强化学习基础篇【1】:基础知识点、马尔科夫决策过程、蒙特卡洛策略梯度定理、REINFORCE 算法
智能体(agent):智能体是强化学习算法的主体,它能够根据经验做出主观判断并执行动作,是整个智能系统的核心。环境(environment):智能体以外的一切统称为环境,环境在与智能体的交互中,能被智能体所采取的动作影响,同时环境也能向智能体反馈状态和奖励。虽说智能体以外的一切都可视为环境,但在设计算法时常常会排除不相关的因素建立一个理想的环境模型来对算法功能进行模拟。
1.强化学习基础知识点
智能体(agent):智能体是强化学习算法的主体,它能够根据经验做出主观判断并执行动作,是整个智能系统的核心。
环境(environment):智能体以外的一切统称为环境,环境在与智能体的交互中,能被智能体所采取的动作影响,同时环境也能向智能体反馈状态和奖励。虽说智能体以外的一切都可视为环境,但在设计算法时常常会排除不相关的因素建立一个理想的环境模型来对算法功能进行模拟。
状态(state):状态可以理解为智能体对环境的一种理解和编码,通常包含了对智能体所采取决策产生影响的信息。
动作(action):动作是智能体对环境产生影响的方式,这里说的动作常常指概念上的动作,如果是在设计机器人时还需考虑动作的执行机构。
策略(policy):策略是智能体在所处状态下去执行某个动作的依据,即给定一个状态,智能体可根据一个策略来选择应该采取的动作。
奖励(reward):奖励是智能体贯式采取一系列动作后从环境获得的收益。注意奖励概念是现实中奖励和惩罚的统合,一般用正值来代表奖励,用负值代表实际惩罚。
:

在flappy bird游戏中,小鸟即为智能体,除小鸟以外的整个游戏环境可统称为环境,状态可以理解为在当前时间点的游戏图像。在本游戏中,智能体可以执行的动作为向上飞,或什么都不做靠重力下降。策略则指小鸟依据什么来判断是要执行向上飞的动作还是什么都不做,这个策略可能是根据值函数大小判断,也可能是依据在当前状态下执行不同动作的概率或是其他的判断方法。奖励分为奖励和惩罚两种,每当小鸟安全的飞过一个柱子都会获得一分的奖励,而如果小鸟掉到地上或者撞到柱子则或获得惩罚。
2.马尔科夫决策过程

图1: 经典吃豆人游戏
在经典的吃豆人游戏中,吃豆人通过对环境进行观察,选择上下左右四种动作中的一种进行自身移动,吃掉豆子获得分数奖励,并同时躲避幽灵防止被吃。吃豆人每更新一次动作后,都会获得环境反馈的新的状态,以及对该动作的分数奖励。在这个学习过程中,吃豆人就是智能体,游戏地图、豆子和幽灵位置等即为环境,而智能体与环境交互进行学习最终实现目标的过程就是马尔科夫决策过程(Markov decision process,MDP)。
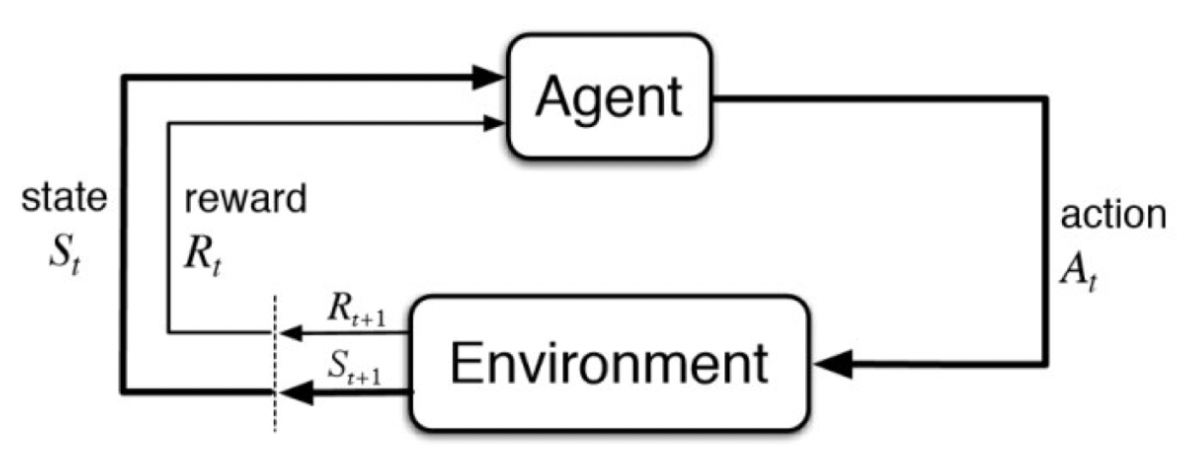
图2: 马尔科夫决策过程中的智能体-环境交互
上图形式化的描述了强化学习的框架,智能体(Agent)与环境(Environment)交互的过程:在 ttt 时刻,智能体在当前状态 S_tS\_tS_t 采取动作 A_tA\_tA_t。在下一时刻 t+1t+1t+1,智能体接收到环境反馈的对于动作 A_tA\_tA_t 的奖励 R_t+1R\_{t+1}R_t+1,以及该时刻状态 S_t+1S\_{t+1}S_t+1。从而,MDP和智能体共同给出一个轨迹:
S_0,A_0,R_1,S_1,A_1,R_2,S_2,A_2,R_3,S_3,A_3,... S\_0,A\_0,R\_1,S\_1,A\_1,R\_2,S\_2,A\_2,R\_3,S\_3,A\_3,... S_0,A_0,R_1,S_1,A_1,R_2,S_2,A_2,R_3,S_3,A_3,...
接下来,更具体地定义以下标识:
- S_tS\_tS_t 是有限的状态集合
- A_tA\_tA_t 是有限的动作集合
- PPP 是基于环境的状态转移矩阵:其中每一项为智能体在某个状态 sss 下,采取动作 aaa 后,与环境交互后转移到其他状态 s′s^{'}s′ 的概率值,表示为 P(S_t+1=s′∣s_t=s,a_t=a)P(S\_{t+1}=s^{'}|s\_{t}=s,a\_{t}=a)P(S_t+1=s′∣s_t=s,a_t=a)
- R是奖励函数:智能体在某个状态 sss 下,采取动作 aaa 后,与环境交互后所获得的奖励,表示为 R(s_t=s,a_t=a)R(s\_{t}=s,a\_{t}=a)R(s_t=s,a_t=a)
- gamma\\gammagamma 是折扣因子(discounted factor),取值区间为 KaTeX parse error: Undefined control sequence: \[ at position 1: \̲[̲0,1\]
所以MDP过程可以表示为 (S,A,P,R,gamma)(S,A,P,R,\\gamma)(S,A,P,R,gamma),如果该过程中的状态转移矩阵 PPP 和奖励 R(s,a)R(s,a)R(s,a) 对智能体都是可见的,我们称这样的Agent为Model-based Agent,否则称为Model-free Agent。
3.策略梯度定理
策略函数的参数化可表示为pi_theta(s,a)\\pi\_{\\theta}(s,a)pi_theta(s,a),其中theta\\thetatheta为一组参数,函数取值表示在状态sss下选择动作aaa的概率。为了优化策略函数,首先需要有一个对策略函数优劣进行衡量的标准。假设强化学习问题的初始状态为s_0s\_{0}s_0,则希望达到最大化的目标为
J(theta):=V_pi_theta(s_0) J(\\theta) := V\_{\\pi\_{\\theta}}(s\_{0}) J(theta):=V_pi_theta(s_0)
其中,v_pi_thetav\_{\\pi\_{\\theta}}v_pi_theta是在策略pi_theta\\pi\_{\\theta}pi_theta下的真实价值函数,这个价值函数代表衡量一个状态的价值,即一个状态采取所有行为后的一个价值的期望值。如果能求出梯度nabla_thetaJ(theta)\\nabla\_{\\theta}J(\\theta)nabla_thetaJ(theta),就可以用梯度上升法求解这个问题,即求解价值函数的最大值。
在这个函数中,J(theta)J(\\theta)J(theta)既依赖于动作的选择有依赖于动作选择时所处状态的分布。给定一个状态,策略参数对动作选择及收益的影响可以根据参数比较直观地计算出来,但因为状态分布和环境有关,所以策略对状态分布的影响一般很难确切知道。而J(theta)J(\\theta)J(theta)对模型参数的梯度却依赖于这种未知影响,那么如何估计这个梯度呢?
Sutton等人在文献中给出了这个梯度的表达式:
nabla_thetaJ(theta)proptosum_smu_pi_theta(s)sum_aq_pi_theta(s,a)nabla_thetapi_theta(s,a) \\nabla\_{\\theta}J(\\theta)\\propto\\sum\_{s}\\mu\_{\\pi\_{\\theta}}(s)\\sum\_{a}q\_{\\pi\_{\\theta}}(s,a)\\nabla\_{\\theta}\\pi\_{\\theta}(s,a) nabla_thetaJ(theta)proptosum_smu_pi_theta(s)sum_aq_pi_theta(s,a)nabla_thetapi_theta(s,a)
其中,mu_pi_theta(s)\\mu\_{\\pi\_{\\theta}}(s)mu_pi_theta(s)称为策略pi_theta\\pi\_{\\theta}pi_theta的在策略分布。在持续问题中,mu_pi_theta(s)\\mu\_{\\pi\_{\\theta}}(s)mu_pi_theta(s)为算法s_0s\_{0}s_0出发经过无限多步后位于状态sss的概率。
策略梯度定理的证明:(注意:在证明过程中,为使符号简单,我们在所有公式中隐去了pi\\pipi对theta\\thetatheta的依赖)
KaTeX parse error: Expected '}', got '&' at position 58: …a v\_{\\pi}(s) &̲= \\nabla\[\\su…
其中,Pr(srightarrowx,k,pi)Pr(s\\rightarrow x,k,\\pi)Pr(srightarrowx,k,pi)是在策略pi\\pipi下,状态sss在kkk步内转移到状态xxx的概率。所以,我们可以得到:
KaTeX parse error: Expected 'EOF', got '&' at position 40: …bla J(\\theta) &̲= \\nabla v\_{\…
4.蒙特卡洛策略梯度定理
根据策略梯度定理表达式计算策略梯度并不是一个简单的问题,其中对mu_pi_theta\\mu\_{\\pi\_{\\theta}}mu_pi_theta和q_pi_thetaq\_{\\pi\_{\\theta}}q_pi_theta的准确估计本来就是难题,更不要说进一步求解nabla_thetaJ(theta)\\nabla\_{\\theta}J(\\theta)nabla_thetaJ(theta)了。好在蒙特卡洛法能被用来估计这类问题的取值,因此首先要对策略梯度定理表达式进行如下的变形:
KaTeX parse error: Expected 'EOF', got '&' at position 50: …eta}J(\\theta) &̲\\propto\\mu\_{…
上式为梯度策略定理的一个常见变形,但由于式中存在q_pi_thetaq\_{\\pi\_{\\theta}}q_pi_theta,算法无法直接使用蒙特卡洛法来求取其中的期望。为此,进一步将该式进行变形,得到:
KaTeX parse error: Expected 'EOF', got '&' at position 50: …eta}J(\\theta) &̲\\propto\\mathb…
其中,T(s,a)T(s,a)T(s,a)表示从状态sss开始执行动作aaa得到的一条轨迹(不包括sss和aaa),G_tG\_{t}G_t为从状态sss开始沿着轨迹T(s,a)T(s,a)T(s,a)运动所得的回报。可以使用蒙特卡洛采样法来求解(即上述公式),算法只需要根据策略来采样一个状态sss、一个动作aaa和将来的轨迹,就能构造上述公式中求取期望所对应的一个样本。
5.REINFORCE 算法
REINFORCE (蒙特卡洛策略梯度) 算法是一种策略参数学习方法,其中策略参数 theta\\thetatheta 的更新方法为梯度上升法,它的目标是为了最大化性能指标 J(theta)J(\\theta)J(theta) , 其更新公式为:
theta_t+1=theta_t+alphawidehatnablaJ(theta_t) \\theta\_{t+1} = \\theta\_{t} + \\alpha\\widehat{\\nabla J(\\theta\_t)} theta_t+1=theta_t+alphawidehatnablaJ(theta_t)
根据蒙特卡洛定理中对 nabla_thetaJ(theta)\\nabla\_{\\theta}J(\\theta)nabla_thetaJ(theta) 的计算,则有:
KaTeX parse error: Undefined control sequence: \[ at position 62: …{s, a\\sim\\pi}\̲[̲G_\\nabla\_{\\t…
根据上述梯度更新公式, 得到蒙特卡洛策略梯度更新公式:
theta=theta+etagamma′Gnabla_thetalnpi_theta(s_t,a_t) \\theta = \\theta + \\eta\\gamma^{'} G\\nabla\_\\theta\\ln\\pi\_\\theta(s\_t, a\_t) theta=theta+etagamma′Gnabla_thetalnpi_theta(s_t,a_t)
其中,eta\\etaeta 为学习率,gamma′\\gamma^{'}gamma′ 为衰减率,在REINFORCE算法中,暂不考虑衰减问题,设置 gamma′=1\\gamma^{'} = 1gamma′=1 。
REINFORCE 算法流程:
输入:马尔可夫决策过程MDP=(S,A,P,R,gamma)MDP=(S, A, P, R, \\gamma)MDP=(S,A,P,R,gamma),即状态,智能体,决策,奖励和折现系数,gamma=1\\gamma = 1gamma=1,暂不讨论。
输出:策略 pi(a∣s,theta)\\pi(a|s, \\theta)pi(a∣s,theta),即在状态为s,参数为theta\\thetatheta的条件下,选择动作a的概率。
算法的具体流程:
- 随机初始化;
- repeat
- 根据策略pi_theta\\pi\_\\thetapi_theta采样一个片段(episode,即智能体由初始状态不断通过动作与环境交互,直至终止状态的过程),获得s_0,a_0,R_1,s_1,...,s_T−1,a_T−1,R_Ts\_0, a\_0, R\_1, s\_1, ..., s\_T-1, a\_T-1, R\_Ts_0,a_0,R_1,s_1,...,s_T−1,a_T−1,R_T;
2. for tleftarrow0t \\leftarrow 0tleftarrow0 to T−1T - 1T−1 do
- Gleftarrowsum_k=1T−tgamma_k−1R_t+kG \\leftarrow \\sum\_{k=1}^{T-t} \\gamma\_{k-1} R\_{t+k}Gleftarrowsum_k=1T−tgamma_k−1R_t+k,G是对回报的计算,回报是奖励随时间步的积累,在本实验中,gamma=1\\gamma = 1gamma=1。
2. theta=theta+etagamma′Gnabla_thetalnpi_theta(s_t,a_t)\\theta = \\theta + \\eta\\gamma^{'} G\\nabla\_\\theta\\ln\\pi\_\\theta(s\_t, a\_t)theta=theta+etagamma′Gnabla_thetalnpi_theta(s_t,a_t),其中eta\\etaeta是学习率。策略梯度算法采用神经网络来拟合策略梯度函数,计算策略梯度用于优化策略网络。- 直到theta\\thetatheta收敛
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 5
5 0
0- 0



 已为社区贡献101条内容
已为社区贡献101条内容

所有评论(0)