo.org/metallb/speaker:v0.14.8
docker push ooovooo.org/metallb/controller:v0.14.8
# 修改配置文件
vim metallb-native.yaml
image: metallb/controller:v0.14.8
image: metallb/speaker:v0.14.8
vim configmap.yml
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: first-pool # 地址池名称
namespace: metallb-system
spec:
addresses:
- 172.25.254.50-172.25.254.99 # 修改本机主机段,不能有IP被占用
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: example
namespace: metallb-system
spec:
ipAddressPools:
- first-pool # 使用地址池
# 应用yml
kubectl apply -f metallb-native.yaml
kubectl apply -f configmap.yml
# 等待服务启动
kubectl -n metallb-system get pods
# 测试
# 创建一个services
vim services.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: dep
name: dep
spec:
replicas: 2
selector:
matchLabels:
app: dep
template:
metadata:
creationTimestamp: null
labels:
app: dep
spec:
containers:
- image: myapp:v1
name: myapp
---
apiVersion: v1
kind: Service
metadata:
labels:
app: dep
name: dep
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: dep
type: LoadBalancer
# 查看状态
kubectl get services
# 测试
curl 172.25.254.50
loadbalancer
云平台会为我们分配vip并实现访问,如果是裸金属主机那么需要metallb来实现ip的分配
[root@k8s-master ~]# vim timinglee.yaml
---
apiVersion: v1
kind: Service
metadata:
labels:
app: timinglee-service
name: timinglee-service
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: timinglee
type: LoadBalancer
[root@k8s2 service]# kubectl apply -f myapp.yml
默认无法分配外部访问IP
[root@k8s2 service]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 4d1h
myapp LoadBalancer 10.107.23.134 <pending> 80:32537/TCP 4s
LoadBalancer模式适用云平台,裸金属环境需要安装metallb提供支持
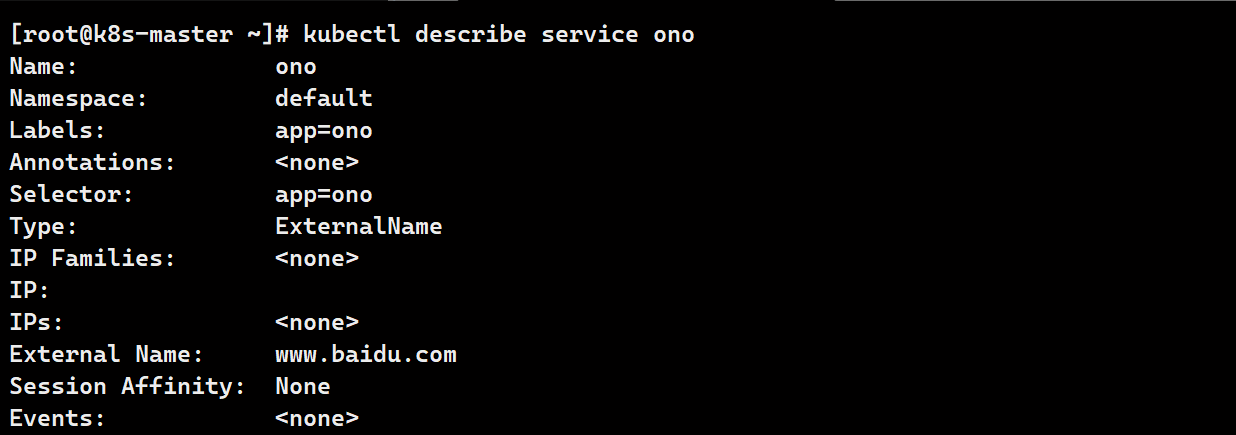
externalname
- 开启services后,不会被分配IP,而是用dns解析CNAME固定域名来解决ip变化问题
- 一般应用于外部业务和pod沟通或外部业务迁移到pod内时
- 在应用向集群迁移过程中,externalname在过度阶段就可以起作用了。
- 集群外的资源迁移到集群时,在迁移的过程中ip可能会变化,但是域名+dns解析能完美解决此问题
# 生成yaml文件
kubectl create service externalname ono --external-name www.baidu.com -dry-run=client -o yaml > ext.yaml
# 编辑文件
vim ext.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: ono
name: ono
spec:
externalName: www.baidu.com
selector:
app: ono
type: ExternalName
# 应用yaml
kubectl apply -f ext.yaml
# 查看ExternalName域名
kubectl describe service ono
# 查看解析
dig ono.default.svc.cluster.local @10.96.0.10
# externalName指向www.baidu.com
ono.default.svc.cluster.local. 30 IN CNAME www.baidu.com.
# 解析到的百度服务器的IP
www.a.shifen.com. 30 IN A 183.2.172.177
www.a.shifen.com. 30 IN A 183.2.172.17
# 测试
kubectl run ono --image busyboxplus -it
ping ono.default.svc.cluster.local



Ingress-nginx
官网:https://kubernetes.github.io/ingress-nginx/deploy/#bare-metal-clusters
- 一种全局的、为了代理不同后端 Service 而设置的负载均衡服务,支持7层
- Ingress由两部分组成:Ingress controller和Ingress服务
- Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力
需要提前部署metallb
部署
# 打标签
docker tag registry.k8s.io/ingress-nginx/controller:v1.13.1 ooovooo.org/ingress-nginx/controller:v1.13.1
docker tag registry.k8s.io/ingress-nginx/kube-webhook-certgen:v1.6.1 ooovooo.org/ingress-nginx/kube-webhook-certgen:v1.6.1
# 上传镜像
docker push ooovooo.org/ingress-nginx/controller:v1.13.1
docker push ooovooo.org/ingress-nginx/kube-webhook-certgen:v1.6.1
# 修改yaml,注意自己的版本
vim deploy.yaml
444 image: ingress-nginx/controller:v1.13.1
547 image: ingress-nginx/kube-webhook-certgen:v1.6.1
603 image: ingress-nginx/kube-webhook-certgen:v1.6.1
sed -n '444p;547p;603p' deploy.yaml
# 应用
kubectl apply -f deploy.yaml
# 查看状态
watch -n 1 kubectl -n ingress-nginx get pods
# 查看ingress-nginx
kubectl -n ingress-nginx get svc
NAME TYPE
ingress-nginx-controller NodePort
# 假如没有EXTERNAL-IP,则没有配置好metalLB
# 修改微服务类型
kubectl -n ingress-nginx edit svc ingress-nginx-controller
51 type: LoadBalancer
# 检验
kubectl -n ingress-nginx get svc
NAME TYPE
ingress-nginx-controller LoadBalancer


测试
# 生成yaml文件
kubectl create ingress uou --rule '*/=ooovooo-svc:80' --dry-run=client -o yaml > ingress.yml
vim ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: uou
spec:
ingressClassName: nginx
rules:
- http:
paths:
- backend:
service:
name: ooovooo-svc
port:
number: 80
path: /
pathType: Prefix
# 应用yaml
kubectl apply -f ingress.yml
# 查看状态
kubectl get ingress
# 生成后端服务器
# 访问
ingress高级用法
基于路径的访问
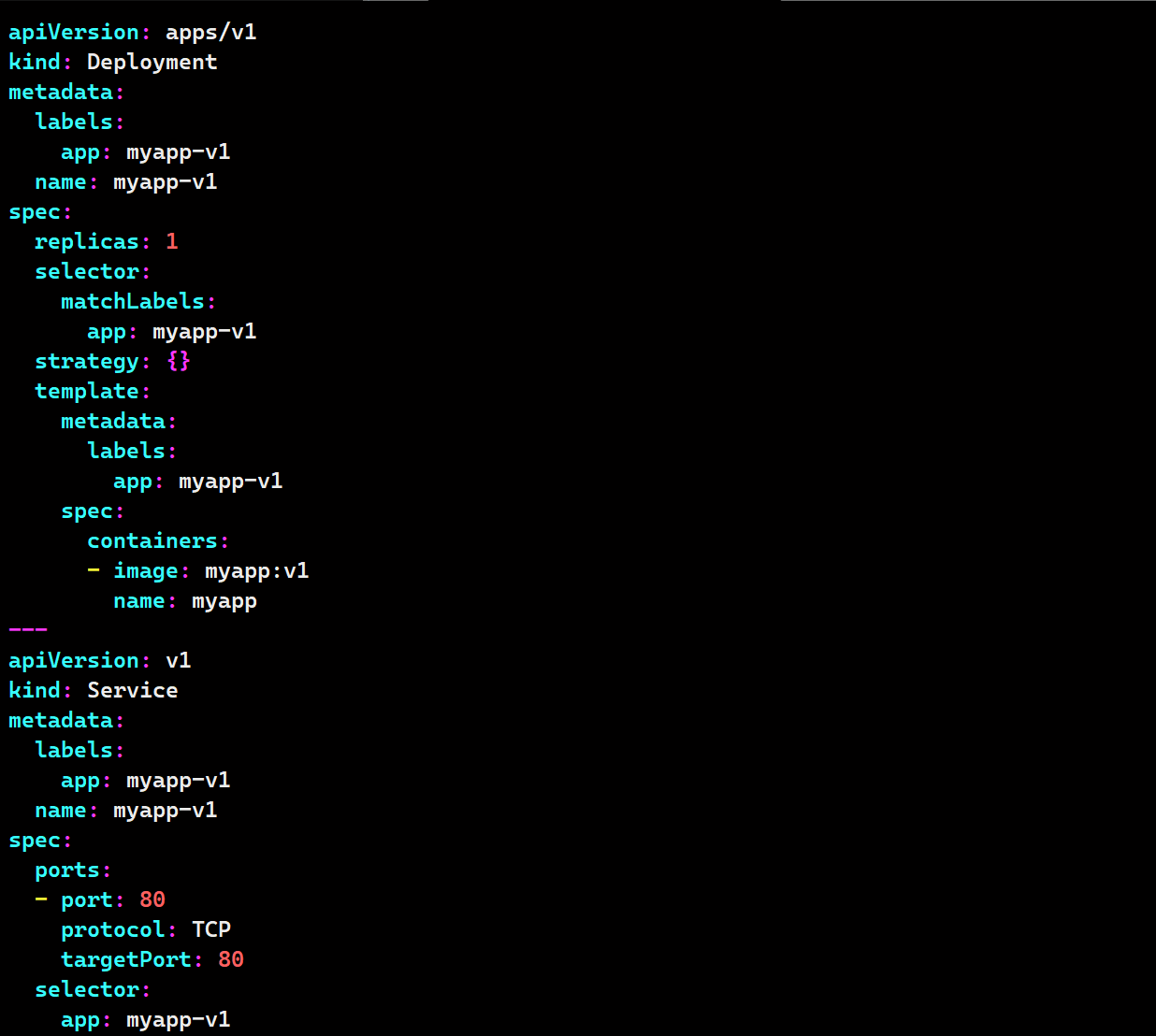
# 生成yaml
kubectl create deployment myapp-v1 --image myapp:v1 --dry-run=client -o yaml > myapp-v1.yaml
kubectl create deployment myapp-v2 --image myapp:v2 --dry-run=client -o yaml > myapp-v2.yaml
# 配置v1
vim myapp-v1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: myapp-v1
name: myapp-v1
spec:
replicas: 1
selector:
matchLabels:
app: myapp-v1
strategy: {}
template:
metadata:
labels:
app: myapp-v1
spec:
containers:
- image: myapp:v1
name: myapp
---
apiVersion: v1
kind: Service
metadata:
labels:
app: myapp-v1
name: myapp-v1
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: myapp-v1
# 配置v2
vim myapp-v2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: myapp-v2
name: myapp-v2
spec:
replicas: 1
selector:
matchLabels:
app: myapp-v2
strategy: {}
template:
metadata:
labels:
app: myapp-v2
spec:
containers:
- image: myapp:v2
name: myapp
---
apiVersion: v1
kind: Service
metadata:
labels:
app: myapp-v2
name: myapp-v2
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: myapp-v2
#
# 暴露端口
kubectl expose deployment myapp-v1 --port 80 --target-port 80 --dry-run=client -o yaml >> myapp-v1.yaml
kubectl expose deployment myapp-v2 --port 80 --target-port 80 --dry-run=client -o yaml >> myapp-v2.yaml
# 查看service状态
kubectl get services

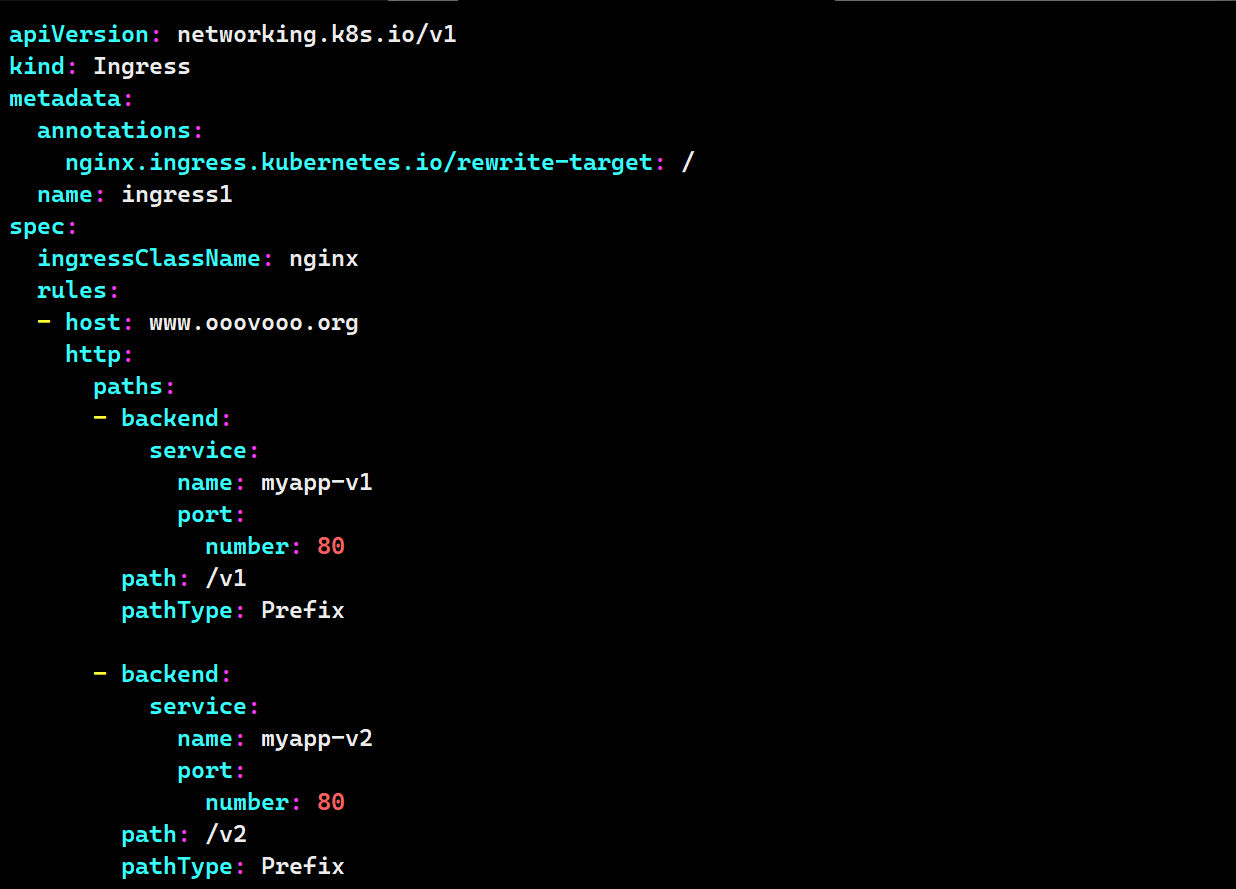
# 建立ingress
vim ingress1.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
# 将匹配到的请求路径,重写(替换)为 / 后,再转发到后端服务
nginx.ingress.kubernetes.io/rewrite-target: /
name: ingress1
spec:
ingressClassName: nginx
rules:
- host: www.ooovooo.org
http:
paths:
- backend:
service:
name: myapp-v1
port:
number: 80
path: /v1
pathType: Prefix
- backend:
service:
name: myapp-v2
port:
number: 80
path: /v2
pathType: Prefix
# 测试
kubectl apply -f ingress1.yaml
echo 172.25.254.55 www.ooovooo.org >> /etc/hosts
curl www.ooovooo.org/v1
curl www.ooovooo.org/v2
curl www.ooovooo.org/v2/vvip

基于域名的访问
# ingress-nginx-controller的EXTERNAL-IP
echo "172.25.254.50 www.myapp-v1.org" >> /etc/hosts
echo "172.25.254.50 www.myapp-v2.org" >> /etc/hosts
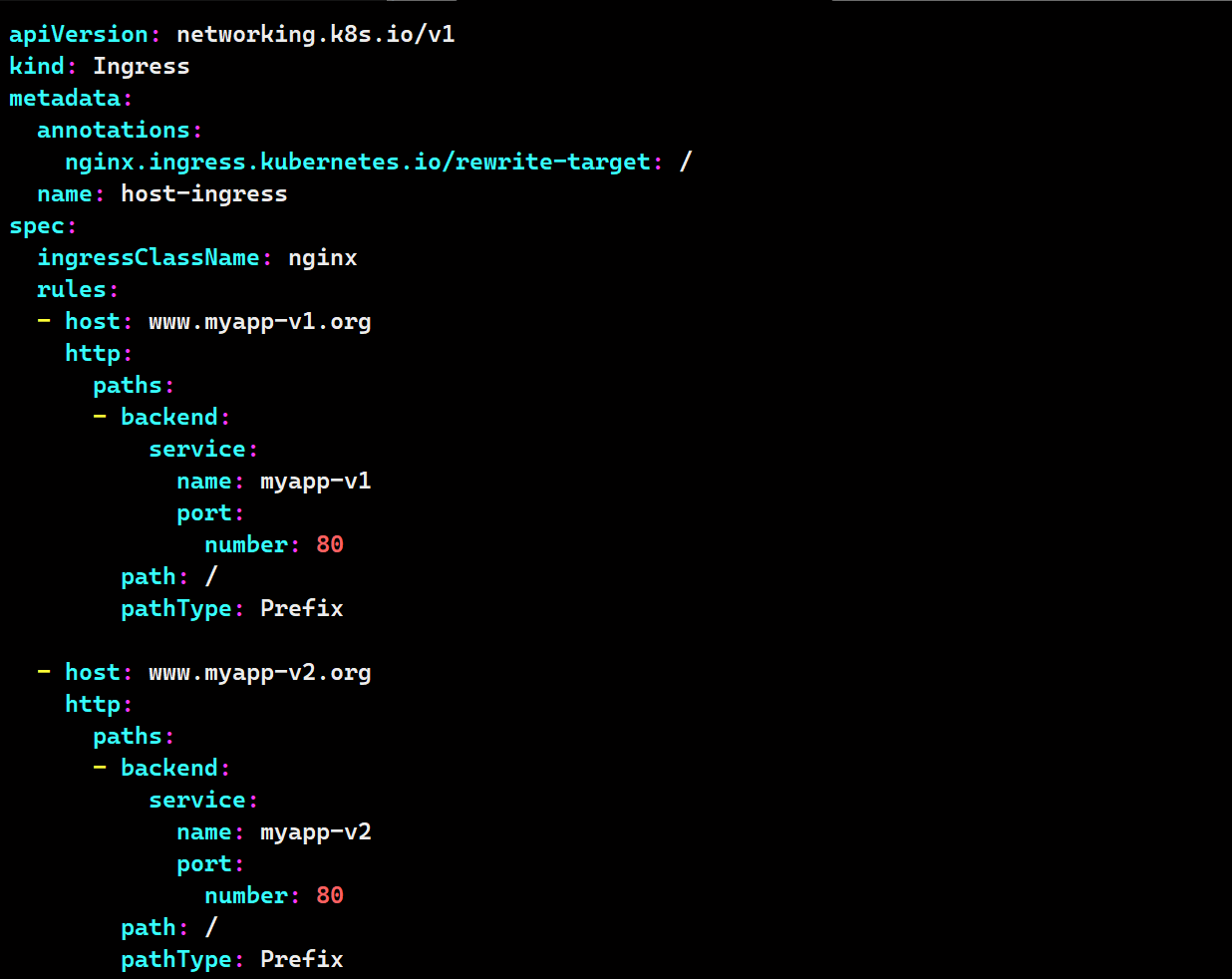
vim host-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
name: host-ingress
spec:
ingressClassName: nginx
rules:
- host: www.myapp-v1.org
http:
paths:
- backend:
service:
name: myapp-v1
port:
number: 80
path: /
pathType: Prefix
- host: www.myapp-v2.org
http:
paths:
- backend:
service:
name: myapp-v2
port:
number: 80
path: /
pathType: Prefix
# 应用ingress
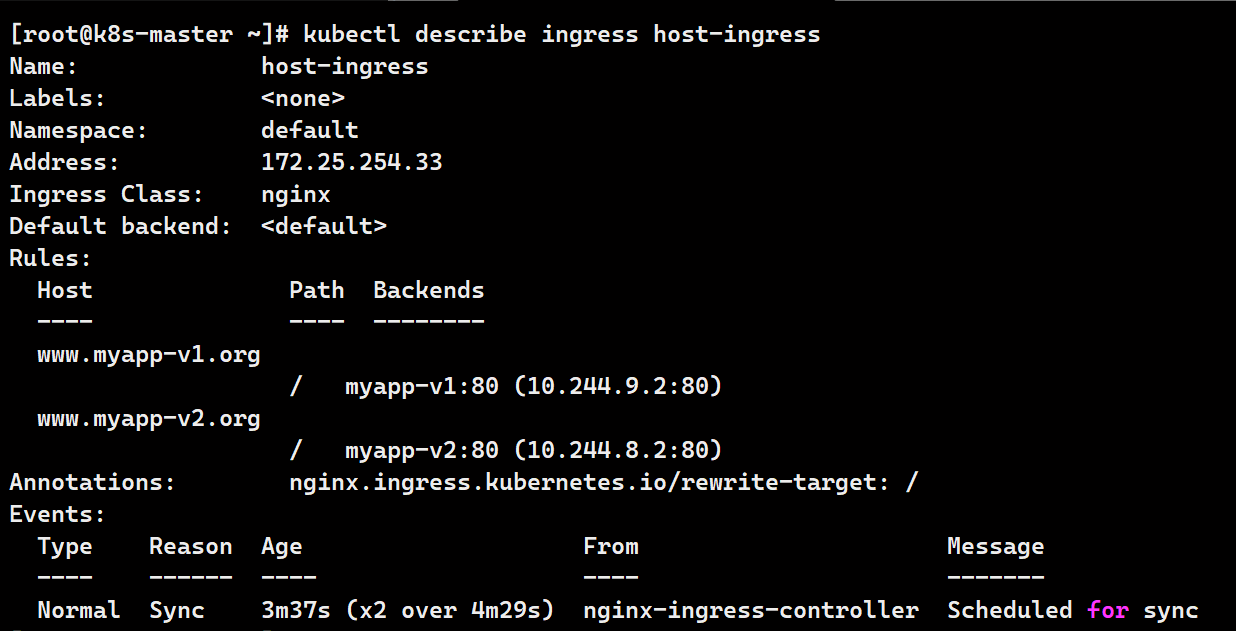
kubectl apply -f host-ingress.yaml
kubectl describe ingress host-ingress
# 测试
curl www.myapp-v1.org
curl www.myapp-v2.org

建立tls加密
# 建立证书
openssl req -newkey rsa:2048 -nodes -keyout tls.key -x509 -days 365 -subj "/CN=nginxsvc/O=nginxsvc" -out tls.crt
# 建立加密资源
kubectl create secret tls web-tls-secret --key tls.key --cert tls.crt
# 查看资源
kubectl get secrets
secrets通常在kubetnetes中存放敏感数据
# 建立基于tls认证的yaml文件
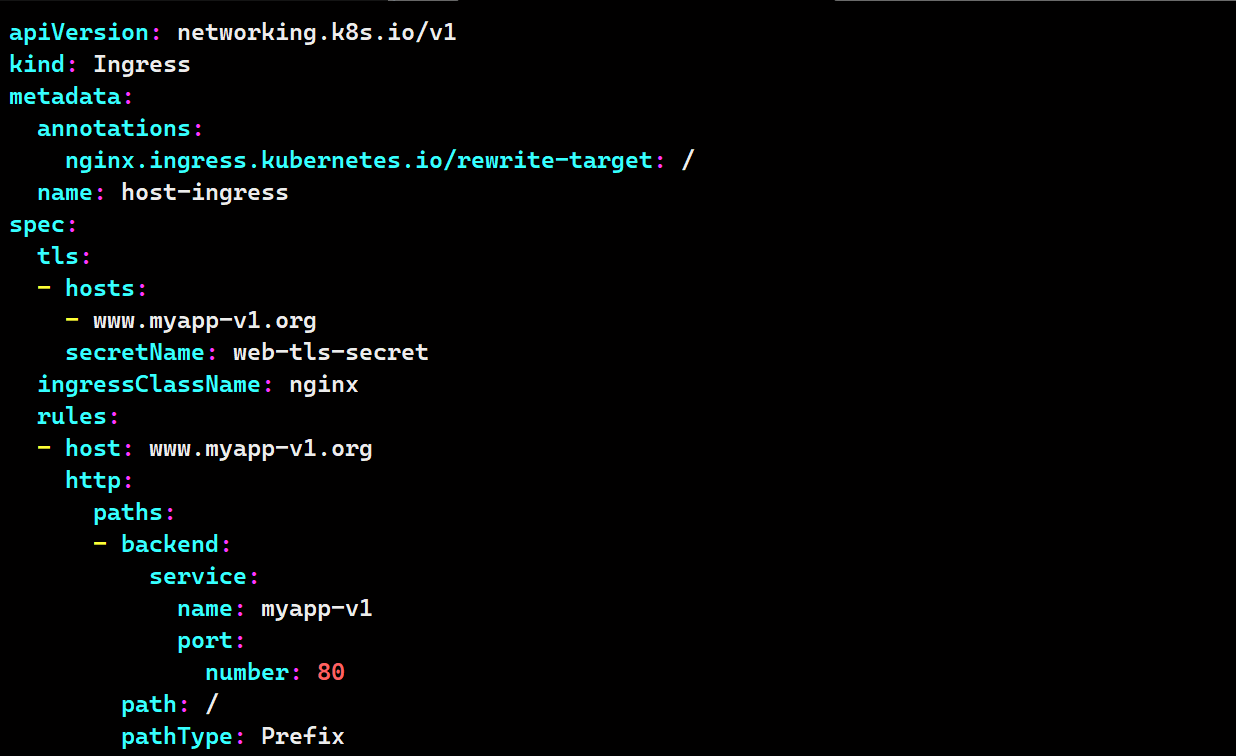
vim tls-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
name: tls-ingress
spec:
tls:
- hosts:
- www.myapp-v1.org
secretName: web-tls-secret
ingressClassName: nginx
rules:
- host: www.myapp-v1.org
http:
paths:
- backend:
service:
name: myapp-v1
port:
number: 80
path: /
pathType: Prefix
# 需要有172.25.254.50 www.myapp-v1.org的解析
curl www.myapp-v1.org
curl -k https://www.myapp-v1.org
建立auth认证
# 认证文件
dnf install httpd-tools -y
# 注意:文件名必须是auth,否则资源不识别
htpasswd -cm auth ovo
cat auth
# 建立认证资源
kubectl create secret generic auth-web --from-file auth
# 建立基于用户的yaml文件
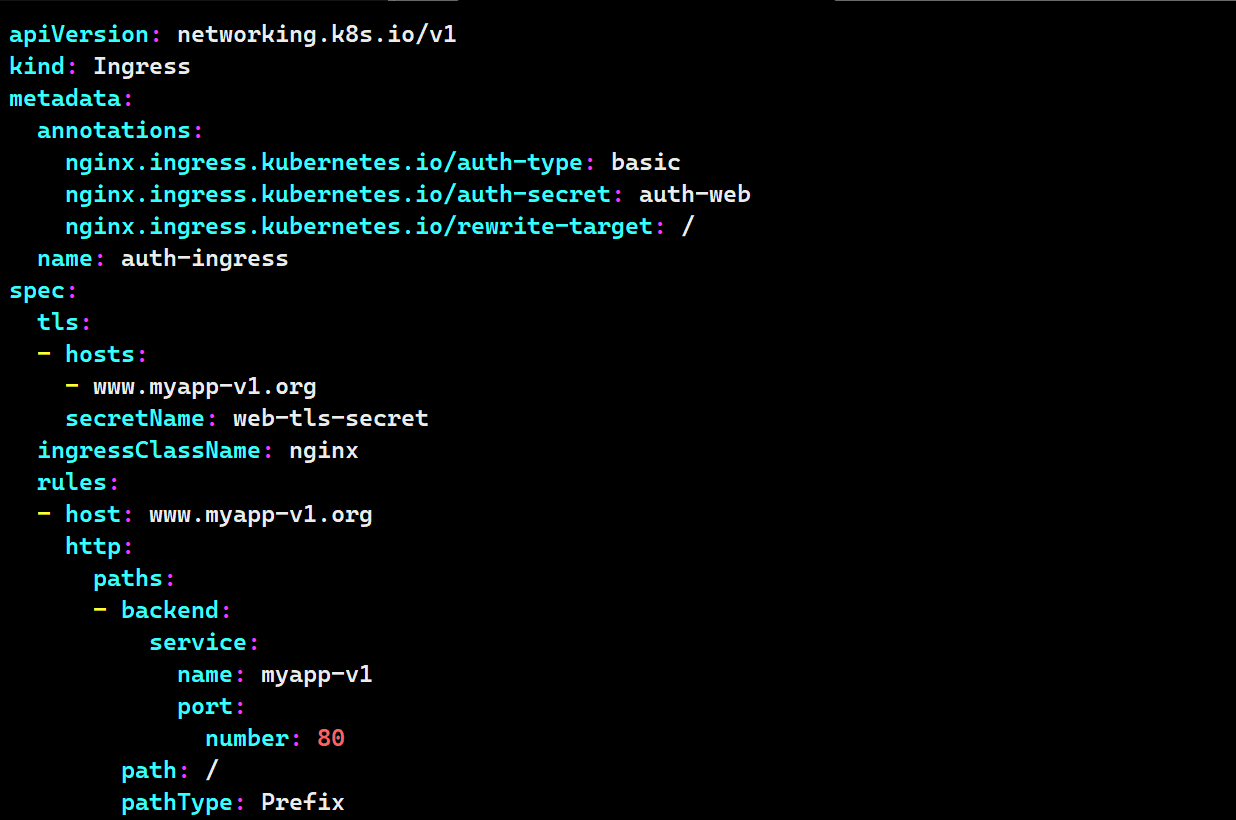
vim auth-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/auth-type: basic
nginx.ingress.kubernetes.io/auth-secret: auth-web
nginx.ingress.kubernetes.io/rewrite-target: /
name: auth-ingress
spec:
tls:
- hosts:
- www.myapp-v1.org
secretName: web-tls-secret
ingressClassName: nginx
rules:
- host: www.myapp-v1.org
http:
paths:
- backend:
service:
name: myapp-v1
port:
number: 80
path: /
pathType: Prefix
# 应用yaml
kubectl apply -f auth-ingress.yaml
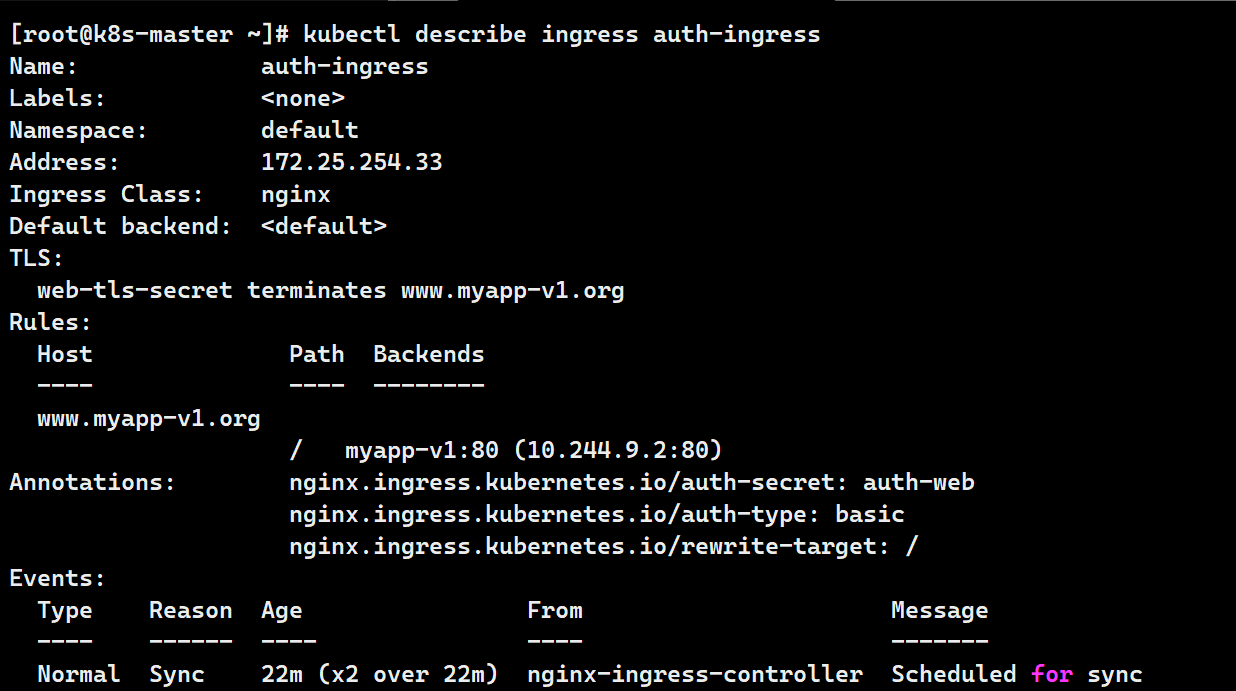
kubectl describe ingress auth-ingress
# 测试
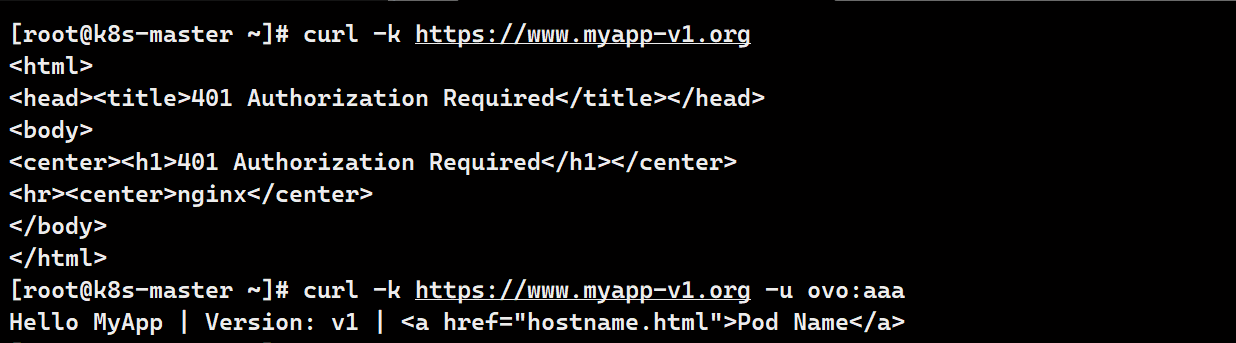
curl -k https://www.myapp-v1.org
curl -k https://www.myapp-v1.org -u ovo:aaa
rewrite重定向
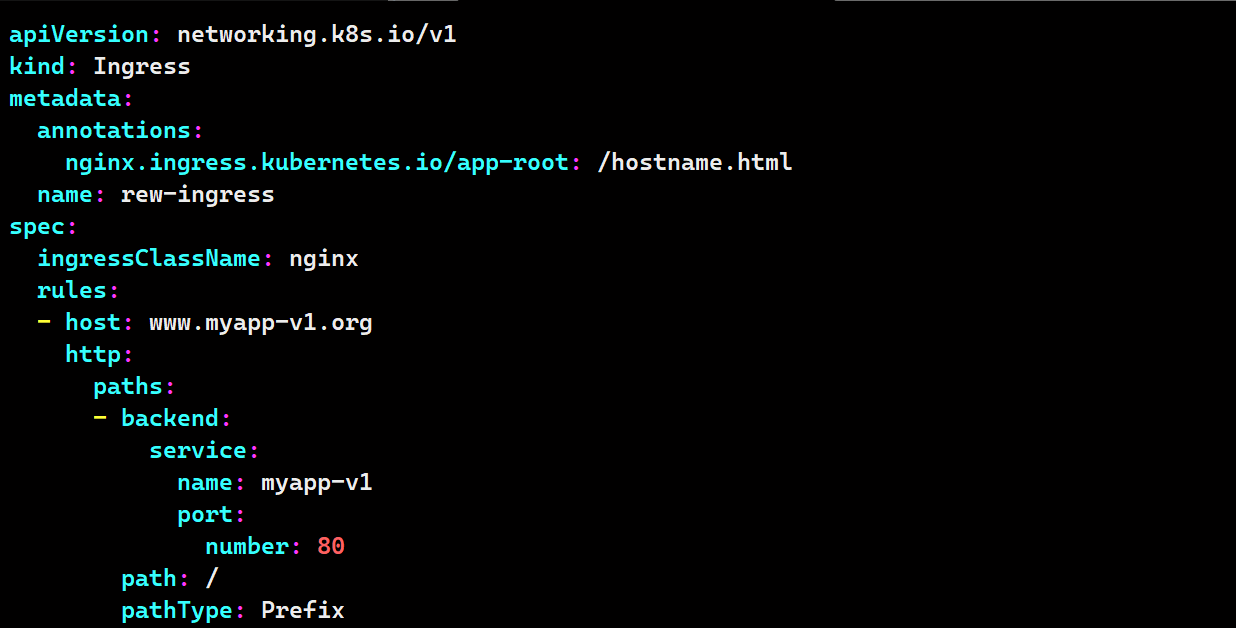
vim rew-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/app-root: /hostname.html
name: rew-ingress
spec:
ingressClassName: nginx
rules:
- host: www.myapp-v1.org
http:
paths:
- backend:
service:
name: myapp-v1
port:
number: 80
path: /
pathType: Prefix
# 应用yaml
kubectl apply -f rew-ingress.yaml
# 查看
kubectl describe ingress rew-ingress
# 测试
curl www.myapp-v1.org
curl www.myapp-v1.org/hostname.html
curl -L www.myapp-v1.org
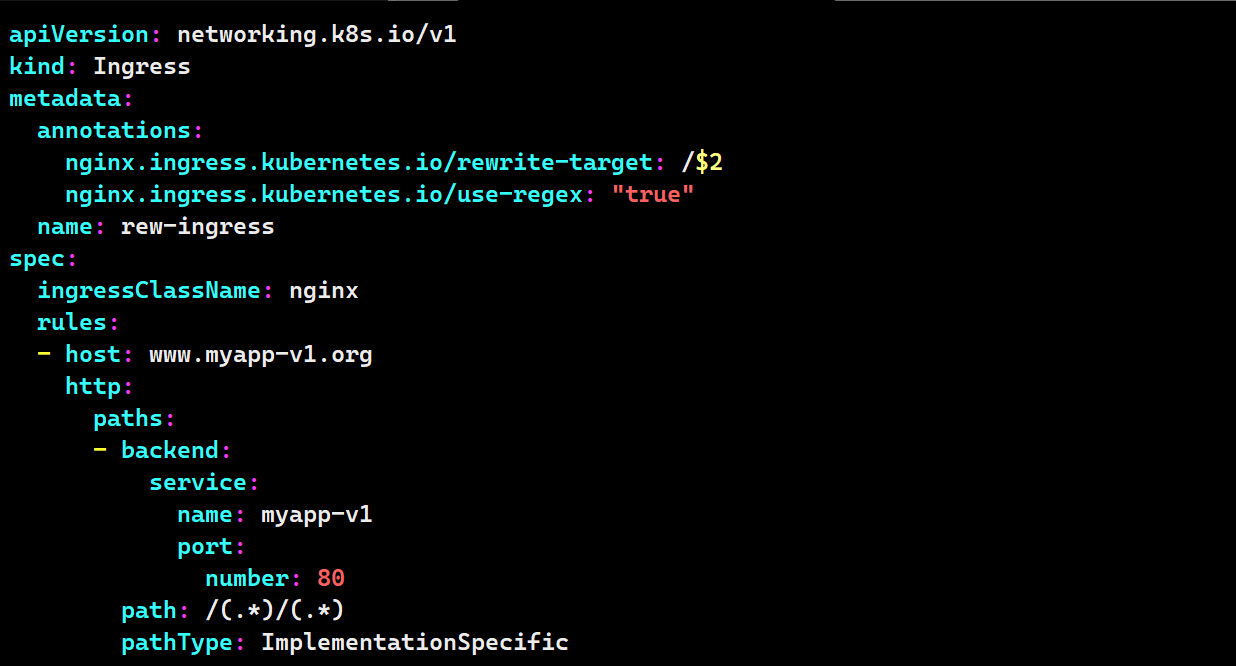
vim rew-ingress2.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$2
nginx.ingress.kubernetes.io/use-regex: "true"
name: rew-ingress2
spec:
ingressClassName: nginx
rules:
- host: www.myapp-v1.org
http:
paths:
- backend:
service:
name: myapp-v1
port:
number: 80
path: /(.*)/(.*)
pathType: ImplementationSpecific
# 应用yaml
kubectl apply -f rew-ingress2.yaml
# 查看
kubectl describe ingress rew-ingress2
# 测试
curl -L www.myapp-v1.org/hostname.html
curl -L www.myapp-v1.org/ono/
curl -L www.myapp-v1.org/ono/hostname.html
canary金丝雀发布
基于header(http包头)灰度
- 通过Annotaion扩展
- 创建灰度ingress,配置灰度头部key以及value
- 灰度流量验证完毕后,切换正式ingress到新版本
- 之前我们在做升级时可以通过控制器做滚动更新,默认25%利用header可以使升级更为平滑,通过key 和vule 测试新的业务体系是否有问题。
#建立版本1的ingress
[root@k8s-master app]# vim ingress7.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
name: myapp-v1-ingress
spec:
ingressClassName: nginx
rules:
- host: myapp-tls.ooovooo.org
http:
paths:
- backend:
service:
name: myappv1
port:
number: 80
path: /
pathType: Prefix
[root@k8s-master app]# kubectl describe ingress myapp-v1-ingress
Name: myapp-v1-ingress
Labels: <none>
Namespace: default
Address: 172.25.254.10
Ingress Class: nginx
Default backend: <default>
Rules:
Host Path Backends
---- ---- --------
myapp.timinglee.org
/ myapp-v1:80 (10.244.2.31:80)
Annotations: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Sync 44s (x2 over 73s) nginx-ingress-controller Scheduled for sync
#建立基于header的ingress
[root@k8s-master app]# vim ingress8.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-header: version
nginx.ingress.kubernetes.io/canary-by-header-value: 2
name: myapp-v2-ingress
spec:
ingressClassName: nginx
rules:
- host: myapp-tls.ooovooo.org
http:
paths:
- backend:
service:
name: myappv2
port:
number: 80
path: /
pathType: Prefix
[root@k8s-master app]# kubectl apply -f ingress8.yml
ingress.networking.k8s.io/myapp-v2-ingress created
[root@k8s-master app]# kubectl describe ingress myapp-v2-ingress
Name: myapp-v2-ingress
Labels: <none>
Namespace: default
Address:
Ingress Class: nginx
Default backend: <default>
Rules:
Host Path Backends
---- ---- --------
myapp.timinglee.org
/ myapp-v2:80 (10.244.2.32:80)
Annotations: nginx.ingress.kubernetes.io/canary: true
nginx.ingress.kubernetes.io/canary-by-header: version
nginx.ingress.kubernetes.io/canary-by-header-value: 2
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Sync 21s nginx-ingress-controller Scheduled for sync
#测试:
[root@reg ~]# curl myapp.timinglee.org
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@reg ~]# curl -H "version: 2" myapp.timinglee.org
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
基于权重的灰度发布
- 通过Annotaion拓展
- 创建灰度ingress,配置灰度权重以及总权重
- 灰度流量验证完毕后,切换正式ingress到新版本
#基于权重的灰度发布
[root@k8s-master app]# vim ingress9.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-weight: "10"
# 更改权重值
nginx.ingress.kubernetes.io/canary-weight-total: "100"
name: myapp-v2-ingress
spec:
ingressClassName: nginx
rules:
- host: myapp-tls.ooovooo.org
http:
paths:
- backend:
service:
name: myappv2
port:
number: 80
path: /
pathType: Prefix
[root@k8s-master app]# kubectl apply -f ingress8.yml
ingress.networking.k8s.io/myapp-v2-ingress created
#测试:
[root@reg ~]# vim check_ingress.sh
#!/bin/bash
v1=0
v2=0
for (( i=0; i<100; i++))
do
response=`curl -s myapp.timinglee.org |grep -c v1`
v1=`expr $v1 + $response`
v2=`expr $v2 + 1 - $response`
done
echo "v1:$v1, v2:$v2"
[root@reg ~]# sh check_ingress.sh
v1:90, v2:10
#更改完毕权重后继续测试可观察变化
存储
| 存储类型 | 功能 |
|---|---|
| configmap | 用于保存配置数据,以键值对形式存储 |
| secrets | 用来保存敏感信息 |
| volumes | 存储容器内容 |
| StorageClass | 存储容器内容 |
| statefulset | 管理有状态服务 |
configmap
保存配置数据,以键值对形式存储
etcd(键值存储系统)限制了文件大小不能超过1M(超过1M,需要修改数据)
创建方式
字面值
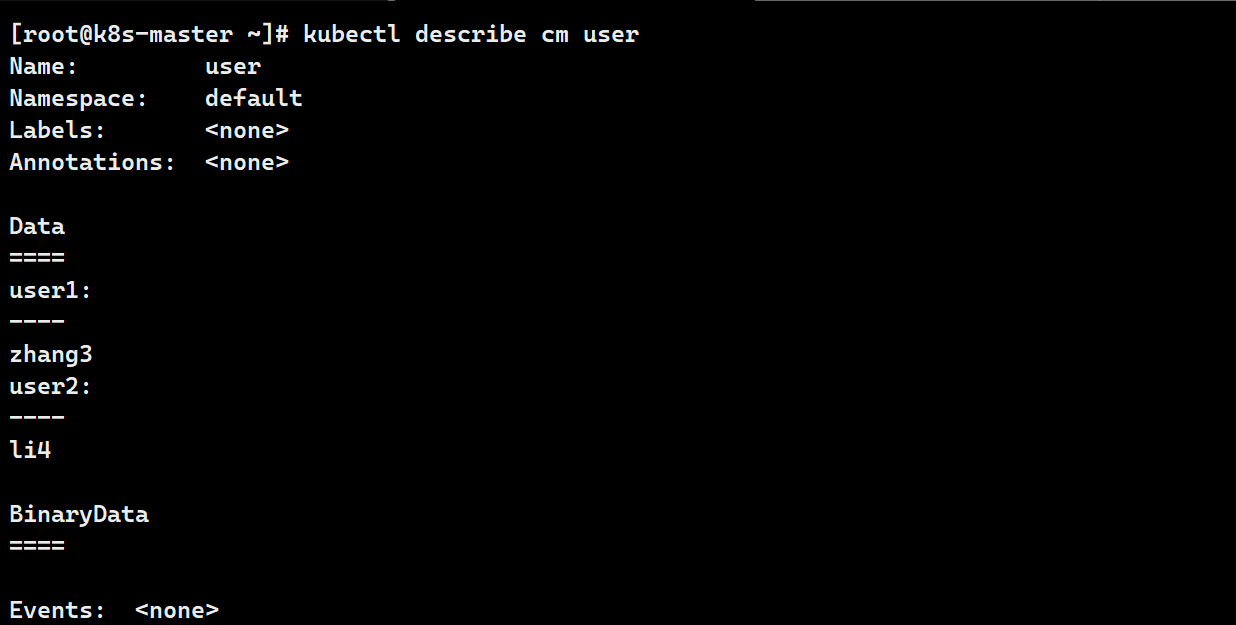
# 键=值方式
kubectl create configmap user --from-literal user1=zhang3 --from-literal user2=li4
# 查看user(可缩写成cm)
kubectl describe cm user
# 删除
kubectl delete configmaps user
文件
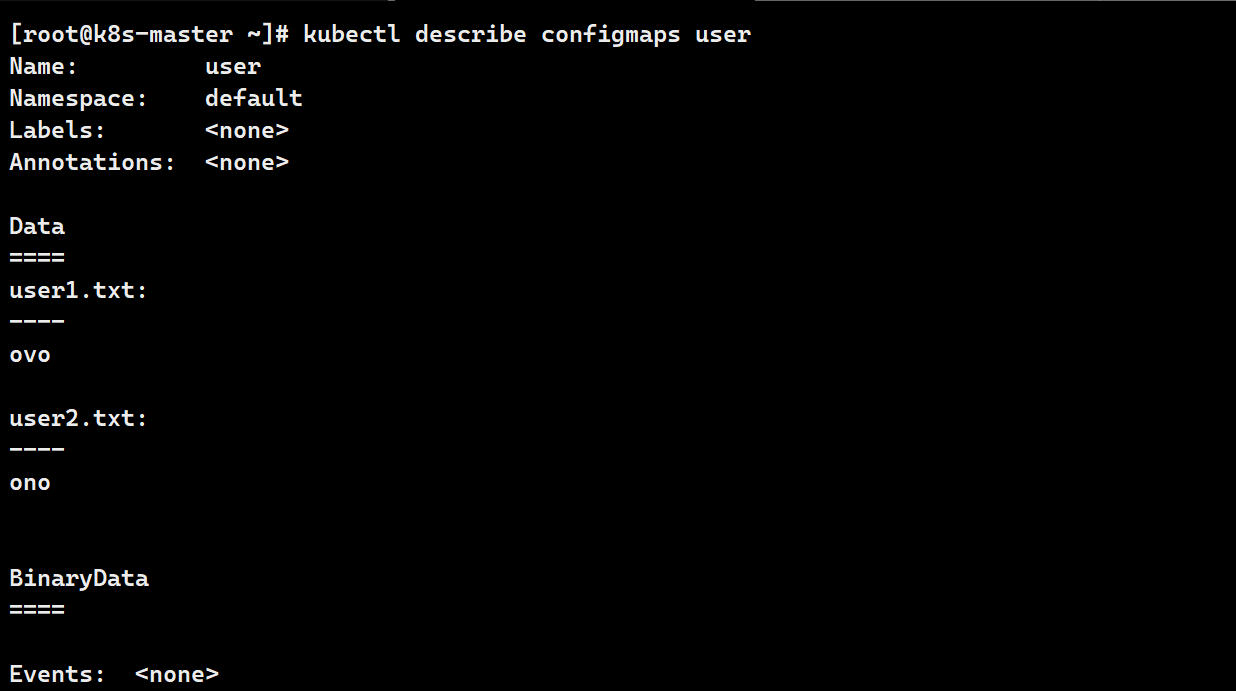
# 创建文件
echo ovo > user1.txt
echo ono > user2.txt
# 加载
kubectl create configmap user --from-file ./user1.txt --from-file ./user2.txt
kubectl describe configmaps user
# 删除
kubectl delete configmaps user
目录
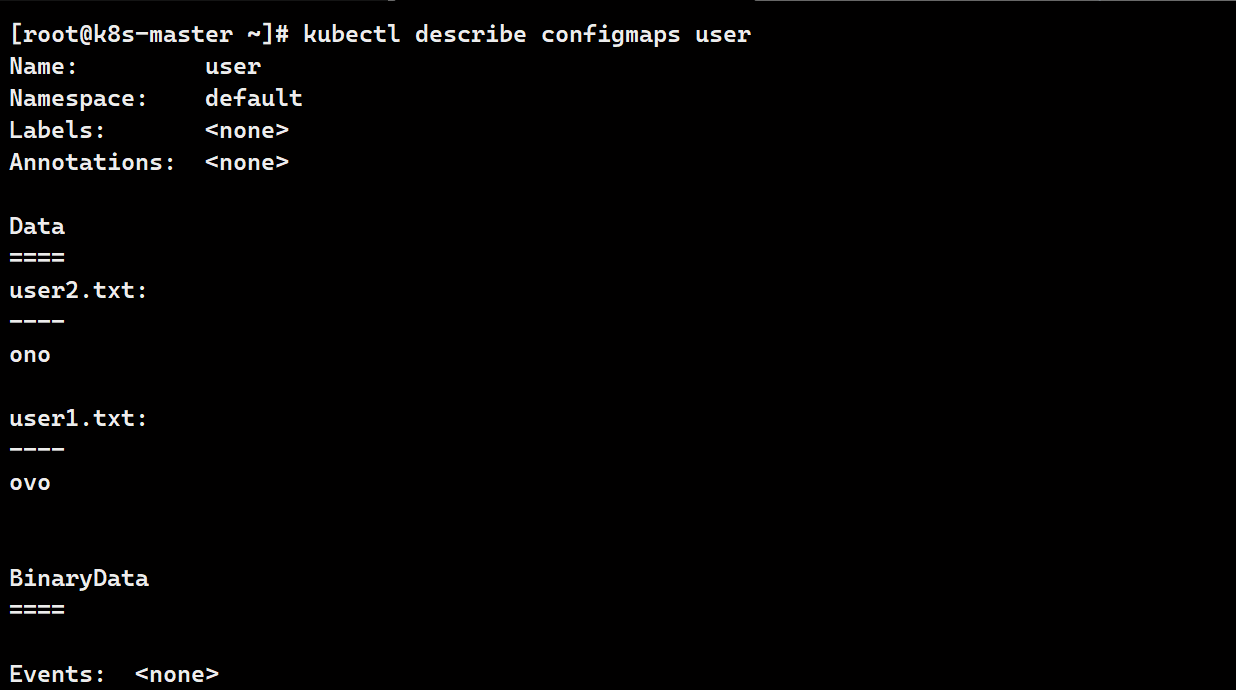
# 创建素材
mkdir user
mv user1.txt ./user/user1.txt
mv user2.txt ./user/user2.txt
# 加载
kubectl create configmap user --from-file user/
# 查看
kubectl describe configmaps user
# 删除
kubectl delete configmaps user
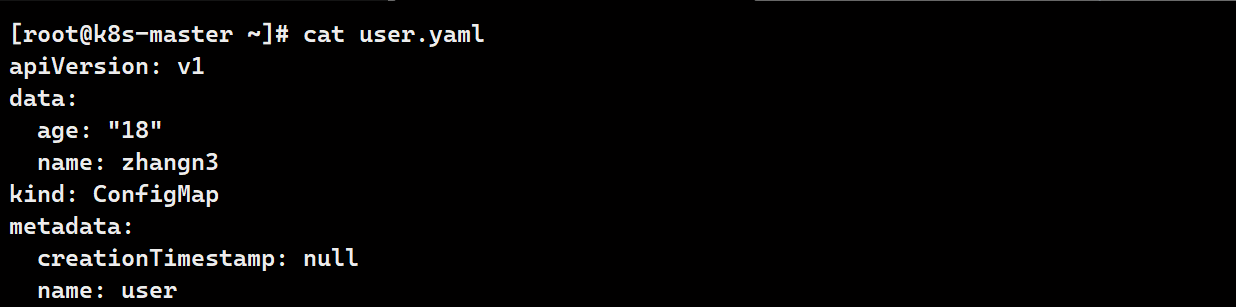
ymal文件
# 生成
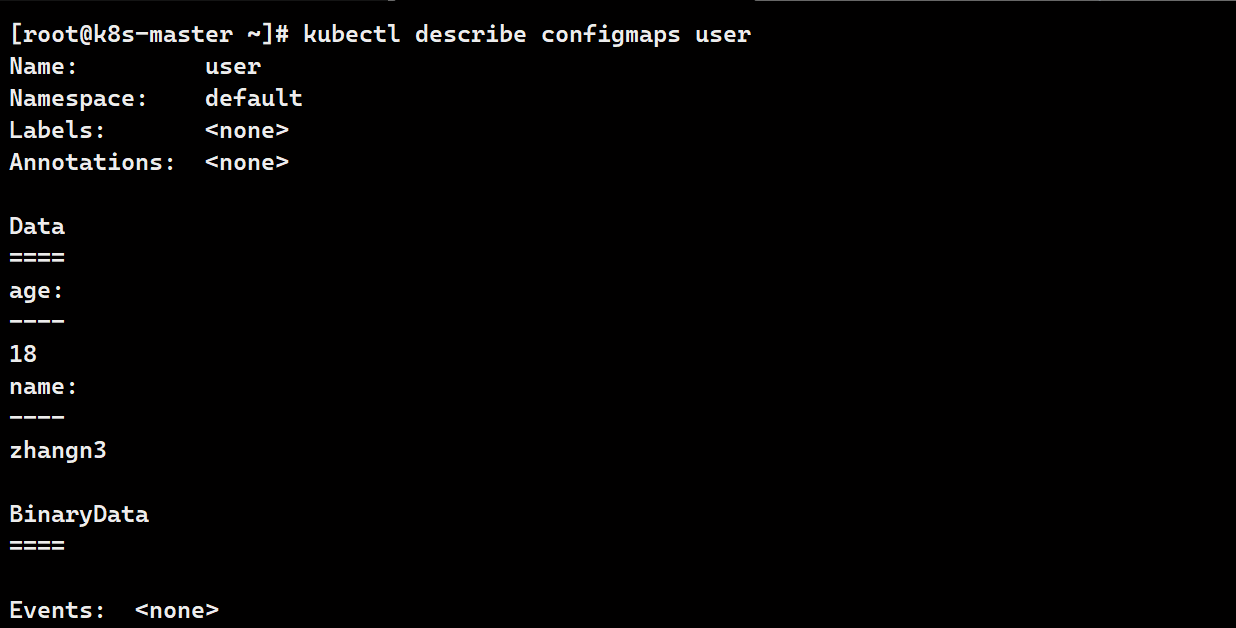
kubectl create configmap user --from-literal name=zhangn3 --from-literal age=18 --dry-run=client -o yaml > user.yaml
# 应用
kubectl apply -f user.yaml
# 查看
kubectl describe configmaps user
# 删除
kubectl delete configmaps user
使用方法
通过环境变量方式传递给Pod
kubectl create configmap ovo --dry-run=client -o yaml > ovo.yaml
vim ovo.yaml
apiVersion: v1
data:
kind: ConfigMap
metadata:
creationTimestamp: null
name: ovo
kubectl run haha --image busyboxplus --dry-run=client -o yaml > ono.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: map
name: map
spec:
containers:
- image: busyboxplus
name: map
command:
- /bin/sh
- -c
- env
env:
- name: key1
valueFrom:
configMapKeyRef:
name: user1
key: zhang3
- name: key2
valueFrom:
configMapKeyRef:
name: age
key: 18
restartPolicy: Never
kubectl apply -f ovo.yaml
# 不运行configmap,则报错 Error: configmap "ono" not found
kubectl apply -f ono.yaml
kubectl logs pods/map
kubectl delete pods map
kubectl delete configmaps ovo
通过Pod的命令运行
# 创建configmap,传递root的密码
kubectl create configmap phpmyadmin --dry-run=client -o yaml > phpmyadmin.yaml
vim phpmyadmin.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: phpmyadmin
data:
MYSQL_ROOT_PASSWORD: aaa
PMA_ARBITRARY: "1"

# 创建MySQL
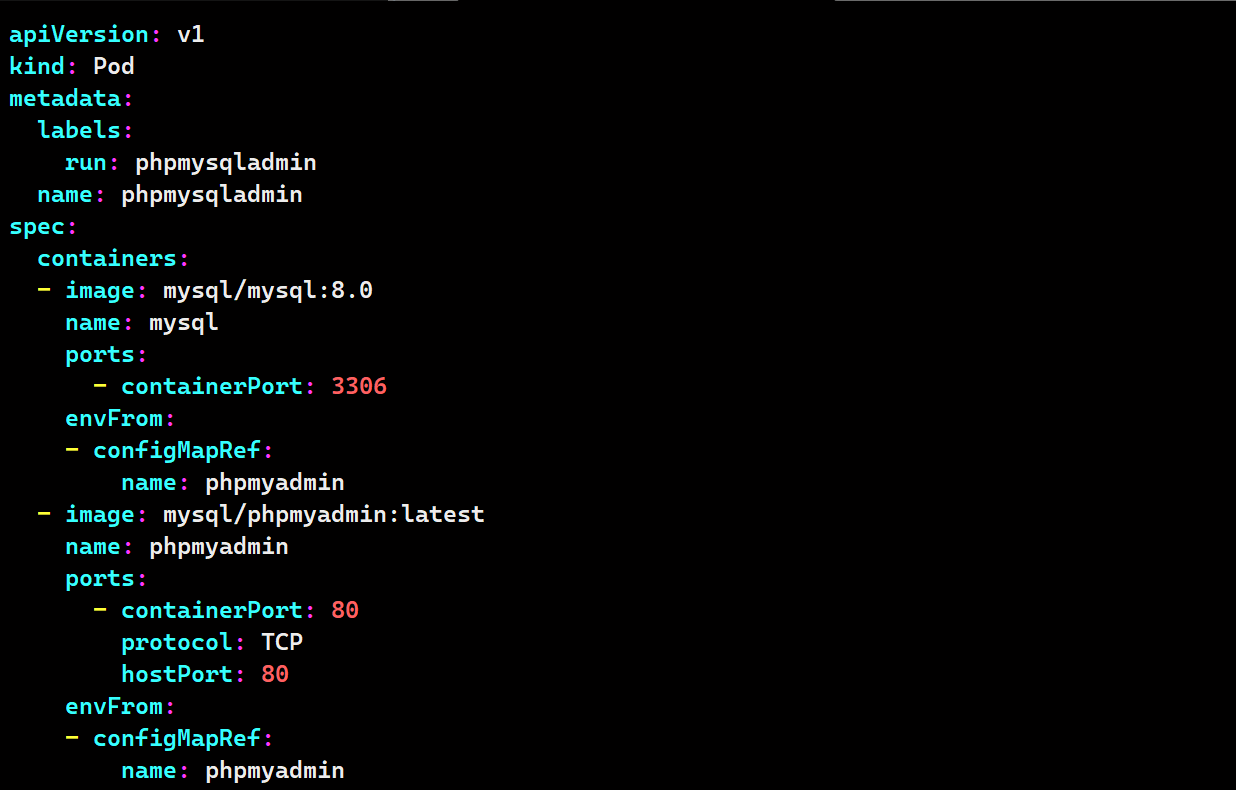
vim phpmysqladmin.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: phpmysqladmin
name: phpmysqladmin
spec:
containers:
- image: mysql/mysql:8.0
name: mysql
ports:
- containerPort: 3306
envFrom:
- configMapRef:
name: phpmyadmin
- image: mysql/phpmyadmin:latest
name: phpmyadmin
ports:
- containerPort: 80
protocol: TCP
hostPort: 80
envFrom:
- configMapRef:
name: phpmyadmin
优化:通过微服务暴露端口
kubectl expose pod phpmysqladmin --port 80 --target-port 80 --dry-run=client -o yaml >> phpmysqladmin.yaml
vim phpmysqladmin.yaml
apiVersion: v1
kind: Service
metadata:
labels:
run: phpmysqladmin
name: phpmysqladmin
spec:
ports:
- port: 80
name: phpadmin
protocol: TCP
targetPort: 80
- port: 3306
name: mysql
protocol: TCP
targetPort: 3306
selector:
run: phpmysqladmin
type: LoadBalancer
# 需要配置metalLB
# 查看服务IP
kubectl get services phpmysqladmin
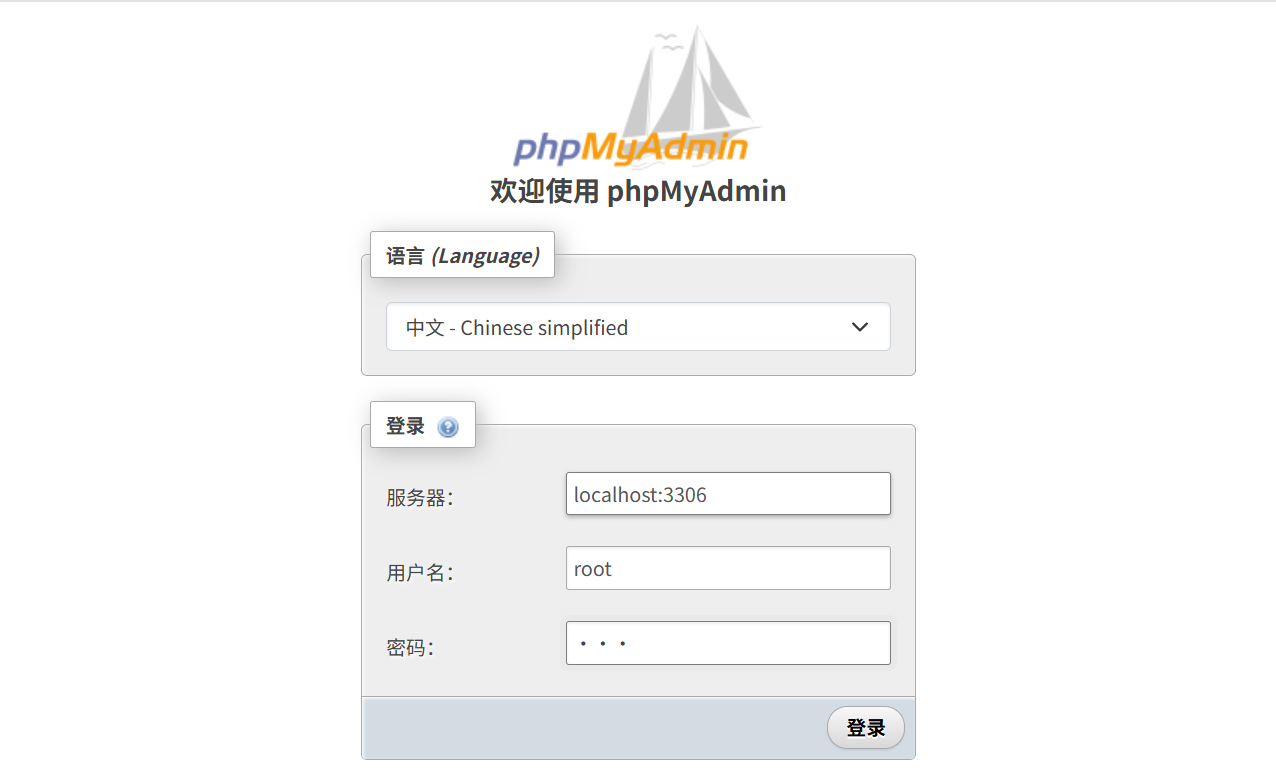
# 浏览器访问172.25.254.51,服务器localhost:3306,用户root

作为Volume方式挂载到Pod内
[root@k8s-master ~]# vim ono.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: ono
name: ono
spec:
containers:
- image: busyboxplus
name: ono
command:
- /bin/sh
- -c
- sleep 1000000
- cat /config/age
- cat /config/name
volumeMounts:
# 被调用的卷
- name: haha
# 被调用卷名
mountPath: /config
volumes:
# 声明卷的配置
- name: haha
configMap:
# 卷的类型
name: user
# 卷的名称
restartPolicy: Never
#查看日志
[root@k8s-master ~]# kubectl logs testpod
172.25.254.100
通过热更新cm修改配置
[root@k8s-master ~]# kubectl edit cm nginx-conf
apiVersion: v1
data:
nginx.conf: |
server {
listen 8080; #端口改为8080
server_name _;
root /usr/share/nginx/html;
index index.html;
}
kind: ConfigMap
metadata:
creationTimestamp: "2024-09-07T02:49:20Z"
name: nginx-conf
namespace: default
resourceVersion: "153055"
uid: 20bee584-2dab-4bd5-9bcb-78318404fa7a
#查看配置文件
[root@k8s-master ~]# kubectl exec pods/nginx-8487c65cfc-cz5hd -- cat /etc/nginx/conf.d/nginx.conf
server {
listen 8080;
server_name _;
root /usr/share/nginx/html;
index index.html;
}
配置文件修改后不会生效,需要删除pod后控制器会重建pod,此时才会生效
secrets
用来保存敏感信息,例如密码、OAuth 令牌和 ssh key
敏感信息放在 secret 中比放在 Pod 的定义或者容器镜像中来说更加安全和灵活
- Pod 可以用两种方式使用 secret:
- 作为 volume 中的文件被挂载到 pod 中的一个或者多个容器里。
- 当 kubelet 为 pod 拉取镜像时使用。
- Secret的类型:
- Service Account:Kubernetes 自动创建包含访问 API 凭据的 secret,并自动修改 pod 以使用此类型的 secret。
- Opaque:使用base64编码存储信息,可以通过base64 --decode解码获得原始数据,因此安全性弱。
- kubernetes.io/dockerconfigjson:用于存储docker registry的认证信息
创建方式
文件创建
[root@k8s-master secrets]# echo -n "timinglee" > username.txt
[root@k8s-master secrets]# echo -n "lee" > password.txt
# 加密
root@k8s-master secrets]# kubectl create secret generic userlist --from-file username.txt --from-file password.txt
# generic
# tls
# dockers-registry
secret/userlist created
[root@k8s-master secrets]# kubectl get secrets userlist -o yaml
password.txt: bGVl
username.txt: dGltaW5nbGVl
echo -n timinglee | base64
echo -n "dGltaW5nbGVl" | base64 -d
yaml文件创建
[root@k8s-master secrets]# kubectl create secret generic userlist --dry-run=client -o yaml > userlist.yml
[root@k8s-master secrets]# vim userlist.yml
apiVersion: v1
kind: Secret
metadata:
creationTimestamp: null
name: userlist
type: Opaque
data:
username: dGltaW5nbGVl
password: bGVl
[root@k8s-master secrets]# kubectl apply -f userlist.yml
secret/userlist created
[root@k8s-master secrets]# kubectl describe secrets userlist
Name: userlist
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 3 bytes
username: 9 byte
使用方法
将Secret挂载到Volume中
# 先创造一个secret
kubectl create secret generic mysecret --dry-run=client -o yaml > mysecret.yaml
# generic:创建通用类型的 Secret
# 补充内容
vim mysecret.yaml
apiVersion: v1
kind: Secret
metadata:
creationTimestamp: null
name: userlist
type: Opaque
data:
username: d2FuZzU=
password: emhhbzY=
---
# 创建一个pod并将secrets挂载到Pod内
kubectl run mypod --image nginx --dry-run=client -o yaml > mypod.yaml
# 补充内容
vim pod1.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: nginx
name: nginx
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
# 要挂载的卷的名称
- name: userlist
# 指定卷在容器内部的挂载路径
mountPath: /secret
# 设置挂载的目录为「只读」模式
readOnly: true
# 定义一个名为userlist的卷
# 卷的数据来源于名为userlist的Secret资源
volumes:
- name: userlist
secret:
secretName: userlist
# 应用
kubectl apply -f mysecret.yaml
kubectl apply -f mypod.yaml

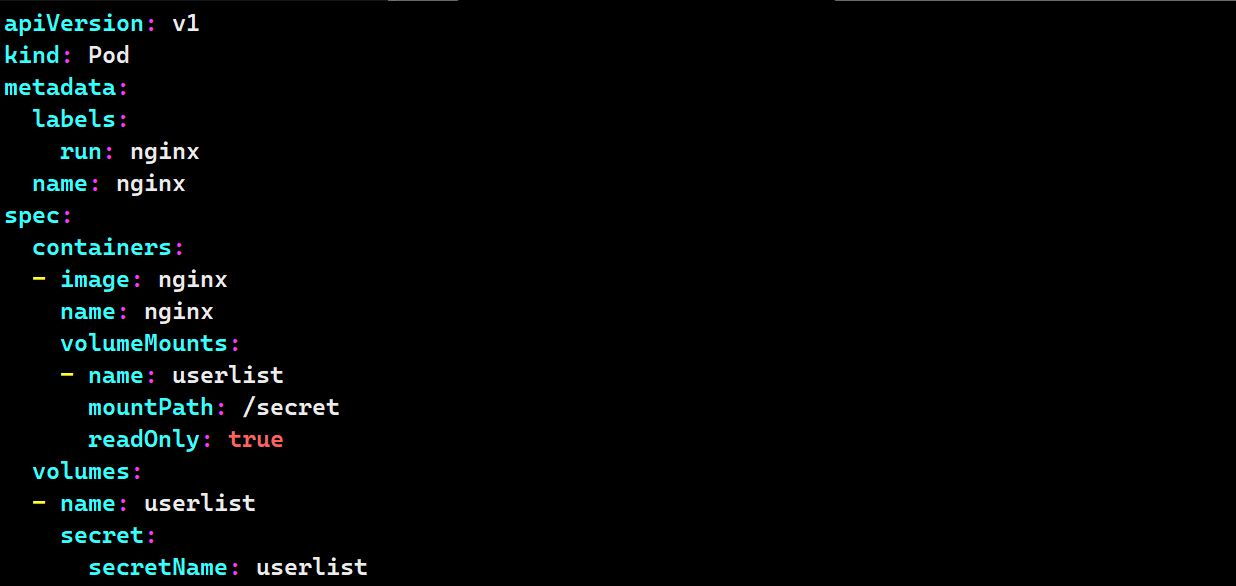
# 测试
kubectl exec pods/mypod -it -- /bin/bash
cd /secret/ && ls
cat username
cat password

向指定路径映射secret密钥
#向指定路径映射
[root@k8s-master secrets]# vim pod2.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: nginx1
name: nginx1
spec:
containers:
- image: nginx
name: nginx1
volumeMounts:
- name: secrets
mountPath: /secret
# 默认在同一个路径下
readOnly: true
volumes:
- name: secrets
secret:
secretName: userlist
# 将userlist放置到其他路径下
items:
- key: username
path: my-users/username
- key: password
path: my-users/password
[root@k8s-master secrets]# kubectl apply -f pod2.yaml
pod/nginx1 created
[root@k8s-master secrets]# kubectl exec pods/nginx1 -it -- /bin/bash
root@nginx1:/# cd secret/
root@nginx1:/secret# ls
my-users
root@nginx1:/secret# cd my-users
root@nginx1:/secret/my-users# ls
username
root@nginx1:/secret/my-users# cat username
将Secret设置为环境变量
[root@k8s-master secrets]# vim pod3.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: busybox
name: busybox
spec:
containers:
- image: busybox
name: busybox
command:
- /bin/sh
- -c
- env
env:
- name: USERNAME
valueFrom:
secretKeyRef:
name: userlist
key: username
- name: PASS
valueFrom:
secretKeyRef:
name: userlist
key: password
restartPolicy: Never
[root@k8s-master secrets]# kubectl apply -f pod3.yaml
[root@k8s-master secrets]# kubectl logs pods/busybox
...
USERNAME=timinglee
...
PASS=lee
...
存储docker registry的认证信息
建立私有仓库并上传镜像
当拉取仓库中私有目录内的镜像时,需要登录后,才能进行下载
拉取时,应使用全路径,比如"reg.timinglee.org/lee/nginx"
# 未登录时,Pod无法拉取私有仓库中的镜像
#登陆仓库
[root@k8s-master secrets]# docker login reg.timinglee.org
#上传镜像
[root@k8s-master secrets]# docker tag timinglee/game2048:latest reg.timinglee.org/timinglee/game2048:latest
[root@k8s-master secrets]# docker push reg.timinglee.org/timinglee/game2048:latest
#建立用于docker认证的secret
[root@k8s-master secrets]# kubectl create secret docker-registry docker-auth --docker-server ooovooo.org --docker-username admin --docker-password aaa --docker-email ooovooo.org@admin
secret/docker-auth created
# docker-auth:名称
# --docker-server:需要认证的仓库
# --docker-username:用户名
# --docker-password:用户密码
# --docker-email:邮件
# 配置
[root@k8s-master secrets]# vim pod3.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: game2048
name: game2048
spec:
containers:
- image: ooovooo.org/library/game2048:latest
name: game2048
imagePullSecrets:
# 加载认证文件
- name: docker-auth
[root@k8s-master secrets]# kubectl get pods
NAME READY STATUS RESTARTS AGE
game2048 1/1 Running 0 4s
volumes
官网:https://kubernetes.io/zh/docs/concepts/storage/volumes/
解决容器生命周期与数据生命周期不一致的问题
仅属于某个具体的 Pod,与 Pod 生命周期绑定(Pod 删除,卷也会被清理,除非使用持久化存储)
当在一个Pod中同时运行多个容器时,常常需要在这些容器之间共享文件
卷不能挂载到其他卷,也不能与其他卷有硬链接
Pod中的每个容器必须独立地指定每个卷的挂载位置
卷比Pod中运行的任何容器的存活期都长,在容器重新启动时数据也会得到保留
当一个Pod不再存在时,卷也将不再存在
卷是 Pod 内的「存储接口」,而 PersistentVolume 是集群级的「持久化存储资源」
卷的类型
k8s支持的卷的类型如下:
-
awsElasticBlockStore 、azureDisk、azureFile、cephfs、cinder、configMap、csi
-
downwardAPI、emptyDir、fc (fibre channel)、flexVolume、flocker
-
gcePersistentDisk、gitRepo (deprecated)、glusterfs、hostPath、iscsi、local、
-
nfs、persistentVolumeClaim、projected、portworxVolume、quobyte、rbd
-
scaleIO、secret、storageos、vsphereVolume
emptyDir卷
当Pod指定到某个节点上时,首先创建的是一个emptyDir卷,并且只要 Pod 在该节点上运行,卷就一直存在。卷最初是空的。 尽管 Pod 中的容器挂载 emptyDir 卷的路径可能相同也可能不同,但是这些容器都可以读写 emptyDir 卷中相同的文件。 当 Pod 因为某些原因被从节点上删除时,emptyDir 卷中的数据也会永久删除
# 创建yaml
kubectl run empty --image nginx --dry-run=client -o yaml > empty.yaml
# kubectl run empty --image nginx --image busybox --dry-run=client -o yaml > empty.yaml
# 修改yaml
vim empty.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: empty
name: empty
spec:
containers:
- image: busyboxplus
name: busybox
command:
- /bin/sh
- -c
- sleep 1000000
volumeMounts:
- name: empty
mountPath: /data
- image: nginx
name: nginx
volumeMounts:
- name: empty
mountPath: /usr/share/nginx/html
volumes:
- name: empty
emptyDir:
medium: Memory
sizeLimit: 100Mi
# 应用yaml
kubectl apply -f empty.yaml
# 查看挂载情况
kubectl describe pods empty
Image: busyboxplus
Mounts: /data from empty (rw)
---
Image: nginx
Mounts: /usr/share/nginx/html from empty (rw)
#
kubectl delete -f empty --force
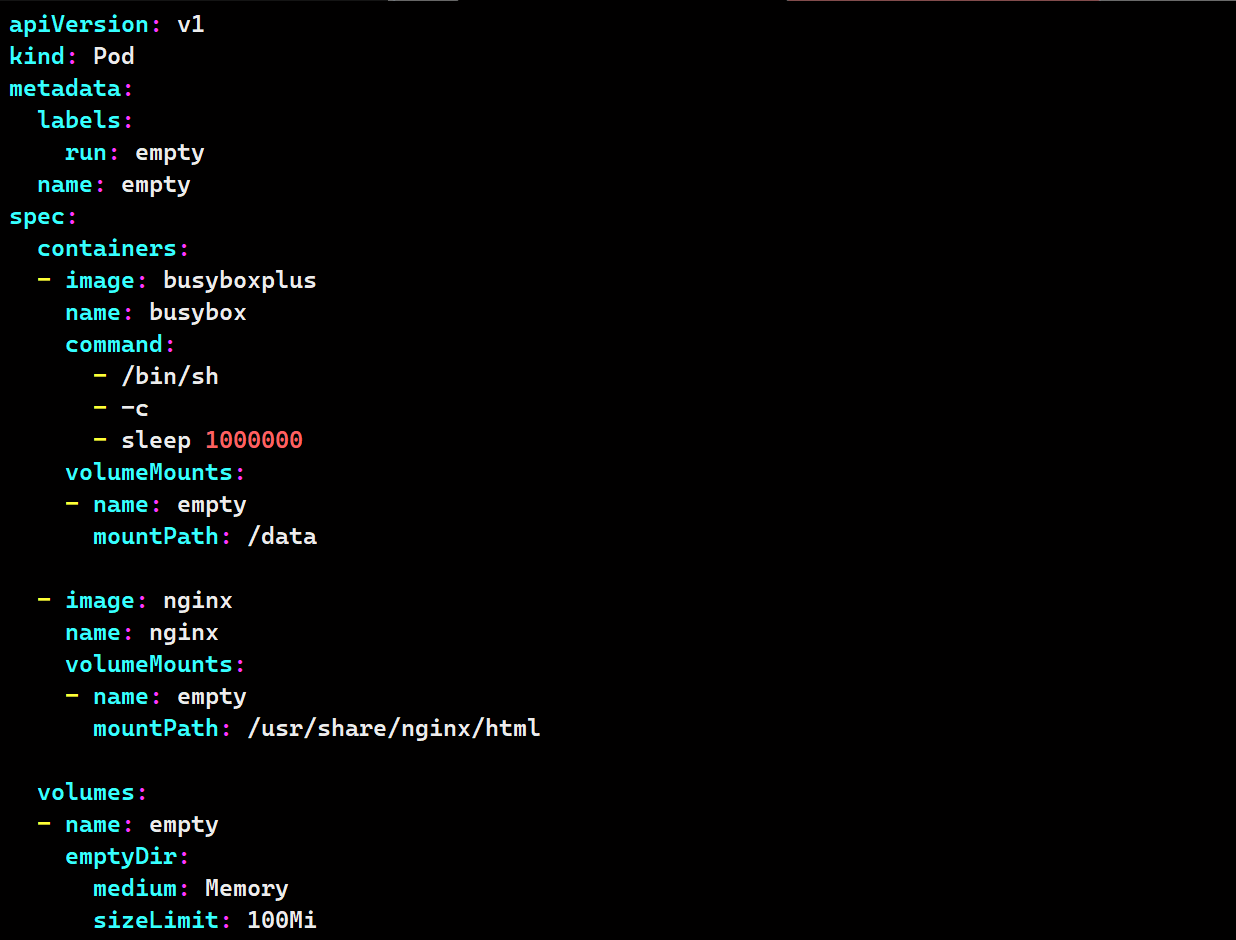
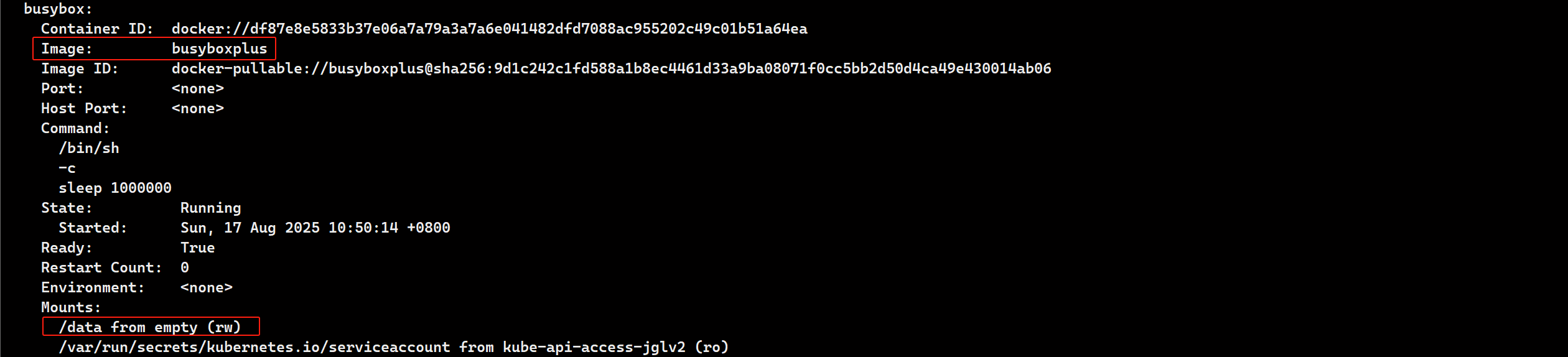

# 测试
# 进入nginx
kubectl exec -it pods/empty -c nginx -- /bin/bash
cd /usr/share/nginx/html && ls
echo "hello busybox" > index.html
# 成功访问
curl localhost
---
# 多开终端,进入busybox中
kubectl exec -it pods/empty -c busybox -- /bin/bash
# 同步文件,成功访问
ls /data/ && curl localhost
# 创建文件,被限制大小(在busybox中好像没被限制???)
dd if=/dev/zero of=bigfile bs=1M count=200
du -sh bigfile
# 仅在挂载目录中同步,其他目录不进行同步
cd / && echo 1 > ono.txt && ls
---
# 在nginx中查看
ls /

hostpath卷
hostPath 卷能将主机节点文件系统上的文件或目录挂载到您的 Pod 中,不会因为pod关闭而被删除
hostPath的安全隐患
- 具有相同配置(例如从 podTemplate 创建)的多个 Pod 会由于节点上文件的不同而在不同节点上有不同的行为
- 当 Kubernetes 按照计划添加资源感知的调度时,这类调度机制将无法考虑由 hostPath 使用的资源
- 基础主机上创建的文件或目录只能由 root 用户写入。您需要在 特权容器 中以 root 身份运行进程,或者修改主机上的文件权限以便容器能够写入 hostPath 卷
[root@k8s-master volumes]# vim 002.yml
apiVersion: v1
kind: Pod
metadata:
name: vol2
spec:
containers:
- image: nginx
name: vm2
volumeMounts:
- mountPath: /usr/share/nginx/html
name: cache-vo2
volumes:
- name: cache-vo2
hostPath:
path: /data # 把/data 挂载到 /usr/share/nginx/html 中
type: DirectoryOrCreate #当/data目录不存在时自动建立
#测试:
[root@k8s-master volumes]# kubectl apply -f 002.yml
pod/vol2 created
[root@k8s-master volumes]# kubectl get pods vol2 -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vol1 1/1 Running 0 10s 10.244.2.48 k8s-node2 <none> <none>
[root@k8s-master volumes]# curl 10.244.2.48
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.27.1</center>
</body>
</html>
# 在镜像内/usr/share/nginx/html 创建文件 也会同步到 /data目录中
# 在vol1 的工作节点上 自动创建/data目录
[root@k8s-node2 ~]# echo timinglee > /data/index.html
[root@k8s-master volumes]# curl 10.244.2.48
timinglee
#当pod被删除后hostPath不会被清理
[root@k8s-master volumes]# kubectl delete -f pod2.yml
pod "vol1" deleted
[root@k8s-node2 ~]# ls /data/
index.html
nfs卷
NFS 卷允许将一个现有的 NFS 服务器上的目录挂载到 Kubernetes 中的 Pod 中。这对于在多个 Pod 之间共享数据或持久化存储数据非常有用
# 在所有主机上安装nfs-utils(包括harbor)
dnf install nfs-utils -y
# 将harbor仓库作为nfs服务器
mkdir /nfsdata
systemctl enable --now nfs-server
# 配置共享目录
vim /etc/exports
/nfsdata *(rw,sync,no_root_squash)
# 刷新并显示共享目录
exportfs -rv
# 在其他主机上挂载
showmount -e 172.25.254.200
kubectl run nfs --image nginx --dry-run=client -o yaml > nfs.yaml
vim nfs.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: nfs
name: nfs
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- mountPath: /usr/share/nginx/html
name: nfs
volumes:
- name: nfs
nfs:
server: 172.25.254.200
path: /nfsdata
kubectl apply -f nfs.yaml
kubectl get pods -o wide
curl 10.244.8.14
403 Forbidden
# 在NFS主上
echo hello nginx > /nfsdata/index.html
curl 10.244.8.14
PersistentVolume持久卷
PersistentVolume(持久卷,简称PV)
-
pv是集群内由管理员提供的网络存储的一部分。
-
PV也是集群中的一种资源。是一种volume插件,
-
但是它的生命周期却是和使用它的Pod相互独立的。
-
PV这个API对象,捕获了诸如NFS、ISCSI、或其他云存储系统的实现细节
-
pv有两种提供方式:静态和动态
-
静态PV:集群管理员创建多个PV,它们携带着真实存储的详细信息,它们存在于Kubernetes API中,并可用于存储使用
-
动态PV:当管理员创建的静态PV都不匹配用户的PVC时,集群可能会尝试专门地供给volume给PVC。这种供给基于StorageClass
-
PersistentVolumeClaim(持久卷声明,简称PVC)
-
是用户的一种存储请求
-
它和Pod类似,Pod消耗Node资源,而PVC消耗PV资源
-
Pod能够请求特定的资源(如CPU和内存)。PVC能够请求指定的大小和访问的模式持久卷配置
-
PVC与PV的绑定是一对一的映射。没找到匹配的PV,那么PVC会无限期得处于unbound未绑定状态
volumes访问模式
-
ReadWriteOnce – 该volume只能被单个节点以读写的方式映射
-
ReadOnlyMany – 该volume可以被多个节点以只读方式映射
-
ReadWriteMany – 该volume可以被多个节点以读写的方式映射
-
在命令行中,访问模式可以简写为:
-
RWO - ReadWriteOnce
-
ROX - ReadOnlyMany
-
RWX – ReadWriteMany
-
volumes回收策略
-
Retain:保留,需要手动回收
-
Recycle:回收,自动删除卷中数据(在当前版本中已经废弃)
-
Delete:删除,相关联的存储资产,如AWS EBS,GCE PD,Azure Disk,or OpenStack Cinder卷都会被删除
注意:
[!NOTE]
只有NFS和HostPath支持回收利用
AWS EBS,GCE PD,Azure Disk,or OpenStack Cinder卷支持删除操作。
volumes状态说明
-
Available 卷是一个空闲资源,尚未绑定到任何申领
-
Bound 该卷已经绑定到某申领
-
Released 所绑定的申领已被删除,但是关联存储资源尚未被集群回收
-
Failed 卷的自动回收操作失败
静态PV
#在nfs主机中建立实验目录
[root@reg ~]# mkdir /nfsdata/pv{1..3}
#编写创建pv的yml文件,pv是集群资源,不在任何namespace中
[root@k8s-master pvc]# vim pv.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: /nfsdata/pv1
server: 172.25.254.100
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv2
spec:
capacity:
storage: 15Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: /nfsdata/pv2
server: 172.25.254.100
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv3
spec:
capacity:
storage: 25Gi
volumeMode: Filesystem
accessModes:
- ReadOnlyMany
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: /nfsdata/pv3
server: 172.25.254.100
[root@k8s-master pvc]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
pv1 5Gi RWO Retain Available nfs <unset> 4m50s
pv2 15Gi RWX Retain Available nfs <unset> 4m50s
pv3 25Gi ROX Retain Available nfs <unset> 4m50s
#建立pvc,pvc是pv使用的申请,需要保证和pod在一个namesapce中
[root@k8s-master pvc]# vim pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc1
spec:
storageClassName: nfs
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc2
spec:
storageClassName: nfs
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc3
spec:
storageClassName: nfs
accessModes:
- ReadOnlyMany
resources:
requests:
storage: 15Gi
[root@k8s-master pvc]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
pvc1 Bound pv1 5Gi RWO nfs <unset> 5s
pvc2 Bound pv2 15Gi RWX nfs <unset> 4s
pvc3 Bound pv3 25Gi ROX nfs <unset> 4s
#在其他namespace中无法应用
[root@k8s-master pvc]# kubectl -n kube-system get pvc
No resources found in kube-system namespace.
在pod中使用pvc
[root@k8s-master pvc]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:
name: zhang3
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- mountPath: /usr/share/nginx/html
name: vol1
volumes:
- name: vol1
persistentVolumeClaim:
claimName: pvc1
[root@k8s-master pvc]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
timinglee 1/1 Running 0 83s 10.244.2.54 k8s-node2 <none> <none>
[root@k8s-master pvc]# kubectl exec -it pods/timinglee -- /bin/bash
root@timinglee:/# curl localhost
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.27.1</center>
</body>
</html>
root@timinglee:/# cd /usr/share/nginx/
root@timinglee:/usr/share/nginx# ls
html
root@timinglee:/usr/share/nginx# cd html/
root@timinglee:/usr/share/nginx/html# ls
[root@reg ~]# echo timinglee > /data/pv1/index.html
[root@k8s-master pvc]# kubectl exec -it pods/timinglee -- /bin/bash
root@timinglee:/# cd /usr/share/nginx/html/
root@timinglee:/usr/share/nginx/html# ls
index.html
存储类storageclass
官网: https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner
-
StorageClass提供了一种描述存储类(class)的方法,不同的class可能会映射到不同的服务质量等级和备份策略或其他策略等。
-
每个 StorageClass 都包含 provisioner、parameters 和 reclaimPolicy 字段, 这些字段会在StorageClass需要动态分配 PersistentVolume 时会使用到
StorageClass的属性
属性说明:https://kubernetes.io/zh/docs/concepts/storage/storage-classes/
Provisioner(存储分配器):用来决定使用哪个卷插件分配 PV,该字段必须指定。可以指定内部分配器,也可以指定外部分配器。外部分配器的代码地址为: kubernetes-incubator/external-storage,其中包括NFS和Ceph等。
Reclaim Policy(回收策略):通过reclaimPolicy字段指定创建的Persistent Volume的回收策略,回收策略包括:Delete 或者 Retain,没有指定默认为Delete。
存储分配器NFS Client Provisioner
源码地址:https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner
-
NFS Client Provisioner是一个automatic provisioner,使用NFS作为存储,自动创建PV和对应的PVC,本身不提供NFS存储,需要外部先有一套NFS存储服务。
-
PV以 n a m e s p a c e − {namespace}- namespace−{pvcName}-${pvName}的命名格式提供(在NFS服务器上)
-
PV回收的时候以 archieved- n a m e s p a c e − {namespace}- namespace−{pvcName}-${pvName} 的命名格式(在NFS服务器上)
部署NFS Client Provisioner
创建SA并授权
vim rbac.yaml
apiVersion: v1
kind: Namespace
metadata:
name: nfs-client-provisioner
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
namespace: nfs-client-provisioner
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: nfs-client-provisioner
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: nfs-client-provisioner
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: nfs-client-provisioner
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
# 应用yaml
kubectl apply -f rbac.yaml
# 查看
kubectl -n nfs-client-provisioner get sa
上传镜像
# 加载
docker load -i nfs-subdir-external-provisioner-4.0.2.tar
# 打标签
docker tag sig-storage/nfs-subdir-external-provisioner:v4.0.2 ooovooo.org/sig-storage/nfs-subdir-external-provisioner:v4.0.2
# 上传镜像
docker push ooovooo.org/sig-storage/nfs-subdir-external-provisioner:v4.0.2
创建NFS动态存储卷供应器
vim deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
namespace: nfs-client-provisioner
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: sig-storage/nfs-subdir-external-provisioner:v4.0.2
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner
- name: NFS_SERVER
value: 172.25.254.200
- name: NFS_PATH
value: /nfsdata
volumes:
- name: nfs-client-root
nfs:
server: 172.25.254.200
path: /nfsdata
# 应用ymal
kubectl apply -f storageclass.yaml
# 查看
kubectl -n nfs-client-provisioner get deployments.apps nfs-client-provisioner
创建存储类
vim storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-client
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:
archiveOnDelete: "false"
# 应用yaml
kubectl apply -f class.yaml
# 查看
kubectl get storageclasses.storage.k8s.io
创建 PVC
vim storagepvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1G
# 应用yaml
kubectl apply -f storagepvc.yaml
# 查看
kubectl get pvc
自动创建 PV
# 测试
vim testpod.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: test-pod
image: busybox
command:
- "/bin/sh"
args:
- "-c"
- "touch /mnt/SUCCESS && exit 0 || exit 1"
volumeMounts:
- name: nfs-pvc
mountPath: "/mnt"
restartPolicy: "Never"
volumes:
- name: nfs-pvc
persistentVolumeClaim:
claimName: test-claim
# 应用yaml
kubectl apply -f teestpod.yaml
# 验证(NFS)
cd /nfsdata/ && ls
ls default-......
自动删除PV
# 查看pv
kubectl get pv
# 解除占用
kubectl delete -f teestpod.yaml
# 删除pvc
kubectl delete pvc test-claim
# 再次查看
kubectl get pv
statefulset控制器
-
Statefulset是为了管理有状态服务的问提设计的
-
StatefulSet将应用状态抽象成了两种情况:
-
拓扑状态:应用实例必须按照某种顺序启动。新创建的Pod必须和原来Pod的网络标识一样
-
存储状态:应用的多个实例分别绑定了不同存储数据。
-
-
StatefulSet给所有的Pod进行了编号,编号规则是: ( s t a t e f u l s e t 名称 ) − (statefulset名称)- (statefulset名称)−(序号),从0开始。
-
Pod被删除后重建,重建Pod的网络标识也不会改变,Pod的拓扑状态按照Pod的“名字+编号”的方式固定下来,并且为每个Pod提供了一个固定且唯一的访问入口,Pod对应的DNS记录
StatefulSet的组成部分
-
Headless Service:用来定义pod网络标识,生成可解析的DNS记录
-
volumeClaimTemplates:创建pvc,指定pvc名称大小,自动创建pvc且pvc由存储类供应。
-
StatefulSet:管理pod的
#建立无头服务
[root@k8s-master statefulset]# vim headless.yml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
[root@k8s-master statefulset]# kubectl apply -f headless.yml
#建立statefulset
[root@k8s-master statefulset]# vim statefulset.yml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx-svc"
replicas: 3
# 副本数量
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
[root@k8s-master statefulset]# kubectl apply -f statefulset.yml
statefulset.apps/web configured
root@k8s-master statefulset]# kubectl get pods
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 3m26s
web-1 1/1 Running 0 3m22s
web-2 1/1 Running 0 3m18s
[root@reg nfsdata]# ls /nfsdata/
default-test-claim-pvc-34b3d968-6c2b-42f9-bbc3-d7a7a02dcbac
default-www-web-0-pvc-0390b736-477b-4263-9373-a53d20cc8f9f
default-www-web-1-pvc-a5ff1a7b-fea5-4e77-afd4-cdccedbc278c
default-www-web-2-pvc-83eff88b-4ae1-4a8a-b042-8899677ae854
测试
#为每个pod建立index.html文件
[root@reg nfsdata]# echo web-0 > default-www-web-0-pvc-0390b736-477b-4263-9373-a53d20cc8f9f/index.html
[root@reg nfsdata]# echo web-1 > default-www-web-1-pvc-a5ff1a7b-fea5-4e77-afd4-cdccedbc278c/index.html
[root@reg nfsdata]# echo web-2 > default-www-web-2-pvc-83eff88b-4ae1-4a8a-b042-8899677ae854/index.html
#建立测试pod访问web-0~2
[root@k8s-master statefulset]# kubectl run -it testpod --image busyboxplus
/ # curl web-0.nginx-svc
web-0
/ # curl web-1.nginx-svc
web-1
/ # curl web-2.nginx-svc
web-2
#删掉重新建立statefulset
[root@k8s-master statefulset]# kubectl delete -f statefulset.yml
statefulset.apps "web" deleted
[root@k8s-master statefulset]# kubectl apply -f statefulset.yml
statefulset.apps/web created
#访问依然不变
[root@k8s-master statefulset]# kubectl attach testpod -c testpod -i -t
If you don't see a command prompt, try pressing enter.
/ # cu
curl cut
/ # curl web-0.nginx-svc
web-0
/ # curl web-1.nginx-svc
web-1
/ # curl web-2.nginx-svc
web-2
statefulset的弹缩
首先,想要弹缩的StatefulSet. 需先清楚是否能弹缩该应用
# 用命令改变副本数
kubectl scale statefulsets <stateful-set-name> --replicas=<new-replicas>
# 通过编辑配置改变副本数
kubectl edit statefulsets.apps <stateful-set-name>
# statefulset有序回收
kubectl scale statefulset web --replicas 0
kubectl delete -f statefulset.yml
kubectl delete pvc --all
kubernetes认证授权
Kubernetes API 访问控制
uthentication(认证)
-
认证方式现共有8种,可以启用一种或多种认证方式,只要有一种认证方式通过,就不再进行其它方式的认证
- 通常启用 X509 Client Certs 和 Service Accout Tokens 两种认证方式
-
Kubernetes集群有两类用户:
- 由Kubernetes管理的Service Accounts (服务账户)
- (Users Accounts) 普通账户
- k8s中账号的概念不是我们理解的账号,它并不真的存在,它只是形式上存在
Authorization(授权)
- 必须经过认证阶段,才到授权请求,根据所有授权策略匹配请求资源属性,决定允许或拒绝请求
- 授权方式现共有6种,AlwaysDeny、AlwaysAllow、ABAC、RBAC、Webhook、Node
- 默认集群强制开启 RBAC
Admission Control(准入控制)
- 用于拦截请求的一种方式,运行在认证、授权之后,是权限认证链上的最后一环,对请求API资源对象进行修改和校验
整体结构

运用
ServiceAccount 运用
建立名字为 moon 的 ServiceAccount
[root@k8s-master ~]# kubectl create sa moon
[root@k8s-master ~]# kubectl describe sa moon
Name: moon
Namespace: default
Labels: <none>
Annotations: <none>
Image pull secrets: <none>
# 无内容
Mountable secrets: <none>
Tokens: <none>
Events: <none>
建立 secrets
[root@k8s-master ~]# kubectl create secret docker-registry docker-login --docker-username admin --docker-password aaa --docker-server ooovooo.org --docker-email admin@ooovooo.org
secret/docker-login created
[root@k8s-master ~]# kubectl describe secrets docker-login
Name: docker-login
Namespace: default
Labels: <none>
Annotations: <none>
Type: kubernetes.io/dockerconfigjson
Data
====
.dockerconfigjson: 113 bytes
将 secrets 注入到 sa 中
[root@k8s-master ~]# kubectl edit sa moon
apiVersion: v1
imagePullSecrets:
- name: docker-login
kind: ServiceAccount
...
[root@k8s-master ~]# kubectl describe sa moon
Name: moon
Namespace: default
Labels: <none>
Annotations: <none>
Image pull secrets: docker-login
# 注入成功
Mountable secrets: <none>
Tokens: <none>
Events: <none>
创建 Harbor 私有仓库并使用 Pod 访问私有仓库
# Harbor 建立名为 sun 私有仓库
[root@ooovooo harbor]# docker tag ooovooo.org/library/nginx:latest ooovooo.org/sun/nginx:latest
[root@ooovooo harbor]# docker push ooovooo.org/sun/nginx:latest
# 拉取私有仓库镜像 使用绝对路径
[root@k8s-master ~]# kubectl run 001 --image ooovooo.org/sun/nginx --dry-run=client -o yaml > 001.yml
[root@k8s-master ~]# kubectl apply -f 001.yml
[root@k8s-master ~]# kubectl describe pods 001
...
Warning Failed 14s kubelet Error: ImagePullBackOff
Normal Pulling 0s (x2 over 15s) kubelet Pulling image "ooovooo.org/sun/nginx"
Warning Failed 0s (x2 over 15s) kubelet Failed to pull image "ooovooo.org/sun/nginx": Error response from daemon: unauthorized: unauthorized to access repository: sun/nginx, action: pull: unauthorized to access repository: sun/nginx, action: pull
Warning Failed 0s (x2 over 15s) kubelet Error: ErrImagePull
[root@k8s-master ~]# kubectl get pods 001
NAME READY STATUS RESTARTS AGE
001 0/1 ImagePullBackOff 0 60s
[!warning]
创建 Pod 时,镜像下载错误,其 Docker 私有仓库下载镜像需要认证
Pod 绑定 SA
[root@k8s-master ~]# vim 001.yml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: "001"
name: "001"
spec:
serviceAccountName: moon
# 绑定
containers:
- image: ooovooo.org/sun/nginx
name: "001"
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
[root@k8s-master ~]# kubectl delete -f 001.yml
[root@k8s-master ~]# kubectl apply -f 001.yml
[root@k8s-master ~]# kubectl get pods 001
NAME READY STATUS RESTARTS AGE
001 1/1 Running 0 60s
[!note]
还可以将 secrets 注入到 sa default 中,这样 Pod 不用绑定 sa moon
认证(在K8s中建立认证用户)
创建 UserAccount
# 建立证书
[root@k8s-master ~]# cd /etc/kubernetes/pki/
[root@k8s-master pki]# openssl genrsa -out moon.key 2048
[root@k8s-master pki]# openssl req -new -key moon.key -out moon.csr -subj "/CN=moon"
[root@k8s-master pki]# openssl x509 -req -in moon.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out moon.crt -days 365
Certificate request self-signature ok
subject=CN = moon
[root@k8s-master pki]# openssl x509 -in moon.crt -text -noout
...
# 建立k8s中的用户
[root@k8s-master pki]# kubectl config set-credentials moon --client-certificate /etc/kubernetes/pki/moon.crt --client-key /etc/kubernetes/pki/moon.key --embed-certs=true
User "moon" set.
[root@k8s-master pki]# kubectl config view
...
- name: moon
user:
client-certificate-data: DATA+OMITTED
client-key-data: DATA+OMITTED
# 为用户创建集群的安全上下文
[root@k8s-master pki]# kubectl config set-context moon@kubernetes --cluster kubernetes --user moon
Context "moon@kubernetes" created.
# 删除安全上下文
# kubectl config delete-context xxx
# 切换用户 用户在集群中只有用户身份而没有授权
[root@k8s-master pki]# kubectl config use-context moon@kubernetes
Switched to context "moon@kubernetes".
[root@k8s-master pki]# kubectl get pods
Error from server (Forbidden): pods is forbidden: User "moon" cannot list resource "pods" in API group "" in the namespace "default"
# 切换回集群管理
[root@k8s-master pki]# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".
# 删除用户
# kubectl config delete-user moon
RBAC(Role Based Access Control)
基于角色访问控制授权:

-
允许管理员通过Kubernetes API动态配置授权策略
- RBAC就是用户通过角色与权限进行关联
-
RBAC只有授权,没有拒绝授权,所以只需要定义允许该用户做什么即可
-
RBAC的三个基本概念
- Subject:被作用者,它表示k8s中的三类主体, user, group, serviceAccount
- Role:角色,它其实是一组规则,定义了一组对 Kubernetes API 对象的操作权限
- RoleBinding:定义了“被作用者”和“角色”的绑定关系
-
RBAC包括四种类型:Role、ClusterRole、RoleBinding、ClusterRoleBinding
-
Role 和 ClusterRole
-
Role是一系列的权限的集合,Role只能授予单个namespace 中资源的访问权限
-
ClusterRole 跟 Role 类似,但是可以在集群中全局使用
-
Kubernetes 还提供了四个预先定义好的 ClusterRole 来供用户直接使用
-
cluster-amdin、admin、edit、view
-
Role 授权应用
# 生成role的yaml文件
[root@k8s-master ~]# kubectl create role myrole --dry-run=client --verb=get --resource pods -o yaml > myrole.yml
# 更改文件内容
[root@k8s-master ~]# vim myrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
creationTimestamp: null
name: myrole
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- watch
- list
- create
- update
- path
- delete
# 创建role
[root@k8s-master ~]# kubectl apply -f myrole.yml
role.rbac.authorization.k8s.io/myrole created
[root@k8s-master ~]# kubectl describe role myrole
Name: myrole
Labels: <none>
Annotations: <none>
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
pods [] [] [get watch list create update path delete]
# 建立角色绑定
[root@k8s-master ~]# kubectl create rolebinding moon --role myrole --namespace default --user moon --dry-run=client -o yaml > rolebinding-myrole.yml
[root@k8s-master ~]# vim rolebinding-myrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: moon
namespace: default
# 角色绑定必须指定 namespace
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: myrole
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: moon
[root@k8s-master ~]# kubectl apply -f rolebinding-myrole.yml
rolebinding.rbac.authorization.k8s.io/moon created
[root@k8s-master ~]# kubectl get rolebindings.rbac.authorization.k8s.io moon
NAME ROLE AGE
moon Role/myrole 60s
# 切换用户测试授权
[root@k8s-master ~]# kubectl config use-context moon@kubernetes
Switched to context "moon@kubernetes".
[root@k8s-master rbac]# kubectl get pods
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
001 1/1 Running 0 9m31s
# 只针对pod进行了授权,所以svc依然不能操作
[root@k8s-master rbac]# kubectl get svc
Error from server (Forbidden): services is forbidden: User "moon" cannot list resource "services" in API group "" in the namespace "default"
# 切换回管理员
[root@k8s-master rbac]# kubectl config use-context kubernetes-admin@kubernetes
ClusterRole 授权应用
# 建立集群角色
[root@k8s-master ~]# kubectl create clusterrole myclusterrole --resource=deployment --verb get --dry-run=client -o yaml > myclusterrole.yml
[root@k8s-master ~]# vim myclusterrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
creationTimestamp: null
name: myclusterrole
rules:
- apiGroups:
- apps
resources:
- deployments
verbs:
- get
- list
- watch
- create
- update
- path
- delete
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- list
- watch
- create
- update
- path
- delete
[root@k8s-master ~]# kubectl apply -f myclusterrole.yml
clusterrole.rbac.authorization.k8s.io/myclusterrole created
[root@k8s-master ~]# kubectl describe clusterrole myclusterrole
Name: myclusterrole
Labels: <none>
Annotations: <none>
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
pods [] [] [get list watch create update path delete]
deployments.apps [] [] [get list watch create update path delete]
# 建立集群角色绑定
[root@k8s-master ~]# kubectl create clusterrolebinding clusterrolebind-myclusterrole --clusterrole myclusterrole --user moon --dry-run=client -o yaml > clusterrolebind-myclusterrole.yml
[root@k8s-master ~]# vim clusterrolebind-myclusterrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: clusterrolebind-myclusterrole
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: myclusterrole
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: moon
[root@k8s-master ~]# kubectl apply -f clusterrolebind-myclusterrole.yml
clusterrolebinding.rbac.authorization.k8s.io/clusterrolebind-myclusterrole created
[root@k8s-master rbac]# kubectl describe clusterrolebindings.rbac.authorization.k8s.io clusterrolebind-myclusterrole
Name: clusterrolebind-myclusterrole
Labels: <none>
Annotations: <none>
Role:
Kind: ClusterRole
Name: myclusterrole
Subjects:
Kind Name Namespace
---- ---- ---------
User moon
[root@k8s-master ~]# kubectl config use-context moon@kubernetes
# 用户测试
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
001 1/1 Running 0 15m
[root@k8s-master rbac]# kubectl get deployments.apps -A
# 没有对svc授权
[root@k8s-master rbac]# kubectl get svc -A
Error from server (Forbidden): services is forbidden: User "moon" cannot list resource "services" in API group "" at the cluster scope
服务账户的自动化
服务账户准入控制器(Service account admission controller)
-
如果该 pod 没有 ServiceAccount 设置,将其 ServiceAccount 设为 default
-
保证 pod 所关联的 ServiceAccount 存在,否则拒绝该 pod
-
如果 pod 不包含 ImagePullSecrets 设置,那么 将 ServiceAccount 中的 ImagePullSecrets 信息添加到 pod 中
-
将一个包含用于 API 访问的 token 的 volume 添加到 pod 中
-
将挂载于 /var/run/secrets/kubernetes.io/serviceaccount 的 volumeSource 添加到 pod 下的每个容器中
服务账户控制器(Service account controller)
服务账户管理器管理各命名空间下的服务账户,并且保证每个活跃的命名空间下存在一个名为 “default” 的服务账户

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)