图像生成系列(GAN-Based)
图像生成系列(GAN-Based)
Continuous Updating
B站GAN学习视频
Overview
GAN模型的核心架构包括一个 生成器G(Generator)和一个 判别器D(Discriminator)。
其中, 生成器G主要负责生成尽可能接近真实数据的新数据,输入一般是从高斯分布随机采样得到的噪声Z。而判别器的主要职责是区分输入数据是来自于生成器生成的样本还是(GroundTruth)样本。
目标是 GAN模型的判别器对gt样本输出的置信度越接近1越好,而对生成样本输出的置信度越接近0越好 。GAN在训练时要同时训练生成器与判别器,所以其训练难度是比较大的。
将生成器比喻为一个“画家”,并将判别器当作“鉴赏家”。“画家”努力让生成图像看起来逼真,“鉴赏家”则不断提升对于生成图像的判别能力。二者在训练中的互相博弈,随着时间的进行,能力都会越来越强。
- 判别器训练:固定生成器,更新判别器的参数,提高其区分真实数据和生成数据的能力。
- 生成器训练:固定判别器,更新生成器的参数,提高生成数据的“真实性”,使得判别器更难以区分。
损失函数:
m i n G m a x D V ( G , D ) = E x : p d a t a ( x ) [ l o g D ( x ) ] + E z : p z ( z ) [ l o g ( 1 − D ( G ( z ) ) ) ] min_G max_DV(G,D) = E_{x:p_{data}(x)}[logD(x)] + E_{z:p_z(z)}[log(1-D(G(z)))] minGmaxDV(G,D)=Ex:pdata(x)[logD(x)]+Ez:pz(z)[log(1−D(G(z)))]
在判别器角度,希望最大化这个目标函数,因为在公式第一部分,其表示GT样本输入判别器后输出的置信度,当然是越接近1越好。而公式的第二部分表示生成器输出的生成样本 G(z)再输入判别器中进行进行二分类判别,其输出的置信度当然是越接近0越好,所以 1 - D(G(z))越接近1越好。
一些要点:
在生成器角度,需要最小化判别器目标函数的最大值 。判别器目标函数的最大值代表的是真实数据分布与生成数据分布的JS散度,JS散度可以度量分布的相似性,两个分布越接近,JS散度越小。
首先使用生成器生成数据,接着冻结生成器参数,将生成数据与gt数据输入判别器,对判别器进行训练;完成判别器的训练,冻结判别器参数,交换label,对生成器进行训练;如此循环迭代,完成整个训练过程。
模式崩溃是指GAN在训练过程中生成多样性不足的问题,即模型可能仅生成少数几种类型的样本,而忽略数据集中其他类型的样本。
GAN在处理包含多种不同类别的复杂数据集时,往往难以学习到所有类别的分布特征。
以StyleGAN为代表的GAN模型,其生成器的输入是由噪声(noise)和潜在编码(Latent Code,通常表示为w)组成。潜在编码w的存在使得GAN在生成过程中具有更直观的可控性,可以通过调整低维空间中的编码来控制生成的高维数据。比如,GAN可以实现连续的插值操作,或者通过像DragGAN这样的技术来进行精细的图像编辑。
GAN不仅可以用于生成任务,还可以作为其他任务的损失函数 ,例如用于图像翻译、超分辨率重建等领域,为这些任务提供有效的监督信号。
避免GAN训练崩溃的一些经验总结
- 归一化图像输入到(-1,1)之间;Generator最后一层使用tanh激活函数
- 生成器的Loss采用: m i n ( l o g ( 1 − D ( G ( z ) ) ) ) min(log(1-D(G(z)))) min(log(1−D(G(z))))。因为原始的生成器Loss存在梯度消失问题;训练生成器的时候,考虑反转标签,real=fake, fake=real。
- 不要在均匀分布上采样,应该在高斯分布上采样
- 一个Mini-batch里面必须只有正样本,或者负样本。不要混在一起;如果用不了Batch Norm,可以用Instance Norm。
- 避免稀疏梯度,即少用ReLU,MaxPool。可以用LeakyReLU替代ReLU,下采样可以用Average Pooling或者Convolution + stride替代。上采样可以用PixelShuffle, ConvTranspose2d + stride
- 平滑标签或者给标签加噪声;平滑标签,即对于正样本,可以使用0.7-1.2的随机数替代;对于负样本,可以使用0-0.3的随机数替代。 给标签加噪声:即训练判别器的时候,随机翻转部分样本的标签。
- 如果可以,用DCGAN或者混合模型:KL+GAN,VAE+GAN。
- 使用LSGAN,WGAN-GP。
- Generator使用Adam,Discriminator使用SGD
- 尽快发现错误;比如:判别器Loss为0,说明训练失败了;如果生成器Loss稳步下降,说明判别器没发挥作用
- 不要试着通过比较生成器和判别器Loss的大小来解决训练过程中的模型坍塌问题。比如: While Loss D > Loss A: Train D While Loss A > Loss D: Train A
- 如果有标签,请尽量利用标签信息来训练
- 给判别器的输入加一些噪声,给G的每一层加一些人工噪声。
- 多训练判别器,尤其是加了噪声的时候
- 对于生成器,在训练,测试的时候使用Dropout
Wasserstein GAN
传统GAN的判别器损失函数本质是JS散度(Jensen-Shannon Divergence),存在两大致命缺陷:
梯度消失:
当真实分布 P r P_r Pr与生成分布 P g P_g Pg无重叠时(高维空间常见),JS散度恒为log2,当 P r ⋂ P g = Φ P_r \bigcap P_g = \Phi Pr⋂Pg=Φ时, J S ( P r ∣ ∣ P g ) = l o g 2 JS(P_r||P_g)=log2 JS(Pr∣∣Pg)=log2
梯度为0,导致训练停滞。
模式崩溃(Mode Collapse):
生成器倾向于生成单一高置信度样本,放弃多样性。
WGAN的核心贡献:
提出用Wasserstein距离(Earth-Mover Distance)替代JS散度,其优势在于:
处处可导:即使真实分布与生成分布无重叠,仍能提供有效梯度
训练稳定性强:损失值直接反映生成质量
Wasserstein距离的数学本质:
物理上:Wasserstein距离描述将概率分布 P r P_r Pr的土堆搬运成概率分布 P g P_g Pg的土堆所需的最小工作量
W ( P r , P g ) = i n f γ ∈ Π ( P r , P g ) E ( x , y ) ∼ γ [ ∣ ∣ x − y ∣ ∣ ] W(P_r, P_g)=inf_{\gamma\in\Pi(P_r,P_g)}E_{(x,y)\sim\gamma}[||x-y||] W(Pr,Pg)=infγ∈Π(Pr,Pg)E(x,y)∼γ[∣∣x−y∣∣]
其中 Π ( P r , P g ) \Pi(P_r,P_g) Π(Pr,Pg)是分布 P r P_r Pr和 P g P_g Pg所有联合分布的集合。
Kantorovich-Rubinstein对偶定理:
通过对偶形式将问题转化为可优化形式:
W ( P r , P g ) = s u p ∣ ∣ f ∣ ∣ L < = 1 E x ∼ P r ( x ) [ f ( x ) ] − E x ∼ P g ( x ) [ f ( x ) ] W(P_r, P_g)=sup_{||f||_L<=1}E_{x\sim P_r(x)}[f(x)]-E_{x\sim P_g(x)}[f(x)] W(Pr,Pg)=sup∣∣f∣∣L<=1Ex∼Pr(x)[f(x)]−Ex∼Pg(x)[f(x)]
要求函数f满足1-Lipschitz连续,即 ∣ ∣ f ( x 1 ) − f ( x 2 ) ∣ ∣ < = ∣ ∣ x 1 − x 2 ∣ ∣ ||f(x_1)-f(x_2)||<=||x_1-x_2|| ∣∣f(x1)−f(x2)∣∣<=∣∣x1−x2∣∣
算法实现:
传统GAN的判别器(输出概率)被替换为评论器(输出标量分数),需满足Lipschitz约束:
class Critic(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 64, 4, stride=2),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, 4, stride=2),
nn.InstanceNorm2d(128), # 使用实例归一化替代BatchNorm
nn.LeakyReLU(0.2),
nn.Conv2d(128, 256, 4, stride=2),
nn.InstanceNorm2d(256),
nn.LeakyReLU(0.2),
nn.Flatten(),
nn.Linear(256*5*5, 1) # 输出实数分数而非概率
)
损失函数:
def wgan_loss(critic_real, critic_fake):
# 最大化真实样本分数 - 生成样本分数
loss_critic = -(torch.mean(critic_real) - torch.mean(critic_fake))
# 生成器目标:最大化生成样本分数
loss_generator = -torch.mean(critic_fake)
return loss_critic, loss_generator
Lipschitz约束的实现:
WGAN提出权重裁剪(Weight Clipping)强制网络满足1-Lipschitz:
for p in critic.parameters():
p.data.clamp_(-0.01, 0.01) # 权重裁剪至[-0.01, 0.01]
该方法易导致梯度消失或爆炸(后续被WGAN-GP改进)。
WGAN-GP:梯度惩罚(Gradient Penalty)
权重裁剪的缺陷:
限制评论器表达能力 ,导致生成质量下降
梯度易饱和(权重被裁剪到边界)
梯度惩罚项
WGAN-GP直接约束函数梯度的L2范数近似于1
L G P = λ E x ′ ∼ P x ′ [ ( ∣ ∣ ∇ x ′ D ( x ′ ) ∣ ∣ 2 − 1 ) 2 ] L_{GP}=\lambda E_{x'\sim P_{x'}}[(||\nabla_{x'}D(x')||_2-1)^2] LGP=λEx′∼Px′[(∣∣∇x′D(x′)∣∣2−1)2]
其中x'是真实样本与生成样本的随机插值点: x ′ = ϵ ∗ x r e a l + ( 1 − ϵ ) ∗ x f a k e , ϵ ∈ U [ 0 , 1 ] x' = \epsilon * x_{real}+(1-\epsilon)*x_{fake}, \epsilon \in U[0,1] x′=ϵ∗xreal+(1−ϵ)∗xfake,ϵ∈U[0,1]
梯度惩罚伪代码
def gradient_penalty(critic, real, fake, device):
epsilon = torch.rand(real.size(0), 1, 1, 1, device=device)
interpolates = epsilon * real + (1 - epsilon) * fake
interpolates.requires_grad_(True)
d_interpolates = critic(interpolates)
# 计算梯度
gradients = torch.autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=torch.ones_like(d_interpolates),
create_graph=True,
retain_graph=True
)[0]
# 惩罚偏离1的梯度范数
gradients_norm = gradients.view(gradients.size(0), -1).norm(2, dim=1)
penalty = ((gradients_norm - 1) ** 2).mean() * lambda_gp
return penalty
在GAN训练中,梯度惩罚项(Gradient Penalty)的核心作用是 强制判别器(Discriminator)满足Lipschitz连续性 ,从而稳定训练过程、改善生成质量,并解决原始Wasserstein GAN(WGAN)中权值裁剪(Weight Clipping)的缺陷。
Wasserstein GAN(WGAN)通过优化Wasserstein距离(Earth-Mover距离)替代传统GAN的JS散度,理论上能缓解模式坍塌和梯度消失问题。
然而,WGAN需要满足Lipschitz约束,即判别器的梯度必须被限制在一定范围内,具体地说,Wasserstein距离的计算要求判别器的函数满足1-Lipschitz连续性,对于任意 x x x,有 ∣ ∣ ∇ x D ( x ) ∣ ∣ < 1 ||\nabla_xD(x)||<1 ∣∣∇xD(x)∣∣<1,即其梯度的范数不超过1:。为此,WGAN-GP(Gradient Penalty)引入了梯度惩罚项来替代权值裁剪,以更有效地实施Lipschitz约束。
原始WGAN通过硬性裁剪判别器的权重到固定范围(如[-0.01, 0.01])来近似满足Lipschitz约束,但易导致梯度消失或爆炸。在损失函数中直接添加对梯度范数的惩罚项,强制判别器的梯度接近1: L G P = λ E x ′ [ ( ∣ ∣ ∇ x ′ D ( x ′ ) ∣ ∣ 2 − 1 ) 2 ] , λ = 10 L_{GP}=\lambda E_{x'}[(||\nabla_{x'}D(x')||_2-1)^2],\lambda=10 LGP=λEx′[(∣∣∇x′D(x′)∣∣2−1)2],λ=10
梯度惩罚项的作用:
稳定训练动力学
- 防止梯度爆炸/消失:
通过约束判别器的梯度范数,避免其参数更新幅度过大或过小,确保生成器(Generator)获得有效的梯度信号。- 平衡对抗过程:
避免判别器过早收敛(判别能力过强导致生成器无法学习),维持生成器与判别器的动态平衡。改善生成质量
- 缓解模式坍塌:
梯度惩罚促使判别器对数据分布的细微变化更敏感,帮助生成器捕捉更多数据模式。- 提升样本多样性:
通过平滑的梯度约束,生成器能更均匀地覆盖数据流形,减少重复样本。理论保障
- 严格满足Lipschitz条件:
相比权值裁剪的间接约束,梯度惩罚直接优化判别器的梯度,更精确地实现1-Lipschitz连续性。- 全局稳定性:
惩罚项作用于真实数据与生成数据之间的插值区域,而非仅关注离散点,确保判别器在整个数据空间上的平滑性。
梯度惩罚项的实践效果- 训练稳定性:
在WGAN-GP中,梯度惩罚显著减少了训练过程中的震荡,使损失曲线更平滑。- 生成质量:
在图像生成任务中(如CelebA、CIFAR-10),生成样本的多样性和清晰度优于传统GAN和原始WGAN。- 超参数敏感性:
惩罚系数 λ \lambda λ需合理设置(通常取10),过大或过小均可能导致训练失效。
| 方法 | 机制 | 优点 | 缺点 |
|---|---|---|---|
| 权值裁剪 | 硬性限制判别器权重范围 | 简单易实现 | 易导致梯度消失、模式坍塌 |
| 谱归一化 | 对权重矩阵进行谱归一化 | 理论严谨,稳定训练 | 计算开销略高 |
| 梯度惩罚(GP) | 直接惩罚梯度范数 | 灵活性强,适应复杂数据分布 | 需计算二阶导数,内存消耗较大 |
DCGAN
Deep Convolutional Generative Adversarial Network
通过引入卷积神经网络(CNN)解决了原始GAN训练不稳定、生成图像质量低的问题。
传统GAN的局限性
训练不稳定:全连接网络易导致梯度消失或爆炸,收敛困难26。
生成质量低:生成的图像模糊、缺乏细节,难以处理高分辨率数据38。
卷积网络的潜力:CNN在图像任务中具有强大的特征提取能力
DCGAN通过以下创新实现稳定训练与高质量生成:
全卷积架构替代全连接层
生成器:使用转置卷积(反卷积)进行上采样,逐步放大噪声向量为图像
判别器:使用步长卷积(Strided Convolution)替代池化层,保留空间信息
批量归一化(Batch Normalization)
应用于除生成器输出层和判别器输入层外的所有层,加速收敛并缓解梯度问题
激活函数优化
生成器:隐藏层用ReLU,输出层用Tanh(将像素值约束到[-1,1])。
判别器:采用LeakyReLU(斜率=0.2),避免负梯度消失。
移除池化层
通过卷积步长控制下采样,避免信息丢失
生成器(Generator)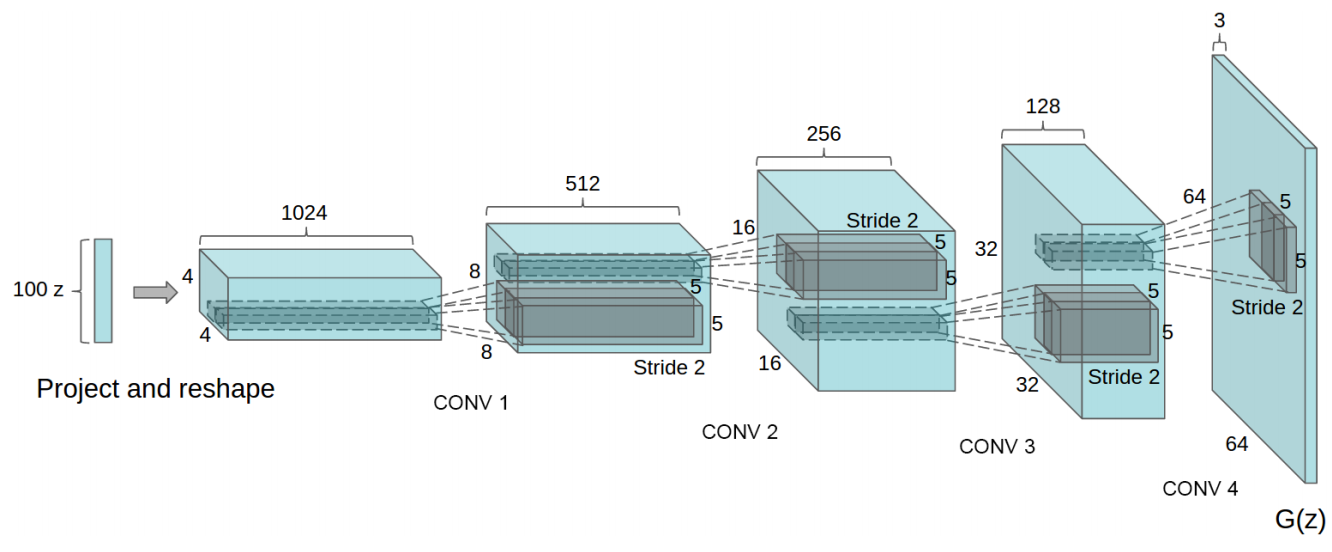
输入:100维随机噪声向量(通常服从均匀分布或高斯分布)。
生成器核心参数:
输入维度:100 (噪声向量)
特征图尺寸变化:4×4 → 8×8 → 16×16 → 32×32 → 64×64
通道数变化:1024 → 512 → 256 → 128 → 3 (RGB)
激活函数:隐藏层ReLU,输出层Tanh
卷积配置:
所有卷积核:4×4
步幅(stride):2 (实现2倍降采样/上采样)
填充(padding):1 (保持尺寸计算)
class Generator:
def __init__(self):
# 初始全连接层:将噪声向量转换为4x4特征图
self.fc = Linear(in_dim=100, out_dim=4*4*1024)
self.reshape = Reshape(shape=(4, 4, 1024))
# 反卷积(转置卷积)块序列
self.deconv_blocks = [
{ # 上采样到8x8
'deconv': ConvTranspose2d(in_channels=1024, out_channels=512,
kernel_size=4, stride=2, padding=1),
'bn': BatchNorm2d(512),
'act': ReLU()
},
{ # 上采样到16x16
'deconv': ConvTranspose2d(in_channels=512, out_channels=256,
kernel_size=4, stride=2, padding=1),
'bn': BatchNorm2d(256),
'act': ReLU()
},
{ # 上采样到32x32
'deconv': ConvTranspose2d(in_channels=256, out_channels=128,
kernel_size=4, stride=2, padding=1),
'bn': BatchNorm2d(128),
'act': ReLU()
},
{ # 上采样到64x64 (输出层)
'deconv': ConvTranspose2d(in_channels=128, out_channels=3,
kernel_size=4, stride=2, padding=1),
'act': Tanh() # 无BN,输出值归一化到[-1,1]
}
]
def forward(self, z):
# 输入处理
x = self.fc(z)
x = self.reshape(x)
# 通过反卷积块
for block in self.deconv_blocks:
x = block['deconv'](x)
if 'bn' in block:
x = block['bn'](x)
x = block['act'](x)
return x # 输出形状: (batch_size, 64, 64, 3)
判别器(Discriminator)
输入:真实图像或生成图像(64×64×3)。
判别器核心参数:
输入维度:64×64×3 (RGB图像)
特征图尺寸变化:64×64 → 32×32 → 16×16 → 8×8 → 4×4
通道数变化:3 → 128 → 256 → 512 → 1024
激活函数:LeakyReLU (斜率0.2)
class Discriminator:
def __init__(self):
# 卷积块序列 (无池化层,使用步幅卷积降采样)
self.conv_blocks = [
{ # 降采样到32x32
'conv': Conv2d(in_channels=3, out_channels=128,
kernel_size=4, stride=2, padding=1),
'act': LeakyReLU(alpha=0.2) # 无BN
},
{ # 降采样到16x16
'conv': Conv2d(in_channels=128, out_channels=256,
kernel_size=4, stride=2, padding=1),
'bn': BatchNorm2d(256),
'act': LeakyReLU(alpha=0.2)
},
{ # 降采样到8x8
'conv': Conv2d(in_channels=256, out_channels=512,
kernel_size=4, stride=2, padding=1),
'bn': BatchNorm2d(512),
'act': LeakyReLU(alpha=0.2)
},
{ # 降采样到4x4
'conv': Conv2d(in_channels=512, out_channels=1024,
kernel_size=4, stride=2, padding=1),
'bn': BatchNorm2d(1024),
'act': LeakyReLU(alpha=0.2)
}
]
# 分类头
self.flatten = Flatten()
self.fc = Linear(in_dim=4*4*1024, out_dim=1)
self.sigmoid = Sigmoid() # 输出真假概率
def forward(self, img):
# 通过卷积块
x = img
for block in self.conv_blocks:
x = block['conv'](x)
if 'bn' in block:
x = block['bn'](x)
x = block['act'](x)
# 分类决策
x = self.flatten(x)
x = self.fc(x)
return self.sigmoid(x) # 输出形状: (batch_size, 1)
训练细节与优化策略
数据预处理:图像归一化至[-1, 1](对应Tanh输出范围)。
优化器与超参数:Adam优化器:学习率=0.0002,动量参数β₁=0.5(低于默认值0.9,减少振荡)。
批大小:128。
参数初始化:权重从均值为0、标准差为0.02的高斯分布采样。
损失函数:沿用原始GAN的二元交叉熵(BCE Loss),但梯度更稳定(因卷积结构)
CGAN
Conditional Generative Adversarial Nets
https://github.com/Lornatang/conditional_gan.git
传统GAN学习数据分布 p d a t a ( x ) p_{data}(x) pdata(x),生成器 G ( z ) G(z) G(z) 将噪声 z ∼ p z ( z ) z\sim p_z(z) z∼pz(z) 映射到数据空间,判别器 D ( x ) D(x) D(x) 区分真实/生成数据,但是无法控制生成的具体属性。
min G max D V ( D , G ) = E x ∼ p d a t a [ log D ( x ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ] \min_G \max_D V(D,G) = \mathbb{E}_{x\sim p_{data}}[\log D(x)] + \mathbb{E}_{z\sim p_z}[\log(1-D(G(z)))] minGmaxDV(D,G)=Ex∼pdata[logD(x)]+Ez∼pz[log(1−D(G(z)))]
通过在生成器和判别器中引入额外的条件信息,使模型能够生成符合特定条件的输出。生成器根据随机噪声和条件信息生成图像,判别器则根据输入图像和条件信息判断图像的真实性。。条件信息可以是类别标签、属性描述或其他数据样本。
引入条件变量 c c c(如类别标签、文本描述),使生成过程条件化:
min G max D V ( D , G ) = E x ∼ p d a t a [ log D ( x ∣ c ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ∣ c ) ) ) ] \min_G \max_D V(D,G) = \mathbb{E}_{x\sim p_{data}}[\log D(x|c)] + \mathbb{E}_{z\sim p_z}[\log(1-D(G(z|c)))] minGmaxDV(D,G)=Ex∼pdata[logD(x∣c)]+Ez∼pz[log(1−D(G(z∣c)))]
| 输入位置 | 实现方法 | 适用场景 |
|---|---|---|
| 生成器输入 | 噪声z与条件c拼接 | 简单条件(如类别标签) |
| 中间层 | AdaIN(自适应实例归一化) | 风格迁移 |
| 注意力机制 | 条件引导的注意力门控 | 文本到图像生成 |
| 投影判别器 | 条件向量与特征图点积(BigGAN) | 高分辨率条件生成 |
生成器伪代码:
class CGAN_Generator(nn.Module):
def __init__(self, z_dim, c_dim, img_channels):
super().__init__()
# 条件嵌入层
self.embed = nn.Embedding(c_dim, c_embed_dim) # 或使用LSTM处理文本
# 生成网络
self.model = nn.Sequential(
# 输入: [z_dim + c_embed_dim]
nn.Linear(z_dim + c_embed_dim, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Linear(512, 256*7*7), # 上采样起点
nn.BatchNorm1d(256*7*7),
nn.ReLU(),
ViewLayer((-1, 256, 7, 7)), # 重塑为图像张量
# 转置卷积上采样
nn.ConvTranspose2d(256, 128, 4, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.ConvTranspose2d(128, img_channels, 4, stride=2, padding=1),
nn.Tanh()
)
def forward(self, z, c):
# 嵌入条件信息
c_embed = self.embed(c) # 或使用文本编码器
# 拼接噪声与条件
x = torch.cat([z, c_embed], dim=1)
return self.model(x)
判别器伪代码:
class ProjectionDiscriminator(nn.Module):
def __init__(self, in_channels, c_dim):
super().__init__()
# 特征提取主干
self.feature_net = nn.Sequential(...) # CNN网络
# 条件投影
self.embed = nn.Embedding(c_dim, feature_dim)
self.linear = nn.Linear(feature_dim, feature_dim)
def forward(self, x, c):
# 提取特征
features = self.feature_net(x) # [B, C, H, W]
features = torch.sum(features, dim=[2,3]) # 全局池化 [B, C]
# 条件投影
embed_c = self.embed(c) # [B, feature_dim]
proj = torch.sum(features * self.linear(embed_c), dim=1, keepdim=True)
# 无条件分支
out_uncond = self.linear_uncond(features)
return out_uncond + proj # 条件化输出
CGAN的损失函数
def cgan_loss(D_real, D_fake, c_real, c_fake):
# 判别器损失
loss_D_real = F.binary_cross_entropy_with_logits(D_real, torch.ones_like(D_real))
loss_D_fake = F.binary_cross_entropy_with_logits(D_fake, torch.zeros_like(D_fake))
# 条件匹配损失
loss_cond = F.cross_entropy(D_classifier(x_fake), c_fake)
return loss_D_real + loss_D_fake + λ * loss_cond
条件Dropout:
训练时以概率 p p p 随机丢弃条件信息,提升鲁棒性:
if self.training and torch.rand(1) < p_drop:
c = torch.zeros_like(c) # 零向量替代条件
条件增强:
对条件 c c c 添加噪声: c ′ = c + ϵ , ϵ ∼ N ( 0 , σ 2 ) c' = c + \epsilon, \epsilon \sim \mathcal{N}(0,\sigma^2) c′=c+ϵ,ϵ∼N(0,σ2),提高泛化能力
渐进式条件训练:
先训练无条件模型,逐步引入条件信息
SAGAN
Self-Attention Generative Adversarial Networks
2018
引入自注意力机制解决了传统卷积GAN难以建模图像长距离依赖的问题,显著提升了生成图像的结构一致性与细节质量。
动机
传统卷积层受限于局部感受野,需堆叠多层才能捕获全局依赖,导致计算效率低且难以生成结构复杂的物体(如动物肢体、几何规则物体)。
在ImageNet等多类别数据集上,卷积GAN生成的纹理类图像(如天空、海洋)质量高,但结构类图像(如狗、建筑)常出现肢体缺失或扭曲。
自注意力机制通过计算特征图所有位置间的相关性,直接建模像素间长程依赖,使生成器能协调全局结构。相比全连接层,自注意力以更低计算成本实现全局交互,平衡效率与表达能力。
方法
相关性计算:
S = f ( x ) T ∗ g ( x ) S=f(x)^T*g(x) S=f(x)T∗g(x),其中 f ( x ) , g ( x ) ∈ R C / 8 ∗ N , N = H ∗ W f(x),g(x)\in R^{C/8 * N}, N=H*W f(x),g(x)∈RC/8∗N,N=H∗W
S ∈ R N ∗ N S\in R^{N*N} S∈RN∗N,则 β j , i = e x p ( S j , i ) ∑ i = 1 N e x p ( S j , i ) \beta_{j,i}=\frac{exp(S_{j,i})}{\sum_{i=1}^Nexp(S_{j,i})} βj,i=∑i=1Nexp(Sj,i)exp(Sj,i)为位置j对位置i的注意力权重
输出重构:
o j = ∑ i = 1 N β j , i ∗ h ( x i ) , h ( x ) ∈ R C ∗ N o_j=\sum_{i=1}^N\beta_{j,i}*h(x_i),h(x)\in R^{C*N} oj=∑i=1Nβj,i∗h(xi),h(x)∈RC∗N
最终输出 o f i n a l = v ( o ) ∗ γ + x o_{final}=v(o)*\gamma + x ofinal=v(o)∗γ+x, γ \gamma γ为可学习缩放参数,初始为0。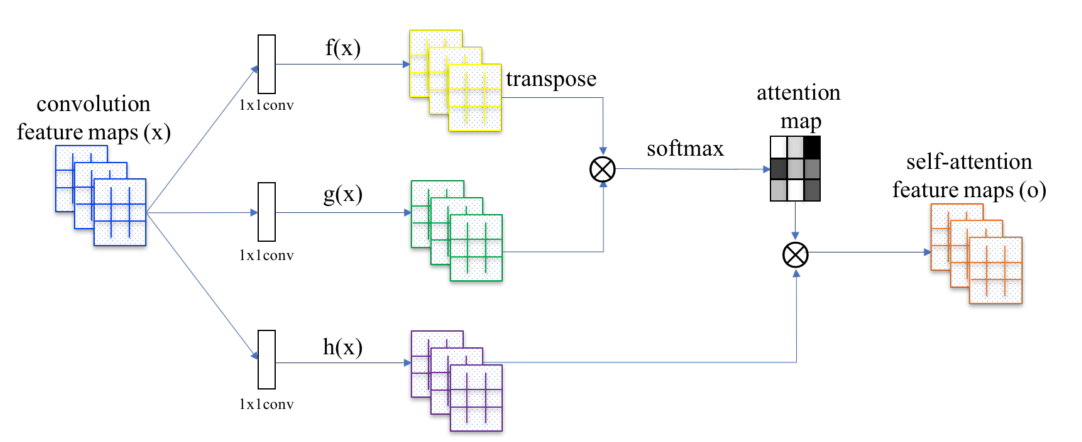
谱归一化(Spectral Normalization)
同时作用于生成器(G)和判别器(D)的权重矩阵
W S N = W / σ ( W ) W_{SN}=W/\sigma(W) WSN=W/σ(W)
σ ( W ) \sigma(W) σ(W)为权重矩阵的谱范数(最大奇异值)。
作用:约束Lipschitz常数,稳定训练动态,避免梯度爆炸
非对称学习率(TTUR)
判别器学习率(0.0004)高于生成器(0.0001),平衡两者收敛速度,替代传统“1G vs. kD”的交替更新策略,减少计算开销
条件批量归一化(Conditional BatchNorm)
在生成器中引入类别条件,将类别嵌入向量投影到BN层的 γ \gamma γ和 β \beta β参数,增强类内一致性
ProGAN
Progressive Growing of GANs for Improved Quality, Stability, and Variation
动机
训练不稳定:传统GAN高分辨率图像生成(如1024×1024)易出现模式崩溃(Mode Collapse),判别器“击败”生成器导致梯度失效
计算效率低:直接训练高分辨率模型参数量大,收敛慢且显存需求高
高分辨率下细节质量差
ProGAN通过逐步增加生成器和判别器的分辨率来训练模型。最初从低分辨率图像开始训练,然后逐渐添加新的层以生成更高分辨率的图像。这种渐进式的方法有助于模型更稳定地收敛,并提高生成图像的质量和多样性。
方法
渐进式训练(Progressive Training):
从低分辨率(4×4)开始训练,逐步增加网络层以提高分辨率(8×8→16×16→…→1024×1024),分阶段学习图像结构。
在训练的每个阶段,模型学习生成更高分辨率的图像细节,同时保留之前阶段学到的低分辨率特征。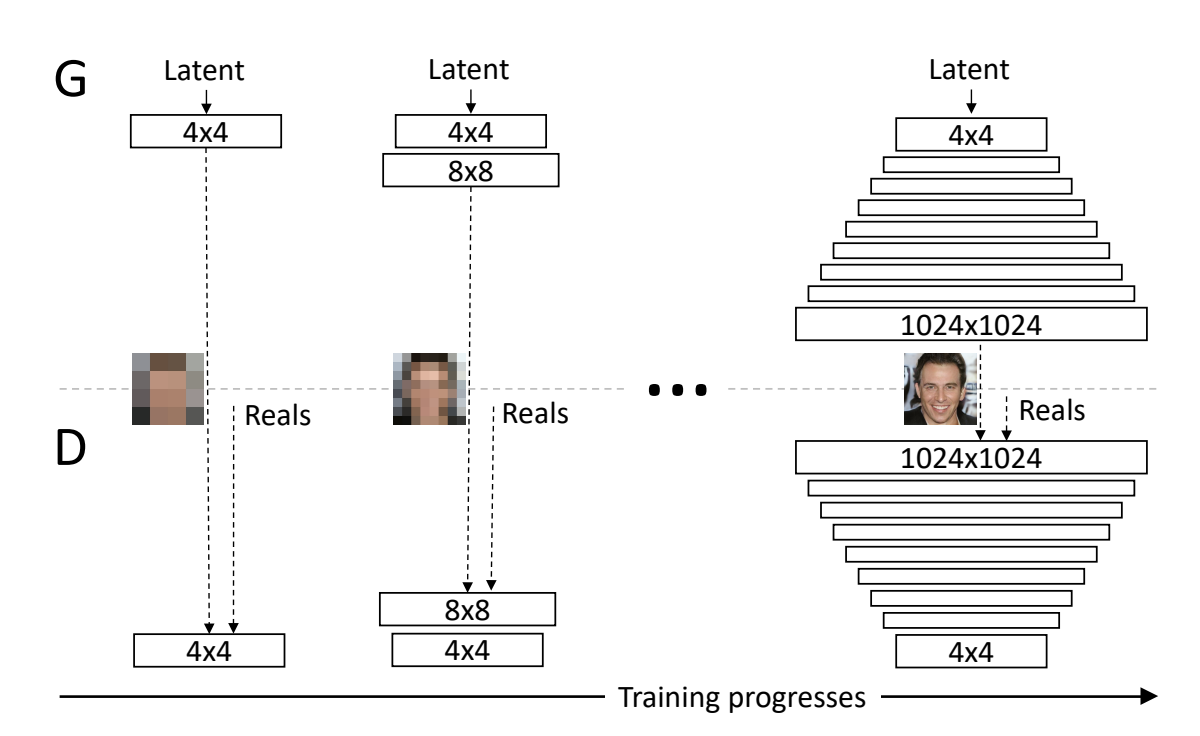
过渡阶段(Transition Phase):
新增层通过权重 α \alpha α线性淡入(0→1),输出图像为旧层与新层的加权组合: o u t p u t = ( 1 − α ) ∗ o r e s + α ∗ o h i g h r e s output=(1-\alpha)*o_{res}+\alpha*o_{highres} output=(1−α)∗ores+α∗ohighres,避免突变冲击已训练层。
稳定阶段(Stabilization Phase):
α = 1 \alpha=1 α=1后固定网络结构,微调所有权重
网络架构同步增长
生成器(Generator):
低层→高层:通道数递减(如512→256),分辨率倍增(如4×4→8×8)。
上采样使用最近邻插值(非转置卷积),后接两个卷积层。
判别器(Discriminator):
与生成器镜像对称,下采样使用平均池化
小批量标准差(Minibatch Standard Deviation)
计算小批量内所有样本在每个空间位置的特征标准差。将均值标准差作为额外通道拼接到判别器输入,增加生成多样性,防止模式崩溃。
逐像素归一化(Pixelwise Normalization)取代批归一化(BatchNorm),避免批次依赖
均等学习率(Equalized Learning Rate)
权重初始化后乘以 c c c(为 H e He He初始化常数),确保各层梯度幅度一致,避免深层网络梯度消失/爆炸,加速收敛
指数移动平均(EMA),生成器权重更新:
θ E M A = β ∗ θ E M A + ( 1 − β ) ∗ θ G , β = 0.999 \theta_{EMA}=\beta*\theta_{EMA}+(1-\beta)*\theta_G, \beta=0.999 θEMA=β∗θEMA+(1−β)∗θG,β=0.999,平滑训练波动。
伪代码
import torch
import torch.nn as nn
import torch.nn.functional as F
# ========================
# 核心组件实现
# ========================
class PixelwiseNorm(nn.Module):
"""逐像素归一化 (ProGAN特有)"""
def __init__(self, epsilon=1e-8):
super().__init__()
self.epsilon = epsilon
def forward(self, x):
# 计算通道维度的L2范数 [B, C, H, W] -> [B, 1, H, W]
norm = torch.sqrt(torch.mean(x**2, dim=1, keepdim=True) + self.epsilon
return x / norm
class MinibatchStdDev(nn.Module):
"""小批量标准差层 (增加生成多样性)"""
def __init__(self, group_size=4):
super().__init__()
self.group_size = group_size
def forward(self, x):
# 输入形状: [B, C, H, W]
B, C, H, W = x.shape
group_size = min(self.group_size, B)
# 重塑为 [G, M, C, H, W] 其中 G = group_size, M = B // G
y = x.view(group_size, -1, C, H, W)
# 计算组内标准差 [G, M, C, H, W] -> [G, M, 1, H, W]
stddev = torch.sqrt(y.var(dim=0, unbiased=False) + 1e-8
# 取平均并扩展为 [B, 1, H, W]
stddev = stddev.mean(dim=[2, 3, 4], keepdim=True).squeeze(2)
stddev = stddev.repeat(group_size, 1, H, W)
# 拼接为额外通道 [B, C+1, H, W]
return torch.cat([x, stddev], dim=1)
class EqualizedLinear(nn.Module):
"""均等学习率全连接层"""
def __init__(self, in_dim, out_dim, lr_multiplier=0.01):
super().__init__()
self.weight = nn.Parameter(torch.randn(out_dim, in_dim))
self.bias = nn.Parameter(torch.zeros(out_dim))
self.lr_multiplier = lr_multiplier
self.scale = (lr_multiplier / (in_dim ** 0.5))
def forward(self, x):
return F.linear(x, self.weight * self.scale, self.bias * self.lr_multiplier)
class EqualizedConv2d(nn.Module):
"""均等学习率卷积层"""
def __init__(self, in_ch, out_ch, kernel, stride=1, padding=0, lr_multiplier=0.01):
super().__init__()
self.weight = nn.Parameter(torch.randn(out_ch, in_ch, kernel, kernel))
self.bias = nn.Parameter(torch.zeros(out_ch))
self.stride = stride
self.padding = padding
self.lr_multiplier = lr_multiplier
self.scale = (lr_multiplier / (in_ch * kernel * kernel) ** 0.5)
def forward(self, x):
return F.conv2d(
x, self.weight * self.scale, self.bias * self.lr_multiplier,
stride=self.stride, padding=self.padding
)
# ========================
# 生成器架构
# ========================
class GeneratorBlock(nn.Module):
"""生成器基础块 (每个分辨率级别)"""
def __init__(self, in_ch, out_ch, initial_block=False):
super().__init__()
self.initial_block = initial_block
if initial_block:
# 初始块 (4x4)
self.conv1 = EqualizedConv2d(in_ch, out_ch, 4, padding=3) # 4x4卷积
self.conv2 = EqualizedConv2d(out_ch, out_ch, 3, padding=1)
else:
# 标准块
self.upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.conv1 = EqualizedConv2d(in_ch, out_ch, 3, padding=1)
self.conv2 = EqualizedConv2d(out_ch, out_ch, 3, padding=1)
self.pixelnorm = PixelwiseNorm()
self.lrelu = nn.LeakyReLU(0.2)
def forward(self, x):
if not self.initial_block:
x = self.upsample(x)
x = self.lrelu(self.conv1(x))
x = self.pixelnorm(x)
x = self.lrelu(self.conv2(x))
return self.pixelnorm(x)
class Generator(nn.Module):
"""渐进式生成器"""
def __init__(self, latent_dim=512, max_resolution=1024):
super().__init__()
self.latent_dim = latent_dim
self.max_resolution = max_resolution
# 初始块 (4x4)
self.initial_block = GeneratorBlock(latent_dim, 512, initial_block=True)
# 动态构建分辨率块 [8x8, 16x16, ..., max_resolution]
self.blocks = nn.ModuleList()
self.to_rgb_layers = nn.ModuleList() # RGB输出层
# 分辨率序列: 4->8->16->32->64->128->256->512->1024
resolutions = [4 * (2**i) for i in range(1, int(torch.log2(torch.tensor(max_resolution//4)) + 1)]
channels = [512, 512, 512, 512, 256, 128, 64, 32, 16] # 通道递减
for res, out_ch in zip(resolutions, channels):
self.blocks.append(GeneratorBlock(channels[0], out_ch))
self.to_rgb_layers.append(EqualizedConv2d(out_ch, 3, 1)) # 1x1卷积转RGB
channels.pop(0) # 更新输入通道数
# 当前训练阶段
self.current_stage = 0 # 0表示4x4阶段
self.alpha = 0.0 # 过渡阶段混合权重
def set_stage(self, stage, alpha=0.0):
"""设置当前训练阶段和alpha值"""
self.current_stage = stage
self.alpha = alpha
def forward(self, z):
"""
z: 潜在向量 [B, latent_dim]
"""
# 初始映射
x = z.view(z.size(0), self.latent_dim, 1, 1) # [B, 512, 1, 1]
# 通过初始块 (4x4)
x = self.initial_block(x)
# 如果当前阶段>0 (4x4以上)
if self.current_stage > 0:
# 低分辨率路径 (用于过渡混合)
rgb_low = self.to_rgb_layers[0](x)
rgb_low = F.interpolate(rgb_low, scale_factor=2**(self.current_stage), mode='nearest')
# 渐进通过后续块
for i in range(self.current_stage):
x = self.blocks[i](x)
# 当前分辨率输出
rgb_high = self.to_rgb_layers[self.current_stage](x)
# 过渡混合
if self.alpha < 1.0:
return (1 - self.alpha) * rgb_low + self.alpha * rgb_high
else:
return rgb_high
else:
# 4x4阶段直接输出
return self.to_rgb_layers[0](x)
# ========================
# 判别器架构
# ========================
class DiscriminatorBlock(nn.Module):
"""判别器基础块"""
def __init__(self, in_ch, out_ch, final_block=False):
super().__init__()
self.final_block = final_block
self.conv1 = EqualizedConv2d(in_ch, in_ch, 3, padding=1)
self.conv2 = EqualizedConv2d(in_ch, out_ch, 3, padding=1)
if not final_block:
self.downsample = nn.AvgPool2d(2)
self.residual = nn.Sequential(
nn.AvgPool2d(2),
EqualizedConv2d(in_ch, out_ch, 1) # 1x1卷积调整通道
)
else:
# 最终块添加小批量标准差
self.minibatch_std = MinibatchStdDev()
self.conv_final = EqualizedConv2d(out_ch + 1, out_ch, 3, padding=1)
self.residual = EqualizedConv2d(in_ch, out_ch, 1)
self.lrelu = nn.LeakyReLU(0.2)
def forward(self, x):
# 残差路径
residual = self.residual(x)
# 主路径
x = self.lrelu(self.conv1(x))
x = self.lrelu(self.conv2(x))
if not self.final_block:
x = self.downsample(x)
# 添加残差连接 (需通道对齐)
return x + residual
else:
# 最终块特殊处理
x = self.minibatch_std(x)
x = self.lrelu(self.conv_final(x))
return x + residual
class Discriminator(nn.Module):
"""渐进式判别器"""
def __init__(self, max_resolution=1024):
super().__init__()
self.max_resolution = max_resolution
# 动态构建块 [max_resolution, 512, 256, ..., 4]
self.blocks = nn.ModuleList()
self.from_rgb_layers = nn.ModuleList() # RGB输入层
# 分辨率序列: 1024->512->256->128->64->32->16->8->4
resolutions = [max_resolution // (2**i) for i in range(int(torch.log2(torch.tensor(max_resolution//4)))]
resolutions.reverse()
channels = [16, 32, 64, 128, 256, 512, 512, 512, 512] # 通道递增
# 添加最终块 (4x4)
self.final_block = DiscriminatorBlock(channels[-1], 512, final_block=True)
self.final_linear = EqualizedLinear(512*4*4, 1) # 最终输出层
for i, res in enumerate(resolutions):
in_ch = 3 if i == 0 else channels[i-1]
self.blocks.append(DiscriminatorBlock(in_ch, channels[i]))
self.from_rgb_layers.append(EqualizedConv2d(3, in_ch, 1)) # 1x1卷积处理RGB
# 当前训练阶段
self.current_stage = len(self.blocks) - 1 # 最高分辨率开始
self.alpha = 0.0
def set_stage(self, stage, alpha=0.0):
"""设置当前训练阶段和alpha值"""
self.current_stage = stage
self.alpha = alpha
def forward(self, x):
# 高分辨率路径 (当前阶段)
x_high = self.from_rgb_layers[self.current_stage](x)
x_high = self.blocks[self.current_stage](x_high)
# 过渡混合处理
if self.alpha < 1.0 and self.current_stage > 0:
# 低分辨率路径 (降采样输入)
x_low = F.avg_pool2d(x, kernel_size=2, stride=2)
x_low = self.from_rgb_layers[self.current_stage-1](x_low)
# 混合特征
x = (1 - self.alpha) * x_low + self.alpha * x_high
# 通过剩余块
for i in range(self.current_stage-1, -1, -1):
x = self.blocks[i](x)
# 最终块 (4x4)
x = self.final_block(x)
x = x.view(x.size(0), -1)
return self.final_linear(x)
# ========================
# 训练循环伪代码
# ========================
class ProGANTrainer:
def __init__(self, latent_dim=512, start_res=4, device='cuda'):
self.device = device
self.resolution = start_res # 当前分辨率 (4, 8, 16, ...)
self.stage = 0 # 训练阶段 (0=4x4, 1=8x8, ...)
self.alpha = 0.0 # 过渡阶段混合系数
# 初始化模型
self.G = Generator(latent_dim).to(device)
self.D = Discriminator().to(device)
# 优化器 (均等学习率已内置)
self.opt_G = torch.optim.Adam(self.G.parameters(), lr=0.001, betas=(0.0, 0.99))
self.opt_D = torch.optim.Adam(self.D.parameters(), lr=0.001, betas=(0.0, 0.99))
# 指数移动平均 (EMA)
self.G_ema = Generator(latent_dim).to(device)
self.G_ema.load_state_dict(self.G.state_dict())
self.ema_beta = 0.999
# 分辨率配置
self.resolutions = [4, 8, 16, 32, 64, 128, 256, 512, 1024]
self.stage_epochs = [20, 20, 20, 20, 20, 20, 20, 10, 10] # 每阶段训练轮数
def update_ema(self):
"""更新生成器的EMA权重"""
with torch.no_grad():
for p_ema, p in zip(self.G_ema.parameters(), self.G.parameters()):
p_ema.copy_(self.ema_beta * p_ema + (1 - self.ema_beta) * p)
def train_step(self, real_images):
"""单次训练迭代"""
# 设置模型当前阶段
self.G.set_stage(self.stage, self.alpha)
self.D.set_stage(self.stage, self.alpha)
B = real_images.size(0)
# ===== 训练判别器 =====
self.opt_D.zero_grad()
# 真实图像
real_pred = self.D(real_images)
loss_D_real = F.softplus(-real_pred).mean() # -log(sigmoid(real_pred))
# 生成图像
z = torch.randn(B, self.G.latent_dim, device=self.device)
fake_images = self.G(z).detach() # 阻断生成器梯度
fake_pred = self.D(fake_images)
loss_D_fake = F.softplus(fake_pred).mean() # -log(1 - sigmoid(fake_pred))
# 梯度惩罚 (WGAN-GP)
gp = self.gradient_penalty(real_images, fake_images)
loss_D = loss_D_real + loss_D_fake + 10 * gp
loss_D.backward()
self.opt_D.step()
# ===== 训练生成器 =====
self.opt_G.zero_grad()
z = torch.randn(B, self.G.latent_dim, device=self.device)
fake_images = self.G(z)
fake_pred = self.D(fake_images)
loss_G = F.softplus(-fake_pred).mean() # -log(sigmoid(fake_pred))
loss_G.backward()
self.opt_G.step()
# 更新EMA生成器
self.update_ema()
return loss_D.item(), loss_G.item()
def gradient_penalty(self, real, fake):
"""WGAN-GP梯度惩罚"""
alpha = torch.rand(real.size(0), 1, 1, 1, device=self.device)
interpolated = (alpha * real + (1 - alpha) * fake).requires_grad_(True)
pred = self.D(interpolated)
grad = torch.autograd.grad(
outputs=pred, inputs=interpolated,
grad_outputs=torch.ones_like(pred),
create_graph=True, retain_graph=True
)[0]
grad_norm = grad.view(grad.size(0), -1).norm(2, dim=1)
return ((grad_norm - 1.0) ** 2).mean()
def progressive_training(self, dataloader):
"""渐进训练主循环"""
total_stages = len(self.resolutions)
for stage in range(total_stages):
self.stage = stage
resolution = self.resolutions[stage]
num_epochs = self.stage_epochs[stage]
print(f"===== 开始训练 {resolution}x{resolution} 分辨率 (阶段 {stage+1}/{total_stages}) =====")
# 过渡阶段 (仅当stage>0)
if stage > 0:
print(f"过渡阶段: alpha 0.0 -> 1.0")
for epoch in range(num_epochs // 2):
self.alpha = epoch / (num_epochs // 2 - 1) # 线性增加alpha
for batch in dataloader:
# 调整图像到当前分辨率
real = F.interpolate(batch, size=resolution, mode='bilinear')
loss_D, loss_G = self.train_step(real)
# 稳定阶段 (alpha=1.0)
self.alpha = 1.0
for epoch in range(num_epochs // 2):
for batch in dataloader:
real = F.interpolate(batch, size=resolution, mode='bilinear')
loss_D, loss_G = self.train_step(real)
print(f"阶段 {stage+1} | 轮次 {epoch+1}/{num_epochs//2} | "
f"Loss_D: {loss_D:.4f} | Loss_G: {loss_G:.4f}")
# 保存检查点
torch.save({
'G': self.G.state_dict(),
'D': self.D.state_dict(),
'G_ema': self.G_ema.state_dict(),
'stage': stage,
'resolution': resolution
}, f"progan_stage_{stage}.pth")
# 准备下一阶段 (添加新层)
if stage < total_stages - 1:
self._add_new_layers(stage + 1)
def _add_new_layers(self, next_stage):
"""动态添加新层 (简化示意)"""
print(f"添加 {self.resolutions[next_stage]}x{self.resolutions[next_stage]} 层...")
# 生成器添加新块
next_ch = self.G.channels[next_stage]
new_block = GeneratorBlock(self.G.blocks[-1].out_ch, next_ch).to(self.device)
self.G.blocks.append(new_block)
self.G.to_rgb_layers.append(EqualizedConv2d(next_ch, 3, 1).to(self.device))
# 判别器添加新块 (前置)
prev_ch = self.D.channels[next_stage-1]
new_block = DiscriminatorBlock(3, prev_ch).to(self.device) # 输入通道为3
self.D.blocks.insert(0, new_block)
self.D.from_rgb_layers.insert(0, EqualizedConv2d(3, prev_ch, 1).to(self.device))
# 更新优化器
self.opt_G = torch.optim.Adam(self.G.parameters(), lr=0.001)
self.opt_D = torch.optim.Adam(self.D.parameters(), lr=0.001)
# ========================
# 使用示例
# ========================
if __name__ == "__main__":
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 初始化训练器 (从4x4开始)
trainer = ProGANTrainer(start_res=4, device=device)
# 准备数据集 (伪代码)
from torch.utils.data import DataLoader
dataset = YourImageDataset(resolution=1024) # 原始高分辨率数据集
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)
# 开始渐进训练
trainer.progressive_training(dataloader)
# 最终保存模型
torch.save(trainer.G_ema.state_dict(), "progan_generator_final.pth")
BigGAN
Large Scale GAN Training for High Fidelity Natural Image Synthesis
2018 DeepMind
https://github.com/ajbrock/BigGAN-PyTorch.git
动机
在BigGAN之前,GAN在ImageNet等复杂数据集上生成高分辨率(如128×128以上)、多样性样本的能力严重不足。
因此通过大规模训练(增大Batch Size、网络宽度)结合稳定性优化,解决GAN在复杂数据上的生成瓶颈,实现保真度与多样性的平衡
方法
增大Batch Size
将Batch Size从256增至2048(8倍),IS提升46%。大Batch覆盖更多数据模式,为生成器(G)和判别器(D)提供更稳定的梯度
增加通道数
每层通道数增加50%,总参数量达16亿(基线2-4倍),IS再提升21%。增加深度反而降低性能,表明宽度对复杂数据集更关键
共享嵌入:将类别标签投影到所有BatchNorm层的缩放(gamma)和偏置(bias),减少内存消耗,训练速度提升37%。
分层潜在空间:将噪声向量 z z z切分后输入 G G G的每一层(而非仅输入层),提升4%性能并加速18%。
截断技巧(Truncation Trick)
在推理阶段对先验分布 z ∼ N ( 0 , 1 ) z\sim N(0,1) z∼N(0,1)截断(阈值外重新采样),通过缩小z的方差实现保真度-多样性权衡
正交正则化(Orthogonal Regularization)
R b e t a ( W ) = β ∣ ∣ W T W ∗ ( 1 − I ) ∣ ∣ F 2 R_{beta}(W)=\beta||W^TW*(1-I)||_F^2 Rbeta(W)=β∣∣WTW∗(1−I)∣∣F2
其中 W W W为权重矩阵, β = 1 e − 4 \beta=1e-4 β=1e−4。删除对角项,仅最小化滤波器间余弦相似性(不约束范数),避免传统正交约束的过强限制。使 G G G对 z z z的映射更平滑,截断适应性从16%→60%,显著减少伪影。
# 正交正则化实现示例(PyTorch)
def orthogonal_regularization(W, beta=1e-4):
W_flat = W.view(W.shape[0], -1)
WTW = torch.mm(W_flat, W_flat.t())
I = torch.eye(WTW.size(0), device=W.device)
return beta * torch.norm(WTW * (1 - I), p="fro")**2
# 截断采样(推理阶段)
def truncated_z(batch_size, z_dim, truncation=0.5):
z = torch.randn(batch_size, z_dim)
while True:
mask = (z.abs() > truncation).any(dim=1)
if not mask.any(): break
z[mask] = torch.randn(mask.sum(), z_dim)
return z
稳定性控制:
生成器( G G G)不稳定性:
监控权重矩阵的奇异值 ( σ 0 , σ 1 , σ 2 ) (\sigma_0,\sigma_1,\sigma_2) (σ0,σ1,σ2),发现训练崩溃时 G G G的第一层谱范数爆炸性增长。
解决方案:钳制最大奇异值(如 σ 0 = r ∗ s g ( σ 1 ) \sigma_0 = r*sg(\sigma_1) σ0=r∗sg(σ1))或使用偏SVD动态调整权重,但无法完全避免崩溃。
判别器( D D D)不稳定性:
D的损失在崩溃时剧增(正常时约为0),因过度记忆训练集(训练集分类精度98% vs 验证集50%)。
强正则化(如梯度惩罚 R 1 = γ 2 E [ ∣ ∇ D ( x ) ∣ F 2 ] R_1 = \frac{\gamma}{2} E[|\nabla D(x)|_F^2] R1=2γE[∣∇D(x)∣F2])可稳定训练但牺牲性能。
基础框架:
基于SAGAN,使用深度残差网络架构:
条件BN( G G G) + 投影判别器( D D D)
Hinge Loss + 谱归一化( D D D)。
训练配置:
优化器:Adam( G G G学习率减半,每1步 G G G对应2步 D D D)
伪代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.utils import spectral_norm
# ========================
# 核心组件实现
# ========================
class ConditionalBatchNorm2d(nn.Module):
"""条件批量归一化 (BigGAN关键创新)"""
def __init__(self, num_features, num_classes, spectral=False):
super().__init__()
self.num_features = num_features
self.bn = nn.BatchNorm2d(num_features, affine=False)
# 条件增益/偏置
self.gain = spectral_norm(nn.Linear(num_classes, num_features)) if spectral else nn.Linear(num_classes, num_features)
self.bias = spectral_norm(nn.Linear(num_classes, num_features)) if spectral else nn.Linear(num_classes, num_features)
def forward(self, x, y):
# 标准批量归一化
x = self.bn(x)
# 从类别标签生成增益和偏置
gain = (1 + self.gain(y)).view(-1, self.num_features, 1, 1)
bias = self.bias(y).view(-1, self.num_features, 1, 1)
return x * gain + bias
class SelfAttention(nn.Module):
"""自注意力机制 (SA-GAN引入)"""
def __init__(self, in_channels):
super().__init__()
self.query = spectral_norm(nn.Conv1d(in_channels, in_channels // 8, 1))
self.key = spectral_norm(nn.Conv1d(in_channels, in_channels // 8, 1))
self.value = spectral_norm(nn.Conv1d(in_channels, in_channels, 1))
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
B, C, H, W = x.shape
N = H * W
# 展平空间维度 [B, C, H*W]
f = x.view(B, C, -1)
# 计算注意力图
q = self.query(f).permute(0, 2, 1) # [B, N, C//8]
k = self.key(f) # [B, C//8, N]
v = self.value(f) # [B, C, N]
energy = torch.bmm(q, k) # [B, N, N]
attention = self.softmax(energy)
# 应用注意力
out = torch.bmm(v, attention.permute(0, 2, 1)) # [B, C, N]
out = out.view(B, C, H, W)
return self.gamma * out + x
class OrthogonalRegularization(nn.Module):
"""正交正则化 (BigGAN特有)"""
def __init__(self, beta=1e-4):
super().__init__()
self.beta = beta
def forward(self, weight):
# 权重形状: [out_channels, in_channels, H, W]
if weight.dim() > 2:
weight = weight.view(weight.size(0), -1)
# 计算 W^T W
wtw = torch.mm(weight.t(), weight)
# 移除对角元素 (只考虑非对角)
eye = torch.eye(wtw.size(0), device=wtw.device)
off_diag = wtw * (1 - eye)
# Frobenius范数平方
return self.beta * torch.norm(off_diag, p='fro')**2
# ========================
# 生成器架构 (ResNet风格)
# ========================
class GBlock(nn.Module):
"""生成器基础块"""
def __init__(self, in_channels, out_channels, num_classes, upsample=True):
super().__init__()
self.upsample = upsample
# 条件批量归一化 + ReLU
self.bn1 = ConditionalBatchNorm2d(in_channels, num_classes)
self.conv1 = spectral_norm(nn.Conv2d(in_channels, out_channels, 3, padding=1))
self.bn2 = ConditionalBatchNorm2d(out_channels, num_classes)
self.conv2 = spectral_norm(nn.Conv2d(out_channels, out_channels, 3, padding=1))
# 快捷连接
self.shortcut = nn.Sequential()
if in_channels != out_channels:
self.shortcut = spectral_norm(nn.Conv2d(in_channels, out_channels, 1))
# 正交正则化
self.ortho_reg1 = OrthogonalRegularization()
self.ortho_reg2 = OrthogonalRegularization()
def forward(self, x, y):
# 快捷连接
shortcut = x
if self.upsample:
shortcut = F.interpolate(shortcut, scale_factor=2)
shortcut = self.shortcut(shortcut)
# 主路径
x = self.bn1(x, y)
x = F.relu(x)
if self.upsample:
x = F.interpolate(x, scale_factor=2)
x = self.conv1(x)
self.ortho_reg1(self.conv1.weight)
x = self.bn2(x, y)
x = F.relu(x)
x = self.conv2(x)
self.ortho_reg2(self.conv2.weight)
return x + shortcut
class BigGenerator(nn.Module):
"""BigGAN生成器"""
def __init__(self, z_dim=120, num_classes=1000, channels=64, bottom_size=4):
super().__init__()
self.z_dim = z_dim
self.num_classes = num_classes
self.channels = channels
# 初始全连接层
self.fc = spectral_norm(nn.Linear(z_dim, 16 * channels * bottom_size**2))
self.bottom_size = bottom_size
# 残差块序列
self.blocks = nn.ModuleList([
GBlock(16*channels, 16*channels, num_classes), # 4x4 -> 8x8
GBlock(16*channels, 8*channels, num_classes), # 8x8 -> 16x16
GBlock(8*channels, 4*channels, num_classes), # 16x16 -> 32x32
GBlock(4*channels, 2*channels, num_classes), # 32x32 -> 64x64
GBlock(2*channels, channels, num_classes) # 64x64 -> 128x128
])
# 自注意力层 (在32x32分辨率)
self.attention = SelfAttention(4*channels)
# 输出层
self.final_bn = nn.BatchNorm2d(channels)
self.conv_out = spectral_norm(nn.Conv2d(channels, 3, 3, padding=1))
self.ortho_reg_out = OrthogonalRegularization()
def forward(self, z, y):
# 初始投影
x = self.fc(z)
x = x.view(-1, 16*self.channels, self.bottom_size, self.bottom_size)
# 通过残差块
for i, block in enumerate(self.blocks):
x = block(x, y)
if i == 2: # 在32x32分辨率应用注意力
x = self.attention(x)
# 输出层
x = self.final_bn(x)
x = F.relu(x)
x = self.conv_out(x)
self.ortho_reg_out(self.conv_out.weight)
return torch.tanh(x)
# ========================
# 判别器架构 (ResNet风格)
# ========================
class DBlock(nn.Module):
"""判别器基础块"""
def __init__(self, in_channels, out_channels, downsample=True):
super().__init__()
self.downsample = downsample
# 主路径
self.conv1 = spectral_norm(nn.Conv2d(in_channels, out_channels, 3, padding=1))
self.conv2 = spectral_norm(nn.Conv2d(out_channels, out_channels, 3, padding=1))
# 快捷连接
self.shortcut = nn.Sequential()
if downsample or in_channels != out_channels:
layers = []
if downsample:
layers.append(nn.AvgPool2d(2))
layers.append(spectral_norm(nn.Conv2d(in_channels, out_channels, 1)))
self.shortcut = nn.Sequential(*layers)
# 正交正则化
self.ortho_reg1 = OrthogonalRegularization()
self.ortho_reg2 = OrthogonalRegularization()
def forward(self, x):
# 快捷连接
shortcut = self.shortcut(x)
# 主路径
x = F.relu(x)
x = self.conv1(x)
self.ortho_reg1(self.conv1.weight)
x = F.relu(x)
x = self.conv2(x)
self.ortho_reg2(self.conv2.weight)
if self.downsample:
x = F.avg_pool2d(x, 2)
return x + shortcut
class BigDiscriminator(nn.Module):
"""BigGAN判别器"""
def __init__(self, num_classes=1000, channels=64):
super().__init__()
self.num_classes = num_classes
# 初始层
self.conv_in = spectral_norm(nn.Conv2d(3, channels, 3, padding=1))
# 残差块序列
self.blocks = nn.ModuleList([
DBlock(channels, 2*channels), # 128x128 -> 64x64
DBlock(2*channels, 4*channels), # 64x64 -> 32x32
DBlock(4*channels, 8*channels), # 32x32 -> 16x16
DBlock(8*channels, 16*channels), # 16x16 -> 8x8
DBlock(16*channels, 16*channels, downsample=False) # 8x8
])
# 自注意力层 (在32x32分辨率)
self.attention = SelfAttention(4*channels)
# 投影判别器
self.embed_y = spectral_norm(nn.Embedding(num_classes, 16*channels))
self.fc = spectral_norm(nn.Linear(16*channels, 1))
self.ortho_reg_fc = OrthogonalRegularization()
def forward(self, x, y=None):
# 初始卷积
x = self.conv_in(x)
# 通过残差块
for i, block in enumerate(self.blocks):
x = block(x)
if i == 1: # 在32x32分辨率应用注意力
x = self.attention(x)
# 全局平均池化
x = F.relu(x)
x = torch.sum(x, dim=[2, 3]) # 全局求和池化
# 投影判别器
if y is not None:
# 类别条件
embed_y = self.embed_y(y)
proj_y = torch.sum(embed_y * x, dim=1, keepdim=True)
out = self.fc(x) + proj_y
else:
out = self.fc(x)
self.ortho_reg_fc(self.fc.weight)
return out
# ========================
# 训练循环伪代码
# ========================
class BigGANTrainer:
def __init__(self, num_classes, z_dim=120, batch_size=2048, device='cuda'):
self.device = device
self.batch_size = batch_size
self.z_dim = z_dim
self.num_classes = num_classes
# 初始化模型
self.G = BigGenerator(z_dim, num_classes).to(device)
self.D = BigDiscriminator(num_classes).to(device)
# 优化器
self.opt_G = torch.optim.Adam(self.G.parameters(), lr=1e-4, betas=(0.0, 0.999))
self.opt_D = torch.optim.Adam(self.D.parameters(), lr=4e-4, betas=(0.0, 0.999))
# 截断参数
self.truncation = 1.0 # 初始不截断
self.psi = 0.7 # 截断阈值
# EMA生成器 (用于评估)
self.G_ema = BigGenerator(z_dim, num_classes).to(device)
self.G_ema.load_state_dict(self.G.state_dict())
def update_ema(self):
"""更新EMA生成器"""
with torch.no_grad():
for p_ema, p in zip(self.G_ema.parameters(), self.G.parameters()):
p_ema.copy_(0.9999 * p_ema + 0.0001 * p)
def train_step(self, real_images, real_labels):
"""单次训练迭代 (BigGAN使用同步BN)"""
# ===== 训练判别器 =====
self.opt_D.zero_grad()
# 真实图像
real_pred = self.D(real_images, real_labels)
loss_D_real = F.softplus(-real_pred).mean()
# 生成图像
z = self.sample_z(self.batch_size, truncation=self.truncation)
fake_images = self.G(z, real_labels).detach()
fake_pred = self.D(fake_images, real_labels)
loss_D_fake = F.softplus(fake_pred).mean()
# 梯度惩罚 (WGAN-GP)
gp = self.gradient_penalty(real_images, fake_images, real_labels)
# 正交正则化
ortho_loss = 0
for module in self.D.modules():
if hasattr(module, 'ortho_reg1'):
ortho_loss += module.ortho_reg1(module.conv1.weight)
if hasattr(module, 'ortho_reg2'):
ortho_loss += module.ortho_reg2(module.conv2.weight)
loss_D = loss_D_real + loss_D_fake + 10 * gp + 1e-4 * ortho_loss
loss_D.backward()
self.opt_D.step()
# ===== 训练生成器 =====
self.opt_G.zero_grad()
z = self.sample_z(self.batch_size, truncation=self.truncation)
fake_images = self.G(z, real_labels)
fake_pred = self.D(fake_images, real_labels)
loss_G = F.softplus(-fake_pred).mean()
# 生成器正交正则化
ortho_loss_G = 0
for module in self.G.modules():
if hasattr(module, 'ortho_reg1'):
ortho_loss_G += module.ortho_reg1(module.conv1.weight)
if hasattr(module, 'ortho_reg2'):
ortho_loss_G += module.ortho_reg2(module.conv2.weight)
loss_G += 1e-4 * ortho_loss_G
loss_G.backward()
self.opt_G.step()
# 更新EMA生成器
self.update_ema()
return loss_D.item(), loss_G.item()
def sample_z(self, batch_size, truncation=1.0):
"""采样潜在向量 (带截断)"""
z = torch.randn(batch_size, self.z_dim, device=self.device)
# 截断技巧
if truncation < 1.0:
while True:
mask = (z.abs() > truncation).any(dim=1)
if not mask.any():
break
z[mask] = torch.randn(mask.sum(), self.z_dim, device=self.device)
return z
def gradient_penalty(self, real, fake, labels):
"""WGAN-GP梯度惩罚"""
alpha = torch.rand(real.size(0), 1, 1, 1, device=self.device)
interpolated = (alpha * real + (1 - alpha) * fake).requires_grad_(True)
pred = self.D(interpolated, labels)
grad = torch.autograd.grad(
outputs=pred, inputs=interpolated,
grad_outputs=torch.ones_like(pred),
create_graph=True, create_graph=True
)[0]
grad_norm = grad.view(grad.size(0), -1).norm(2, dim=1)
return ((grad_norm - 1.0) ** 2).mean()
def train(self, dataloader, total_epochs=100):
"""训练主循环"""
for epoch in range(total_epochs):
for i, (real_images, real_labels) in enumerate(dataloader):
# 数据准备
real_images = real_images.to(self.device)
real_labels = real_labels.to(self.device)
# 动态批处理
if real_images.size(0) < self.batch_size:
continue
# 训练步骤
loss_D, loss_G = self.train_step(real_images, real_labels)
# 动态截断 (后期启用)
if epoch > total_epochs // 2:
self.truncation = self.psi
# 日志输出
if i % 100 == 0:
print(f"Epoch [{epoch+1}/{total_epochs}] | Batch [{i}] | "
f"Loss_D: {loss_D:.4f} | Loss_G: {loss_G:.4f} | "
f"Trunc: {self.truncation:.2f}")
def evaluate(self, num_samples=50000):
"""评估生成质量 (使用EMA生成器)"""
# 生成样本
all_fakes = []
for _ in range(0, num_samples, self.batch_size):
z = self.sample_z(self.batch_size, truncation=self.psi)
y = torch.randint(0, self.num_classes, (self.batch_size,), device=self.device)
with torch.no_grad():
samples = self.G_ema(z, y)
all_fakes.append(samples)
fake_images = torch.cat(all_fakes, dim=0)[:num_samples]
# 计算FID和IS (需预训练Inception网络)
fid_score = calculate_fid(real_stats, fake_images)
is_score = calculate_inception_score(fake_images)
return fid_score, is_score
# ========================
# 使用示例
# ========================
if __name__ == "__main__":
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 初始化训练器 (ImageNet 1000类)
trainer = BigGANTrainer(
num_classes=1000,
batch_size=256, # 实际BigGAN使用2048+
device=device
)
# 准备数据集
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
transform = transforms.Compose([
transforms.Resize(128),
transforms.CenterCrop(128),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
dataset = ImageFolder("path/to/imagenet", transform=transform)
dataloader = DataLoader(dataset, batch_size=256, shuffle=True, num_workers=8)
# 开始训练
trainer.train(dataloader, total_epochs=200)
# 评估最终模型
fid, is_score = trainer.evaluate()
print(f"Final FID: {fid:.2f}, IS: {is_score:.2f}")
# 保存模型
torch.save(trainer.G_ema.state_dict(), "biggan_generator.pth")
torch.save(trainer.D.state_dict(), "biggan_discriminator.pth")
GAN Inversion
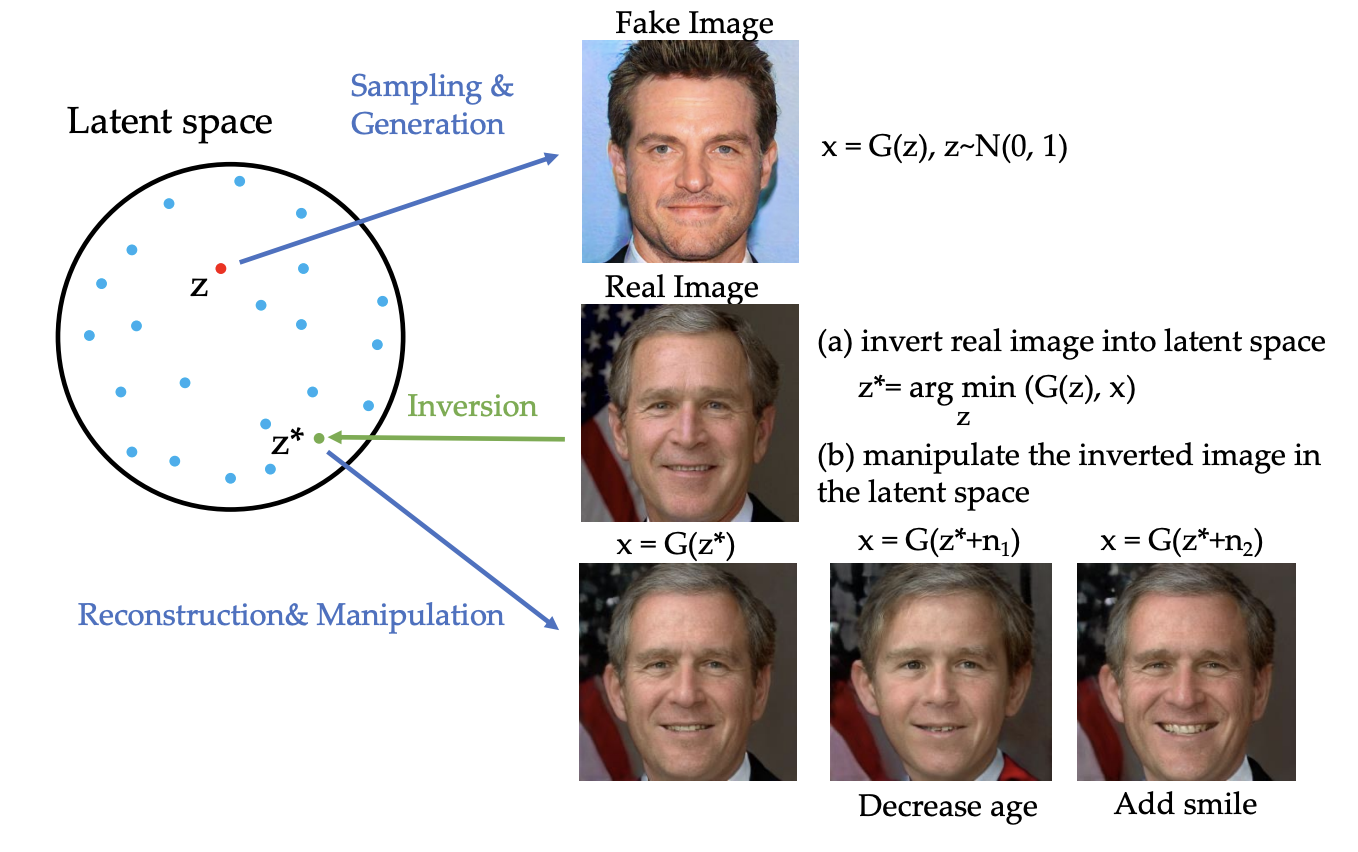
GAN Inversion(GAN逆向)是指将一个已生成的图像或真实图像映射回GAN的潜在空间(latent space),从而找到该图像的潜在向量(latent vector)。
步骤:
1.定义潜在空间和生成器:潜在空间一般是高维空间 Z Z Z,例如服从高斯分布的向量。生成器是一个从潜在空间到图像空间的映射函数 G : Z − > X G:Z->X G:Z−>X
2.目标:给定一个目标图像 x t a r g e t x_{target} xtarget,找到一个潜在向量 z z z,使得生成的图像 G ( z ) G(z) G(z)尽可能接近目标图像
因此目标函数为 z ∗ = a r g m i n z L ( G ( z ) , x t a r g e t ) z^* = argmin_zL(G(z), x_{target}) z∗=argminzL(G(z),xtarget)
常见的选择包括L2损失(均方误差)、L1损失和感知损失。
优化方法:
基于梯度下降的优化:通过梯度下降算法迭代更新潜在向量,即用损失函数的梯度来优化潜在向量。
基于神经网络的优化:使用一个编码器网络 E E E将图像映射到潜在空间 Z Z Z,即 z = E ( x ) z=E(x) z=E(x),训练过程中,同时优化生成器和编码器,使得 G ( E ( x ) ) G(E(x)) G(E(x))接近 x x x,即 m i n G , E = L ( G ( E ( x ) ) , x ) min_{G,E}=L(G(E(x)),x) minG,E=L(G(E(x)),x)
这样,在逆向过程中,只需通过编码器 E E E直接获得潜在向量 z z z
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torchvision.utils import save_image
# 假设G是预训练的生成器模型
G = ... # 预训练的生成器模型
target_image = ... # 目标图像,大小应与生成器输出一致
# 初始化潜在向量z
z = torch.randn(1, 100, requires_grad=True) # 假设潜在空间维度为100
# 定义优化器
optimizer = optim.Adam([z], lr=0.01)
# 损失函数
loss_fn = nn.MSELoss()
# 逆向优化过程
num_steps = 1000
for step in range(num_steps):
optimizer.zero_grad()
generated_image = G(z)
loss = loss_fn(generated_image, target_image)
loss.backward()
optimizer.step()
if step % 100 == 0:
print(f'Step {step}/{num_steps}, Loss: {loss.item()}')
# 保存生成的图像
save_image(generated_image, 'inverted_image.png')
GAN Inversion应用
图像编辑:通过逆向找到图像的潜在向量后,可以在潜在空间中进行编辑(如加减潜在向量),生成新的图像。
图像重建:将损坏或部分缺失的图像进行逆向,找到潜在向量后,通过生成器重建图像。
特征提取:GAN逆向可以用于提取图像的高层特征,用于其他任务如分类、检索等。
Pix2Pix
Image-to-Image Translation: 与自动语言翻译类似,将图像到图像自动翻译定义为:在给定足够的训练数据的情况下 ,将场景的一种可能表示转换为另一种场景的问题。
Pix2Pix是一种基于条件生成对抗网络(cGAN)的图像翻译模型,专门用于将一种图像风格转换为另一种图像风格。该模型通过成对的图像进行训练,其中每对图像分别代表同一场景的两种不同风格或表示。

cGAN 则在此基础上加入了条件信息,使得生成过程不仅依赖于噪声,还依赖于特定的条件输入,从而引导生成器生成符合条件的样本。
在 Pix2Pix 中,直接将一种风格的图像作为输入,生成与该图像配对的另一种风格的图像。
为了适应图像翻译任务的特点,Pix2pix 使用了 PatchGAN 判别器。与传统判别器不同,PatchGAN 关注的是图像的局部区域(通常是 70×70 的图像块),而非整个图像。这种设计有助于判别器关注图像的局部结构和纹理,从而更好地评估生成图像的质量,尤其是在风格迁移任务中。
Unet结构的生成器,判别器是PatchGAN,loss是L1 Loss+对抗Loss,使用L1 Loss捕获低频信息,但是可能会产生模糊的结果。因此引入patchGAN的对抗损失来学习细节纹理和高频信息。
为什么用Unet?
将高分辨率输入映射到高分辨率输出。 输入和输出的表面外观不同,但是两者都是相同结构。 因此,输入中的结构与输出中的结构大致对齐。对于许多图像翻译问题,在输入和输出之间共享大量的低层信息,跳跃连接使输入和输出共享突出边缘的位置。
Pixel2PixelHD
Pixel2PixelHD是Pixel2Pixel的扩展版本,专门用于高分辨率图像的翻译。它通过多尺度生成器和判别器的设计,增强了模型处理高分辨率图像的能力,使其能够生成更细腻和真实的图像。
Pixel2PixelHD及其衍生模型在艺术创作、医学图像处理、遥感图像分析、图像修复、图像超分辨率、智能驾驶等领域展现了巨大的潜力。例如,在医学图像处理中,Pix2pix 可以将低分辨率的扫描图像转化为高分辨率的清晰图像;在自动驾驶中,可以将白天的街景图像转换为夜晚的场景,帮助提高自动驾驶系统的鲁棒性。
StyleGAN
不再是简单地只在第一层接收噪声或隐变量 z z z,而是在生成器各层都注入,并且在 z z z送入生成器之前,先经过多层全连接尝试将其解耦。

StyleGAN的网络结构包含两个部分,第一个是Mapping network,由隐藏变量 z z z生成中间隐藏变量 w w w的过程,这个 w w w就是用来控制生成图像的style,即风格。 第二个是Synthesis network ,它的作用是生成图像,创新之处在于给每一层子网络都喂了A和B,A 是由 w w w转换得到的仿射变换,用于控制生成图像的风格,B是转换后的随机噪声,用于丰富生成图像的细节,即每个卷积层都能根据输入的A来调整 style 。整个网络结构还是保持了 PG-GAN(progressive growing GAN) 的结构。
在人脸中,Style是指人脸的风格,包括了脸型上面的表情、人脸朝向、发型等等,还包括纹理细节上的人脸肤色、人脸光照等方方面面。
Style mixing 的本意是去找到控制不同style的latent code的区域位置,具体做法是将两个不同的latent code z 1 z_1 z1 和 z 2 z_2 z2输入到 mappint network 中,分别得到 w 1 w_1 w1和 w 2 w_2 w2 ,分别代表两种不同的 style,然后在 synthesis network 中随机选一个中间位置,之前的部分使用 w 1 w_1 w1 ,交叉点之后的部分使用 w 2 w_2 w2,生成的图像应该同时具有source A 和source B 的特征,称为 style mixing,由此进行实验,可以大致推断低分辨率的style控制姿态、脸型、配件比如眼镜、发型等style(身份相关),高分辨率的style控制肤色、头发颜色、背景色等style。
StyleGAN2
| 改进维度 | StyleGAN | StyleGAN2 |
|---|---|---|
| 伪影问题 | 存在“水滴”伪影(droplet artifacts) | 通过权重解调消除伪影 |
| 归一化方式 | 使用 AdaIN | 移除 AdaIN,引入权重解调(Weight Demodulation) |
| 特征纠缠 | 潜在空间存在特征耦合 | 路径长度正则化改善解耦性 |
| 细节生成 | 头发/牙齿等高频细节可能模糊 | 改进网络架构,增强细节保真度 |
| 训练稳定性 | 需要精细调参 | 自适应训练策略,收敛更稳定 |
StyleGAN存在瑕疵,少量生成的图片有明显的水珠,这个水珠也存在于feature map上。
权重解调(Weight Demodulation)
导致水珠的原因是 Adain 操作,Adain对每个feature map进行归一化,因此有可能会破坏掉feature之间的信息,因此移除 AdaIN 层,改为在卷积权重上直接应用风格向量(Style Vector)的缩放因子,随后进行权重归一化。消除伪影,提升生成图像的视觉一致性。
路径长度正则化(Path Length Regularization)
StyleGAN 的潜在空间(latent space)存在特征纠缠 ,导致插值生成不自然。约束潜在向量变化与生成图像变化的雅可比矩阵范数,使潜空间插值更平滑,提升潜空间解耦性,使属性编辑更精准。
网络结构优化
StyleGAN 的跳跃连接(Skip Connection)导致细节模糊,StyleGAN2改用双倍上采样 + 单卷积层 ,保留高频细节。
输出层改进
移除 progressive growing 训练策略,改用残差模块统一处理多尺度特征。特征图分辨率通过上采样实现,避免渐进式训练引入的相位偏移问题。
延迟正则化(Lazy Regularization)
将正则化损失(如 R1 梯度惩罚)的计算频率降低,提升训练速度。例如每 16 个 mini-batch 计算一次正则化项,而非每次迭代计算。
自适应噪声输入
将噪声图(Noise Map)从固定位置输入改为 自适应缩放 ,增强细节多样性。
StyleGAN2-ADA
专注于在小数据集或有限数据场景下提升生成质量和训练稳定性。
自适应判别器增强(Adaptive Discriminator Augmentation, ADA)
动态数据增强
- 问题背景:传统GAN在数据不足时,判别器易过拟合,导致生成质量下降。
- 解决方案:
- 在判别器输入前应用 随机数据增强 (如平移、旋转、颜色抖动)。
- 动态调整增强强度:根据判别器的过拟合程度自动调节增强概率,过拟合严重时增强强度增加,反之降低。
- 数学实现:
- 通过监控判别器在验证集上的表现,动态调整增强概率 p p p。
- 目标是将判别器的准确率保持在约50%,避免其过于自信。
优势
- 小数据高效训练:在仅1000张图像的数据集上也能生成高质量结果,FID(Fréchet Inception Distance)显著优于传统方法7。
- 抗过拟合:通过增强噪声迫使判别器关注语义特征而非数据细节。
StyleGAN3
StyleGAN3实现了对图像的平移、旋转等几何变换的不变性,即使在亚像素尺度上也是如此。这使得生成的图像在进行几何变换后,依然能保持高质量和一致性。
网络结构优化:StyleGAN3对网络架构进行了多处优化,如用傅里叶特征替代StyleGAN2中的学习输入常数,删除每个像素的噪声输入,减小映射网络深度并禁用混合正则化和路径长度正则化,去掉输出跳过连接等
训练效率提升:StyleGAN3通过自定义CUDA内核合并上采样、Leaky ReLU、下采样等操作,实现了训练速度的显著提升和内存的节省。
- 边界和上采样改进:引入固定大小的边界来近似无限空间范围,并用理想低通滤波器代替双线性上采样,以提高平移不变性。
- 非线性滤波改进:将非线性滤波过程整合到自定义CUDA内核中,提高计算效率。
- 非临界采样改进:通过降低截止频率来抑制混叠现象,确保所有混叠频率都在阻带。
- 傅里叶特征改进:引入仿射层输出全局平移和旋转参数输入傅里叶特征,提升模型的全局变换能力。
- 灵活层设置:根据不同层的特性灵活设置采样率和截止频率等参数,以更好地消除伪影。
- 旋转等变性增强:将卷积核从3×3替换为1×1,并增加特征映射数量,同时采用径向对称的下采样滤波器,使网络获得旋转不变性。
在生成对抗网络(GAN)中,截断技巧(Truncation Trick)是一种用于在生成图像的保真度(Fidelity)和多样性(Variety)之间进行权衡的技术。其核心思想是通过对从先验分布(通常是标准正态分布或均匀分布)中采样的噪声向量进行截断,以控制生成图像的质量和多样性。
截断技巧通过对噪声向量进行截断,使得生成器更倾向于生成高质量的图像,但同时可能会牺牲一定的多样性。具体来说,截断技巧会设置一个阈值,将超出该阈值的噪声值重新采样,以确保所有噪声向量都落在一个特定的范围内。这个范围的大小决定了生成图像的保真度和多样性之间的平衡。
CycleGAN

Pix2Pix要求训练数据必须是成对的,而要找到两个域(画风)中成对出现的图片是相当困难的,但CycleGAN只需要两种域的数据,而不需要他们有严格对应关系,即可学习域之间的映射关系。
双生成器 + 双判别器结构
生成器 G:将域 X 的图像转换为域 Y(G: X → Y)
生成器 F:将域 Y 的图像转换为域 X(F: Y → X)
判别器 D X D_X DX:判断图像是否属于域 X(真/假)
判别器 D Y D_Y DY:判断图像是否属于域 Y(真/假)
循环一致性损失(Cycle-Consistency Loss)
核心思想:转换后的图像应能重建回原始图像(避免模式坍塌)。
数学表达:
正向循环:X → G(X) → F(G(X)) ≈ X
反向循环:Y → F(Y) → G(F(Y)) ≈ Y
损失函数:
L c y c l e = E X [ ∣ ∣ F ( G ( x ) ) − x ∣ ∣ 1 ] + E Y [ ∣ ∣ G ( F ( y ) ) − y ∣ ∣ 1 ] L_{cycle}=E_{X}[||F(G(x)) - x||_1] + E_Y[||G(F(y)) - y||_1] Lcycle=EX[∣∣F(G(x))−x∣∣1]+EY[∣∣G(F(y))−y∣∣1]
对抗损失
L a d v ( G , D Y ) = E Y [ l o g D Y ( y ) ] + E X [ l o g ( 1 − D Y ( G ( x ) ) ) ] L_{adv}(G, D_Y)=E_Y[logD_Y(y)] + E_X[log(1-D_Y(G(x)))] Ladv(G,DY)=EY[logDY(y)]+EX[log(1−DY(G(x)))]
L a d v ( F , D X ) = E X [ l o g D X ( x ) ] + E Y [ l o g ( 1 − D X ( F ( y ) ) ) ] L_{adv}(F, D_X)=E_X[logD_X(x)] + E_Y[log(1-D_X(F(y)))] Ladv(F,DX)=EX[logDX(x)]+EY[log(1−DX(F(y)))]
总损失
L t o t a k = L a d v ( G , D Y ) + L a d v ( F , D X ) + λ L c y c l e L_{totak} = L_{adv}(G, D_Y) + L_{adv}(F, D_X) + \lambda L_{cycle} Ltotak=Ladv(G,DY)+Ladv(F,DX)+λLcycle
控制循环一致性权重,通常设为10
循环一致性约束替代配对数据监督,强制生成器保留输入的关键特征(如物体形状),仅改变域相关属性(如纹理、颜色)。
身份损失(Identity Loss)(可选),添加 L i d e n t i t y = E Y [ ∣ ∣ G ( y ) − y ∣ ∣ 1 ] + E X [ ∣ ∣ F ( x ) − x ∣ ∣ 1 ] L_{identity} = E_Y[||G(y) - y||₁] + E_X[||F(x) - x||₁] Lidentity=EY[∣∣G(y)−y∣∣1]+EX[∣∣F(x)−x∣∣1]
作用:输入图像已属于目标域时,生成器应保持原图不变(常用于风格迁移)。
PatchGAN 判别器判别器对图像的局部子区域(Patch)进行真伪判断,提升细节生成质量。
训练步骤:
交替更新生成器与判别器:
步骤1:固定生成器,更新判别器 D X D_X DX和 D Y D_Y DY。
步骤2:固定判别器,更新生成器 G 和 F(包含对抗损失 + 循环损失)。
缓解模式坍塌:
使用历史生成图像池(Buffer of Generated Images)
判别器训练时随机从池中抽取旧生成样本,防止振荡。
优化器选择:
Adam 优化器( β 1 = 0.5 , β 2 = 0.999 \beta_1=0.5, \beta_2=0.999 β1=0.5,β2=0.999),学习率初始为 0.0002,后续线性衰减。
伪代码
# CycleGAN 核心伪代码
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 生成器架构
class Generator(nn.Module):
pass
# 2. 判别器架构(基于PatchGAN)
class Discriminator(nn.Module):
pass
# 3. 初始化模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 创建生成器和判别器
G_AB = Generator(input_nc=3, output_nc=3).to(device) # 从域A到域B
G_BA = Generator(input_nc=3, output_nc=3).to(device) # 从域B到域A
D_A = Discriminator(input_nc=3).to(device) # 判别域A
D_B = Discriminator(input_nc=3).to(device) # 判别域B
# 4. 损失函数
criterion_GAN = nn.MSELoss() # LSGAN损失
criterion_cycle = nn.L1Loss() # 循环一致性损失
criterion_identity = nn.L1Loss() # 身份损失(可选)
# 5. 优化器
optimizer_G = optim.Adam(
list(G_AB.parameters()) + list(G_BA.parameters()),
lr=0.0002, betas=(0.5, 0.999)
optimizer_D = optim.Adam(
list(D_A.parameters()) + list(D_B.parameters()),
lr=0.0002, betas=(0.5, 0.999))
# 6. 训练循环
for epoch in range(num_epochs):
for i, batch in enumerate(dataloader):
# 加载真实图像
real_A = batch["A"].to(device) # 域A图像
real_B = batch["B"].to(device) # 域B图像
# ----------------------
# 训练生成器 G_AB 和 G_BA
# ----------------------
optimizer_G.zero_grad()
# 对抗损失
fake_B = G_AB(real_A)
pred_fake_B = D_B(fake_B)
loss_GAN_AB = criterion_GAN(pred_fake_B, torch.ones_like(pred_fake_B))
fake_A = G_BA(real_B)
pred_fake_A = D_A(fake_A)
loss_GAN_BA = criterion_GAN(pred_fake_A, torch.ones_like(pred_fake_A))
# 循环一致性损失
recovered_A = G_BA(fake_B)
loss_cycle_A = criterion_cycle(recovered_A, real_A)
recovered_B = G_AB(fake_A)
loss_cycle_B = criterion_cycle(recovered_B, real_B)
# 身份损失(可选)
identity_A = G_BA(real_A)
loss_identity_A = criterion_identity(identity_A, real_A)
identity_B = G_AB(real_B)
loss_identity_B = criterion_identity(identity_B, real_B)
# 总生成器损失
lambda_cycle = 10 # 循环损失权重
lambda_identity = 0.5 # 身份损失权重
loss_G = (
loss_GAN_AB + loss_GAN_BA +
lambda_cycle * (loss_cycle_A + loss_cycle_B) +
lambda_identity * (loss_identity_A + loss_identity_B)
)
loss_G.backward()
optimizer_G.step()
# ----------------------
# 训练判别器 D_A
# ----------------------
optimizer_D.zero_grad()
# 真实图像损失
pred_real_A = D_A(real_A)
loss_D_real_A = criterion_GAN(pred_real_A, torch.ones_like(pred_real_A))
# 假图像损失(使用detach()阻止梯度传播到生成器)
pred_fake_A = D_A(fake_A.detach())
loss_D_fake_A = criterion_GAN(pred_fake_A, torch.zeros_like(pred_fake_A))
# 总判别器A损失
loss_D_A = 0.5 * (loss_D_real_A + loss_D_fake_A)
loss_D_A.backward()
# ----------------------
# 训练判别器 D_B
# ----------------------
# 真实图像损失
pred_real_B = D_B(real_B)
loss_D_real_B = criterion_GAN(pred_real_B, torch.ones_like(pred_real_B))
# 假图像损失
pred_fake_B = D_B(fake_B.detach())
loss_D_fake_B = criterion_GAN(pred_fake_B, torch.zeros_like(pred_fake_B))
# 总判别器B损失
loss_D_B = 0.5 * (loss_D_real_B + loss_D_fake_B)
loss_D_B.backward()
optimizer_D.step()
# 定期保存生成图像和模型检查点
if i % sample_interval == 0:
save_sample_images(real_A, fake_B, real_B, fake_A, epoch, i)
save_model_checkpoint(epoch, i)
Pixel2Style2Pixel
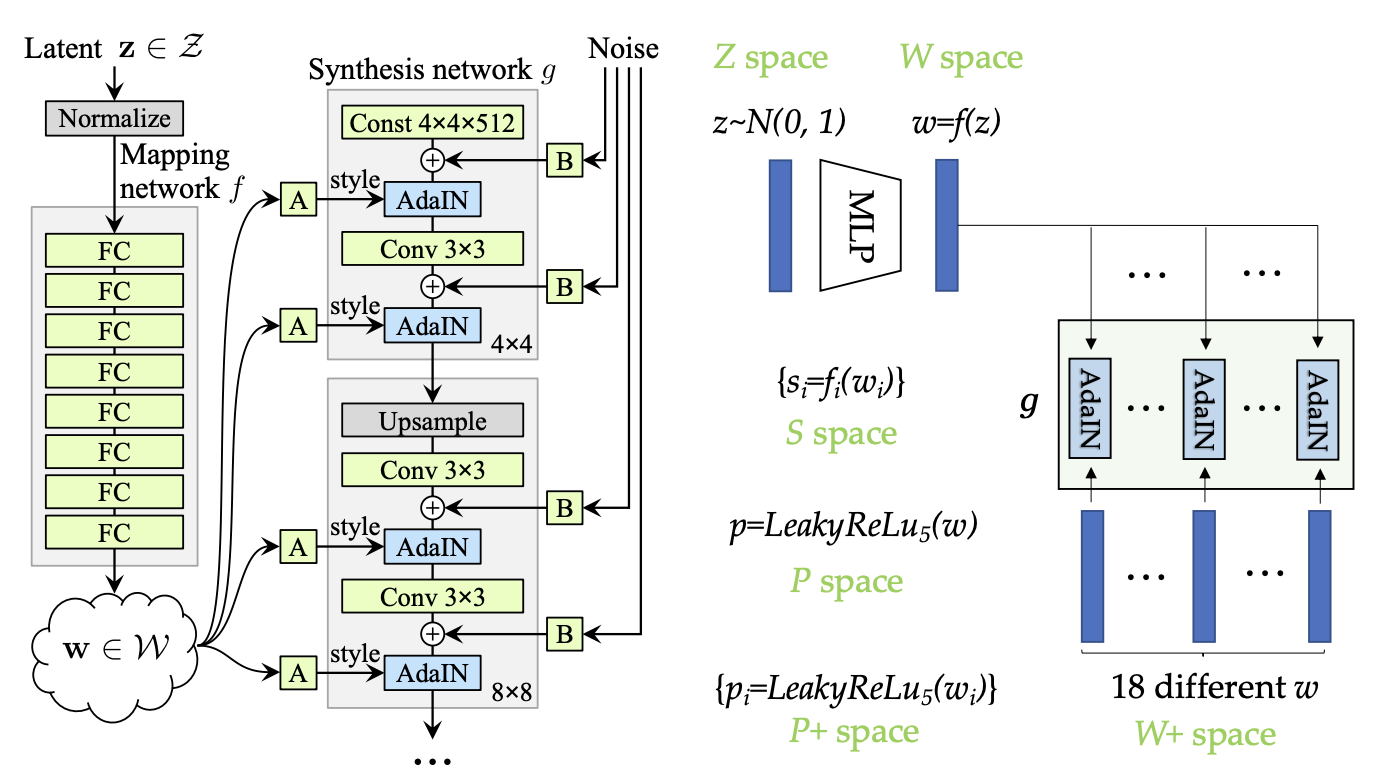
几种不同的空间:
Z Z Z空间:最原始的输入空间,一般是标准正态分布,即随机噪声
W W W空间:对于 Z Z Z进行一系列全连接层的变换,得到潜在空间,维度
[1, 512],通常认为会比 Z Z Z空间更好反映学习到的解纠缠性质。W + W^+ W+空间或者称之为 W ∗ W^* W∗空间,与 W W W空间的构造方法类似,但是生成器每一层被投喂的向量是不一样的,因此维度为
[1, 18, 512],通常用于风格混合和图像反演S S S空间,基于 W W W空间进行进一步的变换,对于生成器的每一层,均采用一个不同的仿射变换,Affine Transformers,进行一次线性变换,再接一个平移操作。将 W W W向量映射为风格参数。

将图像映射到StyleGAN 的latent code(隐向量编码),一种是训练一个encoder,输入图像,输出latent code,但这种方法泛化性不行,只对训练数据集有效;另一种是用训练好的encoder,比如styleGAN的encoder,随机初始化 latent code,将生成的图像与目标图像计算损失,用损失去更新 latent code,迭代几百上千次,这种方法虽然有效,但是耗时长。
之所以需要将图像映射到latent code,是因为发现对训练好的StyleGAN,如果用其他数据集进行finetune,经常会得到很惊喜的结果(比如风格化),因此我们希望能不能直接输入图像,然后用 finetune 后的 styleGAN 得到这个图像的生成结果呢。这时,pixel2style2pixel 就诞生了,第一个pixel是指输入图像,style是指latent code,第二个pixel是指输出图像,即将输入图像先转成latent code,再将这个latent code生成目标图像,这就是pixel2style2pixel 名字的由来,简称 pSp。
pSp encoder,输入是原图,输出是latent code,一共18层,对应StyleGAN2的网络结构,最后得到的 latent code 大小是 18x512。
map2style 结构是将特征图一步步变成512维的向量,pSp encoder的backbone是特征金字塔类型的,采用了resnet的skip结构,输出三个不同尺寸的feature map,然后这个三个feature map,每个feature map都生成多个latent code (这里指 1x1x512大小的latent code)。为什么要分成三个feature map(small, medium, largest),因为不同尺寸和不同深度的feature map包含的语义信息是不一样的,small feature 对应 styles的第0-2层,medium对应styles第3-6层,largest对应styles第7-18层,这个分类跟StyleGAN里的多尺寸也是一一对应的。每一层latent code再进行仿射变换,然后输送给 StyleGAN (StyleGAN是预训练好的),最后输出图像。
损失函数包括:Pixel-Level MSE+LPIPS感知损失(深度特征度量图像相似度,更符合人类视觉感受)+ ID Loss
应用:获取人脸隐向量编码,人脸转正,低分辨率图像到高分辨率图像,图像合成(分割图到人脸),人脸属性编辑等。
Encoder4Editing
是一种为StyleGAN图像编辑设计的编码器模型,旨在解决真实图像反转(Inversion)到StyleGAN潜在空间时的失真-可编辑性-感知质量权衡问题。其核心目标是通过高效编码,使反转后的潜在代码既能准确重建输入图像,又能支持灵活的语义编辑操作。

StyleGAN生成的图像质量高,但将真实图像反转(映射到潜在空间)时存在两难:
- 高保真重建:需潜在代码精确匹配图像细节,但可能导致潜在空间偏离可编辑区域。
- 高可编辑性:需潜在代码位于StyleGAN的语义敏感区域,但可能牺牲重建精度。
因此E4E希望达到:
- 在重建精度、编辑能力和视觉质量之间实现平衡。
- 支持多样化的编辑操作(如属性修改、风格迁移)且避免失真。
E4E通过分解潜在向量为内容(Content)和风格(Style)两部分:
- 内容编码:捕获图像的结构和全局特征,约束在StyleGAN的 W W W空间
[1, 512](主编辑空间)。 - 风格编码:编码局部细节和纹理,映射到 W + W^+ W+空间
[1, 18, 512](扩展潜在空间,支持细粒度控制)。
训练时采用多阶段策略:
- 第一阶段:通过重建损失(如LPIPS、L2)优化内容编码,确保潜在代码位于可编辑区域。
- 第二阶段:联合优化内容与风格编码,引入感知损失(如VGG特征匹配LPIPS)提升视觉质量
失真-可编辑性权衡控制
- 动态权重调节:在训练损失函数中动态调整重建误差与潜在空间正则化的权重,避免潜在代码过度偏离可编辑区域。
- 梯度引导:在反向传播时限制梯度方向,使优化过程更倾向于保持语义可编辑性。
E4E的编码器结构特点包括:
- 多尺度特征融合 :通过跳跃连接(Skip Connections)整合不同层级的特征,增强细节保留能力。
- 自适应归一化 :在编码过程中引入类似AdaIN的归一化层,适配StyleGAN的生成特性。
训练流程伪代码:
import torch
import torch.nn as nn
from e4e.models import E4E
from stylegan2.model import Generator
# 初始化模型
encoder = E4E().cuda()
generator = Generator(512, 512).cuda()
generator.load_state_dict(torch.load('stylegan2-ffhq.pth'))
# 定义损失函数
criterion_l1 = nn.L1Loss()
criterion_l2 = nn.MSELoss()
vgg = load_vgg().cuda() # 预加载 VGG
# 加载成对数据
dataset = PairedDataset("paired_dataset/")
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
# 优化器
optimizer = torch.optim.Adam(encoder.parameters(), lr=0.0001)
# 训练循环
for epoch in range(100):
for src, tgt in dataloader:
src, tgt = src.cuda(), tgt.cuda()
# 编码并生成图像
w_src = encoder(src)
recon = generator(w_src)
# 计算各损失项
loss_recon = criterion_l1(recon, tgt)
loss_latent = criterion_l2(w_src, encoder(tgt))
loss_perc = criterion_l2(vgg(recon), vgg(tgt))
loss_reg = criterion_l2(w_src, w_avg) # w_avg 需预计算
# 总损失
total_loss = 1.0 * loss_recon + 0.5 * loss_latent + 0.8 * loss_perc + 0.1 * loss_reg
# 反向传播
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
准备配对数据(源空间到目标空间),如(有胡子+无胡子,有刘海+无刘海等),或者也可以是自己学自己,寻找某种可编辑隐空间表示。
目标:让编码器学会将源空间(如带刘海)图像映射到潜在空间,并支持通过方向向量生成目标域图像(如去除刘海)。
损失函数
- 重建损失:LPIPS + L2,确保源空间图像编码后的潜在代码能重建目标域图像。 L r e s = E x s r c , x t g t [ ∣ ∣ G ( E ( x s r c ) ) − x t g t ∣ ∣ 1 ] L_{res}=E_{x_{src}, x_{tgt}}[||G(E(x_{src}))-x_{tgt}||_1] Lres=Exsrc,xtgt[∣∣G(E(xsrc))−xtgt∣∣1],其中, E E E是E4E的Encoder, x s r c x_{src} xsrc是源空间图像(带刘海输入图像), x t g t x_{tgt} xtgt是目标域图像(无刘海目标图像), G G G是预训练的StyleGAN生成器。
- 编辑损失(潜空间对齐损失):接约束输入图像和目标图像的潜在向量差异,强制模型学习两者之间的映射关系,通过最小化潜在代码的 L2 距离,建立带刘海到无刘海的直接关联。 L l a t e n t = E x s r c , x t g t [ ∣ ∣ E ( x s r c ) − E ( x t g t ) ∣ ∣ 2 2 ] L_{latent}=E_{x_{src}, x_{tgt}}[||E(x_{src})-E(x_{tgt})||_2^2] Llatent=Exsrc,xtgt[∣∣E(xsrc)−E(xtgt)∣∣22]
- 感知损失:提升生成图像的语义一致性(如保留身份特征),避免仅像素匹配导致的模糊。LPIPS损失。
- 正则化损失:保持潜在代码在StyleGAN的可编辑子空间内。防止潜在代码偏离 StyleGAN 的可编辑区域,避免生成失真或不可控结果。 L r e g = E x s r c [ ∣ ∣ E ( x s r c ) − w a v g ∣ ∣ 2 2 ] L_{reg} = E_{x_{src}}[||E(x_{src})-w_{avg}||_2^2] Lreg=Exsrc[∣∣E(xsrc)−wavg∣∣22],其中, w a v g w_{avg} wavg是StyleGAN 潜在空间的均值向量,约束潜在代码靠近 StyleGAN 的典型分布区域。
- 若仅需编辑局部区域(如刘海,胡子等),可添加掩码加权损失,关注局部区域
编辑流程示例
- 步骤1:将真实图像输入E4E,得到潜在代码 w w w。
- 步骤2:在 w w w上应用语义方向向量(如“微笑”、“年龄”),得到编辑后的 w + w^+ w+。
- 步骤3:通过StyleGAN生成器输出编辑后的图像。
应用:
- 图像修复与增强:通过编辑潜在代码修复老照片或调整光照条件。
- 虚拟试妆与人脸编辑:实时修改人脸属性(如口红颜色、发型,胡型等)。
- 艺术创作:结合StyleGAN的多样化风格生成,实现创意图像合成。
StyleMask
利用一个Mask Network从源图像与目标图像的latent差异中学习一个融合权重m,然后经过该权重融合源图像latent code和目标图像latent code,使之能够重建保持源图像

StyleCLIP
StyleCLIP做的主要事情并不是inversion,主要贡献是在latent code edit上面。
StyleCLIP主要是利用了Contrastive Language-Image Pre-training (CLIP)模型通过用户输入语言描述对latent code进行编辑,从而达到编辑图像的目的。
基于StyleGAN和CLIP的文本驱动图像编辑模型,其核心思想是通过自然语言描述(文本提示)控制生成对抗网络(GAN)生成的图像属性,实现高精度的语义化编辑。
三种latent code编辑的方法:
| 方法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 潜在优化(Latent Optimization) | 直接优化潜在代码,使其生成的图像与文本提示的 CLIP 相似度最大化 | 编辑精度高,支持复杂语义 | 计算成本高,单次编辑需数分钟 |
| 潜在映射(Latent Mapper) | 训练一个前馈网络,直接将文本提示映射到潜在空间偏移量( Δ w \Delta w Δw) | 实时编辑(毫秒级),适合批量处理 | 需要预训练映射网络,灵活性较低 |
| 全局方向(Global Directions) | 在潜在空间中预定义文本相关的全局编辑方向(如“性别”“年龄”),通过线性调整实现编辑 | 简单高效,无需优化或训练 | 仅支持简单属性,无法处理复杂描述 |
潜在优化方法(Latent Optimization)
import torch
import clip
from stylegan2 import Generator
# 加载模型
device = "cuda"
gan = Generator(1024, 512, 8).to(device)
clip_model, preprocess = clip.load("ViT-B/32", device=device)
# 文本编码
text = "a smiling person"
text_features = clip_model.encode_text(clip.tokenize(text).to(device))
# 初始化潜在代码
w = ... # 通过编码器获取原始图像的潜在代码
delta_w = torch.zeros_like(w, requires_grad=True)
optimizer = torch.optim.Adam([delta_w], lr=0.01)
# 优化循环
for _ in range(100):
edited_image = gan.synthesis(w + delta_w)
image_features = clip_model.encode_image(preprocess(edited_image))
loss = -torch.cosine_similarity(text_features, image_features).mean() + 0.1 * delta_w.norm()
loss.backward()
optimizer.step()
目标函数:
Δ w ∗ = a r g m i n Δ w [ D C L I P ( G ( w + Δ w ) , t e x t ) + λ ∣ ∣ Δ w ∣ ∣ 2 ] \Delta w^* = arg min_{\Delta w}[D_{CLIP}(G(w+\Delta w), text) + \lambda ||\Delta w||_2] Δw∗=argminΔw[DCLIP(G(w+Δw),text)+λ∣∣Δw∣∣2]
D C L I P D_{CLIP} DCLIPCLIP 图像-文本对的余弦相似度, λ \lambda λ正则化系数,防止潜在代码过度偏离原始分布
初始化潜在代码偏移量 Δ w \Delta w Δw为0,通过梯度下降优化 Δ w \Delta w Δw,最大化生成图像与文本的 CLIP 相似度,生成最终图像 G ( w + Δ w ) G(w + \Delta w) G(w+Δw)
潜在映射方法(Latent Mapper):通过设计一个text-guided mapper网络进行训练,训练好后就可以一次forward得到结果,适用于对大量图片进行特定属性的编辑操作。
输入:CLIP 文本编码 t C L I P t_{CLIP} tCLIP。
输出:潜在空间偏移量 Δ w \Delta w Δw。
训练目标:生成偏移量使编辑后的图像与文本对齐。
损失函数: L = D C L I P ( G ( w + Δ w ) , t e x t ) + λ ∣ ∣ Δ w ∣ ∣ 2 L=D_{CLIP}(G(w+\Delta w), text)+\lambda ||\Delta w||_2 L=DCLIP(G(w+Δw),text)+λ∣∣Δw∣∣2
全局方向方法(Global Directions)
方向提取 :
收集正负文本对(如男性-女性)。
计算潜在空间中对应样本的平均差异向量 Δ w d i r \Delta w_{dir} Δwdir,并进行归一化。
进行编辑 w e d i t = w + α Δ w d i r w_{edit}=w+\alpha\Delta w_{dir} wedit=w+αΔwdir, α \alpha α编辑强度系数。
图像编辑流程
输入准备 :
- 原始图像 I s r c I_{src} Isrc,通过 E4E 或 pSp 编码器获取潜在代码 w w w。
- 文本提示 T T T(如金发、戴眼镜)。
编辑方法选择 :
- 简单属性(如性别)→ 全局方向 。
- 复杂描述(如“科幻风格”)→ 潜在优化 或 潜在映射 。
应用:
- 人脸属性编辑:调整年龄、表情、发型。
- 艺术风格迁移:将图像转换为“梵高风格”或“卡通化”。
- 场景合成:根据“雪山脚下的木屋”生成符合描述的风景图。
| 优点 | 缺点 |
|---|---|
| 无需标注数据,仅依赖文本提示 | 对复杂语义理解有限(如抽象描述) |
| 支持非刚性编辑(如表情、姿态) | 多属性编辑可能冲突(如“年轻”与“皱纹”) |
| 与预训练GAN兼容(StyleGAN2/3) | 计算成本高(尤其潜在优化方法) |

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)