pycharm 中debug时_帧不可用_frames are not available
如果是神经网络模型调试, 尝试将batch -size=1 ;pycharm 中, file–>settings -->Build, —> pythonDebugger—> Gevent compatible.
1. frames are not available 帧不可用
在使用pycharm 进行调试深度学习的 train.py 训练脚本过程中,
会出现下面这类情况:
frames are not available,在Variable那里还显示:Connected, 但是此时Console,查看变量没反应。
原因在于,我们运行神经网络时,经常会开启多进程运行,
parser.add_argument('--num_worker', default=4, type=int, help='numbers of worker')
或者使用 Dataloader 加载batch_size 时, 开启了多进程。
dataloader = DataLoader(dataset,
batch_size=args.batch_size,
shuffle=True,
num_workers=0,#或者直接不要这个参数,默认是0
collate_fn=MyDataset.collate_fn)
1.1 主进程
运行时,使用多进程没关系。
但是使用pycharm 调试时,
请使用主进程, 即设置num_workers = 0, 注意设置成1 也不行;
-
num_workers=0表示只有主进程去加载batch数据. 训练过程中,这会是导致训练速度慢的一个瓶颈。 但在,调试过程中,请设置成0;
-
num_workers = 1表示除了主进程之外, 还有子进程 worker用来加载batch数据,而主进程是不参与数据加载的。这样速度也会很慢。
(所以,在使用pycharm 调试时,设置1的话, 主进程是没有参与数据加载的,从而变量的数值保存在另外一个worker进程中, 自然,console控制台中, 只能查看到主进程中的数据)
-
num_workers>0 表示只有指定数量的worker 进程去加载数据,主进程不参与。
-
增加num_works也同时会增加cpu内存的消耗。所以num_workers的值依赖于 batch size和机器性能。
-
一般开始是将num_workers设置为等于计算机上的CPU的逻辑核数
-
最好的办法是缓慢增加num_workers,直到训练速度不再提高,就停止增加num_workers的值
class DataLoader(Generic[T_co]):
dataset: Dataset[T_co]
batch_size: Optional[int]
num_workers: int
pin_memory: bool
drop_last: bool
timeout: float
sampler: Union[Sampler, Iterable]
prefetch_factor: int
_iterator : Optional['_BaseDataLoaderIter']
__initialized = False
def __init__(self, dataset: Dataset[T_co], batch_size: Optional[int] = 1,
shuffle: bool = False, sampler: Union[Sampler, Iterable, None] = None,
batch_sampler: Union[Sampler[Sequence], Iterable[Sequence], None] = None,
num_workers: int = 0, collate_fn: Optional[_collate_fn_t] = None,
pin_memory: bool = False, drop_last: bool = False,
timeout: float = 0, worker_init_fn: Optional[_worker_init_fn_t] = None,
multiprocessing_context=None, generator=None,
*, prefetch_factor: int = 2,
persistent_workers: bool = False):
torch._C._log_api_usage_once("python.data_loader")
if num_workers < 0:
raise ValueError('num_workers option should be non-negative; '
'use num_workers=0 to disable multiprocessing.')
1.2 为什么是多进程而不是多线程
num_workers:该参数指定用于数据加载的子进程数。如果 num_workers 设置为 0,则数据将加载到主进程中,这是默认行为。如果设置为正整数,则将生成多个子进程以进行数据加载。
关键的原因是 Python 中 存在 全局解释器所GIL, GIL 每次只允许一个线程执行 Python 字节码.
-
多线程:涉及单个进程中的多个线程。线程共享相同的内存空间,可以有效地相互通信。但是,由于 Python 中的全局解释器锁 (GIL),多线程不会显著提高 Python 中受 CPU 限制的任务的性能(例如许多深度学习框架中的数据加载和预处理)。GIL 每次只允许一个线程执行 Python 字节码。
-
多进程:涉及多个进程,每个进程都有自己的内存空间。这避免了 GIL 问题,因为每个进程都独立运行,并且可以在单独的 CPU 内核上执行。在深度学习数据加载中,多处理通常是首选,因为它可以通过并行化数据加载和预处理任务来显著提高性能,从而允许主过程(通常是训练循环)专注于模型训练。
如何运作:
当大于 0 时 num_workers ,数据加载程序将生成指定数量的子进程。每个工作进程独立检索一批数据。
这些工作进程预取数据并并行执行任何必要的预处理,例如转换和扩充。这意味着主进程不需要等待数据加载和预处理,从而确保GPU或主计算资源不会闲置。
工作进程准备的数据批处理通常存储在队列中。然后,主进程根据需要使用此队列中的数据。
Benefits好处
- 并行性:通过使用多个工作进程,可以并行化数据加载和预处理,从而显著减少主进程等待数据的时间。
- 效率:在主进程处理训练的同时,有效利用 CPU 内核进行数据加载,从而更好地利用系统资源。
- 可伸缩性:随着数据集大小和复杂性的增加,使用更多工作线程可以帮助保持或提高数据加载速度。
Considerations考虑
系统资源:更多的工作进程意味着更多的 CPU 和内存使用量。必须平衡工作线程的数量和可用的系统资源。
数据集大小和复杂性:最佳工作线程数量可能因数据集的大小和复杂性而异,有时需要进行试验才能找到最佳设置。
1.3 DataLoader 加载的机制
num_worker通常使用以下情况:
from torch.utils.data import DataLoader
train_loader = DataLoader(dataset=train_data, batch_size=train_bs, shuffle=True, num_worker=4)
valid_loader = DataLoader(dataset=valid_data, batch_size=valid_bs, num_worker=4)
然后在训练过程中, 每个epoch 中, 每次调用batch_size数据都是使用 DataLoader 加载进来;
for epoch in range(start_epoch, end_epoch):
for i, data in enumerate(trainloader):
-
dataloader一次性创建num_worker个worker,(也可以说dataloader一次性创建num_worker个工作进程,worker也是普通的工作进程),
并用batch_sampler将指定batch分配给指定worker,worker将它负责的batch加载进RAM。
然后,dataloader从RAM中找本轮迭代要用的batch,如果找到了,就使用。
如果没找到,就要num_worker个worker继续加载batch到内存,直到dataloader在RAM中找到目标batch。一般情况下都是能找到的,因为batch_sampler指定batch时当然优先指定本轮要用的batch。 -
num_worker设置得大,好处是寻batch速度快,因为下一轮迭代的batch很可能在上一轮/上上一轮…迭代时已经加载好了。坏处是内存开销大,也加重了CPU负担(worker加载数据到RAM的线程是CPU复制的嘛)。num_workers的经验设置值是自己电脑/服务器的CPU核心数,如果CPU很强、RAM也很充足,就可以设置得更大些。
-
如果num_worker设为0,意味着每一轮迭代时,dataloader不再有自主加载数据到RAM这一步骤(因为没有worker了),而是在RAM中找batch,找不到时再加载相应的batch。缺点当然是速度更慢。
1.4 内存或显存占用
但是,如果出现killed by signal 9, 中断了程序, 请检查自己的内存是否超了, 在linux系统下可以使用增加交换空间的方式,进行临时扩充;
显存占用
cuda out of memory: 现存占用过多, 可以把batch size 调小一点;
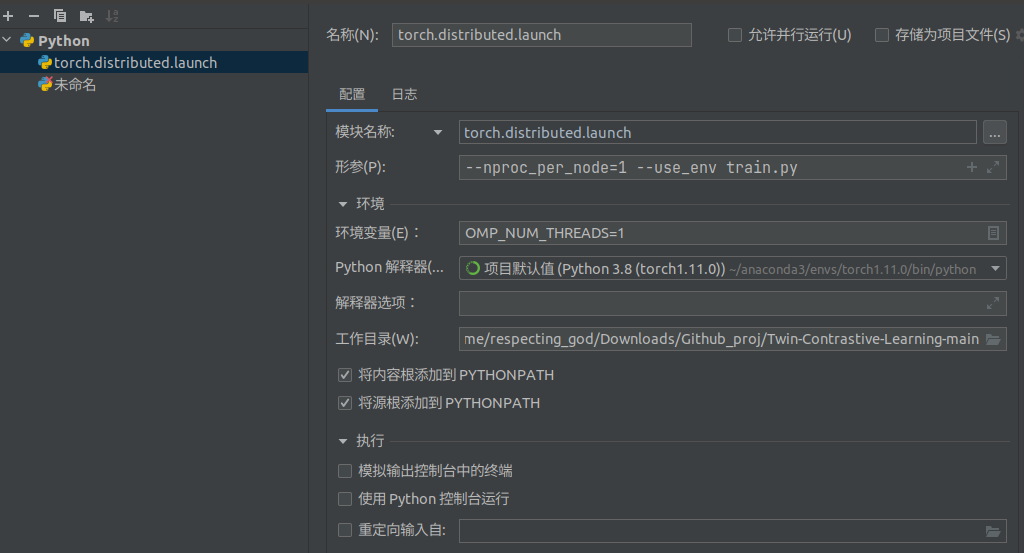
1.5 分布式代码调试
在配置文件中,将脚本路径切换为 模块名称;
形参设置为: --nproc_per_node=1 --use_env train.py 其中 train.py 代表的是要调试的文件, --nproc_per_node, 表示当前使用gpu 的个数;
环境变量设置为OMP_NUM_THREADS=1, 调试过程中设置为1;
OMP_NUM_THREADS 设置为正整数。
该数字表示 OpenMP 并行区域将使用多少个 CPU 进程。
最佳值取决于可用 CPU 核心的数量和应用程序的性质。常见设置是 CPU 上的物理或逻辑核心的数量。
2. pycharm 中断点调试
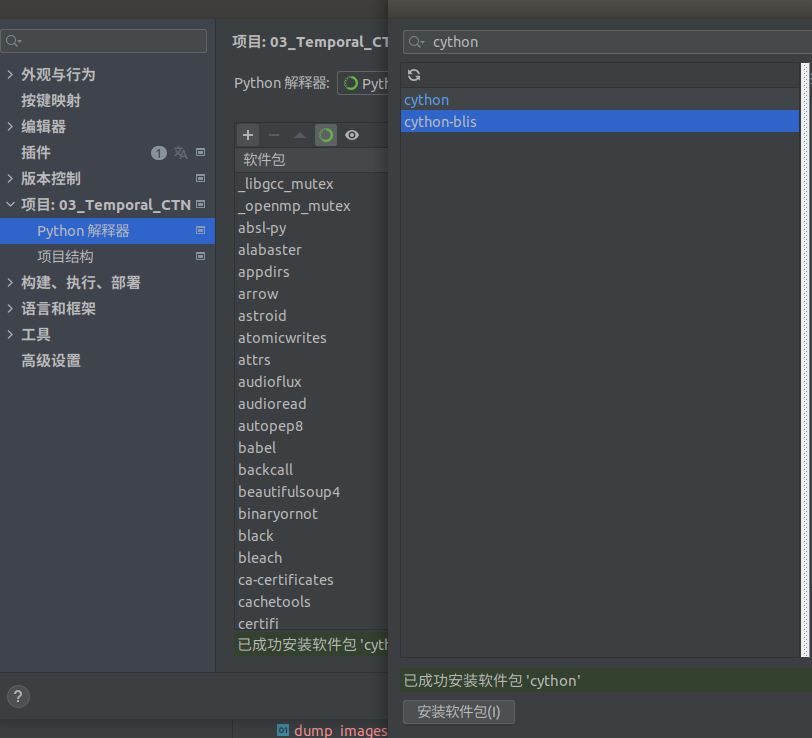
2.1 安装cython 加速调试工具;
整体步骤是 pip install 之后, 还需要在python 解释器, 点击 + 然后搜索,
在点击下方的安装软件包,
To install Cython in your Ubuntu 18 environment and use it within PyCharm, you can follow these steps:
-
Open a terminal in your Ubuntu 18 environment.
-
Update the package list by running the following command:
sudo apt update -
Install the Cython package by running the following command:
sudo apt install cython -
Once Cython is installed, you can open PyCharm.
-
Open your project in PyCharm or create a new project.
-
Go to “File” -> “Settings” -> “Project: ” -> “Python Interpreter”.
-
Click on the “+” button to add a new package.
-
In the search bar, type “cython”.
-
Select the “cython” package and click on the “Install Package” button.
-
PyCharm will download and install the Cython package for your project.
-
You can now use Cython within your PyCharm project for compiling Python code to C.
Make sure to select the appropriate Python interpreter for your project in PyCharm, which should match the Python environment where you installed Cython.
Note: If you are using a virtual environment for your project, make sure to activate the virtual environment before installing Cython.
2.2 配置debug
- 如果是神经网络模型调试, 尝试将batch -size =1 ;
- pycharm 中, file–> settings -->Build, —> python Debugger —> Gevent compatible.

2.3 打印数据的详细数值
对 torch 进行如下设置, 可以打印出 变量 或者 张量的详细 数值;
import numpy as np
# 设置打印选项,threshold设置为一个较大的值
torch.set_printoptions(threshold=np.inf)
print(data.x.shape)
data.x[1]
3 . pycharm 中同级目录下,文件导入
在调试项目之前,需要将当前项目文件设置为 项目的根目录
3.1 项目的根目录设置
在设置 —> project 项目 —》 项目结构中 选将当前项目文件设置为根目录;
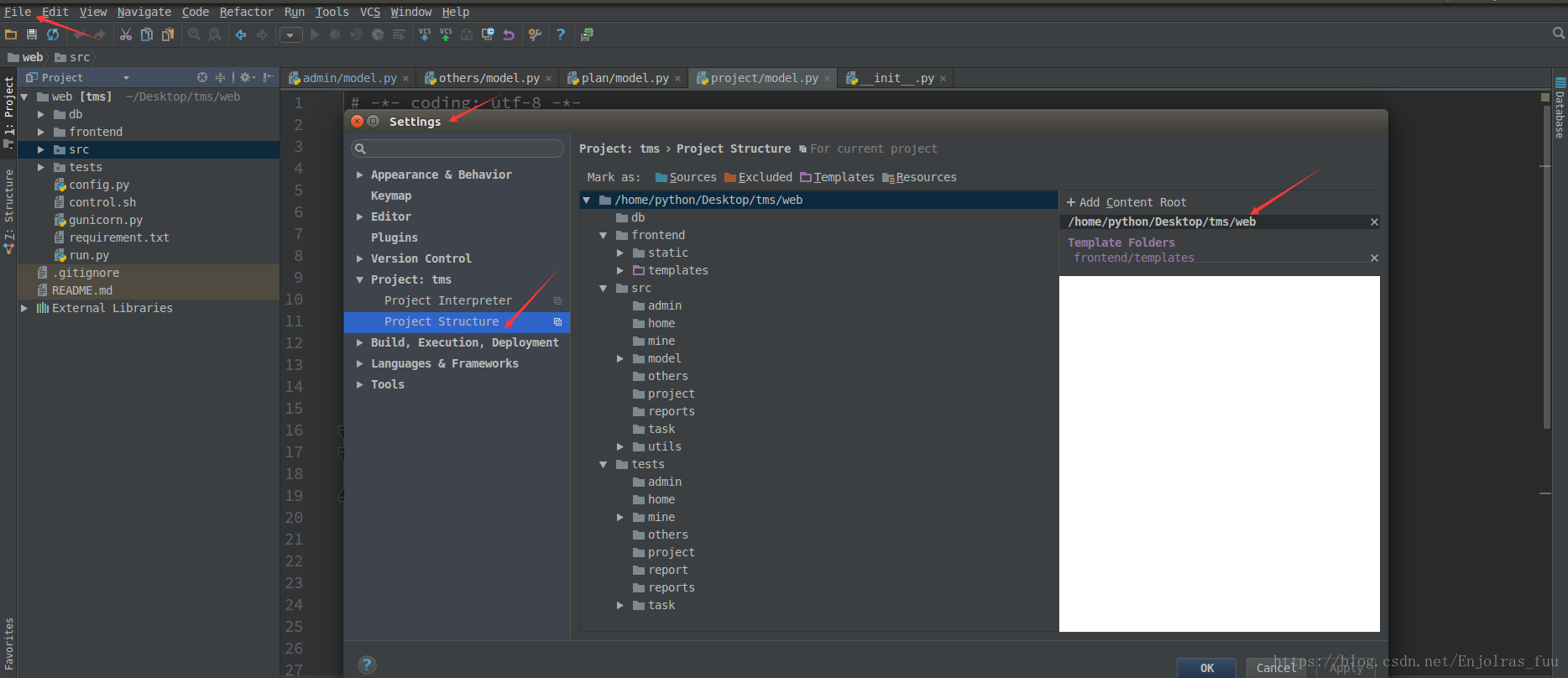
- 该目录是否是一个包含 __ init__.py 文件的包
- pycharm 不会将当前文件目录自动加入source_path, 选中该目录后右键 make_directory as —> Source Root
- from .your_python_file import class ; . 代表同级目录下的文件
参考:
https://www.cnblogs.com/hesse-summer/p/11343870.html

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 9
9 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)