8步学会使用Pandas进行数据清洗
如果你对数据科学感兴趣,那么数据清洗可能对你来说是一个熟悉的术语。如果不熟悉,那么本文先来解释一下。我们的数据通常来自多个资源,而且并不干净。它可能包含缺失值、重复值、错误或不需要的格式等。在这种混乱的数据上运行实验会导致错误的结果。因此,在将数据输入模型之前,有必要对数据进行准备。这种通过识别和解决潜在的错误、不准确性和不一致性来准备数据的做法被称为数据清洗。在本教程中将向你介绍使用Pandas
使用Pandas进行数据清洗,本教程循序渐进,指导初学者使用功能强大的Pandas库进行数据清洗和预处理。
简介
如果你对数据科学感兴趣,那么数据清洗可能对你来说是一个熟悉的术语。如果不熟悉,那么本文先来解释一下。我们的数据通常来自多个资源,而且并不干净。它可能包含缺失值、重复值、错误或不需要的格式等。在这种混乱的数据上运行实验会导致错误的结果。因此,在将数据输入模型之前,有必要对数据进行准备。这种通过识别和解决潜在的错误、不准确性和不一致性来准备数据的做法被称为数据清洗。
在本教程中将向你介绍使用Pandas进行数据清洗的过程。

数据集
本文将使用著名的鸢尾花数据集进行操作。鸢尾花数据集包含三个品种的鸢尾花的四个特征测量值:萼片长度、萼片宽度、花瓣长度和花瓣宽度。本文将使用以下库:
-
Pandas: 用于数据处理和分析的强大库
-
Scikit-learn: 提供数据预处理和机器学习的工具
数据清洗步骤
1. 加载数据集
使用Pandas的read_csv()函数加载鸢尾花数据集:
column_names = ['id', 'sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
iris_data = pd.read_csv('data/Iris.csv', names= column_names, header=0)
iris_data.head()
输出:
| id | sepal_length | sepal_width | petal_length | petal_width | species |
|---|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
参数header=0表示CSV文件的第一行包含列名(标题)。
2. 探索数据集
为了深入了解数据集的基本信息,本文将使用pandas的内置函数打印一些基本信息:
print(iris_data.info())
print(iris_data.describe())
输出:
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):
# 列名 非空计数 类型
--- ------ -------------- -----
0 id 150 non-null int64
1 sepal_length 150 non-null float64
2 sepal_width 150 non-null float64
3 petal_length 150 non-null float64
4 petal_width 150 non-null float64
5 species 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.2+ KB
None
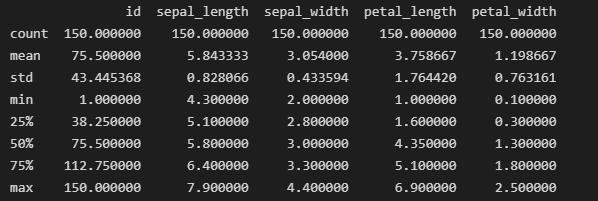
iris_data.describe()的输出结果
info()函数有助于了解数据帧的整体结构、每列中非空值的数量以及内存使用情况。而汇总统计信息则提供了数据集中数值特征的概览。
3. 检查类别分布
这是了解分类列中类别分布情况的重要步骤,对于分类任务来说非常重要。可以使用Pandas中的value_counts()函数来执行此步骤。
print(iris_data['species'].value_counts())
输出:
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
Name: species, dtype: int64
输出的结果显示,数据集是平衡的,每个品种的代表数量相等。这为所有3个类别进行公平评估和比较奠定了基础。
4. 删除缺失值
由于从info()方法明显可见本文的数据中有5列没有缺失值,因此本文将跳过此步骤。但如果遇到任何缺失值,可以使用以下命令处理它们:
iris_data.dropna(inplace=True)
5. 删除重复值
重复值可能会扭曲我们的分析结果,因此本文会从数据集中删除它们。首先使用下面的命令检查是否存在重复值:
duplicate_rows = iris_data.duplicated()
print("Number of duplicate rows:", duplicate_rows.sum())
输出:
Number of duplicate rows: 0
本文的数据集中没有重复值。不过,如果有重复值,可以使用drop_duplicates()函数将其删除:
iris_data.drop_duplicates(inplace=True)
6. 独热编码
对于分类分析,本文将对品种列进行独热编码。由于机器学习算法更适合处理数值数据,所以本文进行独热编码这一步骤。独热编码过程将分类变量转换为二进制(0或1)格式。
encoded_species = pd.get_dummies(iris_data['species'], prefix='species', drop_first=False).astype('int')
iris_data = pd.concat([iris_data, encoded_species], axis=1)
iris_data.drop(columns=['species'], inplace=True)

7. 浮点数列的归一化
归一化是将数值特征缩放为均值为0、标准差为1的过程。这一过程旨在确保各特征对分析的贡献相等。本文将对浮点数列进行归一化,以便进行一致的缩放。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
cols_to_normalize = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
scaled_data = scaler.fit(iris_data[cols_to_normalize])
iris_data[cols_to_normalize] = scaler.transform(iris_data[cols_to_normalize])
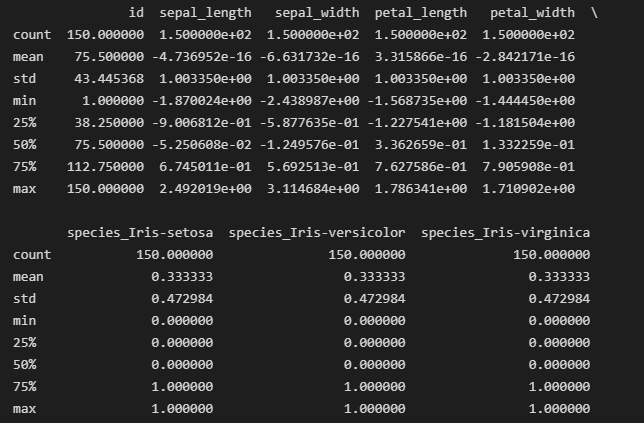
归一化后的iris_data.describe()输出结果
8. 保存清洗后的数据集
将清洗后的数据集保存到新的CSV文件中。
iris_data.to_csv('cleaned_iris.csv', index=False)
总结
恭喜!你已成功使用Pandas清洗了第一个数据集。在处理复杂数据集时,你可能会遇到其他挑战。然而,本文介绍的基本技术将帮助你入门,并为开始数据分析做好准备。
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)

👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python70个实战练手案例&源码👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python大厂面试资料👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。

👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】
点击免费领取《CSDN大礼包》:Python入门到进阶资料 & 实战源码 & 兼职接单方法 安全链接免费领取


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 1
1 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)