综述!推荐系统中的自监督学习
作者|上杉翔二悠闲会·信息检索整理|NewBeeNLP在我们之前分享的『对比学习+推荐』的文章中曾经提到,自监督学习被引入推荐系统领域主要有以下优势:舒缓数据稀疏。一般来说推荐系统的数据集,有点击的监督数据不便于收集,非常少,而且高度稀疏化,因此通过自监督学习是可以对数据进行增强和扩增的;舒缓噪音干扰。不但数据集稀疏,而且比如...

作者 | 上杉翔二
悠闲会 · 信息检索
整理 | NewBeeNLP
在我们之前分享的『对比学习+推荐』的文章中曾经提到,自监督学习被引入推荐系统领域主要有以下优势:
-
舒缓数据稀疏。一般来说推荐系统的数据集,有点击的监督数据不便于收集,非常少,而且高度稀疏化,因此通过自监督学习是可以对数据进行增强和扩增的;
-
舒缓噪音干扰。不但数据集稀疏,而且比如点击数据存在误点错点击等等的现象,因此解决噪音干扰也是自监督学习可以提供的优势。
-
舒缓长尾分布。另外长尾问题甚至冷启动问题也基本是一直伴随着这个领域,所以一些冷门商品和用户的学习在这种情况下会更加的不充分,因此用自监督进行增强也是不错的选择。
今天分享一篇自监督学习用于推荐系统的综述,更为全面地整理Self-Supervised Recommender(SSR)的各方面。先上link:
title:Self-Supervised Learning for Recommender Systems: A Survey
paper:https://arxiv.org/abs/2203.15876
code:https://github.com/Coder-Yu/SELFRec
自监督推荐系统SSR的基本特征
-
通过半自动化的方式获取更多的监督信号。
-
通过一个辅助任务利用增强的数据来微调推荐系统。
-
辅助任务(Pretext task)协助推荐系统任务(Primary task)来完成更高性能的推荐模型。
其中,第一点确定了SSR的基本范围,第二点确定了SSR区别于推荐系统其他领域的问题设置,而第三点阐述了与推荐主任务与辅助任务的关系。
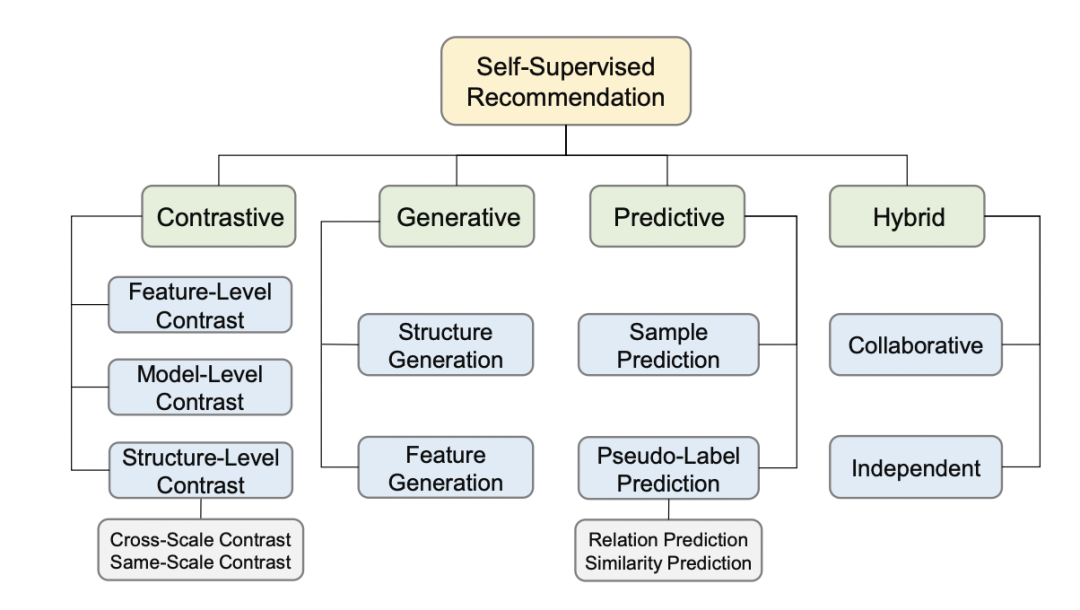
自监督推荐系统SSR的方法分类
-
Contrastive。对比式方法主要思想是通过数据增强任务来拉进两个相近实例的表示,拉远两个不相近实例的距离。
-
Generative。生成式方法主要思想是利用数据当中的一部分来预测另一部分,其是受自然语言处理领域带掩码的语言模型的启发。
-
Predictive。预测式方法与生成式方法类似,其都拥有预测任务。主要思想是利用半监督学习技术来预测富有信息量的新样本或者伪标签。
-
Hybrid。混合式方法主要思想是集成上述提及的任务一种或者多种辅助任务,并利用不同的权重将其整合起来。
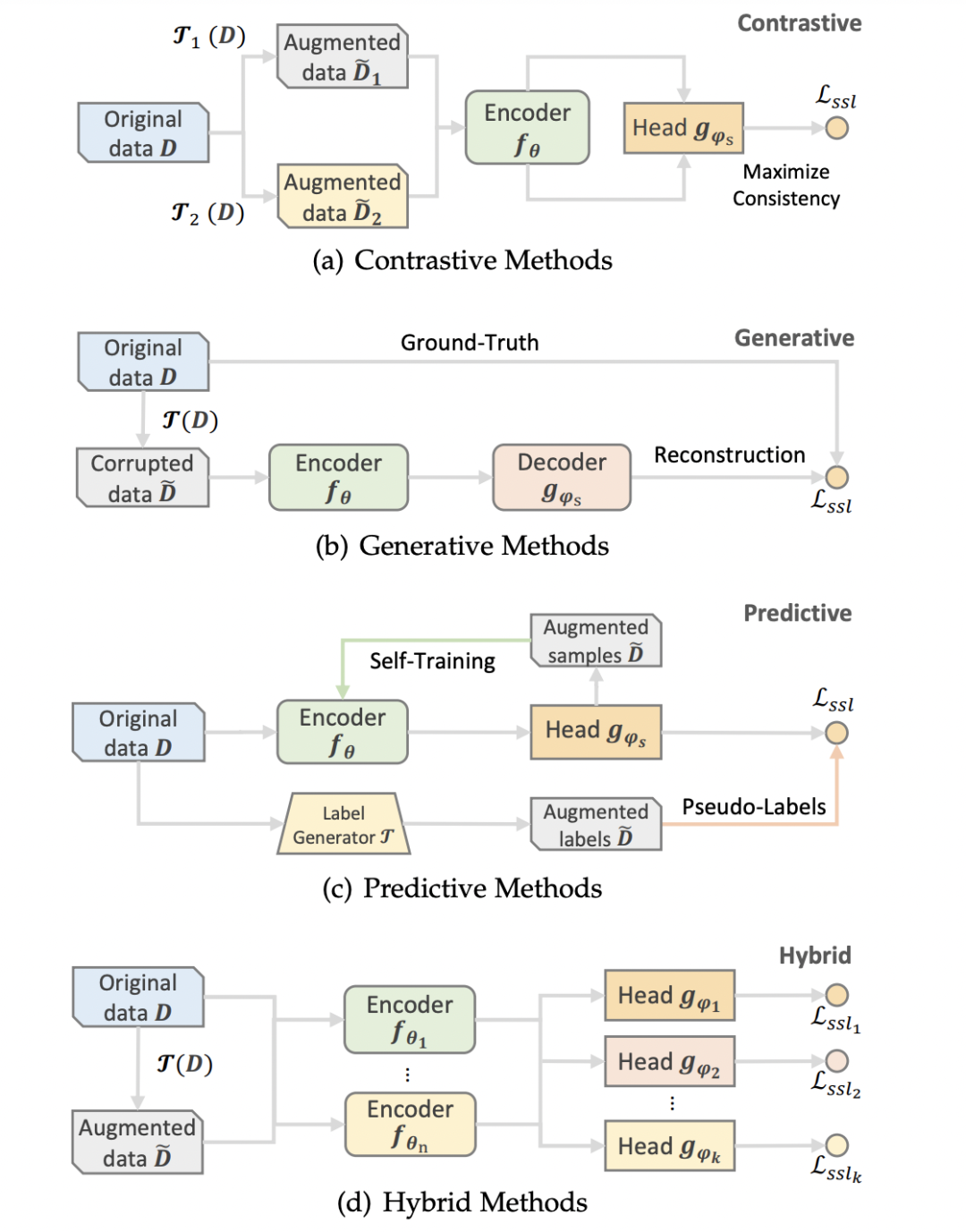
自监督推荐系统SSR的训练方式
-
Joint Learning。联合训练模式主要框架是通过一个共享的编码器来同时优化主任务与辅助任务。
-
Pre-train and Fine-tune。预训练训练模式主要框架是首先在辅助任务上预训练,然后在推荐主任务上进行微调操作。
-
Integrated Learning。综合训练模式通过将主任务与辅助任务进行对齐进而利用整体的损失函数进行优化。
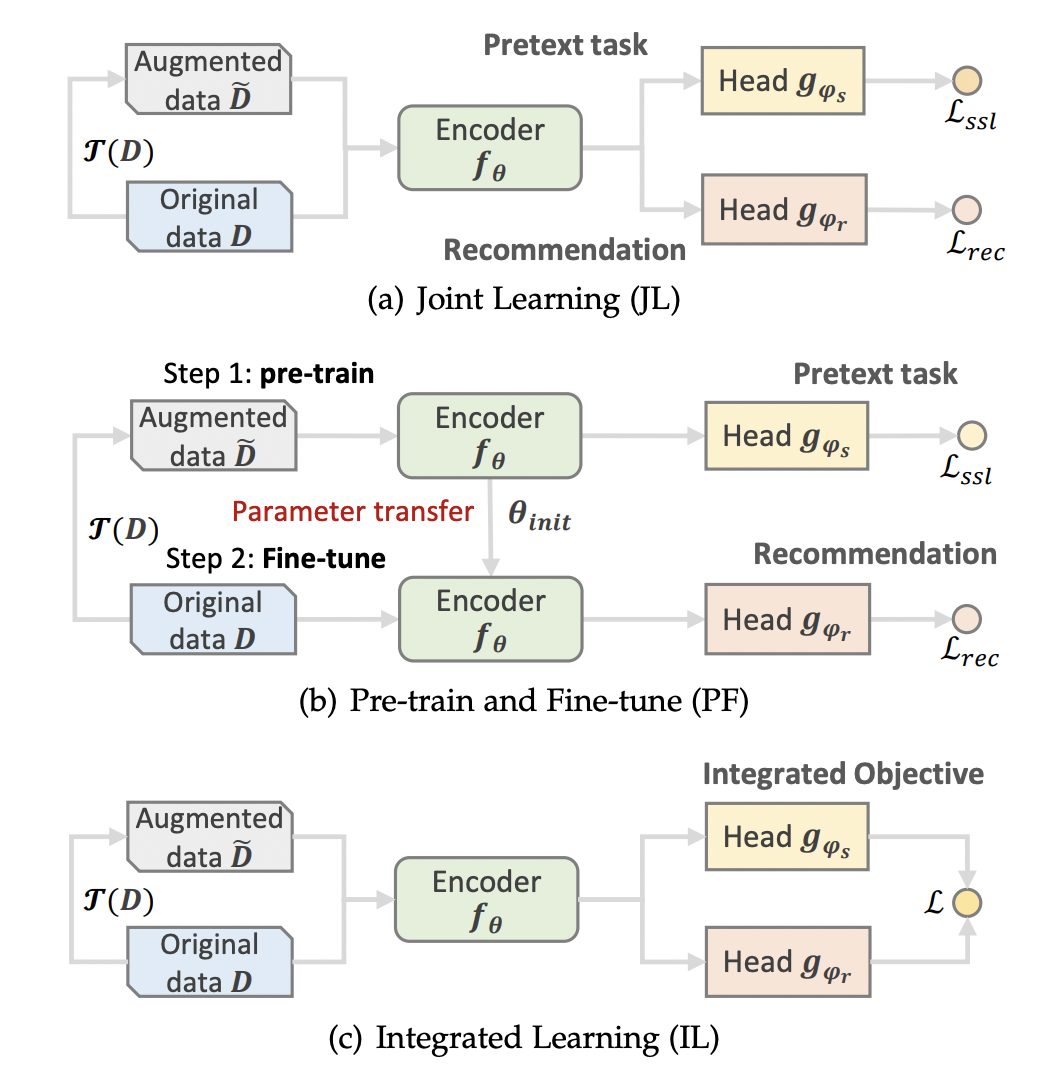
自监督推荐系统SSR的数据增强
-
Sequence-based。主要可以被分为Item Mask,Item Cropping,Item Reordering,Item Substitution与Item Insertion,具体如下图所示的一些操作。
-
Graph-based。主要可以被分为Edge/Node Dropout,Graph Diffusion与Subgraph Sampling
-
Feature-based。主要可以被分为Feature Dropout,Feature Shuffing,Feature Clustering与Feature Mixing。
开源工具包SELFREC
其包括了多个基准数据集以及评价指标,另外还实现了超10种SSR算法。
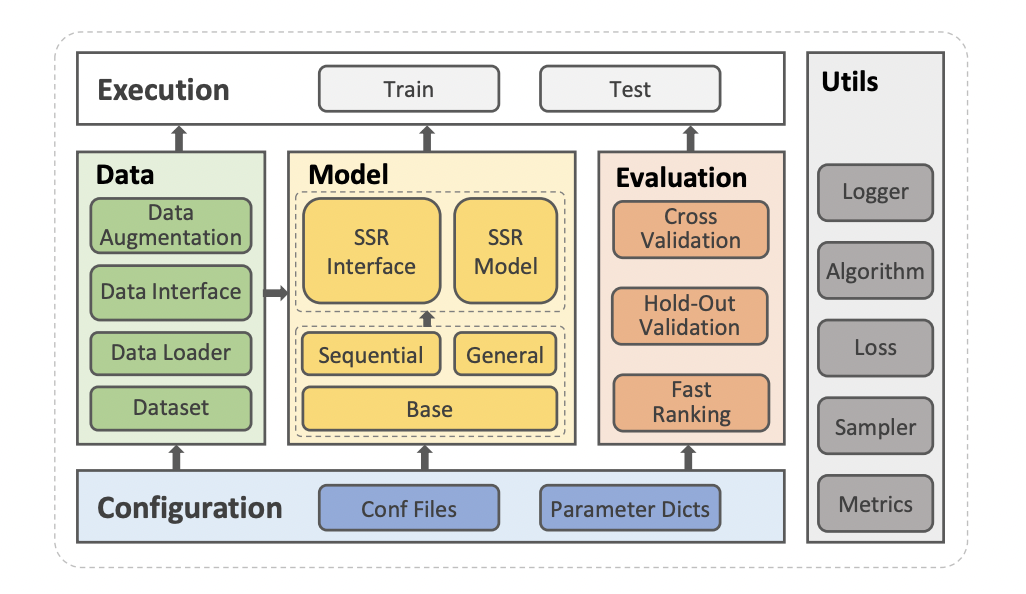
简单贴一下示例code
from SELFRec import SELFRec
from util.conf import ModelConf
if __name__ == '__main__':
#Register your model here
graph_models = ['SGL','SimGCL']#,'BUIR','SelfCF','SEPT','MHCN']
sequential_models = []
dnn_models = []
print('='*80)
print(' SELFRec: A library for self-supervised recommendation. ')
print('='*80)
print('Graph-based Models:')
print(' '.join(graph_models))
print('='*80)
model = input('Please enter the model you want to run:')
import time
s = time.time()
if model in graph_models or model in sequential_models or model in dnn_models:
conf = ModelConf('./conf/' + model + '.conf')
else:
print('Wrong model name!')
exit(-1)
rec = SELFRec(conf)
rec.execute()
e = time.time()
print("Running time: %f s" % (e - s))一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)



魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 3
3 0
0- 0



 已为社区贡献86条内容
已为社区贡献86条内容

所有评论(0)