python系列24:用python爬取ajax请求
使用F12打开chrome的开发者界面,然后执行一遍页面,我们能看到:点击执行时间最长的ajax请求,我们就能看到真实的请求(headers里)和参数(payload里)了url:Header中的request urlheaders:Header中的request headersparams:Payload中的Query String Parametersdata:Payload中的From Da
·
1. 查看ajax发送请求的真实地址
使用F12打开chrome的开发者界面,然后执行一遍页面,我们能看到: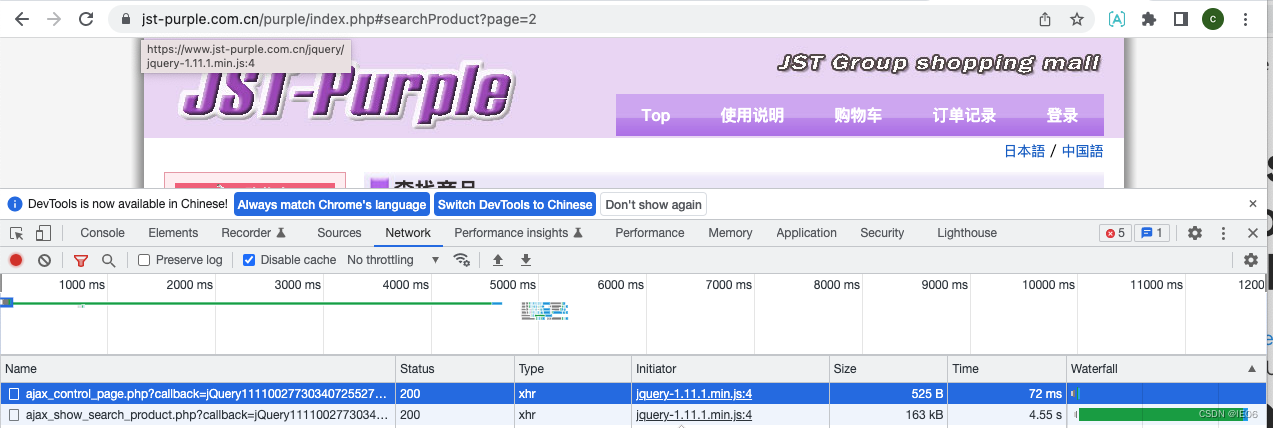
点击执行时间最长的ajax请求,我们就能看到真实的请求(headers里)和参数(payload里)了: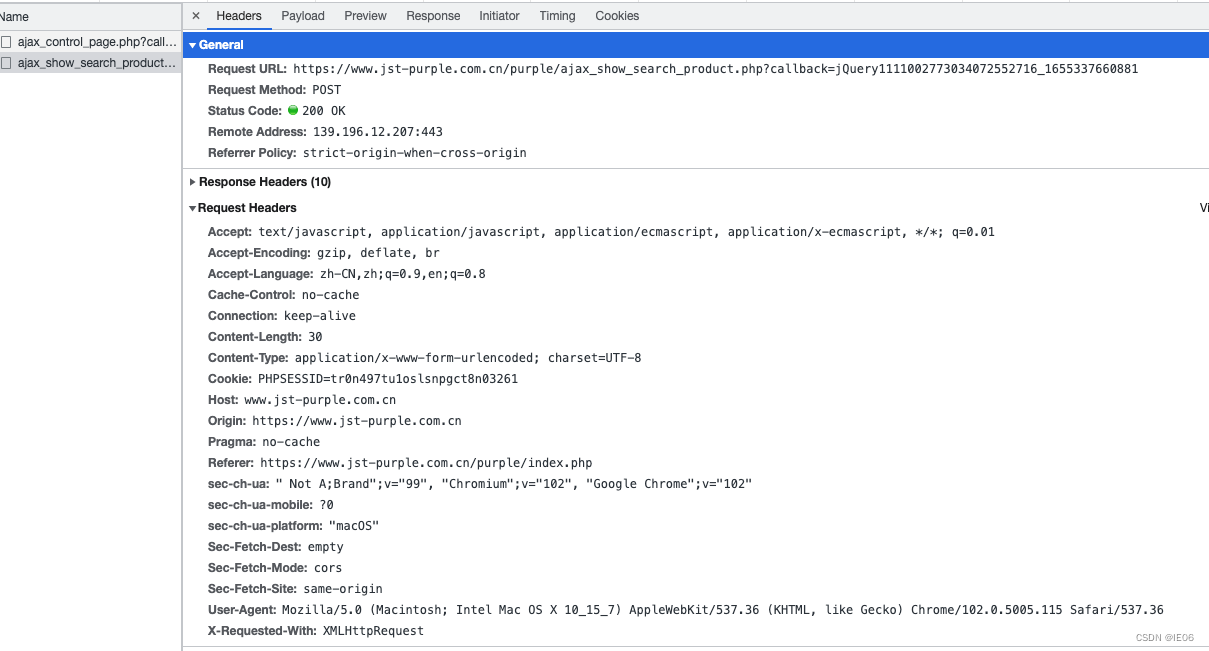
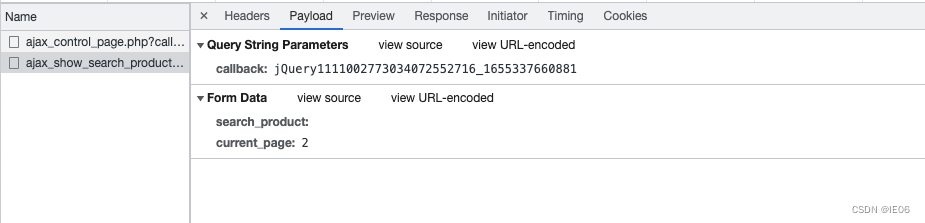
2. 请求代码
url:Header中的request url
headers:Header中的request headers
params:Payload中的Query String Parameters
data:Payload中的From Data
对比上面的两张图,爬取页面信息的代码如下:
import requests
from tqdm import tqdm
headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.115 Safari/537.36',
'Referer': 'https://www.jst-purple.com.cn/purple/index.php',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'PHPSESSID=tr0n497tu1oslsnpgct8n03261'}
url = "https://www.jst-purple.com.cn/purple/ajax_show_search_product.php"
params = {'callback':'jQuery1111007706371456432315_1655294131309'}
# 这里一般用多线程去爬取网页
for i in tqdm(range(1,248)):
rep=requests.post(url=url,params=params,data={"current_page":i},headers=headers)
html = rep.text...

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)