【李宏毅深度强化学习笔记】—2、Proximal Policy Optimization算法(PPO)
原文链接:https://blog.csdn.net/ACL_lihan/article/details/103989581补充:问题:PPO2的损失函数,也就是奖励的平均值函数是怎么通过约束重要性权重让θ和θk的输出分布不至于差距很大的?也就是让其不至于差太多,导致off-policy失效理解:当A>0时候,根据损失函数(奖励函数平均值),此时会提高pθ(s,a)的概率,所以设置上限,不让pθ(
原文链接:https://blog.csdn.net/ACL_lihan/article/details/103989581
补充:
问题:PPO2的损失函数,也就是奖励的平均值函数是怎么通过约束重要性权重让θ和θk的输出分布不至于差距很大的?也就是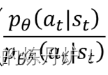
让其不至于差太多,导致off-policy失效
理解:
当A>0时候,根据损失函数(奖励函数平均值),此时会提高pθ(s,a)的概率,所以设置上限,不让pθ(s,a)超过pθk(s,a)太多(1+ξ),如果超过了,则会被截断到1+ξ,则损失函数的值不变了,也就没有梯度了,此时就可以用θ的参数替换θk的参数,重新采集数据了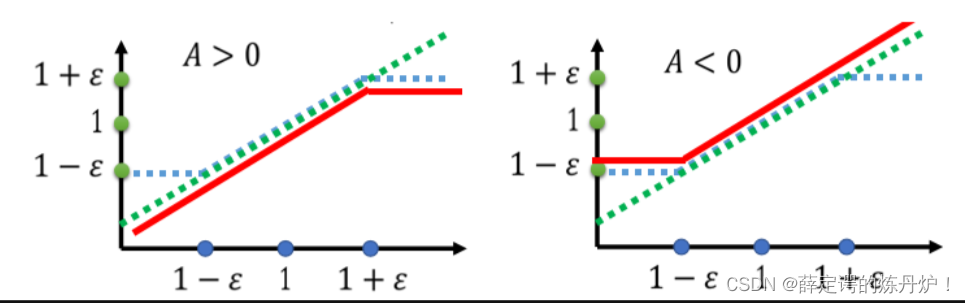
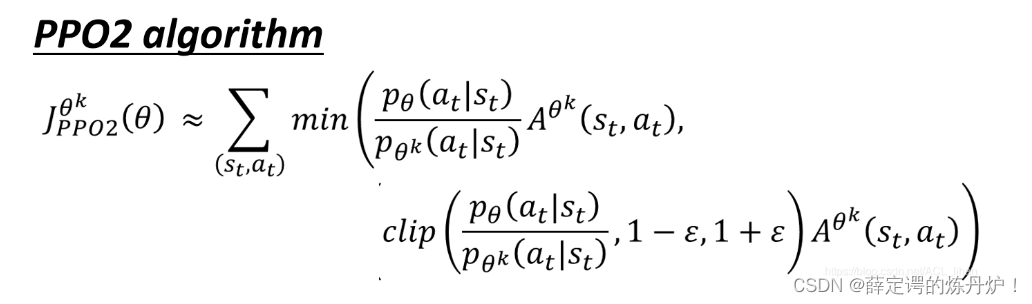
【李宏毅深度强化学习笔记】1、策略梯度方法(Policy Gradient)
【李宏毅深度强化学习笔记】2、Proximal Policy Optimization (PPO) 算法(本文)
【李宏毅深度强化学习笔记】3、Q-learning(Basic Idea)
【李宏毅深度强化学习笔记】4、Q-learning更高阶的算法
【李宏毅深度强化学习笔记】5、Q-learning用于连续动作 (NAF算法)
【李宏毅深度强化学习笔记】6、Actor-Critic、A2C、A3C、Pathwise Derivative Policy Gradient
【李宏毅深度强化学习笔记】8、Imitation Learning
-------------------------------------------------------------------------------------------------------
【李宏毅深度强化学习】视频地址:https://www.bilibili.com/video/av63546968?p=2
课件地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS18.html
-------------------------------------------------------------------------------------------------------
讲PPO前先铺垫一下On-policy和Off-policy的一点知识

所谓 on-policy (左图)指我们学习的 agent(即actor) 和与环境交互的 agent 是相同的,即 agent 一边和环境互动,一边学习;
而 off-policy (右图)指我们学习的 agent 与环境交互的 agent 是不同的,即 agent 通过看别人玩游戏来学习。
on-policy的过程是这样的:

1、使用actor  去收集数据,用这些数据来进行参数的更新,此时参数
去收集数据,用这些数据来进行参数的更新,此时参数 变为\theta^'\theta^' 大于
变为\theta^'\theta^' 大于  ,说明
,说明  相差太大,需要加大
相差太大,需要加大 ,加大惩罚。反之则减小 ,减小惩罚。
,加大惩罚。反之则减小 ,减小惩罚。
上面讲的是PPO,下面要讲的是PPO2。

min(a,b)函数就是取a和b中的最小值。
clip()函数的意思是:  小于
小于  ,则取 ;若 大于
,则取 ;若 大于  则取 ;若介于两者之间,则取 ,即输入等于输出。
则取 ;若介于两者之间,则取 ,即输入等于输出。

上面为clip()函数的图像,横轴指的就是。
总的图像:

绿线代表min()函数的第一项的图像,蓝线代表min()函数的第二项的图像,红线代表最终min()函数的输出结果。
若A>0,则取下图左边红线部分,若A<0则取下图右边红色部分。
这个式子其实就是让 和  不要差距太大。如果A(advantage function)>0,代表当前的action是好的,所以我们希望
不要差距太大。如果A(advantage function)>0,代表当前的action是好的,所以我们希望  越大越好(即横轴代表的 增大),但是 和
越大越好(即横轴代表的 增大),但是 和  二者不能相差太多,所以设了一个上界 (上图左边);A<0,则说明当前的action不好,所以希望 越小越好(即横轴代表的 减小),但同样要设一个下界 。
二者不能相差太多,所以设了一个上界 (上图左边);A<0,则说明当前的action不好,所以希望 越小越好(即横轴代表的 减小),但同样要设一个下界 。
最后再放一下PPO和PPO2的对比:


这里有人纠结怎么一开始写的PPO是取期望,而这里的PPO和PPO2怎么变成是累加的?

TRPO / PPO2 等方法的实验效果:

这边可能不清晰,可以看论文原文(https://arxiv.org/abs/1707.06347)
简单说一下,PPO(Clip)是紫色的线,可以看到每个任务中的效果都是名列前茅。
总结
1、介绍了on-policy和off-policy的概念,和on-policy不足
2、为了实现πθ'去收集数据,用这些数据去训练 (即off-policy),使用Importance sampling方法
3、在Importance sampling方法中要求和θ'不要相差太多,否则会导致结果错误。进而引出PPO算法
4、介绍了PPO和TRPO和PPO2

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)