推理-SQL:用SQL定制奖励的强化学习,让Text-to-SQL学会动脑子
我们这套方法最亮眼的成绩单: - 在BIRD基准测试上,我们14B参数的模型直接碾压了更大的商业模型——比o3-mini高4%,比Gemini-1.5-Pro-002高3% - 推理成本直降93%,但效果反而更好,就像用五菱宏光的油钱开出了特斯拉的加速 - 模型自己琢磨出的推理方式,比人工设计的”解题模板”更管用。关键发现: - 7B模型加了我们这套奖励机制后,性能直接飙升6.77% - 在Spi
背景信息
Text-to-SQL任务是个挺有挑战性的活儿,它需要把自然语言问题翻译成数据库能看懂的SQL查询。这事儿涉及到好几个烧脑的子任务,比如理解人话、搞懂数据库结构,还得写出精准的SQL语句。以前的方法大多靠人工设计的推理路径,就像给模型戴了个”思维导图”眼镜,虽然能看路,但视野受限。
最近像DeepSeek R1和OpenAI o1这些模型玩出了新花样——它们让AI自己探索学习路径,就像给小孩奖励贴纸来鼓励好行为。受这个启发,我们搞了个叫Reasoning-SQL的强化学习框架,专门给Text-to-SQL任务定制了一套”奖励机制”:

图1:就像教小狗做动作给零食一样,我们的训练流程会给模型生成的不同SQL方案打分
研究成果
我们这套方法最亮眼的成绩单: - 在BIRD基准测试上,我们14B参数的模型直接碾压了更大的商业模型——比o3-mini高4%,比Gemini-1.5-Pro-002高3% - 推理成本直降93%,但效果反而更好,就像用五菱宏光的油钱开出了特斯拉的加速 - 模型自己琢磨出的推理方式,比人工设计的”解题模板”更管用

图2:我们的打分系统很智能,就像老师不仅看答案对不对,还会检查解题步骤
研究贡献
我们往AI学术界扔了三块”砖”: 1. 自动推理优化器:第一个用强化学习自动调教Text-to-SQL推理过程的框架 2. 花式奖励套餐:专门为SQL生成设计的打分标准,就像给作文评分时既看立意也查错别字 3. 性价比之王:小模型干翻大模型,让普通实验室也能玩转高质量Text-to-SQL

图3:模型学习过程就像小孩学写字,从歪歪扭扭到工整规范
实验过程数据
我们做了个”模型奥运会”来比试: - 选手:3B/7B/14B不同体量的模型 - 比赛项目:BIRD、Spider等数据库查询基准赛 - 裁判标准:执行准确率(EX)——就像考试不仅要写对公式,还得算出正确结果
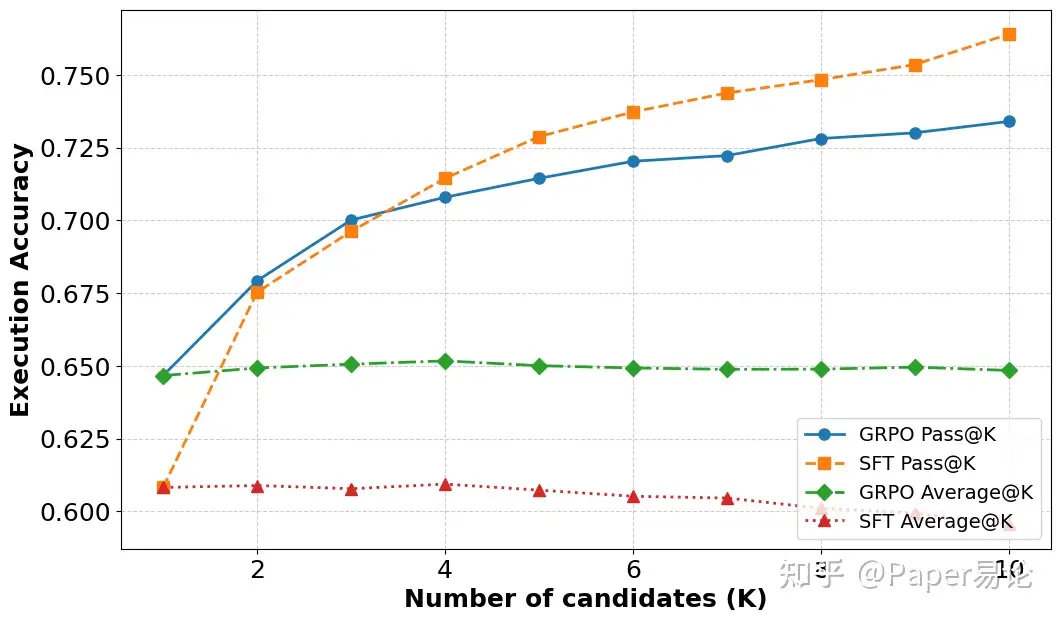
图4:模型表现随计算资源增加的变化,就像给不同马力发动机测油耗
关键发现: - 7B模型加了我们这套奖励机制后,性能直接飙升6.77% - 在Spider等陌生题库上表现也很稳,说明不是死记硬背的”书呆子”
结论
简单说就是:我们用打游戏升级那套思路训练AI写SQL,结果小模型逆袭了大佬。这招不仅效果好,还特别省钱——就像找到了深度学习界的”拼多多”模式。
未来可以往两个方向搞: 1. 把更多数据库知识塞进奖励机制,让AI更像老练的DBA 2. 试试在其他编程语言生成任务上复制这个成功

图5:我们的方法省钱效果堪比双十一满减,性能还不打折
原文:https://arxiv.org/pdf/2503.23157

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 12
12 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)