Hadoop MapReduce ETL数据清洗 | 案例实操
文章目录一、什么是ETL数据清洗?二、案例实操1、需求分析2、撸代码一、什么是ETL数据清洗?ETL英文名:Extract-Transform-Load,用来讲数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程在运行核心业务MapReduce之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据。清理的过程往往只需要运行Mapper呈现,不需要运行
·
Hadoop中的MapReduce是一种编程模型,用于大规模数据集的并行运算
下面的连接是我的MapReduce系列博客~配合食用效果更佳!

文章目录
一、什么是ETL数据清洗?
ETL英文名:Extract-Transform-Load,用来讲数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程
在运行核心业务MapReduce之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据。清理的过程往往只需要运行Mapper呈现,不需要运行Reduce程序
二、案例实操
1、需求分析
需求:去除日志中字段个数小于等于11的日志
输入数据(字段间用空格分隔):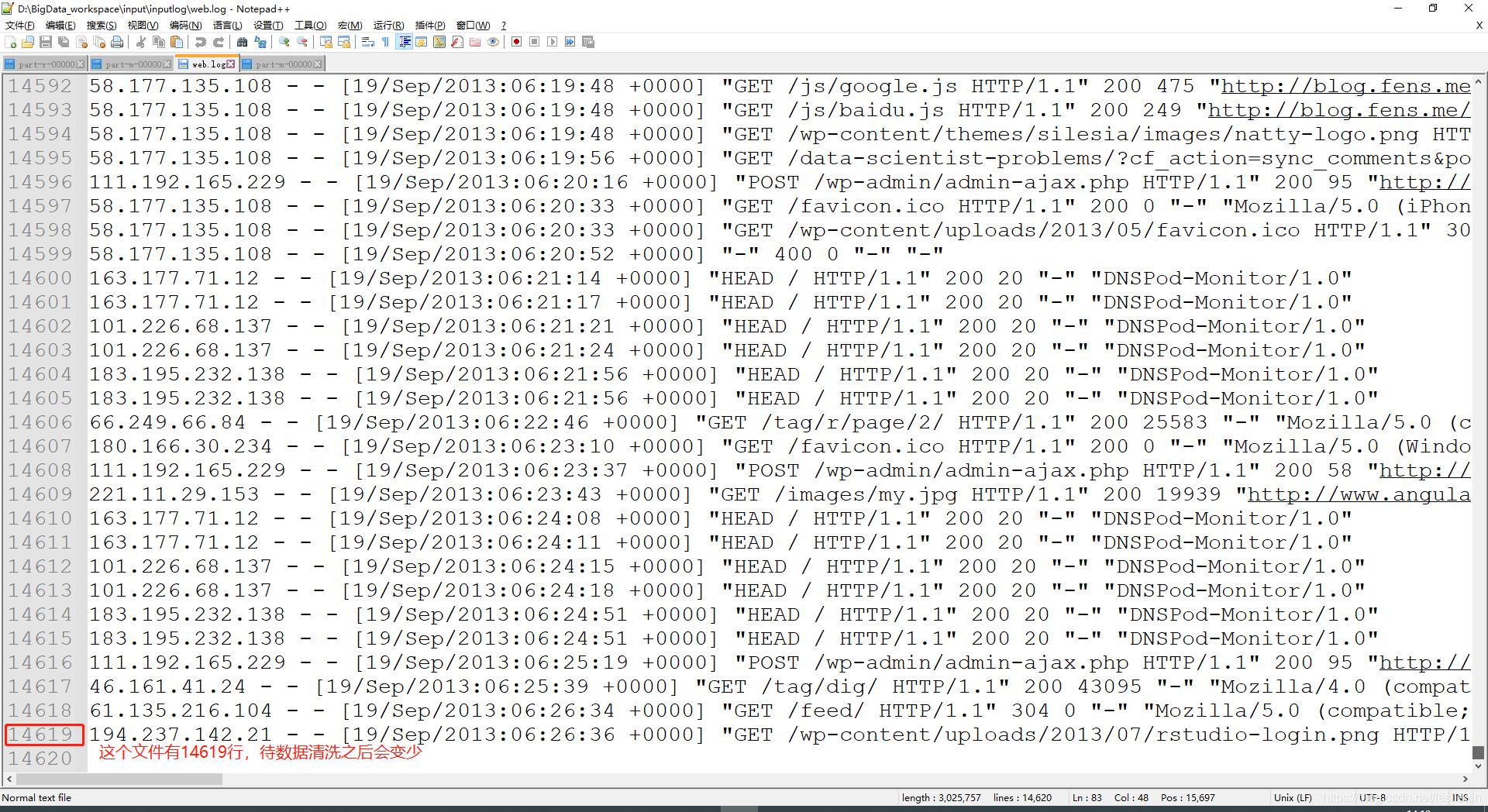
期望输出的每个字段都大于11
2、撸代码
在Mapper阶段:只需要将一行数据切割,判断长度是否大于11就可以了:
package com.wzq.mapreduce.etl;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class LogMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1、获取数据
String line = value.toString();
//2、ETL数据清洗
boolean res = check(line);
//3、判断是否符合规则,然后写入
if(!res){
return;
}
context.write(value,NullWritable.get());
}
private boolean check(String line) {
String[] split = line.split(" ");
if(split.length > 11){
return true;
}
return false;
}
}
Driver阶段需要设置ReduceTask个数为0,不需要做其他变动:
//不需要Reduce阶段,所以设置为0
job.setNumReduceTasks(0);
测试: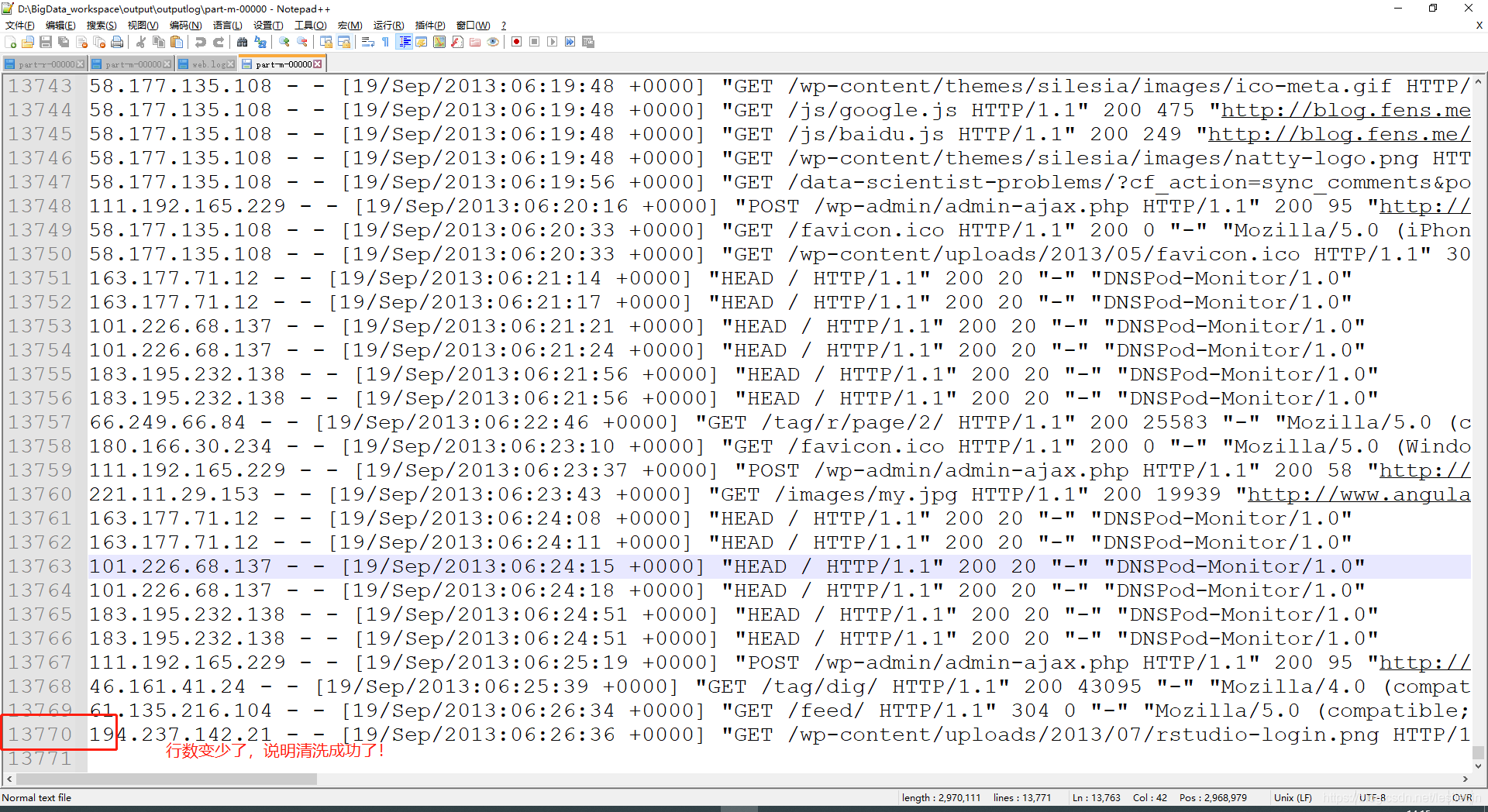

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)