利用深度强化学习预测股价
作者介绍:王茂霖,北京航空航天大学飞行器设计专业博士在读,python、C++入门小白。个人公众号:(vvrn1_field)0.总体思路本文灵感来源于Si...

作者介绍:王茂霖,北京航空航天大学飞行器设计专业博士在读,python、C++入门小白。个人公众号:(vvrn1_field)
0.总体思路
本文灵感来源于Siraj Raval的youtube频道:
https://www.youtube.com/watch?v=05NqKJ0v7EE
本文的基本思路是,利用强化Q学习,通过学习历史股价,学习在得知历史趋势的情况下,如何采取简答的买卖策略,从而获得收益,是监督学习和强化学习的一次简单结合。
1.DQN简介
DQN(deep Q learning)是将传统强化学习中Q-学习与深度神经网络相结合的一种算法。本质上是利用神经网络拟合非线性Q-table,从而解决高维的强化学习问题。DQN由DeepMind在2013年发表在arkiv上的论文“Playing Atari with Deep Reinforcement Learning”中首次提出,并在近几年不断发展,提出了DDPG等一系列改进后的算法。其基本算法思路如下图所示。

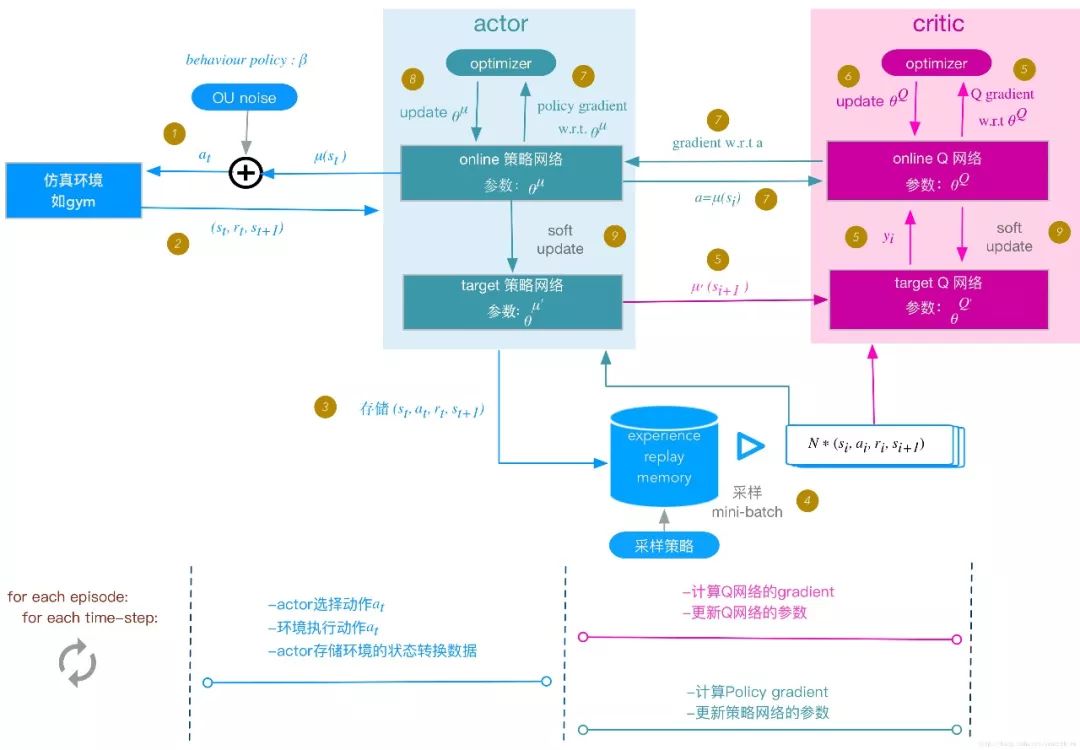
DQN中有许多开创性的想法,例如local网络与target网络,Replay Buffer等,极大地提高了强化学习的效率与收敛性。著名的Alpha Go以及Alpha Zero等也是基于DQN算法开发的。2016年DeepMind提出的DDPG(深度策略梯度下降算法)在DQN的基础上引入了评价器与动作器系统,可以解决高维连续空间中的决策问题,其基本思路如下图所示,(图片来源:https://blog.csdn.net/kenneth_yu/article/details/78478356),在此不多作讨论。
2.DQN代码编写
DQN代码的编写基于Pytorch框架,参考了github上udacity的深度强化学习代码,地址:(https://github.com/udacity/deep-reinforcement-learning),并在其基础上进行改进,主要分为神经网络搭建与agent创建两部分。
神经网络搭建
利用Pytorch搭建神经网络十分方便,本次搭建的神经网络输入为状态,输出为动作值,神经网络包含三个全连接层,前两层使用relu函数激活,第三层为线性连接。
# 新建一个Q神经网络
# 输入为状态,输出为动作
# 神经网络包含三个全连接层,前两层使用relu函数激活
import torch
import torch.nn as nn
import torch.nn.functional as F
class QNetwork(nn.Module):
def __init__(self, state_size, action_size, fc1_units=64, fc2_units=64):
super(QNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, fc1_units)
self.fc2 = nn.Linear(fc1_units, fc2_units)
self.fc3 = nn.Linear(fc2_units, action_size)
def forward(self, state):
x = F.relu(self.fc1(state))
x = F.relu(self.fc2(x))
return self.fc3(x)
agent创建
Agent的搭建基本上按照伪代码的逻辑,获取奖励值,通过贝尔曼方程迭代,梯度下降目标网络和动作网络的差值。代码包含了Agent类和ReplayBuffer类,其中目标网络的更新参考了DDPG中的方式,使用了softupdate方法。
import numpy as np
import random
from collections import namedtuple, deque
from model import QNetwork
import torch
import torch.nn.functional as F
import torch.optim as optim
#初始化超参数
BUFFER_SIZE = int(1e5)
BATCH_SIZE = 64
GAMMA = 0.99
TAU = 1e-3
LR = 5e-4
UPDATE_EVERY = 4
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class ReplayBuffer:
def __init__(self, action_size, buffer_size, batch_size):# 初始化记忆库
self.action_size = action_size
self.memory = deque(maxlen=buffer_size)
self.batch_size = batch_size
self.experience = namedtuple("Experience", field_names=["state", "action", "reward", "next_state", "done"])
def add(self, state, action, reward, next_state, done):# 向记忆库中加入一个记忆
e = self.experience(state, action, reward, next_state, done)
self.memory.append(e)
def sample(self):# 随机取出一个minibatch
experiences = random.sample(self.memory, k=self.batch_size)
states = torch.from_numpy(np.vstack([e.state for e in experiences if e is not None])).float().to(device)
actions = torch.from_numpy(np.vstack([e.action for e in experiences if e is not None])).float().to(device)
rewards = torch.from_numpy(np.vstack([e.reward for e in experiences if e is not None])).float().to(device)
next_states = torch.from_numpy(np.vstack([e.next_state for e in experiences if e is not None])).float().to(device)
dones = torch.from_numpy(np.vstack([e.done for e in experiences if e is not None])).float().to(device)
return (states, actions, rewards, next_states, dones)
def __len__(self):
return len(self.memory)
class Agent:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
# Q-Network
self.qnetwork_local = QNetwork(state_size, action_size).to(device)
self.qnetwork_target = QNetwork(state_size, action_size).to(device)
self.optimizer = optim.Adam(self.qnetwork_local.parameters(), lr=LR)
# Replay Buffer
self.memory = ReplayBuffer(action_size, buffer_size=BUFFER_SIZE,batch_size=BATCH_SIZE)
# 初始化迭代步数
self.t_step = 0
# 初始化持仓
self.inventory = []
def step(self, state, action, reward, next_state, done):
# 每一步需要先存储记忆库
self.memory.add(state, action, reward, next_state, done)
# 每隔若干步学习一次
self.t_step = (self.t_step + 1) % UPDATE_EVERY
if self.t_step == 0:
if len(self.memory) > BATCH_SIZE:
experience = self.memory.sample()
self.learn(experience, GAMMA)
def learn(self, experience, gamma):
# 更新迭代
states, actions, rewards, next_states, dones = experience
# target network
Q_targets_next = self.qnetwork_target(next_states).detach().max(1)[0].unsqueeze(1)
Q_targets = rewards + (gamma * Q_targets_next * (1 - dones))
Q_expected = self.qnetwork_local(states).gather(1, actions.long())
loss = F.mse_loss(Q_expected, Q_targets)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.soft_update(self.qnetwork_local, self.qnetwork_target, tau=TAU)
def soft_update(self, local_model, target_model, tau):
for target_param, local_param in zip(target_model.parameters(), local_model.parameters()):
target_param.data.copy_(tau * local_param.data + (1.0 - tau) * target_param.data)
def act(self, state, eps = 0.):
# 返回动作值
state = torch.from_numpy(state).float().unsqueeze(0).to(device)
self.qnetwork_local.eval()
with torch.no_grad():
action_values = self.qnetwork_local(state)
self.qnetwork_local.train()
if random.random() > eps:
return np.argmax(action_values.cpu().data.numpy())
else:
return random.choice(np.arange(self.action_size))
3.学习历史股价
所有代码已经发布在我的github:https://github.com/vvrn1/stockPrediction
本次学习的股价是600967内蒙一机,因为我在这个股票上吃过甜头。。。(此处鸣谢ljm师兄)。从国泰君安交易平台将历史数据下载下来,如下图。
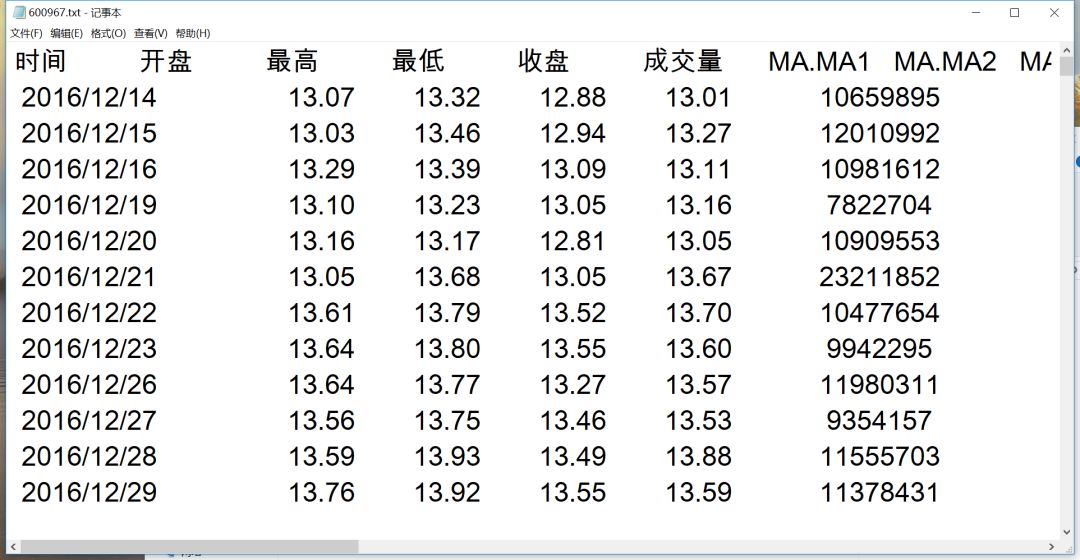
下载数据包括十九列,包括简单的开盘价、收盘价和成交量等,以及进阶的五日均线,十日均线等数据,限于我的水平,就用十日收盘价作为状态量,即本日的操作只取决于前十日的涨跌幅。
读取数据代码如下:
stockData = []
file = open("600967.txt").read().splitlines()
# 打开数据文件
for item in file[1:]:
stockData.append(float(item.split("\t")[4]))
4.学习效果
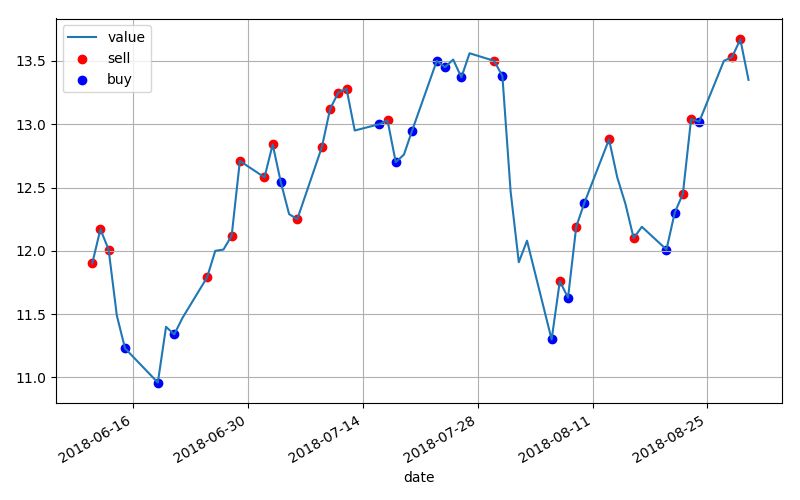
取从2016年12月14日到2018年6月8日的历史股价作为学习样本,取2018年6月11日到2018年8月30日的历史股价作为验证样本。这种处理有一种监督学习的味道,但又不完全一样。以总收益为验证指标,此处不用收益率的原因在于模型太简单,没有设置初始投资额,也没有考虑仓位,后续模型可以在此处改进。训练1000个Episode,在我这个破本上要花大概三分钟时间,训练效果如图所示。
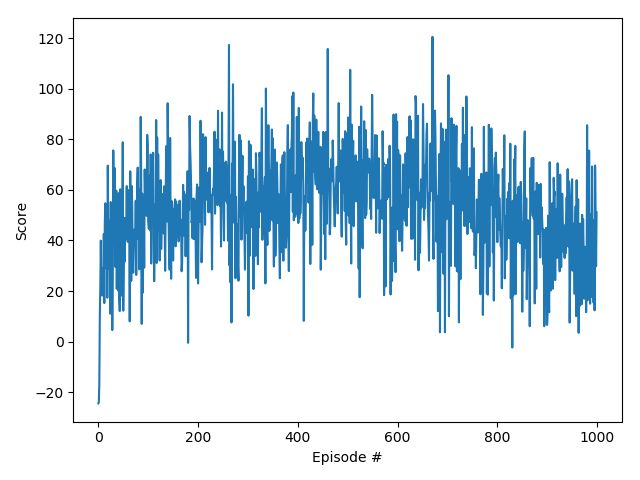
训练效果比较符合强化学习的特征,由于Replay Buffer的不断扩充以及e-探索策略的存在,所以并不会像传统监督学习一样严格收敛,而是呈现一种震荡的收敛趋势。利用matplotlib库做可视化,可以看到基本上已经掌握了低买高卖的基本原理。
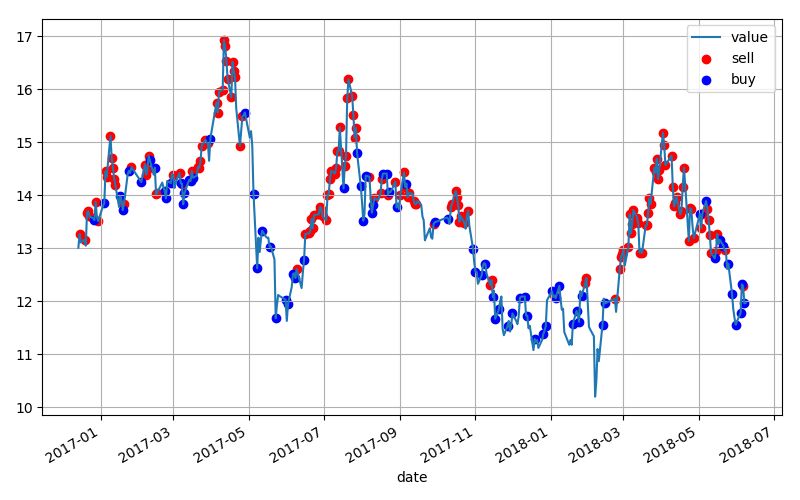
取验证样本试验,得到的操作策略如图,总收益为3.29。
5.结语
本次和科研无关的事情告诉大家:
投资有风险,入市需谨慎;
万般皆下品,惟有科研高。
——沃.兹基硕德
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以通过扫描下方管理员二维码,让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
●
●
●
●
●

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 8
8 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)