机器学习030:无监督学习【聚类算法】-- 四种聚类算法的生活化指南
K-means:像高效的城市规划师,快速把城市分成几个区,但要求区是圆形的,且你要提前告诉他分几个区。DBSCAN:像流行病调查员,从核心病例出发,通过密度扩散找到所有关联者,还能识别出孤立的异常病例。层次聚类:像族谱编纂者,帮你理清从个人到家族的多层关系,可以看到完整的演化路径。谱聚类:像社交关系分析师,通过计算人与人之间的连接强度,发现真正的朋友圈,即使他们在物理位置上不靠近。一句话概括:聚类
想象一下,你刚刚搬到一个新社区,想快速认识邻居们。你会怎么做呢?
一种方法是观察:谁家门口有篮球?谁家花园种了玫瑰?谁家车库里停着山地车?很快你会发现:篮球+运动鞋的几个家庭可能都喜欢运动;玫瑰+园艺工具的家庭可能热爱种植;山地车+防晒霜的家庭可能喜欢户外骑行。
聚类算法就是数据的“社交观察家”——它不告诉你每个家庭的详细信息,而是帮你发现:“嘿,这几户人家看起来是一类人!”今天,我们就来认识四位最受欢迎的“数据社交专家”:K-means、DBSCAN、层次聚类和谱聚类。
让我们先通过一张图,看看它们如何在同一个“社区”中找到不同的朋友圈:
上图展示了四种方法处理同一批数据时的不同思路。接下来,让我们深入了解每位“专家”的独门绝技。
一、分类归属:它们都是“无监督学习”的侦探
首先,我们要知道这四位专家在AI大家族中的位置:
它们都属于“无监督学习”的聚类算法。什么意思呢?
- 有监督学习:像老师带学生——我给你看100张猫的照片(带标签“这是猫”),你再看到新照片时,就能判断是不是猫
- 无监督学习:像侦探破案——我给你100个人的消费记录(没标签),你通过分析发现:“这30人常买奶粉尿布,可能是年轻父母;这20人常买保健品,可能是老年人…”
聚类算法就是无监督学习中的“分组专家”,专门帮我们发现数据中隐藏的自然分组。
二、底层原理:四位专家的独门秘籍
1. K-means:寻找“社区中心”的规划师
生活类比:想象你要在新建的小区里设置3个快递站,让所有住户取快递的平均距离最短。你会:
- 随机选3个位置作为临时快递站
- 让每家住户去最近的快递站
- 根据每个站的客户位置,重新计算更中心的位置
- 重复2-3步,直到快递站位置基本不变
核心逻辑:
关键特点:
- 需要提前指定K值:就像你要先说“我想分3个群”
- 圆形边界:每个点属于离它最近的中心点,自然形成圆形区域
- 公式简单:目标是让每个点到其所属中心的距离平方和最小
J=∑i=1K∑x∈Ci∣∣x−μi∣∣2 J = \sum_{i=1}^{K} \sum_{x \in C_i} ||x - \mu_i||^2 J=i=1∑Kx∈Ci∑∣∣x−μi∣∣2
这里JJJ是目标函数,KKK是簇数,CiC_iCi是第i个簇,μi\mu_iμi是第i个簇的中心,xxx是数据点。我们的目标就是让JJJ最小。
2. DBSCAN:从“核心人物”扩散的社交达人
生活类比:疫情中的密接排查!疾控中心会:
- 找到第一个确诊者(核心点)
- 排查他的密切接触者(距离近的)
- 如果密接者自己也接触了很多人,继续扩散排查
- 孤零零没接触什么人的,算是“噪声”(异常点)
核心逻辑:
关键特点:
- 不需要指定簇数:自己发现有几个“朋友圈”
- 能识别任意形状:不像K-means只能画圆
- 能找出异常点:那些不合群的“孤独者”
- 两个参数:
- eps(ε):社交距离——“多近算密接?”
- min_samples:核心标准——“有多少密接才算超级传播者?”
3. 层次聚类:构建“家族树”的族谱专家
生活类比:编写族谱!从个人开始:
- 先找到最相似的两个人(比如双胞胎)
- 把他们合并成一个“小家庭”
- 再找下一个最相似的(要么是个人,要么是小家庭)
- 一层层合并,最后所有人都归到一个大家族
两种方式:
- 自底向上(常用):每个人都是树叶,逐步合并成树枝,最后到树干
- 自顶向下:从树干开始,逐步分裂成树枝,最后到树叶
可视化——树状图(Dendrogram):
高度表示合并时的距离
┌───┐
│ ├── A
└─┐ │
│ ├── B
└─┤
├── C
└── D
从下往上看:A和B先合并(最相似),然后AB与C合并,最后ABC与D合并。
4. 谱聚类:画“社交关系图”的派对策划师
生活类比:策划一场派对,你要根据客人的亲疏关系分组:
- 先调查每两个人之间的熟悉程度(构建相似度矩阵)
- 画出“社交关系图”——线越粗表示越熟悉
- 把这张图切成几块,让每块内部连线多(熟悉的人在一起),块之间连线少(不熟的人分开)
核心思想:把数据点看成图中的节点,用图切割的方式聚类。
简单步骤:
- 构建相似度图:点之间连线,权重表示相似度
- 计算图的拉普拉斯矩阵(专业的“关系描述符”)
- 对这个矩阵进行特征分解
- 在新空间中进行K-means聚类
为什么特别:能处理那些在原始空间中纠缠在一起,但在某种“关系视角”下可分的数据。
三、局限性:没有完美的专家
K-means的局限
- 需要提前知道K值:如果你不知道小区该设几个快递站,只能猜
- 对异常值敏感:如果有个住户住在10公里外,他会把快递站“拉”向他
- 只能发现球形簇:如果住户沿着河流呈条状分布,K-means会硬分成几个圆
- 初始随机性影响结果:不同的初始快递站位置,可能导致不同的最终方案
DBSCAN的局限
- 密度不均匀时效果差:如果小区有些区域很密集,有些很稀疏,参数难调
- 高维数据效果下降:“距离”在高维空间变得难以定义
- 参数选择需要经验:ε和min_samples设多少合适?需要尝试
层次聚类的局限
- 计算量大:每次都要计算所有点对的距离,数据量大时慢
- 一旦合并不能撤销:族谱上两个人合并了,就不能再分开
- 对噪声敏感:如果有个“到处认亲戚”的人,会把不相关的家族连起来
谱聚类的局限
- 计算复杂度高:要算矩阵特征值,大数据很吃力
- 参数选择敏感:相似度怎么定义?图怎么构建?影响很大
- 需要指定簇数:和K-means一样,要提前知道或猜测K值
四、使用范围:什么时候请哪位专家?
适合用K-means的场景
- 你知道大概要分几类(比如客户分高、中、低三档)
- 数据分布大致是球形的
- 数据量比较大,需要较快速度
- 异常值不多或已处理
适合用DBSCAN的场景
- 你不知道有多少类,想让算法自己发现
- 数据有噪声,你想识别出异常点
- 簇的形状不规则(非球形)
- 数据密度相对均匀
适合用层次聚类的场景
- 数据量不大(万级以下)
- 你想看到完整的层次结构(比如生物分类)
- 需要可视化树状图来帮助理解
- 不确定该分多少层时
适合用谱聚类的场景
- 数据在原始空间纠缠,但可能有隐藏结构
- 簇的形状复杂,甚至是非凸形状
- 你有一些领域知识来定义“相似度”
- 数据量适中(特征值计算可承受)
简单决策流程图
开始聚类任务
│
├─ 数据量很大? → 优先K-means
│
├─ 知道簇数吗?
│ ├─ 知道 → 考虑K-means或谱聚类
│ └─ 不知道 → 考虑DBSCAN或层次聚类
│
├─ 担心异常值吗?
│ ├─ 担心 → DBSCAN
│ └─ 不担心 → 其他
│
└─ 需要层次结构吗?
├─ 需要 → 层次聚类
└─ 不需要 → 其他
五、应用场景:四位专家的实战案例
案例1:电商用户分群(K-means实战)
场景:某电商平台有100万用户,想设计不同的营销策略
做法:用K-means根据用户的“购买频率”、“客单价”、“最近购买时间”分群
结果发现:
- 簇1:高频高额用户(VIP,占5%)→ 推送新品、专属客服
- 簇2:高频低额用户(爱逛不贵,占20%)→ 推送促销、团购
- 簇3:低频高额用户(大件买家,占10%)→ 推送家电、家具
- 簇4:低频低额用户(偶尔买家,占65%)→ 推送爆款、唤醒优惠
案例2:信用卡欺诈检测(DBSCAN实战)
场景:银行监控信用卡交易,找出异常模式
做法:用DBSCAN分析每笔交易的“时间”、“金额”、“地点”、“商户类型”
发现:
- 大多数交易形成几个密集簇:日常消费、大额购物、旅游消费等
- 一些交易远离所有簇:深夜在国外小额测试、短时间内多地消费等 → 触发人工审核
优势:不用提前知道欺诈模式,能发现新型欺诈
案例3:生物物种分类(层次聚类实战)
场景:生物学家收集了200种动物的特征数据
做法:用层次聚类,基于“体型”、“食性”、“栖息地”、“繁殖方式”等
得到树状图:
哺乳动物─┬── 食肉目─┬── 猫科
│ └── 犬科
└── 灵长目─┬── 人科
└── 猴科
价值:不仅知道分几类,还看到演化关系——猫和狗在“食肉目”层面是亲戚,再往上和灵长目都是哺乳动物。
案例4:社交网络社区发现(谱聚类实战)
场景:微信研究者想发现朋友圈中的自然社群
做法:用谱聚类分析用户互动数据
步骤:
- 构建图:每个用户是节点,互动频率是边权重
- 发现:虽然A和B直接互动不多,但他们都和C互动密切 → 可能属于同一社群
- 切分:把整个图切成几个子图,每个子图内部连接紧密,之间连接稀疏
结果:识别出“高中同学群”、“健身俱乐部”、“宝妈交流圈”等自然社群
案例5:新闻主题聚类(综合应用)
场景:新闻App自动将文章分类
做法流程:
- 预处理:将文章转为向量(词频、TF-IDF等)
- 降维:用PCA/t-SNE把高维向量降到2-3维(可视化需要)
- 聚类:
- 先用K-means快速分大类(政治、经济、体育…)
- 在大类内用层次聚类细分(政治→国内、国际;体育→足球、篮球…)
- 用DBSCAN找出异常文章(可能是假新闻或特殊事件)
六、Python实践:用手势识别数据体验四种聚类
让我们用真实数据感受一下四位专家的不同风格。我们使用经典的鸢尾花数据集,但假设我们不知道它有3种花(模拟无监督场景)。
# 1. 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.cluster import SpectralClustering
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
import warnings
warnings.filterwarnings('ignore')
# 2. 加载数据并标准化
iris = datasets.load_iris()
X = iris.data # 花瓣长宽、萼片长宽
y_true = iris.target # 真实标签(在无监督中我们假装不知道)
# 标准化很重要,让不同特征的尺度一致
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print(f"数据集形状: {X.shape}")
print(f"特征名: {iris.feature_names}")
print(f"真实类别数: {len(np.unique(y_true))}")
# 3. 可视化函数:比较不同聚类结果
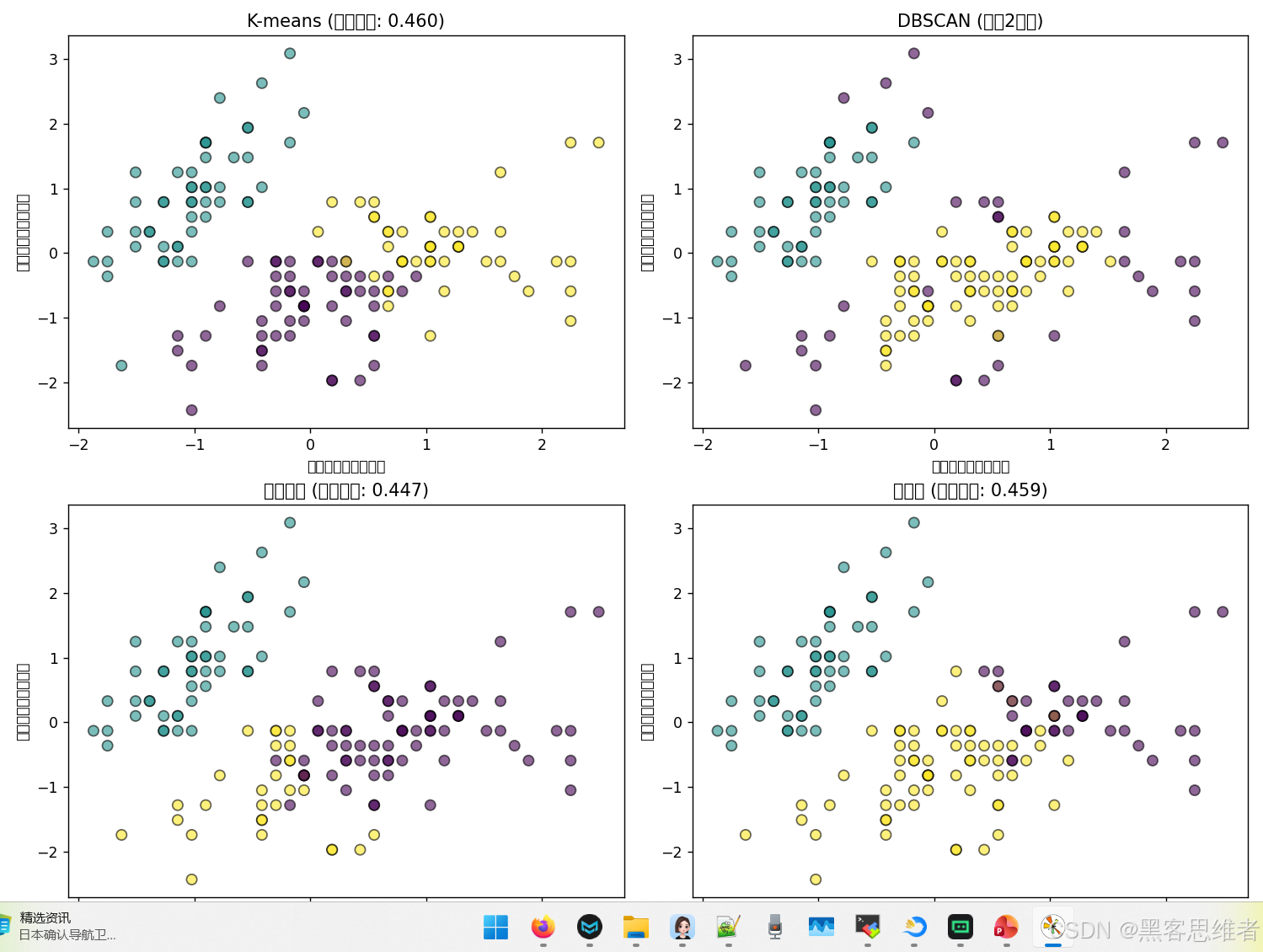
def plot_clusters(X, labels, title, ax):
"""绘制聚类结果的散点图(使用前两个特征)"""
scatter = ax.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis',
s=50, alpha=0.6, edgecolor='k')
ax.set_xlabel('萼片长度(标准化)')
ax.set_ylabel('萼片宽度(标准化)')
ax.set_title(title)
return scatter
# 4. 创建画布
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
axes = axes.flatten()
# 5. K-means聚类
kmeans = KMeans(n_clusters=3, random_state=42, n_init=10)
kmeans_labels = kmeans.fit_predict(X_scaled)
plot_clusters(X_scaled, kmeans_labels, f'K-means (轮廓系数: {silhouette_score(X_scaled, kmeans_labels):.3f})', axes[0])
# 6. DBSCAN聚类
dbscan = DBSCAN(eps=0.5, min_samples=5)
dbscan_labels = dbscan.fit_predict(X_scaled)
# DBSCAN可能把一些点标为噪声(-1)
n_clusters_dbscan = len(set(dbscan_labels)) - (1 if -1 in dbscan_labels else 0)
plot_clusters(X_scaled, dbscan_labels, f'DBSCAN (找到{n_clusters_dbscan}个簇)', axes[1])
# 7. 层次聚类
hierarchical = AgglomerativeClustering(n_clusters=3)
hierarchical_labels = hierarchical.fit_predict(X_scaled)
plot_clusters(X_scaled, hierarchical_labels, f'层次聚类 (轮廓系数: {silhouette_score(X_scaled, hierarchical_labels):.3f})', axes[2])
# 8. 谱聚类
spectral = SpectralClustering(n_clusters=3, random_state=42, affinity='nearest_neighbors')
spectral_labels = spectral.fit_predict(X_scaled)
plot_clusters(X_scaled, spectral_labels, f'谱聚类 (轮廓系数: {silhouette_score(X_scaled, spectral_labels):.3f})', axes[3])
plt.tight_layout()
plt.show()
# 9. 对比分析
print("\n=== 四种算法对比 ===")
print("真实情况:鸢尾花有3个品种(Setosa, Versicolor, Virginica)")
print("\n各算法发现的簇数:")
print(f"K-means: {len(np.unique(kmeans_labels))}个簇")
print(f"DBSCAN: {len(np.unique(dbscan_labels))}个簇(-1表示噪声)")
print(f"层次聚类: {len(np.unique(hierarchical_labels))}个簇")
print(f"谱聚类: {len(np.unique(spectral_labels))}个簇")
# 10. 轮廓系数比较(-1到1,越大越好)
print("\n轮廓系数比较(越大越好):")
algorithms = ['K-means', 'DBSCAN', '层次聚类', '谱聚类']
labels_list = [kmeans_labels, dbscan_labels, hierarchical_labels, spectral_labels]
for name, labels in zip(algorithms, labels_list):
if len(set(labels)) > 1: # 至少要有2个簇才能计算轮廓系数
score = silhouette_score(X_scaled, labels)
print(f"{name}: {score:.3f}")
# 11. 可视化层次聚类的树状图
from scipy.cluster.hierarchy import dendrogram, linkage
plt.figure(figsize=(10, 6))
# 为了可视化清晰,我们只用前30个样本
Z = linkage(X_scaled[:30], method='ward')
dendrogram(Z, labels=[f"样本{i}" for i in range(30)])
plt.title('层次聚类树状图(前30个样本)')
plt.xlabel('样本编号')
plt.ylabel('距离')
plt.axhline(y=4, color='r', linestyle='--', alpha=0.5, label='切割线(分成3组)')
plt.legend()
plt.show()
代码解读与发现:
- 数据准备:我们使用了经典的鸢尾花数据集,但假装不知道它有3个品种
- 标准化:非常重要!因为花瓣长度可能是厘米级,宽度是毫米级,不标准化的话,长度会主导距离计算
- 四种算法对比:
- K-means:干净利落,直接分成3个球形簇
- DBSCAN:参数敏感!调整eps和min_samples会得到不同结果,可能发现噪声点
- 层次聚类:可以看到层次结构,通过树状图决定切几层
- 谱聚类:通过特征变换找到数据的内在结构
- 评估指标:轮廓系数衡量“簇内紧凑、簇间分离”的程度,越接近1越好
运行这个代码,你会看到:
- 四种算法在同一个数据集上的不同表现
- 有些算法天然适合这个数据,有些不适合(取决于参数)
- 没有绝对最好的算法,只有最适合具体问题的算法
七、总结:四位专家的核心价值
K-means:像高效的城市规划师,快速把城市分成几个区,但要求区是圆形的,且你要提前告诉他分几个区。
DBSCAN:像流行病调查员,从核心病例出发,通过密度扩散找到所有关联者,还能识别出孤立的异常病例。
层次聚类:像族谱编纂者,帮你理清从个人到家族的多层关系,可以看到完整的演化路径。
谱聚类:像社交关系分析师,通过计算人与人之间的连接强度,发现真正的朋友圈,即使他们在物理位置上不靠近。
一句话概括:聚类算法是数据的「社交观察家」,不关心个体的详细档案,只专注于发现「谁和谁是一类人」。选择哪位专家,取决于你的数据特性、问题需求和对结果的期待。
八、思维导图:建立完整知识体系
聚类算法家族
│
├── 核心思想:物以类聚,数据自动分组
│
├── 主要类型
│ ├── 基于划分:K-means
│ ├── 基于密度:DBSCAN
│ ├── 基于层次:层次聚类
│ └── 基于图论:谱聚类
│
├── 关键概念
│ ├── 无监督学习(没有老师带)
│ ├── 相似度度量(多近算朋友?)
│ ├── 簇内紧凑(一家人要像)
│ └── 簇间分离(两家人要不像)
│
├── 选择指南
│ ├── 知道分几类?→ K-means/谱聚类
│ ├── 不知道分几类?→ DBSCAN/层次聚类
│ ├── 要排除异常值?→ DBSCAN
│ ├── 要看层次结构?→ 层次聚类
│ ├── 数据量大要快?→ K-means
│ └── 形状复杂?→ DBSCAN/谱聚类
│
├── 实践步骤
│ ├── 1. 理解问题与数据
│ ├── 2. 数据预处理(标准化!)
│ ├── 3. 选择算法与参数
│ ├── 4. 训练与评估
│ └── 5. 解释与应用结果
│
└── 常见应用
├── 客户细分(电商)
├── 异常检测(金融)
├── 社群发现(社交网络)
├── 文档归类(新闻)
└── 基因分类(生物)
给初学者的最后建议
- 从K-means开始:它最直观,参数最少,适合建立直觉
- 可视化是关键:一定要画图看看聚类结果,眼见为实
- 标准化不能忘:不同尺度的特征会扭曲距离计算
- 多尝试多比较:没有银弹算法,多试几种才知道哪个最适合
- 结合业务理解:最好的评估标准是聚类结果在业务上是否说得通
记住,聚类算法不是魔法,它们只是帮助我们看见数据中隐藏模式的工具。真正的智慧,在于你如何提出问题、准备数据、解释结果。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 32
32 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)