Pandas进行数据预处理(合并数据)①
Pandas进行数据合并
·
数据合并操作详解
- 数据合并操作详解
- 主键合并
-
- 意图是先打印df3和df4形状,再通过append方法纵向堆叠二者并打印堆叠后数据框形状 ,但因append在新版pandas中被弃用而报错。
- 1.先构建df3和df4两个数据框,然后使用pd.concat函数将它们纵向拼接,最后打印拼接后数据框的形状,成功实现了纵向堆叠并获取形状。
- 2.使用pd.concat函数,这是新版pandas中推荐用于数据框拼接的方式 ,axis = 0明确指定纵向拼接,能正确实现纵向堆叠需求。
- 六、代码4 - 4:使用`merge`方法按主键合并数据
- 结果
- 七、代码4 - 5:使用`join`方法按主键合并数据
- 结果
- 八、代码4 - 6:使用`combine_first`方法重叠合并数据
- 结果
- 总结
数据合并操作详解
在数据分析和处理过程中,数据合并是一项常见且重要的操作。本文将详细介绍使用Python的pandas库进行数据合并的多种方法,并结合具体代码示例进行说明。
一、导入必要的库和动态构建数据目录路径
import pandas as pd
import os
# 获取当前工作目录
data_dir = os.getcwd()
print(data_dir)
代码解释:
在这段代码中,os.getcwd()用来获取当前工作目录,接着直接在这个目录里查找user_all_info.csv文件。同时,使用try-except块来捕获FileNotFoundError异常,若文件不存在就输出错误信息。
二、读取用户所有信息数据
准备工作
# 读取用户所有信息数据
try:
user_all_info = pd.read_csv('./user_all_info.csv',encoding='gbk')
print("数据读取成功!")
except FileNotFoundError:
print("错误:未在当前目录找到 'user_all_info.csv' 文件。")

代码解释:
pd.read_csv():pandas中的方法,用于读取CSV文件。os.path.join(data_dir, 'user_all_info.csv')将数据目录路径和文件名拼接成完整的文件路径。
三、代码4 - 1:按列合并数据

# 代码 4-1
df3 = user_all_info.iloc[:5, :3] # 取出user_all_info前500行数据
df4 = user_all_info.iloc[2230:, :2] # 取出user_all_info的500后的数据
print(df3)
print(df4)
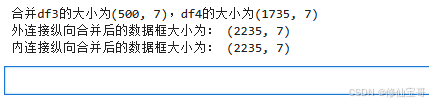
print('合并df3的大小为%s,df4的大小为%s' % (df3.shape, df4.shape))
print('外连接纵向合并后的数据框大小为:', pd.concat([df3, df4], axis=0, join='outer').shape)
print('内连接纵向合并后的数据框大小为:', pd.concat([df3, df4], axis=0, join='inner').shape)
print('合并表后:外连接纵向合并后的数据框大小为:', pd.concat([df3, df4], axis=0, join='outer'))
print('合并表后:内连接纵向合并后的数据框大小为:', pd.concat([df3, df4], axis=0, join='inner'))
结果


代码解释:
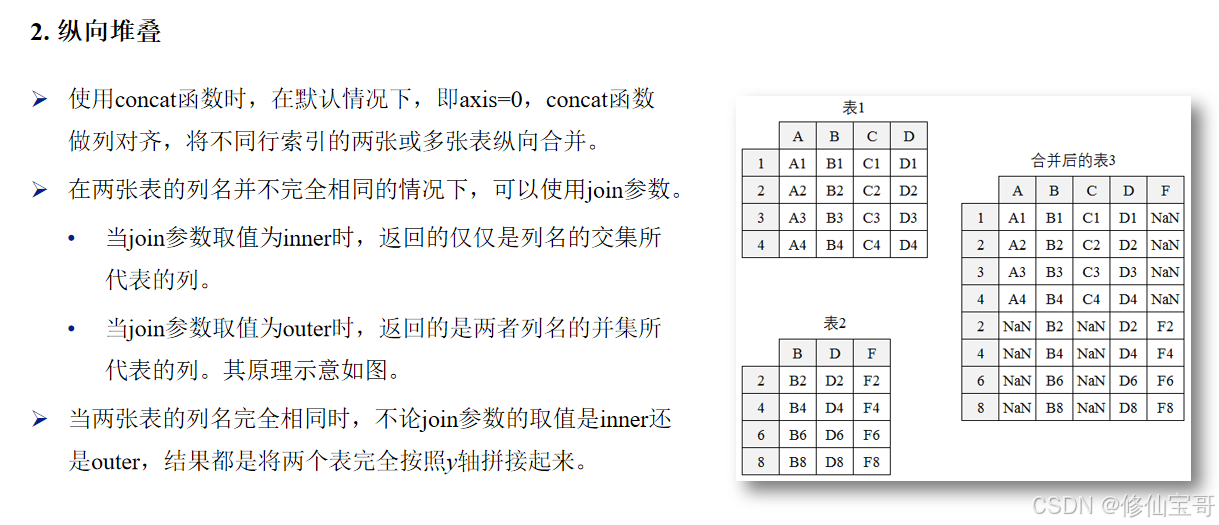
df1 = user_all_info.iloc[:, :3]:使用iloc方法选取user_all_info的前3列数据。df2 = user_all_info.iloc[:, -1:]:使用iloc方法选取user_all_info的最后1列数据。pd.concat():用于将多个DataFrame对象沿着指定轴进行拼接。axis=1:表示按列拼接。join='outer':外连接,合并时包含所有的行和列,缺失值用NaN填充。join='inner':内连接,合并时只包含所有DataFrame对象都有的行和列。
四、代码4 - 2:按行合并数据
# 代码 4-2
df3 = user_all_info.iloc[:500, :] # 取出user_all_info前500行数据
df4 = user_all_info.iloc[500:, :] # 取出user_all_info的500后的数据
print('合并df3的大小为%s,df4的大小为%s' % (df3.shape, df4.shape))
print('外连接纵向合并后的数据框大小为:', pd.concat([df3, df4], axis=0, join='outer').shape)
print('内连接纵向合并后的数据框大小为:', pd.concat([df3, df4], axis=0, join='inner').shape)
代码解释:
df3 = user_all_info.iloc[:500, :]:使用iloc方法选取user_all_info的前500行数据。df4 = user_all_info.iloc[500:, :]:使用iloc方法选取user_all_info的第500行之后的数据。pd.concat():按行拼接数据,axis=0表示按行拼接。
结果
五、代码4 - 3:使用append方法纵向堆叠数据 (弃用)
append方法纵向堆叠数据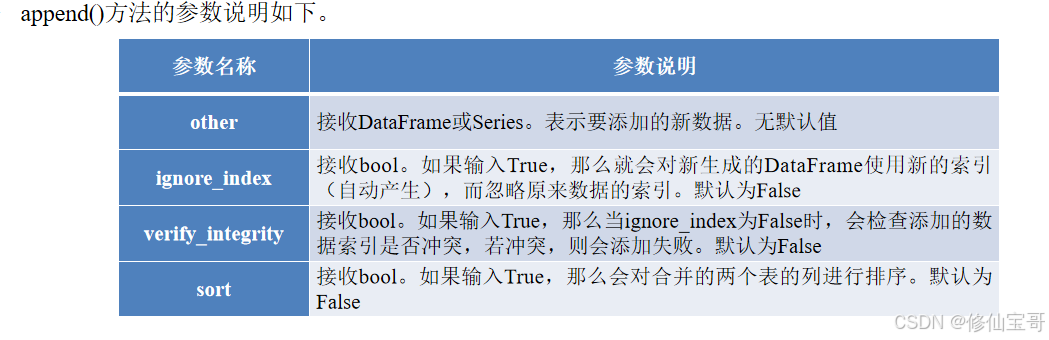
# 代码 4-3
print('堆叠前df3的大小为%s,df4的大小为%s' % (df3.shape, df4.shape))
print('append纵向堆叠后的数据框大小为:', df3.append(df4).shape)
代码解释:
df3.append(df4):DataFrame对象的append方法,用于将另一个DataFrame对象纵向堆叠到当前DataFrame对象的末尾。
在新版的pandas中,DataFrame的append方法已被弃用 ,不再作为DataFrame对象的属性,所以会报'DataFrame' object has no attribute 'append'这个属性错误。
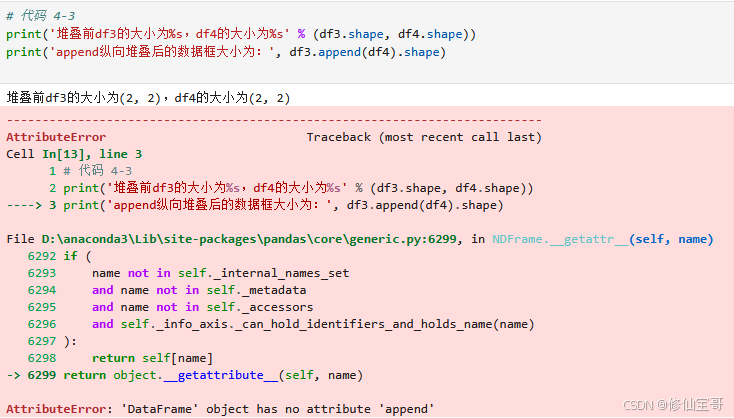
修改后代码
print('堆叠前df3的大小为%s,df4的大小为%s' % (df3.shape, df4.shape))
# 使用 pd.concat 替代 append
print('纵向堆叠后的数据框大小为:', pd.concat([df3, df4], axis=0).shape)
主键合并
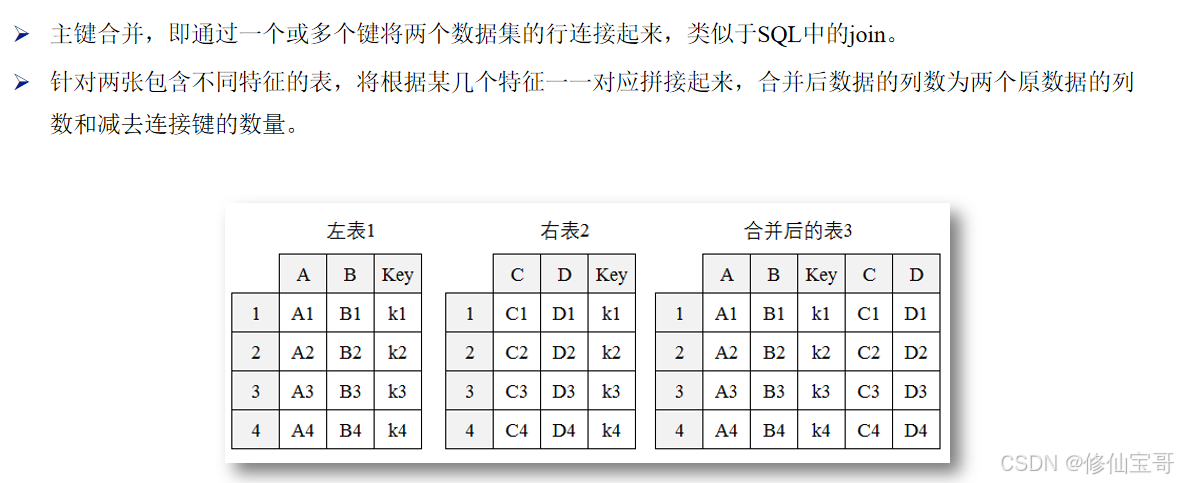

意图是先打印df3和df4形状,再通过append方法纵向堆叠二者并打印堆叠后数据框形状 ,但因append在新版pandas中被弃用而报错。
1.先构建df3和df4两个数据框,然后使用pd.concat函数将它们纵向拼接,最后打印拼接后数据框的形状,成功实现了纵向堆叠并获取形状。
2.使用pd.concat函数,这是新版pandas中推荐用于数据框拼接的方式 ,axis = 0明确指定纵向拼接,能正确实现纵向堆叠需求。
六、代码4 - 4:使用merge方法按主键合并数据
准备
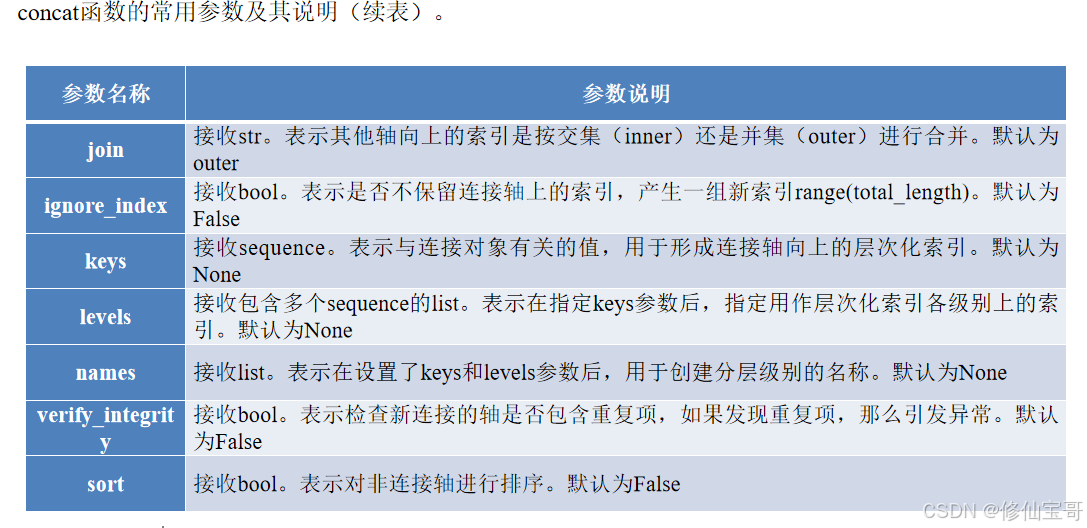
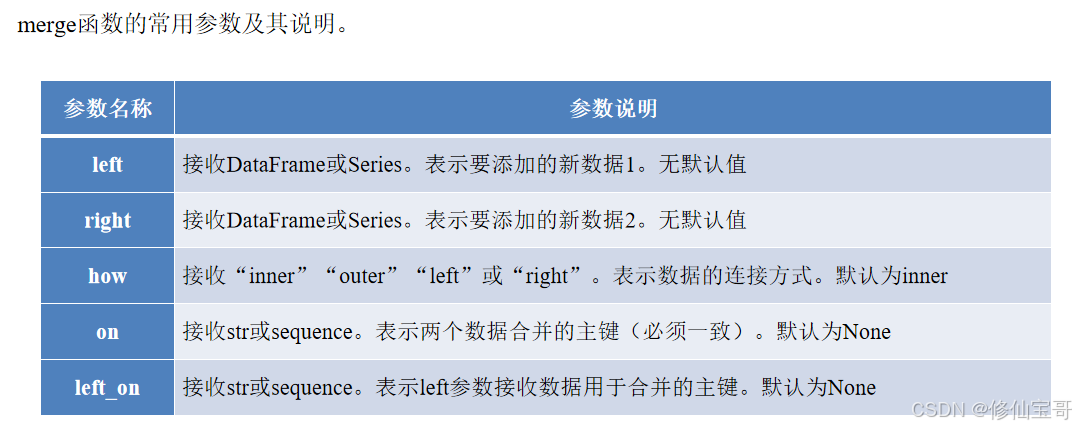
1.merge函数的常用参数及其说明。

# 代码 4-4
# 导入必要的库
# pandas 用于数据处理和分析
# os 用于处理文件路径和操作系统相关功能
# chardet 用于检测文件编码格式
import pandas as pd
import os
import chardet
pay_info = pd.read_csv('./user_pay_info.csv',encoding='utf-8')
download_info = pd.read_csv('./user_download.csv',encoding='GB2312')
# ---------------------- 合并数据框 ----------------------
# 合并下载信息和支付信息数据框
# left_on/right_on 指定左右数据框用于合并的键(列名)
# 这里左侧数据框的键是'用户编号',右侧数据框的键是'编号'(可能列名不同但含义相同)
download_and_pay = pd.merge(
download_info, # 左侧数据框(下载信息)
pay_info, # 右侧数据框(支付信息)
left_on='用户编号', # 左侧数据框的合并键
right_on='编号' # 右侧数据框的合并键
)
print(download_and_pay)
# ---------------------- 定义打印函数 ----------------------
# 定义函数用于打印数据框合并前后的形状信息
# 参数说明:
# df1_name/df2_name: 数据框的名称(字符串,用于显示)
# df1/df2: 原始数据框对象
# merge_method: 合并方式描述(字符串,如'主键')
# merge_result: 合并后的结果数据框
def print_merge_shape(df1_name, df2_name, df1, df2, merge_method, merge_result):
print(f'{df1_name}的原始形状为:', df1.shape) # 打印第一个数据框的形状(行数, 列数)
print(f'{df2_name}的原始形状为:', df2.shape) # 打印第二个数据框的形状
print(f'{df1_name}和{df2_name}{merge_method}合并后的形状为:', merge_result.shape) # 打印合并结果的形状
# ---------------------- 调用函数输出结果 ----------------------
# 调用打印函数,传入数据框名称、对象、合并方式和结果
print_merge_shape(
'download_info', # 下载信息数据框的名称
'pay_info', # 支付信息数据框的名称
download_info, # 下载信息数据框对象
pay_info, # 支付信息数据框对象
'主键', # 合并方式描述(基于主键合并)
download_and_pay # 合并后的结果数据框
)
代码解释:
pd.read_csv():读取user_pay_info.csv和user_download.csv文件。pd.merge():用于根据指定的键将两个DataFrame对象合并。left_on='用户编号':指定左DataFrame(download_info)中用于合并的列。right_on='编号':指定右DataFrame(pay_info)中用于合并的列。
print_merge_shape:自定义函数,用于打印合并前后DataFrame对象的形状。
结果

七、代码4 - 5:使用join方法按主键合并数据
# 代码 4-5
pay_info.rename({'编号': '用户编号'}, inplace=True)
download_and_pay1 = download_info.join(pay_info, on='用户编号', rsuffix='1')
# 按照正确的参数顺序和数量调用函数
print_merge_shape('download_info', 'pay_info',
download_info, pay_info, '主键', download_and_pay1)
代码解释:
pay_info.rename({'编号': '用户编号'}, inplace=True):使用rename方法将pay_info中的编号列重命名为用户编号。download_info.join():DataFrame对象的join方法,用于根据指定的键将两个DataFrame对象合并。on='用户编号':指定用于合并的列。rsuffix='1':当两个DataFrame对象中有相同列名时,为右DataFrame中的列名添加后缀。
代码解释
在调用 print_merge_shape 函数时,依次传递了 df1_name(‘download_info’)、df2_name(‘pay_info’)、df1(download_info)、df2(pay_info)、merge_method(‘主键’)和 merge_result(download_and_pay1)这 6 个参数,这样就能正确调用函数并输出结果了。
结果

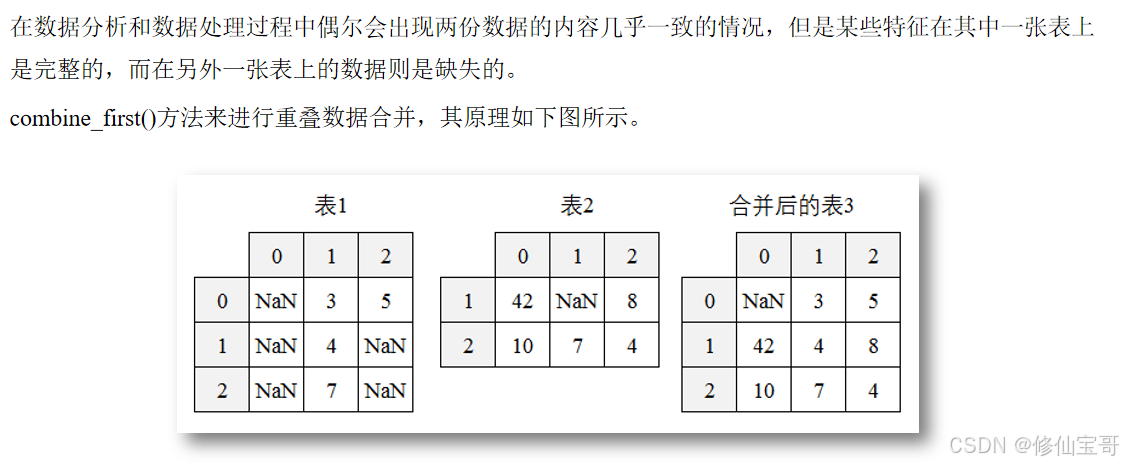
八、代码4 - 6:使用combine_first方法重叠合并数据
# 代码 4-6
import numpy as np
# 建立两个字典,除了ID外,别的特征互补
dict1 = {'ID': [1, 2, 3, 4, 5, 6, 7, 8, 9],
'System': ['win10', 'win10', np.nan, 'win10', np.nan, np.nan,
'win7', 'win7', 'win8'],
'cpu': ['i7', 'i5', np.nan, 'i7', np.nan, np.nan, 'i5', 'i5', 'i3']}
dict2 = {'ID': [1, 2, 3, 4, 5, 6, 7, 8, 9],
'System': [np.nan, np.nan, 'win7',
np.nan, 'win8', 'win7', np.nan, np.nan, np.nan],
'cpu': [np.nan, np.nan, 'i3', np.nan, 'i7', 'i5', np.nan, np.nan, np.nan]}
# 变换两个字典为DataFrame
df1 = pd.DataFrame(dict1)
df2 = pd.DataFrame(dict2)
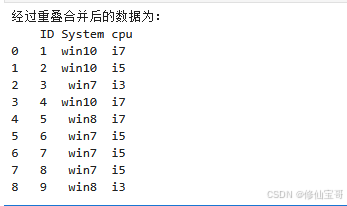
print('经过重叠合并后的数据为:\n', df1.combine_first(df2))
代码解释:
import numpy as np:导入numpy库并将其重命名为np,numpy是一个用于科学计算的库,提供了数组和矩阵操作的方法。pd.DataFrame():将字典转换为DataFrame对象。df1.combine_first(df2):DataFrame对象的combine_first方法,用于将两个DataFrame对象进行重叠合并,当df1中存在缺失值时,用df2中对应位置的值进行填充。-
结果

总结
通过本文的学习,可以掌握以下知识和技能:
- 学会使用
pandas库读取CSV文件。 - 掌握
concat方法按行和列合并数据的操作。 - 了解
append方法纵向堆叠数据的使用。 - 学会使用
merge和join方法按主键合并数据。 - 掌握
combine_first方法进行重叠合并数据的操作。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)