spring boot3整合Elasticsearch 实现快速入门
Elasticsearch是非常强大的一个开源的分布式搜索和分析引擎,是一个Nosql数据库,可以帮助我们从海量数据中快速找到需要的内容。以传统的MySQL数据库为例,要查询一条数据信息,通常是先找到这个数据的id,在顺应的找到这个数据,那么这样就是正向索引或者说普通索引如(select * from userwheretitlelike'%手机%')这条查询语句会在user表中,逐条的查看数据,
Elasticsearch 的详细介绍
Elasticsearch是非常强大的一个开源的分布式搜索和分析引擎,是一个Nosql数据库,可以帮助我们从海量数据中快速找到需要的内容。
es的底层是使用倒排索引来实现的,那么什么是倒排索引呢,接下来简单介绍一下:
倒排索引是指根据内容来查找id。
以传统的MySQL数据库为例,要查询一条数据信息,通常是先找到这个数据的id,在顺应的找到这个数据,那么这样就是正向索引或者说普通索引
如(select * from user where title like '%手机%')这条查询语句会在user表中,逐条的查看数据,看相应的数据是否符合条件
id title price
1 小米手机 3499
2 华为手机 4966
3 小米手环 299
4 华为小米充电器 999
但是,倒排索引不同。它是根据字段来查询id;
将我们要查询的字段单独列出来,并指定对应的id
title id
小米手机 1
华为手机 2
小米手环 3
华为小米充电器 4
查询时,直接查询title字段,如果字段匹配,那么就可以得到相对应的id。
在查询的过程中,我们还可以将字段按照语义进行划分,划分形成的词语我们称为“词条”
词条 id
小米 1,3,4
华为 2,4
手机 1,2
手环 3
充电器 4
我要查询华为手机,那么,符合条件的id有1、2、2、4。我们可以看到id为2出现了两次,相关度最高,那么我们就会把id为2的数据放在查询结果的最前面:2、1、4。这样极大的提高了我们在搜索时的效率,不用再逐条数据的查找。
接下来,我们来查看一下es中的相应概念,并于MySQL数据库进行对比。
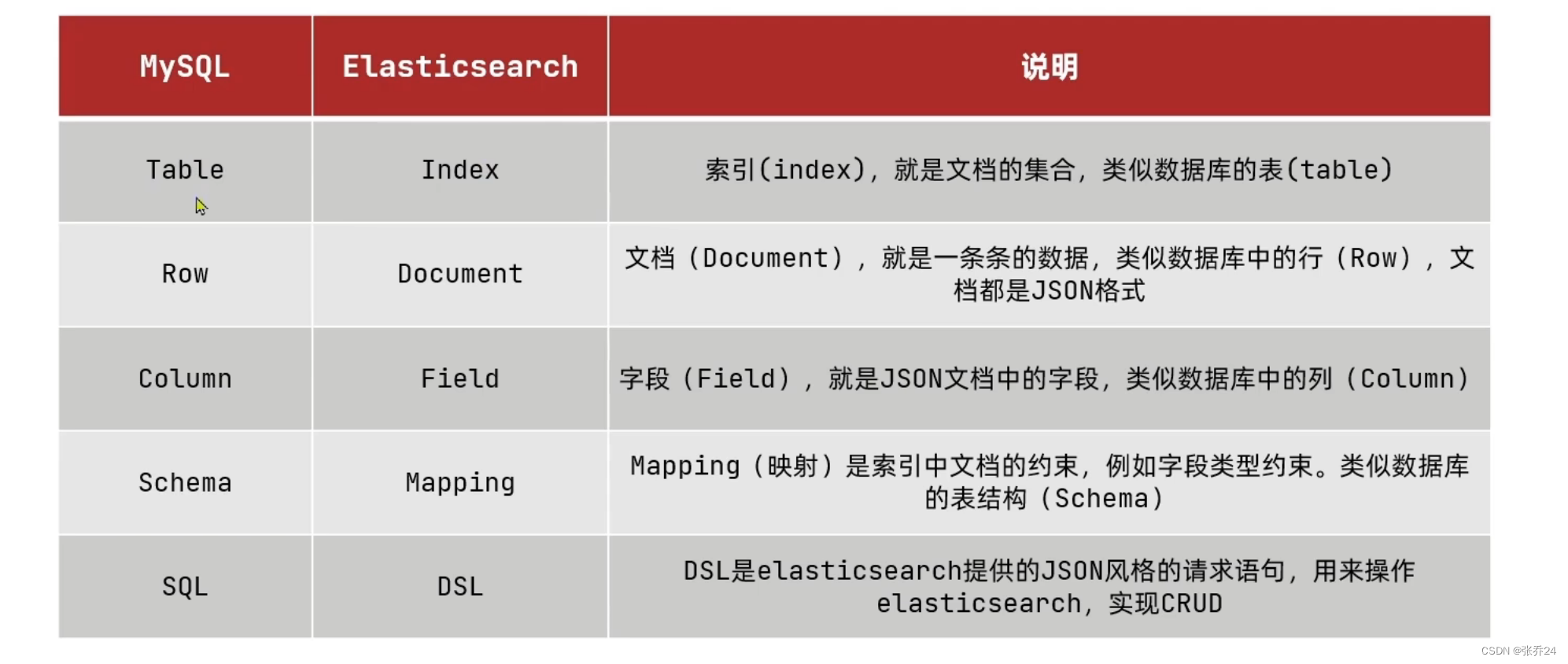
可以看到es中的属性是可以与MySQL中的属性一一对映的,这意味着我们完全可以参照原有的MySQL的表建立一个es的索引。并在es中映射出MySQL表中的字段。然后,就可以使用es来完成MySQL中难以查询的局部搜索了。
es不允许修改已经创建好的索引库,因为已经创建好的索引库mapper映射已经固定好的。所以es不允许我们再去修改创建好的索引。(这点与MySQL是不同的,MySQL即使表已经创建,还是可以修改表的结构)但是我们却可以在已经创建好的索引中在添加新的mapper映射,这个是允许的。
Elasticsearch环境的搭建
本次使用docker进行es环境的部署,需要先安装好docker的运行环境:
安装docker容器
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1* `-e "cluster.name=es-docker-cluster"`:设置集群名称
* `-e "http.host=0.0.0.0"`:监听的地址,可以外网访问
* `-e "ES_JAVA_OPTS=-Xms512m -Xmx512m"`:内存大小
* `-e "discovery.type=single-node"`:非集群模式
* `-v es-data:/usr/share/elasticsearch/data`:挂载逻辑卷,绑定es的数据目录
* `-v es-logs:/usr/share/elasticsearch/logs`:挂载逻辑卷,绑定es的日志目录
* `-v es-plugins:/usr/share/elasticsearch/plugins`:挂载逻辑卷,绑定es的插件目录
* `--privileged`:授予逻辑卷访问权
* `--network es-net` :加入一个名为es-net的网络中
* `-p 9200:9200`:端口映射配置
部署kibana:
kibana可以给我们提供一个elasticsearch的可视化界面,便于我们学习。
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1安装ik分词器:
# 进入容器内部
docker exec -it elasticsearch /bin/bash
# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
#退出
exit
#重启容器
docker restart elasticsearch访问kibana:
http://ip:5601
spring boot整合Elasticsearch
spring boot整合Elasticsearch有两种常见的方式,
一种是spring boot官方整合的spring-boot-starter--dataelasticsearch,这种整合的是es早期的操作方式,使用的客户端被称为Low Level Client,这种客户端操作方式性能方面略显不足。
于是ES官方开发了全新的客户端操作方式,称为High Level Client。(这也是es官方推荐使用的JavaApi)高级别客户端与ES版本同步更新,但是springboot最初整合ES的时候使用的是低级别客户端,所以在企业开发中通常需要更换成高级别的客户端模式。
Spring Boot 与 Elasticsearch 的整合方式主要有两种:使用 Spring Data Elasticsearch 或者使用 Elasticsearch 官方提供的 Java API。
1、使用 Spring Data Elasticsearch
Spring Data Elasticsearch 是 Spring Data 项目的一部分,它提供了对 Elasticsearch 数据库的访问支持。通过 Spring Data Elasticsearch,你可以使用简单的 Java 对象来进行 Elasticsearch 操作,并且可以自动生成相应的 Elasticsearch 查询语句,从而简化开发过程。
在 Spring Boot 中使用 Spring Data Elasticsearch 需要导入 spring-boot-starter-data-elasticsearch 依赖,并且配置相关属性,例如 Elasticsearch 的地址、端口等。然后就可以在代码中使用 ElasticsearchRepository 进行数据存储和检索操作。具体实现详见 Spring Data Elasticsearch 官方文档。
<dependency>
<groupId>org.springframework.boot</groupId>-->
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>-->
</dependency>在配置文件中配置es的连接地址:
spring:
data:
elasticsearch:
cluster-nodes: localhost:9200
初始化和关闭客户端对象:
早期使用ElasticsearchTemplate来操作es,但是使用的客户端被称为Low Level Client,这种客户端操作方式性能方面略显不足,于是ES开发了全新的客户端操作方式,称为High Level Client。高级别客户端与ES版本同步更新,但是springboot最初整合ES的时候使用的是低级别客户端,所以企业开发需要更换成高级别的客户端模式。下面使用高级别客户端方式进行springboot整合ES,操作步骤如下:
Spring Boot会自动根据配置文件中的参数来初始化Elasticsearch客户端对象。您可以直接注入RestHighLevelClient 来使用它,Spring会负责管理客户端的初始化和关闭。
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.stereotype.Service;
@Service
public class MyElasticsearchService {
private final RestHighLevelClient elasticsearchClient;
public MyElasticsearchService(RestHighLevelClient elasticsearchClient) {
this.elasticsearchClient = elasticsearchClient;
}
// 其他业务操作
// ...
}
在上述代码中,我们在MyElasticsearchService中注入了RestHighLevelClient。Spring Boot会自动查找配置并创建Elasticsearch客户端,然后将其注入到MyElasticsearchService类中。当应用程序关闭时,Spring Boot会自动关闭Elasticsearch客户端。
确保Elasticsearch服务器在配置的节点上运行,并且应用程序能够连接到Elasticsearch服务器。整合完成后,您可以在MyElasticsearchService中使用elasticsearchClient来执行各种Elasticsearch操作。
通过使用Spring Data Elasticsearch Starter,您可以避免直接使用低级别的Elasticsearch客户端,而是利用Spring Boot的自动配置来简化初始化和关闭操作。这使得整合Elasticsearch变得更加容易和高效。
2、使用 Elasticsearch 官方提供的 Java API
Elasticsearch 官方提供了用于 Java 开发的 Elasticsearch Java API,你可以使用这个 API 直接与 Elasticsearch 进行交互。它提供了完整的 Elasticsearch REST API 功能,并且支持各种查询和聚合操作。
在 Spring Boot 中使用 Elasticsearch Java API 需要导入 Elasticsearch 官方提供的 Java 客户端依赖,然后根据需要编写相应的 Java 代码来进行 Elasticsearch 操作。这种方式更加灵活,但需要更多的代码编写和维护工作。
1、导入相应的依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.12.1</version>
</dependency>
<properties>
<java.version>17</java.version>
<!--导入es的版本-->
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>2、初始化RestHighLevelClient,将它注册为一个bean,用于以后的使用:
@Configuration
public class ESConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestClientBuilder builder = RestClient.builder(new HttpHost(
"192.168.231.110",
9200));
return new RestHighLevelClient(builder);
}
}3、使用RestHighLevelClient完成一些简单的操作:
(1)、完成索引的创建:(我直接在test中进行测试了,我在测试时直接将异常抛出了,实际中应该用try catch捕获)
@Autowired
private RestHighLevelClient restClientBuilder;
@Test
void createIndex() throws IOException {
restClientBuilder.indices().create(new CreateIndexRequest("hotel")//s索引名称
.source(Custom.INDEX_NAME,XContentType.JSON)//创建索引的语句,使用json传递
, RequestOptions.DEFAULT);//选择默认的请求
}在kibana控制台中可以看到索引已经创建成功了:
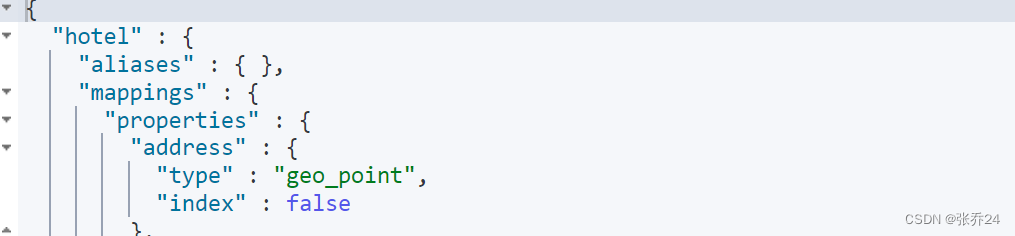
(2)、索引的删除:
@Test
void deleteIndex() throws IOException {
restClientBuilder.indices().
delete(new DeleteIndexRequest("hotel"),RequestOptions.DEFAULT);
}(3)判断索引是否存在:
@Test
void existIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("hotel");
boolean exists = restClientBuilder.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists?"索引存在":"索引不存在");
}(4)完成一个文档的新增:
@Test
void saveDoc() throws IOException {
//从数据库中查询一条数据,放到es中
TbHotel tbHotel = tbHotelMapper.selectById(39141);
TbHotelEs tbHotelEs=new TbHotelEs(tbHotel);
//新建一个IndexRequest对象,指定索引名和文档id(文档id不指定会默认生成)
IndexRequest request = new IndexRequest("hotel").id(tbHotelEs.getId());
request.source(JSON.toJSONString(tbHotelEs),XContentType.JSON);
restClientBuilder.index(request,RequestOptions.DEFAULT);
}(5)完成文档的查询:
@Test
void getDoc() throws IOException {
//创建GetRequest对象,指定索引名和查询文档id
GetRequest request=new GetRequest("hotel","39141");
// 发送请求
GetResponse documentFields = restClientBuilder.get(request, RequestOptions.DEFAULT);
// 解析结果
String sourceAsString = documentFields.getSourceAsString();
System.out.println(sourceAsString);
}(6)文档的更新:
es中文档的更新有两种方式,全部更新和局部更新
全部更新:再次写入一样的文档id,就会删除旧文档,添加新文档。写法与新增没有区别
局部更新:只更新部分字段,我演示方法二:
@Test
void UpdateDoc() throws IOException {
UpdateRequest updateRequest=new UpdateRequest("hotel","39141");
updateRequest.doc(
"name","源神酒店",
"city","洛阳"
);
// 更新文档
restClientBuilder.update(updateRequest,RequestOptions.DEFAULT);
}(7)文档的删除:
@Test
void deleteDoc() throws IOException {
DeleteRequest deleteRequest=new DeleteRequest("hotel","39141");
restClientBuilder.delete(deleteRequest,RequestOptions.DEFAULT);
}(8)批量导入文档:
@Test
void bulkDoc() throws IOException {
// 创建BulkRequest对象,用于批量操作
BulkRequest bulkRequest=new BulkRequest();
// 查询数据库中所有数据
List<TbHotel> tbHotels = tbHotelMapper.selectList(null);
for (TbHotel tbHotel:tbHotels) {
TbHotelEs tbHotelEs=new TbHotelEs(tbHotel);
IndexRequest request = new IndexRequest("hotel").id(tbHotelEs.getId());
// 将新增的doc数据添加到BulkRequest对象
bulkRequest.add(request);
}
// 执行批量操作
restClientBuilder.bulk(bulkRequest,RequestOptions.DEFAULT);
}(9)根据字段查询:
@Test
void searchDoc() throws IOException {
SearchRequest searchRequest=new SearchRequest("hotel");
SearchSourceBuilder sourceBuilder=new SearchSourceBuilder();
//查询name中包含"如家"的酒店
sourceBuilder.query(QueryBuilders.matchQuery("name","如家"));
searchRequest.source(sourceBuilder);
//返回一个search对象,这个search对象中就封装了查询到的json字符
SearchResponse search = restClientBuilder.
search(searchRequest, RequestOptions.DEFAULT);
//打印search
System.out.println(search);
}
总体来说:
使用 Spring Data Elasticsearch 可以更快速地实现 Elasticsearch 的集成和数据操作,而使用 Elasticsearch Java API 则更加灵活,可以更加自由地控制 Elasticsearch 操作。选择哪种方式,应根据具体的业务需求和开发团队的技术特长进行决策。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 19
19 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)