Memo - 音频驱动图像生成说话数字人视频 一张图生成说话视频 本地一键整合包下载
Memo 是由南洋理工大学和新加坡国立大学主导开发的一种最先进的开放式模型,用于音频驱动的通话视频生成。这是一种端到端的音频驱动肖像动画方法,旨在生成具有身份一致性和富有表现力的口型动画视频。Memo 在各类图像和音频类型上生成更为逼真的口型动画视频,并在总体质量、音频-口型同步、身份一致性和表情-情感对齐方面优于现有的最先进方法。Memo 可以用肖像、雕塑、数字艺术和动画等图像生成会说话的视频;
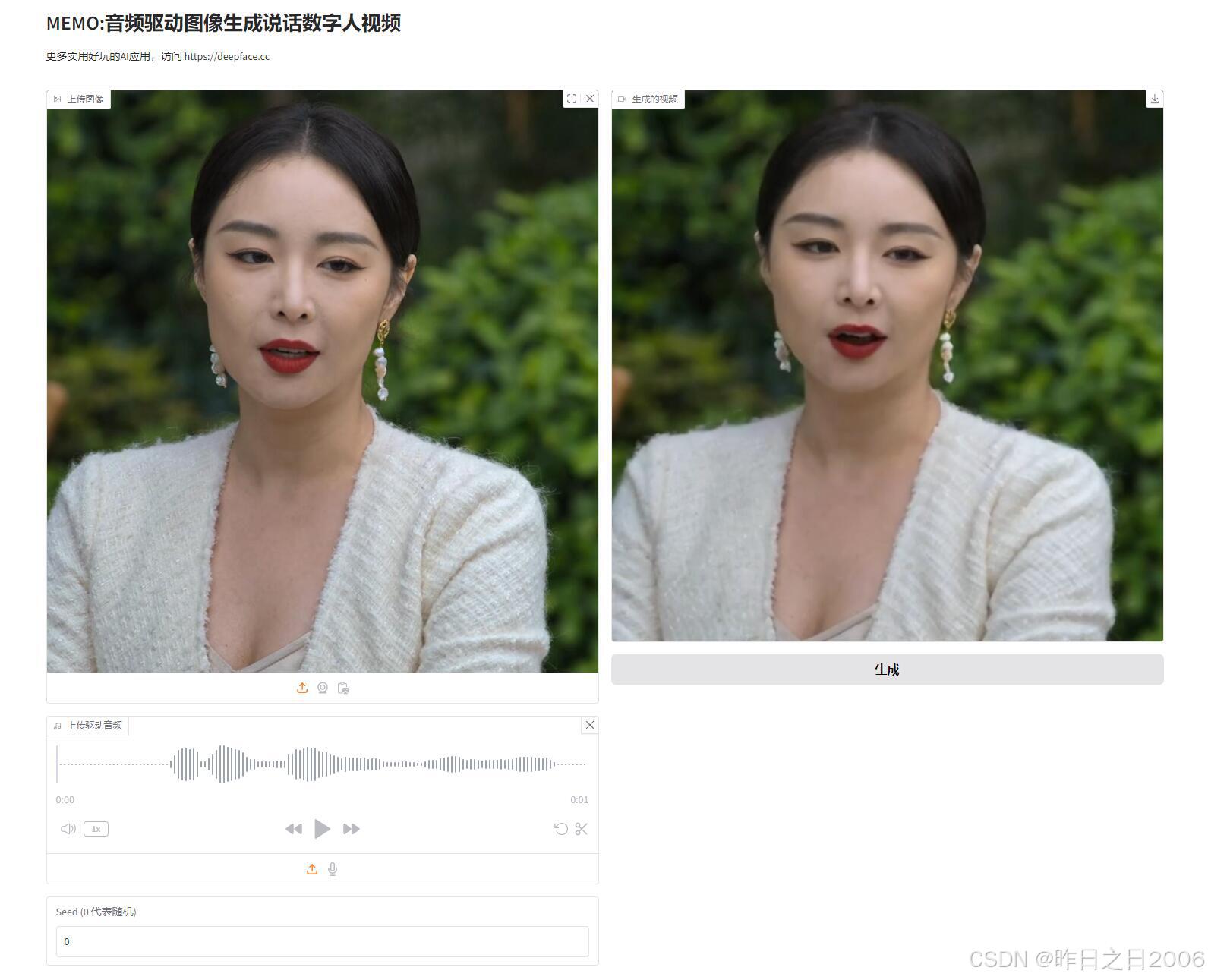
Memo 是由南洋理工大学和新加坡国立大学主导开发的一种最先进的开放式模型,用于音频驱动的通话视频生成。这是一种端到端的音频驱动肖像动画方法,旨在生成具有身份一致性和富有表现力的口型动画视频。
Memo 在各类图像和音频类型上生成更为逼真的口型动画视频,并在总体质量、音频-口型同步、身份一致性和表情-情感对齐方面优于现有的最先进方法。
项目特色:

Memo 可以用肖像、雕塑、数字艺术和动画等图像生成会说话的视频;
Memo 可以生成有声音的视频,音频类型包括演讲、唱歌、说唱;
Memo 支持英语、普通话、西班牙语、日语、韩语和粤语等多种语言;
Memo 可以生成富有表现力的谈话视频或抵消视频中的情绪;
Memo 可以生成具有各种头部姿势的谈话视频;
Memo 可以生成长时间的谈话视频,且伪影和错误累积较少。
使用教程:(当前版本对显卡要求较高,建议N卡,显存12G起,12G显存需开启内存回退)
上传一张照片加一段驱动音频即可生成。
下载地址:评论区回复需要,私信发给你

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 3
3 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)