SQL-R1:通过强化学习训练自然语言到SQL推理模型
自然语言到SQL(NL2SQL)通过将自然语言查询转换为结构化的SQL语句,实现了与数据库的直观交互。尽管最近在增强数据库应用中的人机交互方面取得了进展,但在涉及多表连接和嵌套查询的复杂场景中的推理性能仍然存在显著挑战。目前的方法主要利用监督微调(SFT)来训练NL2SQL模型,这可能限制了其在新环境(如金融和医疗领域)中的适应性和可解释性。为了提高NL2SQL模型在上述复杂情况下的推理性能,我们
马培贤 12{ }^{12}12, 庄霞列 13{ }^{13}13, 徐成进 14∗{ }^{14 *}14∗, 姜旭辉 14{ }^{14}14, 陈然 1{ }^{1}1, 郭建 1{ }^{1}1
1{ }^{1}1 IDEA研究院,国际数字经济学院
2{ }^{2}2 香港科技大学(广州)
3{ }^{3}3 中国科学院大学
4{ }^{4}4 DataArc Tech Ltd.
{mapeixian, zhuangxialie, xuchengjin, jiangxuhui, chenran, guojian} @idea.edu.com
摘要
自然语言到SQL(NL2SQL)通过将自然语言查询转换为结构化的SQL语句,实现了与数据库的直观交互。尽管最近在增强数据库应用中的人机交互方面取得了进展,但在涉及多表连接和嵌套查询的复杂场景中的推理性能仍然存在显著挑战。目前的方法主要利用监督微调(SFT)来训练NL2SQL模型,这可能限制了其在新环境(如金融和医疗领域)中的适应性和可解释性。为了提高NL2SQL模型在上述复杂情况下的推理性能,我们引入了SQL-R1,这是一种通过强化学习(RL)算法训练的新型NL2SQL推理模型。我们设计了一个专门针对NL2SQL任务的基于RL的奖励函数,并讨论了密集训练中冷启动对其有效性的影响。此外,我们仅使用少量合成NL2SQL数据进行增强训练即可实现具有竞争力的准确性,并进一步探索了用于RL的数据工程方法。在现有实验中,SQL-R1分别在基准Spider和BIRD上实现了88.6%和66.6%的执行准确率,仅使用7B基础模型。
1 引言
自然语言到SQL(NL2SQL,或Text2SQL)将自然语言问题(NL)转换为结构化的SQL语句,简化了无需数据库专业知识的数据库交互[1, 2]。最近的NL2SQL进展显著增强了数据库查询应用中的人机交互水平,并有助于广泛的数据科学分析任务[3, 4]。当前的NL2SQL模型主要集中在优化工作流及其组件,如模式链接[5, 6]、内容检索[7]、生成校正[8-12]。
尽管有这些进展,提高NL2SQL系统在复杂数据库场景中的推理性能仍然是一个相当大的挑战。如图1所示,模式复杂性可能导致处理多表连接和嵌套查询时生成错误,并且单独训练的模型难以思考和处理复杂的语义。目前,大量的NL2SQL研究致力于通过监督微调(SFT)训练开源大语言模型(LLMs)[13-15],以在较小模型规模下实现准确性,相比使用闭源LLMs(如GPT-4、GPT-4o)的方法[8, 10, 16]。然而,SFT依赖于数据库模式的结构和训练数据规模。这可能导致现有模型在领域适应和泛化到新数据库环境时的不稳定性。
预印本。正在评审中。
*通讯作者。

图1:我们工作的演示。以往关于NL2SQL的研究主要依靠监督微调使模型学习如何生成SQL。然而,在复杂数据库模式或模糊语义的情况下,微调后的模型可能难以生成符合用户意图的SQL,因为它依赖于固定的生成策略和先前的数据。通过引入强化学习算法,模型可以在训练过程中从数据库获得直观反馈。这种反馈鼓励模型独立探索各种SQL生成推理方法,最终提高其输出的准确性。
在领域适应和新数据库环境中的泛化能力有限。此外,NL2SQL推理逻辑缺乏可解释性限制了模型在高风险领域(如金融和医疗保健)中的应用。
最近,强化学习(RL)在训练LLMs的推理能力方面显示出巨大的潜力。与监督微调相比,强化学习可以通过与环境的互动动态调整LLMs的决策策略,从而在复杂推理任务中取得优越表现[17]。基于RL的方法已在提升金融推理[18]、搜索引擎[19]和数学推理[20, 21]的模型推理和泛化能力方面证明有效。
基于上述启发,我们提出了SQL-R1,一种通过强化学习算法训练的NL2SQL推理模型。图1展示了我们工作的概述。在以下章节中,我们将重点回答以下关键问题:
Q1:我们能否为NL2SQL任务设计特定的强化学习算法并成功训练一个NL2SQL推理模型?与SFT相比,RL算法优先直接优化NL2SQL推理,特别是生成能准确反映用户查询意图的SQL查询。为强化学习设计有效的反馈机制是开发NL2SQL推理模型的重大挑战。强化学习框架中适当构建的奖励可以显著提高其性能。
Q2:对于基于RL的NL2SQL推理模型,我们是否需要对其进行特定形式的冷启动?对于现有的基础模型,有效的冷启动可以加强模型的指令跟随能力和激活其NL2SQL生成能力,从而促进其在强化学习探索中生成更高质量的SQL查询。设计冷启动的形式也将是一个重大挑战。
Q3:我们能否部署可持续的数据工程来训练稳健和高效的NL2SQL推理模型?RL训练依赖高质量的训练数据,而当前的NL2SQL任务缺乏大量真实数据进行训练。如何基于现有的数据工程技术为NL2SQL推理模型开发数据支持,解决模型训练问题,提高模型的稳健性和泛化能力是一个重要挑战。
总的来说,这项工作的贡献如下:
- 明确的NL2SQL推理模型:我们提出了SQL-R1,一种在少量NL2SQL数据(例如5K)上训练的NL2SQL推理模型,能够在领先的基准Spider-Test和BIRD上分别实现88.6%和66.6%的准确率,并能输出详细的明确推理过程。
-
- NL2SQL推理模型的训练策略:我们探讨了冷启动训练对SQL-R1性能的影响,并构建了一种基于SFT和RL的训练策略,可以有效提高模型的NL2SQL推理性能。
2 SQL-R1
2.1 概述
本节主要介绍通过RL算法训练NL2SQL模型的两种形式:直接强化训练和通过冷启动后进行强化训练。其中,冷启动指的是首先通过SFT使用特定数据训练基础模型,使其具备特定的思维和遵循指令的能力。此外,由于真实数据有限,我们使用最新的合成数据支持上述训练过程。第2.2节将介绍我们当前的数据工程解决方案,第2.3节将介绍为NL2SQL设计的SFT算法和RL算法。
2.2 数据准备
2.2.1 来源
目前,我们利用SynSQL-2.5M [22] 数据集作为主要数据来源,这是第一个百万规模的合成NL2SQL数据集,包含超过250万个多样且高质量的数据样本。每个样本由一个四元组组成,包括数据库、自然语言问题、SQL查询和链式思维(CoT)解决方案。该数据集涵盖超过16000个跨领域的合成数据库,确保了现实场景的广泛覆盖。SynSQL-2.5M 包括从简单单表查询到复杂多表连接、函数和公用表表达式的各种SQL复杂度级别。
2.2.2 预处理
SFT 数据集 在本研究中,我们调查了SFT中的冷启动条件对RL训练的影响。目前,我们利用从SynSQL-2.5M 中抽取的200,000个样本的数据集进行SFT训练,样本规模在不同难度级别上均匀分布,每个级别包含50000个样本。为清楚起见,我们将在后续章节中将此子集称为SynSQL-200K。需要强调的是,所有SQL真实值的查询结果都是非空值。对于SFT数据集 VVV 中的每个样本 v=(x,t,y∗)v=\left(x, t, y^{*}\right)v=(x,t,y∗),xxx 表示NL,ttt 表示用 . . 标签括起来的推理过程,y∗y^{*}y∗ 表示用 . . 标签括起来的SQL。
RL 数据集 当前的NL2SQL基础模型在生成简单到中等复杂度的SQL查询方面表现出色。然而,在创建更复杂的SQL查询时存在局限性。因此,在训练过程中使用更具挑战性的样本组成的的数据集可能会有助于解决这些缺陷,提高模型整体生成复杂SQL的能力。我们从SynSQL-2.5M 中随机抽取了5K个复杂级别的NL-SQL对。对于RL数据集 VVV 中的每个NL-SQL对 v=(x,y∗)v=\left(x, y^{*}\right)v=(x,y∗),xxx 表示NL,y∗y^{*}y∗ 表示模型生成的SQL候选者。强化学习的目标是提高答案的准确性并确保其符合预期格式。在下一节中将介绍RL数据集为SynSQL-Complex-5K。值得注意的是,RL数据集的输入不包括原始SynSQL-2.5M 的CoT数据。
2.3 训练
2.3.1 监督微调
在本研究中,我们在Qwen2.5-Coder-7B-Instruct模型上进行SFT,以增强模型在NL2SQL领域的指令遵循和生成能力。我们调查了两种不同的SFT冷启动训练策略。第一种策略仅专注于SQL生成的原始指令。我们参考现有的OmniSQL-7B [22] 检查点。第二种策略利用全面的细调和推理生成指令,促进合规思维过程和最终答案的发展。
2.3.2 强化训练
在强化学习阶段,我们采用Group Relative Policy Optimization (GRPO) 算法增强我们的训练协议,这消除了对价值模型的需求,减少了内存需求,并便于清晰定义奖励目标,使其成为优化NL2SQL策略模型的有效选择 [23]。
对于每个与相应数据库模式对齐的自然语言问题,策略模型从旧策略 πold\pi_{o l d}πold 中生成一组 GGG 个SQL候选者 {o1,o2…,oG}\left\{o_{1}, o_{2} \ldots, o_{G}\right\}{o1,o2…,oG},这些候选者使用复合奖励函数进行细致评估,分配特定的奖励分数。通过关注SQL候选者在组内的相对表现,GRPO巧妙地计算每个输出的奖励,从而根据我们设定的目标指导策略更新。
KaTeX parse error: Expected '\right', got '}' at position 438: …\right)\right] }̲ \end{aligned}
其中 riratio =πθ(oi∣V)πold(oi∣V)r_{i}^{\text {ratio }}=\frac{\pi_{\theta}\left(o_{i} \mid V\right)}{\pi_{o l d}\left(o_{i} \mid V\right)}riratio =πold(oi∣V)πθ(oi∣V) 表示重要性采样比率,量化在新策略 πθ\pi_{\theta}πθ 下相对于 πold\pi_{o l d}πold 生成输出 oi 的相对可能性;AiA_{i}Ai 表示每个输出的组相对优势;裁剪算子、超参数 ϵ\epsilonϵ 和 β\betaβ 控制更新步长和散度正则化;πref \pi_{\text {ref }}πref 表示参考策略。
2.3.3 奖励函数设计
在使用强化学习训练NL2SQL奖励模型时,我们利用一种渐进反馈机制,包括四种类型的奖励:格式奖励、执行奖励、结果奖励和长度奖励。这种分层方法通过在各个阶段提供详细反馈来增强模型的学习。
格式奖励 我们鼓励模型将NL2SQL推理过程置于 … 标签内,并将最终答案置于 … 标签内。为了实现SQL查询的更标准化格式,所有SQL语句必须包含在 ’ ’ 'sql … ’ ’ 标签内;未能做到这一点将被视为格式错误。格式奖励函数的结构如下:
Sf={1, 如果格式正确 −1, 如果格式不正确 S_{f}= \begin{cases}1, & \text { 如果格式正确 } \\ -1, & \text { 如果格式不正确 }\end{cases} Sf={1,−1, 如果格式正确 如果格式不正确
执行奖励 执行奖励旨在评估SQL候选者的语法正确性,防止模型生成混乱、不可执行的响应。当SQL候选者无法正确执行时,模型将不会获得后续的所有奖励。此外,我们限制执行时间以防止模型倾向于生成过于复杂的SQL以获取高奖励。
Sc={2, 如果SQL候选者可执行 0, 如果格式不正确 −2, 如果SQL候选者不可执行 S_{c}= \begin{cases}2, & \text { 如果SQL候选者可执行 } \\ 0, & \text { 如果格式不正确 } \\ -2, & \text { 如果SQL候选者不可执行 }\end{cases} Sc=⎩
⎨
⎧2,0,−2, 如果SQL候选者可执行 如果格式不正确 如果SQL候选者不可执行
结果奖励 查询结果的准确性是评估SQL候选者的重要标准。我们将结果奖励作为奖励机制的关键组成部分,旨在激励模型生成符合用户实际意图的SQL候选者。为了评估SQL候选查询结果的正确性和相关反馈,我们使用执行准确性(EX)。在结果不正确的情况下,我们施加严格的惩罚以引导模型进行后续推理。
Sr={3, 如果查询结果正确 0, 如果格式不正确或SQL候选者不可执行 −3, 如果查询结果不正确 S_{r}= \begin{cases}3, & \text { 如果查询结果正确 } \\ 0, & \text { 如果格式不正确或SQL候选者不可执行 } \\ -3, & \text { 如果查询结果不正确 }\end{cases} Sr=⎩ ⎨ ⎧3,0,−3, 如果查询结果正确 如果格式不正确或SQL候选者不可执行 如果查询结果不正确
长度奖励 我们应用长度奖励机制激励模型产生更全面的推理过程。它分为两个部分:第一部分根据答案总长度与最大响应长度的比例关系分配一半的奖励;第二部分根据内SQL候选长度的比例计算剩余一半的奖励,旨在减少响应中冗余解释的发生。当响应超过最大长度时,给予模型惩罚反馈。
Sl={0.5×Stl+Sal, 如果查询结果正确且 lenresponse <= 最大长度 0.5+Sal, 如果查询结果正确且 lenresponse > 最大长度 0, 其他情况 S_{l}= \begin{cases}0.5 \times S_{t l}+S_{a l}, & \text { 如果查询结果正确且 } \operatorname{len}_{\text {response }}<=\text { 最大长度 } \\ 0.5+S_{a l}, & \text { 如果查询结果正确且 } \operatorname{len}_{\text {response }}> \text { 最大长度 } \\ 0, & \text { 其他情况 }\end{cases} Sl=⎩ ⎨ ⎧0.5×Stl+Sal,0.5+Sal,0, 如果查询结果正确且 lenresponse <= 最大长度 如果查询结果正确且 lenresponse > 最大长度 其他情况
其中 Stl=(lenthink +lenanswer )/S_{t l}=\left(\operatorname{len}_{\text {think }}+\operatorname{len}_{\text {answer }}\right) /Stl=(lenthink +lenanswer )/ 最大长度 和 Sal=lensql /lenanswer S_{a l}=\operatorname{len}_{\text {sql }} / \operatorname{len}_{\text {answer }}Sal=lensql /lenanswer 。
2.4 SQL 候选选择
为了在推理过程中选择最合适的SQL,模型会为一个问题生成几个SQL候选者及其思维过程。我们执行所有SQL候选者,并根据一致性投票选择得分最高的SQL作为最终答案。值得注意的是,SQL-R1的推理响应包含一个可观测的思考和解释过程,使结果更容易让用户理解。
3 实验
3.1 设置
评估基准 我们在两个基准Spider [24] 和BIRD [25] 上评估了所提出的SQL-R1及相关NL2SQL模型。Spider 包含来自200个数据库和138个领域的10,181个问题和5,693个复杂SQL查询。BIRD 包含来自37个专业领域的95个数据库中的12,751个NL2SQL对。
指标 为了公平比较,我们遵循以前作品中的标准评估指标。我们在Spider和BIRD基准上使用执行准确性(EX)作为评估指标。EX 用于估计在所有查询请求中,给定查询及其对应的基事实查询产生的结果一致的问题比例。
实施设置 当前,SQL-R1主要建立在Qwen2.5-Coder-7B-Instruct基础上。对于SFT训练,我们将学习率设为5e-5;批量大小设为1。对于RL训练,我们将学习率设为 3e−73 \mathrm{e}-73e−7,actor模型的rollout设为8;最大响应长度设为2048。对于推理,我们将SQL候选数设为8,温度设为0.8 。
表1:不同NL2SQL方法在Spider和BIRD基准上的执行准确性。
| NL2SQL 方法 | 基础模型 | 候选 选择 |
Spider (Dev) |
Spider (Test) |
BIRD (Dev) |
|---|---|---|---|---|---|
| CodeS [14] | CodeS-15B | - | 84.9 | 79.4 | 57.0 |
| CHESS [7] | Deepseek-Coder-33B | - | - | 87.2 | 61.5 |
| CHASE-SQL [28] | Gemimi-1.5-Pro | - | - | 87.6 | 73.0 |
| Alpha-SQL [29] | Qwen2.5-Coder-7B | 自我一致性 | 84.0 | - | 66.8 |
| SQL-o1 [30] | Qwen2.5-Coder-7B | 自我一致性 | 84.7 | 85.1 | 66.7 |
| OmniSQL [22] | Qwen2.5-Coder-7B | 自我一致性 | 81.6 | 88.9 | 66.1 |
| C3-SQL [10] | GPT-3.5-Turbo | 自我一致性 | 82.0 | 82.3 | - |
| DIN-SQL [8] | GPT-4 | - | 82.8 | 85.3 | - |
| DAIL-SQL [16] | GPT-4 | 自我一致性 | 83.6 | 86.2 | 54.8 |
| MAC-SQL [9] | GPT-4 | 自我一致性 | 86.8 | 82.8 | 59.4 |
| SuperSQL [31] | GPT-4 | 自我一致性 | 84.0 | 87.0 | 58.5 |
| MCTS-SQL [32] | GPT-4o-mini | - | 86.2 | 83.7 | 63.2 |
| MCTS-SQL [32] | GPT-4o | - | 88.7 | 86.6 | 69.4 |
| OpenSearch-SQL [33] | GPT-4o | 自我一致性 | - | 87.1 | 69.3 |
| SQL-R1(我们的) | Qwen2.5-Coder-7B | 自我一致性 | 87.6 | 88.7 | 66.6 |
对于数据集中所有NL2SQL数据样本,我们首先将它们转换为适合训练的输入-输出序列对。具体而言,输入序列包括自然语言问题和相关的数据库模式。受之前研究 [7, 22, 26, 27] 的启发,数据库模式被格式化为带有补充注释的CREATE TABLE语句,包括列属性描述和代表性值。目前,为了增强模型在强化学习阶段的探索能力,训练阶段暂不添加代表性值的注释。
环境 本研究中进行的所有实验都在运行Ubuntu 20.04 Linux发行版的服务器上进行。该服务器配备了Intel® Xeon® Platinum 8358 CPU @ 2.60 GHz CPU,并配有512 GB系统内存。训练开源LLMs的环境配置为8个GPU,每个GPU拥有80 GB内存,并在使用BF16精度时提供312 TFLOPS的性能容量。
3.2 主要结果
主要基准上的性能 表1中的结果显示了SQL-R1的卓越表现。它在Spider开发数据集上达到了最佳执行准确率87.6%,在测试数据集上达到88.7%,在BIRD开发数据集上达到66.6%。与使用Qwen2.5-Coder-7B的NL2SQL解决方案相比,我们提出的模型表现出相当的性能水平。值得注意的是,SQL-R1在许多依赖闭源模型(如GPT-4和GPT-4o)的NL2SQL解决方案中表现出优越性能。
性能与模型规模权衡的见解 如图2所示,我们利用BIRD开发数据集研究了性能与模型规模之间的关系。比较分析涵盖了各种模型类型,包括NL2SQL模型、推理LLMs和通用LLMs。对于GPT-4、GPT-4o、GPT-4o-mini和Gemini-1.5-Pro,我们参考了[22, 29, 34]中的参数描述。结果表明,当使用7B模型作为基础模型时,SQL-R1的准确率超过了更大规模模型的准确率,特别是在此情况下。这突显了所提模型在优化NL2SQL性能的同时确保成本效率的有效性。
案例研究 为了探索RL训练对实际NL2SQL推理的影响,我们在BIRD开发数据集上选择了一些例子进行分析。如图3至图8所示,经过RL训练后,模型表现出增强的推理能力。在处理更具挑战性的样本时,模型在推理生成SQL查询的过程中表现出明显的自上而下的认知策略。这一观察证实了强化学习可以进一步提高模型在NL2SQL任务中的推理能力。
表2:不同冷启动策略模型的执行准确性。
| 模型 | SFT 数据 | 推理 指令 |
Spider (Dev) |
Spider (Test) |
BIRD (Dev) |
|---|---|---|---|---|---|
| Qwen2.5-Coder-7B | F\mathcal{F}F | F\mathcal{F}F | 77.4 | 79.4 | 58.2 |
| Qwen2.5-Coder-7B | SynSQL-200K | ✓\checkmark✓ | 82.7 | 83.3 | 57.0 |
| OmniSQL-7B [22] | SynSQL-2.5M | F\mathcal{F}F | 81.6 | 88.9 | 66.1 |
| SQL-R1 + Qwen2.5-Coder-7B | F\mathcal{F}F | F\mathcal{F}F | 84.5 | 86.1 | 63.1 |
| SQL-R1 + Qwen2.5-Coder-7B | SynSQL-200K | ✓\checkmark✓ | 84.7 | 86.4 | 59.2 |
| SQL-R1 + OmniSQL-7B [22] | SynSQL-2.5M | F\mathcal{F}F | 87.6 | 88.7 | 66.6 |
表3:BIRD-Dev数据集上奖励组件的消融研究。
| 奖励函数 | 准确率 (%) |
|---|---|
| Qwen2.5-Coder-7B | 58.2 |
| Sf+Se+Sr+SlS_{f}+S_{e}+S_{r}+S_{l}Sf+Se+Sr+Sl | 63.1\mathbf{6 3 . 1}63.1 |
| - 无 SfS_{f}Sf(格式评分) | 60.4(↓2.7)60.4(\downarrow 2.7)60.4(↓2.7) |
| - 无 SeS_{e}Se(执行评分) | 60.7(↓2.4)60.7(\downarrow 2.4)60.7(↓2.4) |
| - 无 SrS_{r}Sr(结果评分) | 62.4(↓0.7)62.4(\downarrow 0.7)62.4(↓0.7) |
| - 无 SlS_{l}Sl(长度评分) | 61.0(↓2.1)61.0(\downarrow 2.1)61.0(↓2.1) |
生成SQL查询的推理能力。这一观察证实了强化学习可以进一步提高模型在NL2SQL任务中的推理能力。
总而言之,对于Q1,SQL-R1在Spider和BIRD基准上实现了优异性能,展示了强化学习在优化NL2SQL推理方面的有效性,并超越了基于闭源LLMs的模型。这确认了为NL2SQL任务设计基于RL算法的可行性。
3.3 SFT冷启动分析
在此实验中,我们采用三种不同的基线进行比较,即未预训练的初始模型、使用原始格式进行SFT的模型(OmniSQL-7B),以及使用强化指令格式进行SFT的模型。如表2所示,冷启动训练显著提高了基于RL的NL2SQL推理模型的性能。我们通过实施两种形式的冷启动策略,观察到在RL阶段改进了指令遵循能力和SQL生成质量。对于Q2\mathbf{Q 2}Q2,这些结果确认了冷启动训练在优化模型在复杂数据库场景中的探索和推理性能方面的必要性。目前,我们仍在进行进一步实验,相关结果将继续在后续版本中更新。
对于Q3,我们目前使用SynSQL-2.5M数据集的小规模子集进行强化训练。这种方法在模型中展示了实质性的进步,展示了利用合成数据工程增强NL2SQL领域模型推理能力的可行性。后续出版物将概述有关合成数据工程的进一步策略。
3.4 奖励组件的消融研究
我们在BIRD开发数据集上进行了消融实验,以验证所提出的强化学习奖励机制的有效性。实验在保持第3.1节中建立的参数设置的同时,依次从综合奖励函数中移除个别奖励组件。如表3所示,结果表明从原始奖励函数中移除任何奖励组件都会对推理性能产生不利影响。这凸显了执行反馈和结果奖励在模型训练过程中的关键重要性。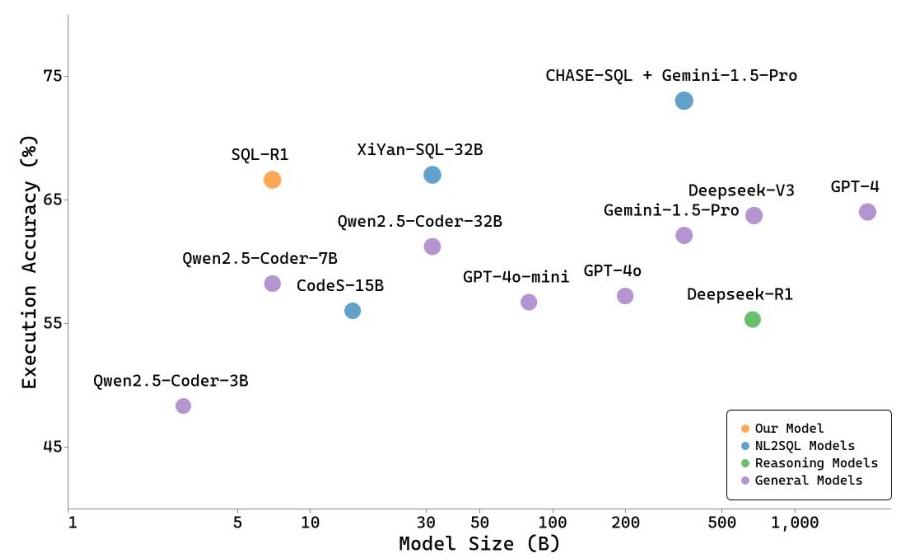
图2:BIRD-Dev数据集上的性能和模型规模。
4 局限性
目前,本研究仍存在以下局限性:
支持的数据库方言 当前研究仅支持SQLite方言的训练和评估,尚未对更多数据库方言(如Snowflake、DuckDB)进行进一步评估。
5 结论
在这项工作中,我们提出了SQL-R1,一种通过强化学习(RL)训练的新型NL2SQL推理模型,解决了复杂数据库场景中语义理解、推理和泛化的关键挑战。通过整合动态奖励机制、冷启动策略和可持续数据工程,SQL-R1在基准数据集上实现了最先进的性能(Spider-Test准确率为88.6%,BIRD准确率为66.6%),同时生成了可解释的推理轨迹。我们的研究表明,RL在增强模型泛化能力、降低领域适应成本方面具有有效性,为高风险应用提供了透明性。未来的工作将专注于提高模型可解释性、扩展多表联合能力,并探索合成数据生成以支持可扩展训练。这项研究通过弥合理解能力和实际应用之间的差距,推进了NL2SQL系统的实际可用性。
参考文献
[1] 刘新宇,沈舒雨,李博岩,马培贤,江润之,罗羽羽,张昱欣,范居,李国良,唐南。大型语言模型的NL2SQL综述:我们在哪里,我们要去哪里?CoRR,abs/2408.05109,2024年。
[2] 洪子金,袁正,张庆刚,陈浩,董俊楠,黄飞然,黄晓。下一代数据库接口:基于LLM的文本到SQL的综述。arXiv预印本arXiv:2406.08426,2024年。
[3] 罗羽羽,唐南,李国良,李文波,赵天宇,余翔。DeepEye:监测和探索COVID-19数据的数据科学系统。IEEE数据工程通报,43(2):121-132,2020年。
[4] 罗羽羽,秦雪迪,柴成亮,唐南,李国良,李文波。可操控的自动驾驶数据可视化。IEEE知识与数据工程汇刊,34(1):475-490,2022年。
[5] 李浩洋,张静,李翠萍,陈红。ResDSQL:文本到SQL的模式链接和骨架解析解耦。在AAAI会议上,2023年。
[6] 曹振彪,郑远磊,范志浩,张小金,陈伟,白祥。RSL-SQL:文本到SQL生成中的鲁棒模式链接。arXiv预印本arXiv:2411.00073,2024年。
[7] Taleai Shayan,Pourreza Mohammadreza,Chang Yu-Chen,Mirhoseini Azalia,Saberi Amin。CHESS:高效SQL合成的情境约束。arXiv预印本arXiv:2405.16755,2024年。
[8] Pourreza Mohammadreza和Rafiei Davood。DIN-SQL:分解上下文学习的文本到SQL自校正。arXiv预印本arXiv:2304.11015,2023年。
[9] 王兵,任长宇,杨建,梁昕年,白佳琪,柴林铮,颜昭,张倩雯,尹迪,孙星,李周军。MAC-SQL:文本到SQL的多智能体协作框架,2024年。
[10] 董雪梅,张超,葛玉航,毛宇恒,高云军,林金书,楼东芳。C3:零样本文本到SQL与ChatGPT。arXiv预印本arXiv:2307.07306,2023年。
[11] 马培贤,李博岩,江润之,范居,唐南,罗羽羽。一种即插即用的自然语言重写器用于自然语言到SQL。arXiv预印本arXiv:2412.17068,2024年。
[12] 刘新宇,沈舒雨,李博岩,唐南,罗羽羽。NL2SQL-Bugs:检测NL2SQL翻译中语义错误的基准。arXiv预印本arXiv:2503.11984,2025年。
[13] Pourreza Mohammadreza和Rafiei Davood。DTS-SQL:分解文本到SQL的小型大规模语言模型。arXiv预印本arXiv:2402.01117,2024年。
[14] 李浩洋,张静,刘汉冰,范居,张晓康,朱军,魏任杰,潘红艳,李翠萍,陈红。CODES:面向文本到SQL的开源语言模型构建。ACM数据管理会议论文集,2(3):1-28,2024年。
[15] 傅涵,刘畅,吴斌,李菲菲,谭健,孙建岭。CATSQL:面向实际应用的自然语言到SQL。VLDB期刊,16(6):1534-1547,2023年。
[16] 高大卫,王海宾,李雅亮,孙秀妍,钱一辰,丁博林,周敬仁。由大规模语言模型赋能的文本到SQL:基准评估。CoRR,abs/2308.15363,2023年。
[17] 郭达亚,杨德健,张浩威,宋俊潇,张若愚,徐闰鑫,朱启豪,马世荣,王佩怡,毕晓,等。DeepSeek-R1:通过强化学习激励大规模语言模型的推理能力。arXiv预印本arXiv:2501.12948,2025年。
[18] 刘召伟,郭欣,楼方奇,曾灵峰,牛锦毅,王梓轩,许家杰,蔡卫杰,杨子伟,赵学谦,等。Fin-R1:通过强化学习进行金融推理的大规模语言模型。arXiv预印本arXiv:2503.16252,2025年。
[19] 金博文,曾韩斯,岳震锐,王东,扎马尼哈米德,韩嘉伟。Search-R1:通过强化学习训练大规模语言模型进行推理和利用搜索引擎。arXiv预印本arXiv:2503.09516,2025年。
[20] 谢田,高子川,任青南,罗浩明,洪玉倩,戴布莱恩,周乔伊,邱凯,吴志融,罗冲。Logic-RL:通过基于规则的强化学习释放大规模语言模型推理能力。arXiv预印本arXiv:2502.14768,2025年。
[21] Hugging Face。Open R1:DeepSeek-R1的完全开放再现,2025年1月。
[22] 李浩洋,吴尚,张晓康,黄心玫,张静,姜福新,王帅,张铁英,陈建军,石瑞,等。OmnisQL:大规模合成高质量文本到SQL数据。arXiv预印本arXiv:2503.02240,2025年。
[23] 邵志宏,王佩怡,朱启豪,徐闰鑫,宋俊潇,毕晓,张浩威,张明川,李渝,吴轶,等。DeepSeekMath:推动开放语言模型数学推理的极限。arXiv预印本arXiv:2402.03300,2024年。
[24] 俞涛,张睿,杨凯,安田政弘,王东旭,李子凡,詹姆斯·马,李爱琳,姚青宁,罗马沙内尔,张子林,拉德夫·德拉戈米尔。Spider:一个大规模人类标注的复杂和跨域语义解析和文本到SQL任务数据集。2018年经验方法自然语言处理会议论文集,比利时布鲁塞尔,2018年。计算语言学协会。
[25] 李金阳,惠斌远,曲歌,李彬华,杨佳曦,李博文,王百林,秦博文,耿瑞英,霍楠,周宣和,马晨浩,李国良,张凯伦·C·C,黄飞,程彦磊,李永斌。LLM已经可以作为数据库接口了吗?大规模数据库支持的文本到SQL的大基准,2023年。
[26] 杨佳曦,惠斌远,杨敏,杨建,林俊阳,周昌。从弱强LLM合成文本到SQL数据。arXiv预印本arXiv:2408.03256,2024年。
[27] Rajkumar Nitarshan,Li Raymond,Bahdanau Dzmitry。大规模语言模型的文本到SQL能力评估。arXiv预印本arXiv:2204.00498,2022年。
[28] Pourreza Mohammadreza,李海龙,孙若曦,钟叶诺,塔莱伊Shayan,卡卡尔Gaurav Tarlok,甘------
宇,萨贝里Amin,奥兹坎Fatma,阿里克Sercan O。CHASE-SQL:文本到SQL中的多路径推理和偏好优化候选选择。arXiv预印本arXiv:2410.01943,2024年。
松井雅弘,杉崎航,冈田健介,小冢伸一。AlphaSQL:自动解决SQL和数据依赖关系、并行化和验证的开源软件工具。2022年IEEE第38届国际数据工程会议研讨会论文集(ICDEW),第38-45页。
------IEEE,2022年。
[30] 吕帅,罗浩然,欧忠鸿,朱一凡,尚晓然,秦阳,宋美娜。SQL-O1:一种用于文本到SQL的自奖励启发式动态搜索方法。arXiv预印本arXiv:2502.11741,2025年。
[31] 李博岩,罗羽羽,柴成亮,李国良,唐南。自然语言到SQL的黎明:我们准备好了吗?arXiv预印本arXiv:2406.01265,2024年。
[32] 袁硕智,陈立明,元苗苗,赵瑾,彭浩然,郭文明。MCTS-SQL:使用蒙特卡洛树搜索进行文本到SQL的有效框架。arXiv预印本arXiv:2501.16607,2025年。
[33] 谢象金,许光伟,赵灵燕,郭瑞杰。OpenSearch-SQL:通过动态少样本和一致性对齐增强文本到SQL。arXiv预印本arXiv:2502.14913,2025年。
[34] 本阿巴查Asma,尹文崴,傅玉娟,孙昭义,梅丽哈·叶蒂斯根,夏飞,林托马斯。MedEC:临床笔记中医疗错误检测和纠正的基准。arXiv预印本arXiv:2412.19260,2024年。
参考论文:https://arxiv.org/pdf/2504.08600

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 23
23 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)