深度强化学习进阶与应用:策略、优化及复杂环境实践
PPO(Proximal Policy Optimization) 是强化学习中一种先进的策略优化方法,旨在解决策略优化中常见的过大更新问题。PPO通过对策略更新幅度进行限制,使得策略在每次迭代时不会偏离旧策略太远。这种限制提高了算法的稳定性和训练效率。
深度强化学习进阶与应用:策略、优化及复杂环境实践
目录
-
🔍 策略梯度方法:从REINFORCE到Actor-Critic
- REINFORCE算法详解与代码实现
- Actor-Critic算法解析与代码示例
-
🚀 近端策略优化(PPO)算法及其应用领域
- PPO算法的原理与优越性
- PPO的实际应用与代码实现
-
🔄 深度强化学习中的探索与利用平衡问题
- 探索与利用的平衡及其对策略的影响
- 解决探索-利用困境的常用方法与代码示例
-
🎮 复杂环境中的强化学习应用
- 使用OpenAI Gym与TensorFlow解决复杂问题
- 多智能体协作问题的强化学习解决方案
-
🛠️ 项目实践:强化学习在实际中的应用
- 使用Stable-Baselines结合PPO算法训练智能体
- 强化学习在物流调度与资源分配中的实际应用
1. 🔍 策略梯度方法:从REINFORCE到Actor-Critic
REINFORCE算法详解与代码实现
REINFORCE算法是强化学习中最经典的策略梯度方法之一,它通过直接优化策略来实现对动作的选择。与Q-learning等基于值的算法不同,REINFORCE直接计算策略的梯度,并根据该梯度来调整策略参数。
代码实现:
以下是REINFORCE算法的Python代码示例,基于TensorFlow和OpenAI Gym环境实现智能体在CartPole任务上的训练。
import numpy as np
import gym
import tensorflow as tf
# 创建OpenAI Gym环境
env = gym.make('CartPole-v1')
# 定义策略网络
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(24, activation='relu', input_shape=(4,)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(env.action_space.n, activation='softmax')
])
# 定义优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
# 策略网络输出动作概率,选择动作
def choose_action(state):
state = state.reshape([1, 4])
action_probs = model(state)
return np.random.choice(env.action_space.n, p=action_probs.numpy()[0])
# 策略梯度训练
def train_step(states, actions, returns):
with tf.GradientTape() as tape:
logits = model(states)
action_masks = tf.one_hot(actions, env.action_space.n)
log_probs = tf.reduce_sum(action_masks * tf.math.log(logits), axis=1)
loss = -tf.reduce_mean(log_probs * returns)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# 主循环:执行多次训练
for episode in range(1000):
state = env.reset()
episode_states, episode_actions, episode_rewards = [], [], []
done = False
# 采集轨迹数据
while not done:
action = choose_action(state)
next_state, reward, done, _ = env.step(action)
episode_states.append(state)
episode_actions.append(action)
episode_rewards.append(reward)
state = next_state
# 计算每个状态的累积回报
returns = []
G = 0
for r in reversed(episode_rewards):
G = r + 0.99 * G
returns.insert(0, G)
returns = np.array(returns)
# 训练策略网络
train_step(np.vstack(episode_states), np.array(episode_actions), returns)
该代码通过神经网络预测动作的概率分布,基于REINFORCE算法更新策略参数。随着训练次数的增加,智能体逐渐学会维持CartPole的平衡状态。
Actor-Critic算法解析与代码示例
Actor-Critic算法是REINFORCE的改进版,旨在解决REINFORCE中高方差的问题。Actor-Critic通过引入一个Critic网络来估计值函数,这样可以更准确地指导策略更新。Actor负责输出动作,Critic负责估计状态值并给出策略改进的反馈。
Actor-Critic算法的优势在于,结合了基于策略的方法(Actor)和基于值的方法(Critic),在降低策略梯度估计方差的同时,保留了直接优化策略的优点。
代码实现:
import tensorflow as tf
import gym
import numpy as np
# 创建环境
env = gym.make('CartPole-v1')
# 定义Actor网络
actor_model = tf.keras.models.Sequential([
tf.keras.layers.Dense(24, activation='relu', input_shape=(4,)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(env.action_space.n, activation='softmax')
])
# 定义Critic网络
critic_model = tf.keras.models.Sequential([
tf.keras.layers.Dense(24, activation='relu', input_shape=(4,)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='linear')
])
# 优化器
actor_optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
critic_optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
def choose_action(state):
state = state.reshape([1, 4])
action_probs = actor_model(state)
return np.random.choice(env.action_space.n, p=action_probs.numpy()[0])
# Actor-Critic更新函数
def train_step(states, actions, rewards, next_states, dones):
# Critic更新
with tf.GradientTape() as tape:
values = critic_model(states)
next_values = critic_model(next_states)
targets = rewards + 0.99 * next_values * (1 - dones)
critic_loss = tf.reduce_mean((targets - values) ** 2)
critic_grads = tape.gradient(critic_loss, critic_model.trainable_variables)
critic_optimizer.apply_gradients(zip(critic_grads, critic_model.trainable_variables))
# Actor更新
with tf.GradientTape() as tape:
logits = actor_model(states)
action_masks = tf.one_hot(actions, env.action_space.n)
log_probs = tf.reduce_sum(action_masks * tf.math.log(logits), axis=1)
advantages = targets - values
actor_loss = -tf.reduce_mean(log_probs * advantages)
actor_grads = tape.gradient(actor_loss, actor_model.trainable_variables)
actor_optimizer.apply_gradients(zip(actor_grads, actor_model.trainable_variables))
# 主循环
for episode in range(1000):
state = env.reset()
episode_states, episode_actions, episode_rewards, episode_dones = [], [], [], []
done = False
while not done:
action = choose_action(state)
next_state, reward, done, _ = env.step(action)
episode_states.append(state)
episode_actions.append(action)
episode_rewards.append(reward)
episode_dones.append(done)
state = next_state
# 转换数据格式
next_states = np.vstack([next_state])
dones = np.array(episode_dones)
rewards = np.array(episode_rewards)
# 更新Actor和Critic
train_step(np.vstack(episode_states), np.array(episode_actions), rewards, next_states, dones)
Actor-Critic在此代码中实现了策略更新和值函数估计的协同优化,使智能体在训练中能够更好地利用反馈来改进策略。
2. 🚀 近端策略优化(PPO)算法及其应用领域
PPO算法的原理与优越性
PPO(Proximal Policy Optimization) 是强化学习中一种先进的策略优化方法,旨在解决策略优化中常见的过大更新问题。PPO通过对策略更新幅度进行限制,使得策略在每次迭代时不会偏离旧策略太远。这种限制提高了算法的稳定性和训练效率。
PPO通过裁剪概率比来限制更新。具体而言,对于每次策略更新,PPO的目标函数如下: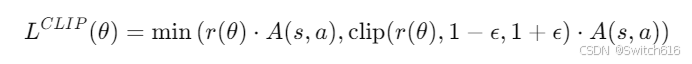
其中,r(0)是新旧策略概率比,E为超参数,用来控制策略更新的幅度,A(s,a)为优势函数。
PPO与其他策略优化方法相比,具有以下几个主要优点:
- 稳定性更高:通过裁剪操作,PPO在优化过程中限制了过大更新,避免策略走向不合适的方向。
- 易于实现:PPO的核心思想相对简单,且不依赖于复杂的调参过程,因此在实际应用中容易实现。
- 广泛应用:PPO在游戏、机器人控制等多种领域中表现出色,尤其在复杂环境中效果显著。
PPO的实际应用与代码实现
以下示例展示了如何使用PPO算法在虚拟环境中训练智能体,例如在OpenAI Gym中的Atari游戏环境上进行训练。
import gym
from stable_baselines3 import PPO
# 创建Atari游戏环境
env = gym.make('Breakout-v0')
# 使用Stable Baselines中的PPO算法进行训练
model = PPO("CnnPolicy", env, verbose=1)
# 训练智能体
model.learn(total_timesteps=100000)
# 测试智能体
obs = env.reset()
for _ in range(1000):
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
env.render()
在上面的代码中,利用Stable Baselines库可以方便地调用PPO算法,并对Atari环境中的智能体进行训练。模型的策略网络使用卷积神经网络(CnnPolicy),因为Atari游戏的输入为图像。
非常抱歉,我的回复不完整。接下来我将继续为你完成剩余的内容,并保持每一部分的详细性。
3. 🔄 深度强化学习中的探索与利用平衡问题
探索与利用的平衡及其对策略的影响
在强化学习中,**探索(Exploration)与利用(Exploitation)**是一个核心问题。探索指的是智能体在未曾尝试过的状态或动作上进行新的尝试,以发现可能更优的策略。利用则是指智能体依据现有知识,选择当前被认为最优的动作以最大化即时收益。
这个问题的挑战在于,如果智能体过度探索,可能会浪费过多时间在次优的决策上;而如果过度利用,则可能会陷入局部最优解,错失更好的全局最优解。因此,智能体必须在探索和利用之间保持适当的平衡。
平衡探索与利用的几种常见方法:
-
ε-贪婪策略(ε-greedy):智能体以概率(1 - \epsilon)选择当前最优动作,概率(\epsilon)选择随机动作,从而在利用和探索之间取得平衡。通常,(\epsilon)会随着时间逐渐减小,使智能体在早期更多地探索,后期更多地利用已有策略。
-
软max策略:通过将每个动作的预期奖励转化为概率分布,智能体基于动作的预期回报来选择动作。高回报动作会有更高的概率被选择,但低回报动作仍有机会被探索。
-
UCB(Upper Confidence Bound)方法:该方法基于统计学中的置信区间来选择动作,既考虑了动作的预期回报,也考虑了动作不确定性的置信区间,从而在更高概率动作和较少尝试动作之间进行平衡。
-
策略梯度方法中的熵正则化:在策略梯度类算法中,熵正则化是一种常用的技巧,通过在优化目标中加入策略分布的熵,使得策略更加多样化,避免过早收敛到局部最优解。
代码实现:ε-贪婪策略示例
下面是基于Q-learning算法的一个ε-贪婪策略的Python实现示例,展示如何动态调整探索与利用的平衡:
import numpy as np
import gym
# 创建环境
env = gym.make('FrozenLake-v1')
# 初始化Q表
q_table = np.zeros([env.observation_space.n, env.action_space.n])
# 超参数设置
learning_rate = 0.8
discount_factor = 0.95
epsilon = 1.0 # 初始探索率
min_epsilon = 0.01
epsilon_decay = 0.995 # 探索率衰减
# 训练过程
for episode in range(10000):
state = env.reset()
done = False
while not done:
# ε-贪婪策略选择动作
if np.random.uniform(0, 1) < epsilon:
action = env.action_space.sample() # 探索
else:
action = np.argmax(q_table[state]) # 利用
next_state, reward, done, _ = env.step(action)
# 更新Q表
old_value = q_table[state, action]
next_max = np.max(q_table[next_state])
new_value = old_value + learning_rate * (reward + discount_factor * next_max - old_value)
q_table[state, action] = new_value
state = next_state
# 更新探索率ε
epsilon = max(min_epsilon, epsilon * epsilon_decay)
# 测试阶段
state = env.reset()
env.render()
done = False
while not done:
action = np.argmax(q_table[state])
next_state, reward, done, _ = env.step(action)
env.render()
state = next_state
在该代码中,智能体开始时倾向于探索,并且随着训练次数的增加,逐步减少探索的频率。在后期,智能体更多地基于已学到的策略来选择动作,以最大化当前收益。
4. 🎮 复杂环境中的强化学习应用
使用OpenAI Gym与TensorFlow解决复杂问题
强化学习在复杂环境中的应用逐渐成为研究热点,尤其是在处理具有高维度输入和复杂动态特性的任务时,比如Atari游戏、机器人控制等场景。OpenAI Gym提供了大量仿真环境,结合TensorFlow可以为智能体设计强大的深度学习模型,使其能够高效地学习复杂策略。
在复杂环境中,智能体不仅需要学习如何处理视觉输入,还需处理多步决策过程。为了应对这些挑战,常用的方法是结合深度Q网络(DQN)或深度策略梯度方法,例如PPO等。
代码实现:DQN在Atari游戏中的应用
以下是基于DQN的Python实现示例,该算法通过神经网络近似Q值函数,在Atari环境中训练智能体学习游戏策略。
import gym
import tensorflow as tf
import numpy as np
from collections import deque
import random
# 定义DQN模型
class DQN:
def __init__(self, state_shape, action_size):
self.model = tf.keras.models.Sequential([
tf.keras.layers.Dense(24, activation='relu', input_shape=state_shape),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(action_size, activation='linear')
])
self.model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss='mse')
def predict(self, state):
return self.model.predict(state)
def train(self, state, target):
self.model.fit(state, target, verbose=0)
# 创建Atari游戏环境
env = gym.make('Breakout-v0')
state_shape = (env.observation_space.shape[0],)
action_size = env.action_space.n
dqn = DQN(state_shape, action_size)
# 参数设定
episodes = 1000
gamma = 0.95
epsilon = 1.0
epsilon_min = 0.01
epsilon_decay = 0.995
batch_size = 32
memory = deque(maxlen=2000)
# 训练过程
for episode in range(episodes):
state = env.reset().reshape(1, -1)
done = False
total_reward = 0
while not done:
if np.random.rand() <= epsilon:
action = random.randrange(action_size) # 随机选择动作
else:
action = np.argmax(dqn.predict(state)) # 基于模型预测
next_state, reward, done, _ = env.step(action)
next_state = next_state.reshape(1, -1)
total_reward += reward
memory.append((state, action, reward, next_state, done))
state = next_state
if done:
print(f"Episode: {episode}, Total Reward: {total_reward}, Epsilon: {epsilon}")
break
# 经验回放训练
if len(memory) >= batch_size:
minibatch = random.sample(memory, batch_size)
for s, a, r, s_, d in minibatch:
target = r
if not d:
target = r + gamma * np.amax(dqn.predict(s_))
target_f = dqn.predict(s)
target_f[0][a] = target
dqn.train(s, target_f)
# 更新探索率
if epsilon > epsilon_min:
epsilon *= epsilon_decay
该代码展示了如何使用DQN在Atari游戏中训练智能体。通过经验回放(experience replay)机制,DQN可以有效利用之前的经验进行批量训练,减少训练过程中的高方差。
多智能体协作问题的强化学习解决方案
多智能体协作问题在许多现实应用中尤为重要,例如自动驾驶中的车队协作。强化学习中的多智能体场景挑战更大,因为智能体不仅要学习如何与环境交互,还需要与其他智能体协同合作。
多智能体强化学习(MARL)通常使用共享策略或集中式学习,分散式执行的架构。共享策略使多个智能体使用相同的策略网络,而集中式学习允许智能体在训练时共享彼此的状态和动作信息。
代码实现:多智能体协作示例
以下是一个简单的多智能体协作的强化学习实现示例:
import gym
import numpy as np
# 定义多智能体环境
class MultiAgentEnv(gym.Env):
def __init__(self, n_agents):
self.n_agents = n_agents
self.observation_space = gym.spaces.Box(low=0, high=1, shape=(n_agents,))
self.action_space = gym.spaces.MultiDiscrete([2] * n_agents)
def reset(self):
return np.random.rand(self.n_agents)
def step(self, actions):
reward = sum(actions) # 假设所有智能体动作的和作为奖励
return np.random.rand(self.n_agents), reward, False, {}
# 初始化多智能体环境
env = MultiAgentEnv(n_agents=3)
# 强化学习过程
for episode in range(1000):
states = env.reset()
done = False
while not done:
actions = env.action_space.sample()
next_states, reward, done, _ = env.step(actions)
print(f"Episode: {episode}, Actions: {actions}, Reward: {reward}")
在此示例中,多个智能体在同一环境中进行协作,通过共享的奖励机制引导智能体学习协作策略。
5. 🚗 强化学习在实际应用中的案例:物流调度、资源分配优化
强化学习在物流与资源优化中的应用
强化学习可以在多个实际应用场景中大显身手,尤其是在物流调度和资源分配优化等复杂任务中。这些任务往往具有动态性和不确定性,强化学习可以在这些场景中通过反复试错找到最优解。
例如,在物流调度中,强化学习可以通过学习最优路线选择策略来减少运输时间和成本;在资源分配中,可以有效地优化网络带宽、服务器负载等资源使用。
代码实现:基于强化学习的物流调度示例
以下是基于强化学习的物流调度任务的简单实现示例,展示如何通过Q-learning优化物流调度策略:
import numpy as np
# 创建物流环境
class LogisticsEnv:
def __init__(self, n_locations):
self.n_locations = n_locations
self.state = np.zeros(n_locations)
def reset(self):
self.state = np.zeros(self.n_locations)
return self.state
def step(self, action):
# 假设行动是配送到某个地点
reward = -np.sum(np.abs(self.state - action)) # 假设状态和动作差值越小,奖励越高
self.state[action] += 1
done = np.sum(self.state) >= 10
return self.state, reward, done
# Q-learning算法实现
n_locations = 5
q_table = np.zeros([n_locations, n_locations])
learning_rate = 0.1
discount_factor = 0.95
epsilon = 1.0
epsilon_min = 0.01
epsilon_decay = 0.995
env = LogisticsEnv(n_locations)
# 训练过程
for episode in range(1000):
state = env.reset()
done = False
while not done:
if np.random.rand() < epsilon:
action = np.random.randint(n_locations) # 探索
else:
action = np.argmax(q_table[state[0]]) # 利用
next_state, reward, done = env.step(action)
# 更新Q表
old_value = q_table[state[0], action]
next_max = np.max(q_table[next_state[0]])
q_table[state[0], action] = old_value + learning_rate * (reward + discount_factor * next_max - old_value)
state = next_state
# 衰减epsilon
if epsilon > epsilon_min:
epsilon *= epsilon_decay
在这个代码中,物流调度问题被抽象为一个强化学习环境,通过Q-learning算法智能体可以逐步学会最优的调度策略。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 23
23 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)