井字游戏的强化学习二
如果我们让s表示贪婪移动之前的状态,s0表示移动之后的状态,那么对s的估计值的更新,表示为V(s),可以写成。例如,如果步长参数随着时间的推移适当减小,那么对于任何固定的对手,该方法都会收敛到我们的玩家在给定最佳游戏的每个状态下获胜的真实概率。换句话说,该方法收敛于玩游戏的最优策略。为了选择我们的动作,我们检查了每一个可能的动作(板上每个空格一个)会产生的状态,并在表中查找它们的当前值。我们的第二
一、动作的分析
假设我们总是玩X,那么对于所有连续有三个X的状态,获胜的概率是1,因为我们已经赢了。类似地,对于所有连续有三个O的状态,或者被“填满”的状态,正确的概率是0,因为我们无法从中获胜。我们将所有其他状态的初始值设置为0.5,表示我们有50%的机会获胜。
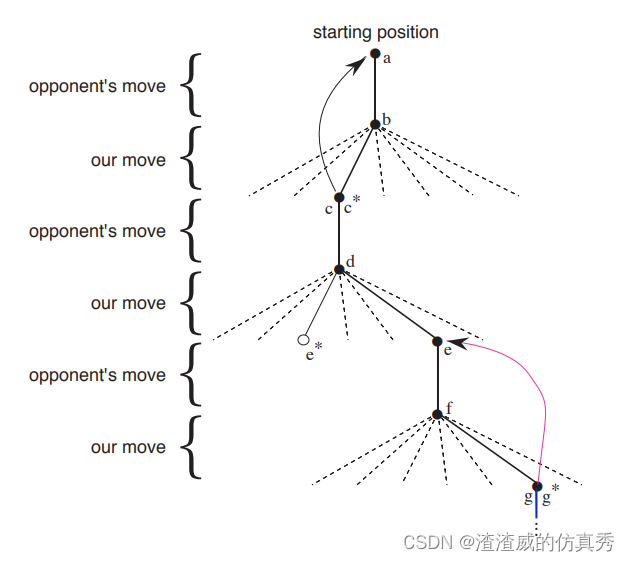
我们和对手打了很多场比赛。为了选择我们的动作,我们检查了每一个可能的动作(板上每个空格一个)会产生的状态,并在表中查找它们的当前值。大多数时候,我们贪婪地移动,选择导致价值最大的状态的移动,即估计获胜概率最高的移动。然而,偶尔我们会从其他动作中随机选择。这些被称为探索性动作,因为它们会让我们体验到我们可能永远看不到的状态。游戏过程中所做和考虑的一系列动作可以如图所示。
这个图表示一连串的井字动作。实线表示在游戏中所采取的动作;虚线表示我们(我们的强化学习玩家)考虑过但没有做出的动作。我们的第二个举动是一个探索性的举动,这意味着即使另一个字举动,即导致e*的举动,排名更高,我们还是采取了这一举动。探索性动作不会带来任何学习,但我们的每一个其他动作都会带来学习,如弯曲箭头所示,后面将详细说明
二、价值的分析
当我们在比赛时,我们会改变我们在比赛中所处状态的价值。我们试图让他们更准确地估计获胜的可能性。为此,我们将每次贪婪移动后的状态值“备份”到移动前的状态,如上图中的箭头所示。更准确地说,较早状态的当前值被调整为更接近较晚状态的值。这可以通过将早期状态的值向后期状态的值移动一小部分来实现。如果我们让s表示贪婪移动之前的状态,s0表示移动之后的状态,那么对s的估计值的更新,表示为V(s),可以写成
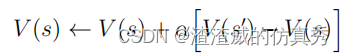
其中,α是一个称为步长的参数,可以理解为学习率。这个更新规则是时间差学习方法的一个例子,之所以这么叫,是因为它的变化是基于两个不同时间的价值估计之间的差异。
上面描述的方法在这个任务上表现得相当好。例如,如果步长参数随着时间的推移适当减小,那么对于任何固定的对手,该方法都会收敛到我们的玩家在给定最佳游戏的每个状态下获胜的真实概率。此外,然后采取的动作(探索性动作除外)实际上是对抗对手的最佳动作。换句话说,该方法收敛于玩游戏的最优策略。如果步长参数没有随着时间的推移一直减少到零,那么这个玩家在对抗慢慢改变打法的对手时也会打得很好。
这个例子说明了进化方法和学习价值函数的方法之间的差异。评估政策是一种进化方法固定策略并与对手进行多次游戏,或者使用对手的模型模拟多次游戏。获胜频率给出了该策略获胜概率的无偏估计,并可用于指导下一个策略选择。但每一次政策变化都是在多次比赛后才做出的,并且只使用每一场比赛的最终结果:比赛期间发生的事情被忽略。例如,如果玩家获胜,那么它在游戏中的所有行为都会得到赞扬,而与特定动作对获胜的关键程度无关。甚至从未发生过的举动也值得称赞!相反,值函数方法允许对单个状态进行评估。最后,进化和价值函数方法都在搜索政策的空间,但学习价值函数会利用游戏过程中可用的信息。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)