模仿学习:逆向强化学习(Inverse Reinforcement Learning, IRL)
1 逆向强化学习的基本设定1.1 智能体&奖励IRL 假设智能体可以与环境交互,环境会根据智能体的动作更新状态,但是不会给出奖励。这种设定非常符合物理世界的实际情况。——>比如人类驾驶汽车,与物理环境交互,根据观测做出决策,得到上面公式中轨迹,轨迹中没有奖励。是不是汽车驾驶问题中没有奖励呢?——>其实是有奖励的。避免碰撞、遵守交通规则、尽快到达目的地,这些操作背后都有隐含的奖励
1 逆向强化学习的基本设定
1.1 智能体&奖励
IRL 假设智能体可以与环境交互,环境会根据智能体的动作更新状态,但是不会给出奖励。
1.2 人类专家的策略是一个黑盒
IRL 假设我们可以把人类专家的策略作为一个黑盒调用。
黑盒的意思是我们不知道策略的解析表达式,但是可以使用黑盒策略控制智能体与环境交互,生成 轨迹。
IRL 假设人类学习策略 的方式与强化学习相同,都是最大化回报(累计奖励)的期望

2 IRL的基本思想

3 从黑盒策略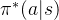 反推隐式奖励
反推隐式奖励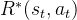

通过上面两条轨迹,我们可以大致得到以下的结论:
-
到达绿色格子有正奖励 r + ,原因是智能体尽量通过绿色格子。到达绿色格子的奖
励只能被收集一次,否则智能体会反复回到绿色格子.
-
到达红色格子有负奖励 r- ,因为智能体尽量避开红色格子。
-
由于左图中智能体穿 越两个红色格子去收集绿色奖励,说明 r + ≳ 2 r- 。
-
由于右图中智能体没有穿越四 个红格子去收集绿色奖励,而是穿越一个红格子,说明 r + ≲ 3 r- 。(- r- ≥-4 r- + r+)
-
-
到达终点有正奖励 r ∗ ,因为智能体会尽力走到终点。由于右图中的智能体穿过红色 格子,说明 r ∗ > r- 。
-
智能体尽量走最短路,说明每走一步,有一个负奖励 r → 。但是 r → 比较小,否则智能体不会绕路去收集绿色奖励。
-
从这两条轨迹中,我们只能大致推断出这几个奖励之间的关系,但是不同推断出他们的实际具体大小
-
——>因为把这些奖励同时乘以一个常量c,最终学出来的策略和不乘上这个常量c的策略是一样的
- ——>最优策略对应的奖励函数不唯一
-
具体如何学习ρ的方法,挖一个坑,后续再补
4 用奖励函数训练策略网络

此时我们可以用学到的奖励函数 R(s, a; ρ)来计算时刻t对应的奖励:
![]()
有了这个之后,我们就可以使用REINFORCE, actor-critic 之类的方法来训练奖励函数了。
REINFORCE和 actor-critic的详细内容可见强化学习笔记:policy learning_UQI-LIUWJ的博客-CSDN博客

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 7
7 0
0- 0



 已为社区贡献118条内容
已为社区贡献118条内容

所有评论(0)