音频相关基础知识
声音的本质声音的本质是波在介质中的传播现象,声波的本质是一种波,是一种物理量。两者不一样,声音是一种抽象的,是声波的传播现象,声波是物理量。声音的三要素响度(loudness): 人主观上感觉声音的大小(俗称音量),由“振幅”(amplitude)和人离声源的距离决定,振幅越大响度越大,人和声源的距离越小,响度越大。音调(pitch): 声音的高低(高音、低音),由频率决定,频率越高音调越高(频率
主要参考:
概述
声音的本质
声音的本质是波在介质中的传播现象,声波的本质是一种波,是一种物理量。 两者不一样,声音是一种抽象的,是声波的传播现象,声波是物理量。具体来说,声音的产生和传播可以拆解为以下过程:
1. 振动是声音的源头
声音的产生始于振动物体(声源),比如声带振动(说话)、琴弦振动(乐器)、喇叭振膜振动(音响)等。这些振动会推动周围的介质(最常见的是空气),使介质分子产生周期性的 “挤压” 和 “稀疏”。
2. 声波是介质的波动传递
- 当声源振动时,相邻的空气分子会被 “推挤” 形成密部(分子密集),随后声源回弹,周围空气分子又会形成疏部(分子稀疏)。
- 这种密部和疏部的交替变化会像水波一样向四周扩散,形成声波。声波的传播方向与介质分子的振动方向平行(纵波),不同于水波的横波(振动方向与传播方向垂直)。
3. 介质是传播的必要条件
声音的传播必须依赖介质,除了空气,液体(如水)、固体(如墙壁、铁轨)也能传播声音,且传播速度和特性与介质有关:
- 空气中的声速约 340 米 / 秒(常温);
- 水中声速约 1500 米 / 秒,因此水下能听到更远的声音(如鲸鱼的低频通讯);
- 固体中声速更快(如钢铁中约 5200 米 / 秒),这也是 “趴在铁轨上能提前听到远处火车声” 的原因。
真空中没有介质,因此无法传播声音(比如太空是 “寂静” 的)。
4. 人耳对声波的感知
当声波传递到耳朵时,会引起鼓膜振动,这种振动通过听小骨传递到耳蜗,最终转化为神经信号被大脑识别为 “声音”。不同的振动频率(对应音调高低)和振幅(对应响度大小),会让人感知到不同的声音特征。
总结
声音的本质可以概括为:声源振动→介质(空气等)的疏密波动(声波)→人耳接收振动并转化为听觉信号。空气振动是声音在日常生活中最常见的传播形式,但本质上,只要存在能传递振动的介质,声音就能产生和传播。
声音的三要素
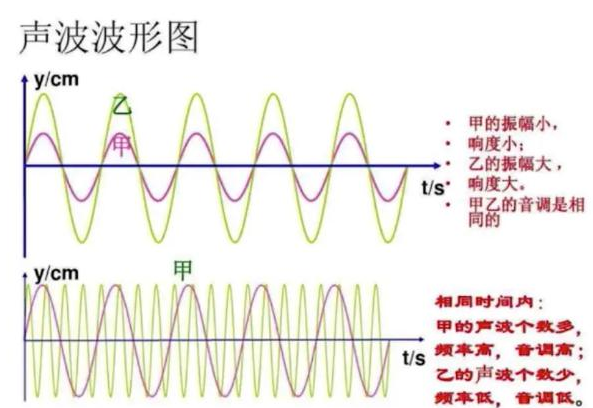
- 响度(loudness): 人主观上感觉声音的大小(俗称音量),由“振幅”(amplitude)和人离声源的距离决定,振幅越大响度越大,人和声源的距离越小,响度越大。
- 音调(pitch): 声音的高低(高音、低音),由频率决定,频率越高音调越高(频率单位Hz,赫兹),人耳听觉范围20~20000Hz。20Hz以下称为次声波,20000Hz以上称为超声波)。
- 音色(Timbre): 波形决定了声音的音调。由于不同对象材料的特点,声音具有不同的特性,音色本身就是抽象的东西,但波形就是把这种抽象和直观的性能。波形因音调而异,不同的音调可以通过波形来区分。
下图为音量与音调关系:
幅度对应响度,频率对应音调,那什么对应音色呢?
音色由声音的谐波成分(泛音结构) 决定,具体可从以下维度理解其与波形特征的对应关系:
声音的构成要素:
任何声音均可分解为 基波(决定音调) 和 谐波(泛音)。当基波频率(音调)和振幅(响度)相同时,谐波的数量、频率分布及振幅比例 是区分音色的关键。
例:钢琴与小提琴演奏同一音高(基波相同)时,因谐波结构不同,音色迥异。
谐波与波形的关联:
不同谐波组合会形成不同的波形形状,而波形的复杂度直接反映音色的丰富度。
案例对比:
发声体 谐波特征 波形表现 音色特点 音叉 仅有基波(或极少量谐波) 近似正弦波 音色纯净、单一 吉他 谐波丰富,振幅随频率升高递减 锯齿状叠加波形 音色明亮、有颗粒感 萨克斯管 低频谐波强,高频谐波较弱 近似梯形波形 音色圆润、温暖 关键逻辑: 谐波数量越多、振幅分布越复杂,波形越偏离正弦波,音色越 “饱满” 或 “独特”。
音频相关参数
接下来看看音频相关参数
音频采样率
音频采样率
其实就是采集音频数据过程中所使用的ADC采样的频率。
声波其实是一种机械波,因此也有波长和振幅的特征,波长对应于时间轴线,振幅对应于采样值轴线。波是无限光滑的,弦线可以看成由无数点组成,由于存储空间是相对有限的,数字编码过程中,必须对弦线的点进行采样。采样的过程就是抽取某点的采样值,很显然,在单位时间中内抽取的点越多,获取得波长信息更丰富,为了复原波形,一个周期中,必须有至少2个点的采样。人耳能够感觉到的最低波长为1.7cm,即20000Hz,因此如果要全范围内满足人耳的听觉要求,则1s采样至少40000次,用40000Hz(40kHz)表达,这个40kHz就是采样率,这样才能将人耳所能听到的声音全部记录下来。我们常见的CD,采样率为44.1kHz(并没有取40kHz整数,可能跟晶振的制作工艺等相关,就跟时钟晶振32.768kHz类似)。
在数字音频领域,常用的采样率有:
- 8,000 Hz - 电话所用采样率, 对于人的说话已经足够
- 11,025 Hz-AM调幅广播所用采样率
- 22,050 Hz和24,000 Hz- FM调频广播所用采样率
- 32,000 Hz - miniDV 数码视频 camcorder、DAT (LP mode)所用采样率
- 44,100 Hz - 音频 CD, 也常用于 MPEG-1 音频(VCD, SVCD, MP3)所用采样率
- 47,250 Hz - 商用 PCM 录音机所用采样率
- 48,000 Hz - miniDV、数字电视、DVD、DAT、电影和专业音频所用的数字声音所用采样率
- 50,000 Hz - 商用数字录音机所用采样率
- 96,000 或者 192,000 Hz - DVD-Audio、一些 LPCM DVD 音轨、BD-ROM(蓝光盘)音轨、和 HD-DVD (高清晰度 DVD)音轨所用所用采样率
- 2.8224 MHz - Direct Stream Digital 的 1 位 sigma-delta modulation 过程所用采样率。
人正常说话的声音一般频率在什么范围?
人正常说话的声音频率范围主要集中在 85 Hz ~ 255 Hz(基频),但语音的完整频率范围(包括谐波和辅音)通常覆盖 80 Hz ~ 8 kHz。具体分布如下:
基频(F0,决定音调)
- 男性:通常 85 Hz ~ 180 Hz(平均约 120 Hz)。
- 女性:通常 165 Hz ~ 255 Hz(平均约 220 Hz)。
- 儿童:可能高达 300 Hz 以上。
注:基频是声带振动产生的低频成分,决定声音的“低沉”或“尖锐”。
语音的完整频率范围(含谐波和辅音)
虽然基频较低,但语音的清晰度依赖于更高频率的谐波和辅音能量分布:
- 元音(Vowels):能量集中在 100 Hz ~ 1 kHz(如“a”、“o”等)。
- 辅音(Consonants):高频成分可达 2 kHz ~ 8 kHz(如“s”、“f”等清辅音)。
例如:“s”音的频率可高达 6 kHz ~ 8 kHz,对语音清晰度至关重要。
语音通信系统的频带设计
基于人声频率特性,常见通信系统会压缩频带以节省带宽:
- 电话语音:300 Hz ~ 3.4 kHz(牺牲部分高频辅音,但仍可保真基本语音)。
- 广播/会议系统:80 Hz ~ 8 kHz(更高保真度)。
- 语音识别(ASR):通常分析 50 Hz ~ 4 kHz 的频段。
关键影响因素
- 音调变化:情绪激动时基频可能升高(如尖叫可达 1 kHz 以上)。
- 环境噪声:高频辅音(如“s”“t”)易被噪声掩盖,需增强处理。
- 设备限制:麦克风或扬声器频响范围不足(如仅 100 Hz ~ 4 kHz)会导致声音“发闷”或“不清晰”。
实验数据参考
语音成分 频率范围 作用 基频(F0) 85 Hz ~ 255 Hz 决定音调(男/女/儿童差异) 元音 100 Hz ~ 1 kHz 提供声音响度和饱满度 清辅音 2 kHz ~ 8 kHz 影响清晰度(如“s”“f”“th”)
总结
- 日常对话:重点关注 100 Hz ~ 4 kHz,这是可懂度的核心频段。
- 高质量音频:需保留 80 Hz ~ 8 kHz 以还原自然度。
- 语音处理:降噪或增强时需特别注意保护 2 kHz ~ 4 kHz 的高频辅音部分。
如果需要测量具体人的语音频率,可使用频谱分析工具(如 Audacity、Praat)。
音乐的频率范围详解
音乐是由不同乐器和人声组成的复杂声学信号,其频率范围远宽于人声。不同类型的音乐、乐器及音效覆盖的频段各不相同,以下是详细的分类和分析:
音乐的整体频率范围
频段 频率范围 主要成分 听觉感受 超低频 20 Hz ~ 60 Hz 低音鼓(Kick)、管风琴、电子低音 震撼感,身体可感知振动 低频 60 Hz ~ 250 Hz 贝斯(Bass)、大提琴、低音吉他 浑厚、温暖 中低频 250 Hz ~ 500 Hz 男声、钢琴低音区、小号 饱满、有力度 中频 500 Hz ~ 2 kHz 人声(主唱)、吉他、小提琴中音区 清晰、明亮(核心频段) 中高频 2 kHz ~ 5 kHz 镲片(Cymbals)、女声高音、钢琴高音 穿透力强,增强细节 高频 5 kHz ~ 12 kHz 小提琴泛音、三角铁、齿音(Sibilance) 清脆、空气感 极高频 12 kHz ~ 20 kHz 钹(Hi-hat)、录音室混响、电子音效 空灵感,但易被年龄大者忽略 注:人耳可听范围一般为 20 Hz ~ 20 kHz,但成年人高频听力会衰退(如 40 岁以上可能听不到 15 kHz 以上)。
不同乐器的频率分布
乐器/音源 主要频率范围 关键频段 人声(歌唱) 80 Hz ~ 1.2 kHz(基频)
谐波可达 8 kHz男声:100 Hz ~ 400 Hz
女声:200 Hz ~ 1 kHz钢琴 27.5 Hz (A0) ~ 4.2 kHz (C8) 低音区:< 200 Hz
高音区:> 2 kHz电吉他 80 Hz ~ 1.2 kHz(基频)
失真音色可达 5 kHz核心频段:200 Hz ~ 2.5 kHz 鼓组 Kick:60 Hz ~ 100 Hz
Snare:150 Hz ~ 5 kHz
Hi-hat:2 kHz ~ 12 kHz低频冲击力 + 高频瞬态 小提琴 196 Hz (G3) ~ 3.1 kHz (A7)
泛音可达 12 kHz中高频表现力强(2 kHz ~ 8 kHz) 电子合成音 全频段(20 Hz ~ 20 kHz) 取决于合成器设计(如Sub Bass或Glitch音效)
音乐制作与音频设备的频响要求
(1) 录音与混音
全频段覆盖:专业录音设备需支持 20 Hz ~ 20 kHz(如电容麦克风、监听音箱)。
关键调整频段:
- 50 Hz 以下:超低频可能需削减(避免浑浊)。
- 200 Hz ~ 500 Hz:控制“闷响”(Muddy)。
- 3 kHz ~ 5 kHz:提升人声/乐器清晰度。
- 10 kHz 以上:增加“空气感”(但过量会刺耳)。
(2) 播放设备
设备类型 有效频响范围 局限性 高端耳机 5 Hz ~ 40 kHz 超高频可能超出人耳感知 普通音箱 60 Hz ~ 18 kHz 低频下潜不足,高频衰减 手机扬声器 300 Hz ~ 15 kHz 几乎无低频,中高频突出 黑胶唱片 20 Hz ~ 20 kHz 超低频可能引起唱针跳轨
不同音乐风格的频率特点
音乐类型 核心频段 特征 古典乐 40 Hz ~ 18 kHz 动态范围大,乐器频段均衡 摇滚/金属 80 Hz ~ 5 kHz 强低频(贝斯/鼓)+ 高能量中频 电子音乐 30 Hz ~ 16 kHz 超低频(Sub Bass)+ 极高频特效 爵士乐 100 Hz ~ 12 kHz 中频温暖(萨克斯、钢琴) 流行音乐 60 Hz ~ 10 kHz 突出人声(1 kHz ~ 4 kHz)
常见问题
Q1:为什么有些音乐听起来“闷”?
原因:中低频(200 Hz ~ 500 Hz)过多,或高频(> 5 kHz)不足。
解决:EQ 削减 250 Hz,提升 3 kHz ~ 8 kHz。
Q2:如何增强音乐的“空间感”?
方法:在 12 kHz 以上小幅提升,或添加混响(Reverb)。
Q3:MP3 压缩会损失哪些频率?
损失频段:优先压缩 > 16 kHz 的极高频和 < 50 Hz 的超低频(因人类对这些频段敏感度较低)。
总结
音乐完整频率范围:20 Hz ~ 20 kHz,但不同乐器和风格侧重不同频段。
关键频段:
- 低频(< 250 Hz):奠定节奏和氛围。
- 中频(500 Hz ~ 2 kHz):决定清晰度和主体感。
- 高频(> 5 kHz):增加细节和临场感。
设备选择:根据音乐类型匹配频响范围(如电子音乐需强低频,古典乐需宽频带)。
如果需要分析具体音乐的频谱,可使用工具如 Adobe Audition、SPAN(VST插件)或 Audacity。
可见,音乐是多种多样的,为了能够满足人耳所能听到的所有声音的范围,音乐的采样率一般至少要40kHz,通常使用的是44.1kHz。
音乐的采样率可以小于40kHz吗?
音乐采样率可以小于40kHz,但需根据音频内容和用途权衡音质和带宽需求。以下是详细分析:
采样率的基础要求(奈奎斯特定理)
奈奎斯特准则:采样率(𝑓𝑠fs)必须 ≥ 2倍信号最高频率(𝑓maxfmax),否则会出现混叠失真(Aliasing)。
例如:若要保留20kHz的高频,采样率至少需 40kHz(实际常用 44.1kHz 或 48kHz)。
人耳听音范围:通常为 20Hz~20kHz,因此理论上 40kHz采样率是下限。
采样率 <40kHz 的适用场景
(1) 语音通信(窄带音频)
- 电话语音:采样率通常为 8kHz(保留 300Hz~3.4kHz 频段),牺牲高频以节省带宽。
- 对讲机/广播:采样率可能低至 6kHz~16kHz,仅保留语音可懂度的核心频段(80Hz~4kHz)。
(2) 低质量音乐或特殊效果
- 复古音效:故意使用低采样率(如 22.05kHz)制造“低保真(Lo-Fi)”效果。
- 游戏音效:非关键背景音可能用 24kHz 采样率以减少资源占用。
(3) 嵌入式设备限制
- 单片机/传感器:存储或算力有限时,可能采用 16kHz~32kHz 采样率(如电子玩具、简单MIDI播放器)。
采样率 <40kHz 的缺点
问题 原因 高频信息丢失 采样率 20kHz 仅能保留 ≤10kHz 的信号,音乐缺失高频细节(如镲片、泛音)。 音质浑浊 低频与中频拥挤,动态范围降低(尤其影响钢琴、吉他等宽频乐器)。 混叠失真 若未严格滤波,高频信号会折叠到可听频段(产生刺耳噪声)。
实际应用中的采样率选择
用途 推荐采样率 保留频段 示例 专业音乐制作 44.1kHz~96kHz 20Hz~20kHz+ CD、流媒体高音质 语音通话(VoIP) 8kHz~16kHz 300Hz~4kHz 微信语音、Zoom会议 广播/播客 24kHz~48kHz 50Hz~12kHz FM电台、有声书 嵌入式音频 16kHz~32kHz 100Hz~8kHz 电子门铃、报警提示音
如何降低采样率而不毁坏音质?
若必须使用 <40kHz 采样率,需遵循以下步骤:
低通滤波(抗混叠):
先滤除高于 𝑓𝑠/2fs/2 的频率(如采样率 32kHz 时,滤除 >16kHz 的信号)。
重采样(Resampling):
用高质量算法(如SoX或iZotope RX)降低采样率,减少失真。
动态范围压缩:
压缩音频动态范围,避免低频能量掩盖中高频。
常见误区
误区1:“采样率越高,音质一定越好。”
事实:高于48kHz的采样率(如192kHz)对人耳无意义,但会增加文件大小。
误区2:“8kHz采样率的音乐也能听。”
事实:仅适合语音,音乐会丢失几乎所有高频,听起来像“电话音质”。
结论
可以 <40kHz,但仅限于语音、低功耗设备或特殊音效。
音乐制作/高音质需求:必须 ≥44.1kHz(CD标准)以保留全频段信息。
关键权衡:采样率越低,带宽/存储需求越小,但音质损失越大。
如果需要优化低采样率音频,建议结合比特深度(如16bit)和压缩编码(如MP3 128kbps)平衡质量与体积。
为什么音乐采样率需要超过48kHz?人耳听不出区别,还有必要吗?
虽然人耳的听音范围通常是 20Hz~20kHz,理论上 48kHz采样率(奈奎斯特频率24kHz) 已经足够覆盖可听声范围,但专业音频制作仍会使用 96kHz、192kHz 甚至更高采样率,主要原因包括:
抗混叠(Anti-Aliasing)与滤波需求
奈奎斯特限制:采样率必须 ≥ 2倍最高频率,但实际ADC(模数转换)过程需要更严格的滤波。
陡峭滤波器的代价:
若采样率=48kHz,需在 20kHz~24kHz 之间急剧滤除高频(避免混叠),这会引入相位失真和预振铃(Pre-ringing)。
更高采样率(如96kHz):允许滤波器在 40kHz~48kHz 范围内平缓衰减,减少音质损失。
✅ 实际受益:更高采样率能降低数字滤波对可听频段(<20kHz)的影响,提升瞬态响应(如鼓声、钢琴的起音更自然)。
高频谐波与超声波的影响
乐器/人声的超声波成分:
许多乐器(如钢琴、小提琴)的泛音可达 30kHz~50kHz,虽人耳听不见,但可能影响设备处理(如电子管话筒、模拟硬件)。
超声波在数字域混音时可能与可听频段产生互调失真(Intermodulation Distortion),更高采样率可减少这类问题。
✅ 实际受益:专业录音时保留超声波信息,可确保后期处理(如降噪、时间拉伸)更精准。
音频处理与后期制作的灵活性
时间拉伸(Time-Stretching):
高采样率音频在变速/变调时(如Melodyne、Ableton Warp)能减少“数字颗粒感”。
混响与空间效果:
高采样率提供更精确的延迟计算,改善人工混响的自然度。
降低量化误差:
高采样率结合高比特深度(如24bit/192kHz)可减少数字舍入误差,提升动态范围。
✅ 实际受益:即使最终导出为44.1kHz/48kHz,原始高采样率文件能提供更干净的后期处理结果。
专业音频设备的支持
现代ADC/DAC芯片:
高端音频接口(如Apollo、RME)默认支持 192kHz,硬件设计已优化高采样率性能。
DSD(直接比特流)录音:
SACD采用 2.8MHz~5.6MHz 采样率(1bit),需高采样率PCM转换。
✅ 实际受益:兼容专业工作流程,避免采样率转换带来的质量损失。
争议与科学验证
盲听测试结果:
多数人无法区分 44.1kHz vs. 192kHz 的最终音乐(如《Audio Engineering Society》研究)。
但录音工程师能感知 处理阶段 的差异(如插件运算精度)。
心理声学效应:
部分研究表明,超声波可能间接影响人耳对可听频段的感知(尚无定论)。
⚠️ 注意:消费者无需追求高采样率音乐(如Tidal的192kHz),因回放设备(耳机/音箱)和听音环境限制其优势。
何时需要高采样率?
场景 推荐采样率 理由 专业录音/混音 96kHz~192kHz 确保后期处理质量 电子音乐制作 48kHz~96kHz 高频合成器可能产生超声波 影视/游戏音效 48kHz~192kHz 时间拉伸/空间效果需求 最终音乐分发 44.1kHz~48kHz 人耳无法感知更高采样率的差异
结论
对人耳直接听感:超过48kHz的采样率(如96kHz/192kHz)无显著提升。
对专业音频制作:高采样率能:
- 改善滤波和抗混叠性能。
- 提供更灵活的后期处理。
- 兼容专业设备和工作流程。
对普通用户:44.1kHz/48kHz 完全足够,无需追求高采样率文件(除非原始录音质量极高)。
建议:
音乐制作:录音时用 96kHz,最终导出 44.1kHz/48kHz。
普通听众:选择 CD质量(44.1kHz/16bit) 或 无损(48kHz/24bit) 即可。
更高的配置其实对普通用户没啥用,但是对专业音频制作人员来说是有用的,可以增加音乐制作的容错度,有更多可选择的余地。
比特深度(位深度)
其实就是采样音频数据时所使用的ADC的位数,位数越高,分辨率越高,采样越精准,但同时占的空间也越大。
位深度表示每个采样点用多少二进制位数(bits)存储振幅信息。
音频的位深度(Bit Depth)决定了数字音频的动态范围和量化精度,直接影响音质细节和噪声水平。以下是常见的位深度及其应用场景:
位深度的基本概念
定义:位深度表示每个采样点用多少二进制位数(bits)存储振幅信息。
动态范围(dB):每增加1bit,动态范围提升约 6dB。
计算公式:动态范围=6.02×位深度+1.76动态范围=6.02×位深度+1.76
例如:16bit → 98dB,24bit → 144dB。
常见的位深度类型
位深度 动态范围 主要用途 优缺点 8bit ~48dB 早期游戏音效、电话语音 噪声明显,音质粗糙 16bit ~98dB CD音频、流媒体(MP3/AAC) 平衡音质与文件大小 24bit ~144dB 专业录音、母带制作、高解析音频 低噪声,适合后期处理 32bit(浮点) ~1528dB* DAW内部处理、影视后期 抗 clipping,超强动态范围 注:32bit浮点的动态范围理论值极高(因浮点运算特性),实际有效精度约24bit。
不同位深度的应用场景
(1) 8bit
用途:复古游戏(如FC红白机)、老式语音设备。
特点:
明显的量化噪声(“颗粒感”)。
文件极小,适合低带宽场景。
(2) 16bit(CD标准)
用途:音乐CD、Spotify/Apple Music(非Hi-Res)、广播。
特点:
动态范围(98dB)覆盖大部分音乐需求。
噪声电平约 -96dBFS,人耳在正常音量下难以察觉。
(3) 24bit(专业音频)
用途:录音室原始录制、Hi-Res音频(如FLAC 24bit/96kHz)、影视配乐。
特点:
更低的底噪(-144dBFS),适合大动态音乐(如古典、爵士)。
后期混音时提供更大调整空间(如提升音量不引入噪声)。
(4) 32bit浮点(DAW内部)
用途:数字音频工作站(如Pro Tools、Ableton Live)的工程文件。
特点:
几乎不会 clipping(过载),适合多轨混音。
导出时通常转为24bit或16bit。
如何选择合适的位深度?
场景 推荐位深度 理由 音乐录制/混音 24bit 保留最大动态范围,方便后期处理 最终音乐分发(CD) 16bit 兼容CD标准,文件更小 影视/游戏音效 24bit或32bit浮点 应对复杂动态变化(如爆炸声到耳语) 语音通话 16bit(或更低) 语音动态范围小,8bit~16bit足够
常见问题
Q1:24bit音乐比16bit听起来更好吗?
答案:在理想条件下(高端设备、安静环境),24bit可能更细腻,但普通人耳难以区分。差异主要在录音和混音阶段的优势。
Q2:为什么32bit浮点用于DAW?
答案:浮点运算允许信号超过0dBFS(如+15dB)而不 clipping,混音时更灵活。
Q3:MP3的位深度是多少?
答案:MP3是有损压缩格式,实际存储的是频域数据,无直接位深度概念,但解码后通常输出16bit PCM。
总结
16bit:音乐分发的黄金标准(CD、流媒体)。
24bit:专业录音和Hi-Res音频的首选。
32bit浮点:DAW内部处理的终极保障。
8bit:仅限复古或极低带宽场景。
选择位深度时,需权衡音质需求、文件大小和工作流程。对于普通听众,16bit/44.1kHz(CD质量)已足够;专业制作建议全程使用24bit或更高。
声道数
由于音频的采集和播放是可以叠加的,因此,可以同时从多个音频源采集声音,并分别输出到不同的扬声器,故声道数一般表示声音录制时的音源数量或回放时相应的扬声器数量。单声道(Mono)和双声道(Stereo)比较常见,顾名思义,前者的声道数为1,后者为2。
音频的声道数决定了声音的空间分布和沉浸感,不同的声道配置适用于不同的场景(如音乐、电影、游戏等)。以下是常见的声道格式及其应用:
单声道(Mono,1.0声道)
信号通道:1个(所有声音混合到同一通道)。
特点:
无方向感,声音来源听起来在正前方。
文件体积最小,兼容所有播放设备。
典型用途:
早期广播、电话语音、播客(人声为主)。
某些乐器录音(如底鼓、军鼓)。
立体声(Stereo,2.0声道)
信号通道:2个(左 + 右)。
特点:
提供基本的左右声场定位,适合音乐和日常聆听。
通过声像(Panning)控制乐器在左右声道的分布。
典型用途:
音乐录制(CD、流媒体平台)。
耳机播放、普通音箱系统。
2.1声道(立体声 + 低音炮)
信号通道:2个主声道(左+右) + 1个低频效果(LFE)通道。
特点:
低音炮(Subwoofer)负责 80Hz以下低频,减轻主音箱负担。
增强低音冲击力,但声场仍为2D(左右)。
典型用途:
家用音响、电脑多媒体音箱。
5.1声道(环绕声)
信号通道:
前置:左、中、右(3个)。
环绕:左后、右后(2个)。
低频:LFE(1个)。
特点:
提供 360° 环绕声场,适合电影和游戏。
中置声道(Center)强化对白人声。
典型用途:
影院杜比(Dolby)音效、家庭影院。
游戏音效(如PS5、Xbox支持)。
7.1声道(增强环绕声)
信号通道:在5.1基础上增加 侧环绕左、右(2个),共8个。
特点:
更精准的声源定位,尤其适合大空间。
需要更多扬声器和专业调校。
典型用途:
高端家庭影院、虚拟现实(VR)音效。
3D音频(基于对象的声道)
技术代表:
杜比全景声(Dolby Atmos)
DTS:X
索尼360 Reality Audio
特点:
突破固定声道,通过元数据(Metadata)动态渲染声音位置(包括高度)。
支持扬声器阵列或耳机虚拟化。
典型用途:
影院、游戏(如《使命召唤》)、沉浸式音乐。
其他多声道格式
格式 声道数 应用场景 4.0(Quad) 4 70年代实验性环绕声 6.1 7 在5.1基础上增加后中置 9.1(Atmos) 10+ 顶部扬声器增强空间感
如何选择声道数?
需求 推荐声道 理由 语音/播客 Mono(1.0) 节省带宽,内容无方向需求 音乐聆听 Stereo(2.0) 兼容所有设备,自然声场 电影/游戏 5.1 或 7.1 沉浸式体验 专业制作(VR/Atmos) 3D音频(如Atmos) 动态音效定位
常见问题
Q1:立体声和双声道是一回事吗?
答案:是的,但“立体声”强调声场空间感,而“双声道”仅描述通道数量。
Q2:耳机能模拟5.1环绕声吗?
答案:可通过虚拟环绕技术(如Windows Sonic、Dolby Atmos for Headphones)实现,但效果弱于真实多扬声器系统。
Q3:音乐是否需要5.1声道?
答案:大部分音乐为立体声,但少数专辑(如摇滚现场)会发布5.1混音版(如DVD-Audio)。
总结
单声道:兼容性强,适合语音。
立体声:音乐的标准配置。
5.1/7.1:影视和游戏的沉浸式选择。
3D音频:未来趋势,灵活定位声源。
选择声道数时需考虑内容类型、播放设备和空间大小。普通用户优先选择立体声,影音爱好者可升级至5.1或Atmos系统。
左声道和右声道到底有什么区别?听起来明明是一模一样的?
左声道和右声道听起来 “一模一样”,通常是因为音频内容本身没有设计立体声分离效果,或者播放设备 / 场景弱化了声道差异。但从原理和功能上看,两者的区别主要体现在信号独立性、空间定位作用和立体声体验上,具体如下:
1. 信号独立性:传输不同的音频信息
左声道(L)和右声道(R)本质上是两条独立的音频信号通路,它们可以传输完全不同的声音内容:
- 例如在立体声音乐中,左声道可能侧重小提琴的细节,右声道可能突出钢琴的伴奏;
- 在电影中,左声道可能播放左侧环境音(如左侧车门关闭声),右声道播放右侧音效(如右侧人群喧闹声)。
如果音频本身是 “单声道”(左右声道信号完全相同),或者播放时强制合并为单声道,就会觉得两者听起来一样。2. 核心作用:构建空间感和定位
左声道和右声道的核心价值是模拟人类双耳听觉的空间差异,实现 “立体声” 效果:
- 人类的左右耳位置不同,接收到的声音在时间差(如左侧声源先到左耳)、强度差(如右侧声源右耳听起来更响)和音色差(声波绕射带来的细微变化)上存在差异,大脑通过这些差异判断声音的方位。
- 左、右声道分别对应左右耳的听觉信息,通过播放不同信号,让大脑 “误以为” 声音来自真实空间的不同位置。例如:
- 当左声道音量大于右声道时,会感觉声音偏左;
- 若左声道先发声、右声道延迟几毫秒,会感觉声音从左向右移动。
3. 场景差异:不同内容的声道设计
- 单声道内容:如老式收音机、部分语音广播,左右声道信号完全一致,此时听不出区别。
- 立体声内容:
- 音乐:乐器、人声在左右声道的分配不同(如主唱居中,吉他偏左,贝斯偏右),增强层次感;
- 电影 / 游戏:爆炸声、脚步声等音效随画面中物体的移动在左右声道切换,提升沉浸感;
- 环绕声系统(如 5.1 声道):左、右声道是基础,配合中置、环绕声道进一步扩展空间维度。
总结
左声道和右声道的区别不在物理结构(喇叭本身可能完全相同),而在传输的音频信号和功能定位上。当内容是立体声时,两者通过信号差异构建空间感;若内容是单声道或设备未正确解码立体声,就会感觉 “一模一样”。这也是为什么听立体声音乐时,用双声道耳机比单喇叭音箱更有 “身临其境” 的体验 —— 左右声道的差异被耳朵清晰捕捉到了。
音频码率
音频码率(Bitrate)是指单位时间内音频数据占用的比特数,通常以 kbps(千比特每秒) 为单位。它直接影响音频的音质和文件大小,是衡量数字音频效率的核心参数之一。
码率的基本概念
定义: 码率 = 每秒存储或传输的音频数据量(比特数)。 公式:
码率 (kbps)=采样率 (Hz)×位深度 (bit)×声道数/1000
例如:CD音质(44.1kHz/16bit/立体声)的无压缩码率为:
44100×16×2/1000=1411.2 kbps
关键影响:
码率越高 → 音质越好(细节保留更多),但文件体积越大。
码率越低 → 文件越小,但音质可能下降(高频丢失、压缩失真)。
常见音频码率范围
音频类型 码率范围 适用场景 电话语音 8~16 kbps 移动通信(如AMR-NB编码) 网络语音(VoIP) 24~64 kbps 微信语音、Zoom会议(Opus编码) 流媒体音乐 96~320 kbps Spotify(Ogg Vorbis)、Apple Music(AAC) CD音质(无损) 1411 kbps 未压缩的WAV/AIFF文件 高清音频(Hi-Res) 2000~9000 kbps 24bit/96kHz FLAC或DSD文件 更多待补充。
进一步理解音频码率
注意,上面说的是原始音频数据的码率,跟采样时的采样率、位深度以及通道数有关,决定了一段音频的最大码率值;码率究竟是什么呢?码率本质上是音频数据的密度!之后,我们可以对音频进行编码,数据的密度就会有所改变,此时,码率就会改变。
具体怎么理解音频数据的密度呢?
首先,音频原始数据都是采样来的,这个原始音频数据就有一段时间长度,这个时间对应的是实际时间长度,一般不通过剪辑的话就是固定不变的。单位时间内的数据量,就是码率,即数据的时间密度。
音频通过编码,就可以降低数据量,但是因为时间长度是不变的,所以单位时间的数据量就减少了,也就相应降低了码率,实际上,就是损失了音质。之后,解码时就要按照同样的码率去解码,要不然就会导致音频播放出现问题。
另外要注意,码率只对解码和播放阶段有影响,和音频数据传输的快慢无关!比如一个 128kbps 的 MP3 文件,无论用 U 盘拷贝、网络传输还是本地播放,其每秒钟的音频数据量始终是 128 千比特,不会因传输速度变化而改变。传输速度是 “动态变化的实时值”,而码率是 “静态的文件属性”,下载一个 10MB 的 128kbps 音频文件,若网络速度为 1MB/s,10 秒可完成;若网络速度降至 500KB/s,则需 20 秒完成,但文件的码率始终是 128kbps。
对于一个 128kbps 的 MP3 文件,通过1MB/s传输到播放器端,不会实时地按照这个传输速率来解码播放,而是会放到缓存里,然后按照音频的码率去解码和播放(通过定时器拿数据)。
播放时的 “码率” 与 “传输速度” 的关系
本地播放场景:
音频文件已存储在设备中,播放时从本地读取数据,传输速度(读取速度)通常远高于码率需求(如硬盘读取速度约 100MB/s,而音频码率最高约 1.5MB/s),因此不会出现传输瓶颈,码率固定不变。
流媒体播放场景:
音频数据通过网络实时传输,此时需满足 “传输速度≥码率” 才能流畅播放。
例:若音频码率为 128kbps(约 16KB/s),则网络传输速度需至少 16KB/s 才能保证不卡顿。若传输速度低于 16KB/s(如网络拥堵),播放器会因数据缓冲不足而暂停,但音频本身的码率仍为 128kbps(缓冲后继续按原码率播放)。
注意:部分流媒体平台会根据网络速度动态调整码率(如 YouTube 音频的自适应流媒体),但这是平台主动切换了不同码率的文件版本,而非改变了单个文件的码率。
常见误解:“传输快则码率高” 的错误根源
错误逻辑:认为 “传输速度快 = 单位时间传输的数据多 = 码率高”,本质是混淆了 “码率” 与 “传输速率” 的概念。
正确逻辑:
码率是音频文件的 “数据密度”,决定了文件每秒所需的最小传输速度(如 128kbps 文件至少需要 128kbps 的传输速度才能流畅播放)。
传输速度是实际的 “数据传输效率”,可以大于或等于码率,但无法改变文件本身的码率。
音频数据的播放并非 “传多快就播多快”
一、播放的本质:需严格遵循 “时间基准”,而非传输速度
音频的时间属性:音频是 “时序性媒体”,每个采样点对应固定的时间位置(如 44.1kHz 采样率下,第 44100 个采样点对应 1 秒)。若按传输速度随意播放,会导致:
- 时序错乱:比如传输速度忽快忽慢时,音频会出现 “加速 - 卡顿 - 加速” 的失真,完全破坏内容节奏(如音乐节奏混乱、语音语调变形)。
- 音画不同步:若音频与视频同步播放,传输速度波动会导致声画错位(如电影中人物说话时声音延迟或提前)。
类比理解:音频播放类似 “钟表走时”,必须按固定的时间刻度(如每秒 44100 个采样点)推进,而传输速度只是 “送钟表零件的速度”,零件送得快可提前缓存,但钟表仍按固有频率走动。
二、技术实现:播放依赖 “缓冲机制” 与 “时钟同步”
1. 缓冲机制:平滑传输波动的影响
工作原理:
播放器先将传输的数据存入 “缓冲区”(如内存中的一段存储区域),再按固定频率从缓冲区读取数据播放。
例:传输速度突然变快时,缓冲区会积累更多数据;传输速度变慢时,缓冲区已存储的数据可维持播放,避免卡顿。
关键作用:将 “动态传输速度” 转化为 “静态播放速度”。例如:
网络下载 128kbps 音频时,若瞬间传输速度达到 256kbps,缓冲区会暂时存满 2 秒的数据;随后传输速度降至 64kbps,缓冲区可继续提供 1 秒的数据,确保播放仍按 128kbps 的固定速度进行。
2. 时钟同步:锁定播放的时间基准
设备时钟的作用:
播放器通过设备的时钟(如 CPU 时钟、音频芯片时钟)生成固定的 “播放频率”(如 44.1kHz),严格按该频率读取音频数据。
例如:CD 播放器的晶振(时钟源)精度极高,确保每秒精确读取 44100 个采样点,不受数据读取速度影响。
同步技术(如 PTP、NTP):
在专业场景(如直播、多设备协同)中,需通过网络时间协议(NTP)或精确时间协议(PTP)统一多设备的时钟,避免因时钟偏差导致播放速度不一致。
简而言之:码率是 “内容的属性”,传输速度是 “环境的表现”,二者相互独立,传输速度的变化不会改变音频文件的码率。
将一首MP3音乐的码率从320kbps改到128kbps,发生了什么?
1. 码率转换的两种场景
升码率(如从 128kbps 到 320kbps):
- 本质:并非真正 “增加” 音频细节,而是在原数据基础上填充冗余信息(如补零),或通过算法 “模拟” 高频信号(效果有限)。
- 实际效果:文件体积变大,但音质无法超越原始低码率音频的上限(因原始编码已丢失细节),属于 “无效升码”。
降码率(从320kbps改到128kbps):
- 本质:通过压缩算法去除更多细节,文件变小,音质下降。
- 关键:若原始音频为无损格式,降码率至 320kbps 时仍能保留大部分听感细节,适合在音质与体积间平衡。
MP3 压缩基于 “人耳听觉掩蔽效应”:高码率(320kbps)时仅丢弃少量人耳不敏感的高频泛音(如 20kHz 以上超声波)和被强音掩盖的微弱信号;
降至 128kbps 后,压缩算法会进一步删除:
- 高频细节:16kHz 以上的声音(如三角铁、小提琴泛音)被大幅衰减,甚至切除至 15kHz 以下;
- 动态范围信息:弱音信号(如人声气音、乐器共鸣尾音)被压缩或丢弃,导致声音 “层次感” 下降。
2. 专业编辑中的码率调整原则
优先保留原始高码率文件:若需后期编辑(如混音、母带处理),应始终以无损或高码率格式为源文件,避免降码率导致的不可逆损失。
根据用途选择码率:
- 网络传播:选择 128-256kbps 的 MP3/AAC,兼顾音质与传输效率;
- 专业存档:使用无损格式(FLAC、WAV),保留所有原始数据;
- 车载音响:若设备支持,可使用 320kbps 或无损格式,提升听感。
3、典型场景与注意事项
适用场景
手机铃声制作(体积小且对音质要求低);
老旧设备播放(如早期 MP3 播放器仅支持低码率);
网络传输(如上传至短视频平台,减少加载时间)。
音质损失的临界点
128kbps 是 MP3 音质的 “分水岭”:高于此码率时,普通听众较难察觉明显失真;低于此值(如 64kbps),音质会断崖式下降。
不可逆性提醒
从 320kbps 降至 128kbps 后,丢失的高频和动态信息无法通过重新提高码率恢复(如转回 320kbps 时,音质不会回到原始水平,仅文件体积变大)。
简而言之,降码率的过程相当于 “选择性删除音频细节”—— 用音质换体积,适合对听觉体验要求不高的场景,但无法逆转或恢复原始音频的完整信息。
音频帧
音频帧(Audio Frame)是数字音频处理中的基础单位,指将连续的音频信号按固定时间间隔分割成的多个小段数据块。它的设计与音频编码、传输及存储逻辑紧密相关,以下从技术原理、应用场景等维度展开解析:
一、音频帧的技术定义与核心作用
(1)时域分割的物理意义
音频是随时间连续变化的模拟信号,数字化时需按固定频率采样(如 44.1kHz),而 “帧” 是将采样点按时间窗口分组的产物。
例:若帧长为 20ms,44.1kHz 采样率下每帧包含 44.1k × 0.02 = 882 个采样点。
(2)数据处理的基本单元
在编码(如 MP3、AAC)、解码、实时传输(如 VoIP)中,音频帧是算法处理的最小单位(如傅里叶变换、降噪、压缩等均以帧为单位执行)。
二、音频帧的关键参数与技术特性
(1)帧长(Frame Length)
典型值范围:10ms~100ms,由应用场景决定:
语音通信(如微信语音):10ms~30ms(低延迟优先);
音乐编码(如 MP3):20ms~50ms(兼顾音质与压缩效率)。
长短帧的权衡:
短帧:延迟低,但压缩效率差(每帧数据量小);
长帧:压缩效率高,但处理延迟增加(如 100ms 帧长会引入明显卡顿)。
(2)帧间隔(Frame Interval)
相邻帧的时间间隔,通常与帧长相等(如 20ms 帧长对应 20ms 间隔),确保信号连续性。
(3)帧结构(Frame Format)
包含 音频数据 和 元信息(如采样率、通道数、编码参数等),不同编码格式帧结构差异显著:
MP3 帧:包含头部(Header)和音频数据块,头部含比特率、采样率等信息;
PCM 帧:纯原始采样数据,无元信息(需外部指定格式)。
三、不同场景下的音频帧应用实例
(1)音频编码中的帧处理
MP3 编码流程:
将原始 PCM 音频分割为 576 采样点 / 帧(44.1kHz 下约 13ms);
对每帧执行傅里叶变换,转换为频域数据;
利用人耳听觉特性(如掩蔽效应)丢弃高频段无关数据,压缩后封装为 MP3 帧。
(2)实时音频传输(如 VoIP)
例:SIP 协议中,G.711 编码将音频按 20ms 分帧(每帧 160 个 16 位采样点,共 320 字节),添加 RTP 头部后打包传输,确保实时性与抗丢包性。
(3)音频编辑与处理
音频工作站(如 Audition)中,用户操作(如剪切、混音)的最小单位通常为帧,软件会显示帧边界便于精确编辑。
四、音频帧与相关概念的区别与联系
概念 定义与特性 与音频帧的关系 采样点 音频数字化时的单个幅度值(如 44.1kHz 采样率下每秒 44100 个点) 多个采样点组成一帧 音频包 网络传输中封装帧的数据包(如 RTP 包包含 1~ 多帧音频数据) 一包包含一帧或多帧 ** GOP(组帧)** 视频编码中连续帧的分组,与音频帧独立(但音视频同步时需对齐帧时序) 音频帧需与视频帧同步时间戳
五、帧处理对音频质量的影响
帧长与音质的关系:
长帧(如 50ms)可捕获更完整的信号特征,压缩后音质损失小(如 FLAC 无损编码常用长帧);
短帧(如 10ms)因数据量少,压缩时易丢失细节,适合对音质要求低的场景(如电话语音)。
帧重叠(Frame Overlap): 在某些编码(如 AAC)中,相邻帧会重叠 50%(如当前帧包含前一帧后 10ms 数据),减少分帧造成的 “断裂感”,提升音质平滑度。
核心总结
音频帧是数字音频的 “基础积木”,通过时域分割将连续信号转化为离散数据单元,便于编码压缩、实时传输和算法处理。其参数(帧长、结构、间隔)的选择直接影响音频的延迟、音质和传输效率,是理解音频数字化全流程的关键概念。
PCM
主要参考:
音频处理——音频处理的基本概念_1000hz音频采集-CSDN博客
PCM这个概念在多种场合都可能被用到。
首先,PCM是一种技术方法。
PCM(Pulse Code Modulation)脉冲编码调制是数字通信的编码方式之一,作用是将模拟信号转换为数字信号。在PCM 过程中,将输入的模拟信号进行采样、量化和编码,用二进制进行编码的数来代表模拟信号的幅度。其实就是ADC的一种实现原理。
ADC的核心工作原理本质上是PCM(脉冲编码调制)技术的实现,但具体实现方式可能因ADC类型和应用场景有所不同。
ADC与PCM的关系
(1) PCM是ADC的理论基础
PCM(脉冲编码调制)是模拟信号数字化的通用方法,包含三个关键步骤:
- 采样(Sampling):按固定时间间隔采集模拟信号值。
- 量化(Quantization):将采样值转为离散数字(如16bit)。
- 编码(Encoding):将数字值转换为二进制格式。
ADC的核心功能正是完成这一过程,因此可以说 ADC是PCM的硬件实现。
(2) ADC的输出本质是PCM数据
ADC输出的原始数据是 未压缩的数字信号序列,符合PCM的定义。
但ADC的输出格式可能需要调整(如并行转串行)才能匹配标准PCM接口(如I2S)。
不同类型ADC的PCM特性
(1) 音频专用ADC(直接输出PCM)
示例芯片:WM8960、CS5368、AK5552。
特点:
直接输出标准PCM格式(如I2S/TDM接口)。
内置抗混叠滤波器和采样率控制器,优化音频信号。
(2) 通用ADC(需后处理为PCM)
示例:SAR ADC(逐次逼近型)、ΔΣ ADC(Sigma-Delta)。
特点:
输出可能是并行数据或非标准格式(如12bit、18bit)。
需通过软件或硬件(如FPGA)转换为标准PCM(如16bit/44.1kHz)。
(3) 压缩型ADC(非纯PCM)
示例:蓝牙芯片的ADC(如Qualcomm CSR8675)。
特点:
内置DSP,ADC输出后直接压缩为SBC/AAC格式,跳过标准PCM阶段。
因为PCM在音频数据里体现得最广泛最明显,所以,音频数据通常都会跟PCM挂钩。
常见问题
Q1:所有ADC都用PCM吗?
答案:绝大多数ADC基于PCM原理,但:
DSD ADC输出1bit高速数据流(非PCM),需后续转换。
压缩ADC(如语音芯片)可能跳过PCM直接输出编码数据。
Q2:为什么音频ADC常用I2S接口?
答案:I2S是专为PCM数据设计的标准串行接口,可高效传输采样率、位深同步的音频数据。
Q3:手机录音的PCM数据如何生成?
流程: 麦克风 → 音频ADC(PCM输出) → 处理器 → 存储为WAV或压缩为MP3/AAC。
总结
ADC的核心技术是PCM,但输出形式可能需调整才能匹配标准PCM格式。
音频ADC通常直接输出PCM(如I2S),通用ADC需后处理。
例外:DSD ADC和压缩型ADC不直接输出PCM。
简单结论:
如果ADC用于音频且输出未压缩数字信号,则它一定使用PCM技术。
非音频ADC(如温度传感器)虽基于PCM原理,但通常不称其输出为“PCM数据”。
由此可见,PCM数据一般都是特指原始音频数据,未经压缩,音质无损但体积大,在这种场景下,PCM特指音频数据。
另外,我们还经常听到PCM接口这个说法。
PCM(Pulse Code Modulation,脉冲编码调制)接口是一种用于传输数字化音频信号的通信协议或硬件接口,广泛应用于音频设备、通信系统和数字信号处理(DSP)领域。它的核心功能是传输未经压缩的数字音频数据流。
PCM 接口的基本概念
PCM 接口传输的是原始音频采样数据,即通过以下参数描述的离散信号:
- 采样率(Sample Rate):每秒采集音频信号的次数(如 44.1kHz、48kHz)。
- 位深度(Bit Depth):每个采样点的量化精度(如 16bit、24bit)。
- 声道数(Channels):单声道(Mono)、立体声(Stereo)或多声道(如 5.1、7.1)。
PCM 数据的特点
- 未压缩:直接传输量化后的数字信号,音质无损。
- 低延迟:无需编解码,适合实时音频传输(如录音、通话)。
- 标准化:几乎所有数字音频设备都支持 PCM 格式。
PCM 接口的类型
PCM 接口可以通过多种物理或协议形式实现,主要包括:
(1) 硬件接口(常见于音频设备)
接口类型 描述 I2S 集成电路内置音频总线(Inter-IC Sound),用于芯片间传输 PCM 数据(如 DAC/ADC)。 TDM(Time-Division Multiplexing) 支持多声道 PCM 传输(如 8 通道音频)。 PCM 同步串口 某些 DSP 或编解码芯片的专用接口(如 TI/ADI 芯片)。 S/PDIF(索尼/飞利浦数字接口) 通过同轴或光纤传输 PCM 数据(家用 Hi-Fi 常见)。 (2) 软件/协议接口
- 音频驱动层(如 ALSA、Core Audio):操作系统通过 PCM 格式与声卡通信。
- 网络传输(如 VoIP):未压缩的 PCM 数据可通过 RTP/UDP 传输(如 G.711 编码)。
PCM 接口的典型应用
(1) 音频设备
- ADC/DAC 芯片:将模拟信号转换为 PCM 数据(或反向转换)。
- 数字音频工作站(DAW):录音时麦克风信号通过 PCM 接口输入计算机。
- Hi-Fi 播放器:解码器通过 I2S 接口将 PCM 数据传输给 DAC 芯片。
(2) 通信系统
- 电话系统:传统电话使用 8kHz 采样率的 PCM(G.711 编码)。
- 蓝牙音频(SBC 编码前):原始音频先以 PCM 格式传输,再压缩为 SBC/AAC。
- 车载音频:数字功放通过 PCM 接口接收多声道信号。
(3) 计算机音频
声卡与 CPU 通信:操作系统通过 PCM 格式管理音频输入/输出(如 WAV 文件播放)。
PCM vs. 其他音频接口
对比项 PCM 接口 其他接口(如 PDM、DSD) 数据格式 多比特量化(如 16/24bit) 1bit 位流(PDM/DSD) 音质 无损(原始采样) 依赖调制方式(DSD 适合高频细节) 延迟 低(直接传输) 可能需转换(如 PDM 转 PCM) 典型应用 录音、专业音频、通信 高端 Hi-Fi(SACD)、MEMS 麦克风 ✅ PDM(Pulse Density Modulation):常见于数字麦克风(如智能手机麦克风),需通过滤波器转换为 PCM。
常见问题
Q1: PCM 和 WAV 的关系?
PCM 是原始音频数据格式,WAV 是 PCM 的封装格式(加文件头)。
例如:CD 音质的 WAV = 44.1kHz/16bit 的 PCM 数据 + WAV 文件头。
Q2: 为什么蓝牙耳机不直接传输 PCM?
PCM 数据量太大(如 44.1kHz/16bit 立体声 ≈ 1.4Mbps),蓝牙带宽不足,需压缩为 SBC/AAC/LDAC。
Q3: PCM 接口需要时钟信号吗?
是的!PCM 依赖同步时钟(BCLK)和帧同步信号(LRCLK)(如 I2S 接口)。
总结
PCM 接口是数字音频的“通用语言”,传输未经压缩的采样数据。
硬件接口(如 I2S、TDM)用于芯片级通信,软件接口用于系统级音频处理。
几乎所有音频设备(从手机到专业录音棚)都依赖 PCM 格式作为基础。
如果需要具体场景的接口选型(如选择 I2S 还是 TDM),可以进一步探讨!
音频格式
音频格式可以分为 无损格式 和 有损格式,以及不同的 封装格式。以下是常见的音频格式分类和介绍:
一、无损音频格式(无压缩或无损压缩)
PCM(脉冲编码调制)
- 特点:原始音频数据,未压缩,音质最好,但文件极大。
- 常见封装:WAV、AIFF、CDDA(CD音轨)。
- 用途:专业录音、音频编辑、CD音轨。
WAV(Waveform Audio File Format)
- 特点:微软开发,通常存储PCM数据(未压缩),但也可支持压缩(如ADPCM)。
- 用途:Windows平台、专业音频制作。
AIFF(Audio Interchange File Format)
- 特点:苹果开发,类似WAV,默认PCM,支持AIFF-C(压缩格式,但极少用)。
- 用途:Mac系统、音乐制作(如Logic Pro)。
FLAC(Free Lossless Audio Codec)
- 特点:开源无损压缩,体积比WAV小约50%,音质相同。
- 用途:高保真音乐存储、流媒体(如Tidal HiFi)。
ALAC(Apple Lossless Audio Codec)
- 特点:苹果的无损压缩格式,类似FLAC,但苹果生态专用(.m4a封装)。
- 用途:iTunes、AirPlay无损传输。
DSD(Direct Stream Digital)
- 特点:超高采样率(如2.8MHz/5.6MHz),用于SACD(超级音频CD)。
- 用途:高端Hi-Fi设备。
二、有损音频格式(压缩后音质降低)
MP3(MPEG-1 Audio Layer III)
- 特点:最流行的有损格式,兼容性极强,但高频细节丢失。
- 用途:音乐下载、流媒体、移动设备。
AAC(Advanced Audio Coding)
- 特点:MP3的升级版,效率更高(相同比特率下音质更好)。
- 封装:.m4a(苹果常用)、.mp4(视频音频流)。
- 用途:iTunes、YouTube、Spotify(部分)。
OGG Vorbis
- 特点:开源有损格式,音质优于MP3,但兼容性较差。
- 用途:游戏音频(如Steam)、早期Spotify。
Opus
- 特点:低延迟,适合实时语音和流媒体,音质优于AAC(低比特率下)。
- 用途:网络通话(Discord、WhatsApp)、WebRTC。
WMA(Windows Media Audio)
- 特点:微软开发,有损(WMA)和无损(WMA Lossless)版本。
- 用途:旧版Windows Media Player。
三、其他特殊音频格式
MIDI(.mid)
- 特点:存储音符指令而非音频数据,文件极小,依赖合成器播放。
- 用途:电子音乐制作、游戏背景音乐。
DSD(.dsf/.dff)
- 特点:1bit超高采样率音频,用于SACD。
- 用途:高端Hi-Fi播放。
MQA(Master Quality Authenticated)
- 特点:折叠式无损压缩,需专用解码器展开。
- 用途:Tidal Masters高解析度流媒体。
四、格式对比表
格式 类型 音质 文件大小 主要用途 PCM 无损原始 ★★★★★ 极大 专业录音、CD WAV 无损封装 ★★★★★ 大 Windows音频编辑 FLAC 无损压缩 ★★★★★ 中 高保真音乐存档 ALAC 无损压缩 ★★★★★ 中 苹果设备无损 MP3 有损压缩 ★★☆(128kbps) 小 通用音乐格式 AAC 有损压缩 ★★★(同码率优于MP3) 小 流媒体(Apple/YouTube) Opus 有损压缩 ★★★★(低延迟) 极小 网络通话、实时流 五、如何选择合适的音频格式?
- 音乐制作/录音:WAV/AIFF(PCM)或FLAC/ALAC(无损压缩)。
- 高音质播放:FLAC、ALAC、DSD(Hi-Fi设备)。
- 日常听歌:MP3(兼容性强)、AAC(更高效)。
- 网络传输/语音:Opus(低延迟)、AAC(通用流媒体)。
如果有具体需求(如设备兼容性、音质优先级),可以进一步推荐最佳格式!
音频压缩
关于音频的封装格式和压缩
一、音频封装格式(Container Format)
封装格式是音频数据的“包装盒”,它定义了如何存储音频流(可能还有视频、字幕等元数据),但不直接决定音频的编码方式。
常见的封装格式包括:
- WAV、AIFF(无损,通常封装PCM)
- MP3(既是编码格式也是封装格式)
- FLAC(无损压缩封装)
- OGG(可封装Vorbis、Opus等编码)
- MP4/M4A(封装AAC、ALAC等)
- AAC(通常以
.m4a或.mp4封装)封装格式的作用:
- 存储元数据:如采样率、位深度、声道数、作者信息等。
- 支持多轨道:例如MKV可封装多语言音频、字幕。
- 兼容性:不同设备/软件支持的封装格式不同(如苹果设备偏好MP4/M4A)。
📌 示例:
同一份PCM数据,可以封装为
.wav(加文件头)或.aiff(苹果格式)。MP3文件既是压缩编码,也是封装格式(不含视频等额外数据)。
二、音频压缩(编码方式)
压缩的目的是减小文件体积,分为无损压缩和有损压缩:
无损压缩
原理:通过算法消除冗余数据,但可完全还原原始音频。
格式:FLAC、ALAC(Apple Lossless)、WAV(PCM未压缩)、APE。
特点:
音质 = 原始PCM,文件体积约为PCM的50%~60%。
适合专业音频编辑、音乐存档。
有损压缩
原理:利用心理声学模型,剔除人耳不敏感的频段(如高频弱信号)。
格式:MP3、AAC、OGG Vorbis、Opus。
特点:
文件体积大幅减小(MP3约为PCM的10%~20%)。
音质损失不可逆,高频细节可能丢失。
适合流媒体、移动设备。
三、常见问题
为什么WAV文件比FLAC大?
WAV直接存储PCM数据,FLAC通过无损压缩算法减小体积(类似ZIP压缩)。
MP3和AAC哪个音质更好?
相同比特率下,AAC音质通常优于MP3(AAC是MP3的升级版)。
转换格式会损失音质吗?
无损→无损(如WAV→FLAC):无损失。
有损→有损(如MP3→AAC):音质进一步下降。
无损→有损(如WAV→MP3):永久丢失部分数据。
四、总结
封装格式是“容器”,决定文件结构和元数据。
压缩编码是“内容”,决定音质和文件大小。
无损(FLAC/WAV)适合专业用途,有损(MP3/AAC)适合日常使用。
如果需要具体场景的格式推荐(如音乐制作、语音录制),可以进一步探讨!
wav和aiff有压缩吗?
WAV 和 AIFF 文件本身是封装格式,它们通常不压缩音频数据(即默认使用无损的PCM编码),但也可以包含某些压缩格式。以下是详细对比:
WAV(Waveform Audio File Format)
默认情况:
存储未压缩的PCM音频数据(无损,文件体积大)。
例如:CD音质的WAV = 44.1kHz采样率 × 16bit位深度 × 立体声 ≈ 10MB/分钟。
支持压缩的情况:
WAV的扩展性很强,可以通过
编码器(Codec)存储压缩音频,例如:ADPCM(有损压缩,用于早期语音和游戏音频)。
MP3、GSM、G.711(需特定编码器支持,但兼容性差)。
这类压缩的WAV文件较少见,可能被某些专业设备或软件使用。
✅ 如何判断WAV是否压缩? 用音频工具(如Audacity、FFmpeg)查看文件属性,若编码格式显示
PCM则为未压缩,显示ADPCM、MP3等则为压缩。
AIFF(Audio Interchange File Format)
默认情况:
类似WAV,AIFF通常存储未压缩的PCM数据(苹果生态常用)。
音质与WAV(PCM)完全相同,但文件结构不同(基于苹果的格式标准)。
支持压缩的情况:
AIFF的变种格式AIFF-C(Compressed) 支持压缩编码,例如:
MACE(Macintosh Audio Compression/Expansion,有损压缩)。
ALAC(Apple Lossless,无损压缩,但现代ALAC通常直接封装为
.m4a)。实际使用中,AIFF-C非常罕见,主流AIFF文件均为PCM。
WAV vs. AIFF 对比
特性 WAV AIFF 默认编码 PCM(未压缩) PCM(未压缩) 支持压缩 是(ADPCM、MP3等,但少见) 是(AIFF-C,极罕见) 文件头结构 微软/IBM标准 苹果标准 元数据支持 有限(依赖扩展字段) 支持更多标签(如专辑封面) 主要用途 Windows、专业音频 Mac、音乐制作
为什么通常认为WAV/AIFF是无损的?
因为它们默认使用PCM编码,而PCM是原始音频数据,未经压缩。
即使支持压缩,实际应用中几乎不会用WAV/AIFF存储MP3等有损格式(直接存为MP3/AAC更高效)。
如何确保WAV/AIFF是无损的?
检查文件的编码格式(通过播放器或工具如
MediaInfo):未压缩:显示
PCM、Linear PCM。压缩:显示
ADPCM、MP3等。导出时选择明确的无损选项(如DAW中导出为
WAV (PCM)或AIFF (PCM))。
总结
WAV和AIFF通常是无损的(默认PCM),但技术上支持某些压缩格式(实际极少使用)。
如果需要无损音频,直接使用WAV/AIFF(PCM)或FLAC/ALAC(压缩无损)。
如果需要有损压缩,优先选MP3、AAC等专用格式。
如果有具体的使用场景(如音乐制作、设备兼容性),可以进一步探讨最佳选择!
音量表和音量dB
“dB” 是 分贝(Decibel) 的缩写,是衡量声音强度(音量)、信号功率等物理量的 相对单位,而非绝对单位。它的核心作用是将人类听觉或物理设备能感知的 “巨大动态范围”(比如从蚊子叫到飞机引擎声)压缩成更易理解和计算的数值,本质是对物理量比值的对数换算。
要理解音量相关的 dB,关键要先分清两个最常用的场景:dB SPL(衡量实际听到的声音大小)和 dB FS(衡量音频信号的强弱,常见于设备设置)。
1. 最常见:dB SPL(声压级,Sound Pressure Level)
这是描述 “人耳实际听到的声音响度” 的单位,也是日常说 “音量多少 dB” 时默认的场景。它以 人类能听到的最小声音(听觉阈值,约 20 微帕斯卡的声压) 为基准,计算实际声音与这个基准的相对强度。
关键数值参考(帮你建立直观认知):
场景 音量(dB SPL) 人耳感受 影响 绝对安静(听觉阈值) 0 dB 刚能听到,几乎察觉不到 无 耳语(1 米内) 20 - 30 dB 轻柔,不打扰 无 正常对话(1 米内) 60 - 70 dB 清晰,舒适 无 闹市 / 吸尘器 80 - 90 dB 较吵,需提高声音对话 长期暴露可能轻微不适 摇滚现场 / 电锯 110 - 120 dB 刺耳,耳朵有压迫感 短期暴露可能耳鸣,长期致听力损伤 飞机引擎(10 米内) 140 dB 剧痛,难以忍受 瞬间可能致永久性听力损伤 注意:dB SPL 是 “对数关系”,不是线性的!
比如 “60 dB 比 30 dB 响多少?”—— 不是 2 倍,而是 1000 倍(因为每增加 10 dB,声音的实际能量(声压平方)增加 10 倍;30 dB 到 60 dB 差 30 dB,即 10³=1000 倍)。
这也符合人耳的感知特点:人类对 “小声的变化” 更敏感,对 “大声的变化” 不敏感(比如在安静房间里,10 dB 的变化很明显;在闹市中,20 dB 的变化可能才察觉)。2. 设备里常见:dB FS(满刻度分贝,Full Scale)
这是 音频设备(如音箱、耳机、录音软件)中描述 “信号强度” 的单位,基准是 “设备能输出的最大信号(满刻度,Full Scale)”。
- 0 dB FS:设备能输出的 最大信号强度(此时声音最大,再大就会 “失真”,出现杂音);
- 负数 dB FS(如 -10 dB FS、-20 dB FS):信号强度低于最大值,数值越小(负得越多),音量越轻。
比如你在手机音量条调小,本质就是把音频信号从 “接近 0 dB FS” 往 “-20 dB FS”“-30 dB FS” 等更低数值调整。
总结:dB 的核心特点
- 相对单位:必须有一个 “基准”(dB SPL 基准是听觉阈值,dB FS 基准是设备最大信号),单独说 “50 dB” 没意义,要结合场景;
- 对数换算:压缩了巨大的物理量范围,让数值更易使用;
- 场景区分:日常听声音看 dB SPL,调设备音量 / 处理音频看 dB FS。
看下这组dB FS音量表
-50.000000dB = 51 -49.500000dB = 54 -49.000000dB = 58 -48.500000dB = 61 -48.000000dB = 65 -47.500000dB = 69 -47.000000dB = 73 -46.500000dB = 77 -46.000000dB = 82 -45.500000dB = 86 -45.000000dB = 92 -44.500000dB = 97 -44.000000dB = 103 -43.500000dB = 109 -43.000000dB = 115 -42.500000dB = 122 -42.000000dB = 130 -41.500000dB = 137 -41.000000dB = 146 -40.500000dB = 154 -40.000000dB = 163 -39.500000dB = 173 -39.000000dB = 183 -38.500000dB = 194 -38.000000dB = 206 -37.500000dB = 218 -37.000000dB = 231 -36.500000dB = 245 -36.000000dB = 259 -35.500000dB = 275 -35.000000dB = 291 -34.500000dB = 308 -34.000000dB = 326 -33.500000dB = 346 -33.000000dB = 366 -32.500000dB = 388 -32.000000dB = 411 -31.500000dB = 435 -31.000000dB = 461 -30.500000dB = 489 -30.000000dB = 518 -29.500000dB = 548 -29.000000dB = 581 -28.500000dB = 615 -28.000000dB = 652 -27.500000dB = 690 -27.000000dB = 731 -26.500000dB = 775 -26.000000dB = 821 -25.500000dB = 869 -25.000000dB = 921 -24.500000dB = 975 -24.000000dB = 1033 -23.500000dB = 1095 -23.000000dB = 1159 -22.500000dB = 1228 -22.000000dB = 1301 -21.500000dB = 1378 -21.000000dB = 1460 -20.500000dB = 1546 -20.000000dB = 1638 -19.500000dB = 1735 -19.000000dB = 1838 -18.500000dB = 1947 -18.000000dB = 2062 -17.500000dB = 2184 -17.000000dB = 2314 -16.500000dB = 2451 -16.000000dB = 2596 -15.500000dB = 2750 -15.000000dB = 2913 -14.500000dB = 3086 -14.000000dB = 3269 -13.500000dB = 3462 -13.000000dB = 3667 -12.500000dB = 3885 -12.000000dB = 4115 -11.500000dB = 4359 -11.000000dB = 4617 -10.500000dB = 4891 -10.000000dB = 5181 -9.500000dB = 5488 -9.000000dB = 5813 -8.500000dB = 6157 -8.000000dB = 6522 -7.500000dB = 6909 -7.000000dB = 7318 -6.500000dB = 7752 -6.000000dB = 8211 -5.500000dB = 8698 -5.000000dB = 9213 -4.500000dB = 9759 -4.000000dB = 10337 -3.500000dB = 10950 -3.000000dB = 11598 -2.500000dB = 12286 -2.000000dB = 13014 -1.500000dB = 13785 -1.000000dB = 14602 -0.500000dB = 15467 0.000000dB = 16384你提供的是一组 “dB(分贝)值” 与 “线性数值” 的对应关系表,结合数值特征(尤其是最终
0.000000dB = 16384),可以明确这是 音频领域中 “dB FS(满刻度分贝)” 与 “音频采样量化值” 的转换关系——16384 是 15 位二进制数的 “半满刻度值”(2¹⁴ = 16384),常见于 16 位音频设备的信号量化场景。一、核心逻辑:dB FS 与线性量化值的转换原理
dB FS 是音频设备中 “信号强度相对于满刻度(最大信号)的分贝值”,其本质是 对数运算;而右侧的数值(51、54、…、16384)是 线性的音频采样量化值(即设备将模拟声音信号转换成数字时的 “数值表示”)。两者的转换公式是理解这张表的关键:
1. 量化值 → dB FS 的计算公式
对于单极性信号(仅正数值,常见于某些音频设备的内部信号处理),转换公式为:
dB FS = 20 × log₁₀(量化值 / 满刻度量化值)
- 满刻度量化值:这里是 16384(对应表中
0.000000dB,即 “信号达到最大强度”);- 20×log₁₀(...):因为 dB FS 描述的是 “电压 / 声压类物理量”(与幅度相关),这类物理量的分贝换算需用 20×log₁₀(功率类物理量用 10×log₁₀)。
2. 验证:用表中数据反向推导
以表中
0.000000dB = 16384为例:
代入公式 →dB FS = 20 × log₁₀(16384 / 16384) = 20 × log₁₀(1) = 0 dB,完全匹配。再以
-10.000000dB = 5181为例:
计算20 × log₁₀(5181 / 16384) ≈ 20 × log₁₀(0.316) ≈ 20 × (-0.5) = -10 dB,也与表中数据一致。二、表格的关键特征与应用场景
1. 数值变化规律:对数关系的直观体现
- dB FS 每增加 0.5 dB(从 -50 dB 逐步接近 0 dB),右侧的量化值非线性增长—— 前期增长慢(-50 dB 时仅 51),后期增长快(-0.5 dB 时已达 15467,接近满刻度 16384)。
- 这正是对数运算的特点:压缩 “小信号区间” 的数值跨度、放大 “大信号区间” 的差异,与音频设备 “对小信号敏感、对大信号需精准控制失真” 的需求完全匹配。
2. 典型应用场景
这张表本质是 “音频数字信号强度” 的 “对数 - 线性” 对照查询表,常见于以下场景:
- 音频设备固件开发:比如耳机、音箱的音量控制模块,需将用户调节的 “线性音量等级”(如旋钮刻度)转换为 dB FS,再映射到对应的量化值,确保音量变化符合人耳听觉感知(对数特性);
- 录音 / 混音软件:显示音频波形的 “分贝刻度” 时,需通过这类表将原始采样量化值转换为 dB FS,让用户直观看到信号强度是否接近满刻度(避免失真);
- ADC/DAC 芯片配置:模拟信号(如麦克风输入)经 ADC 转换为数字量化值后,需通过此表换算成 dB FS,判断信号是否过载或过弱。
三、关键结论
这张表不是 “通用 dB 换算表”,而是 “16 位音频设备中,dB FS(满刻度分贝)与单极性量化值的专用对应表”:
- 满刻度(0 dB FS)对应量化值 16384;
- 数值越小(如 -50 dB FS),对应量化值越小,代表音频信号越弱;
- 所有数值均遵循 “dB FS = 20×log₁₀(量化值 / 16384)” 的转换逻辑,是音频数字信号处理的基础数据参考。
再来看看这组dB SPL音量表
0db 34db 40db 45db 50db 54db 58db 61db 64db 67db 70db 72db 74db 76db 78db 79db 80db我们实际听的时候,或者测量分贝大小的时候,一般都是用的dB SPL,那么,实际在音箱等设备的DAC中要写入的dB FS量化值是多少呢?这个没有统一的公式,先明确两个参数的基准关联—— 二者本质描述不同物理量(前者是声学压力,后者是数字信号幅度),没有通用公式,必须结合具体设备的 “声学 - 电学转换特性” 才能确定。
实际中,需要实测,不断调整量化值,然后测试是否对应相应的dB SPL声音大小。
更多补充
音频EQ是什么
音频EQ(Equalizer,均衡器) 是一种用于调节音频信号中不同频率成分强度的工具或设备,通过增强(Boost)或衰减(Cut)特定频段的音量,来优化音质或适应不同的听音需求。
EQ的作用
改善音质:弥补扬声器或耳机的频响缺陷,使声音更均衡。
适应听音偏好:如增强低音(Bass)或突出人声(Vocal)。
修正环境问题:减少房间共振或耳机佩戴漏音的影响。
专业音频处理:音乐制作中用于混音、消除噪音、分离乐器等。
EQ的核心参数
(1) 频段(Frequency Band)
音频频谱通常分为几个关键频段:
频段名称 频率范围 影响的声音特性 低频(Sub-Bass) 20Hz - 60Hz 超低音(如雷声、电子鼓) 低频(Bass) 60Hz - 250Hz 鼓、贝斯、低音厚重感 中低频(Low-Mid) 250Hz - 500Hz 人声厚度、部分乐器基音 中频(Mid) 500Hz - 2kHz 人声、主乐器清晰度 中高频(Upper-Mid) 2kHz - 4kHz 人声齿音、乐器细节 高频(Presence) 4kHz - 6kHz 明亮度、临场感 超高频(Brilliance) 6kHz - 20kHz 空气感、镲片、细节 (2) 增益(Gain)
- 提升(+dB):增强某频段音量(如增强Bass)。
- 衰减(-dB):降低某频段音量(如减少刺耳的高频)。
(3) Q值(带宽)
- Q值高:影响较窄的频段(精确调整)。
- Q值低:影响较宽的频段(平滑调整)。
EQ的常见类型
(1) 图形均衡器(Graphic EQ)
通过滑块直观调节固定频段(如5段、10段、31段EQ)。
适用场景:消费级音响、耳机APP(如手机音乐播放器)。
(2) 参数均衡器(Parametric EQ)
可自由调节频点、增益和Q值,更精准。
适用场景:专业录音、混音(如DAW软件中的EQ插件)。
(3) 半参数均衡器(Semi-Parametric EQ)
固定频点,但可调增益和Q值(折中方案)。
(4) 动态均衡器(Dynamic EQ)
根据输入信号自动调整增益(如人声自动避让背景音乐)。
常见EQ调节示例
需求 调节方式 增强低音 提升60Hz - 150Hz(Bass) 人声更清晰 提升1kHz - 3kHz(Mid),衰减200Hz - 500Hz(减少浑浊感) 减少刺耳感 衰减4kHz - 6kHz(降低齿音) 提升通透感 轻微提升10kHz以上(空气感) 消除嗡嗡声 衰减200Hz - 400Hz(减少房间共振)
EQ的应用场景
- 音乐播放:手机/播放器的EQ预设(如“流行”、“摇滚”)。
- 耳机调音:补偿频响缺陷(如索尼Headphones APP)。
- 录音混音:平衡乐器、消除噪音(如Adobe Audition、FabFilter Pro-Q)。
- 车载音响:优化车内声学环境。
- 直播/K歌:美化人声,降低环境噪音。
注意事项
- 过度调节可能失真:大幅提升某频段可能导致爆音或音质劣化。
- 不同设备效果不同:耳机、音箱的频响曲线影响EQ效果。
- 参考标准曲线:如哈曼曲线(Harman Target)是耳机调音的常见参考。
总结
EQ是调整音频频率分布的工具,合理使用可以优化听感,但需根据设备和需求灵活调节。专业音频工作者会结合频谱分析仪(如REW)进行精确调整,而普通用户可直接使用预设或简单微调。
音频Hi-Fi是什么
Hi-Fi(High-Fidelity,高保真) 是指音频系统能够尽可能真实、无失真地还原原始声音,提供接近录音现场的听音体验。它强调高音质、低失真、宽频响,与普通消费级音频设备(如手机外放、廉价耳机)形成鲜明对比。
Hi-Fi 的核心标准
衡量一个音频系统是否达到Hi-Fi级别,通常参考以下几个关键指标:
参数 Hi-Fi 标准 普通音频设备 频响范围 20Hz - 20kHz(±3dB内) 可能缺失极低频/高频 信噪比(SNR) ≥100dB(越高背景越干净) 70-90dB(可能有底噪) 总谐波失真(THD) <0.1%(越低音质越纯净) 可能>1%(声音发糊) 分离度 >70dB(声道隔离度高) 可能<50dB(声场混乱) 采样率/位深 ≥24bit/96kHz(高解析音频) 16bit/44.1kHz(CD标准)
Hi-Fi 系统的关键组成部分
一套完整的Hi-Fi音频系统通常包括以下组件:
(1) 音源(Source)
数字音源:
无损格式(FLAC、WAV、DSD)。
高解析流媒体(Tidal、Qobuz)。
模拟音源:黑胶唱片、磁带(需高质量唱放/磁头放大)。
(2) 数字模拟转换器(DAC)
将数字信号转为模拟信号,决定音质基础。
代表芯片:ESS Sabre ES9038PRO、AKM AK4499EX、Burr-Brown PCM1794。
(3) 放大器(AMP)
耳放(Headphone AMP):驱动高阻抗耳机(如300Ω的森海塞尔HD800)。
功放(Power AMP):推动音箱(如Class A/B或Class D放大)。
(4) 耳机/音箱
耳机:
开放式(声场宽,如拜雅DT 1990 Pro)。
封闭式(隔音好,如索尼MDR-Z1R)。
音箱:
书架箱(如KEF LS50 Meta)。
落地箱(如B&W 800系列)。
(5) 线材与供电
线材:高品质模拟信号线(如OCC铜)、数字线(如USB隔离)。
电源:线性电源(低噪声)比开关电源更纯净。
Hi-Fi 的常见流派
不同用户对Hi-Fi的追求方向不同,主要分为几类:
流派 特点 典型设备 监听派 追求绝对真实,无音染 拜雅DT 880 Pro、真力监听音箱 音乐味派 强调“好听”,适当音染 森海塞尔HD650、胆机(电子管) 解析派 极致细节,高频延伸 索尼IER-Z1R、ESS DAC芯片 低频控 强劲低音但保持清晰 Fostex TH900、低音炮系统
Hi-Fi vs 消费级音频的区别
对比项 Hi-Fi 系统 普通音频设备 音质 高解析、低失真、动态范围大 压缩、失真明显 价格 数千元到数十万元 几十元到千元 适用场景 专注欣赏音乐 日常通话、背景音乐 用户群体 发烧友、音乐制作人 普通消费者
如何入门Hi-Fi?
(1) 从入门设备开始
耳机:森海塞尔HD560S、飞傲FH3。
DAC/耳放:拓品DX3 Pro+、iFi Zen DAC。
音源:本地FLAC文件或Tidal Masters。
(2) 避免常见误区
盲目堆料:高价设备不一定适合你的听音偏好。
忽视音源:MP3文件在Hi-Fi系统上会暴露缺陷。
过度追求参数:听感比数据更重要。
(3) 进阶方向
试听对比:耳机店体验不同风格设备。
学习调音:EQ、线材、供电的优化。
升级路径:
手机直推 → 便携DAC耳放 → 台式系统 → 分体式Hi-End
Hi-Fi 的未来趋势
无线Hi-Fi:LDAC、aptX Lossless等无损蓝牙编码普及。
空间音频:苹果AirPods Max、索尼360 Reality Audio。
AI音质增强:如DSP算法补偿耳机频响。
总结
Hi-Fi的本质是追求极致音质,但并非越贵越好,关键是找到适合自己听音风格的系统。如果你是新手,可以从一副好耳机+入门DAC开始,逐步探索高保真音乐的乐趣!
什么是麦克风阵列
麦克风阵列是由多个麦克风按特定几何排列组成的系统,通过声学信号处理算法(如波束成形、声源定位)实现以下核心功能:
- 定向拾音(增强目标方向的声音)
- 噪声抑制(降低环境干扰)
- 声源定位(判断说话人方位)
- 远场语音捕获(3~5米清晰拾音)
麦克风阵列的组成与原理
(1) 硬件组成
麦克风单元:通常使用数字麦克风(如MEMS麦克风),支持PDM/I2S输出。
排列方式:
- 线性阵列(2~4个麦克风,适合单向拾音)
- 环形阵列(4~8个麦克风,支持360°拾音)
- 立体声阵列(2个麦克风,用于左右声道分离)
主控芯片:需带DSP或NPU(如瑞芯微RK3308、高通QCC5141)。
(2) 核心算法
技术 作用 典型算法 波束成形(Beamforming) 增强特定方向的声源,抑制其他方向噪声 MVDR、GSC 声源定位(DOA) 计算声音到达角度(如±30°) GCC-PHAT、SRP-PHAT 回声消除(AEC) 消除设备自身扬声器的回声 NLMS、Kalman滤波 降噪(ANS) 抑制背景噪声(如风扇声、键盘声) Spectral Subtraction
麦克风阵列的常见类型
(1) 线性阵列(2~4麦克风)
特点:成本低,适合单向拾音(如智能音箱正面)。
应用:电视语音遥控器、车载中控。
示例:
Mic1 —— Mic2 —— Mic3 (间距2~4cm)
(2) 环形阵列(4~8麦克风)
特点:360°全向拾音,支持声源跟踪。
应用:智能音箱(如Amazon Echo)、会议系统。
示例:
Mic1 Mic4 Mic2 Mic3
(3) 远场阵列(6+麦克风)
特点:5米内高清晰度拾音,抗混响能力强。
应用:智能家居中控、视频会议设备。
麦克风阵列的关键技术
(1) 波束成形(Beamforming)
原理:通过调整各麦克风信号的相位和幅度,形成“定向拾音波束”。
效果:
信噪比(SNR)提升10~20dB。
示例:在嘈杂环境中清晰捕获用户指令。
(2) 声源定位(DOA)
实现方式:
计算声音到达不同麦克风的时间差(TDOA)。
通过几何关系反推声源角度。
应用:
机器人头部转向声源方向。
会议系统自动跟踪发言人。
(3) 多通道回声消除(AEC)
挑战:每个麦克风接收的回声路径不同,需独立处理。
方案:自适应滤波(如NLMS) + 非线性处理。
典型应用场景
场景 阵列类型 技术要求 智能音箱 环形4~6麦 远场拾音+音乐播放时回声消除 车载语音 线性2~4麦 抗风噪+引擎噪声抑制 视频会议 环形6~8麦 声源定位+发言人跟踪 工业控制 线性2麦 高可靠性+防水防尘设计
开发与选型建议
(1) 硬件选型
低成本方案:
主控:ESP32(支持PDM麦克风,Wi-Fi/BLE)。
麦克风:INMP441(数字输出,信噪比65dB)。
高性能方案:
主控:瑞芯微RK3308(内置8通道音频DSP)。
麦克风:Knowles SPH0645(信噪比72dB)。
(2) 算法实现
开源库:
WebRTC(AEC/ANS/VAD)
GCC-PHAT(声源定位)
商业方案:
科大讯飞麦克风阵列SDK(中文优化)。
思必驰(针对智能家居场景)。
(3) 调试工具
REW(Room EQ Wizard):分析麦克风频响曲线。
MATLAB:仿真波束成形算法效果。
常见问题
Q1:单麦克风 vs 阵列的区别?
单麦克风:无法区分噪声和有用信号,远场效果差。
阵列:通过空间滤波抑制噪声,提升信噪比。
Q2:麦克风间距如何设计?
原则:间距 ≥ 目标频率波长的一半(如1kHz对应17cm)。
实际:2~4cm(兼顾低频和高频响应)。
Q3:如何评估阵列性能?
指标:
唤醒率(>95%)、误唤醒率(<1次/天)。
信噪比提升(>10dB)。
总结
麦克风阵列是智能语音设备的“耳朵”,通过多麦克风协同+算法处理实现清晰拾音。选型时需平衡成本、功耗和性能,并根据场景选择线性/环形配置。对于开发者,可借助开源算法(如WebRTC)快速验证,或直接采用厂商提供的完整解决方案(如阿里云语音套件)。
音频的动态范围是什么?
音频的动态范围(Dynamic Range) 是描述声音信号中 “最响部分” 与 “最静部分” 之间差异的指标,通常以分贝(dB) 为单位。它反映了音频系统或音频内容所能呈现的音量变化幅度,是衡量音质和表现力的核心指标之一。
一、核心定义:从 “最静” 到 “最响” 的差距
具体来说,动态范围指的是音频中最大不失真信号(峰值音量) 与最小可辨信号(背景噪声底) 之间的分贝差值。公式可简化为:
动态范围(dB)= 20 × log₁₀(最大信号振幅 / 最小信号振幅)
- “最大信号”:指音频中最响亮、未失真的部分(如交响乐中的高潮、鼓点重击)。
- “最小信号”:指音频中可被清晰分辨的最弱声音(如乐器的泛音、人声的气音),或系统本身的背景噪声(如设备底噪)。
二、不同场景下的动态范围表现
动态范围的大小直接影响听感:
- 大动态范围:声音的强弱对比强烈,既能听到极细微的弱音(如小提琴的泛音),也能承受震撼的强音(如交响乐团的全奏),听感更 “鲜活”“有层次”。
例:现场音乐会的动态范围可达 100dB 以上(从安静的钢琴独奏到爆棚的铜管齐鸣)。- 小动态范围:声音的强弱差异小,弱音细节被压缩,强音缺乏冲击力,整体听感 “扁平”“生硬”。
例:早期收音机的动态范围仅 30-40dB(嘈杂环境中也能听清,但细节丢失严重)。三、动态范围的关键影响因素
音频内容本身
- 不同类型的音频天然具有不同动态范围:
- 古典音乐、电影原声:动态范围大(常达 80-100dB),强调强弱对比;
- 流行音乐、广播语音:动态范围较小(约 40-60dB),通过压缩处理让音量更平稳,适合在嘈杂环境播放。
录制与播放设备
- 麦克风、声卡、功放、扬声器等设备的动态范围决定了它们能 “捕捉” 或 “还原” 的信号范围:
- 专业录音设备(如高端电容麦、监听音箱)动态范围可达 120dB 以上,能保留更多细节;
- 廉价耳机、手机扬声器动态范围可能低于 80dB,弱音会被噪声掩盖,强音易失真。
后期处理
- 动态压缩(Compression)是调整动态范围的核心工具:通过削弱强音、提升弱音,缩小动态范围,让声音更 “紧凑”(适合流媒体、广播等场景);
- 过度压缩会导致动态范围过小,声音失去活力(如某些 “响度战争” 中的流行歌曲,为追求大音量牺牲了动态对比)。
四、与 “响度” 的区别
动态范围≠响度(Loudness):
- 响度是声音的 “平均音量”(如一首歌整体听起来 “大声” 还是 “小声”);
- 动态范围是 “最响与最静的差距”(如同一首歌中,鼓点与吉他分解和弦的音量对比)。
例如:两首响度相同的歌曲,A 的动态范围大(强弱对比明显),B 的动态范围小(所有乐器音量接近),听感会截然不同 ——A 更有层次感,B 更 “平”。
总结
动态范围是音频 “生命力” 的重要指标,它决定了声音能否呈现自然的强弱变化和细节层次。无论是音乐制作、设备选择还是日常聆听,理解动态范围都能帮助我们更好地把控音质:追求 “真实还原” 时,需保留大动态;适配 “嘈杂环境” 或 “小设备” 时,适当压缩动态范围则更实用。
音频数据采集到之后一般都有哪些处理?
音频数据采集(如麦克风录音、乐器拾音等)后,通常需要经过一系列处理来优化音质、适配应用场景或满足特定需求。这些处理步骤根据用途(如音乐制作、语音识别、广播等)有所差异,但核心流程可分为预处理、核心处理、后期优化三大类,具体如下:
一、预处理:解决原始数据的基础问题
原始采集的音频往往存在噪声、电平不稳等问题,预处理的目标是 “清理信号”,为后续处理铺路。
电平调整(Gain Adjustment)
- 原始音频可能因录音设备距离、音量设置等原因,出现电平过高(易失真)或过低(信噪比差)的问题。
- 处理方式:通过放大(提升弱信号)或衰减(降低强信号),将音频电平调整到合适范围(如专业领域常用 - 18dBFS 作为参考),避免后续处理时信号过载或丢失细节。
降噪处理(Noise Reduction)
- 原始录音常混入环境噪声(如空调声、电流底噪、远处交谈声),尤其在低质量麦克风或嘈杂环境下更明显。
- 处理方式:
- 静态降噪:先采集一段 “纯噪声样本”(如录音前的环境声),通过算法(如谱减法)识别并削弱与样本相似的噪声;
- 动态降噪:实时分析音频,对低电平的噪声进行压制(不影响主信号),常见于语音通话、播客后期。
消除直流偏移(DC Offset Removal)
- 部分录音设备可能因电路问题,导致音频信号叠加直流分量(表现为波形偏离中轴线)。
- 危害:可能导致后续放大时失真,或喇叭产生额外电流声。
- 处理方式:通过高通滤波器(滤除 0Hz 附近的直流成分),让波形回归基线。
二、核心处理:优化音质与适配场景
根据音频的用途(如音乐、语音、广播等),核心处理会侧重不同方向,常见包括:
1. 针对 “音质优化” 的处理
均衡器(EQ,Equalization)
调整不同频率的音量(如提升人声的中频、削弱刺耳的高频),弥补录音设备的频率响应缺陷,或塑造特定听感(如 “温暖”“明亮” 的音色)。
- 例:廉价麦克风录的人声高频刺耳,可用 EQ 衰减 3-5kHz 频段;低音不足时,提升 60-150Hz 频段。
动态处理(Dynamic Processing)
- 压缩器(Compressor):缩小音频中 “最响” 与 “最静” 的差距(如把演唱会中忽大忽小的声音压得更平稳),避免音量突变,同时增强声音的 “力度感”。
- 限制器(Limiter):更极端的压缩,防止音量超过某个阈值(如避免广播信号过载导致的破音)。
- 扩展器(Expander):与压缩器相反,拉大强弱差距(如突出交响乐的动态对比)。
失真与染色处理(仅用于音乐创作)
故意加入轻微失真(如吉他失真效果器),或通过电子管模拟、磁带模拟等工具,为声音增加 “温暖感”“颗粒感”,提升艺术表现力。2. 针对 “语音信号” 的处理(如通话、语音识别)
回声消除(Echo Cancellation)
消除语音设备中因扬声器与麦克风距离过近导致的 “回声”(如视频通话时,对方的声音从你的扬声器传出,又被你的麦克风录回去,形成重复回声)。人声分离(Vocal Isolation)
通过算法分离音频中的人声与背景音(如从歌曲中提取纯人声,或从嘈杂环境录音中提取清晰对话),常见于 K 歌软件、语音转文字工具。语音增强(Speech Enhancement)
针对性提升语音的清晰度:
- 过滤非语音频段的噪声(如 200Hz 以下的低频噪声);
- 增强 300-3400Hz 频段(人声核心频段),让说话声更通透。
3. 格式与传输适配处理
采样率 / 位深转换
原始录音可能采用高采样率(如 96kHz)和高位深(如 24bit),但为了适配播放设备(如手机支持 44.1kHz)或减少文件体积,需转换为更低规格(如 44.1kHz/16bit)。
- 注意:转换过程需用优质算法(如线性插值),否则会引入失真。
编码压缩(Codec)
将无损音频(如 WAV、FLAC)压缩为适合传输 / 存储的格式:
- 有损压缩:如 MP3、AAC(通过丢弃人耳不敏感的细节减小体积,牺牲部分音质);
- 无损压缩:如 ALAC(保留完整数据,体积比 WAV 小)。
三、后期优化:提升听感细节
立体声处理
- 调整左右声道的平衡(避免某一侧声音过强);
- 通过声像旋钮(Pan)分配乐器在声场中的位置(如吉他偏左、贝斯居中),增强空间感。
混响与延迟(Reverb & Delay)
- 混响:模拟声音在房间、大厅中的反射效果(如给人声加 “大厅混响”,使其更有 “空间感”,不像在 “闷罐” 里录音);
- 延迟:让声音重复(如电吉他的 “回声” 效果),增加层次感。
响度标准化(Loudness Normalization)
统一不同音频的播放音量(如流媒体平台会将所有歌曲的响度调整到 - 14LUFS 左右,避免切换歌曲时音量忽大忽小)。总结:处理流程的核心逻辑
音频处理的本质是 **“修正缺陷”+“适配需求”**:
- 先通过预处理解决原始录音的 “硬伤”(噪声、电平、直流偏移);
- 再根据用途(音乐 / 语音 / 广播等)进行核心优化(EQ、动态处理、编码等);
- 最后通过后期细节调整(混响、响度)提升听感体验。
不同场景的处理侧重点差异很大(如专业音乐制作会用到数十种效果器,而语音通话只需简单降噪和回声消除),但最终目标都是让音频 “更好听” 或 “更适用”。
什么是音频的谐波失真?
音频的谐波失真(Harmonic Distortion) 是指音频信号在放大、转换或传输过程中,因设备(如功放、扬声器、麦克风)性能缺陷,导致输出信号中出现原始信号中不存在的额外频率成分(即 “谐波”),从而破坏声音真实性的现象。这些额外的谐波频率是原始信号基频的整数倍,会扭曲声音的音色和质感。
一、谐波失真的产生原理
声音的原始信号(如人声、乐器声)由一个基频(决定音高的主要频率)和多个天然谐波(基频的整数倍,决定音色,如钢琴与小提琴的区别)组成。例如,440Hz 的 A 音(标准音),其天然谐波为 880Hz(2 倍频)、1320Hz(3 倍频)等,这些谐波的比例是声音 “独特性” 的来源。
而谐波失真是设备在处理信号时,额外产生了非天然的谐波(与原始信号的谐波比例不符):
- 假设原始信号只有基频 f,经过劣质设备后,输出信号中除了 f,还出现了 2f、3f、4f… 等频率(即 “失真谐波”);
- 这些额外谐波会干扰原始音色,导致声音变味(如刺耳、发闷、粗糙)。
二、谐波的分类:偶次与奇次谐波
根据谐波频率与基频的倍数关系,失真谐波可分为两类,对听感的影响差异显著:
偶次谐波(2f、4f、6f…)
- 特点:频率是基频的偶数倍,与原始信号的天然谐波规律更接近(多数乐器的天然谐波中偶次谐波占比更高)。
- 听感:适量偶次谐波会让声音更 “温暖”“柔和”(如电子管功放的轻微偶次失真,被部分人认为是 “悦耳的染色”),但过量会导致声音模糊、缺乏层次感。
奇次谐波(3f、5f、7f…)
- 特点:频率是基频的奇数倍,与天然谐波规律差异大,属于 “不和谐” 的干扰成分。
- 听感:即使少量奇次谐波也会让声音 “刺耳”“生硬”“粗糙”(如劣质晶体管功放、廉价扬声器的失真,常伴随明显的奇次谐波),严重时会产生 “金属味” 或 “撕裂感”。
三、谐波失真的来源
几乎所有音频设备都可能产生谐波失真,核心原因是设备非线性工作(理想设备应线性放大信号,即输出与输入成正比例关系):
功放(功率放大器)
- 功放中的晶体管、电子管若工作在非线性区域(如信号过大导致 “过载”),会无法线性跟随输入信号,从而产生谐波。例如,小功率功放推大音量时,信号被 “削顶”,会产生大量奇次谐波。
扬声器(喇叭)
- 振膜材质刚性不足、悬挂系统(弹波、折环)非线性,或音圈位移过大,都会导致振动时产生额外谐波。例如,廉价小喇叭播放低频时,振膜过度振动会产生失真谐波,导致低频 “发闷” 或 “浑浊”。
麦克风与声卡
- 麦克风振膜、声卡的 ADC/DAC 芯片若精度不足,会在信号转换时引入谐波。例如,劣质麦克风录制人声时,高频部分可能因失真产生额外谐波,导致声音 “刺耳”。
线缆与接口
- 劣质音频线的屏蔽不良、接触电阻不稳定,会干扰信号传输,间接引发谐波失真(通常占比极低,但高端系统中需重视)。
四、谐波失真的衡量指标:THD(总谐波失真)
通常用总谐波失真(Total Harmonic Distortion,THD) 量化失真程度,计算公式为:
THD = (所有谐波的总功率 ÷ 基频功率)× 100%
- 数值越小,失真越低(音质越纯净)。例如,Hi-Fi 功放的 THD 通常<0.1%,而廉价蓝牙音箱的 THD 可能>1%。
- 注意:THD 是 “所有谐波的总和”,但未区分偶次 / 奇次,因此需结合听感判断(如电子管功放 THD 可能>0.5%,但因偶次谐波为主,听感仍较柔和)。
五、对听感的具体影响
- 轻微失真(THD<0.1%):人耳通常难以察觉,对音质影响可忽略(如高端音响设备)。
- 中等失真(0.1%<THD<1%):音色开始变化,如人声变得 “生硬”,乐器泛音被掩盖(如小提琴失去 “光泽”)。
- 严重失真(THD>1%):声音明显变味,低频浑浊、高频刺耳,甚至出现 “破音”(如手机外放最大音量时的失真)。
六、总结
谐波失真是破坏声音真实性的核心因素之一,其本质是设备引入了额外的 “杂音频率”(谐波)。偶次谐波可能带来 “温暖染色”,但奇次谐波几乎总是导致听感劣化。在音频设备选择中,低 THD 是优质设备的基础(如 Hi-Fi 系统追求 THD<0.01%),但需结合实际听感 —— 毕竟数据只是参考,耳朵对 “自然度” 的判断更为直接。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 32
32 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)