基于Kmeans的简单聚类分析
·
一、数据展示
数据是文章列表,包含出版社、作者、出版时间、地址、内容等等:

二、数据分析
①分词后,收集词表,分别统计30分位数和99.5分位数位置的单词:


②对文章进行kmeans聚类:
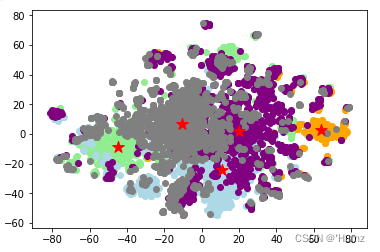
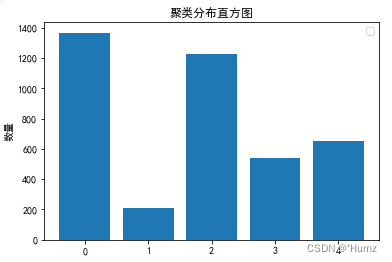
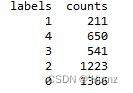
③聚类直方图
三、代码
import pandas as pd
import numpy as np
import nltk
import re
from tqdm import tqdm
from collections import Counter
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
import matplotlib.pyplot as plt
from nltk.corpus import words
from sklearn.decomposition import PCA
from nltk.stem.porter import PorterStemmer
porter_stemmer = PorterStemmer()
# content处理
def content_process(content_list):
processed_content_list = []
all_words = []
# 处理专有名词和数字
for i in tqdm(range(len(content_list))):
try:
# 基础数据清洗
c_list = content_list[i].replace('[', '').replace(']', '').replace('"', '').replace('.', '').replace(',', '').replace(':', '')
# 标记词性
tagged_sentence = nltk.tag.pos_tag(c_list.split())
# 筛选非专有名词、全部小写
edited_sentence = [ re.sub(r"\d+", '', porter_stemmer.stem(word.lower().replace(',', ''))) for word,tag in tagged_sentence if tag != 'NNP']
# 正则删除数字
processed_content_list.append(re.sub(r"\d+", '', ' '.join(edited_sentence)).replace('.', ''))
#将所有单词加入list
all_words.extend(edited_sentence)
except:
print('something went wrong')
return processed_content_list, all_words
# 词汇表简化
def vocab_process(all_words):
count_res = Counter(all_words)
counts = pd.DataFrame(count_res.items(), columns=['words', 'counts'])
counts.reset_index(drop=True, inplace=True)
for i in tqdm(range(len(counts))):
if counts.loc[i, 'words'] in nltk.corpus.words.words('en'):
counts.loc[i, 'counts'] = 0
final_res = counts[counts['counts'] != 0]
final_res.reset_index(drop=True, inplace=True)
# 选取50~95分位数
final_res = final_res.sort_values('counts',ascending=False)
content_list = final_res.iloc[round(len(final_res)*0.005):round(len(final_res)*0.5), :]
content_list.reset_index(drop=True, inplace=True)
content_list.head(10)
content_list.tail(100)
return content_list
# 矢量化处理
def tfidf_process(content_list):
# 去除nan值
new_list=[]
for elem in content_list:
if len(str(elem)) > 5:
new_list.append(elem)
transformer = TfidfVectorizer()
# 将文本中的词语转换成词频矩阵,矩阵元素 a[i][j] 表示j词在i类文本下的词频
vectorizer = CountVectorizer()
# fit_transform是计算tf-idf fit_transform是将文本转为词频矩阵
tfidf_train = transformer.fit_transform(new_list)
tfidf_test = transformer.transform(new_list)
# 将tf-idf矩阵抽取出来,元素w[i][j]表示j词在i类文本中的tf-idf权重
weight = tfidf_test.toarray()
return weight
# 降维
def pca_process(weight, dimension):
print( '原有维度: ', len(weight[0]))
print( '开始降维:')
pca = PCA(n_components=dimension) # 初始化PCA
X = pca.fit_transform(weight) # 返回降维后的数据
print( '降维后维度: ', len(X[0]))
print( X)
return X
# 聚类
def kmeans(X): # X=weight
from sklearn.cluster import KMeans
from sklearn.manifold import TSNE
print( '开始聚类:')
clusterer = KMeans(n_clusters=5, init='k-means++') # 设置聚类模型
# 每个样本所属的簇
y = clusterer.fit_predict(X) # 把weight矩阵扔进去fit一下,输出label
#将原始数据中的索引设置成得到的数据类别
X_out = pd.DataFrame(X,index=clusterer.labels_)
X_out_center = pd.DataFrame(clusterer.cluster_centers_) #找出聚类中心
#将中心放入到数据中,一并tsne,不能单独tsne
X_outwithcenter=X_out.append(X_out_center)
#用TSNE进行数据降维并展示聚类结果
from sklearn.manifold import TSNE
tsne = TSNE()
tsne.fit_transform(X_outwithcenter) #进行数据降维,并返回结果
X_tsne = pd.DataFrame(tsne.embedding_, index = X_outwithcenter.index)
#将index化成原本的数据的index,tsne后index会变化
#根据类别分割数据后,画图
d = X_tsne[X_tsne.index == 0] #找出聚类类别为0的数据对应的降维结果
plt.scatter(d[0], d[1],c='lightgreen',
marker='o' )
d = X_tsne[X_tsne.index == 1]
plt.scatter(d[0], d[1], c='orange',
marker='o' )
d = X_tsne[X_tsne.index == 2]
plt.scatter(d[0], d[1], c='lightblue',
marker='o' )
d = X_tsne[X_tsne.index == 3] #找出聚类类别为0的数据对应的降维结果
plt.scatter(d[0], d[1],c='purple',
marker='o' )
d = X_tsne[X_tsne.index == 4]
plt.scatter(d[0], d[1], c='grey',
marker='o' )
d = X_tsne[X_tsne.index == 5]
plt.scatter(d[0], d[1], c='black',
marker='o' )
#取中心点,画出
d = X_tsne.tail(5)
plt.scatter(d[0], d[1], c='red',s=150,
marker='*' )
plt.show()
# 绘制bar线图
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
figsize = (10,8)#调整绘制图片的比例
jl_data = Counter(y)
jl_df = pd.DataFrame(jl_data.items(), columns=['labels', 'counts'])
plt.bar(jl_df.labels, jl_df.counts)
plt.ylabel('数量') #y轴
plt.title('聚类分布直方图') #图像的名称
plt.legend() #显示labe
if __name__ == '__main__':
# 读取数据
data = pd.read_csv(r'E:\secret\数据集\Dataset.csv')
pd.set_option('expand_frame_repr', False)
# 采样十分之一
data_mini = data.sample(round(len(data)*(1/10)))
content = data_mini['content']
content_list = list(content)
# 文本处理
clean_content, all_words = content_process(content_list)
# 词汇表简化
final_res = vocab_process(all_words)
# 矢量化处理
weight = tfidf_process(content_list)
# 降维降到88维度
pca_res = pca_process(weight, 88)
# 聚类
km_jl = kmeans(pca_res)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)