LLM:NLP,LM,seq2seq,ELMo
2w字吐血整理,GPT入门材料(NLP,LM,词嵌入,Word2vec,N-gram,基于RNN的语言模型,seq2seq,Decoder结构,Attention,自监督学习,预训练)。包括:基础知识,底层原理,数学公式表示,刁钻问题解答。
1,自然语言处理(NLP)
1.1,NLP基本任务
文本分类:在处理中文文本时,由于中文语言的特点,词与词之间没有像英文那样的明显分隔(如空格),所以无法直接通过空格来确定词的边界。正确的分词结果对于后续的词性标注、实体识别、句法分析等任务至关重要。
英文输入:The cat sits on the mat. 英文切割输出:[The | cat | sits | on | the | mat] 中文输入:今天天气真好,适合出去游玩. 中文切割输出:["今天", "天气", "真", "好", ",", "适合", "出去", "游玩", "。"]子词切分:旨在将词汇进一步分解为更小的单位,即子词。子词切分特别适用于处理词汇稀疏问题,即当遇到罕见词或未见过的新词时,能够通过已知的子词单位来理解或生成这些词汇。
输入:unhappiness 不使用子词切分:整个单词作为一个单位,输出:“unhappiness” 使用子词切分(假设BPE算法):单词被分割为:“un”、“happi”、“ness”词性标注:为文本中的每个单词分配一个词性标签,如名词、动词、形容词等。
is (动词,Verb,VBZ) park (名词,Noun,NN)文本分类:将文本分为不同的预定义类别,例如情感分类(积极情感还是消极情感,是否具有攻击性和恶意)、主题分类、垃圾邮件分类等。
文本:“NBA季后赛将于下周开始,湖人和勇士将在首轮对决。” 类别:“体育” 文本:“苹果公司发布了新款 Macbook,配备了最新的m3芯片。” 类别:“科技”实体识别(NER):旨在识别文本中具有特定命名实体的片段,如人名、地名、组织名、时间、日期、货币、数量等。
输入:李雷和韩梅梅是北京市海淀区的居民,他们计划在2024年4月7日去上海旅行。 输出:[("李雷", "人名"), ("韩梅梅", "人名"), ("北京市海淀区", "地名"), ("2024年4月7日", "日期"), ("上海", "地名")]关系抽取:从文本中识别实体之间的语义关系。这些关系可以是因果关系、拥有关系、亲属关系、地理位置关系等。
输入:比尔·盖茨是微软公司的创始人。 输出:[("比尔·盖茨", "创始人", "微软公司")]
语言生成(LG):语言生成(Language Generation)是自然语言处理(NLP)领域中的一种任务,指的是使用计算机生成自然语言文本的过程。语言生成可以应用于多种应用场景,如机器翻译、文本摘要、对话系统、自动生成文章、生成代码、音乐和艺术创作等。
- 基于规则(Rule-based)生成:通过预定义的规则和模板来生成文本。这种方法通常适用于生成简单的文本,如问候语、固定格式的消息等,但对于复杂的文本生成任务来说,Rule-based 方法的扩展性有限。
- 基于统计(Statistical-based)生成:使用统计模型来生成文本,如n-gram语言模型、隐马尔可夫模型(HMM)等。这种方法通过统计文本数据中的频率和概率信息,生成文本序列,但可能会受限于数据的数量和质量。
- 基于机器学习(Machine Learning-based)生成:使用机器学习算法来生成文本。例如,循环神经网络(RNN)和变种(LSTM)被广泛用于生成文本,因为它们能够处理序列数据和捕捉上下文信息。
- 基于深度学习(Deep Learning-based)生成:使用深度学习模型来生成文本,如变种的生成对抗网络(GAN)和变分自编码器(VAE)。这些模型通常能够生成更复杂和高质量的文本,但需要大量的训练数据和计算资源。
- 基于预训练模型(Pre-trained Model-based)生成:利用预训练的模型,如GPT-3、BERT等,来生成文本。这些模型通过大量的无监督训练从大规模文本数据中学习到了丰富的语言知识,可以生成高质量且多样性的文本。
1.2,语言模型(LM)
最小语义单位Token:文本的最小处理单元,它可以是一个单词、一个字符、或者一个字符的子串,具体取决于模型的词汇表和分词方式。
- 词汇表:语言模型有一个预定义的词汇表,包含所有可能的token。模型只能识别并处理词汇表中的token。因此,词汇表的设计和大小对模型的性能和效率有重要影响。
- Embedding(词嵌入):将高维、稀疏的离散数据(如单词、句子、图像等)映射到低维、稠密的连续向量空间的一种方法。
LM(语言模型):通过概率(Token概率)来描述自然语言中单词序列的模型。这种语言模型的过程就是通过已有的Token预测接下来的Token。
- 输入:由于这里输入的是文本信号,而计算机能进入神经网络处理和计算的是数值,所以需要将字符通过一定方式转化为数值。
- 输出:由于所需要输出的部分也是文本,而神经网络的输出是数值类型的(分类问题:二分类问题对应01输出;多分类对应多个01输出;回归问题:对应数值类型输出),所以需要建立神经网络的数值类型输出和最终字符输出的映射关系。
Large Language Model(LLM):
- 参数数量:数十亿甚至上千亿。
- 数据量:庞大的文本数据集,涵盖各种主题和领域。
- 资源需求:需要强大的计算资源,如GPU集群。
【案例】Token:如Her words interested me a lot,这里的word加了一个s就可以衍生出一个words,interest这个单词也可以变成过去式interested(这也可以是个形容词,of course),加了ing也可以变成进行时或者另一个形容词。如果给每一种衍生方式都单独编码,增加one-hot向量的维数,那么就太麻烦了。相比之下,不如只记录word,interest,s,ed,ing这几个Token。
【案例】 语言模型(LM)的经典定义是一种对词元序列(token)的概率分布。假设有一个词元集的词汇表
。语言模型
为每个词元序列
分配一个概率(介于0和1之间的数字):
如果词汇表为{ate, ball, cheese, mouse, the},语言模型可能会分配以下概率:
语言模型应该隐含地赋予"𝗆𝗈𝗎𝗌𝖾 𝗍𝗁𝖾 𝗍𝗁𝖾 𝖼𝗁𝖾𝖾𝗌𝖾 𝖺𝗍𝖾"一个非常低的概率,因为它在语法上是不正确的。由于世界知识的存在,语言模型应该隐含地赋予"𝗍𝗁𝖾 𝗆𝗈𝗎𝗌𝖾 𝖺𝗍𝖾 𝗍𝗁𝖾 𝖼𝗁𝖾𝖾𝗌𝖾"比"𝗍𝗁𝖾 𝖼𝗁𝖾𝖾𝗌𝖾 𝖺𝗍𝖾 𝗍𝗁𝖾 𝗆𝗈𝗎𝗌𝖾"更高的概率。这是因为两个句子在句法上是相同的,但在语义上却存在差异,而语言模型需要具备卓越的语言能力和世界知识,才能准确评估序列的概率。
联合概率:将序列
的联合分布
可以用概率的链式法则表示为:
其中:
是一个给定前面的记号
后,下一个记号
的条件概率分布。
例如:
自回归语言模型:可以利用例如前馈神经网络等方法有效计算出每个条件概率分布
所以,本质上语言模型就是一个基于概率的自回归填字游戏。
其中
是一个控制从语言模型中得到多少随机性的温度参数:
- T=0:确定性地在每个位置
选择最可能的词元
- T=1:从纯语言模型“正常(normally)”采样。
- T=∞:从整个词汇表上的均匀分布中采样。然而,如果仅将概率提高到 1/T 的次方,概率分布可能不会加和到 1。可以通过重新标准化分布来解决这个问题。将标准化版本
称为退火条件概率分布。
【问题】Temperature 为 0 时理论上应该可以复现模型输出,但实际上工程实现中并不能完整复现一模一样的输出,问为什么,如何解决?
- 浮点数精度:神经网络计算涉及大量矩阵运算,浮点数的舍入误差在多层累积后可能影响最终结果。
- 并行计算的非确定性:GPU并行计算中,操作顺序可能不同(如矩阵乘法、reduce操作),导致浮点累加顺序变化。
- 实现细节差异:推理框架(如vLLM、SGLang)或硬件环境(如不同GPU型号)的实现差异,会导致计算路径不一致。PyTorch/TensorFlow的某些算子有多种实现,自动选择的算法可能不同。
- 批次大小变化:不同批次大小会改变计算顺序,引发数值差异。
例如:
,选择最可能的词元,退火后
。
,从整个词汇表上的均匀分布中采样。
对于非自回归的条件生成,可以通过指定某个前缀序列
(称为提示)并采样其余的
(称为补全)来进行条件生成。例如,
的产生的:
如果将温度改为
,可以得到更多的多样性,例如,"its house" 和 "my homework"。条件生成解锁了语言模型通过简单地更改提示就能解决各种任务的能力。
1.3,分词算法
【Tokenizer】Token 是使用 Tokenizer 分词后的结果,Tokenizer 是将文本分割成token的工具。
- word level:将文本按照空格或者标点分割成单词。简单易懂,缺点是无法处理未登录词(jieba)。
- Character level:将文本按照字母级别分割成 token。词汇量要小得多;OOV要少得多,因为每个单词都可以从字符构建。在英文中每个字母本身并没有多大意义,单词才有意义。然而在中文中,每个字比拉丁语言中的字母包含更多的信息;生成的 token 数量极多。
- Sub-word level:子词分词算法依赖于这样一个原则,即不应将常用词拆分为更小的子词,而应将稀有词分解为有意义的子词。
【jieba】jieba 分词基于统计和规则的方法,结合 TF-IDF 算法、TextRank 算法等多种技术,通过构建词图(基于前缀词典)并使用动态规划查找最大概率路径来确定分词结果。此外,对于未登录词,jieba 分词使用了基于汉字成词能力的 HMM(隐马尔科夫模型)和 Viterbi 算法来进行识别和分词。
【BPE】从字符级开始,不断寻找出现频率最高的一对相邻符号,并把它们合并成一个新的 Token。假设 "hug" 出现了10次,"pug" 出现了5次。BPE 会发现 "u" 和 "g" 经常在一起,就把它们合并成 "ug"。
【BBPE】将文本中的字符对(UTF-8 编码中是字节对)进行合并,以形成常见的词汇或字符模式,直到达到预定的词汇表大小或者无法继续合并为止。它和 BPE 的区别在于,BPE 是基于字符级别 character 的,而 BBPE 是基于字节 byte 级别的。
- 跨语言通用性:由于它基于字节级别,因此可以更容易地跨不同语言和脚本进行迁移;
- 减少词汇表大小:通过合并字节对,BBPE 可以生成更通用的子词单元;
- 处理罕见字符 OOV 问题:BBPE 可以更有效地处理罕见字符,因为它不会为每个罕见字符分配单独的词汇表条目,而是将它们作为字节序列处理
【WordPiece】与 BPE 类似,但合并的标准不是频率,而是似然值(Likelihood)。它会评估:如果合并这两个子词,对提升语言模型性能的贡献有多大。被拆分的子词通常会带上 ## 前缀(playing -> play, ##ing)。
【SentencePiece】WordPiece 是将 word 先切分成最小 piece,然后再合新 token。而 SentencePiece 是将 sentence 切分成最小 piece,然后再合并成 token。
- 纯数据驱动:直接从句子中训练分词和去分词模型,不需要预先分词;
- 语言无关:将句子视为 Unicode 字符序列,不依赖于特定语言的逻辑;
- 多种子词算法:支持 BPE 和 Unigram 算法;
- 快速且轻量:分割速度快,内存占用小;
【Unigram】逻辑与 BPE 相反。它先初始化一个巨大的词表,然后根据概率不断“剪枝”,删掉那些对整体语料库概率贡献最小的 Token,直到达到预设的词表大小。
1.4,词嵌入(Embedding)
One-hot向量:早期的NLP常用one-hot编码来表示词向量,假如词典中共有10000个词,则这个one-hot向量长度就是10000,该词在词典中所处位置对应的值为1,其他值为0。one-hot表示方法虽然简单,但其有诸多缺点:
- 词典中的词是不断增多的,比如英语,通过对原有的词增加前缀和后缀,可以变换出很多不同的词,one-hot编码会导致向量维度非常大,且每个向量是稀疏的;
- 不同词的one-hot编码向量是正交的,在向量空间中无法表示近似关系,即使两个含义相近的词,它们的词向量点积也为0。
Distributed representation(思想)可以解决One-Hot编码存在的问题,它的思路是通过训练,将原来One-Hot编码的每个词都映射到一个较短的连续词向量上来。将词汇表里的词用 "Royalty", "Masculinity", "Femininity" 和 "Age"4个维度来表示。
有了用Distributed Representation表示的较短的词向量,就可以较容易的分析词之间的关系了,比如将词的维度降维到2维:
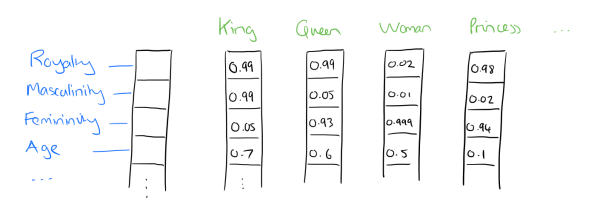
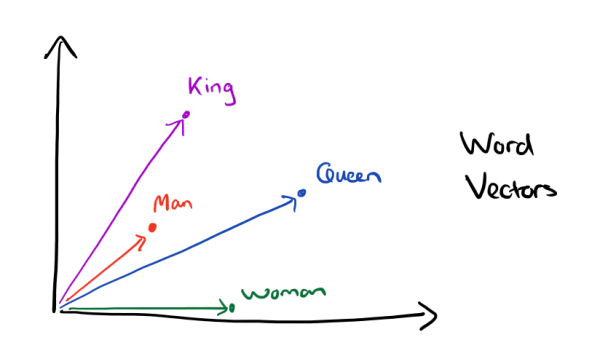
词嵌入(Distributed representation 在词级别的实现):词嵌入就和用RGB表示颜色一样,用维度有限的稠密的向量来表示所有的词汇。将高维、稀疏的离散数据(如单词、句子、图像等)映射到低维、稠密的连续向量空间的一种方法。传统的Transformer中,词嵌入有512维;BERT中,词嵌入有768维和1024维两个版本。此外,词嵌入中的向量的元素数字好像会更加意义不明。RGB代表三种颜色各自的灰度,但是词向量中的数字,除了计算机外就没人能看懂了。
通过把One-hot向量通过一个权重矩阵投射到词嵌入里:对于一个有3000个词汇量的词典V,每一个词都是3000维的一个稀疏向量。对于每一个词,乘一个3000*512的权重矩阵,最终就得到一个512维的向量了。
1.5,Word2vec
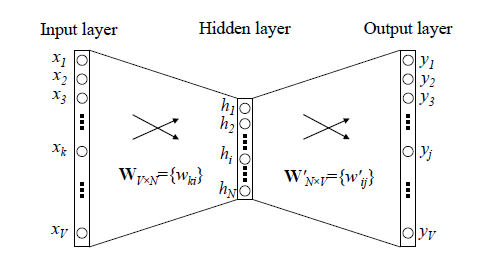
Word2vec 使用一个1层的神经网络模型,从大型的文本语料库中学习单词关联,将自然语言中的单词转换为数学向量。它可以将单词之间的关系表示为向量空间中的距离和方向,从而使得单词的语义信息可以用数学方式表示和处理。
Word2Vec 的输入是采用 One-Hot 编码的词汇表向量,它的输出也是 One-Hot 编码的词汇表向量。使用所有的样本,训练这个神经元网络,等到收敛之后,从输入层到隐含层的那些权重,便是每一个词的采用 Distributed Representation 的词向量。输入一组单词的 Word Embedding 后的向量便是矩阵
的第
维的词向量,并保持相关关系。
Word2vec的训练方式:
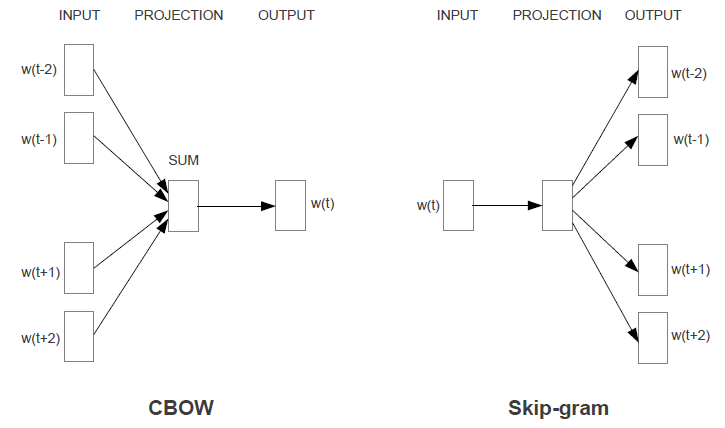
- 连续词袋(CBOW):给定上下文词汇(即目标词周围的词汇),预测目标词。CBOW 适合于小数据集和对训练效率要求较高的场景,但在处理稀有词和捕捉词序信息方面表现不佳。
- Skip-gram:给定一个目标词,预测其上下文词汇。Skip-gram 更适合于需要高质量词向量和处理稀有词的场景,尽管训练时间较长,但能更好地捕捉词序和语义信息。
Input: There is an apple on the table CBOW: is,an,on,the → apple Skip-gram:apple → is,an,on,the对 Skip-Gram 和 CBOW 都是基于窗口的模型,这意味着语料库的共现统计不能被有效使用,导致次优的嵌入(suboptimal embeddings)。
2,语言生成
2.1,LM 损失函数
对语言模型而言,标准目标是最大化训练数据的对数似然:给定前缀,最大化下一个 token 的真实概率。直观上,就是让模型尽可能复现数据分布。
熵:用于衡量将样本
编码(压缩)成比特串所需的预期比特数的度量。例如,"the mouse ate the cheese" 可能会被编码成 "0001110101"。熵的值越小,表明序列的结构性越强,编码的长度就越短。直观地理解,
可以视为用于表示出现概率为
的元素
的编码的长度。
例如,如果
,就需要分配
个比特(或等价地,
个自然单位)。
交叉熵:交叉熵用于评估一个分布
用来近似目标分布
【困惑度】对于一个 token 序列
,困惑度衡量模型预测该序列的"惊讶程度",PPL 越小说明模型对预测越有把握,模型生成的文本就越确定、越连贯。
- 如果删除
后困惑度上升很多 → token很重要
- 如果删除
【困惑度-对数形式】为防止概率连乘导致的数值下溢(数值变得无限趋近于 0),取对数将其转化为与交叉熵的关系:
【KL散度】https://shao12138.blog.csdn.net/article/details/140842362#t14
【问题】KL散度和交叉熵的关系?交叉熵(总成本) = 理论最低成本(熵) + 因为预测不准而多花的成本(KL散度)
2.2,基于统计学的语言生成:N-gram
马尔科夫假设:假设一个词的出现不依赖于前面的全部词,而是仅仅依赖它前面的几个词。以三元语言模型(Trigram)为例,如果一个词的出现仅依赖于它前面出现的两个词,那么就称之为三阶马尔科夫假设,对应的语言模型就是三元语言模型:
N-gram:N-gram 模型用于估计给定前 N-1 个词时,第 N 个词的条件概率。假设使用三元语法(3-gram),估计
,其中
是前两个词。
其中,
是三元语法的出现频率,
是二元语法出现的频率。
- 数据稀疏问题:随着 N 的增大,可能的 N-gram 组合数量会急剧增加,导致很多组合在训练数据中从未出现过,从而难以准确估计它们的概率。
- 长距离依赖问题:N-gram 模型只能捕捉相邻 N 个词之间的依赖关系,无法处理更长距离的词语依赖。
- 相关性问题:本质上还是基于词语在语料库Corpus里出现的频率做概率的预测,无法解决相似性的问题。
- 固执问题:根据语料库,n-gram模型会知道有黑车,白车,但预测不出来语料库里没有出现过的黄车。不过死板也未必是坏事,因为它不会去瞎编,只会根据语料库输出黑马,白马,而不说绿马。
2.3,基于FFNN优化 n-gram 模型
神经语言模型:通过词嵌入的方法,可以把文字转化为稠密的、维度有限的向量,从而输入给一个神经网络的能力。根据MLP的万能逼近定理,具有一个隐层的神经网络可以很好的逼近各种函数,非常适合用于拟合概率分布;而语言模型在做下一个词预测的时候,输出的其实也是一个概率分布。因此,神经网络非常适合用于语言模型。
神经语言模型的目标:估计一个句子或词序列
的联合概率:
神经语言模型通过神经网络来近似这些条件概率
。
神经语言模型的类型:前馈神经网络,循环神经网络,长短期记忆网络,Transformer。
- BERT:双向 Transformer 编码器,通过掩蔽语言模型和下一句预测进行预训练。
- GPT:生成式 Transformer,通过语言模型目标(即给定前面的词预测下一个词)进行预训练,擅长文本生成任务。
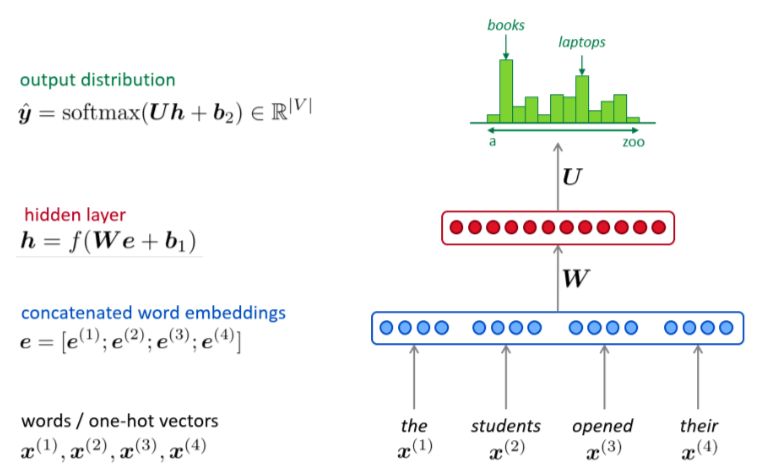
【案例】 用FFNN(前馈神经网络)去优化一个5-gram模型,即以前4个单词为输入,预测下一个词的输出。假设词嵌入是512维,词典中有3000个Token。
- Input Layer:输入的句子就是前4个词元构成的序列,每一个Token都对应一个稀疏的one-hot向量。
- Projection Layer:把上一层输入每个one-hot向量通过乘一个权重矩阵
,映射到词嵌入
,并且把这四个词嵌入给拼起来变成一个2048维的向量。
- Hidden Layer:输入上一层拼出来的2048维向量,以一个权重矩阵
做一个全连接。
- Output Layer: 是一个Softmax层,也是与上一个隐层的输出以矩阵
做全连接,输出一个3000维的,每个元素都为正值的、元素之和为1的向量,即下一个词的概率分布函数了。
只用FFNN去升级n-gram模型还是太low了,并没有克服一个本质缺点:他的窗口数是固定的,每次预测新词
个词。
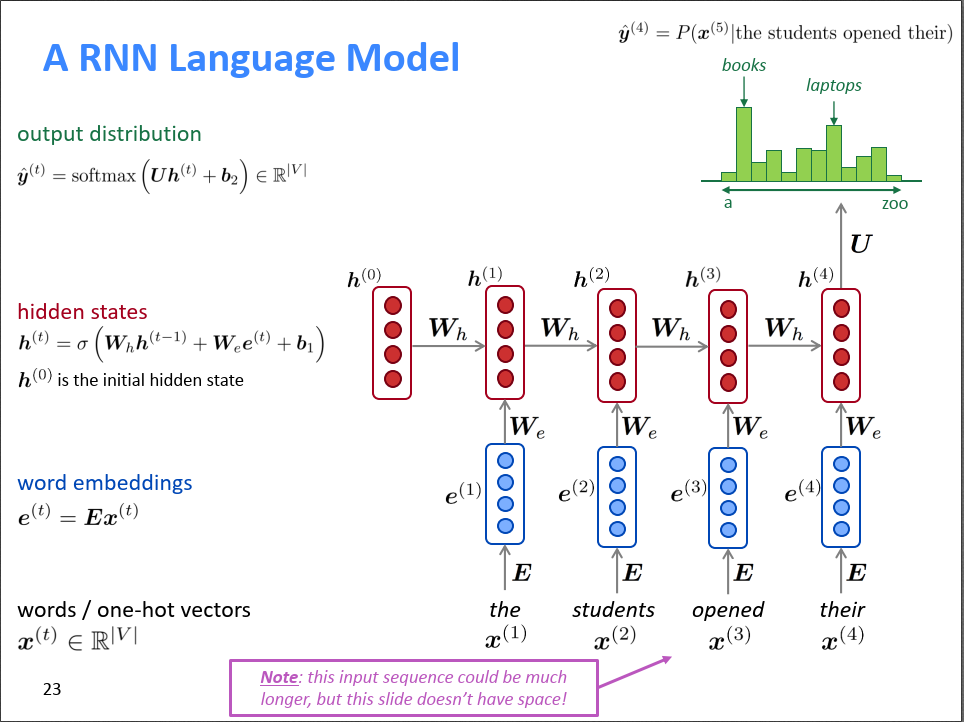
2.4,基于RNN的语言模型
【问题】RNN不同时间步为啥采用相同的参数
?
【答案】在RNN中,不同时间步之间共享参数的原因主要是为了捕捉序列数据的时序关系,减少参数数量,防止模型过拟合。假设我们要用RNN来预测一句话中的下一个单词。在这种任务中,句子是一个序列,每个单词的预测需要依赖前面的单词。RNN通过在每个时间步共享相同的参数(即权重矩阵),可以在不增加模型复杂度的情况下让每个时间步学习和传递序列的上下文信息。
假设我们有一句话 "I enjoy reading books",我们想预测每个单词的下一个单词。在训练过程中,每个时间步的输入(如"I"、"enjoy"等)通过共享的RNN参数进行处理,这样每个时间步就能使用相同的模型逻辑和参数来预测下一个单词。
- 减少参数数量:共享参数让我们在处理一个序列时不必为每个时间步都设定独立的参数,参数总量大大减少,模型更轻量。
- 加强时序依赖:共享参数让模型可以将序列信息从前面传递到后面。比如,通过共享参数,RNN可以理解“enjoy”通常和“reading”有关系,从而提高对下一个单词的预测准确性。
RNN相比于固定窗口的神经网络,其优势是:
- 不受输入长度限制,可以处理任意长度的序列
- 状态
可以感知很久以前的输入的信息,因此理论上可以解决长文本依赖问题。
- 模型大小是固定的,因为不同时刻的参数
都是共享的,不受输入长度的影响。
然而其劣势也很明显:
- 虽然理论上t时刻可以感知很久以前的状态,但实际因为隐状态h的记忆力过强,存在梯度消失的问题,实际上效果远没有想的要好。“虽然RNN理论上能建立长距离依赖关系,但由于梯度爆炸或梯度消失问题,实际上学到的还是短期的依赖关系”(这个可以用LSTM、GRU比较好的缓解)。
- 因为无法并行计算而是串行计算,所以训练起来特别慢(这个哪怕改用Fancy RNN也一样是个问题,解决不了)。
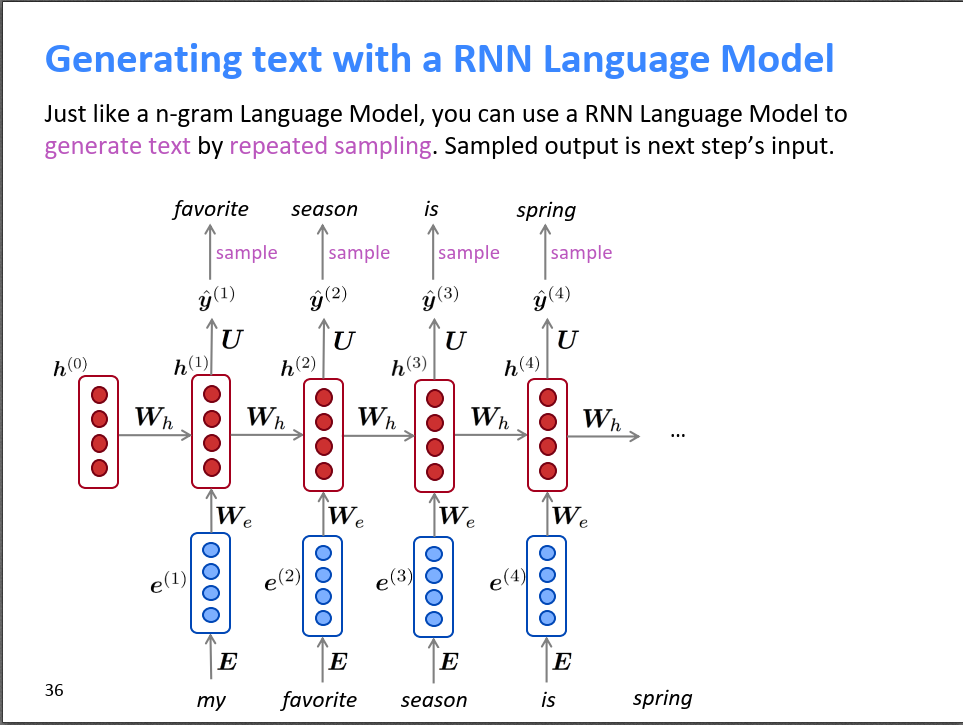
3,seq2seq模型与注意力机制Attention
seq2seq(sequence to sequence)的意义:seq2seq 启发了序列自编码器,这对于后来出现的 NLP 的自监督学习很有意义。而 Encoder-Decoder 的架构也被用在 Transformer里。Attention在一开始是一个对基于 RNN 的 seq2seq 模型的改进技巧。后面 Transformer 放弃 RNN,完全基于注意力机制和前馈神经网络。
3.1,seq2seq架构
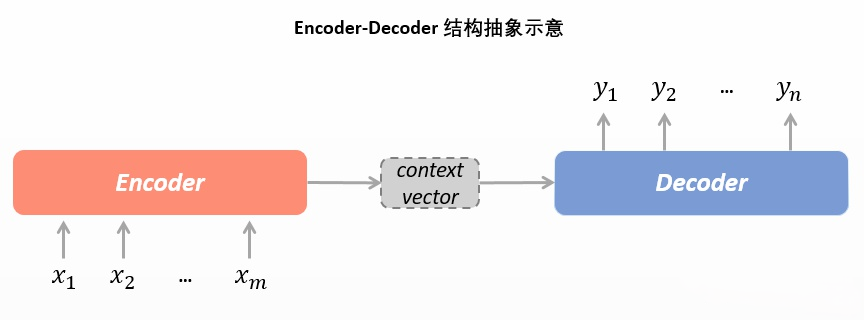
神经机器翻译(NMT)用了 seq2seq 的结构,它的另一个常见的名字是编码-解码器(Encoder-Decoder)结构。
- 编码器 Encoder:读取输入文本,将输入的文本(词序列)整体编码成一个表示向量,而后交给Decoder进行解码。在编码器中,输入的词会变成一个one-hot向量,而后经过Embedding层投射到一个(512维的)向量空间,随后输入到RNN的结构里面去(这个RNN一般是LSTM,而且可以是双向等结构,而且可以有很多层,即把神经网络搞的很深,从而可以去提取更高级的特征)。
- Context Vector:经过了编码器中的RNN的一系列计算,输出来的对源文本整体的一个表示向量。
- 解码器 Decoder:接受编码器编码出的输入(以及标准答案的词序列),自行生成文字。在NMT中,Decoder的输出是预测出的词的序列,但输入在训练和预测时有所不同。
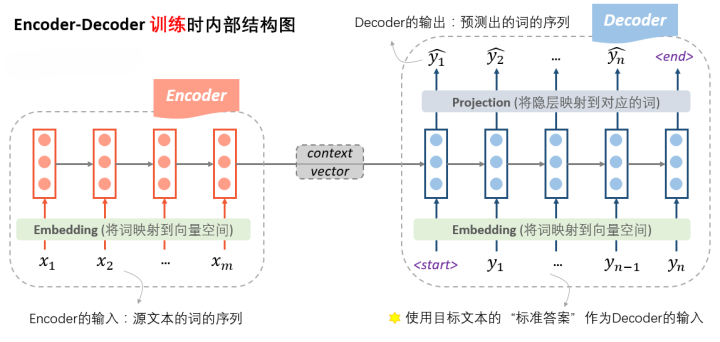
- 训练时:接受编码器给出的表示向量和“标准答案”作为输入。根据第一个输入<start>符号和编码器送来的表示向量,先生成预测结果
。而后,根据第二个输入符号
(而不是前一步的预测结果
。
- 损失函数:前一步最终生成的整个词表的概率分布与标准答案对应的one-hot向量的交叉熵函数,基于这个损失函数对RNN网络做梯度下降,从而让模型预测的越来越准。
预测时:自产自销,每一步预测的结果,都送给下一步作为输入。这样的输出方法我们称为自回归(Auto-regressive)。根据第一个输入<start>符号和编码器送来的表示向量,先生成预测结果
【案例】在 "I like *****" 这个例子中,RNN(递归神经网络)可能会预测出 "I like to",然后继续预测 "I like to eat"。这是因为RNN在每一步预测中仅根据前一步的输出进行下一步的预测。然而,seq2seq(序列到序列模型)在预测"I like"之后,会将"like"纳入上下文进行下一步的预测。通过这种方式,seq2seq模型能够在每一步中利用更多的上下文信息,从而生成更加通顺和符合语法的句子。
seq2seq用于神经翻译,在性能上肯定是非常优秀的,但它依然存在一些问题:
- 领域不匹配。很多时候,我们在Wikipedia、论文、新闻稿等这种比较正式的语料库中训练,那么用来翻译Twitter,甚至在游戏国际服里和外国人的交流这种口语或者非正式语料时,就会有问题。
- 长文本的翻译,目前介绍的都只是翻译一个句子,句子相对来说还是比较短的,如果要翻译一篇论文或一本书,那么怎样考虑非常长距离的上下文依赖关系?
- 对一些惯用语、俚语等翻译容易闹笑话(说曹操,曹操到;笑死我了;等等)
3.2,Decoder结构
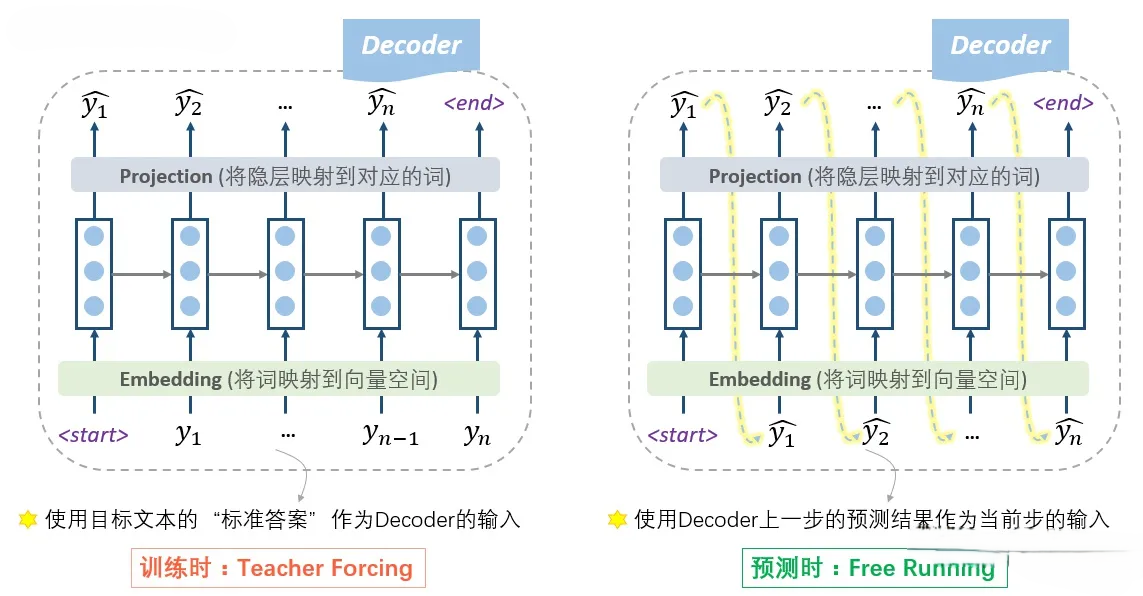
Decoder 的初始隐状态是基于 Encoder RNN 的输出,所以把 Decoder 称为一个条件语言模型。Decoder 在训练时是根据标准答案做输出,而预测时则是在自产自销。
其实,free running 的模式真的不能在训练时使用吗?——当然是可以的!从理论上没有任何的问题,又不是不能跑。但是,在实践中人们发现,这样训练太难了。因为没有任何的引导,一开始会完全是瞎预测,正所谓“一步错,步步错”,而且越错越离谱,这样会导致训练时的累积损失太大(「误差爆炸」问题,exposure bias),训练起来就很费劲。这个时候,如果我们能够在每一步的预测时,让老师来指导一下,即提示一下上一个词的正确答案,decoder就可以快速步入正轨,训练过程也可以更快收敛。因此大家把这种方法称为teacher forcing。所以,这种操作的目的就是为了使得训练过程更容易。
- 训练:根据标准答案来Decode的方式,称为Teacher Forcing。
- 预测:根据上一步的输出作为下一步输入的Decode方式,Free Running。
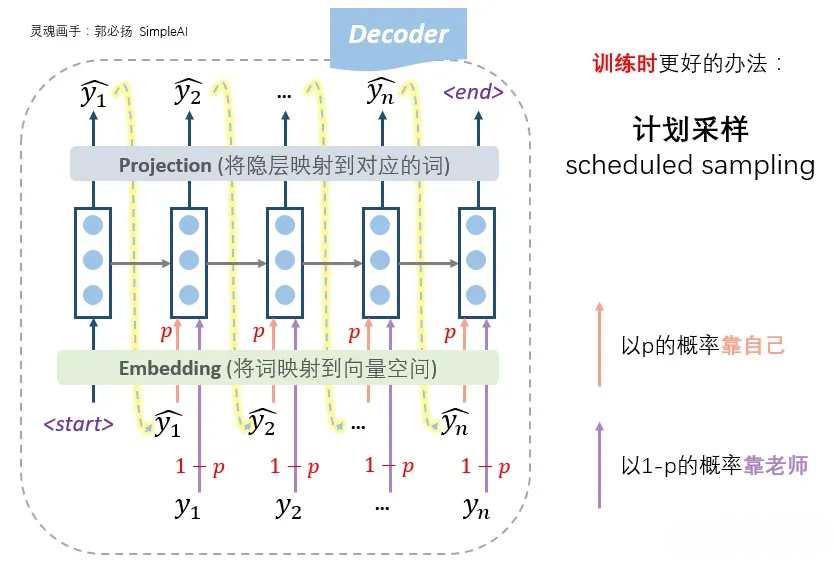
Decoder一上来就瞎预测,就像是高中盲目刷题,在完全没有老师指导的情况下不断积累自己瞎写题产生的经验,可能越走越偏;一直按照标准答案来训练,就像高中刷题时一直看着正确答案来写,如果真上了高考考场,没了标准答案,那就忽然蒙圈了。所以,更好的办法,也是更常用的办法,是老师只给适量的引导,学生也积极学习。
【计划采样】 设置一个概率
【贪心算法】如果每一步都预测出概率最大的那个词,而后输入给下一步,那么这种方式就称为Greedy Decoding。用iPhone打了“不要”两个字,而后一直只点击苹果系统自带输入法推荐的第一个词。就有了下面这段文字:不要再来了,我们的生活方式是什么时候回来呢,我们的生活方式是什么时候回来呢,我们的生活方式是什么时候回来呢,我们的生活方式是什么时候回来呢,我们的生活方式。
【局部最优】Greedy只能保证每一步是最优的,但却无法保证预测出来的句子整体是最优的。特别是如果在
时刻贪心选择的词不是全局最优,会导致
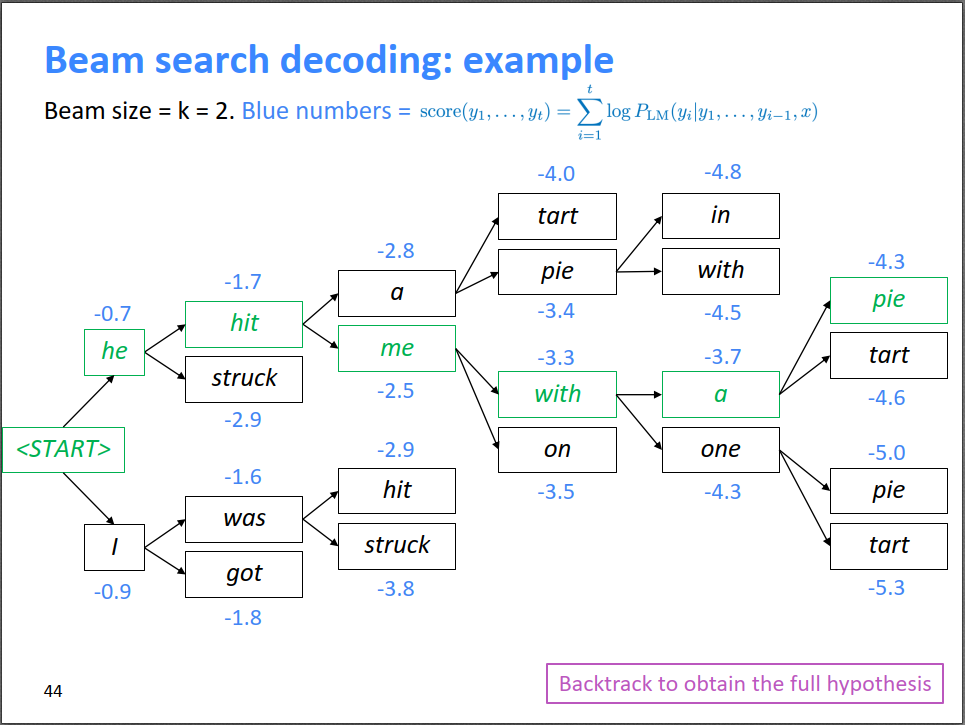
【Beam Search】Beam Search的思想是每一步都多选几个可能的序列作为候选,最后综合考虑,选出最优组合。
- 在Beam search的过程中,不同路径预测输出结束标志符<END>的时间点可能不一样,有些路径可能提前结束了,称为完全路径。暂时把这些完全路径放一边,其他路径接着beam search。
- Beam search的停止条件有很多种,可以设置一个最大的搜索时间步数,也可以设置收集到的最多的完全路径数。当Beam search结束时,需要从 n 条完全路径中选一个打分最高的路径作为最终结果。
- 序列得分函数:
。序列得分全都是负的,而且越高越好。Beam search打分是累加项,越长的序列会打分越低,所以在最终决定要选择哪一句时,需要用长度对打分进行归一化:
Beam search作为一种剪枝策略,并不能保证得到全局最优解,但它能以较大的概率得到全局最优解,同时相比于穷举搜索极大的提高了搜索效率。
- 设定候选集大小 Beam size =
(图中,k=2;实践中,k一般等于5~10)
- 对于每一个时间步
个候选序列。在这
,还指最终会从
- 图中,t=3的时间步时,top2是[he hit]和[I was],所以下一步时是这两个序列继续预测下一个词,并且产生四个概率最大的分支;[he stuck]和[I got]会被剪枝,保证beam search过程的复杂性不会指数放大。
3.3,注意力机制(Attention)
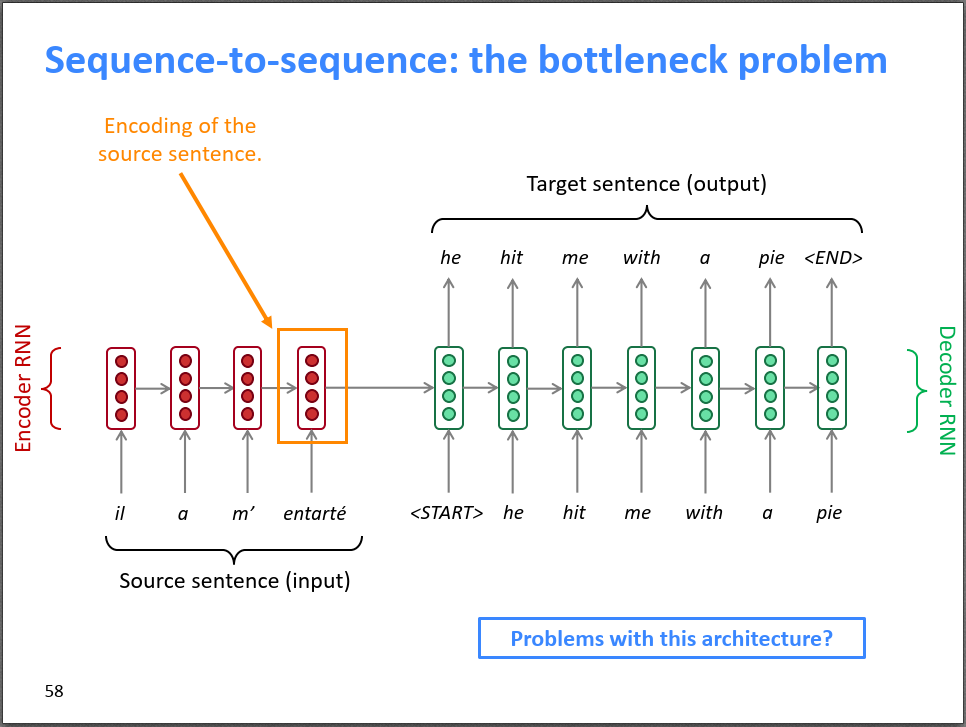
seq2seq的瓶颈:朴素的 seq2seq 神经机器翻译模型中,用 Encoder RNN 的最后一个神经元的隐状态作为 Decoder RNN 的初始隐状态。这里存在一个问题:Encoder 的最后一个隐状态(Context Vector)承载了源句子的所有信息,成为整个模型的“信息”瓶颈。其实不妨去想一想,在 Encoder 的 RNN 中,
(法语,a(表示过去时) m'(我) entarté(hit 的过去时动词变位))编码完的时候,中间都是有隐向量,但最后输入给解码器的只有最终的
。有没有这么一种可能,在解码器输出“hit”这个词的时候,相比于用被更新过的
或
,效果反而会更好?
Attention 直接把 Decoder 中的每一个隐层,和 Encoder 中的每一个隐层,都连接起来了。Encoder RNN 的最后一个隐状态就不再是“信息”瓶颈了。在解码的时候,是一个词一个词生成的。对于每一个词,它不仅可以接受Context Vector(上下文向量)作为辅助信息,也可以通过“直连”线路去获取Encoder RNN中的其他的隐状态的信息,从而Decoder的解码进行辅助。
下图中的 Decoder 的第二个时间步,以 he为输入,并且综合考虑
(法语,a(表示过去时) m'(我) entarté(hit的过去时动词变位))的隐状态。可见,"he"时刻的注意力主要分布在 Encoder 的第2和第4个词上,解码器最终做出了输出hit的决定。
3.4,Attention的数学原理
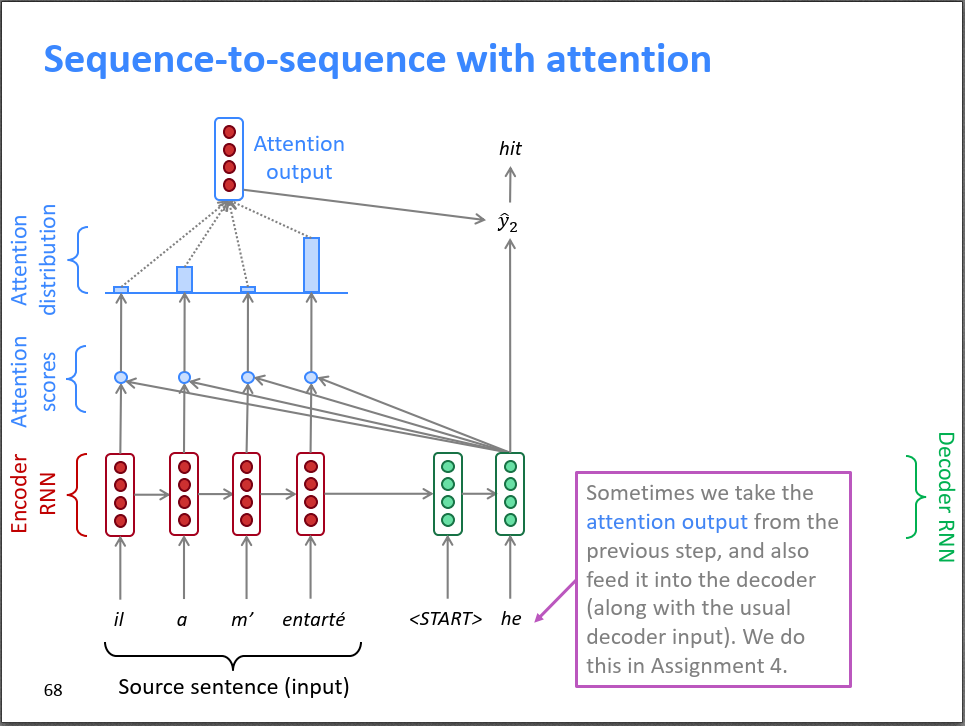
Attention机制则允许解码器在生成每个输出时,根据输入序列的不同部分给予不同的注意力,从而使得模型更好地关注到输入序列中的重要信息。
【Attention机制】在时刻
,同时也有 Encoder 所有时刻的隐状态
。将
使用 Softmax 对这些权重进行归一化(这些隐状态的和为一),就得到Attention distribution(注意力分布)。这个Attention distribution告诉了Decoder在时刻
接下来,对Encoder所有隐状态使用 Attention distribution 进行加权求和,得到 Attention output(注意力输出)
。
把注意力输出
,再进行非线性变换,就得到输出
4,ELMo:Embedding新纪元
4.1,word2vec的局限性
word2vec:word2vec 模型是一种可以用于各种任务的单词级别的表示学习。以单词 stick 为例子,它有非常多的意思:
v. 粘贴;粘住;被接受;(在某物中)卡住,陷住,动不了; (尤指迅速或随手)放置;戳;容忍;将…刺入(或插入); 对…不感兴趣;不再要牌 n. 棍,条,签;(飞机的)操纵杆,驾驶杆;一管,一支(胶棒等); 枝条;批评;(车辆的)变速杆,换挡杆; 枯枝;球棍;指挥棒;条状物;棍状物;柴火棍儿如果使用 word2vec、GloVe 的那些词嵌入,那么不管 stick 的上下文是什么,单词 stick 都将由同一个向量表示。也就是说,对一个词只有一个词嵌入,哪怕这个词其实有超级多的意思。这其实还挺蠢的。所以就有很多学者站出来说:“stick有多种意思,而它的意思则取决于他的上下文。“Let's stick to”和“he pick up a stick so that”中的stick显然是两个意思,却用了同一个词向量。为什么不根据上下文语境进行embedding呢?这样既能捕捉该语境中的含义,又捕捉其他语境信息。”
4.2,语境化词嵌入
语境化词嵌入可以根据词语在句子语境中的含义赋予词语不同的 embedding。在问 ELMo,stick 的词嵌入是什么的时候,ELMo 是不会像 word2vec 一样给一个肯定的答案的,因为ELMo 没有对每个单词使用固定的词嵌入,而是在为每个单词计算 embedding 之前考虑整个句子。ELMo 模型使用的是特定任务上训练好的双向 LSTM(bi-LSTM)进行词嵌入。

4.3,ELMo模型结构
宏观上ELMo分三个主要模块:
- 最底层黄色标记的 Embedding 模块。
- 中间层蓝色标记的两部分双层 LSTM 模块。
- 最上层绿色标记的词向量表征模块。
【字符嵌入层】ELMo 模型使用字符嵌入来表示每个词语,这是通过卷积神经网络来实现的。ELMo 模型中的 CNN 主要用于从输入文本中提取字符级别的特征,这些特征可以捕捉到单词中的前缀和后缀信息,从而提高词向量的表达能力。具体来说,ELMo 使用了一个具有多个卷积核的卷积层,每个卷积核对应一个不同的字符级别窗口大小,通过对输入文本进行卷积操作,可以提取出每个字符级别窗口中的特征。这些特征经过池化和拼接操作后,可以形成一个与输入文本相同长度的字符级别特征向量,作为 LSTM 网络的输入之一。
【双向LSTM层】ELMo 模型使用双向 LSTM(Bi-LTSM)来捕捉词语在上下文中的语义信息。Bi-LSTM 分别从左向右和从右向左对输入序列进行扫描,可以同时考虑到前向和后向的上下文信息,从而生成上下文相关的词向量。在 ELMo 模型中,Bi-LSTM 层由两个独立的LSTM 单元组成,分别从前向和后向两个方向对输入文本进行建模,形成了两个独立的隐藏状态序列。
- 对于左半部分:给定
个
, Language Model 通过前面
个位置的 token 序列来计算第
- 对于右半部分:给定
,Language Model 通过后面
个位置的 token 序列来计算第
【上下文相关词向量层】ELMo 模型通过将字符嵌入和双向 LSTM 层的输出进行拼接,并通过一个线性变换得到最终的上下文相关词向量。这些词向量可以根据输入句子的不同上下文进行调整,从而捕捉到不同上下文中词语的语义信息。
【输出层】ELMo 模型可以通过在上下文相关词向量上添加任务特定的输出层,如全连接层、Softmax 层等,来进行具体的 NLP 任务,如文本分类、命名实体识别等。因为 ELMo 给下游提供的是每个单词的特征形式,所以这一类预训练方法被称为"Feature-based Pre-Training"。
【缺点】ELMo在传统静态 word embedding 方法(Word2Vec,GloVe)的基础上提升了很多, 但是依然存在缺陷,有很大的改进余地。主要有以下两点:
- 第一点:一个很明显的缺点在于特征提取器的选择上,ELMo使用了双向双层LSTM,而不是现在横扫千军的 Transformer,在特征提取能力上肯定是要弱一些的。如果 ELMo的提升提取器选用 Transformer,那么后来的 BERT 的反响将远不如当时那么火爆。
- 第二点:ELMo 选用双向拼接的方式进行特征融合,这种方法肯定不如 BERT 一体化的双向提取特征好。


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 2
2 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)