【强化学习环境配置+github 无人机强化学习demo复现】
通过本【强化学习环境配置+github demo复现】,您应该能够从零到一入门强化学习啦,也完成无人机的强化学习demo复现。从而实现对外部世界进行感知,充分认识这个有机与无机的环境,科学地合理地进行创作和发挥效益,然后为人类社会发展贡献一点微薄之力。🤣🤣🤣我会持续更新对应专栏博客,非常期待你的三连!!!🎉🎉🎉如果鹏鹏有哪里说的不妥,还请大佬多多评论指教!!!👍👍👍下面有我的🐧
【强化学习环境配置+github demo复现】
1. N卡驱动安装
首先用系统管家查看电脑硬件信息,本次采用RTX 2080Ti 显卡配置环境,系统接入N卡官网地址:https://www.nvidia.cn/drivers/lookup/, 手动填写系统配置点击查找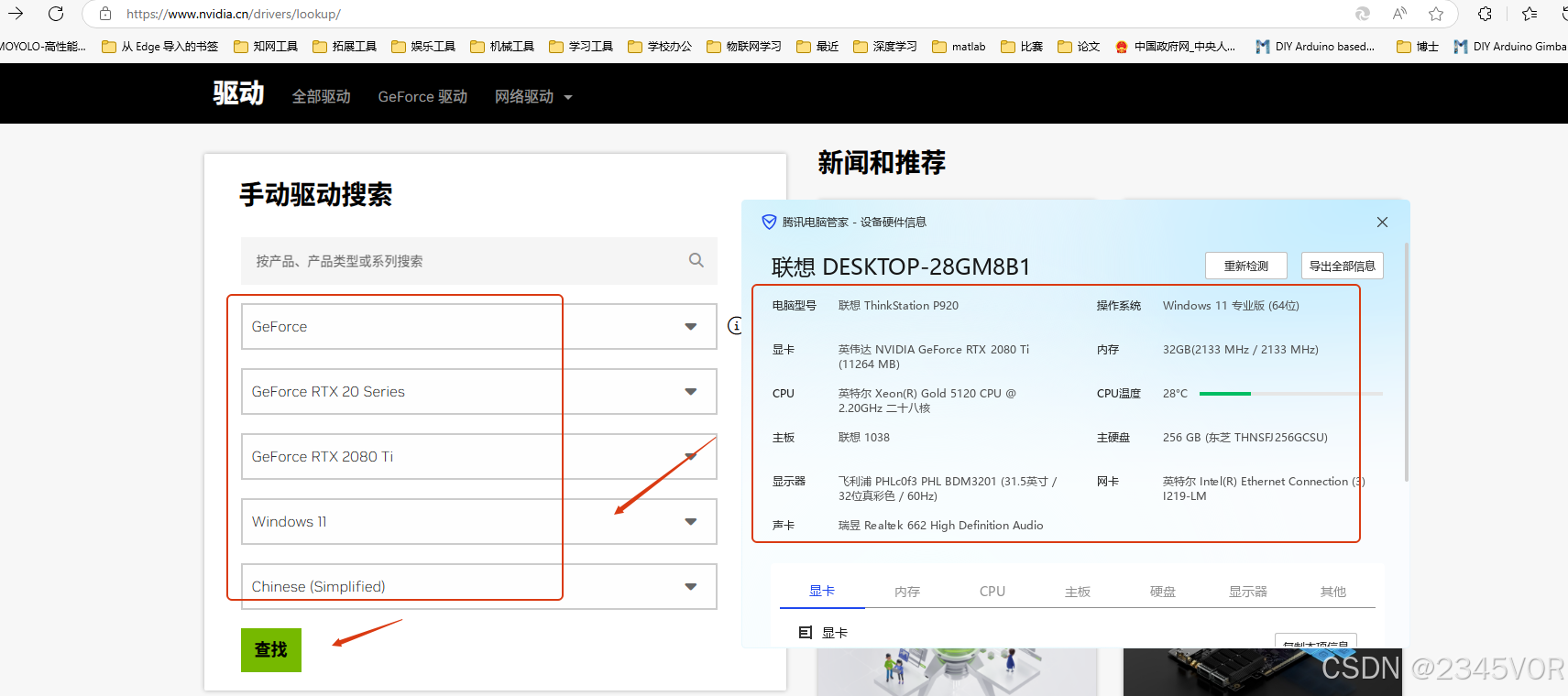
如果不玩游戏的朋友,推荐选择NVIDIA Studio驱动程序,点击查看按钮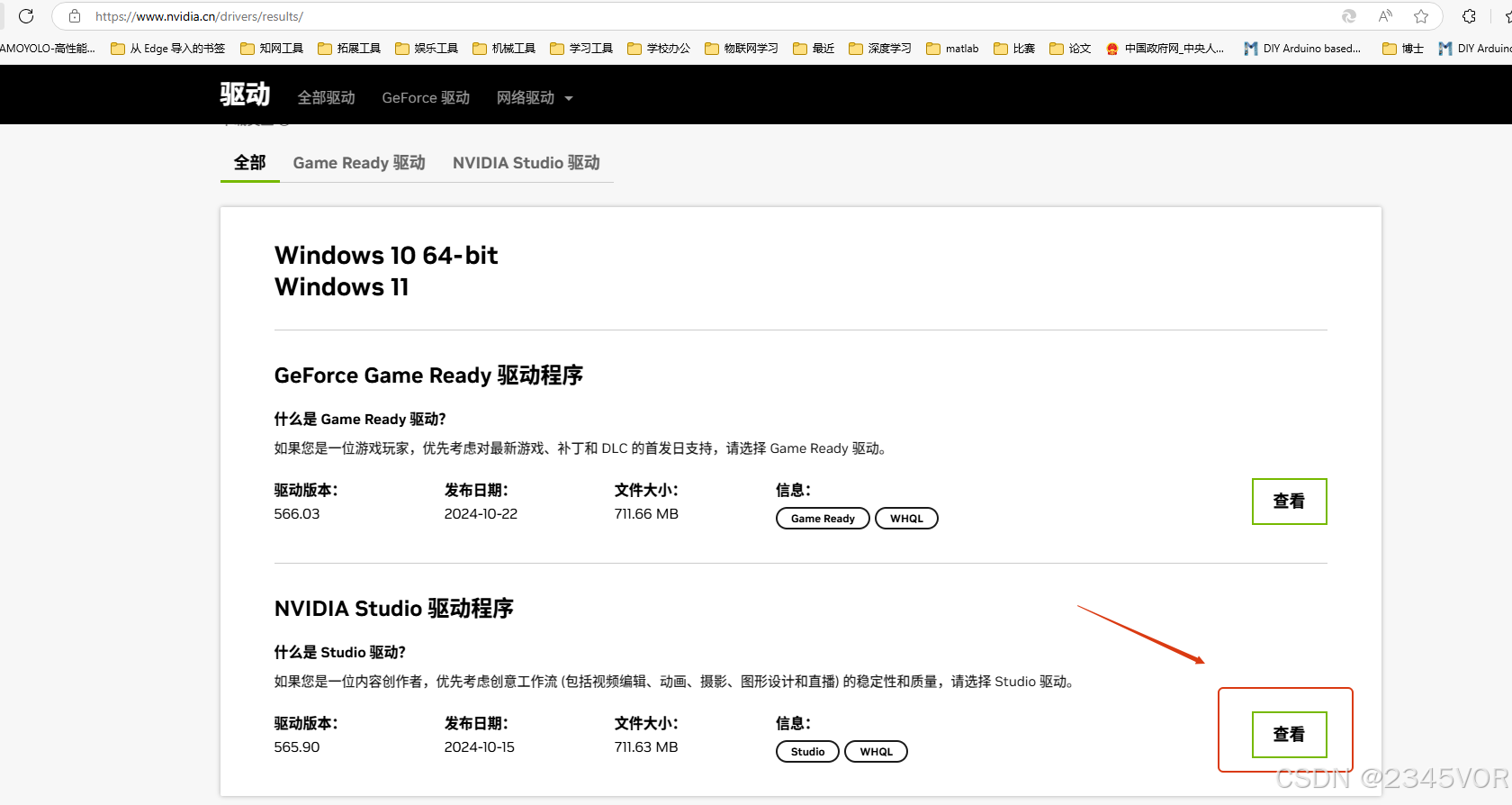
这里点击下载最新的驱动程序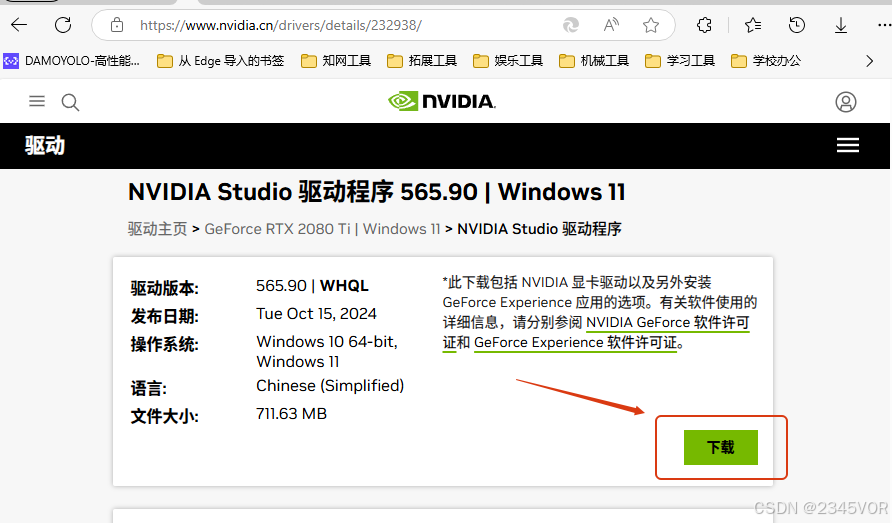
双击运行,选择安装位置
耐心等待安装过程

安装(更新)好了显卡驱动以后查看对应版本。我们按下win+R组合键,打开cmd命令窗口。输入如下的命令。
nvidia-smi
得到如下图的信息图,可以看到驱动的版本是565.90;最高支持的CUDA版本是12.7版本。得到显卡的最高支持的CUDA版本,我们就可以根据这个信息来安装环境了。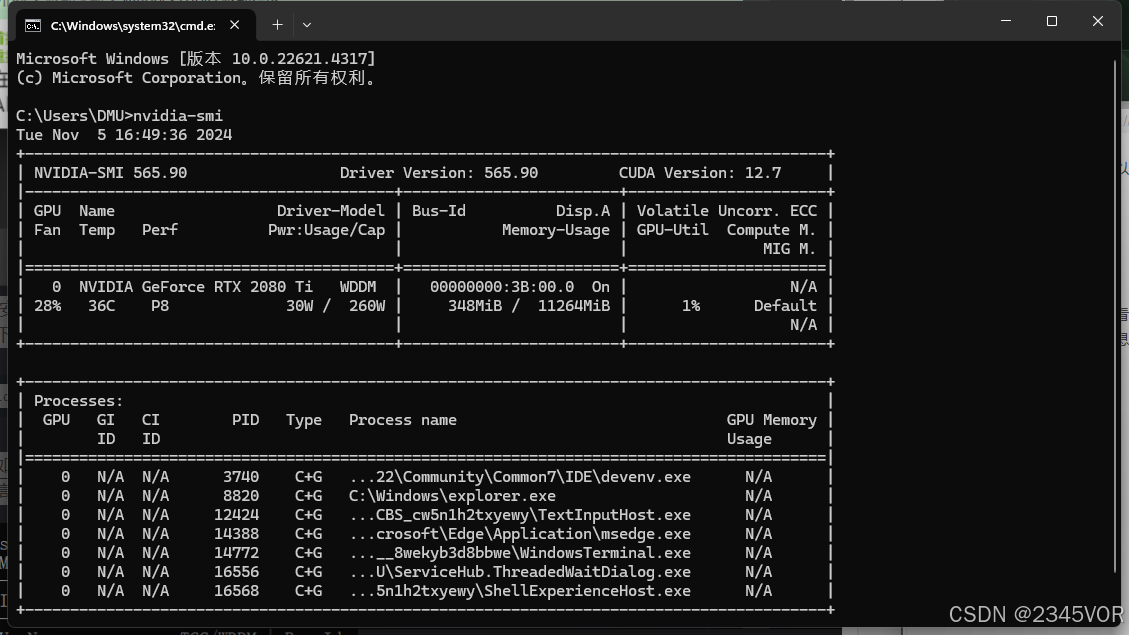
2. Anaconda 安装
打开网址:https://www.anaconda.com/download/success,现在是2024年11月,对应的anaconda版本是支持python3.12。如果想下载之前的版本,或者更低python版本的anaconda。大家可以根据自己空间大小选择anaconda或者miniconda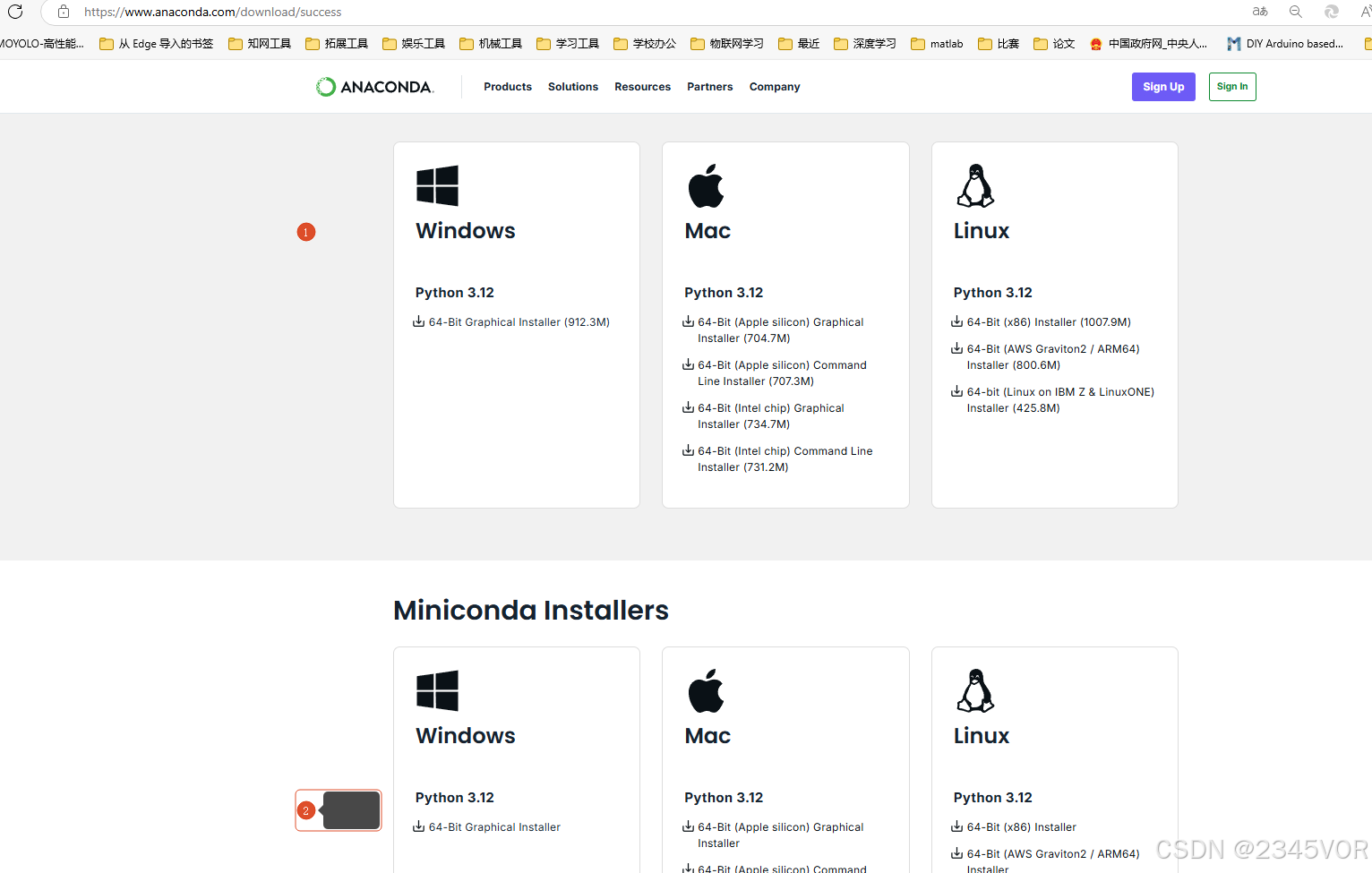
安装conda
以管理员身份运行软件,点击next
修改位置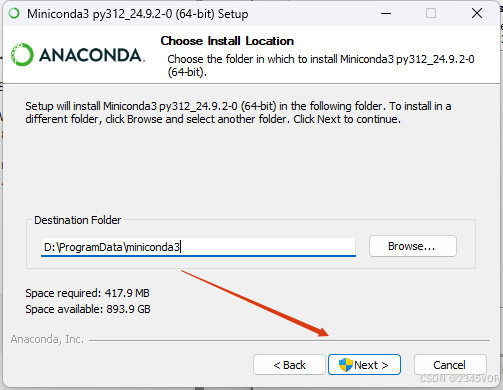
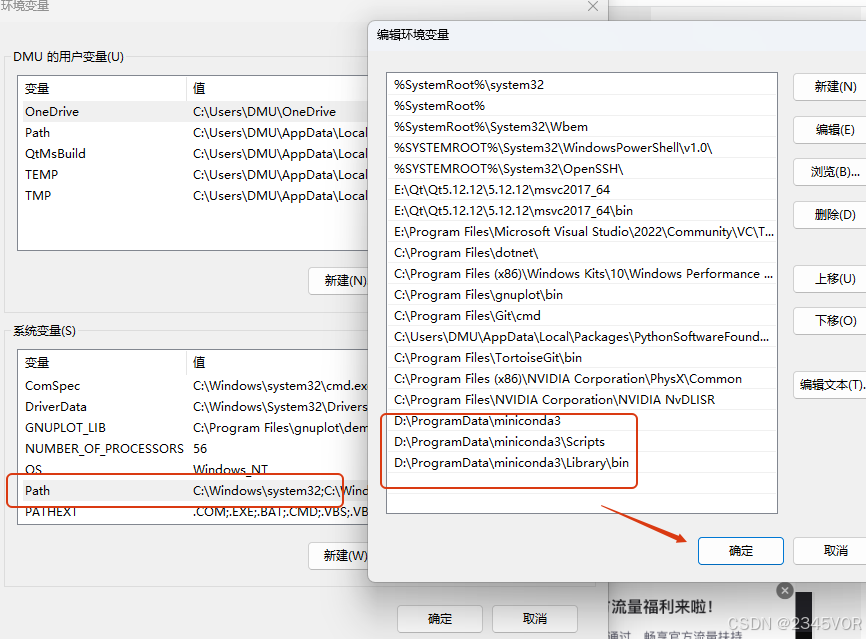
上面就是安装完成,可以检查环境变量,添加一下,方便后期编译器识别
注:根据Anaconda安装的位置修改(E:\Anaconda)部分
E:\Anaconda(Python需要)
E:\Anaconda\Scripts(conda自带脚本)
E:\Anaconda\Library\mingw-w64\bin(使用C with python的时候)
E:\Anaconda\Library\usr\bin
E:\Anaconda\Library\bin(jupyter notebook动态库)
3. Pytorch环境安装
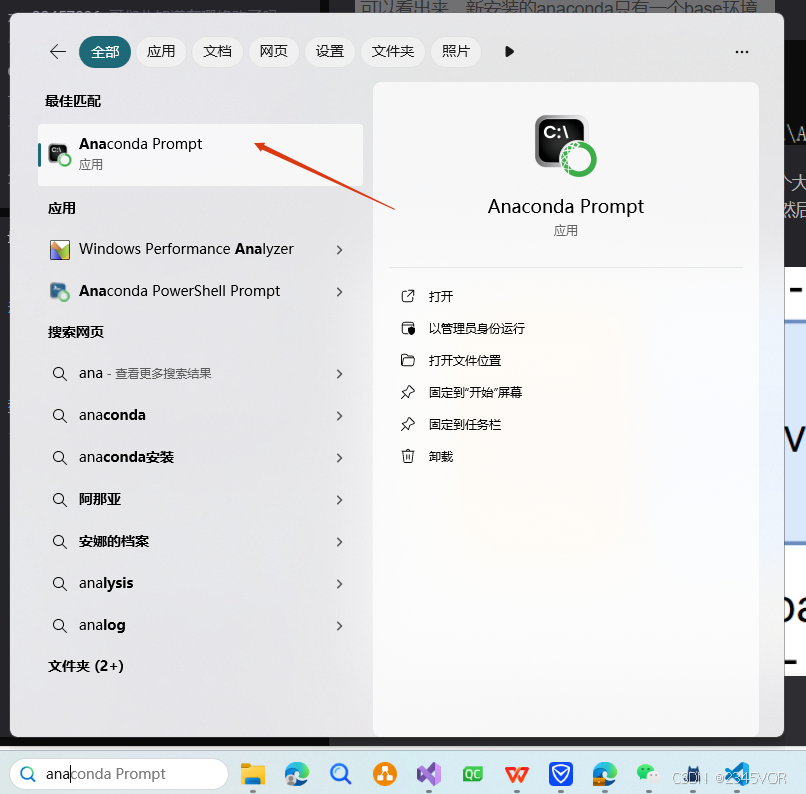
按下开始键(win键),点击如图中的图标。打开anaconda的终端Prompt。
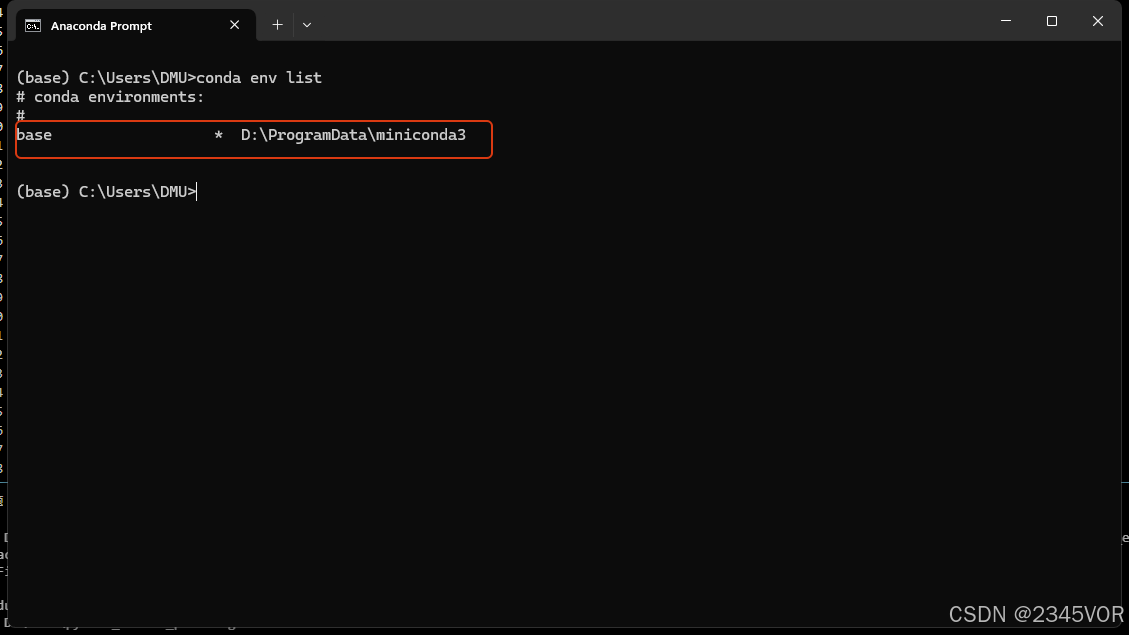
执行如下的指令查看有哪些环境
conda env list
可以看出来,新安装的anaconda只有一个base环境。
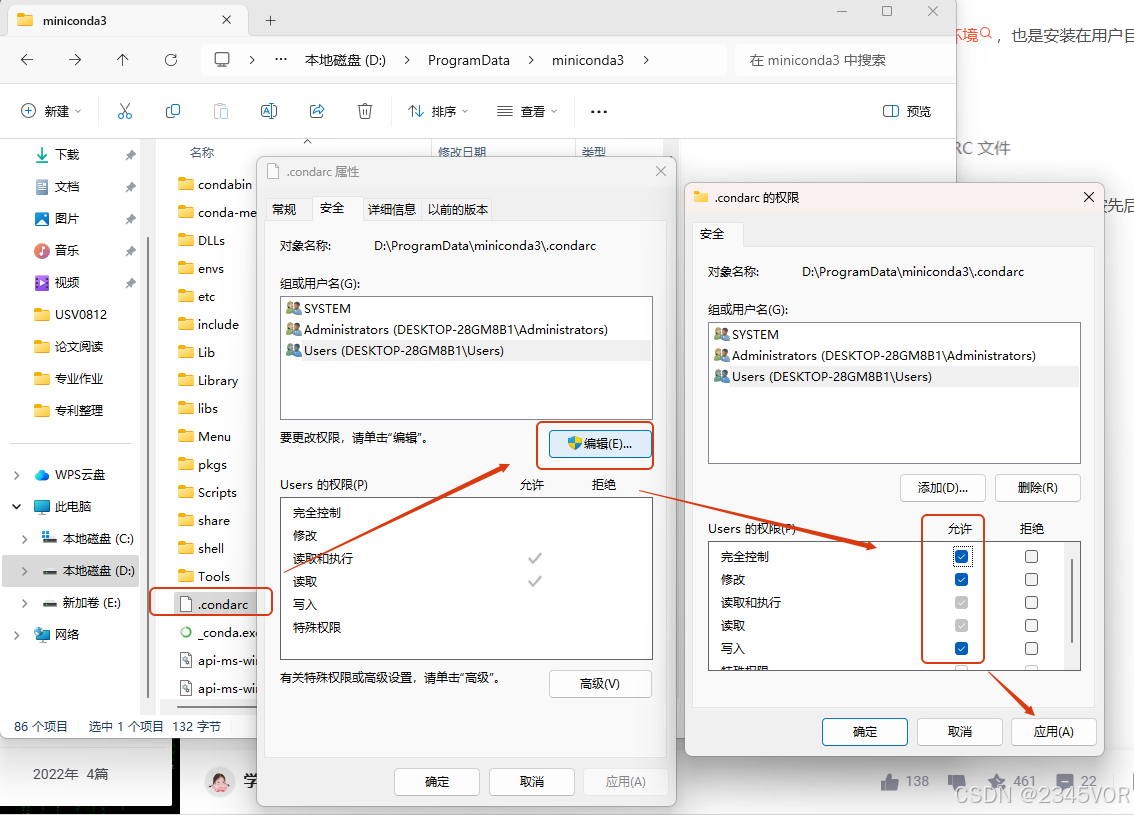
修改环境位置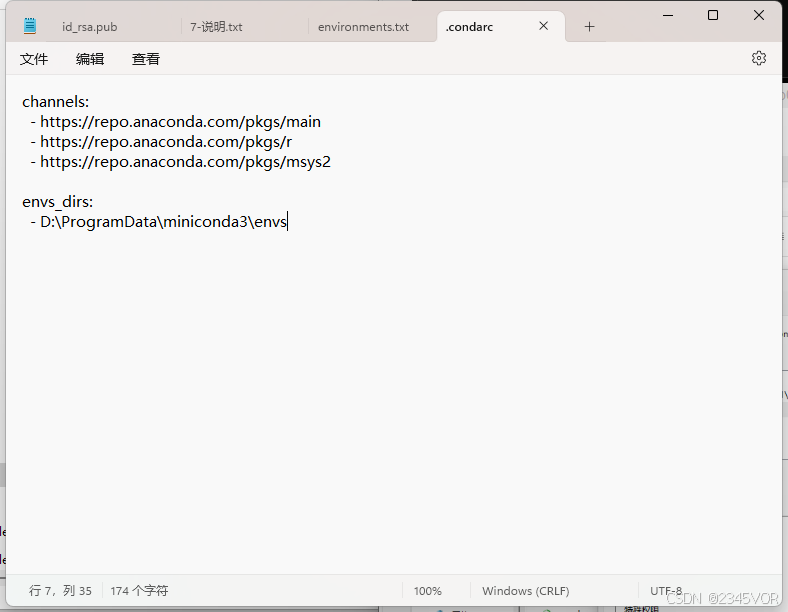
安装的文件夹也需要设置权限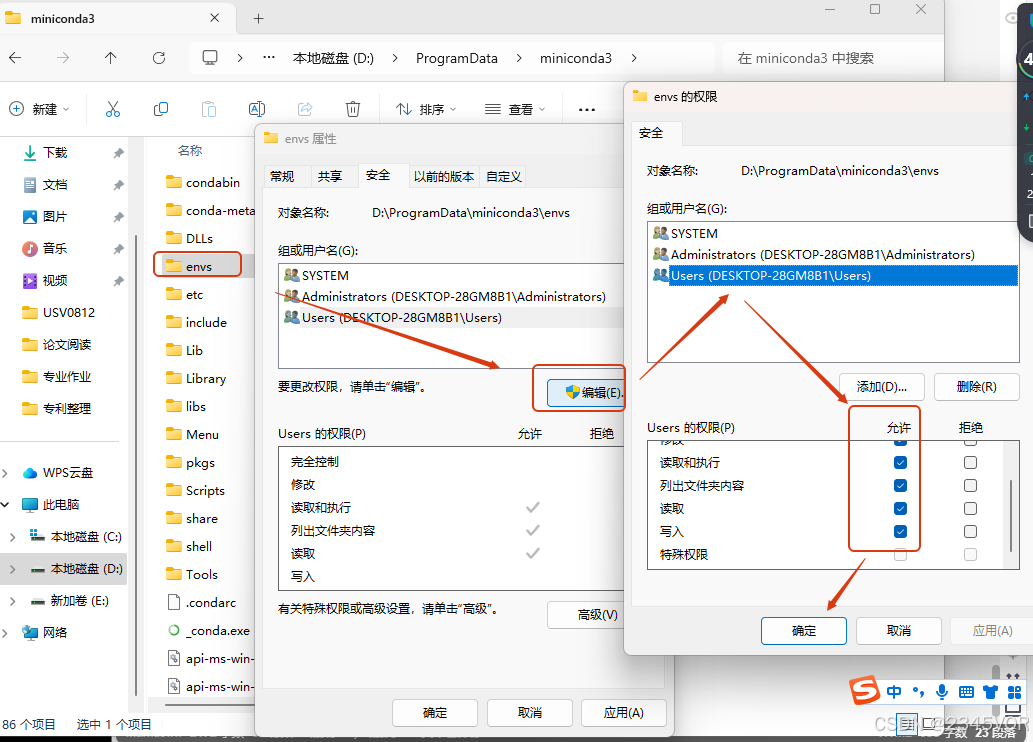
conda info
conda create -n rltorch python=3.10
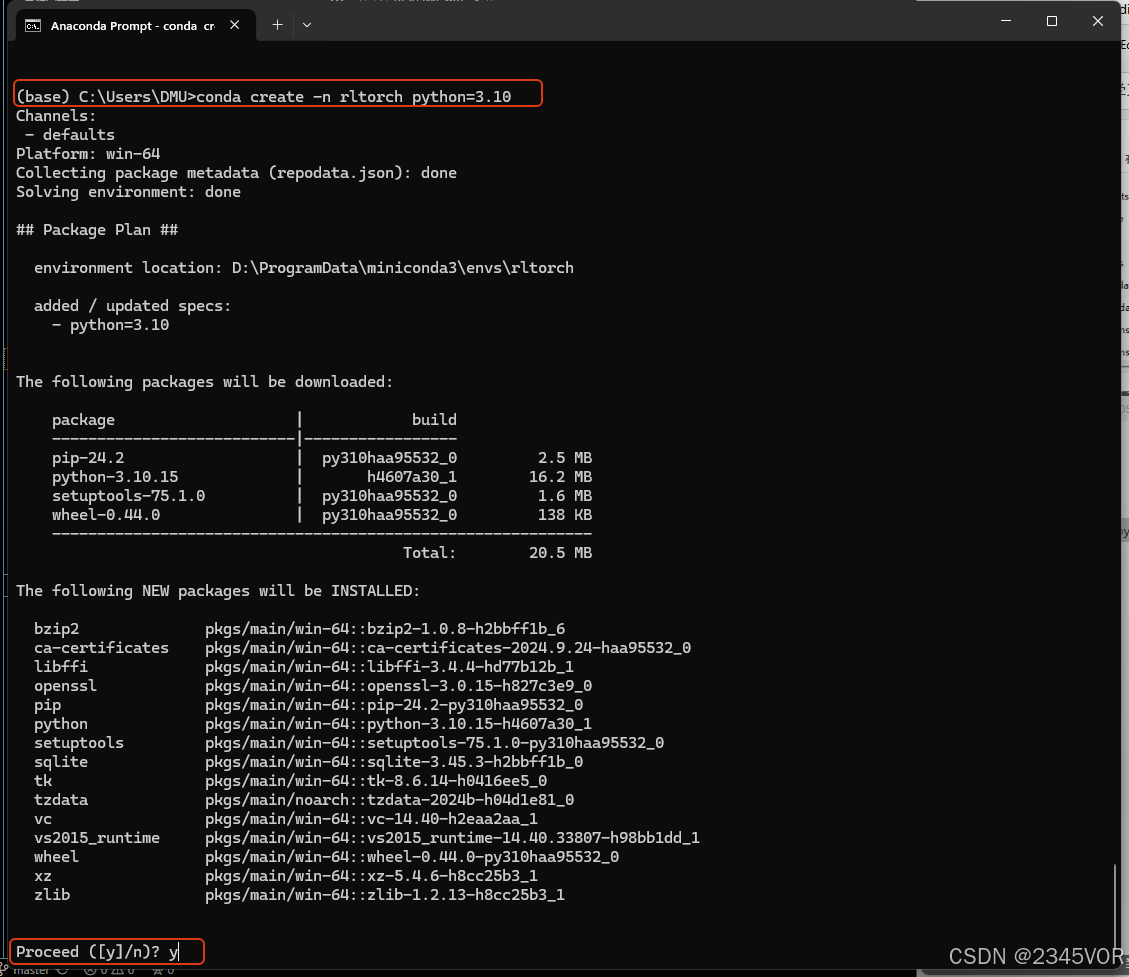
当安装好了以后,执行conda env list这个命令,就可以看到比一开始多了一个pytorch这个环境。现在我们可以在这个环境里面安装深度学习框架和一些Python包了。
执行如下命令,激活这个环境。conda activate 虚拟环境名称
conda activate rltorch

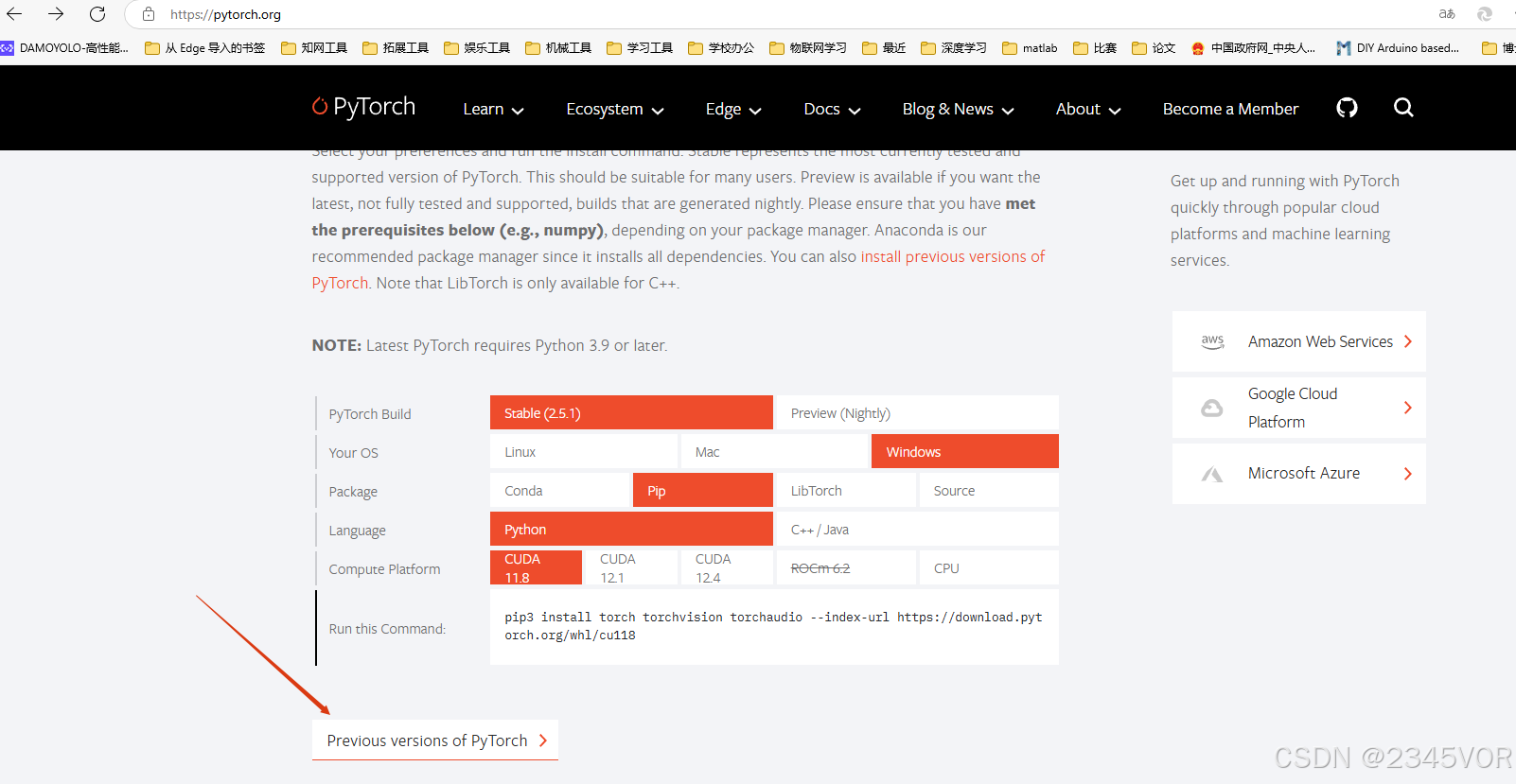
安装pytorch-gup版的环境,由于[pytorch的官网](https://pytorch.org/)在国外,下载相关的环境包是比较慢的,所以我们给环境换源。在pytorch环境下执行如下的命名给环境换清华源。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
然后打开pytorch的官网,由于开头我们通过驱动检测到我的显卡为 RTX2080Ti,最高支持cuda11.6版本,所以我们选择cuda11.3版本的cuda,然后将下面红色框框中的内容复制下来,一定不要把后面的-c pytorch也复制下来,因为这样运行就是还是在国外源下载,这样就会很慢。
# CUDA 11.8
conda install pytorch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 pytorch-cuda=11.8 -c pytorch -c nvidia
# CUDA 12.1
conda install pytorch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 pytorch-cuda=12.1 -c pytorch -c nvidia
# CPU Only
conda install pytorch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 cpuonly -c pytorch
安装过程需要耐心等待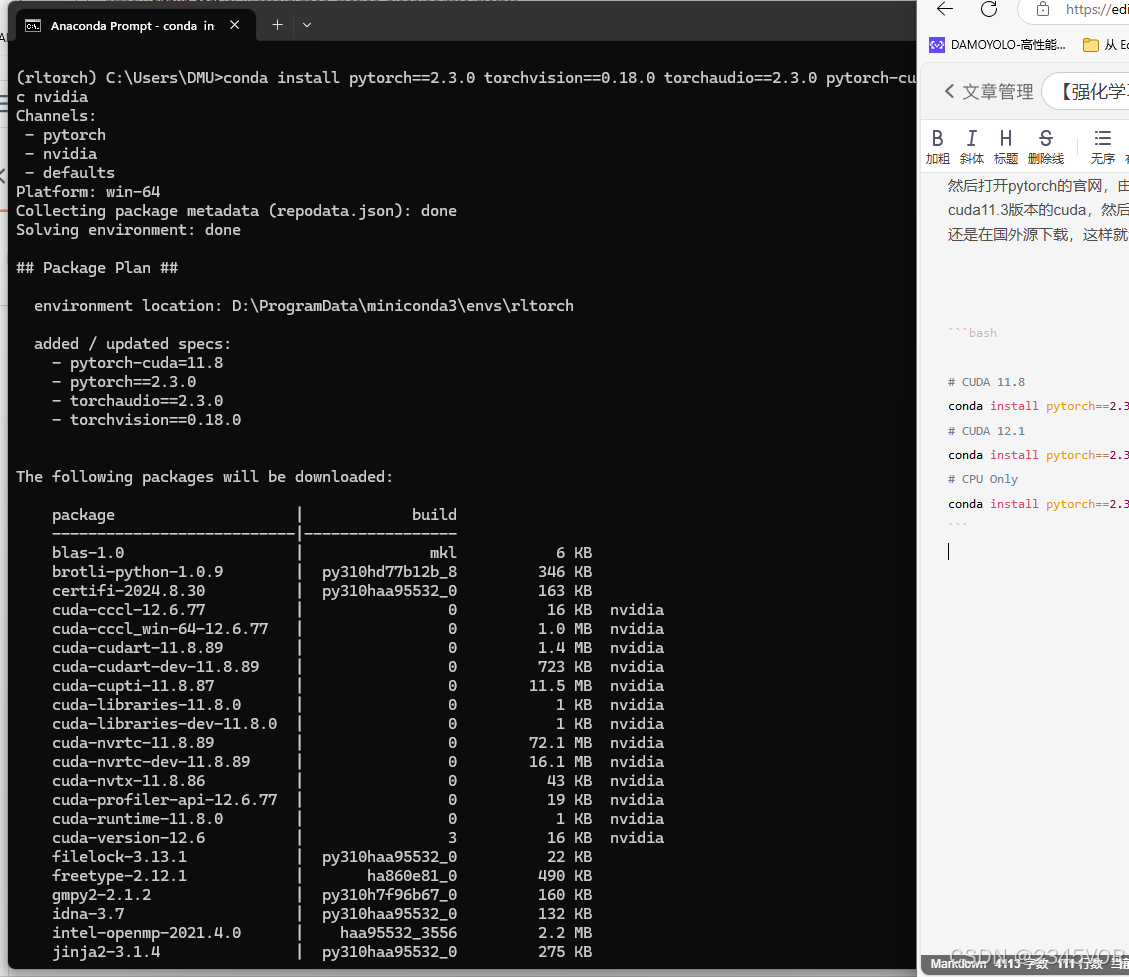
pip list
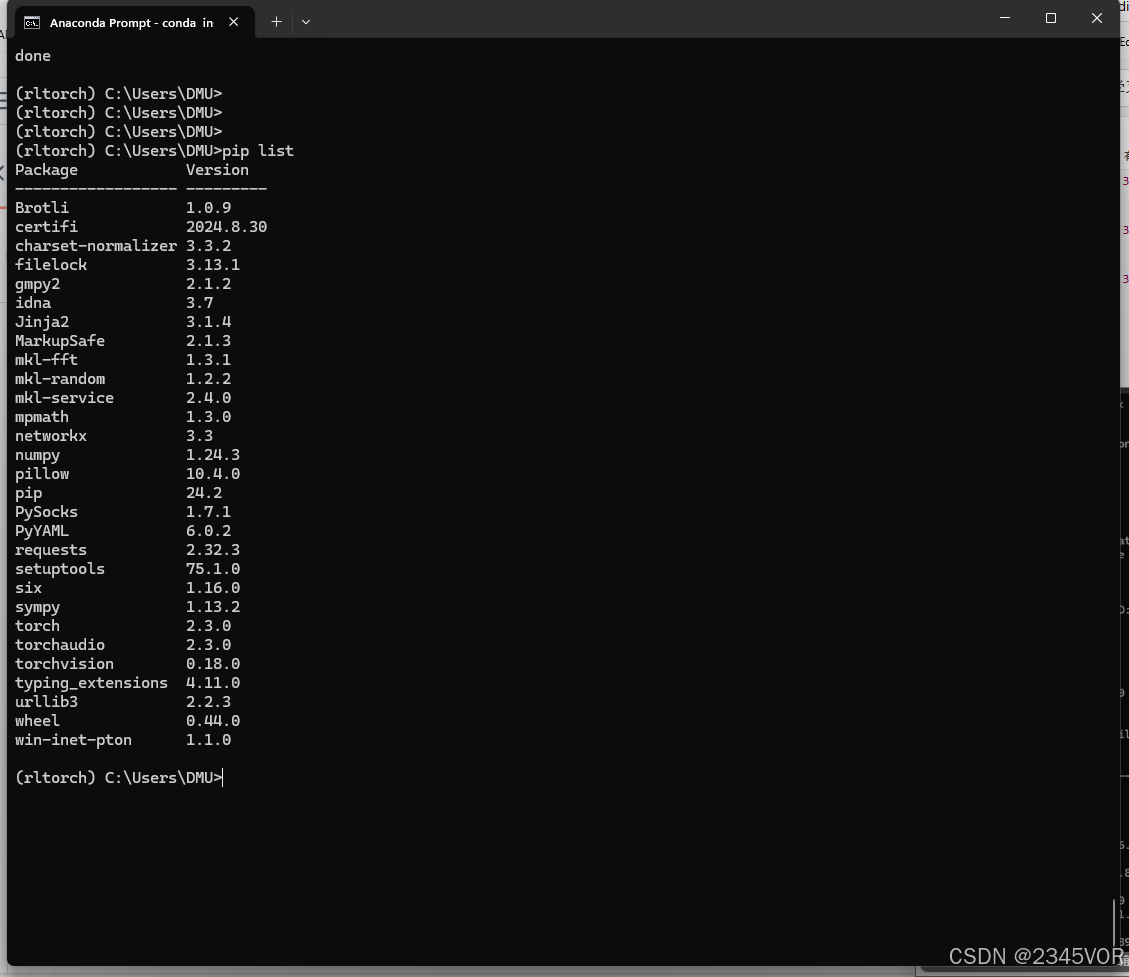
安装 gym 模块: 你可以使用 pip 来安装 gym 模块。pygame模块一般用来交互显示训练效果,打开终端或命令提示符,然后运行以下命令:
pip install gym
pip install pygame
4. Vscode安装
我们编写代码采用Vscode,Vscode和Git软件配置教程参考:https://vor2345.blog.csdn.net/article/details/142727918
5. Github demo复现
我们来复现西工大的一篇开源论文《基于MASAC强化学习算法的多无人机协同路径规划》文章DOI: https://doi.org/10.1360/SSI-2024-0050
github代码开源地址:https://github.com/henbudidiao/UAV-path-planning
打开Vscode gitbash
git clone "https://github.com/henbudidiao/UAV-path-planning.git"
我们需要打开motion plan项目文件夹
修改四处代码
5.1. main_SAC.py
是作者论文主要设计的强化学习方法:
# -*- coding: utf-8 -*-
#开发者:Bright Fang
#开发时间:2023/7/30 18:13
from rl_env.path_env import RlGame
# import pygame
# from assignment import constants as C
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from matplotlib import pyplot as plt
import os
import pickle as pkl
filedir = os.path.dirname(__file__)
shoplistfile = filedir + "\\MASAC_new1" #保存文件数据所在文件的文件名
shoplistfile_test = filedir + "\\MASAC_d_test2" #保存文件数据所在文件的文件名
shoplistfile_test1 = filedir + "\\MASAC_compare" #保存文件数据所在文件的文件名
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
N_Agent=1
M_Enemy=4
RENDER=True
TRAIN_NUM = 1
TEST_EPIOSDE=100
env = RlGame(n=N_Agent,m=M_Enemy,render=RENDER).unwrapped
state_number=7
action_number=env.action_space.shape[0]
max_action = env.action_space.high[0]
min_action = env.action_space.low[0]
EP_MAX = 500
EP_LEN = 1000
GAMMA = 0.9
q_lr = 3e-4
value_lr = 3e-3
policy_lr = 1e-3
BATCH = 128
tau = 1e-2
MemoryCapacity=20000
Switch=1
class Ornstein_Uhlenbeck_Noise:
def __init__(self, mu, sigma=0.1, theta=0.1, dt=1e-2, x0=None):
self.theta = theta
self.mu = mu
self.sigma = sigma
self.dt = dt
self.x0 = x0
self.reset()
def __call__(self):
x = self.x_prev + \
self.theta * (self.mu - self.x_prev) * self.dt + \
self.sigma * np.sqrt(self.dt) * np.random.normal(size=self.mu.shape)
'''
后两行是dXt,其中后两行的前一行是θ(μ-Xt)dt,后一行是σεsqrt(dt)
'''
self.x_prev = x
return x
def reset(self):
if self.x0 is not None:
self.x_prev = self.x0
else:
self.x_prev = np.zeros_like(self.mu)
class ActorNet(nn.Module):
def __init__(self,inp,outp):
super(ActorNet, self).__init__()
self.in_to_y1=nn.Linear(inp,256)
self.in_to_y1.weight.data.normal_(0,0.1)
self.y1_to_y2=nn.Linear(256,256)
self.y1_to_y2.weight.data.normal_(0,0.1)
self.out=nn.Linear(256,outp)
self.out.weight.data.normal_(0,0.1)
self.std_out = nn.Linear(256, outp)
self.std_out.weight.data.normal_(0, 0.1)
def forward(self,inputstate):
inputstate=self.in_to_y1(inputstate)
inputstate=F.relu(inputstate)
inputstate=self.y1_to_y2(inputstate)
inputstate=F.relu(inputstate)
mean=max_action*torch.tanh(self.out(inputstate))#输出概率分布的均值mean
log_std=self.std_out(inputstate)#softplus激活函数的值域>0
log_std=torch.clamp(log_std,-20,2)
std=log_std.exp()
return mean,std
class CriticNet(nn.Module):
def __init__(self,input,output):
super(CriticNet, self).__init__()
#q1
self.in_to_y1=nn.Linear(input+output,256)
self.in_to_y1.weight.data.normal_(0,0.1)
self.y1_to_y2=nn.Linear(256,256)
self.y1_to_y2.weight.data.normal_(0,0.1)
self.out=nn.Linear(256,1)
self.out.weight.data.normal_(0,0.1)
#q2
self.q2_in_to_y1 = nn.Linear(input+output, 256)
self.q2_in_to_y1.weight.data.normal_(0, 0.1)
self.q2_y1_to_y2 = nn.Linear(256, 256)
self.q2_y1_to_y2.weight.data.normal_(0, 0.1)
self.q2_out = nn.Linear(256, 1)
self.q2_out.weight.data.normal_(0, 0.1)
def forward(self,s,a):
inputstate = torch.cat((s, a), dim=1)
#q1
q1=self.in_to_y1(inputstate)
q1=F.relu(q1)
q1=self.y1_to_y2(q1)
q1=F.relu(q1)
q1=self.out(q1)
#q2
q2 = self.q2_in_to_y1(inputstate)
q2 = F.relu(q2)
q2 = self.q2_y1_to_y2(q2)
q2 = F.relu(q2)
q2 = self.q2_out(q2)
return q1,q2
class Memory():
def __init__(self,capacity,dims):
self.capacity=capacity
self.mem=np.zeros((capacity,dims))
self.memory_counter=0
'''存储记忆'''
def store_transition(self,s,a,r,s_):
tran = np.hstack((s, a,r, s_)) # 把s,a,r,s_困在一起,水平拼接
index = self.memory_counter % self.capacity#除余得索引
self.mem[index, :] = tran # 给索引存值,第index行所有列都为其中一次的s,a,r,s_;mem会是一个capacity行,(s+a+r+s_)列的数组
self.memory_counter+=1
'''随机从记忆库里抽取'''
def sample(self,n):
assert self.memory_counter>=self.capacity,'记忆库没有存满记忆'
sample_index = np.random.choice(self.capacity, n)#从capacity个记忆里随机抽取n个为一批,可得到抽样后的索引号
new_mem = self.mem[sample_index, :]#由抽样得到的索引号在所有的capacity个记忆中 得到记忆s,a,r,s_
return new_mem
class Actor():
def __init__(self):
self.action_net=ActorNet(state_number,action_number)#这只是均值mean
self.optimizer=torch.optim.Adam(self.action_net.parameters(),lr=policy_lr)
def choose_action(self,s):
inputstate = torch.FloatTensor(s)
mean,std=self.action_net(inputstate)
dist = torch.distributions.Normal(mean, std)
action=dist.sample()
action=torch.clamp(action,min_action,max_action)
return action.detach().numpy()
def evaluate(self,s):
inputstate = torch.FloatTensor(s)
mean,std=self.action_net(inputstate)
dist = torch.distributions.Normal(mean, std)
noise = torch.distributions.Normal(0, 1)
z = noise.sample()
action=torch.tanh(mean+std*z)
action=torch.clamp(action,min_action,max_action)
action_logprob=dist.log_prob(mean+std*z)-torch.log(1-action.pow(2)+1e-6)
return action,action_logprob
def learn(self,actor_loss):
loss=actor_loss
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
class Entroy():
def __init__(self):
self.target_entropy = -0.1
self.log_alpha = torch.zeros(1, requires_grad=True)
self.alpha = self.log_alpha.exp()
self.optimizer = torch.optim.Adam([self.log_alpha], lr=q_lr)
def learn(self,entroy_loss):
loss=entroy_loss
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
class Critic():
def __init__(self):
self.critic_v,self.target_critic_v=CriticNet(state_number*(N_Agent+M_Enemy),action_number),CriticNet(state_number*(N_Agent+M_Enemy),action_number)#改网络输入状态,生成一个Q值
self.target_critic_v.load_state_dict(self.critic_v.state_dict())
self.optimizer = torch.optim.Adam(self.critic_v.parameters(), lr=value_lr,eps=1e-5)
self.lossfunc = nn.MSELoss()
def soft_update(self):
for target_param, param in zip(self.target_critic_v.parameters(), self.critic_v.parameters()):
target_param.data.copy_(target_param.data * (1.0 - tau) + param.data * tau)
def get_v(self,s,a):
return self.critic_v(s,a)
def target_get_v(self,s,a):
return self.target_critic_v(s,a)
def learn(self,current_q1,current_q2,target_q):
loss = self.lossfunc(current_q1, target_q) + self.lossfunc(current_q2, target_q)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def main():
run(env)
def run(env):
if Switch==0:
try:
assert M_Enemy == 1
except:
print('程序终止,被逮到~嘿嘿,哥们儿预判到你会犯错,这段程序中变量\'M_Enemy\'的值必须为1,请把它的值改为1。\n'
'改为1之后程序一定会报错,这是因为组数越界,更改path_env.py文件中的跟随者无人机初始化个数;删除多余的\n'
'求距离函数,即变量dis_1_agent_0_to_3等,以及提到变量dis_1_agent_0_to_3等的地方;删除画无人机轨迹的\n'
'函数;删除step函数的最后一个返回值dis_1_agent_0_to_1;将player.py文件中的变量dt改为1;即可开始训练!\n'
'如果实在不会改也无妨,我会在不久之后出一个视频来手把手教大伙怎么改,可持续关注此项目github中的README文件。\n')
else:
print('SAC训练中...')
all_ep_r = [[] for i in range(TRAIN_NUM)]
all_ep_r0 = [[] for i in range(TRAIN_NUM)]
all_ep_r1 = [[] for i in range(TRAIN_NUM)]
for k in range(TRAIN_NUM):
actors = [None for _ in range(N_Agent+M_Enemy)]
critics = [None for _ in range(N_Agent+M_Enemy)]
entroys = [None for _ in range(N_Agent+M_Enemy)]
for i in range(N_Agent+M_Enemy):
actors[i] = Actor()
critics[i] = Critic()
entroys[i] = Entroy()
M = Memory(MemoryCapacity, 2 * state_number*(N_Agent+M_Enemy) + action_number*(N_Agent+M_Enemy) + 1*(N_Agent+M_Enemy))
ou_noise = Ornstein_Uhlenbeck_Noise(mu=np.zeros(((N_Agent+M_Enemy), action_number)))
action=np.zeros(((N_Agent+M_Enemy), action_number))
# aaa = np.zeros((N_Agent, state_number))
for episode in range(EP_MAX):
observation = env.reset() # 环境重置
reward_totle,reward_totle0,reward_totle1 = 0,0,0
for timestep in range(EP_LEN):
for i in range(N_Agent+M_Enemy):
action[i] = actors[i].choose_action(observation[i])
# action[0]=actor0.choose_action(observation[0])
# action[1] = actor0.choose_action(observation[1])
if episode <= 20:
noise = ou_noise()
else:
noise = 0
action = action + noise
action = np.clip(action, -max_action, max_action)
observation_, reward,done,win,team_counter= env.step(action) # 单步交互
M.store_transition(observation.flatten(), action.flatten(), reward.flatten(), observation_.flatten())
# 记忆库存储
# 有的2000个存储数据就开始学习
if M.memory_counter > MemoryCapacity:
b_M = M.sample(BATCH)
b_s = b_M[:, :state_number*(N_Agent+M_Enemy)]
b_a = b_M[:, state_number*(N_Agent+M_Enemy): state_number*(N_Agent+M_Enemy) + action_number*(N_Agent+M_Enemy)]
b_r = b_M[:, -state_number*(N_Agent+M_Enemy) - 1*(N_Agent+M_Enemy): -state_number*(N_Agent+M_Enemy)]
b_s_ = b_M[:, -state_number*(N_Agent+M_Enemy):]
b_s = torch.FloatTensor(b_s)
b_a = torch.FloatTensor(b_a)
b_r = torch.FloatTensor(b_r)
b_s_ = torch.FloatTensor(b_s_)
# if not done[0]:
# new_action_0, log_prob_0 = actor0.evaluate(b_s_[:, 0:state_number])
# target_q10, target_q20 = critic0.target_critic_v(b_s_[:, 0:state_number], new_action_0)
# target_q0 = b_r[:, 0:1] + GAMMA * (1 - b_done[0]) *(torch.min(target_q10, target_q20) - entroy0.alpha * log_prob_0)
# current_q10, current_q20 = critic0.get_v(b_s[:,0:state_number], b_a[:, 0:action_number*1])
# critic0.learn(current_q10, current_q20, target_q0.detach())
# a0, log_prob0 = actor0.evaluate(b_s[:, 0:state_number*1])
# q10, q20 = critic0.get_v(b_s[:, 0:state_number*1], a0)
# q0 = torch.min(q10, q20)
# actor_loss0 = (entroy0.alpha * log_prob0 - q0).mean()
# alpha_loss0 = -(entroy0.log_alpha.exp() * (
# log_prob0 + entroy0.target_entropy).detach()).mean()
# actor0.learn(actor_loss0)
# entroy0.learn(alpha_loss0)
# entroy0.alpha = entroy0.log_alpha.exp()
# # 软更新
# critic0.soft_update()
# if not done[1]:
# new_action_1, log_prob_1 = actor1.evaluate(b_s_[:, state_number:state_number*2])
# target_q11, target_q21 = critic1.target_critic_v(b_s_[:, state_number:state_number*2], new_action_1)
# target_q1= b_r[:, 1:2] + GAMMA * (1 - b_done[1])*(torch.min(target_q11, target_q21) - entroy1.alpha * log_prob_1)
# current_q11, current_q21 = critic1.get_v(b_s[:, state_number:state_number*2], b_a[:, action_number:action_number * 2])
# critic1.learn(current_q11, current_q21, target_q1.detach())
# a1, log_prob1 = actor1.evaluate(b_s[:, state_number:state_number*2])
# q11, q21 = critic1.get_v(b_s[:, state_number:state_number*2], a1)
# q1 = torch.min(q11, q21)
# actor_loss1 = (entroy1.alpha * log_prob1 - q1).mean()
# alpha_loss1 = -(entroy1.log_alpha.exp() * (
# log_prob1 + entroy1.target_entropy).detach()).mean()
# actor1.learn(actor_loss1)
# entroy1.learn(alpha_loss1)
# entroy1.alpha = entroy1.log_alpha.exp()
# # 软更新
# critic1.soft_update()
for i in range(N_Agent+M_Enemy):
# # # TODO 方法二
# new_action_0, log_prob_0 = actor0.evaluate(b_s_[:, :state_number])
# new_action_1, log_prob_1 = actor0.evaluate(b_s_[:, state_number:state_number * 2])
# new_action = torch.hstack((new_action_0, new_action_1))
# # new_action = torch.cat((new_action_0, new_action_1),dim=1)
# log_prob_ = (log_prob_0 + log_prob_1) / 2
# # log_prob_=torch.hstack((log_prob_0.mean(axis=1).unsqueeze(dim=1),log_prob_1.mean(axis=1).unsqueeze(dim=1)))
# target_q1, target_q2 = critic0.target_critic_v(b_s_, new_action)
#
# target_q = b_r + GAMMA * (torch.min(target_q1, target_q2) - entroy0.alpha * log_prob_)
#
# current_q1, current_q2 = critic0.get_v(b_s, b_a)
# critic0.learn(current_q1, current_q2, target_q.detach())
# a0, log_prob0 = actor0.evaluate(b_s[:, :state_number])
# a1, log_prob1 = actor0.evaluate(b_s[:, state_number:state_number * 2])
# a = torch.hstack((a0, a1))
# # a = torch.cat((a0, a1),dim=1)
# log_prob = (log_prob0 + log_prob1) / 2
# # log_prob = torch.hstack((log_prob0.mean(axis=1).unsqueeze(dim=1), log_prob1.mean(axis=1).unsqueeze(dim=1)))
# q1, q2 = critic0.get_v(b_s, a)
# q = torch.min(q1, q2)
#
# actor_loss = (entroy0.alpha * log_prob - q).mean()
# alpha_loss = -(entroy0.log_alpha.exp() * (log_prob + entroy0.target_entropy).detach()).mean()
#
# actor0.learn(actor_loss)
# # actor1.learn(actor_loss)
# entroy0.learn(alpha_loss)
# entroy0.alpha = entroy0.log_alpha.exp()
# # 软更新
# critic0.soft_update()
# TODO 方法零
# if not done[i]:
new_action, log_prob_ = actors[i].evaluate(b_s_[:, state_number*i:state_number*(i+1)])
target_q1, target_q2 = critics[i].target_critic_v(b_s_, new_action)
target_q = b_r[:, i:(i+1)] + GAMMA * (torch.min(target_q1, target_q2) - entroys[i].alpha * log_prob_)
current_q1, current_q2 = critics[i].get_v(b_s, b_a[:, action_number*i:action_number*(i+1)])
critics[i].learn(current_q1, current_q2, target_q.detach())
a, log_prob = actors[i].evaluate(b_s[:, state_number*i:state_number*(i+1)])
q1, q2 = critics[i].get_v(b_s, a)
q = torch.min(q1, q2)
actor_loss = (entroys[i].alpha * log_prob - q).mean()
alpha_loss = -(entroys[i].log_alpha.exp() * (
log_prob + entroys[i].target_entropy).detach()).mean()
actors[i].learn(actor_loss)
entroys[i].learn(alpha_loss)
entroys[i].alpha = entroys[i].log_alpha.exp()
# 软更新
critics[i].soft_update()
# #TODO 方法一
# new_action_0, log_prob_0 = actors[i].evaluate(b_s_[:, :state_number])
# new_action_1, log_prob_1 = actors[i].evaluate(b_s_[:, state_number:state_number * 2])
# new_action = torch.hstack((new_action_0, new_action_1))
# # new_action = torch.cat((new_action_0, new_action_1),dim=1)
# # log_prob_ = (log_prob_0 + log_prob_1) / 2
# # log_prob_=torch.hstack((log_prob_0.mean(axis=1).unsqueeze(dim=1),log_prob_1.mean(axis=1).unsqueeze(dim=1)))
# target_q1, target_q2 = critics[i].target_critic_v(b_s_, new_action)
# if i==0:
# target_q = b_r[:, i:(i+1)] + GAMMA * (torch.min(target_q1, target_q2) - entroys[i].alpha * log_prob_0)
# elif i==1:
# target_q = b_r[:, i:(i+1)] + GAMMA * (torch.min(target_q1, target_q2) - entroys[i].alpha * log_prob_1)
# current_q1, current_q2 = critics[i].get_v(b_s, b_a)
# critics[i].learn(current_q1, current_q2, target_q.detach())
# a0, log_prob0 = actors[i].evaluate(b_s[:, :state_number])
# a1, log_prob1 = actors[i].evaluate(b_s[:, state_number:state_number * 2])
# a = torch.hstack((a0, a1))
# # a = torch.cat((a0, a1),dim=1)
# # log_prob = (log_prob0 + log_prob1) / 2
# # log_prob = torch.hstack((log_prob0.mean(axis=1).unsqueeze(dim=1), log_prob1.mean(axis=1).unsqueeze(dim=1)))
# q1, q2 = critics[i].get_v(b_s, a)
# q = torch.min(q1, q2)
# if i == 0:
# actor_loss = (entroys[i].alpha * log_prob0 - q).mean()
# alpha_loss = -(entroys[i].log_alpha.exp() * (log_prob0 + entroys[i].target_entropy).detach()).mean()
# elif i == 1:
# actor_loss = (entroys[i].alpha * log_prob1 - q).mean()
# alpha_loss = -(entroys[i].log_alpha.exp() * (log_prob1 + entroys[i].target_entropy).detach()).mean()
# actors[i].learn(actor_loss)
# entroys[i].learn(alpha_loss)
# entroys[i].alpha = entroys[i].log_alpha.exp()
# # 软更新
# critics[i].soft_update()
# #TODO 方法二
# new_action_0, log_prob_0 = actors[i].evaluate(b_s_[:, :state_number])
# new_action_1, log_prob_1 = actors[i].evaluate(b_s_[:, state_number:state_number * 2])
# new_action = torch.hstack((new_action_0, new_action_1))
# log_prob_ = (log_prob_0 + log_prob_1) / 2
# # log_prob_=torch.hstack((log_prob_0.mean(axis=1).unsqueeze(dim=1),log_prob_1.mean(axis=1).unsqueeze(dim=1)))
# target_q1, target_q2 = critics[i].target_critic_v(b_s_, new_action)
# target_q = b_r + GAMMA * (torch.min(target_q1, target_q2) - entroys[i].alpha * log_prob_)
# current_q1, current_q2 = critics[i].get_v(b_s, b_a)
# critics[i].learn(current_q1, current_q2, target_q.detach())
# a0, log_prob0 = actors[i].evaluate(b_s[:, :state_number])
# a1, log_prob1 = actors[i].evaluate(b_s[:, state_number:state_number * 2])
# a = torch.hstack((a0, a1))
# log_prob = (log_prob0 + log_prob1) / 2
# # log_prob = torch.hstack((log_prob0.mean(axis=1).unsqueeze(dim=1), log_prob1.mean(axis=1).unsqueeze(dim=1)))
# q1, q2 = critics[i].get_v(b_s, a)
# q = torch.min(q1, q2)
# actor_loss = ( entroys[i].alpha * log_prob - q).mean()
# actors[i].learn(actor_loss)
# alpha_loss = -( entroys[i].log_alpha.exp() * (log_prob + entroys[i].target_entropy).detach()).mean()
# entroys[i].learn(alpha_loss)
# entroys[i].alpha = entroys[i].log_alpha.exp()
# # 软更新
# critics[i].soft_update()
# new_action_0, log_prob_0 = actor.evaluate(b_s_[:, :state_number])
# new_action_1, log_prob_1 = actor.evaluate(b_s_[:, state_number:state_number*2])
# new_action=torch.hstack((new_action_0,new_action_1))
# log_prob_=(log_prob_0+log_prob_1)/2
# # log_prob_=torch.hstack((log_prob_0.mean(axis=1).unsqueeze(dim=1),log_prob_1.mean(axis=1).unsqueeze(dim=1)))
# target_q1,target_q2=critic.target_critic_v(b_s_,new_action)
# target_q=b_r+GAMMA*(torch.min(target_q1,target_q2)-entroy.alpha*log_prob_)
# current_q1, current_q2 = critic.get_v(b_s, b_a)
# critic.learn(current_q1,current_q2,target_q.detach())
# a0,log_prob0=actor.evaluate(b_s[:, :state_number])
# a1, log_prob1 = actor.evaluate(b_s[:, state_number:state_number*2])
# a = torch.hstack((a0, a1))
# log_prob=(log_prob0+log_prob1)/2
# # log_prob = torch.hstack((log_prob0.mean(axis=1).unsqueeze(dim=1), log_prob1.mean(axis=1).unsqueeze(dim=1)))
# q1,q2=critic.get_v(b_s,a)
# q=torch.min(q1,q2)
# actor_loss = (entroy.alpha * log_prob - q).mean()
# actor.learn(actor_loss)
# alpha_loss = -(entroy.log_alpha.exp() * (log_prob + entroy.target_entropy).detach()).mean()
# entroy.learn(alpha_loss)
# entroy.alpha=entroy.log_alpha.exp()
# # 软更新
# critic.soft_update()
observation = observation_
reward_totle += reward.mean()
reward_totle0 += float(reward[0])
reward_totle1 += float(reward[1])
if RENDER:
env.render()
if done:
break
print("Ep: {} rewards: {}".format(episode, reward_totle))
all_ep_r[k].append(reward_totle)
all_ep_r0[k].append(reward_totle0)
all_ep_r1[k].append(reward_totle1)
if episode % 20 == 0 and episode > 200:#保存神经网络参数
save_data = {'net': actors[0].action_net.state_dict(), 'opt': actors[0].optimizer.state_dict()}
torch.save(save_data, filedir + "\\Path_SAC_actor_L1.pth")
save_data = {'net': actors[1].action_net.state_dict(), 'opt': actors[1].optimizer.state_dict()}
torch.save(save_data, filedir + "\\Path_SAC_actor_F1.pth")
# plt.plot(np.arange(len(all_ep_r)), all_ep_r)
# plt.xlabel('Episode')
# plt.ylabel('Total reward')
# plt.figure(2, figsize=(8, 4), dpi=150)
# plt.plot(np.arange(len(all_ep_r0)), all_ep_r0)
# plt.xlabel('Episode')
# plt.ylabel('Leader reward')
# plt.figure(3, figsize=(8, 4), dpi=150)
# plt.plot(np.arange(len(all_ep_r1)), all_ep_r1)
# plt.xlabel('Episode')
# plt.ylabel('Follower reward')
# plt.show()
# env.close()
all_ep_r_mean = np.mean((np.array(all_ep_r)), axis=0)
all_ep_r_std = np.std((np.array(all_ep_r)), axis=0)
all_ep_L_mean = np.mean((np.array(all_ep_r0)), axis=0)
all_ep_L_std = np.std((np.array(all_ep_r0)), axis=0)
all_ep_F_mean = np.mean((np.array(all_ep_r1)), axis=0)
all_ep_F_std = np.std((np.array(all_ep_r1)), axis=0)
d = {"all_ep_r_mean": all_ep_r_mean, "all_ep_r_std": all_ep_r_std,
"all_ep_L_mean": all_ep_L_mean, "all_ep_L_std": all_ep_L_std,
"all_ep_F_mean": all_ep_F_mean, "all_ep_F_std": all_ep_F_std,}
f = open(shoplistfile, 'wb') # 二进制打开,如果找不到该文件,则创建一个
pkl.dump(d, f, pkl.HIGHEST_PROTOCOL) # 写入文件
f.close()
all_ep_r_max = all_ep_r_mean + all_ep_r_std * 0.95
all_ep_r_min = all_ep_r_mean - all_ep_r_std * 0.95
all_ep_L_max = all_ep_L_mean + all_ep_L_std * 0.95
all_ep_L_min = all_ep_L_mean - all_ep_L_std * 0.95
all_ep_F_max = all_ep_F_mean + all_ep_F_std * 0.95
all_ep_F_min = all_ep_F_mean - all_ep_F_std * 0.95
plt.margins(x=0)
plt.plot(np.arange(len(all_ep_r_mean)), all_ep_r_mean, label='MASAC', color='#e75840')
plt.fill_between(np.arange(len(all_ep_r_mean)), all_ep_r_max, all_ep_r_min, alpha=0.6, facecolor='#e75840')
plt.xlabel('Episode')
plt.ylabel('Total reward')
plt.figure(2, figsize=(8, 4), dpi=150)
plt.margins(x=0)
plt.plot(np.arange(len(all_ep_L_mean)), all_ep_L_mean, label='MASAC', color='#e75840')
plt.fill_between(np.arange(len(all_ep_L_mean)), all_ep_L_max, all_ep_L_min, alpha=0.6,
facecolor='#e75840')
plt.xlabel('Episode')
plt.ylabel('Leader reward')
plt.figure(3, figsize=(8, 4), dpi=150)
plt.margins(x=0)
plt.plot(np.arange(len(all_ep_F_mean)), all_ep_F_mean, label='MASAC', color='#e75840')
plt.fill_between(np.arange(len(all_ep_F_mean)), all_ep_F_max, all_ep_F_min, alpha=0.6,
facecolor='#e75840')
plt.xlabel('Episode')
plt.ylabel('Follower reward')
plt.legend()
plt.show()
env.close()
else:
print('SAC测试中...')
aa = Actor()
checkpoint_aa = torch.load(filedir + "\\Path_SAC_actor_L1.pth")
aa.action_net.load_state_dict(checkpoint_aa['net'])
bb = Actor()
checkpoint_bb = torch.load(filedir + "\\Path_SAC_actor_F1.pth")
bb.action_net.load_state_dict(checkpoint_bb['net'])
action = np.zeros((N_Agent+M_Enemy, action_number))
win_times = 0
average_FKR=0
average_timestep=0
average_integral_V=0
average_integral_U= 0
all_ep_V, all_ep_U, all_ep_T, all_ep_F = [], [], [], []
for j in range(TEST_EPIOSDE):
state = env.reset()
total_rewards = 0
integral_V=0
integral_U=0
v,v1,Dis=[],[],[]
for timestep in range(EP_LEN):
for i in range(N_Agent):
action[i] = aa.choose_action(state[i])
for i in range(M_Enemy):
action[i+1] = bb.choose_action(state[i+1])
# action[0] = aa.choose_action(state[0])
# action[1] = bb.choose_action(state[1])
new_state, reward,done,win,team_counter,dis = env.step(action) # 执行动作
if win:
win_times += 1
v.append(state[0][2]*30)
v1.append(state[1][2]*30)
Dis.append(dis)
integral_V+=state[0][2]
integral_U+=abs(action[0]).sum()
total_rewards += reward.mean()
state = new_state
if RENDER:
env.render()
if done:
break
FKR=team_counter/timestep
average_FKR += FKR
average_timestep += timestep
average_integral_V += integral_V
average_integral_U += integral_U
print("Score", total_rewards)
all_ep_V.append(integral_V)
all_ep_U.append(integral_U)
all_ep_T.append(timestep)
all_ep_F.append(FKR)
# print('最大编队保持率',FKR)
# print('最短飞行时间',timestep)
# print('最短飞行路程', integral_V)
# print('最小能量损耗', integral_U)
# d = {"leader": v, "follower": v1 }
# d = {"distance": Dis}
# f = open(shoplistfile_test, 'wb') # 二进制打开,如果找不到该文件,则创建一个
# pkl.dump(d, f, pkl.HIGHEST_PROTOCOL) # 写入文件
# f.close()
# plt.plot(np.arange(len(v)), v)
# plt.plot(np.arange(len(v1)), v1)
# plt.plot(np.arange(len(Dis)), Dis)
# plt.show()
print('任务完成率',win_times / TEST_EPIOSDE)
print('平均最大编队保持率', average_FKR/TEST_EPIOSDE)
print('平均最短飞行时间', average_timestep/TEST_EPIOSDE)
print('平均最短飞行路程', average_integral_V/TEST_EPIOSDE)
print('平均最小能量损耗', average_integral_U/TEST_EPIOSDE)
# d = {"all_ep_V": all_ep_V, "all_ep_U": all_ep_U, "all_ep_T": all_ep_T, "all_ep_F": all_ep_F, }
# f = open(shoplistfile_test1, 'wb') # 二进制打开,如果找不到该文件,则创建一个
# pkl.dump(d, f, pkl.HIGHEST_PROTOCOL) # 写入文件
# f.close()
env.close()
if __name__ == '__main__':
main()
5.2 main_DDPG.py
是作者论文对比的一种强化学习方法
# -*- coding: utf-8 -*-
#开发者:Bright Fang
#开发时间:2023/7/20 23:34
from rl_env.path_env import RlGame
# import pygame
# from assignment import constants as C
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from matplotlib import pyplot as plt
import os
import pickle as pkl
filedir = os.path.dirname(__file__)
shoplistfile = filedir + "\\MADDPG" #保存文件数据所在文件的文件名
shoplistfile_test = filedir + "\\MADDPG_compare" #保存文件数据所在文件的文件名
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
N_Agent=1
M_Enemy=4
RENDER=True
env = RlGame(n=N_Agent,m=M_Enemy,render=RENDER).unwrapped
state_number=7
TEST_EPIOSDE=100
TRAIN_NUM = 3
EP_LEN = 1000
EPIOSDE_ALL=500
action_number=env.action_space.shape[0]
max_action = env.action_space.high[0]
min_action = env.action_space.low[0]
LR_A = 1e-3 # learning rate for actor
LR_C = 1e-3 # learning rate for critic
GAMMA = 0.95
MemoryCapacity=20000
Batch=128
Switch=1
tau = 0.005
'''DDPG第一步 设计A-C框架的Actor(DDPG算法,只有critic的部分才会用到记忆库)'''
'''第一步 设计A-C框架形式的网络部分'''
class ActorNet(nn.Module):
def __init__(self,inp,outp):
super(ActorNet, self).__init__()
self.in_to_y1=nn.Linear(inp,50)
self.in_to_y1.weight.data.normal_(0,0.1)
self.y1_to_y2=nn.Linear(50,20)
self.y1_to_y2.weight.data.normal_(0,0.1)
self.out=nn.Linear(20,outp)
self.out.weight.data.normal_(0,0.1)
def forward(self,inputstate):
inputstate=self.in_to_y1(inputstate)
inputstate=F.relu(inputstate)
inputstate=self.y1_to_y2(inputstate)
inputstate=torch.sigmoid(inputstate)
act=max_action*torch.tanh(self.out(inputstate))
# return F.softmax(act,dim=-1)
return act
class CriticNet(nn.Module):
def __init__(self,input,output):
super(CriticNet, self).__init__()
self.in_to_y1=nn.Linear(input+output,40)
self.in_to_y1.weight.data.normal_(0,0.1)
self.y1_to_y2=nn.Linear(40,20)
self.y1_to_y2.weight.data.normal_(0,0.1)
self.out=nn.Linear(20,1)
self.out.weight.data.normal_(0,0.1)
def forward(self,s,a):
inputstate = torch.cat((s, a), dim=1)
inputstate=self.in_to_y1(inputstate)
inputstate=F.relu(inputstate)
inputstate=self.y1_to_y2(inputstate)
inputstate=torch.sigmoid(inputstate)
Q=self.out(inputstate)
return Q
class Actor():
def __init__(self):
self.actor_estimate_eval,self.actor_reality_target = ActorNet(state_number,action_number),ActorNet(state_number,action_number)
self.optimizer = torch.optim.Adam(self.actor_estimate_eval.parameters(), lr=LR_A)
'''第二步 编写根据状态选择动作的函数'''
def choose_action(self, s):
inputstate = torch.FloatTensor(s)
probs = self.actor_estimate_eval(inputstate)
return probs.detach().numpy()
'''第四步 编写A的学习函数'''
'''生成输入为s的actor估计网络,用于传给critic估计网络,虽然这与choose_action函数一样,但如果直接用choose_action
函数生成的动作,DDPG是不会收敛的,原因在于choose_action函数生成的动作经过了记忆库,动作从记忆库出来后,动作的梯度数据消失了
所以再次编写了learn_a函数,它生成的动作没有过记忆库,是带有梯度的'''
def learn_a(self, s):
s = torch.FloatTensor(s)
A_prob = self.actor_estimate_eval(s)
return A_prob
'''把s_输入给actor现实网络,生成a_,a_将会被传给critic的实现网络'''
def learn_a_(self, s_):
s_ = torch.FloatTensor(s_)
A_prob=self.actor_reality_target(s_).detach()
return A_prob
'''actor的学习函数接受来自critic估计网络算出的Q_estimate_eval当做自己的loss,即负的critic_estimate_eval(s,a),使loss
最小化,即最大化critic网络生成的价值'''
def learn(self, a_loss):
loss = a_loss
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
'''第六步,最后一步 编写软更新程序,Actor部分与critic部分都会有软更新代码'''
'''DQN是硬更新,即固定时间更新,而DDPG采用软更新,w_老_现实=τ*w_新_估计+(1-τ)w_老_现实'''
def soft_update(self):
for target_param, param in zip(self.actor_reality_target.parameters(), self.actor_estimate_eval.parameters()):
target_param.data.copy_(target_param.data * (1.0 - tau) + param.data * tau)
class Critic():
def __init__(self):
self.critic_estimate_eval,self.critic_reality_target=CriticNet(state_number*(N_Agent+M_Enemy),action_number),CriticNet(state_number*(N_Agent+M_Enemy),action_number)
self.optimizer = torch.optim.Adam(self.critic_estimate_eval.parameters(), lr=LR_C)
self.lossfun=nn.MSELoss()
'''第五步 编写critic的学习函数'''
'''使用critic估计网络得到 actor的loss,这里的输入参数a是带梯度的'''
def learn_loss(self, s, a):
s = torch.FloatTensor(s)
# a = a.view(-1, 1)
Q_estimate_eval = -self.critic_estimate_eval(s, a).mean()
return Q_estimate_eval
'''这里的输入参数a与a_是来自记忆库的,不带梯度,根据公式我们会得到critic的loss'''
def learn(self, s, a, r, s_, a_):
s = torch.FloatTensor(s)
a = torch.FloatTensor(a)#当前动作a来自记忆库
r = torch.FloatTensor(r)
s_ = torch.FloatTensor(s_)
# a_ = a_.view(-1, 1) # view中一个参数定为-1,代表动态调整这个维度上的元素个数,以保证元素的总数不变
Q_estimate_eval = self.critic_estimate_eval(s, a)
Q_next = self.critic_reality_target(s_, a_).detach()
Q_reality_target = r + GAMMA * Q_next
loss = self.lossfun(Q_estimate_eval, Q_reality_target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def soft_update(self):
for target_param, param in zip(self.critic_reality_target.parameters(), self.critic_estimate_eval.parameters()):
target_param.data.copy_(target_param.data * (1.0 - tau) + param.data * tau)
'''第三步 建立记忆库'''
class Memory():
def __init__(self,capacity,dims):
self.capacity=capacity
self.mem=np.zeros((capacity,dims))
self.memory_counter=0
'''存储记忆'''
def store_transition(self,s,a,r,s_):
tran = np.hstack((s, a,r, s_)) # 把s,a,r,s_困在一起,水平拼接
index = self.memory_counter % self.capacity#除余得索引
self.mem[index, :] = tran # 给索引存值,第index行所有列都为其中一次的s,a,r,s_;mem会是一个capacity行,(s+a+r+s_)列的数组
self.memory_counter+=1
'''随机从记忆库里抽取'''
def sample(self,n):
assert self.memory_counter>=self.capacity,'记忆库没有存满记忆'
sample_index = np.random.choice(self.capacity, n)#从capacity个记忆里随机抽取n个为一批,可得到抽样后的索引号
new_mem = self.mem[sample_index, :]#由抽样得到的索引号在所有的capacity个记忆中 得到记忆s,a,r,s_
return new_mem
'''OU噪声'''
class Ornstein_Uhlenbeck_Noise:
def __init__(self, mu, sigma=0.1, theta=0.1, dt=1e-2, x0=None):
self.theta = theta
self.mu = mu
self.sigma = sigma
self.dt = dt
self.x0 = x0
self.reset()
def __call__(self):
x = self.x_prev + \
self.theta * (self.mu - self.x_prev) * self.dt + \
self.sigma * np.sqrt(self.dt) * np.random.normal(size=self.mu.shape)
'''
后两行是dXt,其中后两行的前一行是θ(μ-Xt)dt,后一行是σεsqrt(dt)
'''
self.x_prev = x
return x
def reset(self):
if self.x0 is not None:
self.x_prev = self.x0
else:
self.x_prev = np.zeros_like(self.mu)
def main():
os.environ["SDL_VIDEODRIVER"] = "dummy"
run(env)
def run(env):
if Switch==0:
all_ep_r = [[] for i in range(TRAIN_NUM)]
all_ep_r0 = [[] for i in range(TRAIN_NUM)]
all_ep_r1 = [[] for i in range(TRAIN_NUM)]
for k in range(TRAIN_NUM):
actors = [None for _ in range(N_Agent + M_Enemy)]
critics = [None for _ in range(N_Agent + M_Enemy)]
for i in range(N_Agent + M_Enemy):
actors[i] = Actor()
critics[i] = Critic()
M = Memory(MemoryCapacity, 2 * state_number*(N_Agent+M_Enemy) + action_number*(N_Agent+M_Enemy) + 1*(N_Agent+M_Enemy)) # 奖惩是一个浮点数
ou_noise = Ornstein_Uhlenbeck_Noise(mu=np.zeros(((N_Agent+M_Enemy), action_number)))
action = np.zeros(((N_Agent + M_Enemy), action_number))
# all_ep_r = []
for episode in range(EPIOSDE_ALL):
observation=env.reset()
reward_totle, reward_totle0, reward_totle1 = 0, 0, 0
for timestep in range(EP_LEN):
for i in range(N_Agent + M_Enemy):
action[i] = actors[i].choose_action(observation[i])
# action[0]=actor0.choose_action(observation[0])
# action[1] = actor0.choose_action(observation[1])
if episode <= 50:
noise = ou_noise()
else:
noise = 0
action = action + noise
action = np.clip(action, -max_action, max_action)
observation_, reward,done,win,team_counter = env.step(action) # 单步交互
M.store_transition(observation.flatten(), action.flatten(), reward.flatten()/1000, observation_.flatten())
if M.memory_counter > MemoryCapacity:
b_M = M.sample(Batch)
b_s = b_M[:, :state_number*(N_Agent+M_Enemy)]
b_a = b_M[:,
state_number * (N_Agent + M_Enemy): state_number * (N_Agent + M_Enemy) + action_number * (
N_Agent + M_Enemy)]
b_r = b_M[:, -state_number * (N_Agent + M_Enemy) - 1 * (N_Agent + M_Enemy): -state_number * (
N_Agent + M_Enemy)]
b_s_ = b_M[:, -state_number * (N_Agent + M_Enemy):]
for i in range(N_Agent + M_Enemy):
actor_action_0 = actors[i].learn_a(b_s[:, state_number*i:state_number*(i+1)])
# actor_action_1 = actors[1].learn_a(b_s[:, state_number:state_number * 2])
# actor_action = torch.hstack((actor_action_0, actor_action_1))
actor_action_0_ = actors[i].learn_a_(b_s_[:, state_number*i:state_number*(i+1)])
# actor_action_1_ = actors[1].learn_a_(b_s_[:, state_number:state_number * 2])
# actor_action_ = torch.hstack((actor_action_0_, actor_action_1_))
critics[i].learn(b_s, b_a[:, action_number*i:action_number*(i+1)], b_r, b_s_, actor_action_0_)
Q_c_to_a_loss = critics[i].learn_loss(b_s, actor_action_0)
actors[i].learn(Q_c_to_a_loss)
# 软更新
actors[i].soft_update()
critics[i].soft_update()
observation = observation_
reward_totle += reward.mean()
reward_totle0 += float(reward[0])
reward_totle1 += float(reward[1])
if RENDER:
env.render()
if done:
break
print('Episode {},奖励:{}'.format(episode, reward_totle))
# all_ep_r.append(reward_totle)
all_ep_r[k].append(reward_totle)
all_ep_r0[k].append(reward_totle0)
all_ep_r1[k].append(reward_totle1)
if episode % 50 == 0 and episode > 200:#保存神经网络参数
save_data = {'net': actors[0].actor_estimate_eval.state_dict(), 'opt': actors[0].optimizer.state_dict()}
torch.save(save_data, filedir + "\\Path_DDPG_actor_new.pth")
save_data = {'net': actors[1].actor_estimate_eval.state_dict(), 'opt': actors[1].optimizer.state_dict()}
torch.save(save_data, filedir + "\\Path_DDPG_actor_1_new.pth")
# plt.plot(np.arange(len(all_ep_r)), all_ep_r)
# plt.xlabel('Episode')
# plt.ylabel('Moving averaged episode reward')
# plt.show()
# env.close()
all_ep_r_mean = np.mean((np.array(all_ep_r)), axis=0)
all_ep_r_std = np.std((np.array(all_ep_r)), axis=0)
all_ep_L_mean = np.mean((np.array(all_ep_r0)), axis=0)
all_ep_L_std = np.std((np.array(all_ep_r0)), axis=0)
all_ep_F_mean = np.mean((np.array(all_ep_r1)), axis=0)
all_ep_F_std = np.std((np.array(all_ep_r1)), axis=0)
d = {"all_ep_r_mean": all_ep_r_mean, "all_ep_r_std": all_ep_r_std,
"all_ep_L_mean": all_ep_L_mean, "all_ep_L_std": all_ep_L_std,
"all_ep_F_mean": all_ep_F_mean, "all_ep_F_std": all_ep_F_std,}
f = open(shoplistfile, 'wb') # 二进制打开,如果找不到该文件,则创建一个
pkl.dump(d, f, pkl.HIGHEST_PROTOCOL) # 写入文件
f.close()
all_ep_r_max = all_ep_r_mean + all_ep_r_std * 0.95
all_ep_r_min = all_ep_r_mean - all_ep_r_std * 0.95
all_ep_L_max = all_ep_L_mean + all_ep_L_std * 0.95
all_ep_L_min = all_ep_L_mean - all_ep_L_std * 0.95
all_ep_F_max = all_ep_F_mean + all_ep_F_std * 0.95
all_ep_F_min = all_ep_F_mean - all_ep_F_std * 0.95
plt.margins(x=0)
plt.plot(np.arange(len(all_ep_r_mean)), all_ep_r_mean, label='MADDPG', color='#e75840')
plt.fill_between(np.arange(len(all_ep_r_mean)), all_ep_r_max, all_ep_r_min, alpha=0.6, facecolor='#e75840')
plt.xlabel('Episode')
plt.ylabel('Total reward')
plt.figure(2, figsize=(8, 4), dpi=150)
plt.margins(x=0)
plt.plot(np.arange(len(all_ep_L_mean)), all_ep_L_mean, label='MADDPG', color='#e75840')
plt.fill_between(np.arange(len(all_ep_L_mean)), all_ep_L_max, all_ep_L_min, alpha=0.6,
facecolor='#e75840')
plt.xlabel('Episode')
plt.ylabel('Leader reward')
plt.figure(3, figsize=(8, 4), dpi=150)
plt.margins(x=0)
plt.plot(np.arange(len(all_ep_F_mean)), all_ep_F_mean, label='MADDPG', color='#e75840')
plt.fill_between(np.arange(len(all_ep_F_mean)), all_ep_F_max, all_ep_F_min, alpha=0.6,
facecolor='#e75840')
plt.xlabel('Episode')
plt.ylabel('Follower reward')
plt.legend()
plt.show()
env.close()
else:
print('MADDPG测试中...')
aa = Actor()
checkpoint_aa = torch.load(filedir + "\\Path_DDPG_actor_new.pth")
aa.actor_estimate_eval.load_state_dict(checkpoint_aa['net'])
bb = Actor()
checkpoint_bb = torch.load(filedir + "\\Path_DDPG_actor_1_new.pth")
bb.actor_estimate_eval.load_state_dict(checkpoint_bb['net'])
action = np.zeros((N_Agent + M_Enemy, action_number))
win_times = 0
average_FKR = 0
average_timestep = 0
average_integral_V = 0
average_integral_U = 0
all_ep_V, all_ep_U, all_ep_T, all_ep_F = [], [], [], []
for j in range(TEST_EPIOSDE):
state = env.reset()
total_rewards = 0
integral_V = 0
integral_U = 0
v, v1 = [], []
for timestep in range(EP_LEN):
for i in range(N_Agent):
action[i] = aa.choose_action(state[i])
for i in range(M_Enemy):
action[i + 1] = bb.choose_action(state[i + 1])
# action[0] = aa.choose_action(state[0])
# action[1] = bb.choose_action(state[1])
new_state, reward, done, win, team_counter,d = env.step(action) # 执行动作
if win:
win_times += 1
v.append(state[0][2])
v1.append(state[1][2])
integral_V += state[0][2]
integral_U += abs(action[0]).sum()
total_rewards += reward.mean()
state = new_state
if RENDER:
env.render()
if done:
break
FKR = team_counter / timestep
average_FKR += FKR
average_timestep += timestep
average_integral_V += integral_V
average_integral_U += integral_U
print("Score", total_rewards)
all_ep_V.append(integral_V)
all_ep_U.append(integral_U)
all_ep_T.append(timestep)
all_ep_F.append(FKR)
# print('最大编队保持率',FKR)
# print('最短飞行时间',timestep)
# print('最短飞行路程', integral_V)
# print('最小能量损耗', integral_U)
# plt.plot(np.arange(len(v)), v)
# plt.plot(np.arange(len(v1)), v1)
# plt.show()
print('任务完成率', win_times / TEST_EPIOSDE)
print('平均最大编队保持率', average_FKR / TEST_EPIOSDE)
print('平均最短飞行时间', average_timestep / TEST_EPIOSDE)
print('平均最短飞行路程', average_integral_V / TEST_EPIOSDE)
print('平均最小能量损耗', average_integral_U / TEST_EPIOSDE)
d = {"all_ep_V": all_ep_V, "all_ep_U": all_ep_U, "all_ep_T": all_ep_T, "all_ep_F": all_ep_F, }
f = open(shoplistfile_test, 'wb') # 二进制打开,如果找不到该文件,则创建一个
pkl.dump(d, f, pkl.HIGHEST_PROTOCOL) # 写入文件
f.close()
env.close()
if __name__ == '__main__':
main()
5.3 main.py
是作者测试训练完评估权重的演示demo
# -*- coding: utf-8 -*-
#开发者:Bright Fang
#开发时间:2023/7/30 18:13
from rl_env.path_env import RlGame
# import pygame
# from assignment import constants as C
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from matplotlib import pyplot as plt
import os
import pickle as pkl
shoplistfile_test = "MASAC_compare" #保存文件数据所在文件的文件名
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
N_Agent=1
M_Enemy=4
RENDER=True
TRAIN_NUM = 1
TEST_EPIOSDE=100
env = RlGame(n=N_Agent,m=M_Enemy,render=RENDER).unwrapped
state_number=7
action_number=env.action_space.shape[0]
max_action = env.action_space.high[0]
min_action = env.action_space.low[0]
EP_MAX = 500
EP_LEN = 1000
def main():
run(env)
def run(env):
print('随机测试中...')
action = np.zeros((N_Agent+M_Enemy, action_number))
win_times = 0
average_FKR=0
average_timestep=0
average_integral_V=0
average_integral_U= 0
all_ep_V,all_ep_U,all_ep_T,all_ep_F=[],[],[],[]
for j in range(TEST_EPIOSDE):
state = env.reset()
total_rewards = 0
integral_V=0
integral_U=0
v,v1=[],[]
for timestep in range(EP_LEN):
for i in range(N_Agent+M_Enemy):
action[i] = env.action_space.sample()
# action[0] = aa.choose_action(state[0])
# action[1] = bb.choose_action(state[1])
new_state, reward,done,win,team_counter,d = env.step(action) # 执行动作
if win:
win_times += 1
v.append(state[0][2])
v1.append(state[1][2])
integral_V+=state[0][2]
integral_U+=abs(action[0]).sum()
total_rewards += reward.mean()
state = new_state
if RENDER:
env.render()
if done:
break
FKR=team_counter/timestep
average_FKR += FKR
average_timestep += timestep
average_integral_V += integral_V
average_integral_U += integral_U
print("Score", total_rewards)
all_ep_V.append(integral_V)
all_ep_U.append(integral_U)
all_ep_T.append(timestep)
all_ep_F.append(FKR)
# print('最大编队保持率',FKR)
# print('最短飞行时间',timestep)
# print('最短飞行路程', integral_V)
# print('最小能量损耗', integral_U)
# plt.plot(np.arange(len(v)), v)
# plt.plot(np.arange(len(v1)), v1)
# plt.show()
print('任务完成率',win_times / TEST_EPIOSDE)
print('平均最大编队保持率', average_FKR/TEST_EPIOSDE)
print('平均最短飞行时间', average_timestep/TEST_EPIOSDE)
print('平均最短飞行路程', average_integral_V/TEST_EPIOSDE)
print('平均最小能量损耗', average_integral_U/TEST_EPIOSDE)
# d = {"all_ep_V": all_ep_V,"all_ep_U": all_ep_U,"all_ep_T": all_ep_T,"all_ep_F": all_ep_F,}
# f = open(shoplistfile_test, 'wb') # 二进制打开,如果找不到该文件,则创建一个
# pkl.dump(d, f, pkl.HIGHEST_PROTOCOL) # 写入文件
# f.close()
env.close()
if __name__ == '__main__':
main()
第四处是环境配置位置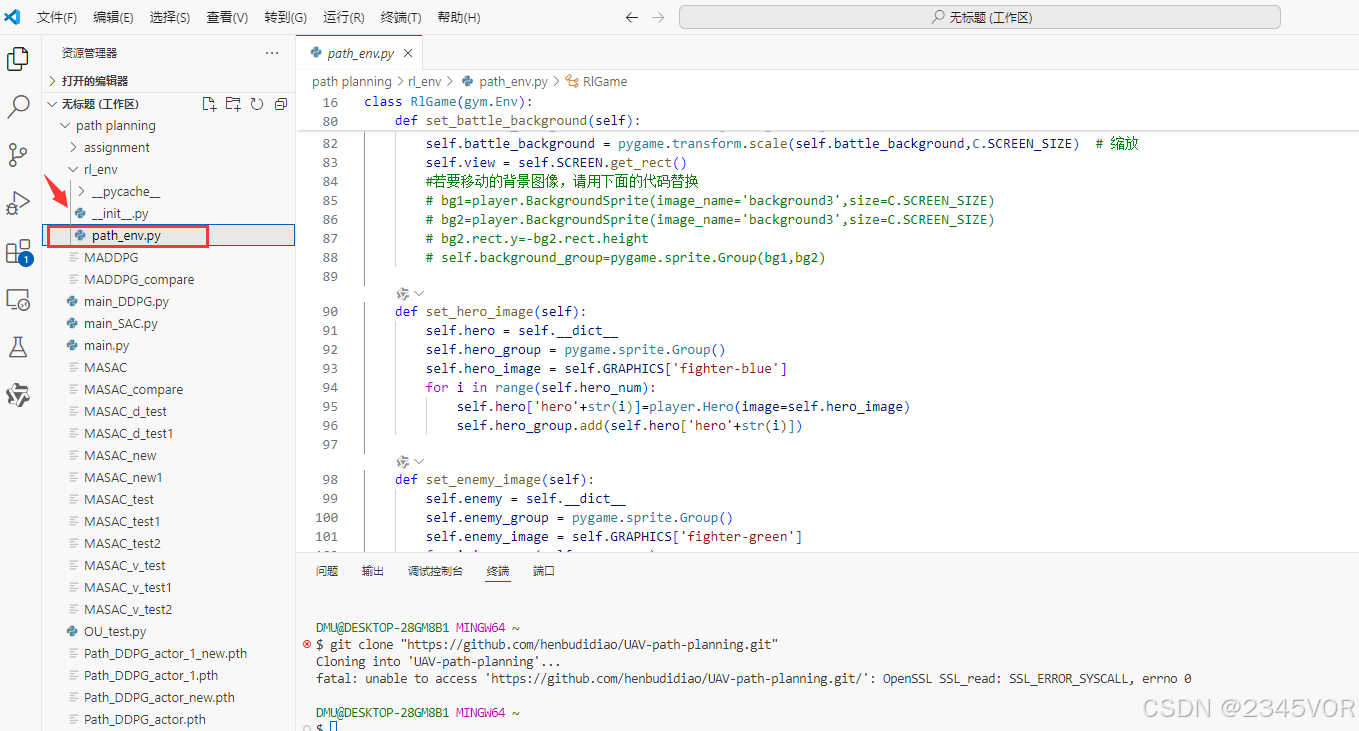
5.4. path_env.py
环境显示调用的类与方法
# -*- coding: utf-8 -*-
#开发者:Bright Fang
#开发时间:2023/7/20 23:30
import numpy as np
import os
import copy
import gym
from assignment import constants as C
from gym import spaces
import math
import random
import pygame
from assignment.components import player
from assignment import tools
from assignment.components import info
class RlGame(gym.Env):
def __init__(self, n,m,render=False):
self.hero_num = n
self.enemy_num = m
self.obstacle_num=1
self.goal_num=1
self.Render=render
self.game_info = {
'epsoide': 0,
'hero_win': 0,
'enemy_win': 0,
'win': '未知',
}
if self.Render:
pygame.init()
pygame.mixer.init()
self.SCREEN = pygame.display.set_mode((C.SCREEN_W, C.SCREEN_H))
pygame.display.set_caption("基于深度强化学习的空战场景无人机路径规划软件")
self.GRAPHICS = tools.load_graphics(".\\assignment\\source\\image")
self.SOUND = tools.load_sound(".\\assignment\\source\\music")
self.clock = pygame.time.Clock()
self.mouse_pos=(100,100)
pygame.time.set_timer(C.CREATE_ENEMY_EVENT, C.ENEMY_MAKE_TIME)
# self.res, init_extra, update_extra, skip_override, waypoints = simulate(filename='')
# else:
# self.dispaly=None
low = np.array([-1,-1])
high=np.array([1,1])
# self.action_space =spaces.Discrete(21)
# self.action_space = spaces.Discrete(2)
self.action_space=spaces.Box(low=low,high=high,dtype=np.float32)
# self.action_space = [spaces.Discrete(2),spaces.Discrete(2),spaces.Discrete(2),spaces.Discrete(2),
# spaces.Discrete(2),spaces.Discrete(2),spaces.Discrete(2),spaces.Discrete(2),
# spaces.Discrete(2),spaces.Discrete(2),spaces.Discrete(2),spaces.Discrete(2),
# spaces.Discrete(2),spaces.Discrete(2),spaces.Discrete(2),spaces.Discrete(2),
# spaces.Discrete(2),spaces.Discrete(2),spaces.Discrete(2),spaces.Discrete(2),]
def start(self):
# self.game_info=game_info
self.finished=False
# self.next='game_over'
self.set_battle_background()#战斗的背景
self.set_enemy_image()
self.set_hero_image()
self.set_obstacle_image()
self.set_goal_image()
self.info = info.Info('battle_screen',self.game_info)
# self.state = 'battle'
self.counter_1 = 0
self.counter_hero = 0
self.enemy_counter=0
self.enemy_counter_1 = 0
#又定义了一个参数,为了放在start函数里重置
self.enemy_num_start=self.enemy_num
self.trajectory_x,self.trajectory_y=[],[]
self.enemy_trajectory_x,self.enemy_trajectory_y=[[] for i in range(self.enemy_num)],[[] for i in range(self.enemy_num)]
# RL状态
# self.hero_state = np.zeros((self.hero_num, 4))
# self.hero_α = np.zeros((self.hero_num, 1))
self.uav_obs_check= np.zeros((self.hero_num, 1))
def set_battle_background(self):
self.battle_background = self.GRAPHICS['background']
self.battle_background = pygame.transform.scale(self.battle_background,C.SCREEN_SIZE) # 缩放
self.view = self.SCREEN.get_rect()
#若要移动的背景图像,请用下面的代码替换
# bg1=player.BackgroundSprite(image_name='background3',size=C.SCREEN_SIZE)
# bg2=player.BackgroundSprite(image_name='background3',size=C.SCREEN_SIZE)
# bg2.rect.y=-bg2.rect.height
# self.background_group=pygame.sprite.Group(bg1,bg2)
def set_hero_image(self):
self.hero = self.__dict__
self.hero_group = pygame.sprite.Group()
self.hero_image = self.GRAPHICS['fighter-blue']
for i in range(self.hero_num):
self.hero['hero'+str(i)]=player.Hero(image=self.hero_image)
self.hero_group.add(self.hero['hero'+str(i)])
def set_enemy_image(self):
self.enemy = self.__dict__
self.enemy_group = pygame.sprite.Group()
self.enemy_image = self.GRAPHICS['fighter-green']
for i in range(self.enemy_num):
self.enemy['enemy'+str(i)]=player.Enemy(image=self.enemy_image)
self.enemy_group.add(self.enemy['enemy'+str(i)])
def set_hero(self):
self.hero = self.__dict__
self.hero_group = pygame.sprite.Group()
for i in range(self.hero_num):
self.hero['hero'+str(i)]=player.Hero()
self.hero_group.add(self.hero['hero'+str(i)])
def set_enemy(self):
self.enemy = self.__dict__
self.enemy_group = pygame.sprite.Group()
for i in range(self.enemy_num):
self.enemy['enemy'+str(i)]=player.Enemy()
self.enemy_group.add(self.enemy['enemy'+str(i)])
def set_obstacle_image(self):
self.obstacle = self.__dict__
self.obstacle_group = pygame.sprite.Group()
self.obstacle_image = self.GRAPHICS['hole']
for i in range(self.obstacle_num):
self.obstacle['obstacle'+str(i)]=player.Obstacle(image=self.obstacle_image)
self.obstacle_group.add(self.obstacle['obstacle'+str(i)])
def set_obstacle(self):
self.obstacle = self.__dict__
self.obstacle_group = pygame.sprite.Group()
for i in range(self.obstacle_num):
self.obstacle['obstacle'+str(i)]=player.Obstacle()
self.obstacle_group.add(self.obstacle['obstacle'+str(i)])
def set_goal_image(self):
self.goal = self.__dict__
self.goal_group = pygame.sprite.Group()
self.goal_image = self.GRAPHICS['goal']
for i in range(self.goal_num):
self.goal['goal'+str(i)]=player.Goal(image=self.goal_image)
self.goal_group.add(self.goal['goal'+str(i)])
def set_goal(self):
self.goal = self.__dict__
self.goal_group = pygame.sprite.Group()
for i in range(self.goal_num):
self.goal['goal'+str(i)]=player.Goal()
self.goal_group.add(self.goal['goal'+str(i)])
def update_game_info(self):#死亡后重置数据
self.game_info['epsoide'] += 1
self.game_info['enemy_win'] = self.game_info['epsoide'] - self.game_info['hero_win']
def reset(self):#reset的仅是环境状态,
# obs=np.zeros((self.n, 4))#这是个二维矩阵,n*2维,现在只考虑一个己方无人机,所以现在是一个一维的
# game_info=self.my_game.state.game_info
# self.my_game.state.start(game_info)
if self.Render:
self.start()
else:
self.set_hero()
self.set_enemy()
self.set_goal()
self.set_obstacle()
self.team_counter = 0
self.done = False
self.hero_state = np.zeros((self.hero_num+self.enemy_num,7))
self.hero_α = np.zeros((self.hero_num, 1))
# self.goal_x,self.goal_y=random.randint(100, 500), random.randint(100, 200)
return np.array([[self.hero0.init_x/1000,self.hero0.init_y/1000,self.hero0.speed/30,self.hero0.theta*57.3/360
,self.goal0.init_x/1000, self.goal0.init_y/1000,0],
[self.enemy0.init_x / 1000, self.enemy0.init_y / 1000, self.enemy0.speed / 30,
self.enemy0.theta * 57.3 / 360
, self.hero0.init_x/1000, self.hero0.init_y/1000,self.hero0.speed / 30],
[self.enemy1.init_x / 1000, self.enemy1.init_y / 1000, self.enemy1.speed / 30,
self.enemy1.theta * 57.3 / 360
, self.hero0.init_x / 1000, self.hero0.init_y / 1000, self.hero0.speed / 30],
[self.enemy2.init_x / 1000, self.enemy2.init_y / 1000, self.enemy2.speed / 30,
self.enemy2.theta * 57.3 / 360
, self.hero0.init_x / 1000, self.hero0.init_y / 1000, self.hero0.speed / 30],
[self.enemy3.init_x / 1000, self.enemy3.init_y / 1000, self.enemy3.speed / 30,
self.enemy3.theta * 57.3 / 360
, self.hero0.init_x / 1000, self.hero0.init_y / 1000, self.hero0.speed / 30],
])#np.array([self.my_game.state.hero['hero0'].posx/1000,self.my_game.state.hero['hero0'].posy/1000,self.my_game.state.hero['hero0'].speed/2,self.my_game.state.hero['hero0'].theta*57.3/360])#np.zeros((self.n,2)).flatten()
def step(self,action):
dis_1_obs = np.zeros((self.hero_num, 1))
dis_1_goal = np.zeros((self.hero_num+self.enemy_num, 1))
r=np.zeros((self.hero_num+self.enemy_num, 1))
o_flag = 0
o_flag1 = 0
#空气阻力系数
F_k=0.08
#无人机质量,100是像素与现实速度的比例,因为10像素/帧对应现实的100m/s
m=12000/100
#扰动的加速度
F_a=0
#边界奖励
edge_r=np.zeros((self.hero_num, 1))
edge_r_f = np.zeros((self.enemy_num, 1))
#避障奖励
obstacle_r = np.zeros((self.hero_num, 1))
obstacle_r1 = np.zeros((self.enemy_num, 1))
#目标奖励
goal_r = np.zeros((self.hero_num, 1))
# 编队奖励
follow_r = np.zeros((self.enemy_num, 1))
follow_r0 = 0
speed_r=0
# print(self.goal0.init_x)
dis_1_agent_0_to_1=math.hypot(self.hero0.posx - self.enemy0.posx, self.hero0.posy - self.enemy0.posy)
dis_1_agent_0_to_2 = math.hypot(self.hero0.posx - self.enemy1.posx, self.hero0.posy - self.enemy1.posy)
dis_1_agent_0_to_3 = math.hypot(self.hero0.posx - self.enemy2.posx, self.hero0.posy - self.enemy2.posy)
dis_1_agent_0_to_4 = math.hypot(self.hero0.posx - self.enemy3.posx, self.hero0.posy - self.enemy3.posy)
for i in range(self.hero_num+self.enemy_num):
#空气阻力
# self.hero['hero' + str(i)].F=F_k*math.pow(self.hero['hero' + str(i)].speed,2)
# F_a=(self.hero['hero' + str(i)].F/m)*math.cos(self.hero['hero' + str(i)].theta * 57.3)
# 己方与障碍物的碰撞检测
# self.hero['hero' + str(i)].enemies = pygame.sprite.spritecollide(self.hero['hero' + str(i)],
# self.obstacle_group, False)
if i==0:#leader
dis_1_obs[i] = math.hypot(self.hero['hero' + str(i)].posx - self.obstacle0.init_x,
self.hero['hero' + str(i)].posy - self.obstacle0.init_y)
dis_1_goal[i] = math.hypot(self.hero['hero' + str(i)].posx - self.goal0.init_x,
self.hero['hero' + str(i)].posy - self.goal0.init_y)
if self.hero['hero' + str(i)].posx <= C.ENEMY_AREA_X + 50:
edge_r[i] = -1
elif self.hero['hero' + str(i)].posx >= C.ENEMY_AREA_WITH:
edge_r[i] = -1
if self.hero['hero' + str(i)].posy >= C.ENEMY_AREA_HEIGHT:
edge_r[i] = -1
elif self.hero['hero' + str(i)].posy <= C.ENEMY_AREA_Y + 50:
edge_r[i] = -1
if 0 < dis_1_agent_0_to_1 < 50 and dis_1_agent_0_to_2<50 and dis_1_agent_0_to_3<50and dis_1_agent_0_to_4<50:
follow_r0=0
self.team_counter+=1
if abs(self.hero0.speed-self.enemy0.speed)<1:
speed_r=1
else:
follow_r0=-0.001*dis_1_agent_0_to_1
if dis_1_goal[i] < 40 and not self.hero['hero' + str(i)].dead:
goal_r[i] = 1000.0
self.hero['hero' + str(i)].win = True
self.hero['hero' + str(i)].die()
self.done= True
# self.game_info['hero_win'] += 1
# self.update_game_info()
print('aa')
# elif dis_1_goal < 100:
# r = 1.0
elif dis_1_obs[i] < 20 and not self.hero['hero' + str(i)].dead:
o_flag = 1
obstacle_r[i] = -500
self.hero['hero' + str(i)].die()
self.hero['hero' + str(i)].win = False
self.done = True
# self.update_game_info()
print('gg')
elif dis_1_obs[i] < 40 and not self.hero['hero' + str(i)].dead:
o_flag = 1
# print(-100000*math.pow(1/dis_1_obs[i],2))
obstacle_r[i] = -2#-100000*math.pow(1/dis_1_obs[i],2)
elif not self.hero['hero' + str(i)].dead:
# print(math.exp(100/dis_1_goal[i])/10)
goal_r[i] =-0.001 * dis_1_goal[i]# math.exp(100/dis_1_goal[i])/10
r[i] = edge_r[i] + obstacle_r[i] + goal_r[i]+speed_r+follow_r0
self.hero_state[i] = [self.hero['hero' + str(i)].posx / 1000, self.hero['hero' + str(i)].posy / 1000,
self.hero['hero' + str(i)].speed / 30,
self.hero['hero' + str(i)].theta * 57.3 / 360,
self.goal0.init_x / 1000, self.goal0.init_y / 1000, o_flag]
self.hero['hero' + str(i)].update(action[i], self.Render)
self.trajectory_x.append(self.hero['hero' + str(i)].posx)
self.trajectory_y.append(self.hero['hero' + str(i)].posy)
else:
dis_2_obs = math.hypot(self.enemy['enemy' + str(i-1)].posx - self.obstacle0.init_x,
self.enemy['enemy' + str(i-1)].posy - self.obstacle0.init_y)
dis_1_goal[i] = math.hypot(self.enemy['enemy' + str(i-1)].posx - self.goal0.init_x,
self.enemy['enemy' + str(i-1)].posy- self.goal0.init_y)
if dis_2_obs < 40:
o_flag1 = 1
obstacle_r1 = -2
if self.enemy['enemy' + str(i-1)].posx <= C.ENEMY_AREA_X + 50:
edge_r_f[i-1] = -1
elif self.enemy['enemy' + str(i-1)].posx >= C.ENEMY_AREA_WITH:
edge_r_f[i-1] = -1
if self.enemy['enemy' + str(i-1)].posy >= C.ENEMY_AREA_HEIGHT:
edge_r_f[i-1] = -1
elif self.enemy['enemy' + str(i-1)].posy <= C.ENEMY_AREA_Y + 50:
edge_r_f[i-1] = -1
if 0 < dis_1_agent_0_to_1 < 50 and dis_1_goal[0]<dis_1_goal[1]:
# follow_r[i-1]=5-abs(self.hero0.theta-self.enemy0.theta)
# print('hhh')
if abs(self.hero0.speed-self.enemy0.speed)<1:
speed_r=1
# print('hh')
else:
follow_r[i-1]=-0.001*dis_1_agent_0_to_1
r[i] = follow_r[i-1]+speed_r
self.hero_state[i] = [self.enemy['enemy' + str(i-1)].posx / 1000, self.enemy['enemy' + str(i-1)].posy / 1000,
self.enemy['enemy' + str(i-1)].speed / 30,
self.enemy['enemy' + str(i-1)].theta * 57.3 / 360,
self.hero0.posx / 1000, self.hero0.posy / 1000,self.hero0.speed / 30 ]
self.enemy['enemy' + str(i-1)].update(action[i], self.Render)
self.enemy_trajectory_x[i-1].append(self.enemy['enemy' + str(i-1)].posx)
self.enemy_trajectory_y[i-1].append(self.enemy['enemy' + str(i-1)].posy)
# print(self.hero_state[i])
# init_to_goal=math.atan2((-150+self.hero['hero'+str(i)].init_y),(200-self.hero['hero'+str(i)].init_x))
# uav_to_goal = math.atan2((-self.goal0.init_y + self.hero['hero' + str(i)].posy), (self.goal0.init_x - self.hero['hero' + str(i)].posx))
# uav_to_obstacle = math.atan2((-self.obstacle0.init_y + self.hero['hero' + str(i)].posy), (self.obstacle0.init_x - self.hero['hero' + str(i)].posx))
# self.hero_α[i] = 0.1*abs(uav_to_obstacle - self.hero['hero' + str(i)].theta)
# 自己更新位置
# self.hero_group.update(action[0], action[1],self.Render)
hero_state = copy.deepcopy(self.hero_state)
done = copy.deepcopy(self.done)
return hero_state,r,done,self.hero['hero0'].win,self.team_counter,dis_1_agent_0_to_1
def render(self):
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.display.quit()
quit()
elif event.type == pygame.MOUSEMOTION:
self.mouse_pos = pygame.mouse.get_pos()
elif event.type == C.CREATE_ENEMY_EVENT:
C.ENEMY_FLAG = True
# 画背景
self.SCREEN.blit(self.battle_background, self.view)
# 文字显示
self.info.update(self.mouse_pos)
# 画图
self.draw(self.SCREEN)
pygame.display.update()
self.clock.tick(C.FPS)
def draw(self,surface):
# self.background_group.draw(surface)
#敌占区的矩形
pygame.draw.rect(surface, C.BLACK, C.ENEMY_AREA, 3)
#目标星星
# pygame.draw.polygon(surface, C.GREEN,[(200, 135), (205, 145), (215, 145), (210, 155), (213, 165), (200, 160), (187, 165), (190, 155), (185, 145), (195, 145)])
pygame.draw.circle(surface, C.RED, (self.goal0.init_x, self.goal0.init_y), 1)
pygame.draw.circle(surface, C.RED, (self.goal0.init_x, self.goal0.init_y), 40,1)
# pygame.draw.circle(surface, C.GREEN, (self.goal0.init_x, self.goal0.init_y),100, 1)
pygame.draw.circle(surface, C.BLACK, (self.obstacle0.init_x, self.obstacle0.init_y), 20, 1)
# 画轨迹
for i in range(1, len(self.trajectory_x)):
pygame.draw.line(surface, C.BLUE, (self.trajectory_x[i - 1], self.trajectory_y[i - 1]), (self.trajectory_x[i], self.trajectory_y[i]))
for j in range(self.enemy_num):
for i in range(1, len(self.trajectory_x)):
pygame.draw.line(surface, C.GREEN, (self.enemy_trajectory_x[j][i - 1], self.enemy_trajectory_y[j][i - 1]),
(self.enemy_trajectory_x[j][i], self.enemy_trajectory_y[j][i]))
#障碍物
# pygame.draw.circle(surface, C.BLACK, (250, 300), 20)
# 画自己
self.hero_group.draw(surface)
self.enemy_group.draw(surface)
#障碍物
self.obstacle_group.draw(surface)
# 目标星星
self.goal_group.draw(surface)
#画文字信息
self.info.draw(surface)
def close(self):
pygame.display.quit()
quit()
然后直接运行main_SAC.py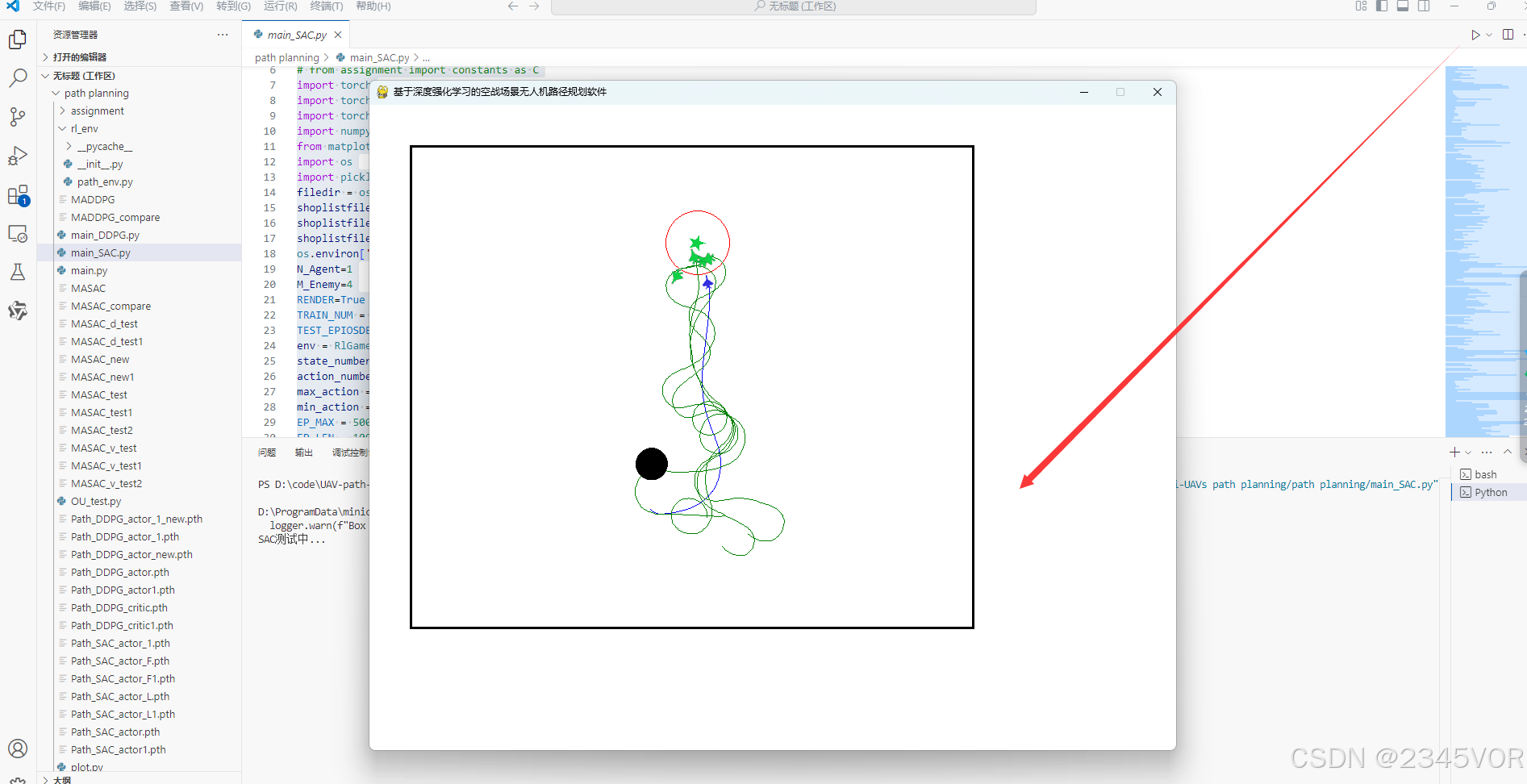
完美!🤞🤞🤞💕💕💕
6. 总结
通过本【强化学习环境配置+github demo复现】,您应该能够从零到一入门强化学习啦,也完成无人机的强化学习demo复现。从而实现对外部世界进行感知,充分认识这个有机与无机的环境,科学地合理地进行创作和发挥效益,然后为人类社会发展贡献一点微薄之力。🤣🤣🤣
- 我会持续更新对应专栏博客,非常期待你的三连!!!🎉🎉🎉
- 如果鹏鹏有哪里说的不妥,还请大佬多多评论指教!!!👍👍👍
- 下面有我的🐧🐧🐧群推广,欢迎志同道合的朋友们加入,期待与你的思维碰撞😘😘😘

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 40
40 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)