强化学习的学习之路(十八)_2021-01-18:Double Q-learning(Deep Reinforcement Learning with Double Q-learning)
作为一个新手,写这个教程也是想和大家分享一下自己学习强化学习的心路历程,希望对大家能有所帮助。这个系列后面会不断更新,希望自己能保证起码平均一天一更的速度,先是介绍强化学习的一些基础知识,后面介绍强化学习的相关论文。本来是想每一篇多更新一点内容的,后面想着大家看CSDN的话可能还是喜欢短一点的文章,就把很多拆分开来了,目录我单独放在一篇单独的博客里面了。完整的我整理好了会放在github上,大家一
作为一个新手,写这个强化学习-基础知识专栏是想和大家分享一下自己学习强化学习的学习历程,希望对大家能有所帮助。这个系列后面会不断更新,希望自己在2021年能保证平均每日一更的更新速度,主要是介绍强化学习的基础知识,后面也会更新强化学习的论文阅读专栏。本来是想每一篇多更新一点内容的,后面发现大家上CSDN主要是来提问的,就把很多拆分开来了(而且这样每天任务量也小一点哈哈哈哈偷懒大法)。但是我还是希望知识点能成系统,所以我在目录里面都好按章节系统地写的,而且在github上写成了书籍的形式,如果大家觉得有帮助,希望从头看的话欢迎关注我的github啊,谢谢大家!另外我还会分享深度学习-基础知识专栏以及深度学习-论文阅读专栏,很早以前就和小伙伴们花了很多精力写的,如果有对深度学习感兴趣的小伙伴也欢迎大家关注啊。大家一起互相学习啊!可能会有很多错漏,希望大家批评指正!不要高估一年的努力,也不要低估十年的积累,与君共勉!
接下来的几个博客将会分享以下有关DQN算法及其改进,包括DQN(Nature)、Double DQN、 Multi-step DQN、Pirority Replay Buffer、 Dueling DQN、DQN from Demonstrations、Distributional DQN、Noisy DQN、Q-learning with continuous actions、Rainbow、Practical tips for DQN等。
DQN 使用了两个结构相同的网络:Behavior Network 和 Target Network。通过在一段时间内固定 Target Network 的参数,Q-Learning 方法的目标价值能够得到一定的固定,这 样模型也能够获得一定的稳定性。
虽然这个方法提升了模型的稳定性,但它并没有解决另外一个问题: Q-Learning 对价值过高估计的问题。在许多实验中,我们发现DQN的估计总会偏高:
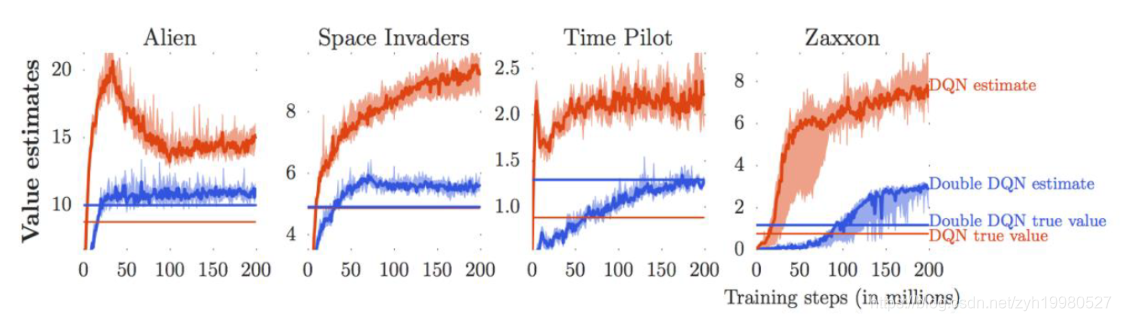
我们知道 Q-Learning 在计算时利用了下一时刻的最优价值,所以它通常在计算时给出了一个状态行动的估计上限。由于训练过程中模型并不够稳定, 因此对上限的估计可能会存在一定的偏差。如果偏差是一致的,也就是说,每个行动都拥有相近的偏差,那么偏差对模型效果的影响相对较小; 如果偏差是不一致的,那么这 个偏差会造成模型对行动优劣的判断偏差,这样就会影响模型的效果。直观一点进行解释:如果Q网络的估计是有噪声的,那么在计算target的时候的max操作会倾向于取较大的值,就导致估计一直往较大值的方向,从而出现over-estimate的问题。
严谨一点, 假设存在两个随机变量, 它们的期望就是真实的Q-value, 这个时候我们需要的是两个变量的期望的max (式子中的右方),而实际上由于一次只能拿到一个数据, 所以实际估计的是两个量最大值的期望。这样就使得得到的结果会偏大:
E [ max ( X 1 , X 2 ) ] ≥ max ( E [ X 1 ] , E [ X 2 ] ) E\left[\max \left(X_{1}, X_{2}\right)\right] \geq \max \left(E\left[X_{1}\right], E\left[X_{2}\right]\right) E[max(X1,X2)]≥max(E[X1],E[X2])
我们已经知道 Target Network 求解价值目标值的公式
y j = r j + 1 + γ max a ′ Q ( s j + 1 , a ′ ; θ − ) \boldsymbol{y}_{j}=\boldsymbol{r}_{j+1}+\gamma \max _{\boldsymbol{a}^{\prime}} Q\left(s_{j+1}, \boldsymbol{a}^{\prime} ; \theta^{-}\right) yj=rj+1+γa′maxQ(sj+1,a′;θ−)
其中 θ − \theta^{-} θ− 表示 Target Network 的参数。将公式进一步展开,可以得到更详细的公式内容 :
y j = r j + 1 + γ Q ( s j + 1 , argmax a ′ Q ( s j + 1 , a ′ ; θ − ) ; θ − ) \boldsymbol{y}_{j}=\boldsymbol{r}_{j+1}+\gamma Q\left(\boldsymbol{s}_{j+1}, \operatorname{argmax}_{\boldsymbol{a}^{\prime}} Q\left(\boldsymbol{s}_{j+1}, \boldsymbol{a}^{\prime} ; \theta^{-}\right) ; \theta^{-}\right) yj=rj+1+γQ(sj+1,argmaxa′Q(sj+1,a′;θ−);θ−)
公式展开后,我们发现采用 Target Network 后,模型在选择最优行动和计算目标值时依然使用了同样的参数模型,根据Q去选择一个最佳的action,然后得到这个最佳action的Q值。前面之所以出现over-estimation的问题,正是因为这个选到的action必然会导致得到的Q值最大。为了尽可能地减少过高估计的影响,一个简单的办法就是把选择最优行动和估计最优行动两部分的工作分离,我们用 Behavior Network 完成最优行动的选择工作,这样就保证了引入的网络和当前网络的差距不太大,这样就可以得到
y j = r j + 1 + γ Q ( s j + 1 , argmax a ′ Q ( s j + 1 , a ′ ; θ ) ; θ − ) \boldsymbol{y}_{j}=\boldsymbol{r}_{j+1}+\gamma Q\left(\boldsymbol{s}_{j+1}, \operatorname{argmax}_{\boldsymbol{a}^{\prime}} Q\left(\boldsymbol{s}_{j+1}, \boldsymbol{a}^{\prime} ; \theta\right) ; \theta^{-}\right) yj=rj+1+γQ(sj+1,argmaxa′Q(sj+1,a′;θ);θ−)
通过这样的变化,算法在三个环节的模型安排如下。
(1 ) 采样: Behavior Network Q ( θ ) Q(\theta) Q(θ) 。
(2)选择最优行动: Behavior NetworkQ ( θ ) (\theta) (θ) 。
(3)计算目标价值: Target Network Q ( θ − ) Q\left(\theta^{-}\right) Q(θ−)
经过这样的变换,模型在过高估计的问题上得到了缓解,稳定性也就得到了提高。
上一篇:强化学习的学习之路(十七)_2021-01-17:DQN(Deep Q Network:Human-level control through deep reinforcement learning)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)