问答系统的实现方法
信息检索,问答系统,机器阅读理解。
引言
这是Speech and Language Processing的笔记。
信息检索
信息检索(Information retrieval,IR)系统通常也称为搜索引擎。
我们考虑的IR任务被称为ad hoc检索,常见的场景为用户提交一个查询到检索系统,然后系统从某个文档集合中返回一个排序的(小的)文档集合。
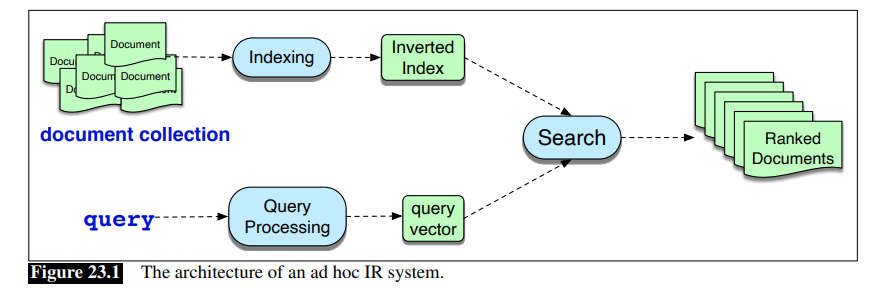
基本的IR架构使用向量空间模型,在其中我们映射查询和文档到向量,基于unigram单词计数,然后利用余弦相似度计算查询向量和文档向量之间的相似度,从而进行排名。
单词权重和文档打分
我们为每个文档中的单词计算单词权重(term weight),常用的是 tf-idf \text{tf-idf} tf-idf和它的变体BM25。
词频(term frequence) 反映了单词的频率,单词在某篇文章中出现的越多,越可能由它反映文章的内容。通常会对词频取对数,因为某个单词出现了100次,并不见得它对文章的贡献有100倍那么重要。因为 log 0 \log 0 log0是无意义的,因此我们加了一个 1 1 1:
t f t , d = log ( count ( t , d ) + 1 ) tf_{t,d} = \log(\text{count}(t,d) + 1) tft,d=log(count(t,d)+1)
文档频率(document frequence) df t \text{df}_t dft反映了出现单词 t t t的文档的数量。基于常理,我们知道只在一小部分文档中出现的单词通常更助于这些文档的区分度。而在整个集合中的文档都出现的单词通常是没什么帮助的,比如“的”、“呢”这些词。
逆文档频率(inverse document frequency) 单词权重被定义为:
idf t = log N df t \text{idf}_t = \log \frac{N}{\text{df}_t} idft=logdftN
其中 N N N是集合中文档的总数; df t \text{df}_t dft是单词 t t t出现的文档数量;
从公式可以看出,某个单词出现的文档数量越小,它的权重就越大;如果它在所有文档中都出现,那么 tf t = N → log 1 = 0 \text{tf}_t = N \rightarrow \log 1 =0 tft=N→log1=0,表示权重最低。
tf-idf \text{tf-idf} tf-idf表示单词 t t t在文档 d d d中的权重:
tf-idf ( t , d ) = tf t , d ⋅ idf t \text{tf-idf}(t,d) = \text{tf}_{t,d} \cdot \text{idf}_t tf-idf(t,d)=tft,d⋅idft
BM25
一个 tf-idf \text{tf-idf} tf-idf的变体是BM25,它增加了两个参数: k k k和 b b b。其中 k k k用来平衡 t f tf tf和 i d f idf idf; b b b控制文档长度的重要性。给定 q q q计算文档 d d d的BM25得分公式如下:
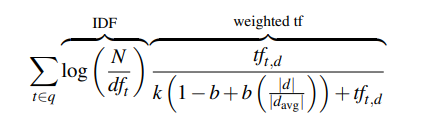
其中 ∣ d ∣ |d| ∣d∣是文档 d d d长度; ∣ d a v g ∣ |d_{avg}| ∣davg∣是文档集合中平均文档长度。
假设 b = 0 b=0 b=0,那么加权的 tf \text{tf} tf就是 t f t f + k \frac{tf}{tf + k} tf+ktf,其中 k k k是用来控制 t f tf tf的增速的,假设某篇文章单词 a a a出现200次,它能带来的相关性是出现100次的两倍吗?
假设 a a a出现了100次,那么该篇文章肯定是与 a a a有关的,如果再出现更多的次数带来权重也不应该增加这种相关性了。使用 t f t f + k \frac{tf}{tf+k} tf+ktf就能避免它的无限增大,相当于达到某个阈值就饱和了。
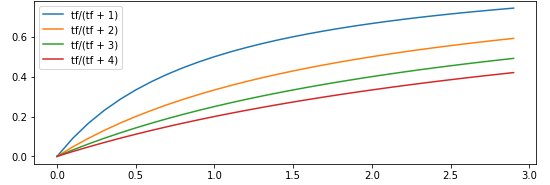
上图是不同的 k k k值得到的曲线, k k k越大,曲线越缓和。当 k = 0 k=0 k=0时,BM25就没有计算 tf \text{tf} tf,只是使用了 idf \text{idf} idf。
引入 b b b的目的是考虑文档长度,如果某篇文章很短,出现了某个单词1次,和某篇文章特别长,但是也只出现了2次。我们就像让文章的长度来控制 k k k的取值,如果文章很长,那么 k k k就取大一点,得到的 t f t f + k \frac{tf}{tf+k} tf+ktf就小一点;反之文章很短,那么 k k k就设小一点。如何才能知道文章是短是长呢?这里的做法就是用它的长度和平均长度作比较,如果大于平均,那么就是相对较长。
而引入 b b b就是为了控制文章长度的重要性, b b b的取值范围是 [ 0 , 1 ] [0,1] [0,1]。若 b = 0 b=0 b=0,那么完全不考虑文章长度;若 b = 1 b=1 b=1,如果文章较长,那么就增大 k k k;如果文章较短,那么就减少 k k k。下图是 b = 0.2 b=0.2 b=0.2和 b = 0.8 b=0.8 b=0.8相关的图形:
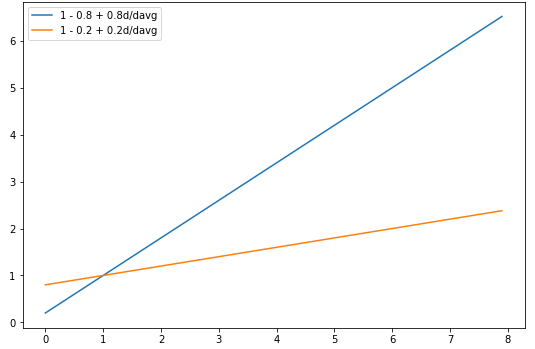
从中可以看出, b b b越大,对文章长度的惩罚也越大。
常用的取值 k = [ 1.2 , 2 ] , b = 0.75 k=[1.2,2],b=0.75 k=[1.2,2],b=0.75。
关于 idf \text{idf} idf也有一种变体叫作概率IDF(probabilistic IDF),它的公式为
log N − d f t + 0.5 d f t + 0.5 \log \frac{N-df_t + 0.5}{df_t + 0.5} logdft+0.5N−dft+0.5
这样得到的 idf \text{idf} idf对出现在较多文档中的单词来说是急剧下降的,但是它可能得到负值,Lucene的实现是在最后加 1 1 1,防止出现负值:
log ( N − d f t + 0.5 d f t + 0.5 + 1 ) \log(\frac{N-df_t + 0.5}{df_t + 0.5} + 1) log(dft+0.5N−dft+0.5+1)
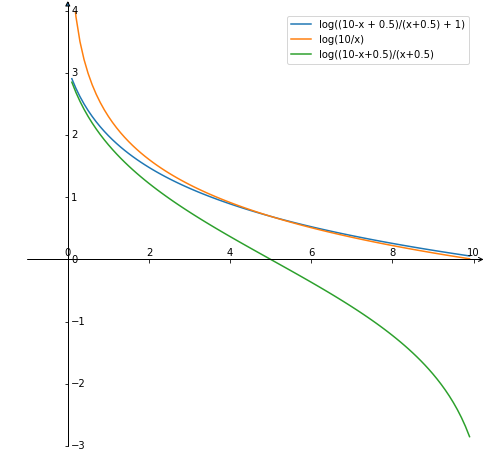
假设 N = 10 N=10 N=10, x x x代表 idf \text{idf} idf的取值,上图是原始的 idf = log ( 10 / x ) \text{idf}=\log(10/x) idf=log(10/x)与它两种变体的图形。可以看到,Lucene的实现的图形和传统的图形类似。
文档打分
我们通过查询向量 q q q与文档向量 d d d之间的余弦相似度为文档打分:
score ( q , d ) = cos ( q , d ) = q ⋅ d ∣ q ∣ ∣ d ∣ \text{score}(q,d) = \cos(q,d) = \frac{q \cdot d}{|q| |d|} score(q,d)=cos(q,d)=∣q∣∣d∣q⋅d
可以看成是单位向量的点积,即首先将每个向量除以它们的模标准化为单位向量,然后计算标准化之后的点积:
score ( q , d ) = cos ( q , d ) = q ∣ q ∣ ⋅ d ∣ d ∣ \text{score}(q,d) = \cos(q,d) = \frac{q}{|q|} \cdot \frac{d}{|d|} score(q,d)=cos(q,d)=∣q∣q⋅∣d∣d
倒排索引
为了打分,我们需要高效的找到包含查询 q q q中单词的文档集合。
通常解决这个问题的方法是使用倒排索引(inverted index)。
在倒排索引中,给定一个查询词,可以很快找到包含该查询词的文档列表。
倒排索引包含两部分,一个字典和ID列表。字典中包含了所有的单词,每个单词指向一个出现该单词的文档ID列表。其中还可以词频或甚至是单词在文档中出现的位置信息。

比如上面就是一个简单的倒排索引,基于下面这4个简单的文档集合实现。其中包含了单词的总数,以及每个文档中该单词出现的次数。这样可以很方便地计算 tf-idf \text{tf-idf} tf-idf。

评估IR系统
我们评估排序的IR系统表现通过精确率(precision)和召回率(recall)指标。
精确率表示返回的文档中属于相关文档的比例;
召回率表示返回相关的文档占总相关文档数的比例;
P r e c i s i o n = ∣ R ∣ ∣ T ∣ R e c a l l = ∣ R ∣ ∣ U ∣ Precision=\frac{|R|}{|T|} \quad Recall = \frac{|R|}{|U|} Precision=∣T∣∣R∣Recall=∣U∣∣R∣
T T T是返回的文档数;
R R R是返回的文档中相关文档的数量;
N N N是返回的文档中不相关文档的数量;
U U U是所有文档中相关文档的数据;
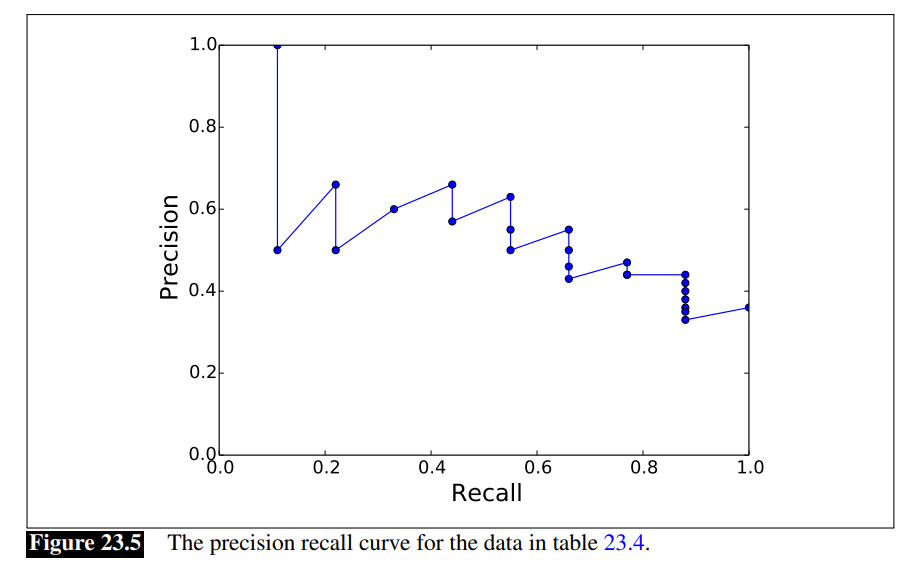
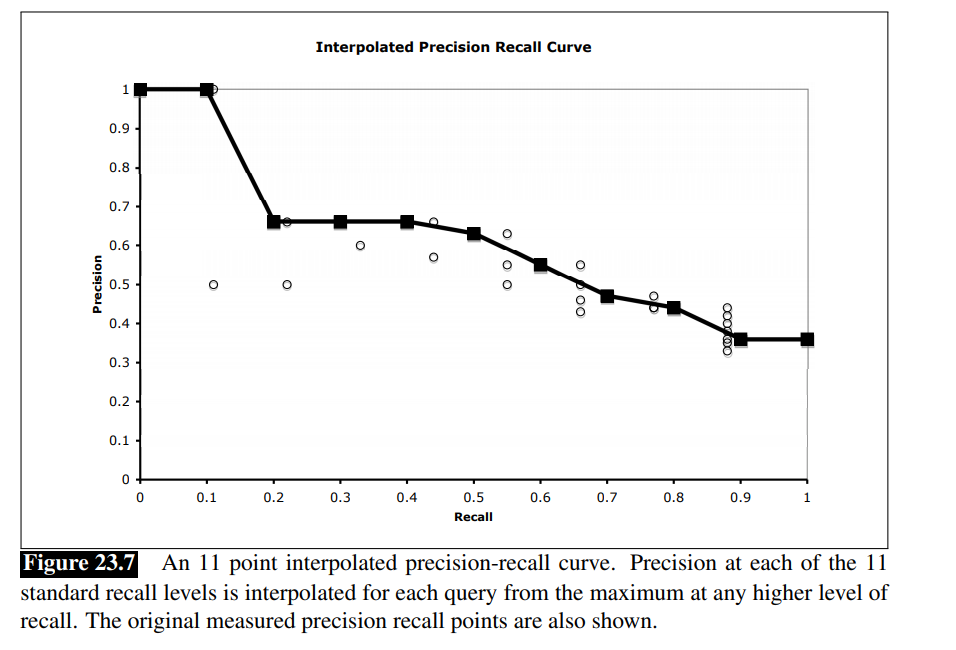
我们可以通过让系统返回更多的文档来提高召回率,因此召回值是非递减的,而精度值当遇到相关的时增加,反之减少。上图显示的是针对单个查询的结果。但是我们需要结合所有查询的结果,这样可以让我们比较不同系统的好坏。其中一种方式是画平均精度值,以固定的召回级别(0到100,步长为10;或者是0.0,0.1,…,1.0)。由于我们不太可能有这些精确级别的数据点,我们使用插值精度值(interpolated precision)。
我们可以通过选择在我们计算的任何召回级别上得到的最大精度值来实现这一点,公式为,
IntPrecision ( r ) = max i ≥ r Precision ( i ) \text{IntPrecision}(r) = \max _{i \geq r} \text{Precision}(i) IntPrecision(r)=i≥rmaxPrecision(i)
其中 r r r为对应的召回级别。
然后求每个级别对应精确率的平均值系统的得分。
使用稠密向量的IR
用户可能通过不同的描述方式来描述一个问题 q q q,可能导致 q q q描述的词汇和类似问题的词汇完全不一样,这叫作词汇不匹配问题(vocabulary mismatch problem)。
解决方案是使用一种能处理相似词汇的方法。现代方法都是使用了像BERT的编码器。在有时被称为biencoder的编码其中,我们使用两个独立的编码模型,一个用来编码查询,另一个用于编码文档,分别得到一个向量,然后用这两个向量进行点积运算来计算得分。
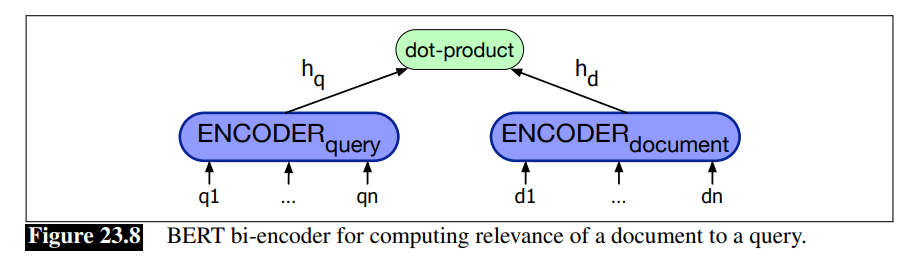
举例来说,如果我们使用BERT,我们就会有两个编码 BERT Q \text{BERT}_Q BERTQ和 BERT D \text{BERT}_D BERTD,
h q = BERT Q ( q ) [ C L S ] h d = BERT D ( d ) [ C L S ] score ( d , q ) = h q ⋅ h d h_q = \text{BERT}_Q(q)[CLS]\\ h_d = \text{BERT}_D(d)[CLS]\\ \text{score}(d,q) = h_q \cdot h_d hq=BERTQ(q)[CLS]hd=BERTD(d)[CLS]score(d,q)=hq⋅hd
使用稠密向量在QA中仍然是研究的开放领域。很多活跃研究在如何在IR任务上进行编码器模块的fine-tuning,如何处理文档长度通常远长于像BERT这种编码器能处理的长度(通常的做法是将文档分词段落)。
效率也是一个问题,IR引擎的核心根据相似度对文档进行排序。现代系统一般都是用FAISS算法。
基于IR的事实类问答
基于IR的问答(有时称为开放领域问答)是指通过从网络或其他大的文档集中找到回答用户问题的短文本,下图是一些例子。

基于IR的问答主要的组成部分是Retriever和Reader模块,如下图所示。
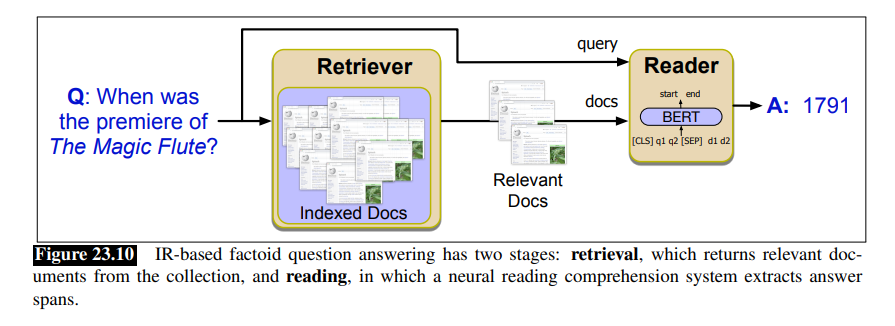
在这个两阶段的模型的第一个阶段中,我们从文本集合中检索到相关的段落,通常使用我们上节介绍的搜索引擎。在第二阶段,一个基于神经网络的阅读理解(reading comprehension)算法从相关段落中找到可能回答问题的块(span)。
阅读理解系统基于给定的事实类问题 q q q和一个可能包含答案的段落 p p p,然后返回一个答案 s s s或表面没有答案。
其他的问答系统直接处理整个检索和理解任务;给定它们一个事实问题和大量文档集,然后就可以返回一个答案,通常也是从某个文档中抽取的某块(span)。这种任务通常被称为开放领域问答。
基于IR的问答:数据集
基于IR问答的数据集常用的是首次开发的阅读理解数据集,包含(passage,question,answer)元组。阅读理解系统能使用该数据集训练一个reader,给定一个段落和一个问题,然后预测段落中的某一块作为答案。
比如斯坦福的问答数据集(SQuAD)包含从维基百科抽取的段落和相关联的问题,这些问题的答案该段落中的某一块。Squad2.0额外增加了一些被设计为没有答案的问题,共有150000个问题。

上图显示了SQuAD2.0中某个例子段落,包含了问题和它们的答案(用黄色区域标出)。
在阅读理解任务中,需要给定一个问题和可能包含答案的段落到阅读理解系统中;而在完整的两阶段问答任务中,它们的系统不需要给定段落,通常需要系统本身从文档集合中去检索。
基于IR的问答:Reader(答案块抽取)
基于IR的问答第一阶段是一个retriver起作用,第二阶段是reader。在我们这里讨论的提取式(extractive)的QA,答案是段落中的某一块。
答案抽取任务通常通过标记块(span labeling)来建模:从段落中指出构成答案的一块(连续的文本字符串)。基于神经网络阅读理解的算法的做法是,给定一个 n n n个单词 q 1 , ⋯ , q n q_1,\cdots,q_n q1,⋯,qn组成的问题 q q q和 m m m个单词 p 1 , ⋯ , p m p_1,\cdots,p_m p1,⋯,pm组成的段落 p p p。目标就是计算每个块 a a a是答案的概率 P ( a ∣ q , p ) P(a|q,p) P(a∣q,p)。
假设每个块 a a a从位置 a s a_s as开始到位置 a e a_e ae结束,我们做了一个简化假设,通过 P ( a ∣ q , p ) = P s t a r t ( a s ∣ q , p ) P e n d ( a e ∣ q , p ) P(a|q,p) = P_{start}(a_s|q,p)P_{end}(a_e|q,p) P(a∣q,p)=Pstart(as∣q,p)Pend(ae∣q,p)来估计该概率。即对于每个段落中的单词 p i p_i pi,我们会计算两个概率: p i p_i pi是答案块开始位置的概率 p s t a r t ( i ) p_{start}(i) pstart(i)和 p i p_i pi是答案块结束位置的概率 p e n d ( i ) p_{end}(i) pend(i)。
阅读理解任务的一个标准的基准算法是传入问题和段落到任意的编码器像BERT,其中问题和段落通过[SEP]标记分隔,形成了一个每个段落单词 p i p_i pi的编码嵌入向量。
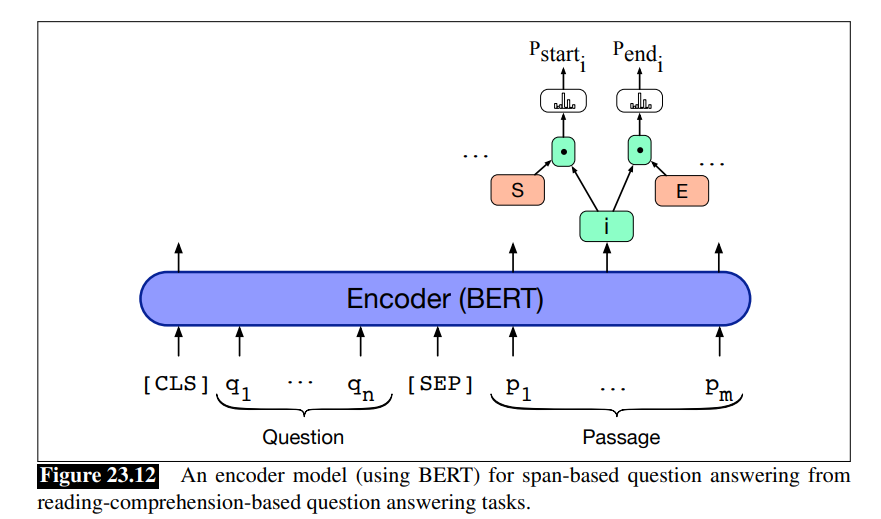
对于基于块的问答任务,我们将问题表示为第一个序列,段落表示为第二个序列,中间用[SEP]分开,还需要添加一个线性层,用于在fine-tuning阶段训练来预测块的开始和结束位置。我们还会增加两个特殊的向量:一个块开始嵌入 S S S和一个块结束嵌入 E E E,也会在fint-tuning阶段学习。为了得到每个输出单词 p i ′ p_i^\prime pi′的的块开始概率,我们计算 S S S和 p i ′ p_i^\prime pi′的点积,然后通过Softmax去归一化:
P s t a r t i = e x p ( S ⋅ p i ′ ) ∑ j e x p ( S ⋅ p j ′ ) P_{start_i}=\frac{exp(S \cdot p_i^\prime) }{\sum_j exp(S \cdot p_j^\prime)} Pstarti=∑jexp(S⋅pj′)exp(S⋅pi′)
类似地,我们计算块结束概率:
P e n d i = e x p ( E ⋅ p i ′ ) ∑ j e x p ( E ⋅ p j ′ ) P_{end_i}=\frac{exp(E \cdot p_i^\prime) }{\sum_j exp(E \cdot p_j^\prime)} Pendi=∑jexp(E⋅pj′)exp(E⋅pi′)
从位置 i i i到 j j j的候选块得分是 S ⋅ p i ′ + E ⋅ p j ′ S \cdot p_i^\prime + E \cdot p_j^\prime S⋅pi′+E⋅pj′,然后选取最高得分的块作为模型的预测,其中 j ≥ i j \geq i j≥i。
微调(fine-tuning)的训练损失是每个样本正确的开始和结束位置的负对数似然之和:
L = − log P s t a r t i − log P e n d i L = - \log P_{start_i} - \log P_{end_i} L=−logPstarti−logPendi
很多数据集,像SquAD2.0,也包含答案不在段落中的问题-段落对。我们也需要一种方式来估计问题的答案不在文档中的概率。标准地做法是把没有答案的问题当做有答案的问题来处理,但是答案是[CLS]标记,这样答案块就会指向[CLS]的位置。
实体链接
实体链接(Entity linking)是在一个本体(ontology)中将文本中的描述(mention)与一些真实世界的实体表示关联起来的任务。
事实回答问题最常见的本体是维基百科,因为维基百科通常是回答问题的文本的来源。在这种用法中,每个唯一的维基百科页面作为特定实体的唯一id。决定哪个维基百科页面与一个个体对应被一个文本描述(text mention)所引用任务有它自己的名字:维基化(wikification)。
自最早的系统以来,实体链接分为(大致)两个阶段:描述检测(mention detection)和描述消歧(mention disambiguation)。我们将给出两种算法,一种简单的经典基准,使用锚点字典(anchor dictionaries)和来自维基百科图结构的信息和一种现代神经算法。我们将在这里主要关注链接到问题的实体的应用,而不是其他类型。
基于锚点词典和网络图的链接
作为一个简单的基准我们引入用于维基百科的TAGME linker,它本身利用了早期的算法。为计划算法将维基百科页面集定义为实体集合,所以我们用独立的实体 e e e指代每个维基百科页面。TAGME首先创建一个所有实体的目录(比如,所有的维基百科页面,移除一些消歧和其他元页面)然后用标准的IR引擎如Lucene索引它们。对于每个页面 e e e,该算法计算一个链接内(in-link)计数 i n ( e ) in(e) in(e):其他维基百科页面指向该页面的数量。
最终,该算法需要一个锚点词典。一个锚点词典列出了每个维基百科页面,它的锚点文本:指向它的其他页面上的锚文本的超链接文本块。比如,斯坦福大学的网页http://www.stanford.edu,可能被其他页面通过下面的锚文本Stanford University所指向:
<a href="http://www.stanford.edu">Stanford University</a>
我们计算一个维基百科锚点字典,包括每个维基百科页面 e e e, e e e的标题以及所有维基百科页面指向 e e e的锚文本。对于每个锚字符串 a a a,我们还将计算其在维基百科中的总频率 f r e q ( a ) freq(a) freq(a)(包括非锚使用), a a a作为链接出现的次数(我们称为 l i n k ( a ) link(a) link(a)),和它的链接概率 l i n k p r o b ( a ) = l i n k ( a ) / f r e q ( a ) linkprob(a) = link(a)/freq(a) linkprob(a)=link(a)/freq(a)。需要对最终的锚点字典进行一些清理,例如删除仅由数字或单个字符组成的锚点字符串,这些数据非常罕见,或者不太可能是有用的实体,因为它们的 l i n k p r o b linkprob linkprob非常低。
描述检测 给定一个问题,TAGME通过查询每个单词序列最多6个单词的锚点字典来检测描述(mention)。这些大的序列集用一些简单的启发式方法进行修剪(例如,如果子字符串的 l i n k p r o b linkprob linkprob较小,则进行修剪)。问题:
When was Ada Lovelace born?
可能会产生锚点Ada Lovelace和Ada,但是像Lovelace这样的子串块可能会被修剪,因为 l i n k p r o b linkprob linkprob太低,但像born一样的块的 l i n k p r o b linkprob linkprob太低,以至于它们根本不在锚点词典中。
描述消歧 如果一个描述块是明确的(只指向一个实体/维基百科页面),实体链接就完成了!然后,很多块是不明确的,匹配了多个维基实体/页面的锚点。TAGME算法使用两个法宝来为不明确的块进行消歧,这被称为先验概率和相关性/一致性。第一个因素是 p ( e ∣ a ) p(e|a) p(e∣a),即块指定特定实体的概率。对于每个页面 e ∈ E ( a ) e\in \mathcal{E}(a) e∈E(a),锚点 a a a指向 e e e的概率 p ( e ∣ a ) p(e|a) p(e∣a) ,是使用锚文本 a a a链入 e e e的链接数与 a a a作为锚点出现的总数的比率:
prior ( a → e ) = p ( e ∣ a ) = count ( a → e ) link ( a ) \text{prior}(a \rightarrow e) = p(e|a) = \frac{\text{count}(a \rightarrow e)}{\text{link}(a)} prior(a→e)=p(e∣a)=link(a)count(a→e)
TAGME算法还有第二个法宝,输入问题中该实体与其他实体的相关性。给定一个问题 q q q,其中检测到的每个候选锚点块 a a a,我们为每个可能的实体 e ∈ E ( a ) e \in \mathcal{E}(a) e∈E(a)分配一个相关性得分。链接 a → e a \rightarrow e a→e的相关性得分是所有其他 q q q中实体与 e e e的相关性的加权平均。有两个实体被认为是相关的与它们的维基百科页面共享许多内部链接的程度有关。更正式地说,两个实体 A A A和 B B B之间的相关性计算为
r e l ( A , B ) = l o g ( m a x ( ∣ i n ( A ) ∣ , ∣ i n ( B ) ∣ ) ) − l o g ( ∣ i n ( A ) ∣ ∩ ∣ i n ( B ) ∣ ) l o g ( ∣ W ∣ ) − l o g ( m i n ( ∣ i n ( A ) ∣ , ∣ i n ( B ) ∣ ) ) rel(A,B) = \frac{log(max(|in(A)|,|in(B)|))−log(|in(A)| ∩|in(B)|) }{log(|W|)−log(min(|in(A)|,|in(B)|))} rel(A,B)=log(∣W∣)−log(min(∣in(A)∣,∣in(B)∣))log(max(∣in(A)∣,∣in(B)∣))−log(∣in(A)∣∩∣in(B)∣)
其中 i n ( x ) in(x) in(x)是指向 x x x的维基百科页面集合; W W W是所有维基百科页面集合。
锚点 b b b给候选标注 a → X a \rightarrow X a→X的投票是 b b b的所有可能实体与 X X X相关性的平均值,通过它们的先验概率加权:
v o t e ( b , X ) = 1 ∣ E ( b ) ∣ ∑ Y ∈ E ( b ) r e l ( X , Y ) p ( Y ∣ b ) vote(b,X) = \frac{1} {|\mathcal{E}(b)|} \sum_{Y \in \mathcal{E}(b)} rel(X,Y)p(Y|b) vote(b,X)=∣E(b)∣1Y∈E(b)∑rel(X,Y)p(Y∣b)
a → X a \rightarrow X a→X的总相关性得分是 q q q中所有其他锚点的投票之和:
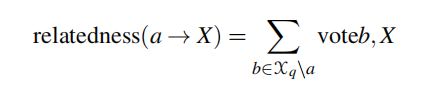
为了计算 a → X a \rightarrow X a→X的得分,我们结合相关性和先验通过选择具有最高相关性 ( a → X ) (a \rightarrow X) (a→X)的实体 X X X,在该值的一个小 ϵ \epsilon ϵ中找到其他实体,并从这个集合中选择先验 P ( X ∣ a ) P(X|a) P(X∣a)最高的实体。这步得到的是在 q q q中分配给每个块的单个实体。
TAGME算法还有一个进一步的步骤来剪枝假的锚点/实体对,分配一个具有一致性(coherence)的分数平均链接概率。
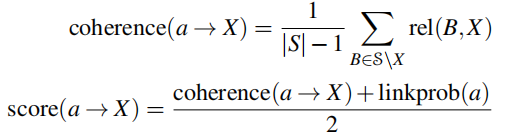
最后,如果得分 s c o r e ( a → X ) < λ score(a→X)<λ score(a→X)<λ,则锚点/实体对被修剪,其中阈值 λ \lambda λ是在一个保留集上设置的。
基于神经网络图的链接
最近的实体链接模型是基于双编码器(biencoders),编码一个候选描述块(mention span),编码一个实体,并计算编码之间的点积。这允许对知识库中所有实体的嵌入进行预计算和缓存1。让我们画出Li2等人提出的ELQ链接算法草图,它给出了一个问题 q q q和一组来自维基百科的候选实体与相关的维基百科文本,并实体id的输出元组 ( e , m s , m e ) (e,m_s,m_e) (e,ms,me),描述(mention)开始和描述(mention)结束。如图所示,它通过使用维基百科中的文本编码每个维基百科实体,使用问题中的文本对每个描述块进行编码,并计算它们的相似性。
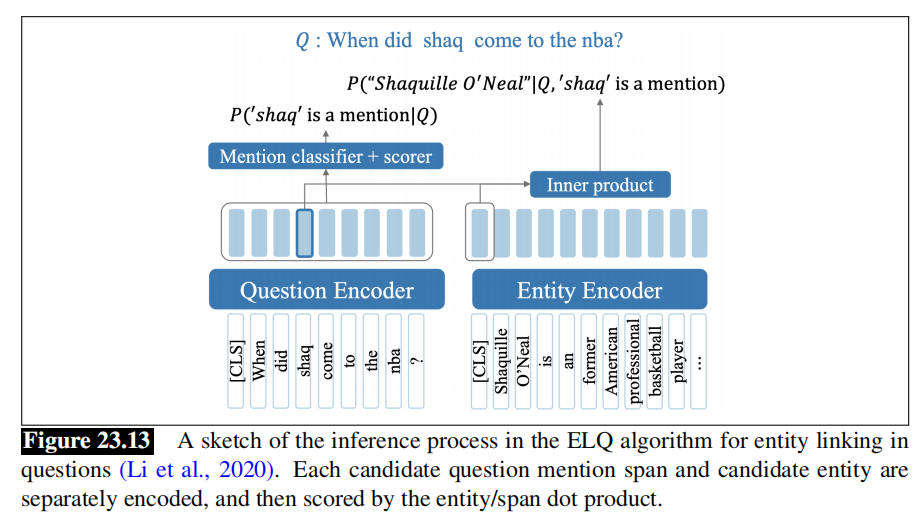
实体描述检测 为了得到每个问题单词的一个 h h h维的嵌入,该算法传入问题到BERT中:
[ q 1 ⋯ q n ] = BERT ( [ CLS ] q 1 ⋯ q n [ SEP ] ) [q_1\cdots q_n] = \text{BERT}([\text{CLS}]q_1 \cdots q_n[\text{SEP}]) [q1⋯qn]=BERT([CLS]q1⋯qn[SEP])
然后计算 q q q中的每个块 [ i , j ] [i,j] [i,j]作为一个实体描述的可能性,以一种与我们上面看到的基于块的算法类似的方式。首先我们计算 i / j i/j i/j作为一个描述开始/结束的得分:
S s t a r t ( i ) = w s t a r t ⋅ q i , S e n d ( j ) = w e n d ⋅ q j S_{start}(i) = w_{start} \cdot q_i, \quad S_{end}(j) = w_{end} \cdot q_j Sstart(i)=wstart⋅qi,Send(j)=wend⋅qj
其中 w s t a r t w_{start} wstart和 w e n d w_{end} wend是在训练期间学习的向量。接下来,另一个可训练的嵌入, w m e n t i o n w_{mention} wmention用来计算每个单词作为某个描述一部分的得分:
s m e n t i o n ( t ) = w m e n t i o n ⋅ q t s_{mention} (t) = w_{mention} \cdot q_t smention(t)=wmention⋅qt
描述概率然后通过组合这些得分计算:
p ( [ i , j ] ) = σ ( S s t a r t ( i ) + s e n d ( j ) + ∑ t = i j S m e n t i o n ( t ) ) p([i,j]) = \sigma \left( S_{start}(i) + s_{end}(j) + \sum_{t=i}^j S_{mention}(t) \right) p([i,j])=σ(Sstart(i)+send(j)+t=i∑jSmention(t))
实体链接 为了链接描述到实体,我们下面计算每个在所有维基百科实体集合 E = e 1 , ⋯ , e i , ⋯ , e w \mathcal{E}=e_1,\cdots, e_i, \cdots ,e_w E=e1,⋯,ei,⋯,ew中的实体的嵌入。对于每个实体 e i e_i ei,我们将从该实体的维基百科页面获得文本,标题 t ( e i ) t(e_i) t(ei)和维基百科页面的前128个单词,我们将称之为 d ( e i ) d(e_i) d(ei)。再次传入BERT,以CLS单词 BERT [ CLS ] \text{BERT}_{[\text{CLS}]} BERT[CLS]的输出作为实体表示:
x e = BERT [ CLS ] ( [ CLS ] t ( e i ) [ ENT ] d ( e i ) [ SEP ] ) x_e = \text{BERT}_{[\text{CLS}]}([\text{CLS}]t(e_i)[\text{ENT}]d(e_i)[\text{SEP}]) xe=BERT[CLS]([CLS]t(ei)[ENT]d(ei)[SEP])
描述块可以链入实体通过计算对于每个实体 e e e和块 [ i , j ] [i,j] [i,j]的点积相似度,点积的计算方式是以块编码(单词嵌入的平均值)和实体编码:
y i , j = 1 j − i + 1 ∑ t − i j q t s ( e , [ i , j ] ) = x e y i , j y_{i,j} = \frac{1}{j - i + 1} \sum_{t-i}^j q_t \\ s(e, [i,j]) = x_e y_{i,j} yi,j=j−i+11t−i∑jqts(e,[i,j])=xeyi,j
最终,我们通过softmax得到每个块的实体分布:
p ( e ∣ [ i , j ] ) = e x p ( s ( e , [ i , j ] ) ) = exp ( s ( e , [ i , j ] ) ) ∑ e ′ ∈ E exp ( s ( e ′ , [ i , j ] ) ) p(e|[i,j]) = exp(s(e,[i,j])) = \frac{\exp(s(e,[i,j]))}{\sum_{e^\prime \in \mathcal{E} } \exp(s(e^\prime,[i,j]))} p(e∣[i,j])=exp(s(e,[i,j]))=∑e′∈Eexp(s(e′,[i,j]))exp(s(e,[i,j]))
训练 ELQ描述检测和实体链接算法是完全监督的。这意味着,与前面的锚点字典算法不同,它需要具有标记的和链接的实体边界的数据集。
给定一个训练集,ELQ描述检测和实体链接阶段被联合训练,优化它们的总损失。描述检测损失是一个二分类交叉熵损失
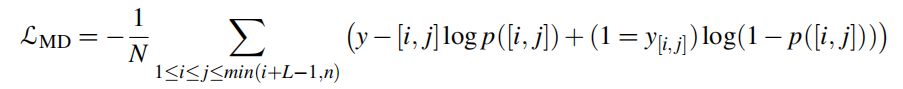
其中 y [ i , j ] = 1 y_[i,j]=1 y[i,j]=1如果 [ i , j ] [i,j] [i,j]是标注的描述块,否则为0。实体链接损失为:
L ED = − log p ( e g ∣ [ i , j ] ) \mathcal{L}_{\text{ED}} = - \log p(e_g | [i,j]) LED=−logp(eg∣[i,j])
其中 e g e_g eg是描述 [ i , j ] [i,j] [i,j]的标注实体。
基于知识库的问答
基于知识库的问答两个常用方法是:(1)基于图的问答,将知识库建模成图结构,通常将实体作为节点,将相关性表示为节点之间的边。(2)基于语义分析的问答。
这两种方法都需要进行一些实体链接。
使用RDF三元组的基于知识库的问答
假设在实体链接处理了之后,我们关注于基于图问答的最简单情况,其中数据集是RDF三元组形式的事实集合,任务就回答与三元组中某个缺失的参数有关的问题。考虑下面的三元组:
subject predicate object
Ada Lovelace birth-year 1815
该三元组可以用于回答像“When was Ada Lovelace born?”或“Who was born in 1815”这样的文本问题。
让假设我们已经完成了前一节中介绍的实体链接的阶段。因此,我们已经从像Ada Lovelace这样的文本提取到映射到知识库中的规范实体ID。对于简单的三元关系问题回答,下一步是确定要询问的关系,从字符串如“When was … born”映射到知识库中的规范关系,像birth-year。我们可以将组合后的任务概括为:

下一步是关系检测和链接。对于简单的问题,我们假设问题只有一个关系,关系检测和链接可以以一种类似于集成神经网络实体链接模型的方式完成:计算问题文本的编码和每个可能关系的编码之间的相似性(通常是通过点积)。例如,在Lukovnikovetal3的算法中,使用BERT模型的CLS输出来表示关系检测的问题块(question span),并为每个关系 r i r_i ri训练一个单独的向量。然后通过点积后的softmax计算特定关系 r i r_i ri的概率:
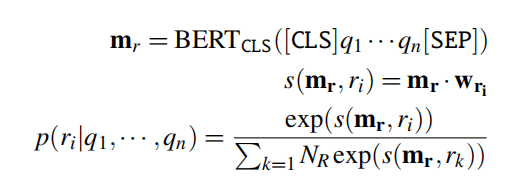
答案排序 大多数算法都有一个最后阶段,获取最前面的 j j j个实体和实体返回的最前面的 k k k个关系,在知识库中搜索包含这些实体和关系的三元组,然后对这些三元组进行排序。这种排序可以是启发式的,例如,根据描述块和实体文本别名之间的字符串相似性对每个实体/关系对进行评分,或者支持具有高程度(hight in-degree)(由许多关系链接到)的实体。或者,也可以通过训练一个分类器输入连接(concatenated)的实体/关系编码,进行预测,得到一个概率来完成排序。
基于语义分析的问答
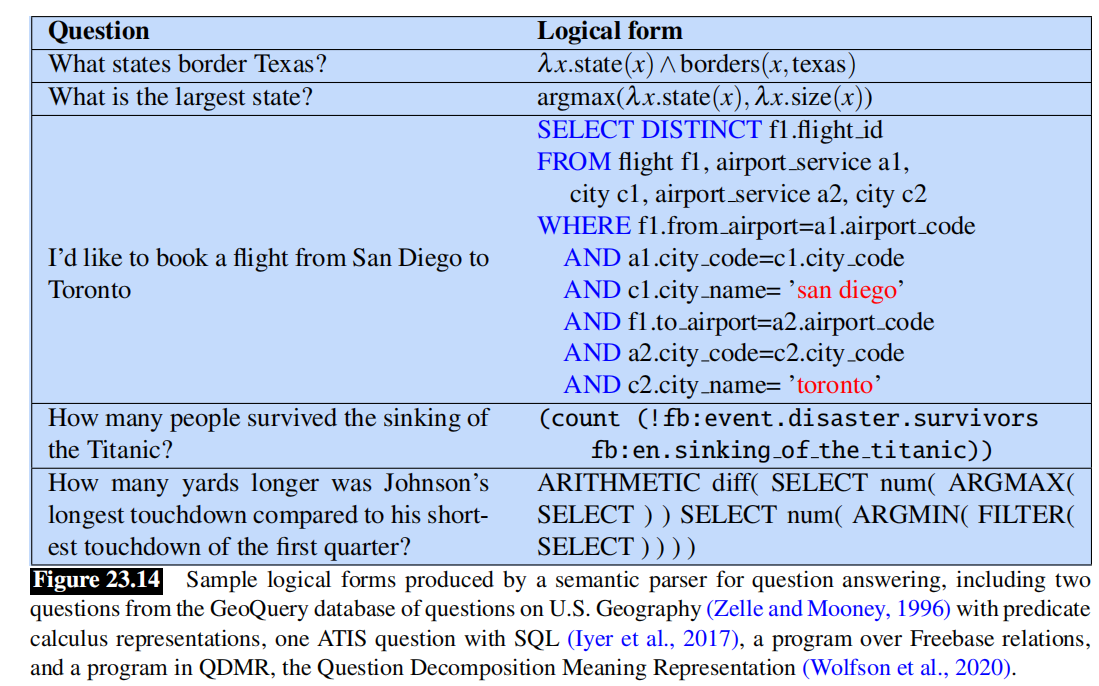
第二种基于知识库的QA使用语义分析器将问题映射到一个结构化的程序中,以生成答案。
语义分析算法可以是完全监督的用手工构建的逻辑形式的问题,也可以是弱监督的用带有答案(表示)的问题,其中逻辑形式只被建模为一个隐变量(latent variable)。
对于完全监督的情况,我们可以从关于美国地理问题的数据集中得到一组问题及其正确的逻辑形式,比如GEOQUERY数据集,需要推理的复杂问题(关于历史和足球游戏)的DROP数据集,它们都有SQL版本或其他逻辑形式4。
然后,任务是使用这些训练元组对,并生成一个从新问题映射到其逻辑形式的系统。一个常见的基准算法是一个简单的seq2seq模型,例如使用BERT来表示问题单词,将它们传递给BiLSTM编码器解码器,如下图所示:
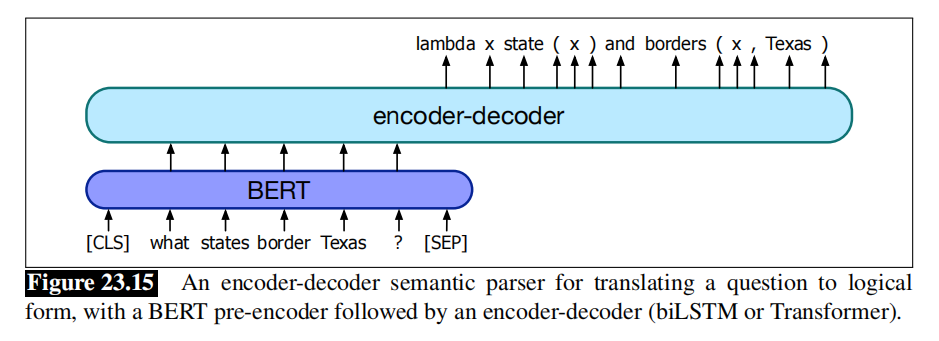
使用语言模型进行问答
问答任务的另一种方法是查询预先训练过的语言模型,迫使模型仅从其参数中存储的信息来回答问题。例如,Roberts5使用T5语言模型,这是一个预先训练好的编码器解码器架构,来填充屏蔽的块(masked span)任务。
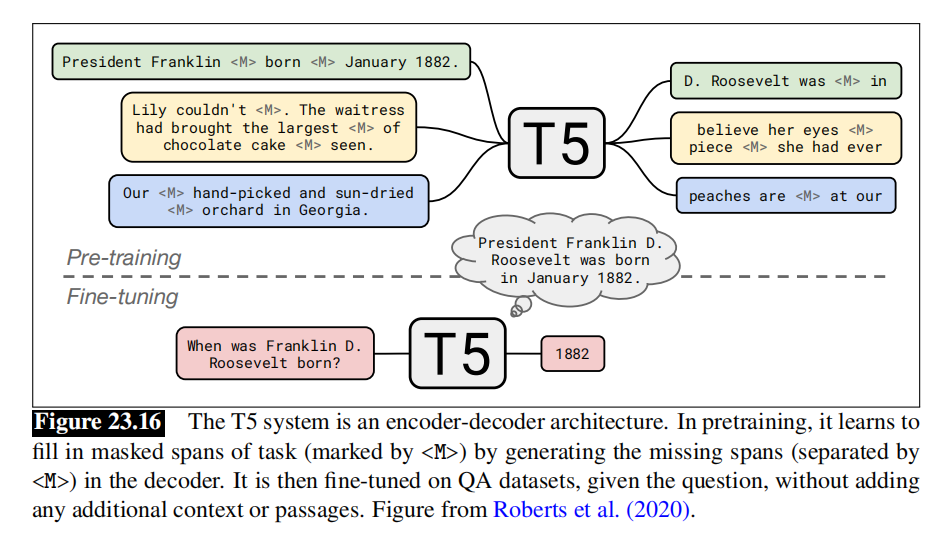
上图显示了这种结构,删除的块用<M>标记,然后这个带有解码器的系统被训练来生成缺失的块(通过<M>分隔)。
然后将T5系统微调到问答任务,给它一个问题,并训练它输出解码器中的回答文本。使用最大的110亿个参数的T5模型确实具有竞争力,尽管不像专门为问答任务而设计的系统那么好。
语言建模还不是一个完整的问答问题的解决方案;例如,除了效果不太好之外,他们的可解释性也很差(例如,与标准的问答系统不同,它们目前不能通过告诉用户答案来自哪个段落来给用户更多的上下文)。
事实答案的评估
在1999年的TREC Q/A track中引入的事实问题回答的一个常见的评估度量是平均倒数排名(mean reciprocal rank,MRR)。MRR假设有一组已经被人类标记为正确的答案的测试集。MRR还假设系统返回一个短的答案或包含答案段落的排名列表。然后根据第一个正确答案的排名的倒数对每个问题进行评分。例如,如果系统返回了5个答案,但前三个答案是错误的,因此排名最高的正确答案排名为第四,那么该问题的倒数排名分数将是 1 4 \frac{1}{4} 41。不包含任何问题正确答案的返回集得分被定义为零。一个系统的分数是该集中每个问题得分的平均值。更正式地说,即对于对由 N N N个问题组成的测试集返回一组排名的答案的系统的评估,MRR被定义为
MRR = 1 N ∑ i = 1 s.t. rank i ≠ 0 N 1 rank i \text{MRR} = \frac{1}{N} \sum_{i=1 \, \text{s.t.} \, \text{rank}_i \neq 0}^N \frac{1}{\text{rank}_i} MRR=N1i=1s.t.ranki=0∑Nranki1
基于像SQuAD数据集的阅读理解系统通常使用两个指标评估:
- 完全匹配:预测的答案完全匹配标记的答案的比例
- F 1 F_1 F1分数:预测答案和标记答案之间重叠的均值。将预测和标记作为单词袋,并计算 F 1 F_1 F1,求所有问题 F 1 F_1 F1分数的均值
参考

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 3
3 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)