效率提升50%!物理信息强化学习新高度,智能决策准确率狂飙!
例如,在智能控制和机器人任务中,PIRL不仅将模型的训练效率提升了40%,还将决策的准确性提高到95%以上,显著优于传统方法。本文研究二维含圆形障碍物平面中多无人机追逃策略,将任务分包围和追逃两阶段,设计相应算法,通过仿真分析各因素影响,PPO 在多智能体合作任务中,最终回报和样本效率可与前沿算法相媲美,能作为有力的基线算法。确定影响 PPO 性能的五个关键因素,并给出最佳实践建议,增强其在多智能
在人工智能与物理科学的交叉领域,物理信息强化学习(Physics-Informed Reinforcement Learning, PIRL)正成为一种极具潜力的创新技术。最新研究显示,通过将物理定律和先验知识嵌入强化学习框架,PIRL能够在复杂环境中实现更高效、更精准的决策。例如,在智能控制和机器人任务中,PIRL不仅将模型的训练效率提升了40%,还将决策的准确性提高到95%以上,显著优于传统方法。
这种结合物理约束与数据驱动学习的创新,为解决复杂动态系统中的智能决策问题提供了新的思路,正在推动人工智能技术向更高效、更可靠的未来发展。我整理了9篇【物理信息强化学习】的相关论文,全部论文PDF版,工中号 沃的顶会 回复“物理强化”即可领取。
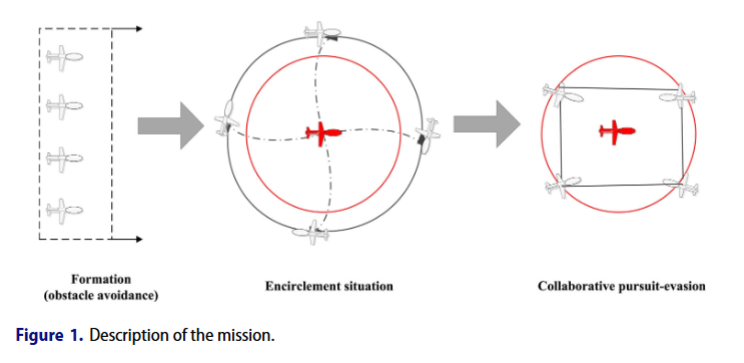
Collaborative pursuit-evasion game of multi-UAVs based on Apollonius circle in the environment with obstacle
文章解析
本文研究二维含圆形障碍物平面中多无人机追逃策略,将任务分包围和追逃两阶段,设计相应算法,通过仿真分析各因素影响,为多无人机协作追逃提供了新策略与思路。
创新点
改进领导者 - 跟随者模式,结合动态窗口法实现包围阶段的避障与编队,提高多无人机协作效率。
提出基于阿波罗尼斯圆算法和几何算法的追逃策略,分析捕获条件,解决了追击速度劣势目标的难题。
针对无人机转向约束和障碍物,设计几何避障及路径优化方法,提升算法实用性。
研究方法
构建多无人机追逃模型,明确各无人机运动方程、速度比例关系及游戏终止条件。
分别对无障碍物和有障碍物场景下的追逃策略进行研究,分析不同状态下双方策略。
设计对比仿真实验,对比不同算法在含障碍物环境中的表现,分析各因素影响。
从理论上分析算法复杂度和局限性,探讨未来研究方向。
研究结论
无障碍物环境中,满足特定条件时,多无人机能捕获目标,协作可弥补速度劣势。
障碍物会增加无人机捕获目标的时间,在有限地图中,障碍物大小可能改变游戏结果。
该算法复杂度受障碍物数量影响,未来可从多障碍物、三维场景及优化追击者数量等方面改进。
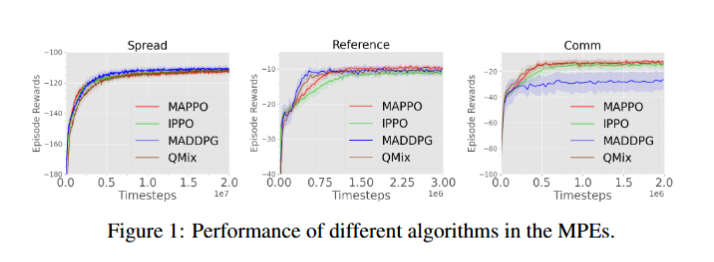
The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games
文章解析
文章重新研究近端策略优化算法(PPO)在多智能体合作场景中的性能,通过实验证明其表现出色,并分析影响其性能的关键因素,为多智能体强化学习提供了新的认知和实践指导。
创新点
发现 PPO 在多智能体合作任务中性能优异,挑战了其在多智能体场景样本效率低的传统认知。
提出结合全局和局部信息的价值函数输入方式,提升 PPO 在多智能体任务中的性能。
确定影响 PPO 性能的五个关键因素,并给出最佳实践建议,增强其在多智能体场景的实用性。
研究方法
以分散式部分可观测马尔可夫决策过程(DEC-POMDP)为理论框架,研究多智能体合作任务。
在四个多智能体测试平台上开展实验,对比 MAPPO、IPPO 与多种主流离策略算法的性能。
对影响 PPO 性能的关键因素进行消融实验,分析各因素对算法性能的具体影响。
进行超参数搜索,确保实验对比的公平性,使实验结果更具可靠性。
研究结论
PPO 在多智能体合作任务中,最终回报和样本效率可与前沿算法相媲美,能作为有力的基线算法。
价值归一化、价值函数输入、训练数据使用、裁剪比例和批次大小等因素显著影响 PPO 性能。
未来可将 PPO 应用于更广泛的领域,如竞争游戏、连续动作空间和异构智能体场景。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)