强化学习简介
本文介绍了强化学习的基本概念和要素。强化学习涉及智能体与环境交互,通过状态、动作、奖励等要素进行学习和决策。智能体通过策略(确定性或随机性)选择动作,环境根据动作改变状态并反馈奖励。文章阐述了马尔可夫决策过程、轨迹、总回报(折扣回报)等概念,并详细讨论了目标函数(最大化期望回报)和值函数(状态值函数和Q函数)。值函数用于策略评估和优化,通过贝尔曼方程进行迭代计算。强化学习的目标是找到最优策略以获得
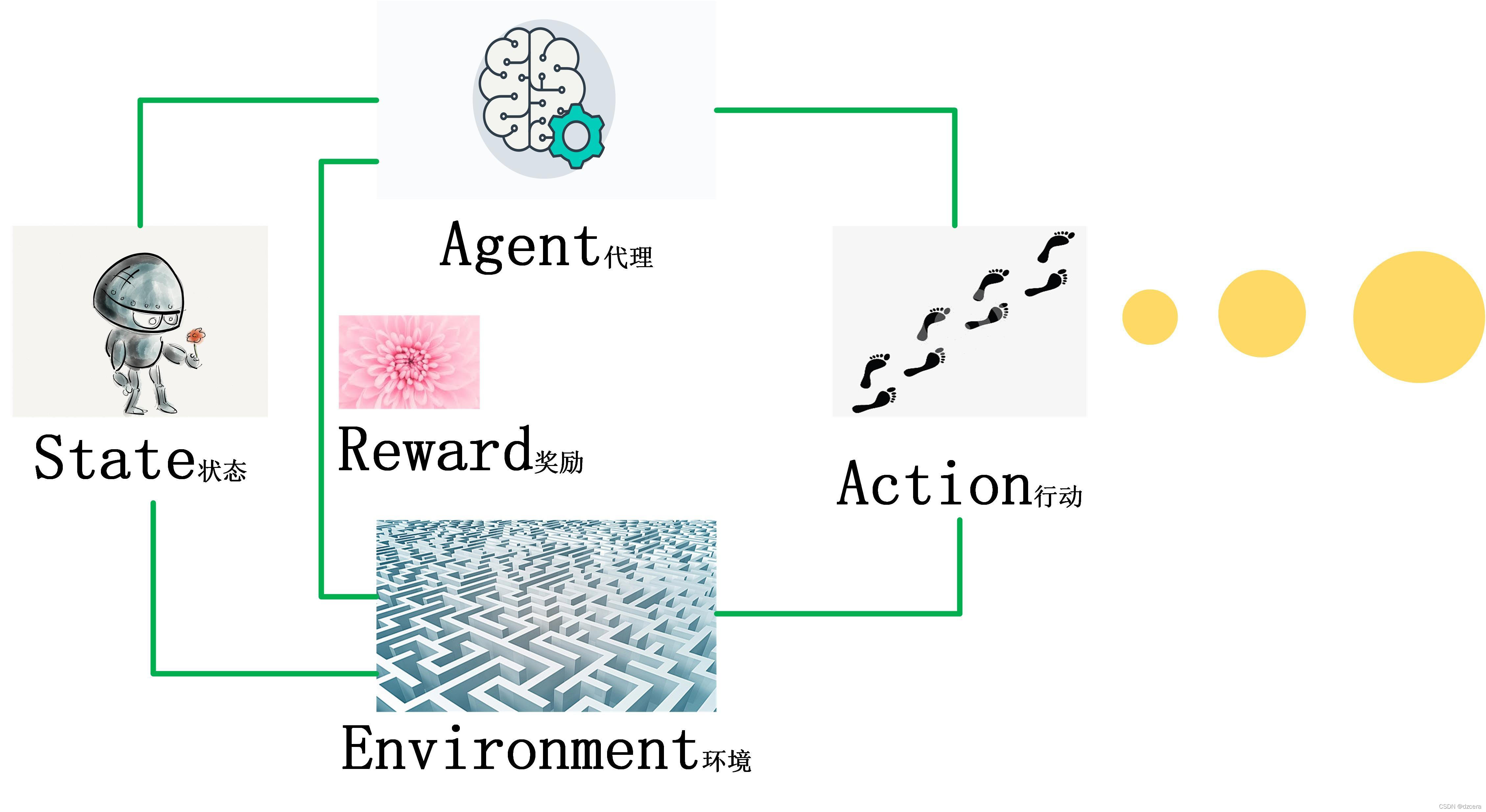
一、强化学习的定义
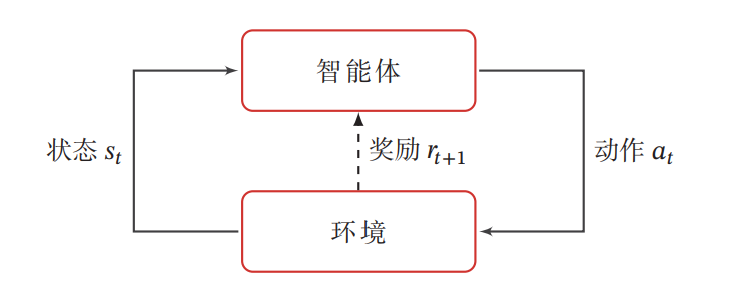
在强化学习中, 有两个可以进行交互的对象: 智能体和环境。
智能体( Agent) 可以感知外界环境的状态( State) 和反馈的奖励( Reward), 并进行学习和决策. 智能体的决策功能是指根据外界环境的状态来做出不同的动作( Action), 而学习功能是指根据外界环境的奖励来调整策略。
环境( Environment) 是智能体外部的所有事物, 并受智能体动作的影响而改变其状态, 并反馈给智能体相应的奖励
强化学习的基本要素包括:
- 状态𝑠是对环境的描述, 可以是离散的或连续的, 其状态空间为𝒮。
- 动作𝑎 是对智能体行为的描述, 可以是离散的或连续的, 其动作空间为𝒜。
- 策略𝜋(𝑎|𝑠)是智能体根据环境状态𝑠来决定下一步动作𝑎的函数。
- 状态转移概率𝑝(𝑠′|𝑠, 𝑎)是在智能体根据当前状态𝑠做出一个动作𝑎之后, 环境在下一个时刻转变为状态𝑠′ 的概率。
- 即时奖励𝑟(𝑠, 𝑎, 𝑠′) 是一个标量函数, 即智能体根据当前状态 𝑠 做出动作 𝑎之后, 环境会反馈给智能体一个奖励, 这个奖励也经常和下一个时刻的状态𝑠′ 有关。
二、策略
智能体的策略( Policy) 就是智能体如何根据环境状态 𝑠 来决定下一步的动作 𝑎, 通常可以分为确定性策略( Deterministic Policy) 和随机性策略( Stochastic Policy) 两种。采用确定性策略的智能体总是对同样的环境做出相同的动作, 会导致它的策略很容易被对手预测。通常情况下, 强化学习一般使用随机性策略。随机性策略可以有很多优点:
1) 在学习时可以通过引入一定随机性更好地探索环境;
2) 随机性策略的动作具有多样性, 这一点在多个智能体博弈时也非常重要。
为了能够使用梯度下降等优化方法,策略需要被参数化。
三、轨迹
智能体从感知到的初始环境 𝑠0 开始, 然后决定做一个相应的动作 𝑎0, 环境相应地发生改变到新的状态𝑠1, 并反馈给智能体一个即时奖励𝑟1, 然后智能体又根据状态𝑠1 做一个动作𝑎1, 环境相应改变为𝑠2, 并反馈奖励𝑟2. 这样的交互可以一直进行下去。
𝑠0, 𝑎0, 𝑠1, 𝑟1, 𝑎1, ⋯ , 𝑠𝑡-1, 𝑟𝑡-1, 𝑎𝑡-1, 𝑠𝑡, 𝑟𝑡, ⋯ ,
智能体与环境的交互过程可以看作一个马尔可夫决策过程。马尔可夫决策过程在马尔可夫过程中加入一个额外的变量: 动作𝑎, 下一个时刻的状态𝑠𝑡+1 不但和当前时刻的状态𝑠𝑡 相关, 而且和动作𝑎𝑡 相关
𝑝(𝑠𝑡+1|𝑠𝑡, 𝑎𝑡, ⋯ , 𝑠0, 𝑎0) = 𝑝(𝑠𝑡+1|𝑠𝑡, 𝑎𝑡)
其中𝑝(𝑠𝑡+1|𝑠𝑡, 𝑎𝑡)为状态转移概率。
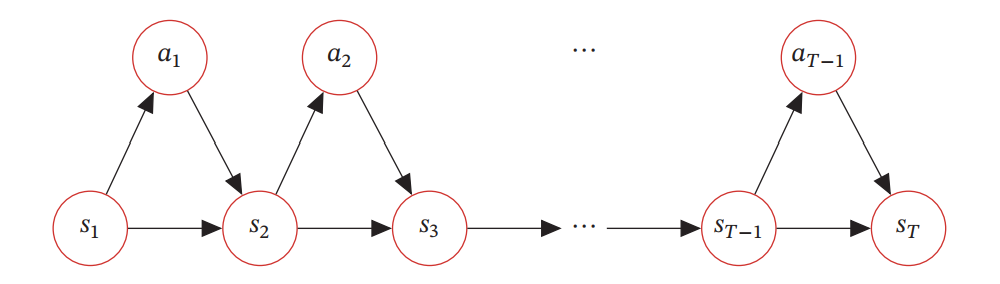
给定策略𝜋(𝑎|𝑠), 马尔可夫决策过程的一个轨迹( Trajectory)
𝜏 = 𝑠0, 𝑎0, 𝑠1, 𝑟1, 𝑎1, ⋯ , 𝑠𝑇-1, 𝑎𝑇-1, 𝑠𝑇, 𝑟𝑇
的概率为
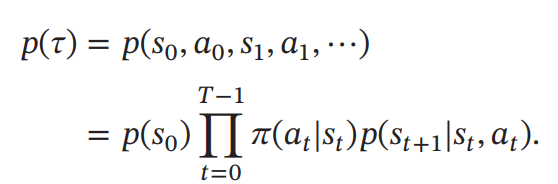
即初始状态乘以策略再乘以状态转移概率的叠乘。
四、总回报
给定策略 𝜋(𝑎|𝑠), 智能体和环境一次交互过程的轨迹 𝜏 所收到的累积奖励为总回报( Return)
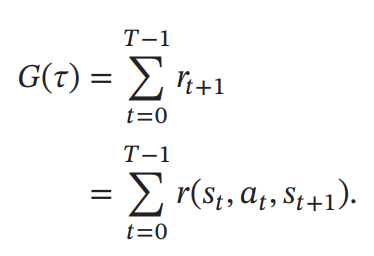
假设环境中有一个或多个特殊的终止状态( Terminal State), 当到达终止状态时, 一个智能体和环境的交互过程就结束了。 这一轮交互的过程称为一个回合( Episode) 或试验( Trial)。 一般的强化学习任务( 比如下棋、 游戏) 都属于这种回合式任务( Episodic Task)。如果环境中没有终止状态( 比如终身学习的机器人), 即 𝑇 = ∞, 称为持续式任务( Continuing Task), 其总回报也可能是无穷大. 为了解决这个问题, 我们可以引入一个折扣率来降低远期回报的权重。 折扣回报( Discounted Return)定义为
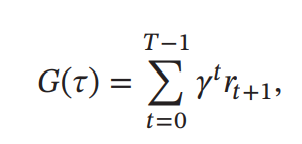
其中𝛾 ∈ [0, 1]是折扣率. 当𝛾接近于0时, 智能体更在意短期回报; 而当𝛾接近于1时, 长期回报变得更重要。
五、目标函数
因为策略和状态转移都有一定的随机性, 所以每次试验得到的轨迹是一个随机序列, 其收获的总回报也不一样。强化学习的目标是学习到一个策略𝜋𝜃(𝑎|𝑠)来最大化期望回报( Expected Return), 即希望智能体执行一系列的动作来获得尽可能多的平均回报。其中 θ 是策略的参数,s 是当前状态,a 是可能的行动。参数化策略可以通过神经网络、线性回归模型等函数近似器来实现。例如,使用神经网络作为策略函数,输入是状态 s,输出是行动 a 的概率分布参数(如分类问题中的softmax输出)。
强化学习的目标函数为:
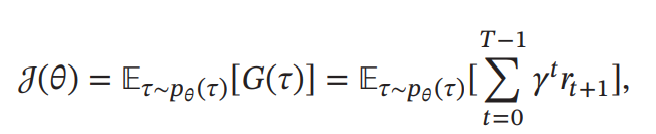
六、值函数
为了评估策略 𝜋 的期望回报, 我们定义两个值函数: 状态值函数和状态-动作值函数。
6.1 状态值函数
策略𝜋的期望回报可以分解为
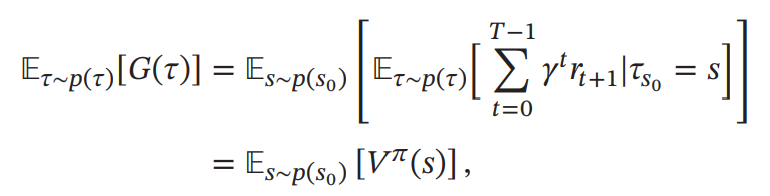
其中𝑉𝜋(𝑠)称为状态值函数( State Value Function), 表示从状态𝑠开始, 执行策略𝜋得到的期望总回报
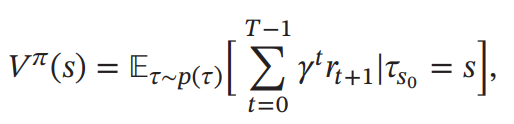
其中𝜏𝑠0 表示轨迹𝜏的起始状态。
为了方便起见, 我们用𝜏0∶𝑇 来表示轨迹𝑠0, 𝑎0, 𝑠1, ⋯ , 𝑠𝑇, 用𝜏1∶𝑇 来表示轨迹𝑠1, 𝑎1, ⋯ , 𝑠𝑇, 因此有𝜏0∶𝑇 = 𝑠0, 𝑎0, 𝜏1∶𝑇。
根据马尔可夫性质, 𝑉𝜋(𝑠)可展开得到
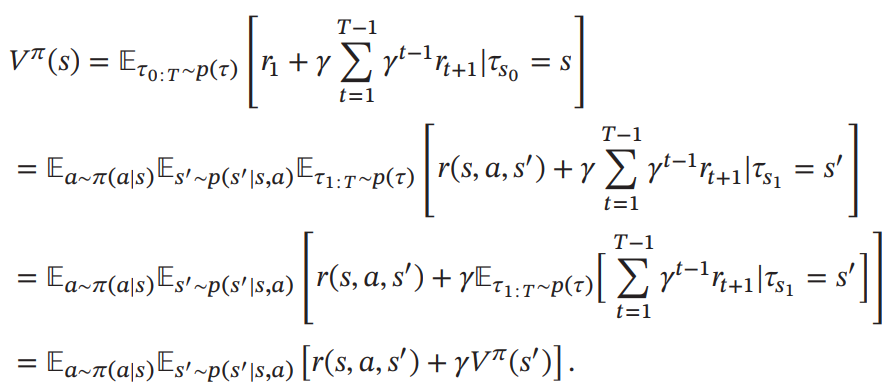
上式也称为贝尔曼方程( Bellman Equation), 表示当前状态的值函数可以通过下个状态的值函数来计算。
如果给定策略 𝜋(𝑎|𝑠), 状态转移概率 𝑝(𝑠′|𝑠, 𝑎) 和奖励 𝑟(𝑠, 𝑎, 𝑠′), 我们就可以通过迭代的方式来计算𝑉𝜋(𝑠)。 由于存在折扣率, 迭代一定步数后, 每个状态的值函数就会固定不变。
6.2 状态-动作值函数
上式中的第二个期望是指初始状态为𝑠并进行动作𝑎, 然后执行策略𝜋得到的期望总回报, 称为状态-动作值函数( State-Action Value Function):
![]()
状态-动作值函数也经常称为Q函数( Q-Function)。
状态值函数𝑉𝜋(𝑠)是Q函数𝑄𝜋(𝑠, 𝑎)关于动作𝑎的期望, 即
![]()
Q函数可以写为:
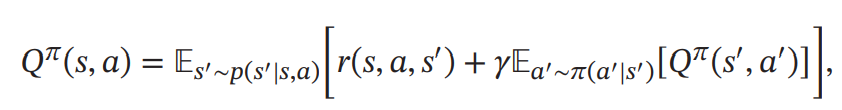
这是关于Q函数的贝尔曼方程。
6.3 值函数的作用
值函数可以看作对策略 𝜋 的评估, 因此我们就可以根据值函数来优化策略。假设在状态𝑠, 有一个动作𝑎∗ 使得𝑄𝜋(𝑠, 𝑎∗) > 𝑉𝜋(𝑠), 说明执行动作𝑎∗ 的回报比当前的策略𝜋(𝑎|𝑠)要高, 我们就可以调整参数使得策略中动作 𝑎∗ 的概率 𝑝(𝑎∗|𝑠)增加。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 39
39 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)