orc和parquet数据存储格式
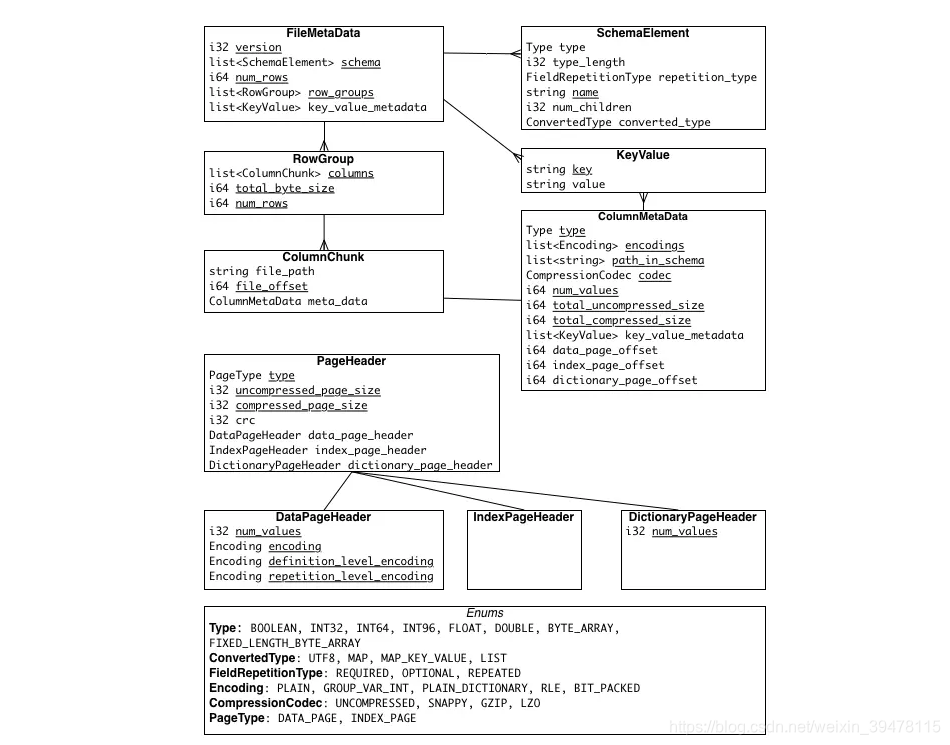
Parquet行组(Row Group):按照行将数据物理上划分为多个单元,每一个行组包含一定的行数。一个行组包含这个行组对应的区间内的所有列的列块官方建议更大的行组意味着更大的列块,使得能够做更大的序列IO。我们建议设置更大的行组(512MB-1GB)。因为一次可能需要读取整个行组,所以我们想让一个行组刚好在一个HDFS块中。因此,HDFS块的大小也需要被设得更大。一个最优的读设置是:1GB的行
Parquet
-
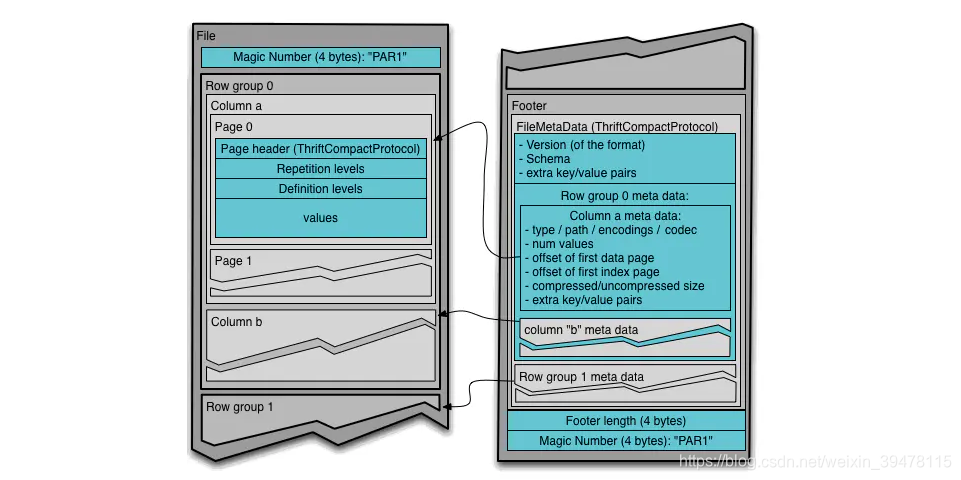
行组(Row Group):按照行将数据物理上划分为多个单元,每一个行组包含一定的行数。一个行组包含这个行组对应的区间内的所有列的列块
官方建议
更大的行组意味着更大的列块,使得能够做更大的序列IO。我们建议设置更大的行组(512MB-1GB)。因为一次可能需要读取整个行组,所以我们想让一个行组刚好在一个HDFS块中。因此,HDFS块的大小也需要被设得更大。一个最优的读设置是:1GB的行组,1GB的HDFS块,1个HDFS块放一个HDFS文件。 -
列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。不同的列块可能使用不同的算法进行压缩。一个列块由多个页组成
-
页(Page):每一个列块划分为多个页,页是压缩和编码的单元,对数据模型来说页是透明的。在同一个列块的不同页可能使用不同的编码方式。官方建议一个页为8KB。
文件结构
-
一个文件中可以存储多个行组
-
文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件
-
Footer length存储了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量
-
文件的元数据中包括每一个行组的元数据信息和当前文件的Schema信息
parquet. compression:默认值为 UNCOMPRESSED,表示页的压缩方式,可以使用的压缩方式有 UNCOMPRESSED、 SNAPPY、GZIP和LZO。
谓词下推
在数据库之类的查询系统中最常用的优化手段就是谓词下推了,通过将一些过滤条件尽可能的在最底层执行可以减少每一层交互的数据量,从而提升性能,例如”select count(1) from A Join B on A.id = B.id where A.a > 10 and B.b < 100″SQL查询中,在处理Join操作之前需要首先对A和B执行TableScan操作,然后再进行Join,再执行过滤,最后计算聚合函数返回,但是如果把过滤条件A.a > 10和B.b < 100分别移到A表的TableScan和B表的TableScan的时候执行,可以大大降低Join操作的输入数据。
映射下推
-
避免扫描整个表文件内容
-
降低随机读的次数
-
如果某些需要的列是存储位置是连续的,那么一次读操作就可以把多个列的数据读取到内存
详细解释:
说到列式存储的优势,映射下推是最突出的,它意味着在获取表中原始数据时只需要扫描查询中需要的列,由于每一列的所有值都是连续存储的,所以分区取出每一列的所有值就可以实现TableScan算子,而避免扫描整个表文件内容。
在Parquet中原生就支持映射下推,执行查询的时候可以通过Configuration传递需要读取的列的信息,这些列必须是Schema的子集,映射每次会扫描一个Row Group的数据,然后一次性得将该Row Group里所有需要的列的Cloumn Chunk都读取到内存中,每次读取一个Row Group的数据能够大大降低随机读的次数,除此之外,Parquet在读取的时候会考虑列是否连续,如果某些需要的列是存储位置是连续的,那么一次读操作就可以把多个列的数据读取到内存。
ORC
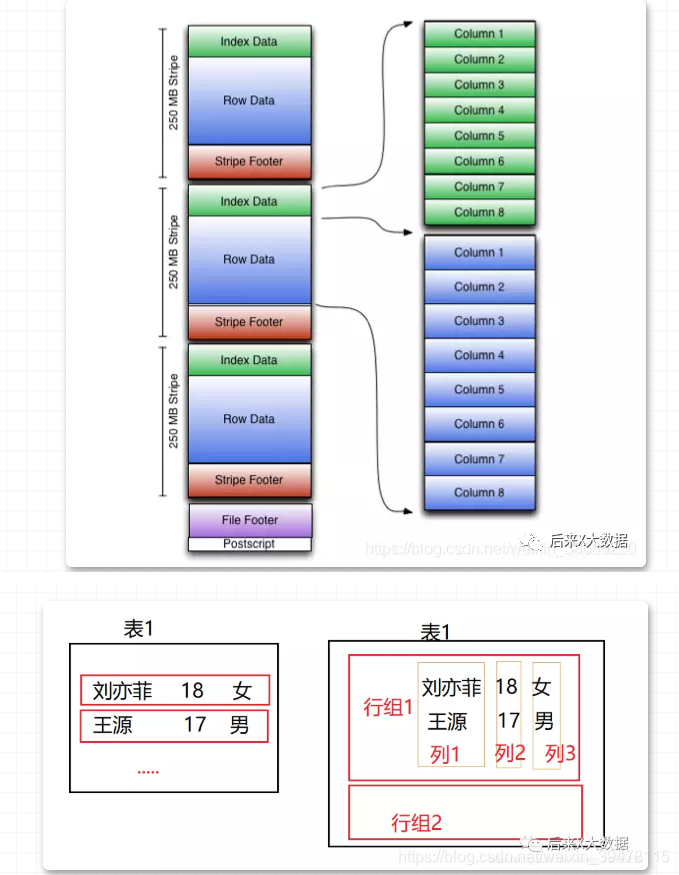
左边的图就表示了传统的行式数据库存储方式,按行存储,如果没有存储索引的话,如果需要查询一个字段,就需要把整行的数据都查出来然后做筛选,这么做是比较消耗IO资源的,于是在Hive中最开始也是用了索引的方式来解决这个问题。
但是由于索引的高成本,在**「目前的Hive3.X 中,已经废除了索引」**,当然也早就引入了列式存储。
列式存储的存储方式,是按照一列一列存储的,如上图中的右图,这样的话如果查询一个字段的数据,就等于是索引查询,效率高。但是如果需要查全表,它因为需要分别取所有的列最后汇总,反而更占用资源。于是ORC行列式存储出现了。
- 在需要全表扫描时,可以按照行组读取
- 如果需要取列数据,在行组的基础上,读取指定的列,而不需要所有行组内所有行的数据和一行内所有字段的数据。
存储模型
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RoJER9IM-1608193053572)(C:\Users\weiyunhao\AppData\Roaming\Typora\typora-user-images\image-20201119182443484.png)]](https://i-blog.csdnimg.cn/blog_migrate/8fb1d2034fde4eea731a8fb02c3bfa44.png)
- 条带( stripe):ORC文件存储数据的地方,每个stripe一般为HDFS的块大小。(包含以下3部分)
- index data:保存了所在条带的一些统计信息,以及数据在 stripe中的位置索引信息
- rows data:数据存储的地方,由多个行组构成,每10000行构成一个行组,数据以流(stream)的形式进行存储
- stripe footer:保存数据所在的文件目录
- 文件脚注( file footer):包含了文件中stripe的列表,每个 stripe的行数,以及每个列的数据类型。它还包含每个列的最小值、最大值、行计数、求和等聚合信息
- postscript:含有压缩参数和压缩大小相关的信息
所以其实发现,ORC提供了3级索引,文件级、条带级、行组级,所以在查询的时候,利用这些索引可以规避大部分不满足查询条件的文件和数据块。
但注意,ORC中所有数据的描述信息都是和存储的数据放在一起的,并没有借助外部的数据库。
「特别注意:ORC格式的表还支持事务ACID,但是支持事务的表必须为分桶表,所以适用于更新大批量的数据,不建议用事务频繁的更新小批量的数据,orc不指定压缩方式,默认使用zlib进行压缩」
总结
相同点:
- 均为列式存储,均有行组、列块的概念
- 基本数据类型均支持
- 谓词下推(ORC支持Bloom Filter,它可以进一步提升谓词下推的效率)、映射下推均支持
- 压缩均支持
不同点
-
orc存储压缩率比parquet要高
-
hive、presto在读取orc数据时效率高,spark、impala读取parquet数据时效率高
-
orc支持格式的表还支持事务ACID,但是支持事务的表必须为分桶表,所以适用于更新大批量的数据,不建议用事务频繁的更新小批量的数据,parquet则不行
-
向量化读取,hive支持orc存储格式,spark支持parquet存储格式
生产实践经验:由于列式存储能指定对应的列和列对应的数据,因此能够实现字段的动态感知。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)