通过 TensorFlow Similarity 自监督学习提高模型准确率
发布人:Google 的 Elie Bursztein、Owen VallisTensorFlow Similarity 现已支持关键的自监督学习算法,以帮助您在没有大量标记数据时提高模型...


发布人:Google 的 Elie Bursztein、Owen Vallis
TensorFlow Similarity 现已支持关键的自监督学习算法,以帮助您在没有大量标记数据时提高模型准确率。
-
TensorFlow Similarity
https://blog.tensorflow.org/2021/09/introducing-tensorflow-similarity.html
-
自监督
https://developers.google.cn/machine-learning/glossary#self-supervised-learning
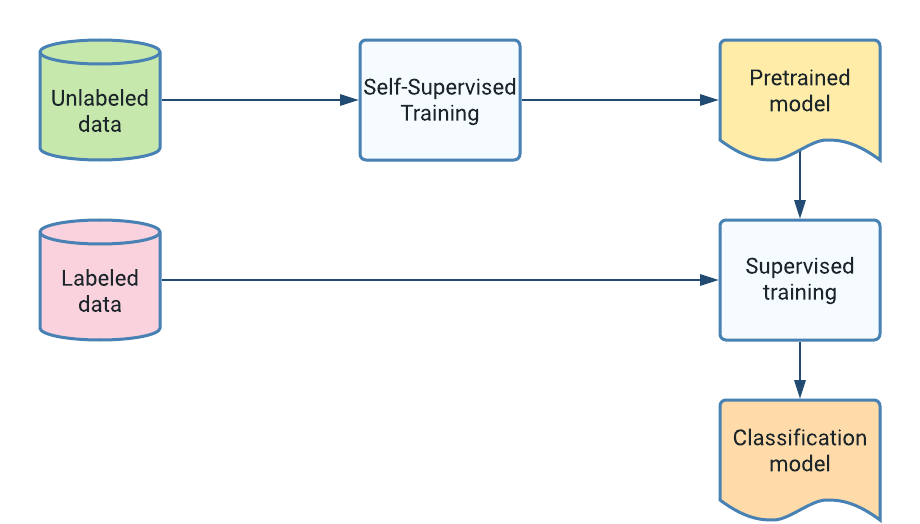
基本自监督训练
通常在训练新的机器学习分类器时,我们拥有的未标记数据(例如照片)比标记示例要多得多。自监督学习技术旨在利用这些未标记的数据来学习有用的数据表征,通过对这些未标记示例进行预训练来提高分类器的准确率。在某些情况下,利用大量未标记数据可以显著提高模型的准确率。
最熟知的自监督训练成功案例可能是转换器模型,例如 BERT,它通过使用大量文本(例如维基百科或网页)进行预训练来学习有意义的语言表征。
自监督学习可以应用于任何类型的数据和各种数据规模。例如,如果您只有几百张标记图像,则可以使用自监督学习,通过在 ImageNet 等中等规模数据集上进行预训练来提高模型的准确率。又如,SimCLR 使用 ImageNet ILSVRC-2012 数据集来训练表征,然后在 CIFAR、Oxford-IIIT Pets、Food-101 等 12 个其他图像数据集上评估迁移学习性能。自监督学习也适用于更大规模的数据集,对数十亿个示例进行预训练同样可以提高准确率,包括文本转换器和视觉转换器。
-
文本转换器
https://arxiv.org/abs/2101.00027
-
视觉转换器
https://arxiv.org/abs/2106.04560v1
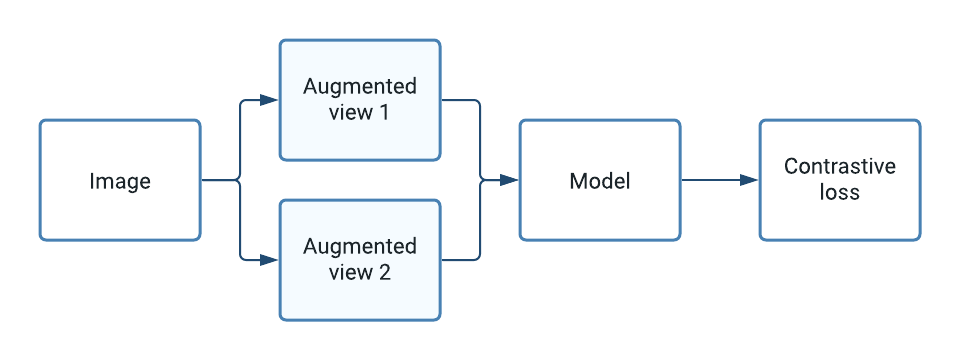
自监督学习如何作用于图像的简要描述
自监督学习的核心是通过对比同一示例的两个增强“视图”来提高模型准确率。模型目标是最大化这些视图之间的相似性,以学习对下游任务有用的表征,例如训练监督式分类器。在实践中,在对大量未标记图像进行预训练之后,通过在冻结的预训练表征之上添加一个 softmax 密集层来训练图像分类器,并像往常一样使用少量标记示例进行训练。

hello world 笔记本中 CIFAR10 上的增强视图对示例
TensorFlow Similarity 目前提供了三种学习自监督表征的关键方法:SimCLR、SimSiam、Barlow Twins(都是开箱即用), 并提供了所有必要的组件来实现其他形式的无监督学习,包括回调、指标和数据采样器等。
-
SimSiam
https://arxiv.org/abs/2011.10566
-
Barlow Twins
https://arxiv.org/abs/2103.03230
您可以利用自监督学习 hello world 笔记本开始探索如何在 CIFAR10 上将准确率翻倍。
-
hello world
https://github.com/tensorflow/similarity/blob/master/examples/unsupervised_hello_world.ipynb
 点击屏末 | 阅读原文 | 访问 TensorFlow 官网
点击屏末 | 阅读原文 | 访问 TensorFlow 官网




魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)