四十二、SPSS方差分析,相关分析和回归分析
@Author : By Runsen@Date:2020/5/14在2020年一月初,也是我大三上的寒假,我开始写书,为什么呢?因为化工原理和化工热力学挂了,我需要重拾自己的自信。对于一个大学三年,每天往死里干的人,竟然挂了两科。虽然,我化工专业已经陷入了绝境,大学我主要学习日语,Python,Java和一系列数据分析软件。所以本专栏数据分析将使用Excel,Powerbi,Python,R,S
@Author : By Runsen
@Date:2020/5/14
在2020年一月初,也是我大三上的寒假,我开始写书,为什么呢?因为化工原理和化工热力学挂了,我需要重拾自己的自信。
对于一个大学三年,每天往死里干的人,竟然挂了两科。
虽然,我化工专业已经陷入了绝境,大学我主要学习日语,Python,Java和一系列数据分析软件。
所以本专栏数据分析将使用Excel,Powerbi,Python,R,Sql,SPSS,stata以及Tableau,后面还会补充BI。
第五章应该是二月份上完成的。
文章目录
5.9 方差分析
5.9.1 单因素多元方差分析
单因素指有一个自变量,为二分类或多分类变量。多元指因变量有2个或以上,为连续变量,而且因变量相互独立,呈现多元正态分布且其之间没有多重共线性。单因素多元方差分析是指研究一个自变量和两个或两个以上因变量的相互关系的一组统计理论和方法。
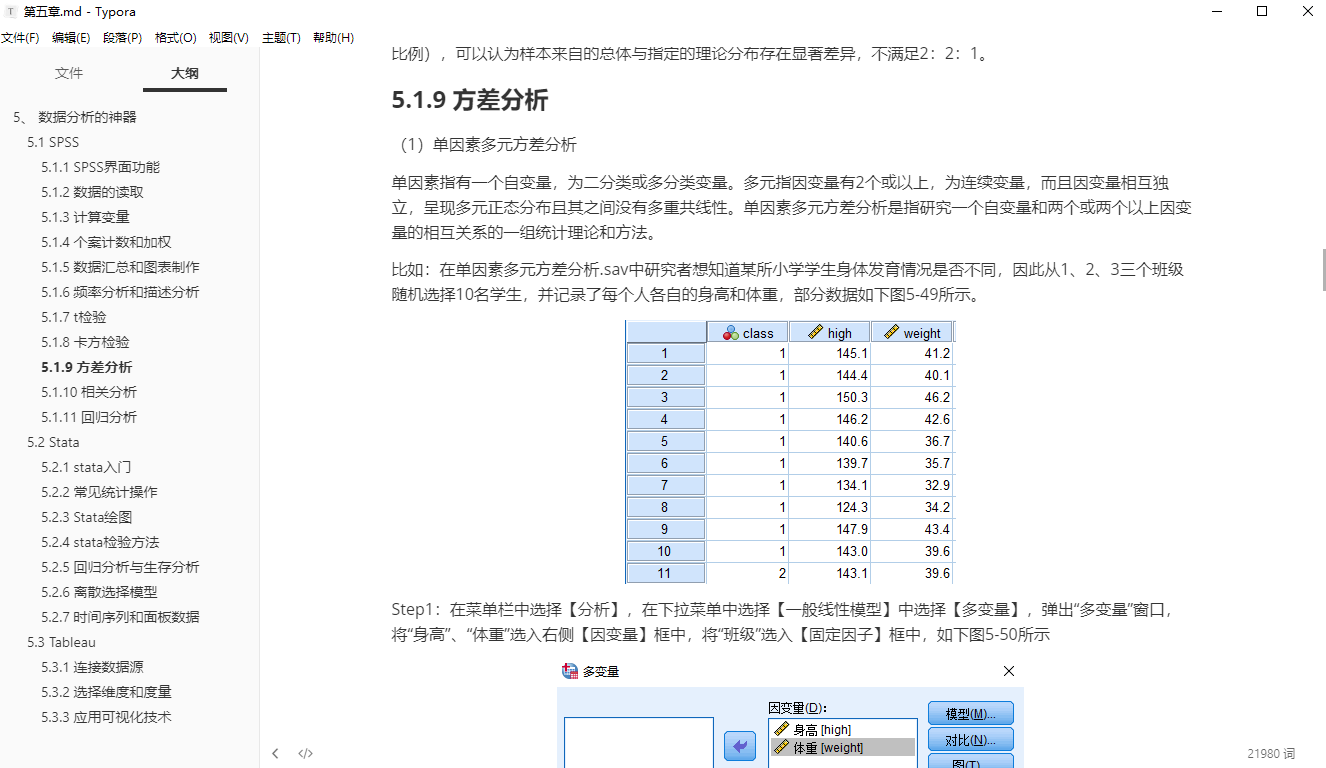
比如:在单因素多元方差分析.sav中研究者想知道某所小学学生身体发育情况是否不同,因此从1、2、3三个班级随机选择10名学生,并记录了每个人各自的身高和体重,部分数据如下图5-49所示。
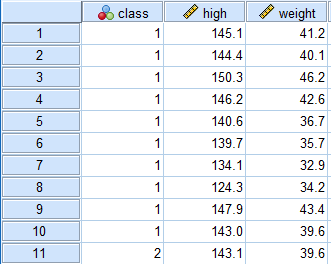
Step1:在菜单栏中选择【分析】,在下拉菜单中选择【一般线性模型】中选择【多变量】,弹出“多变量”窗口,将“身高”、“体重”选入右侧【因变量】框中,将“班级”选入【固定因子】框中,如下图5-50所示
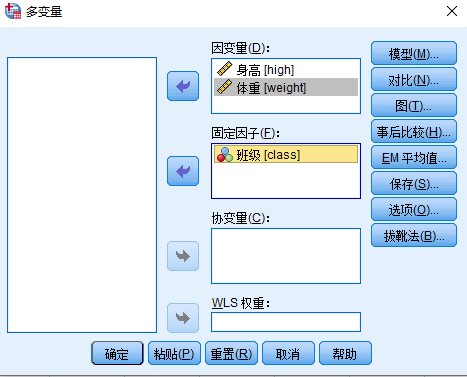
Step2:点击【事后比较】在【多变量:实测平均值的事后比较】窗口中,将“class”选入右侧【事后检验】中,并选中【图基】,点击【继续】,如下图5-51所示。
最后确定,查看分析结果,结果如下图5-52和5-53所示
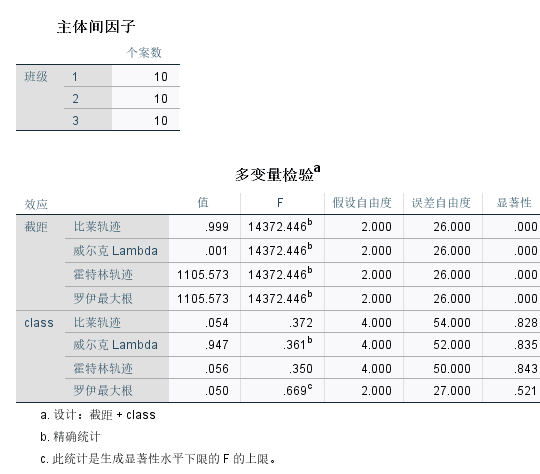
我们可以看到最常用的是威尔克Lambda,该检验量 P P P=0.01<0.05时,自变量的组间差异有统计学意义。
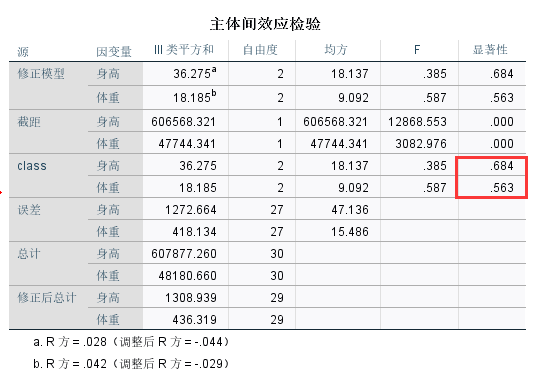
上图5-53中,我们可以看到身高和体重所对应的P值均大于0.05,因此各班级之间学生的身高体重水平没有差异。即无统计学意义。
5.9.2 两因素多元方差分析
两因素多元方差分析,用于研究多个因变量是否受两个自变量(也称为因素)的影响,它检验两个因素取值水平的不同组合之间,因变量的均值是否存在显著的差异。
比如:不同的年级和班别对语文成绩和数学成绩是否有显著影响?
在两因素多元方差分析.sav中存在六个年级的四个班级的语文,数学成绩,共有72个数据,部分数据如下图5-54所示。
两因素多元方差分析.sav变量视图中,年级1~6分布代表一年级,二年级,三年级,四年级,五年级,六年级。班级1~4分布代表一班,二班,三班和四班,如下图5-55所示

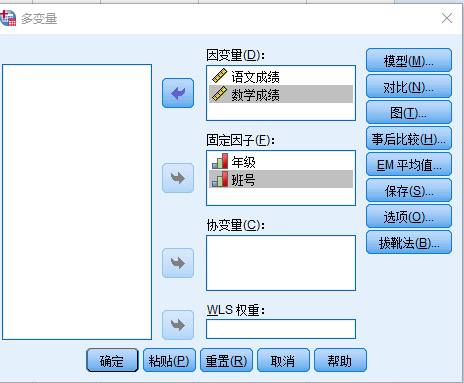
Step1:在菜单栏中选择【分析】,在下拉菜单中选择【一般线性模型】,右侧弹出子菜单中选择【多变量】,弹出“多变量”窗口,将“语文成绩”、“数学成绩”选入右侧【因变量】框中,将“年级”和“班号”选入【固定因子】框中,如下图5-56所示
最后确定,查看分析结果,结果如下图5-57和5-58所示
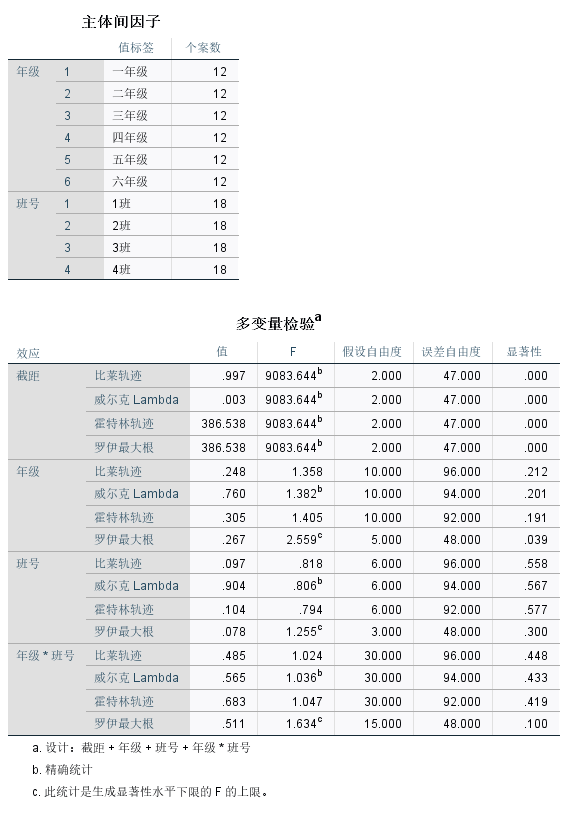
主体间因子表格给出了样本个数统计。多变量检验表格可以看出显著性检验的Sig值都大于0.01,推断年级效应、班号效应和年级*班号效应对模型的影响是不显著的。
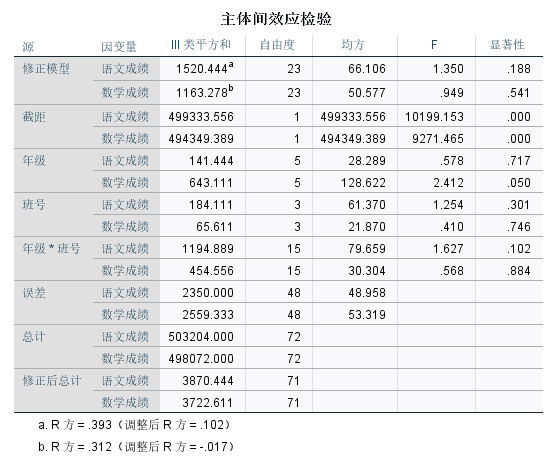
从主体间效应的检验表格显示的是各效应检验的输出结果。从各项显著性检验的Sig值可以看出“年级”、“班号”对语文和数学成绩的影响并不显著。
5.10 相关分析
5.10.1 Pearson相关
P e a r s o n Pearson Pearson相关系数,分析常见的是线性相关,也就是描述当一个连续变量发生变化时,另一个连续变量也相应地呈线性变,用来衡量两个数据集合是否在一条线上面,衡量定距变量间的线性关系
两个变量之间的 P e a r s o n Pearson Pearson相关系数定义为两个变量之间的协方差和标准差的商
r = ρ X , Y = c o v ( X , Y ) σ X σ Y = E ∣ ( X − μ X ) ( Y − μ Y ) ∣ σ X σ Y r=\rho_X,_Y=\frac{cov(X,Y)}{\sigma_X\sigma_Y}=\frac{E\left|(X-\mu_X)(Y-\mu_Y)\right |}{\sigma_X\sigma_Y} r=ρX,Y=σXσYcov(X,Y)=σXσYE∣(X−μX)(Y−μY)∣
P e a r s o n Pearson Pearson相关系数的取值范围,如下表所示
| |r|取值范围 | 相关系程度 |
|---|---|
| 0<|r|<0.3 | 低相关 |
| 0.3<=|r|<0.8 | 中相关 |
| 0.8<=|r|<=1 | 高相关 |
某研究者猜测,45岁至65岁健康男性中,久坐时间较长者,血液中的胆固醇浓度要高一些。现在探讨胆固醇浓度(mmol/L)与久坐时间((mins/day))是否有关。在Pearson相关.sav收集了研究对象每天久坐时间(变量time)和胆固醇浓度(变量cholesterol),部分数据如图5-59所示。
Pearson要求两个变量之间存在线性关系。本研究要求久坐时间(time)和胆固醇浓度(cholesterol)之间存在线性关系。要确定是否存在线性关系,我们可以查看两个变量的散点图。如果散点图大致呈一条直线,说明有线性关系。但是,如果不是一条直线则没有线性关系。
Step01:在菜单栏中选择【图形】,在下拉菜单中选择【旧对话框】,右侧弹出子菜单中选择【散点图/点图】,选择【简单散点图】,单击【定义】按钮,出现的【简单散点图】窗口,如下图5-60所示
Step 02:在弹出的【简单散点图】窗口,将变量“cholesterol”(胆固醇浓度)移至右侧的Y轴,将变量“time”移至右侧的X轴中,完成后,单击【确定】按钮,散点图如下图5-61所示
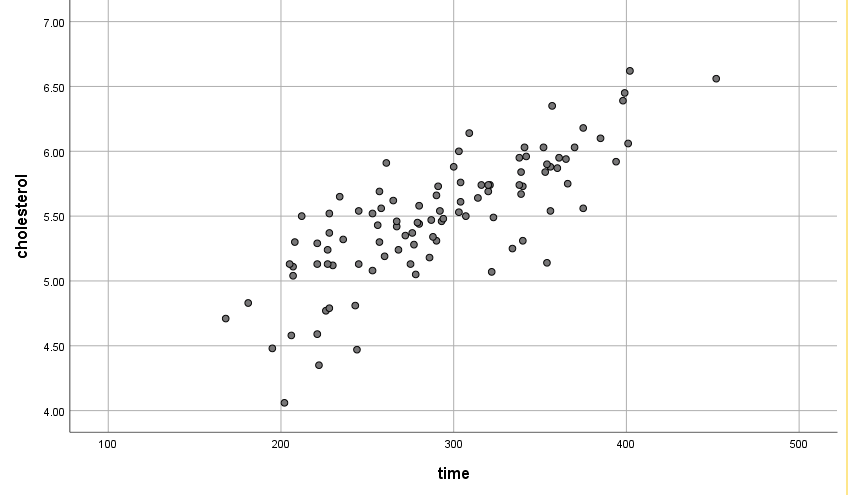
散点图大致呈一条直线,说明存在线性关系。那么这两个变量之间的相关程度到底是多少,高还是低呢?这就是我们接下来要说得相关性分析操作了。
Step03:在菜单栏中选择【分析】,在下拉菜单中选择【相关】,右侧弹出子菜单中选择【双变量】,出现【双变量相关性】窗口将“time“和”cholesterol”两个变量移至右侧的【变量】框中,如下图5-62所示
点击【确定】按钮,就可得到相关分析的结果,如下图5-63所示
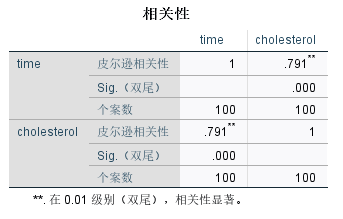
从图5-63中,我们就可以清楚地看到“宣传费用”与“销售金额”之间是具有很高的相关性的,皮尔逊相关系数达到0.791,也就是中相关程度,显著性 P = 0.000 < 0.05 P=0.000 <0.05 P=0.000<0.05, 具有极其显著的统计效果。
5.10.2 Spearman等级和Kendall W等级相关
等级相关,也称为秩相关,属于非参数统计方法,但对原变量的分布不作要求。适用于不服从正态分布的,还有总体分布未知和原始数据用等级表示数据。
S p e a r m a n Spearman Spearman等级相关系数,又称斯皮尔曼相关系数,被定义成等级变量之间的皮尔逊相关系数,适用于定序变量与定序变量之间的相关系数,计算公式如下:
p = 1 − 6 Σ d i 2 n ( n 2 − 1 ) p=1-\frac{6\Sigma d_i^2}{n(n^2-1)} p=1−n(n2−1)6Σdi2
其中, d i = ( x i − y i ) di=(x_i-y_i) di=(xi−yi),$ x_i 和 和 和y_i 分 别 是 两 个 变 量 按 大 小 排 序 的 秩 , 分别是两个变量按大小排序的秩, 分别是两个变量按大小排序的秩,n$是样本的容量。
首先对两个变量(X, Y)的数据进行排序,然后记下排序以后的位置 ( X ’ , Y ’ ) , ( X ’ , Y ’ ) (X’, Y’),(X’, Y’) (X’,Y’),(X’,Y’)的值就称为秩次,秩次的差值就是上面公式中的 d i di di, n n n就是变量中数据的个数,最后带入公式就可求解结果。
比如,有5个人的经过某一刺激,听觉、视觉反应时(单位:毫秒),数据如下表。根据数据能否推断出视觉、听觉反应时是否具有一致性?
| 编号(人) | 听觉反应时(毫秒) | 视觉反应时(毫秒) | X X X | Y Y Y | d | d 2 d^2 d2 | X Y XY XY |
|---|---|---|---|---|---|---|---|
| 1 | 170 | 180 | 3 | 4 | -1 | 1 | 12 |
| 2 | 150 | 165 | 1 | 1 | 0 | 0 | 1 |
| 3 | 210 | 190 | 5 | 5 | 0 | 0 | 25 |
| 4 | 180 | 168 | 4 | 2 | 2 | 4 | 8 |
| 5 | 160 | 172 | 2 | 3 | -1 | 1 | 6 |
| ∑ ∑ ∑ | 870 | 875 | 15 | 15 | 2 | 6 | 52 |
其中, X X X为听觉反应时间按大小排序, Y Y Y为视觉反应时间按大小排序, d = X − Y d=X-Y d=X−Y。将 n = 5 n=5 n=5, ∑ d 2 = 6 ∑d^2=6 ∑d2=6 带入公式中,得到 ρ = 0.7 ρ=0.7 ρ=0.7。这 5 5 5人的视听反应时等级相关系数为 0.7 0.7 0.7,属于高度相关。
K e n d a l l W Kendall W KendallW 相关系数称肯德尔和谐系数,肯德尔和谐系数是计算多个等级变量相关程度的一种相关量。
前述的 s p e a r m a n spearman spearman等级相关讨论的是两个等级变量的相关程度,用于评价时只适用于两个评分者评价 N N N个人或 N N N件作品,或同一个人先后两次评价 N N N个人或 N N N件作品,而 k a n d a l l kandall kandall和谐系数则适用于数据是多列相关的等级,适用于 k k k个评分者评 N N N个对象,也可以是同一个人先后 k k k次评 N N N个对象。通过求得 k a n d a l l kandall kandall和谐系数,可以较为客观地选择好的作品或好的评分者。
K a n d a l l W Kandall W KandallW相关性检验,即肯德尔和谐系数,常用 W W W表示,其基本假设为: H 0 H0 H0:多个等级变量间不存在一致关系或和谐关系。 H 1 H1 H1:多个等级变量间存在一致关系或和谐关系。
K e n d a l l W Kendall W KendallW 相关系数 W W W计算公式如下:
S = ∑ i = 1 n ( R i − R i ‾ ) 2 = ∑ i = 1 n R i 2 − ( ∑ i = 1 n R i ) 2 n S=\sum_{i=1}^{n}({R_i-\overline{R_i}})^2=\sum_{i=1}^{n}R_i^2-\frac{(\sum_{i=1}^{n}R_i)^2}{n} S=i=1∑n(Ri−Ri)2=i=1∑nRi2−n(∑i=1nRi)2
W = 12 S K 2 ( N 3 − N ) − K ∑ i = 1 K T i W=\frac{12S}{K^2(N^3-N)-K \sum_{i=1}^{K}{T_i}} W=K2(N3−N)−K∑i=1KTi12S
T i = ∑ i = 1 m i ( n i j 3 − n i j ) / 12 T_i=\sum_{i=1}^{m_i}(n_{ij}^3-n_{ij})/12 Ti=i=1∑mi(nij3−nij)/12
其中 , S S S等于每个被评对象所评等级之和 R i R_i Ri与所有这些和的平均数的 R i ‾ \overline{R_i} Ri离差平方和。 N N N为被评的对象总数, K K K为评分者人数或评分所依据的标准数。 m i m_i mi表示第 i i i个评价者的评定结果中有重复等级的个数, n i j n_{ij} nij第 i i i个评价者的评定结果中第 j j j个重复等级的相同等级数。对于评定结果无相同等级的评价者, T i = 0 Ti = 0 Ti=0,因此只须对评定结果有相同等级的评价者计算 T i Ti Ti。
比如, 某比赛,6位评选员对6篇作品评定得奖等级,结果如下表所示,试计算6位评选员评定结果的 k a n d a l l W kandall W kandallW和谐系数。
| 评分老师编号 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| A | 3 | 1 | 2 | 5 | 4 | 6 |
| B | 2 | 1 | 3 | 4 | 5 | 6 |
| C | 3 | 2 | 1 | 5 | 4 | 6 |
| D | 4 | 1 | 2 | 6 | 3 | 5 |
| E | 3 | 1 | 2 | 6 | 4 | 5 |
| F | 4 | 2 | 1 | 5 | 3 | 6 |
| R i R_i Ri | 19 | 8 | 11 | 31 | 23 | 34 |
| R i 2 R_i^2 Ri2 | 361 | 64 | 121 | 96 | 529 | 1156 |
由于每个评分老师对6篇作品的评定都无相同的等级,由表中数据得:
S = ∑ i = 1 6 R i 2 − ( Σ i = 1 6 R i ) 2 6 = 3192 − 12 6 2 6 = 546 S=\sum_{i=1}^{6}R_i^2-\frac{(\Sigma_{i=1}^{6}R_i)^2}{6}=3192-\frac{126^2}{6}=546 S=i=1∑6Ri2−6(Σi=16Ri)2=3192−61262=546
W = 12 S K 2 ( N 3 − N ) = 12 ∗ 546 6 2 ( 6 3 − 6 ) = 0.87 W=\frac{12S}{K^2(N^3-N)}=\frac{12*546}{6^2(6^3-6)}=0.87 W=K2(N3−N)12S=62(63−6)12∗546=0.87
由W=0.87表明6位老师的评定结果有较大的一致性。
在 P e a r s o n Pearson Pearson相关案例中,我们只需要在“双变量相关性”窗口,“相关系数”复选框中勾选“肯德尔“和”斯皮尔曼”,即可计算出 K e n d a l l W Kendall W KendallW等级和 S p e a r m a n Spearman Spearman等级相关,如下图5-64所示
点击【确定】按钮,就可得到相关分析的结果,如下图5-65所示
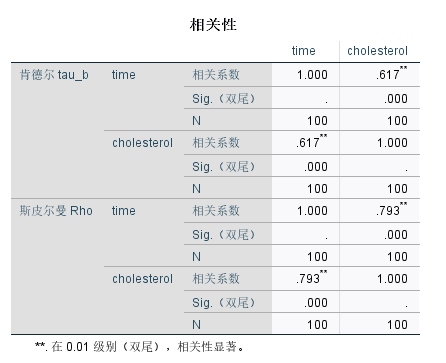
从5-65图的结果可知,肯德尔系数为0.617,斯皮尔曼系数为0.793,都属于中相关
5.11 回归分析
5.11.1 简单线性回归分析
在统计学中,线性回归是利用称为线性回归方程的最小二乘函数对一个或多个自变量和因变量]之间关系进行建模的一种回归分析。
在 P e a r s o n Pearson Pearson相关案例中,在菜单栏中选择【分析】,在下拉菜单中选择【回归】,右侧弹出子菜单中选择【散线性】,弹出线性回归窗口,将“cholesterol“变量移至右侧的【因变量】框中,”time”变量移至右侧的【自变量】框选择因变量和自变量,如下图5-66所示
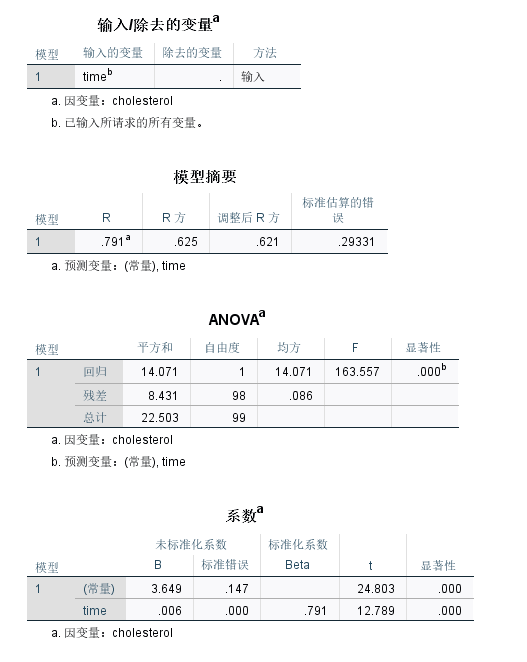
点击【确定】按钮,就可得到线性回归分析,如下图5-67所示
在第二个表格展示了自变量对因变量的解释程度,即模型拟合程度。
第一个指标R是回归的多重相关系数。如果简单线性回归中只有一个自变量时,R值与因变量和自变量的 P e a r s o n Pearson Pearson相关系数相同, R = 0.791 R=0.791 R=0.791,提示胆固醇浓度与久坐时间中等相关。但实际上,简单线性回归并不关注R值。
第二个指标 R 2 = 0.625 R^2=0.625 R2=0.625,提示自变量(久坐时间)可以解释62.5%的因变量(胆固醇浓度)变异。
第三个指标是 a d j u s t e d R = 0.622 adjustedR=0.622 adjustedR=0.622,提示中等影响。调整R方和R方类似,不同的是,调整R方同时考虑了样本量(n)和回归中自变量的个数(k)的影响,这使得调整R方永远小于R方, a d j u s t e d R 2 = 0.622 < R 2 = 0.625 adjusted R^2=0.622<R^2=0.625 adjustedR2=0.622<R2=0.625,校正了 R R R对于总体自变量对因变量变异解释程度的夸大作用。
在第四个表格展示了回归系数的解释程度,回归方程可以表示为: c h o l e s t e r o l = b 0 + ( b 1 × t i m e ) cholesterol= b0+(b1×time) cholesterol=b0+(b1×time) 。其中, b 0 b0 b0是截距, b 1 b1 b1是斜率。在SPSS中,截距 b 0 = 3.649 b0=3.649 b0=3.649,斜率 b 1 = 0.006 b1=0.006 b1=0.006。得到回归方程 c h o l e s t e r o l = 3.649 + ( 0.006 × t i m e ) cholesterol= 3.649+(0.006×time) cholesterol=3.649+(0.006×time)
SPSS还要很多强大的分析方法和非参数检验方法,如二分类Logistic回归,多重线性回归,聚类分析,二项分布检验,Mann-Whitney U检验(两独立样本)和Kruskal-Wallis H检验(多个独立样本)
学习SPSS的重点并不在于软件本身,而是相关的统计学知识,也就是学会怎样去分析“输入数据后,软件给你呈现的结果”。
数据集
数据集下载:练习文件都在码云上:
https://gitee.com/MaoliRUNsen/data_analysis_series.git
在SPSSl文件夹中


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)