树莓派简易语音对话系统构建指南
树莓派(Raspberry Pi)是一款基于ARM架构的低成本、信用卡大小的单板计算机,它由Raspberry Pi基金会开发,旨在促进基础计算机科学教育。由于它的便携性、低功耗以及丰富的GPIO接口,树莓派被广泛应用于教育、原型设计、家用服务器和个人项目中。语音识别技术是将人类的语音转换为可读或可理解的文本形式的过程,它是语音对话系统的核心组件之一。

简介:树莓派语音对话系统是一项基于树莓派计算机平台的智能交互技术,适合初学者用于提升编程技能并理解AI应用。本指南详述了如何在树莓派上建立一个基础的语音对话机器人,涵盖了硬件设置、软件安装、代码实现和问题解决。文档包含使用WinSCP安全传输文件和关键的Python脚本来处理语音识别及对话逻辑。通过该指南,初学者可以学习树莓派、Python编程和AI语音技术。 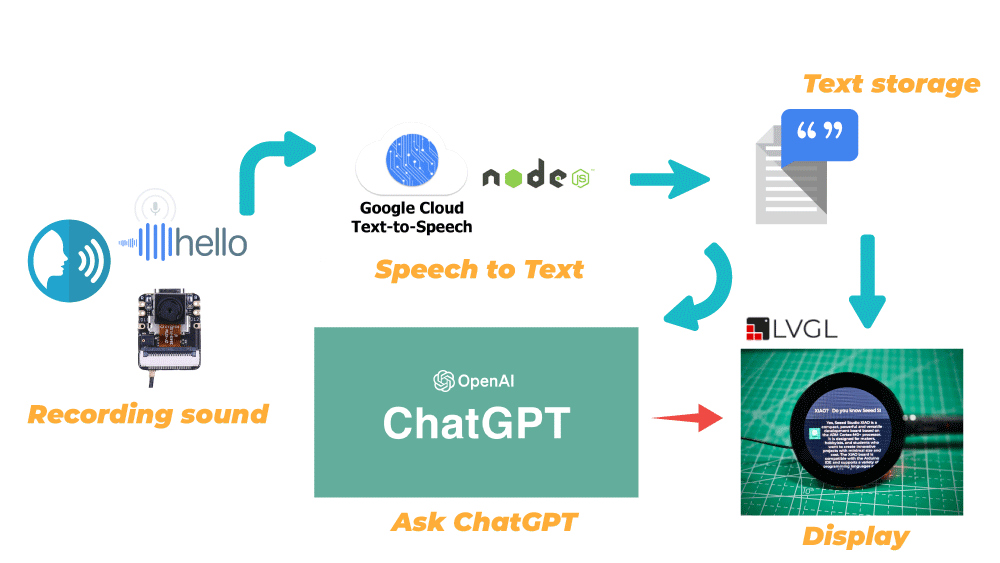
1. 树莓派基础介绍
简介与起源
树莓派(Raspberry Pi)是一款基于ARM架构的低成本、信用卡大小的单板计算机,它由Raspberry Pi基金会开发,旨在促进基础计算机科学教育。由于它的便携性、低功耗以及丰富的GPIO接口,树莓派被广泛应用于教育、原型设计、家用服务器和个人项目中。
树莓派系列与规格
自2012年首次发布以来,树莓派已经经历了多个版本的更新,包括经典的A系列、B系列,以及更高级的3系列和最新发布的4系列。每个版本在处理能力、内存大小、连接接口等方面都有所改进。开发者可根据具体需求选择合适的树莓派型号。
入门设置与开发环境
对于初学者来说,树莓派的设置相对简单。您需要准备一张SD卡,并使用官方推荐的NOOBS操作系统安装包来安装操作系统。一旦安装完成,您可以连接显示器、键盘和鼠标进行基础操作。此外,树莓派社区活跃,提供了丰富的学习资源和开发工具,帮助开发者快速搭建开发环境,进行项目开发。
2. 树莓派语音对话系统概念
2.1 语音对话系统的工作原理
2.1.1 语音识别技术简介
语音识别技术是将人类的语音转换为可读或可理解的文本形式的过程,它是语音对话系统的核心组件之一。在树莓派上实现语音识别,可以通过调用专门的语音识别库如Google Speech Recognition,或通过使用开源库如PocketSphinx进行实现。Google Speech Recognition提供了较高的识别准确性,但依赖于网络连接;而PocketSphinx作为离线解决方案,虽然准确性稍低,但无需网络连接,适合独立运行在树莓派上。
下面是使用Python集成Google Speech Recognition的代码示例:
import speech_recognition as sr
# 初始化识别器
recognizer = sr.Recognizer()
# 使用默认的麦克风作为音频源
with sr.Microphone() as source:
print("请说些什么:")
audio = recognizer.listen(source)
# 使用Google Web Speech API进行语音识别
try:
# 将语音转换成文字
text = recognizer.recognize_google(audio, language='en-US')
print("你说: " + text)
except sr.UnknownValueError:
print("Google Speech Recognition无法理解音频")
except sr.RequestError as e:
print("无法从Google Speech Recognition服务请求结果; {0}".format(e))
此代码段首先导入 speech_recognition 库,并创建一个 Recognizer 对象。然后,它使用默认的麦克风作为音频源,并调用 recognize_google 方法来执行实际的语音识别。如果识别成功,输出识别的文本,否则捕获异常并输出错误信息。
2.1.2 语音合成技术简介
语音合成技术(Text-to-Speech, TTS)是将文本信息转换为语音输出的过程,使得机器可以以听觉形式与人类用户进行交互。在树莓派上实现TTS,可以使用Mimic,这是一个基于Google Text-to-Speech引擎的命令行工具,或者使用诸如eSpeak这样的开源TTS引擎。Mimic提供非常自然的语音合成效果,但同样依赖于网络连接。
下面是一个使用Mimic工具将文本转换为语音的示例:
# 安装Mimic
sudo apt-get install mimic
# 使用Mimic将文本转换为语音并播放
echo "Hello, this is a text-to-speech example." | mimic -w out.wav
aplay out.wav
以上命令首先安装Mimic工具,然后使用echo命令输出要转换的文本,通过管道将文本传递给Mimic,生成语音文件 out.wav 。使用 aplay 命令播放生成的语音文件。
2.1.3 对话管理技术简介
对话管理技术是语音对话系统中负责理解用户意图、维护对话状态、决定下一步动作的部分。它通过自然语言理解(NLU)和对话策略管理来实现这一功能。对话管理系统通常涉及到一系列的预定义规则或使用机器学习模型来解析用户的输入,并作出相应的回答或请求额外信息。
对话管理可以分为以下几个步骤: 1. 意图识别 :确定用户想要执行的行动或信息需求。 2. 实体提取 :从用户的句子中抽取相关的细节,比如日期、时间、地点等。 3. 对话策略 :决定下一步是提供信息、请求更多信息还是结束对话。 4. 回复生成 :根据当前对话状态和用户的输入生成自然回复。
对话管理的实现可以使用现成的框架如Rasa或通过自定义Python代码来实现。下图展示了基本的对话管理流程:
graph LR
A[用户输入] --> B[意图识别]
B --> C[实体提取]
C --> D[对话策略]
D --> |提供信息| E[生成回复]
D --> |请求信息| F[生成回复]
D --> |结束对话| G[结束对话]
E --> H[发送回复]
F --> H[发送回复]
2.2 语音对话系统的设计目标
2.2.1 用户体验
在设计语音对话系统时,用户体验(UX)是至关重要的。系统的响应速度、准确性、自然度以及与用户的交互方式,都会直接影响用户的满意度。为了提供良好的用户体验,语音对话系统需要做到以下几点:
- 快速响应用户输入。
- 准确地理解和处理用户的请求。
- 以自然、流畅的方式回应用户。
- 提供清晰的错误处理和帮助信息。
- 支持多种语言和方言,特别是本地用户的语言习惯。
2.2.2 系统准确性和效率
系统准确性和效率是衡量语音对话系统性能的关键指标。高准确性的语音识别和自然语言理解算法可以减少用户的误解和重复询问,提高用户满意度。效率意味着系统能够快速处理请求,并提供及时的反馈。
为了实现高准确性和效率,开发团队需要进行以下几个方面的优化: - 确保语音识别库或API的选择适合应用环境和用户群体。 - 使用高性能的硬件和优化过的算法来减少处理时间和延迟。 - 对于使用机器学习的系统,持续收集数据并训练模型以提高识别和理解的准确性。
2.2.3 硬件和软件的协同工作
树莓派作为一个嵌入式硬件设备,在与软件协同工作时,需要注意以下几点: - 选择与树莓派兼容的硬件组件,如麦克风、扬声器等。 - 软件层面上,选择轻量级且高效的软件包,以免超出树莓派的计算能力。 - 确保软件和硬件的集成是流畅的,比如通过适当配置音频输入输出设备来避免音量问题或延迟。
在设计语音对话系统时,需要在用户需求、技术实现和硬件能力之间找到一个平衡点,确保系统的整体性能和稳定性。
3. 树莓派操作系统安装
3.1 树莓派系统的安装步骤
3.1.1 准备工作和硬件要求
安装树莓派操作系统是让树莓派运行起来的第一步。在开始之前,我们需要确保以下准备工作和硬件要求得到满足:
- 硬件列表 :
- 树莓派(建议选择性能较好的型号,如3B+或4B以获得更佳体验)。
- 高速SD卡(至少16GB,Class 10以上,推荐使用32GB以获得更好的扩展性)。
- 读卡器(用于将操作系统镜像写入SD卡)。
- 电源适配器(输出为5V,2A或更高,确保稳定供电)。
- 显示器和HDMI线(用于初次设置和测试)。
-
键盘和鼠标(USB接口设备)。
-
软件需求 :
- 操作系统镜像文件(推荐使用Raspbian,这是官方提供的针对树莓派优化的Linux发行版)。
-
SD卡写入工具(如balenaEtcher)。
-
准备工作 :
- 确认SD卡完好无损,并且容量符合安装要求。
- 下载所需版本的Raspbian操作系统镜像文件。
- 备份SD卡上的所有重要数据(在写入镜像前)。
- 安装SD卡写入工具,并确认可以正常使用。
3.1.2 下载和安装Raspbian系统
Raspbian是一个为树莓派定制的Linux发行版,它针对ARM处理器架构进行了优化。以下是下载和安装Raspbian系统的详细步骤:
- 下载Raspbian :
- 访问Raspbian的官方网站下载最新的操作系统镜像。
-
选择适合树莓派型号的Raspbian版本,如Raspbian Buster with desktop(带有桌面的版本)或Raspbian Buster Lite(轻量级无桌面版本)。
-
写入镜像到SD卡 :
- 使用balenaEtcher或其他类似的工具将下载好的Raspbian镜像写入SD卡。
- 打开软件,选择下载好的镜像文件,插入SD卡后,选择对应的SD卡设备。
-
点击Flash开始写入过程,完成后取出SD卡。
-
调整配置文件 (可选):
- 在SD卡中找到boot分区,新建一个名为
config.txt的文件。 - 根据需要修改或添加配置,比如设置分辨率、启用特定功能等。
3.1.3 初次启动和系统配置
初次启动树莓派并进行基本配置,步骤如下:
- 硬件连接 :
- 将SD卡插入树莓派的卡槽中。
- 连接HDMI线到显示器,并选择正确的输入源。
- 连接键盘和鼠标。
-
插入电源适配器启动树莓派。
-
系统初次启动 :
- 按照屏幕上的指示完成初始设置,包括设定地区、语言、时区、密码等。
-
确认网络连接,可以选择有线或者无线网络。
-
软件更新和安装 :
- 点击桌面左下角的“Menu”,选择“Preferences” -> “Raspberry Pi Configuration”。
- 在打开的配置界面中切换到“Interfaces”标签,确保“SSH”选项为“Enabled”,允许远程访问。
- 在命令行界面中,执行以下命令来更新系统软件包:
bash sudo apt update sudo apt full-upgrade -y - 重启树莓派以应用更新:
bash sudo reboot
3.2 系统优化和更新
3.2.1 更新软件包和系统工具
在树莓派上运行一段时间后,建议定期进行软件包和系统工具的更新,以保证系统安全和最新功能的使用。更新步骤如下:
- 更新软件包 :
bash sudo apt update sudo apt upgrade -y - 清理不再需要的软件包 :
bash sudo apt autoremove
3.2.2 系统性能调优
树莓派虽然功能强大,但其硬件资源有限,适当调优可以提升整体性能。调优建议如下:
- 禁用不必要的服务和守护进程 ,例如蓝牙和Avahi服务:
bash sudo systemctl disable hciuart sudo systemctl disable avahi-daemon - 调整图形桌面性能 :
- 编辑
/etc/sysctl.conf文件,添加以下配置以提高帧率:bash sudo nano /etc/sysctl.conf在文件中添加:vm.swappiness=10 vm.dirty_background_ratio=5 vm.dirty_ratio=10 -
应用更改:
bash sudo sysctl -p -
调整交换空间设置 :
- 创建或调整交换文件大小,释放更多内存给系统使用:
bash sudo dphys-swapfile swapoff sudo nano /etc/dphys-swapfile修改CONF_SWAPSIZE的值为期望的交换空间大小(单位为KB),例如1024(1GB):CONF_SWAPSIZE=1024然后启用交换空间:bash sudo dphys-swapfile swapon
以上步骤可以帮助您安装和优化树莓派操作系统,为接下来的项目做好准备。
4. 网络配置与SSH服务
4.1 网络配置基础
4.1.1 有线网络设置
在树莓派上配置有线网络相对简单。首先,确保你的树莓派已连接到显示器、键盘和鼠标。一旦设备正常启动,你需要打开终端以输入命令行操作。
要设置静态IP地址,可以通过修改 /etc/dhcpcd.conf 文件来实现。以下是一个静态IP地址设置的例子:
interface eth0
static ip_address=192.168.1.10/24
static routers=192.168.1.1
static domain_name_servers=192.168.1.1 8.8.8.8
在这个配置中: - interface eth0 指定了有线网络接口。 - static ip_address 设置了树莓派的IP地址以及子网掩码。 - static routers 设置了默认网关。 - static domain_name_servers 设置了DNS服务器。
使用 sudo 命令编辑文件,并保存更改。之后,你可以重启网络服务以使更改生效:
sudo service dhcpcd restart
4.1.2 无线网络设置
如果你需要通过无线网络连接树莓派,首先需要确认树莓派模型支持无线功能。当前大多数树莓派模型都内置了Wi-Fi硬件。
配置无线网络,你同样需要编辑 dhcpcd.conf 文件,但要添加不同的配置行:
interface wlan0
static ip_address=192.168.1.11/24
static routers=192.168.1.1
static domain_name_servers=192.168.1.1 8.8.8.8
另外,如果需要连接到特定的Wi-Fi网络,可以使用 wpa_supplicant.conf 文件进行配置:
network={
ssid="你的网络名称"
psk="你的网络密码"
key_mgmt=WPA-PSK
}
之后,重启 wpa_supplicant 服务和 dhcpcd 服务:
sudo service wpa_supplicant restart
sudo service dhcpcd restart
4.2 SSH服务的设置和使用
4.2.1 安装和启动SSH服务
SSH(Secure Shell)是一种网络协议,用于在不安全的网络中为计算机之间提供安全的加密通信。树莓派默认不启用SSH服务,但可以通过简单的步骤启用它。
安装并启动SSH服务的命令如下:
sudo apt-get update
sudo apt-get install openssh-server
sudo systemctl start ssh
上述命令首先更新软件包列表,然后安装 openssh-server ,最后启动SSH服务。
4.2.2 远程连接管理
一旦SSH服务在树莓派上运行,你可以在任何计算机上远程连接到树莓派。在Windows系统上,你可以使用PuTTY来连接。在Linux或macOS系统上,可以使用内置的 ssh 命令。
连接到树莓派的命令格式如下:
ssh 用户名@树莓派IP地址
例如:
ssh pi@192.168.1.10
连接成功后,你会被提示输入密码。密码输入正确后,你将能够在远程终端中完全控制树莓派。
为了提高安全性,建议更改默认的SSH端口,并为SSH服务设置密钥认证。这可以通过修改 /etc/ssh/sshd_config 文件来完成,例如:
Port 2222
PubkeyAuthentication yes
更改配置后,重启SSH服务以应用更改:
sudo systemctl restart ssh
在远程连接到树莓派时,请确保遵守网络安全最佳实践,比如使用复杂的密码,定期更新SSH密钥,并使用VPN来提供额外的安全层。
5. Python环境和库安装
5.1 Python环境的搭建
5.1.1 安装Python解释器
Python是一种广泛使用的高级编程语言,以其简洁明了的语法和强大的功能库而闻名。在树莓派上搭建Python环境是构建任何Python应用程序的先决条件。安装Python解释器是实现这一目标的第一步。
首先,我们需要连接到树莓派。如果你已经正确安装了SSH服务,你可以使用任何支持SSH的终端来连接到树莓派。使用树莓派的IP地址、用户名和密码进行连接。
登录后,打开终端,然后输入以下命令来安装最新版本的Python:
sudo apt-get update
sudo apt-get install python3
这里, sudo 命令用于以超级用户权限运行后续命令, apt-get 是Debian及其衍生系统包管理工具。 update 子命令用来下载包列表, install 子命令用来安装软件包。 python3 是我们要安装的软件包。
安装完成后,可以通过输入 python3 --version 验证Python解释器是否已经正确安装。如果安装成功,系统会显示Python的版本号。
5.1.2 Python环境配置
安装好Python解释器之后,接下来是配置Python环境。Python环境配置涉及到安装Python包、设置环境变量、配置虚拟环境等步骤。在Python中使用虚拟环境是推荐的做法,它允许你在隔离的环境中安装包,避免不同项目之间的依赖冲突。
创建一个虚拟环境:
mkdir myproject
cd myproject
python3 -m venv venv
上述命令首先创建了一个名为 myproject 的目录,用于存放项目文件,并进入该目录。然后使用 venv 模块创建了一个新的虚拟环境,名为 venv 。
激活虚拟环境的命令依操作系统的不同而不同。在Windows系统下,你可以使用:
venv\Scripts\activate
在Unix或MacOS系统下,使用:
source venv/bin/activate
一旦虚拟环境被激活,你可以使用 pip (Python包安装器)安装需要的Python库。 pip 应该会在Python安装过程中被一同安装,可以通过输入 pip --version 来确认。
5.2 重要库的安装和介绍
5.2.1 安装语音处理库
在开发语音对话系统时,你可能需要安装一些专门处理语音的Python库。 SpeechRecognition 是一个流行的库,它可以用来识别语音并将其转换为文本。要安装这个库,首先确保虚拟环境是激活状态,然后运行以下命令:
pip install SpeechRecognition
SpeechRecognition 依赖于其他一些库来获取音频输入,例如 PyAudio 。如果在安装时遇到错误提示缺少 PyAudio ,你可以通过安装 portaudio19-dev 来解决依赖问题,如下:
sudo apt-get install portaudio19-dev
pip install PyAudio
安装完成后,可以通过一个简单的脚本来测试语音识别功能:
import speech_recognition as sr
r = sr.Recognizer()
with sr.Microphone() as source:
print("Please say something...")
audio = r.listen(source)
try:
print("You said: " + r.recognize_google(audio))
except sr.UnknownValueError:
print("Sorry, I did not understand that.")
except sr.RequestError:
print("Sorry, my speech service is down.")
5.2.2 安装对话管理库
对话管理库是语音对话系统中关键的组件之一。 ChatterBot 是一个用于构建聊天机器人的Python库,它提供了一系列工具来训练聊天机器人进行对话。安装ChatterBot的命令如下:
pip install chatterbot
pip install chatterbot_corpus
安装完成后,你可以创建一个简单的聊天机器人并训练它识别简单的语句:
from chatterbot import ChatBot
from chatterbot.trainers import ChatterBotCorpusTrainer
chatbot = ChatBot('ExampleBot')
trainer = ChatterBotCorpusTrainer(chatbot)
trainer.train('chatterbot.corpus.english')
5.2.3 第三方库的功能介绍
在使用第三方库进行开发时,了解库的特性和功能对于项目的成功至关重要。以 SpeechRecognition 和 ChatterBot 库为例,下面表格列举了它们的一些核心功能:
| 库名称 | 核心功能 | |--------------|--------------------------------------------------------------| | SpeechRecognition | 实现多种音频源的语音识别,并且支持多种语言。 | | ChatterBot | 提供训练聊天机器人进行对话的功能,包括基于预定义语料库的训练。 |
这些库通过简单的API调用,使得开发者能够轻松集成语音识别和对话管理的能力。而且,这些库的安装和配置相对简单,能够在树莓派这样的小型计算平台上高效运行。对于那些对深度学习、自然语言处理等技术感兴趣的开发者,可以深入研究这些库的内部实现机制,甚至对库本身做出贡献。
6. 语音识别及处理脚本上传与运行
6.1 语音识别脚本的基本结构
在本章节中,我们将探索构建一个基本的语音识别系统所需的脚本结构。理解其基本结构对于开发一个高效和稳定的语音识别应用程序至关重要。
6.1.1 代码框架解析
语音识别脚本通常包含以下主要组件:
- 初始化 :在此部分,我们初始化语音识别引擎和配置必要的参数,如采样率和模型选择。
- 录制音频 :系统将从用户那里录制音频数据。此部分可能包括音频文件的处理或实时音频流的处理。
- 特征提取 :录制的音频数据将被转换为一组用于后续处理的特征。这通常是语音识别过程中最为复杂的部分。
- 解码过程 :此部分负责将特征向量转换成文字。它是语音识别流程中的核心,经常采用机器学习技术,如隐马尔可夫模型(HMM)或深度神经网络(DNN)。
- 后处理 :识别出的文字将被进一步处理以提高识别的准确性。这可能包括词性标注、句法分析等。
6.1.2 核心代码功能介绍
以下是一个简化的Python伪代码示例,用于说明语音识别脚本的核心功能。
import speech_recognition as sr
# 初始化识别器
recognizer = sr.Recognizer()
# 录制音频
with sr.Microphone() as source:
audio_data = recognizer.listen(source)
# 特征提取和识别
try:
text = recognizer.recognize_google(audio_data, language='en-US')
print("You said: " + text)
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
6.1.3 代码逻辑分析
- 初始化 :通过
speech_recognition.Recognizer()创建一个识别器对象。这个对象是与语音识别服务的接口。 - 录制音频 :使用
recognizer.listen(source)方法来录制音频数据,其中source是一个麦克风对象,它被用来指定音频输入的设备。 - 特征提取和识别 :
recognizer.recognize_google()方法使用Google的语音识别服务来解析录制的音频。language参数指定了期望识别的语言代码。 - 异常处理 :脚本包括了处理可能出现的异常情况,比如无法识别的音频或者请求错误。
6.2 脚本的上传和执行
一旦脚本准备就绪,下一步就是将其上传到树莓派并执行。这里我们详细讨论如何上传和运行脚本,并提供一些可能遇到的常见问题及其解决方案。
6.2.1 通过SSH上传脚本
首先,我们需要将脚本上传到树莓派。这通常通过SSH来完成,SSH提供了一种安全的方式来远程执行命令和文件传输。
scp /path/to/your_script.py pi@raspberrypi:/home/pi/scripts
这条命令的作用是从本地计算机复制 your_script.py 文件到树莓派的 /home/pi/scripts 目录下。
6.2.2 脚本的运行和调试
一旦脚本成功上传,我们就可以登录树莓派并执行脚本。
ssh pi@raspberrypi
python /home/pi/scripts/your_script.py
在脚本运行过程中,可能遇到各种问题。这里有几个调试技巧:
- 检查依赖 :确保所有依赖库都已正确安装在树莓派上。
- 查看输出 :仔细查看输出信息,通常错误和警告都会在这里显示。
- 逐步运行 :在脚本中添加打印语句或使用Python的调试器逐步执行代码来定位问题。
- 网络连接 :确保树莓派连接到互联网,因为某些语音识别服务可能需要在线调用。
6.2.3 常见问题及解决方案
| 问题 | 解决方案 | | --- | --- | | 依赖安装错误 | 确认网络连接正常,然后重新运行安装命令 | | 权限不足 | 使用 sudo 前缀或修改文件权限 | | 脚本运行错误 | 查看错误日志,查找问题所在,必要时更新脚本 |
通过遵循上述步骤和解决方案,您应该能够成功地上传和运行语音识别脚本,并在树莓派上构建自己的语音识别系统。
7. 对话逻辑实现及调整
7.1 设计对话逻辑
设计有效的对话逻辑是构建任何语音对话系统的基础。一个成功的对话逻辑应该能够在多种情况下理解用户的意图,并给出恰当的响应。
7.1.1 对话流程的制定
对话流程是指对话系统根据用户的输入确定输出的过程。它类似于一个决策树,根据用户的回答选择不同的路径。举个例子,如果一个系统的目标是处理用户对天气的查询,其对话流程可能如下:
graph TD;
A[开始] --> B[收到输入]
B -->|问天气| C[发送查询请求]
C --> D{有无结果}
D -->|有| E[返回天气信息]
D -->|无| F[请求更多信息]
在设计对话流程时,你需要考虑所有可能的用户输入,并为每种输入准备一个或多个合适的响应。这要求对话系统能够理解多种表达方式,并且能够处理错误的输入。
7.1.2 逻辑条件的设置
逻辑条件是控制对话流程走向的判断点。它们可以基于多种条件,如时间、地点、用户的历史交互等。例如,在一个天气查询的对话中,系统需要知道询问者所在的城市才能给出正确的信息。因此,对话系统必须能够识别和处理用户的地理位置信息。
def get_weather(city):
# 这里可以是一个调用天气API的函数
# 假设函数返回一个包含天气信息的字典
weather_info = get_weather_api(city)
if weather_info:
return weather_info
else:
return "无法获取天气信息,请检查您的输入是否正确。"
在这个函数中,我们设定的逻辑条件是用户必须提供一个有效的城市名称,系统才能继续执行后续的操作。
7.2 对话效果的调整和优化
为了使对话系统更加流畅和自然,必须对其进行调整和优化。这包括实时光交互测试和错误处理。
7.2.1 实时交互测试
实时交互测试是对话逻辑测试的重要组成部分。通过和真实用户的对话,系统开发者可以收集反馈并发现潜在的问题。测试过程中,需要记录以下几点:
- 用户是否容易理解系统的意图?
- 系统是否能够准确理解用户的意图?
- 系统响应是否自然、及时?
- 是否有重复的问题或错误响应?
例如,我们可以使用如下的伪代码记录测试结果:
def test_conversation():
test_cases = [
{"user_input": "今天天气怎么样?", "expected": "今天多云转晴。"},
{"user_input": "想听笑话", "expected": "给你讲个笑话。"}
]
for case in test_cases:
user_input = case["user_input"]
expected = case["expected"]
response = get_system_response(user_input)
if response == expected:
print(f"测试通过: {user_input}")
else:
print(f"测试失败: {user_input}, 系统响应: {response}, 期望响应: {expected}")
通过这样的测试,我们可以对对话系统进行微调,以提高其性能。
7.2.2 错误处理和反馈
在对话系统中,错误处理机制是必不可少的。它确保即使在发生错误时,用户也能获得有用的反馈,并且系统能够适当地恢复对话流程。常见的错误处理包括:
- 回复错误消息:"对不起,我不理解您的意思。能否请您提供更多信息?"
- 引导用户重新输入:"您似乎输入了一个无效的命令,我们能重新开始吗?"
- 转给人工客服:"抱歉,我遇到问题了。我现在将您转接到人工服务。"
以下是处理错误的简单伪代码示例:
def handle_error(error_type):
if error_type == "unknown_command":
return "我不理解这个命令,请重新输入或告诉我需要帮助。"
elif error_type == "syntax_error":
return "您的输入有语法错误,请重新输入。"
else:
return "发生了一个错误,现在将您转接给人工客服。"
对话系统中的错误处理机制应该能够覆盖所有可能的错误场景,并且提供清晰的指引,以减少用户挫折感。
简介:树莓派语音对话系统是一项基于树莓派计算机平台的智能交互技术,适合初学者用于提升编程技能并理解AI应用。本指南详述了如何在树莓派上建立一个基础的语音对话机器人,涵盖了硬件设置、软件安装、代码实现和问题解决。文档包含使用WinSCP安全传输文件和关键的Python脚本来处理语音识别及对话逻辑。通过该指南,初学者可以学习树莓派、Python编程和AI语音技术。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 13
13 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)