【监督学习】Supervised learning概述与案例分析简单理解
监督学习-Supervised Learning
什么是监督学习
它是一种机器学习中的训练方法或者学习方式
机器学习训练方法通常有
监督学习、非监督学习、强化学习
那么监督学习:需要具备明确的目标,很清楚自己想要什么结果,比如:按照“既定规则”分类,预测某一个具体的值…
具体流程
- 选择一个适合目标任务的数学模型
- 先把一部分已知的问题和答案给机器去学习
- 机器总结出自己的方法论
- 人类把新问题的测试集给机器,让他去解答
通常,监督体现在第2部分
监督学习的2个任务:回归和分类
针对回归预测,通俗点讲类似于线性回归,针对连续性变量
分类,可以理解成对离散数据的处理,机器将图片辨析为男or女
回归案例
芝麻信用评分原理
通常评估个人信用,我们一样用FICO
步骤一:构建问题,选择模型
首先找出个人信用的影响因素,从逻辑将一个人的体重跟他的信用是没有关系,比如我,身边很讲信用的人,有胖子也有瘦子
从财富资本来讲,跟信用有一定关系,因为马云不将信用的话,损失非常巨大,所有从来没有听说过马云会不还信用卡!而一个乞丐不讲信用的损失很小,这条街混不下去换一条街继续生活乞讨 !!
我们常用这些特征来作为影响因素!
- 付款记录
- 账户总金额
- 信用记录跨度(自开户以来的信用记录、特定类型账户开户以来的信用记录)
- 新账户(近期开户数目、特定类型账户的开户比例)
- 信用类别(各种账户的数目)
Y=f(Xi)Y=f(X_i)Y=f(Xi)
Y 是个人信用评分,下标i表示上述五个影响因素
步骤二:收集已知数据
为了计算Y值,我们要去寻找收集大量的数据,这些数据必须包含每一个人的5中数据和他的信用状态,并且将状态转化为分数
我们把收集好的数据,进行整理【清洗】一部分用来训练,一部分用来测试和验证
步骤三:训练处理想模型
有了这些数据,通过机器学习,就能猜测出这5中数据和评分的关系,这个关系就是表达式fff
然后通过验证数据和测试数据,来验证一下这个表达式
测试验证方法
将5中数据套入公式,计算出信用分,再用计算出的信用分和这个人实际的信用分比较
评分公式的准确度,如果问题很大在进行调整和优化
步骤三:对新用户进行预测
通常我们训练好的模型,在测试上有良好的效果了,我们就可以部署我们的模型,对新用户进行信用评价,只需要收集信用上述的五钟数据,输入模型,计算就可以得到新用户的信用得分!!!
分类案例:通过图像识别男女
步骤一:构建问题,选择模型
通过查阅资料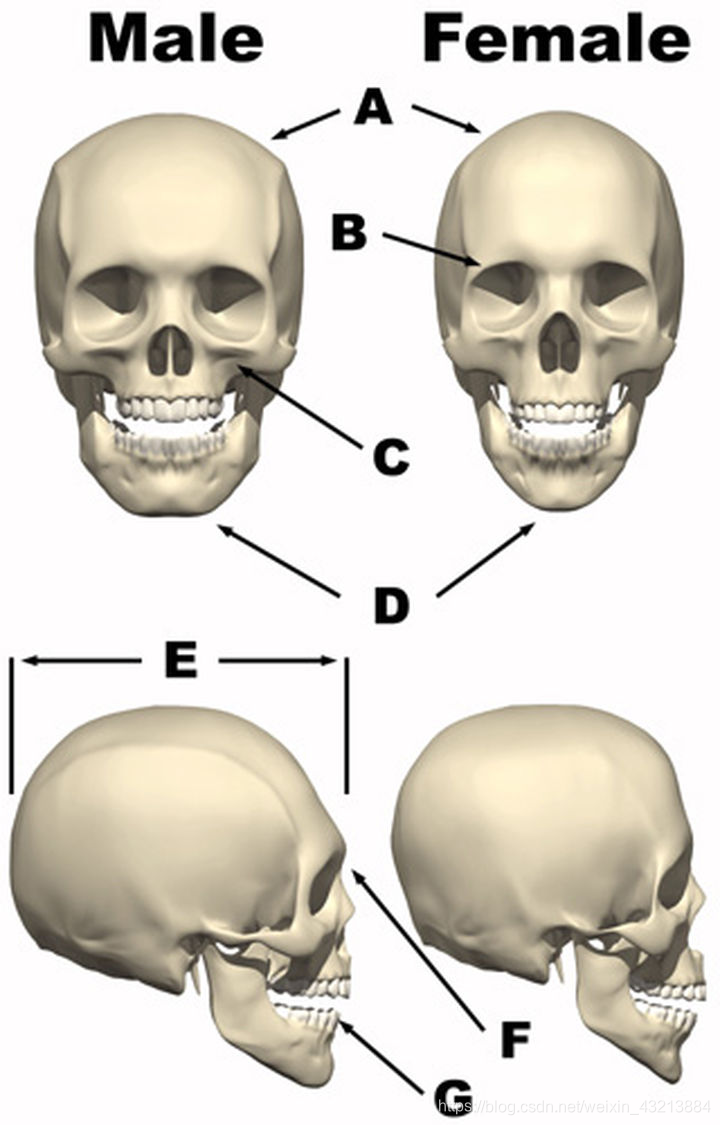
A-男性的顶骨更起棱角,而女性的更圆也更尖。
B-女性的眶上缘比较锐利,而男性的眶上缘是圆的,而且厚重。
C-男性的颧骨也相对女性更明显。
D-女性的下颌骨更圆,男性则是偏向方的。
E-男性额头相对更后倾,有大的颅相深度。
F-男性的眉弓也明显高于女性。
G-下颌角,男性的角度也小于女性。
我们有7个指标可以去判断,男女的面部特征。
恰好,我们也可以建立如上图的一个模型
步骤二:收集已知数据
我们将收集关于上述模型提及的相关数据,但是存在一个问题:所建模型的指标并不是很直观、可量化。比如,顶骨更起棱角。这个棱角的范围?划分的标准是?这些都待于我们去探讨,这里假设数据都是可以量化的,并且已处理呈现成数据格式!
步骤三:训练处理想模型
训练过程如回归,将收集好的数据扔进模型,并输出0-1,这里用01来代表性别,而衡量模型好坏,就去看预测的男在真实中是否为男,这也涉及了分类中对模型评估的评估指标!【后续会涉及】
步骤四:对新用户进行预测
对训练好的模型,并且也通过了验证和测试集,我们将可以将其利用来预测男女性别!
常见的监督学习算法

简言之!!监督学习,会对数据打上人为标签!这里的Y值就是标签值!!那么区分监督学习和非监督学习就可以表述为:
是否打标签

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)