Dijkstra算法实战:解决最短路径规划问题
Dijkstra算法是最著名的图搜索算法之一,由荷兰计算机科学家艾兹赫尔·戴克斯特拉于1956年提出,并于1959年发表。它用于在加权图中找到单源最短路径,即从单一源点出发,到达图中所有其他顶点的最短路径。该算法解决了多源最短路径问题,广泛应用于网络路由协议、地图导航、社交网络分析和许多其他领域。最短路径问题是图论中的一个经典问题,其目标是在图中找到两个指定顶点之间的最短路径。这里的“最短”是指路

简介:Dijkstra算法是一种用于寻找加权有向图中两点间最短路径的经典算法。它利用贪心策略,通过维护一个优先队列来逐步确定节点的最短路径。算法广泛应用于路径规划、网络路由优化和交通导航等领域。本文将介绍Dijkstra算法的原理、优缺点以及如何应用于实际场景,同时也将探讨其在不同领域中的扩展应用。 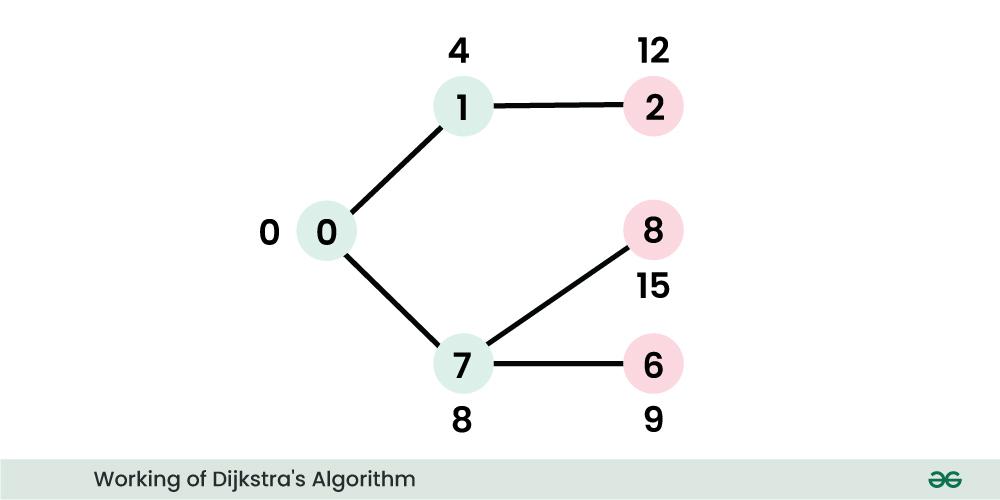
1. Dijkstra算法介绍
Dijkstra算法是最著名的图搜索算法之一,由荷兰计算机科学家艾兹赫尔·戴克斯特拉于1956年提出,并于1959年发表。它用于在加权图中找到单源最短路径,即从单一源点出发,到达图中所有其他顶点的最短路径。该算法解决了多源最短路径问题,广泛应用于网络路由协议、地图导航、社交网络分析和许多其他领域。
1.1 算法的应用场景
Dijkstra算法的核心优势在于其解决有向和无向图的能力,适用于有权重的边。在现实世界中,我们可以将该算法应用于网络路由、交通规划、电信网络、物流配送等多个场景。例如,在交通网络中,Dijkstra算法能够帮助我们确定两点之间的最短行驶距离。
1.2 算法的基本要求
为了使用Dijkstra算法,我们需要确保图中没有负权重的边。这是因为算法依赖于逐步确定最短路径,而负权重边的存在会破坏算法的正确性,导致无法找到实际的最短路径。在实际应用中,这种情况需要通过预处理来确保图满足算法要求。
在下一章,我们将深入了解算法的理论基础和具体的执行步骤。
2. 算法原理及步骤
2.1 理论基础
2.1.1 图论的基本概念
在探讨Dijkstra算法之前,我们需要先了解图论中的一些基本概念。图论是数学的一个分支,专门研究图的概念以及在图上的各种算法。图是由一组顶点(或称为节点)和连接这些顶点的一组边组成的结构。在计算机科学中,图通常用来模拟网络,其中顶点代表实体,边代表实体间的某种关系。
图可以分为有向图和无向图,边可以是有权重的或无权重的。在路径查找问题中,我们通常关心的是带权重的有向图,因为权重可以表示距离、成本或任何其他影响路径选择的因素。Dijkstra算法就适用于这样的图模型。
2.1.2 最短路径问题的定义
最短路径问题是图论中的一个经典问题,其目标是在图中找到两个指定顶点之间的最短路径。这里的“最短”是指路径权重的总和最小,而非路径中边的数量最少。Dijkstra算法正是为了解决这类单源最短路径问题而设计的,即给定一个源顶点,找到该顶点到图中所有其他顶点的最短路径。
最短路径问题在现实世界中有广泛的应用,如导航系统中的路径规划、网络中的数据包传输路由等。Dijkstra算法的效率和准确性对这些问题至关重要。
2.2 算法流程详解
2.2.1 起点的选择和初始化过程
Dijkstra算法的起点选择和初始化过程是算法运行的基础。假设我们有一个带权重的有向图G=(V, E),其中V代表顶点集合,E代表边集合。算法首先选择一个起始顶点s ∈ V,并对所有顶点进行初始化,设置每个顶点的最短路径估计值为无穷大,除了起点s的最短路径估计值设为0。
初始化过程中,还需要维护两个集合S和Q,其中S包含已经找到最短路径的顶点,Q则是待考察顶点的集合。一开始,S为空,而Q包含图中的所有顶点。
# 初始化所有顶点的距离为无穷大
distances = {vertex: float('infinity') for vertex in vertices}
# 将起点的距离设为0
distances[start_vertex] = 0
# 初始化待考察的顶点集合
unvisited = set(vertices)
# 将所有顶点加入待考察集合
unvisited = set(vertices)
2.2.2 松弛操作的原理与实现
松弛操作是Dijkstra算法的核心概念,它用于更新顶点之间的最短路径估计值。对于起点s的每个邻居u,算法检查是否存在一条通过s的路径到达u,使得路径的总权重小于当前u的最短路径估计值。如果是,就更新u的最短路径值,并记录路径。
松弛操作不仅更新了当前顶点的最短路径值,还帮助我们更接近最终解。在实现时,通常会用一个优先队列来存储和更新待考察顶点的信息,优先队列按照顶点的最短路径估计值进行排序。
import heapq
# 松弛操作
def relax(u, v, weight, distances, unvisited):
if distances[u] + weight < distances[v]:
distances[v] = distances[u] + weight
heapq.heappush(unvisited, (distances[v], v))
# 示例:更新顶点u和v之间的路径
relax(start_vertex, v, weight, distances, unvisited)
2.2.3 路径的重构与最短路径的确定
在Dijkstra算法的最后阶段,我们需要重构从起点s到终点t的最短路径。这通常是通过追踪每个顶点的前驱节点来完成的。一旦算法完成,我们就可以查看任意顶点的最短路径估计值,或者通过从终点回溯到起点来重构整条路径。
路径重构是算法的最后一步,也是将算法结果用于实际应用的关键步骤。通过前驱节点的追踪,我们可以准确地构造出一条最短路径,并可用于各种实际场景,如导航、网络路由等。
在实际的代码实现中,会有一个额外的字典来存储每个顶点的前驱节点信息。这个信息是在松弛操作的过程中逐步构建起来的。
# 路径重构函数
def construct_path(current_vertex, previous_vertices):
path = []
while current_vertex in previous_vertices:
path.append(current_vertex)
current_vertex = previous_vertices[current_vertex]
path.append(start_vertex) # 添加起点
path.reverse() # 反转路径
return path
# 示例:路径重构
previous_vertices = {v: u for u, v in edges}
reconstructed_path = construct_path(end_vertex, previous_vertices)
以上内容详细介绍了Dijkstra算法的各个步骤,展示了从初始化、松弛操作到路径重构的整个过程。这种由浅入深的解释方式可以帮助读者更好地理解算法的运行机制和应用价值。
3. 优先队列在算法中的应用
优先队列是一种特殊的队列,它在Dijkstra算法中扮演了至关重要的角色。它能够根据元素的优先级进行排序,使得优先级最高的元素总是位于队列的前端,从而在每次访问时都可以直接获取到优先级最高的元素。在本章节中,我们将深入探讨优先队列的概念、特点,以及它如何优化Dijkstra算法的效率。
3.1 数据结构简介
3.1.1 优先队列的概念与特点
优先队列是一种抽象数据类型,它允许插入任意元素,并支持删除最小(或最大)元素的操作。它不同于普通队列,后者仅支持先进先出(FIFO)原则。优先队列通常由堆(heap)数据结构实现,堆是一种特殊的完全二叉树,能够保持父节点的键值总是大于或等于任何一个子节点的键值(在最小堆的情况下)。
优先队列的主要特点包括: - 插入操作 :可以插入任意元素,一般用O(log n)的时间复杂度完成。 - 删除操作 :删除并返回队列中优先级最高的元素,一般用O(log n)的时间复杂度完成。 - 查找操作 :查找优先级最高的元素,通常用O(1)的时间复杂度完成。
3.1.2 优先队列在Dijkstra中的角色
在Dijkstra算法中,优先队列用于维护未被访问的顶点集合,并按照当前已知的最短路径长度排序。算法过程中,优先队列不断提供当前估计最短路径的顶点,而算法则更新该顶点邻接顶点的路径长度。如果没有优先队列,算法需要遍历所有未访问的顶点来找出距离最小的顶点,这会使得时间复杂度增加到O(V^2),其中V是顶点数量。
借助优先队列,Dijkstra算法的时间复杂度降低到O((V+E)logV),其中E是边的数量。这是因为在每一步中,算法从优先队列中提取最小元素的操作仅需要O(logV)的时间复杂度,而更新操作需要遍历所有邻接顶点,这需要O(E)的时间复杂度。
3.2 优先队列优化算法效率
3.2.1 时间复杂度的降低分析
为了理解优先队列如何优化Dijkstra算法的时间复杂度,我们需要分析算法中各个步骤的复杂度。
- 初始化过程 :初始化所有顶点的距离为无穷大,这一过程的时间复杂度为O(V)。
- 松弛操作 :对于每个顶点,松弛操作将遍历其所有邻接顶点,所以总的时间复杂度为O(E)。
- 最短路径的确定 :这个过程会不断从优先队列中提取最小元素,每次操作需要O(logV)的时间。
将上述步骤的时间复杂度相加,我们得到整个算法的总体时间复杂度: [ O(V) + O(E \cdot logV) = O((V+E)logV) ]
3.2.2 优先队列的实现技术(如斐波那契堆)
为了达到最优的时间复杂度,优先队列的实现技术至关重要。在Dijkstra算法中,最常用的优先队列实现方式是二叉堆(binary heap)或斐波那契堆(Fibonacci heap)。
二叉堆 是一种较为简单的堆实现,它能在O(logV)的时间内执行插入和删除最小元素的操作。对于Dijkstra算法,二叉堆已经可以达到理论上的时间复杂度要求。然而,二叉堆的性能受到堆高度的限制。
斐波那契堆 是一种更高效的实现,它改进了二叉堆在多次删除操作时的性能。斐波那契堆支持更优的 amortized 时间复杂度: - 插入操作:O(1) - 删除最小元素操作:O(logV) - 减小键值操作:O(1) amortized
由于Dijkstra算法的每次松弛操作可能需要减小一个顶点的键值,因此斐波那契堆可以在最坏情况下为Dijkstra算法提供更好的性能。
graph TD;
A[Dijkstra's Algorithm] --> B[Initialize Distances];
B --> C[Insert Vertices into Priority Queue];
C --> D[Examine and Dequeue Vertex];
D --> E[Relaxation Step];
E --> F[All Vertices Processed?];
F -- No --> C;
F -- Yes --> G[Reconstruct Shortest Paths];
在实际应用中,实现斐波那契堆需要相对复杂的代码和较高的时间复杂度。因此,在许多编程语言和库中,二叉堆的实现依然是默认的优先队列实现。但是,在需要处理大量数据和松弛操作的应用场景中,使用斐波那契堆可能会带来性能上的显著提升。
graph TD;
A[Priority Queue] --> B[Binary Heap];
A --> C[Fibonacci Heap];
B --> D[Insert: O(log V)];
B --> E[Delete Min: O(log V)];
C --> F[Insert: O(1) amortized];
C --> G[Delete Min: O(log V) amortized];
D --> H[Used in Most Implementations];
G --> I[Used in Specialized Cases];
在本章节中,我们探讨了优先队列的基本概念、特点,以及它在Dijkstra算法中所发挥的重要作用。通过深入分析优先队列如何优化算法效率,我们了解到不同实现技术对算法性能的潜在影响。在选择数据结构时,我们必须考虑到实际应用场景的需求和限制,以达到最优的性能表现。
4. 算法的时间复杂度分析
4.1 基本算法的时间复杂度
4.1.1 简单实现的时间复杂度评估
Dijkstra算法的基本实现通常涉及对每个顶点进行松弛操作,以找到最短路径。在最简单的情况下,该算法的时间复杂度可以通过分析其操作步骤来确定。
假设我们有一个顶点数为V和边数为E的图,Dijkstra算法会执行以下步骤:
- 初始化所有顶点的最短路径估计值为无穷大(除了起点,它被设置为0)。
- 对于图中的每个顶点,执行松弛操作,计算到达其他顶点的最短路径。
- 重复执行松弛操作,直到所有顶点的最短路径都被确定。
每一步松弛操作都可能涉及到检查和更新所有顶点的最短路径值,因此,基本的Dijkstra算法的时间复杂度是O(V^2),其中V是顶点的数量。这是因为对于每个顶点,算法可能需要比较所有顶点的最短路径值。
如果图是有边界的,并且使用邻接矩阵表示,那么在最坏的情况下,算法的时间复杂度仍然保持在O(V^2)。但是,如果图使用邻接表表示,则可以优化算法以达到O((V+E)logV)的时间复杂度,这是通过使用优先队列实现的。使用优先队列(如最小堆),可以更快地选择下一个要处理的顶点,从而减少不必要的松弛操作。
下面是使用邻接表和优先队列实现Dijkstra算法的一个简单示例:
import heapq
def dijkstra(graph, start):
distances = {vertex: float('infinity') for vertex in graph}
distances[start] = 0
priority_queue = [(0, start)]
while priority_queue:
current_distance, current_vertex = heapq.heappop(priority_queue)
if current_distance > distances[current_vertex]:
continue
for neighbor, weight in graph[current_vertex].items():
distance = current_distance + weight
if distance < distances[neighbor]:
distances[neighbor] = distance
heapq.heappush(priority_queue, (distance, neighbor))
return distances
graph = {
'A': {'B': 1, 'C': 4},
'B': {'A': 1, 'C': 2, 'D': 5},
'C': {'A': 4, 'B': 2, 'D': 1},
'D': {'B': 5, 'C': 1}
}
print(dijkstra(graph, 'A'))
在上述代码中,我们定义了一个简单的图,并通过 dijkstra 函数实现了Dijkstra算法。该函数返回从起点到所有其他顶点的最短路径长度。我们使用 heapq 模块来实现优先队列,以优化松弛操作的性能。
4.2 优化后算法的时间复杂度
在使用优先队列优化后的Dijkstra算法中,时间复杂度与优先队列中的操作效率密切相关。具体来说,如果使用斐波那契堆来实现优先队队列,算法的时间复杂度可以降低到O(VlogV + E)。这是因为在有E条边的图中,使用斐波那契堆可以减少每次从优先队列中取出最小元素的操作时间。
斐波那契堆是一种自适应数据结构,其在最坏情况下的操作时间通常低于二项堆和其他传统的堆结构。斐波那契堆可以在O(1)时间复杂度内进行一次减小键值的操作,这使得Dijkstra算法在包含大量顶点和边的图中的表现更加高效。
为了展示斐波那契堆在Dijkstra算法中的应用,我们将对之前的代码进行修改,以使用斐波那契堆实现优先队列:
import heapq
import itertools
class FibonacciHeapNode:
def __init__(self, value, priority):
self.value = value
self.priority = priority
self.mark = False
self.parent = None
self.child = None
self.left = self
self.right = self
def __lt__(self, other):
return self.priority < other.priority
class FibonacciHeap:
def __init__(self):
self.min = None
self.count = 0
def push(self, value, priority):
node = FibonacciHeapNode(value, priority)
self.min = self._consolidate(self._add_to_root_list(node))
self.count += 1
return node
def pop_min(self):
x = self.min
children = []
if x.child is not None:
children = [child for child in x.child.left一圈接回起始点]
self._remove_from_circular_list(child)
child.parent = None
for child in children:
self._add_to_root_list(child)
self.cascading_cut(child)
self.min = x.left
self._remove_from_circular_list(x)
self._consolidate(self.min)
self.count -= 1
return x.value
# (以下省略了FibonacciHeap的其他方法实现)
def dijkstra_with_fibonacci_heap(graph, start):
distances = {vertex: float('infinity') for vertex in graph}
distances[start] = 0
fibonacci_heap = FibonacciHeap()
for vertex in graph:
fibonacci_heap.push(vertex, distances[vertex])
while fibonacci_heap.count > 0:
current_vertex = fibonacci_heap.pop_min()
for neighbor, weight in graph[current_vertex].items():
distance = distances[current_vertex] + weight
if distance < distances[neighbor]:
distances[neighbor] = distance
fibonacci_heap.push(neighbor, distance)
return distances
# 使用斐波那契堆实现的Dijkstra算法
print(dijkstra_with_fibonacci_heap(graph, 'A'))
请注意,上述代码提供了一个简化版的斐波那契堆实现,并不是完整的斐波那契堆库。在实际应用中,您需要一个完全实现的斐波那契堆来达到O(VlogV + E)的时间复杂度优化。
通过比较优先队列优化前后的时间复杂度,我们可以看到优化后的算法在处理大规模图时具有显著的性能提升。由于其较低的时间复杂度,优化后的Dijkstra算法在实际应用中,如网络路由和地理信息系统中,得到了广泛使用。
在下一节中,我们将对Dijkstra算法与其他最短路径算法的时间效率进行对比,以及讨论如何选择最合适的算法来解决不同领域的问题。
5. 网络路由优化应用
5.1 网络路由概述
5.1.1 路由算法的基本要求和目标
在计算机网络中,路由算法是实现数据包从源点传输到目的节点的关键技术。路由算法的基本要求是高效、可靠和灵活。为了满足这些要求,一个路由算法必须满足几个关键目标:
- 路径的选择 :算法需要能够从多个可能的路径中选择到达目的地的最佳路径。
- 快速收敛 :在网络拓扑发生变化时,算法应迅速适应这些变化,以避免数据包丢失。
- 资源的优化利用 :路由算法应有效利用网络资源,例如带宽和处理能力,以避免拥堵。
- 公平性和效率 :算法应公平地处理不同的数据流,同时确保整体网络效率。
- 可扩展性 :随着网络规模的扩展,算法应能持续高效地工作。
5.1.2 Dijkstra算法在网络路由中的作用
Dijkstra算法在网络路由中的作用主要体现在它提供了一种计算单源最短路径的方法。它在网络拓扑结构保持稳定时,可以快速找到从单一源点到网络中所有其他节点的最短路径。这意味着,对于路由决策来说,Dijkstra算法可以确保数据包在网络中以最小的代价传输。在实际的网络环境中,Dijkstra算法通常作为内部使用的路由协议(例如OSPF)的一部分。
5.2 实际应用案例分析
5.2.1 在因特网中的应用
在因特网中,Dijkstra算法被集成在各种路由协议中,例如开放最短路径优先(OSPF)协议。OSPF使用Dijkstra算法来计算网络中的最短路径树,这是进行路由决策的基础。
- 网络拓扑的构建 :路由器定期发送链路状态更新消息到网络中的其他路由器,构建整个网络的拓扑视图。
- 链路权重的计算 :链路权重可以基于多种因素,如带宽、延迟、可靠性或费用。
- 最短路径树的生成 :每个路由器使用Dijkstra算法,以自己为起点计算最短路径树,从而知道到网络中每个节点的最小代价路径。
5.2.2 实际网络环境下的优化策略
在实际网络环境中使用Dijkstra算法时,必须考虑到各种优化策略,以应对网络的动态变化和复杂性。
- 负载均衡 :多个路径可能具有相同的最短距离,路由器可将流量分配到这些路径上,以平衡网络负载。
- 路由信息的聚合 :大型网络可以聚合路由信息来减少路由表的大小,这有助于降低内存的消耗并加速路由决策。
- QoS支持 :在选择路径时考虑服务质量(QoS)参数,如确保延迟敏感的应用(如VoIP)使用最短且延迟最小的路径。
- 缓存机制 :使用缓存存储最近计算的最短路径结果,当网络拓扑未发生显著变化时,可以直接使用缓存数据,节省计算时间。
在下一节中,我们将讨论Dijkstra算法在其他领域中的应用,例如地理信息系统(GIS)和社交网络分析,以及在任务调度优化中的应用。
6. Dijkstra算法在其他领域中的应用
Dijkstra算法作为图论中经典的最短路径算法,在多个领域中拥有广泛的应用,从地理信息系统(GIS)的路径规划到社交网络分析,再到任务调度优化,这一算法都能发挥作用。
6.1 地理信息系统中的应用
6.1.1 地理信息系统的基本概念
地理信息系统(GIS)是一门集计算机科学、地理学、测量学、地图学等多学科知识于一体的交叉学科。GIS用于捕获、存储、操作、分析和显示地理信息。它被广泛应用于土地管理、资源规划、环境监测和灾害预防等诸多领域。
6.1.2 Dijkstra算法在路径规划中的应用实例
在GIS中,路径规划是一个非常重要的功能,它能帮助用户找到从一点到另一点的最短路径。Dijkstra算法可以用来计算道路网络中两点之间的最短距离。例如,使用Dijkstra算法可以为物流配送中心规划出最优配送路线,减少行驶距离和时间,提高效率。
一个简单的应用实例是在城市导航系统中,算法可以计算出从用户当前位置到目的地的最短路径,考虑实时交通情况,避开拥堵路段,从而为用户提供最优的导航路线。
6.2 社交网络分析应用
6.2.1 社交网络的特点和分析需求
社交网络,如Facebook、Twitter等,包含了大量的用户以及他们之间的连接关系。这类网络的特点是图结构复杂、节点众多且动态变化。社交网络分析通常需要识别重要节点、连接关系、社区划分等。
6.2.2 Dijkstra算法在社交网络分析中的角色
在社交网络分析中,Dijkstra算法可以用来计算网络中任意两个用户之间的最短路径,这有助于理解用户之间的社交关系紧密程度。例如,可以利用这一算法来找到朋友关系链中任意两个人之间的最短朋友路径。
此外,Dijkstra算法还可以被用于寻找关键节点(如具有影响力的个体),算法能够辅助社交网络平台增强推荐系统、优化用户之间的互动。
6.3 任务调度中的应用
6.3.1 任务调度问题的描述
任务调度问题在工业、计算机科学等领域广泛存在,它关注的是如何有效地安排多个任务的执行顺序,使得在满足各种约束条件的情况下达到某些性能指标的最优化。
6.3.2 Dijkstra算法在任务调度优化中的应用
在任务调度领域,Dijkstra算法可以用来寻找在时间或资源成本上最优的任务执行顺序。例如,在软件项目管理中,通过Dijkstra算法可以安排任务的优先级,从而最小化项目完成的时间或成本。
Dijkstra算法可以处理带有先后关系和时间要求的任务调度问题,通过为每项任务计算一个“到达时间”,以此来决定任务的执行顺序,从而优化整体任务流程。
# 示例代码:使用Dijkstra算法解决任务调度问题
# 这个例子简单说明Dijkstra算法如何应用于任务调度中计算任务的到达时间
import heapq
def dijkstra_edges(distance, n):
for k in range(n):
for i in range(n):
for j in range(n):
if i != j and distance[i][j] > distance[i][k] + distance[k][j]:
distance[i][j] = distance[i][k] + distance[k][j]
return distance
# 距离矩阵,n为节点数量,distance[i][j]表示节点i到节点j的距离
n = 5
distance = [[float("inf")] * n for _ in range(n)]
for i in range(n):
distance[i][i] = 0
# 假设某些节点间的距离
distance[0][1] = 10
distance[0][2] = 3
distance[1][3] = 1
distance[1][4] = 2
distance[2][4] = 4
distance[3][4] = 2
# 执行Dijkstra算法
dijkstra_edges(distance, n)
# 输出最终的距离矩阵
for row in distance:
print(row)
代码中的距离矩阵代表了任务之间的依赖关系和成本,通过Dijkstra算法的迭代计算,最终得到所有任务之间的最短路径,可以用于确定任务的执行顺序,从而在任务调度中起到关键作用。
通过上述分析可见,Dijkstra算法不局限于计算机网络,它在地理信息系统、社交网络分析和任务调度等领域都有广泛的应用前景。随着算法的深入研究和优化,其适用领域和性能将进一步提升。
简介:Dijkstra算法是一种用于寻找加权有向图中两点间最短路径的经典算法。它利用贪心策略,通过维护一个优先队列来逐步确定节点的最短路径。算法广泛应用于路径规划、网络路由优化和交通导航等领域。本文将介绍Dijkstra算法的原理、优缺点以及如何应用于实际场景,同时也将探讨其在不同领域中的扩展应用。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 8
8 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)