数字视网膜与云视觉系统演进
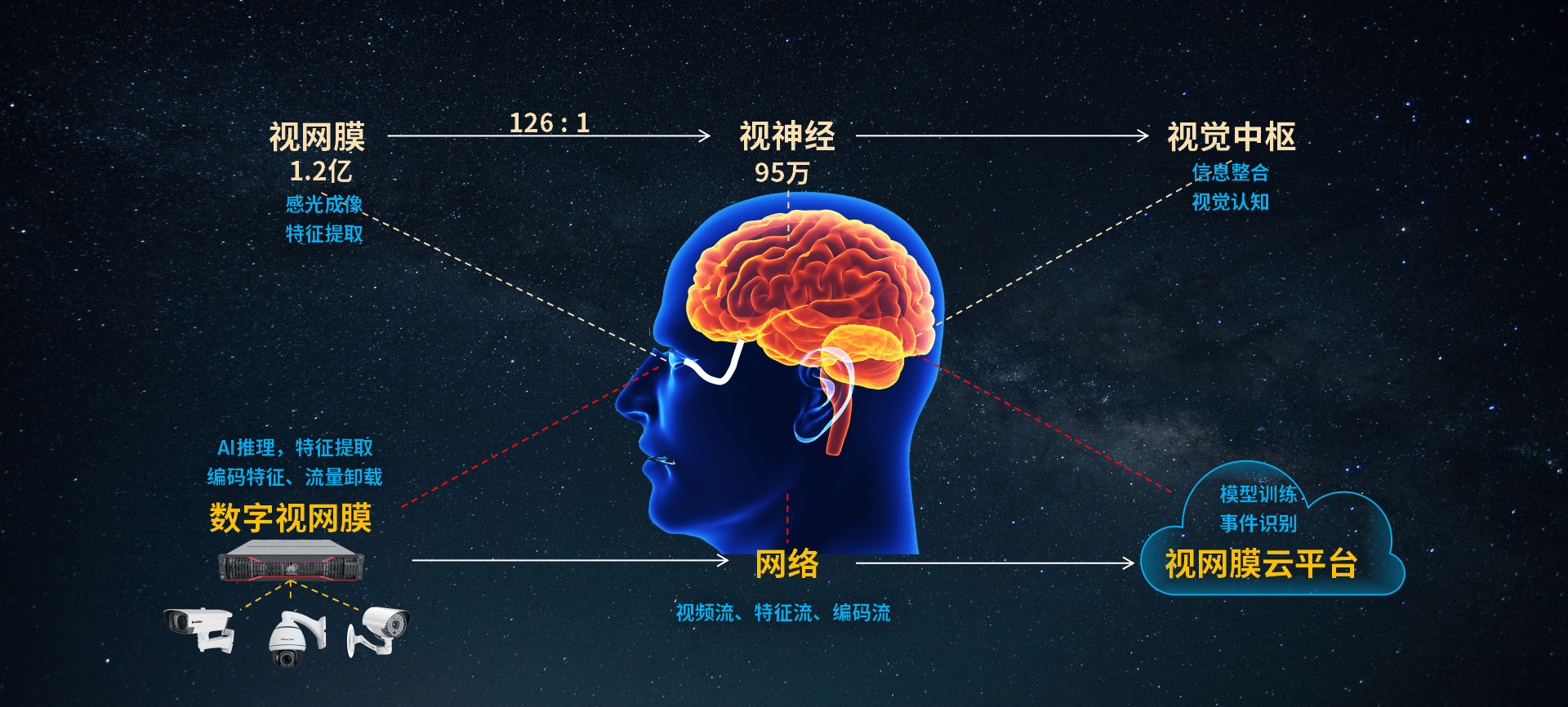
高文院士分享了如何利用对神经网络的理解来改进包括城市大脑或智慧城市系统等现有云视觉系统方面存在的一些问题。高文院士等人从高级生命体视觉系统的进化历史中寻找灵感,在设计新的第二代城市大脑或者说云视觉系统时,在中间的视觉神经通道做工作。他们将这一想法称之为数字视网膜。
本篇文章是博主在知识拓展学习时,用于个人学习、研究或者欣赏使用,并基于博主对相关领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在知识拓展笔记专栏:
知识拓展笔记(4)---《数字视网膜与云视觉系统演进》
数字视网膜与云视觉系统演进
目录
高文院士分享了如何利用对神经网络的理解来改进包括城市大脑或智慧城市系统等现有云视觉系统方面存在的一些问题。
云视觉系统目前存在的两大主要的挑战:
第一,虽然视频数据非常多,但是能够对其进行规范并能够从中挖掘出规律的大数据却并不多。
第二,这些视频数据中绝大多数都是正常视频,而敏感视频比较少,因而产生的价值并不大。
而深究到底,这两大问题其实是整个视觉感知系统架构造成的直接后果。
对此,高文院士等人从高级生命体视觉系统的进化历史中寻找灵感,在设计新的第二代城市大脑或者说云视觉系统时,在中间的视觉神经通道做工作。他们将这一想法称之为数字视网膜。
数字视网膜的定义包括八个基本要素
特征或功能可分为以下三组:
第一组特征是全局统一的时空 ID,包括全网统一的时间以及精确的地理位置两个基本要素;
第二组特征是多层次视网膜表示,包括视频编码、特征编码、联合优化三个基本要素;
第三组是模型可更新、可调节、可定义,即将模型可更新、注意力可调节以及软件可定义三个基本元素组合到一起。
不同于传统的摄像头只有一个流,即一个视频压缩流或一个识别结果流,这种数字视网膜存在三个流,即视频编码流,特征编码流,模型编码流,三者各自有分工,有的是在前端可以实时控制调节,有的是通过云端反馈出来进行调节和控制的。
使能技术方面的重要进展
在过去两三年中,高文院士等人对此也开展了大量工作,重点实现了以下四个使能技术方面的重要进展:
第一个使能技术是高效视频编码技术,其中他们提出的场景实现了以下四个使能技术方面的重要进展:编码技术成为中国学者对世界所做出的的一大贡献,将编码效率提升到了一个新的水平;
第二个使能技术是是特征编码技术,其中就包括他们与国际专家一同完成的两个国际标准 CDVS 和 CDVA,而 CDVA 更是为满足支持深度网络而建立的标准。
第三个使能技术是视频和特征联合编码技术,这是由于视频编码和特征编码使用的优化模型不一样,视频编码使用的是 2D 优化模型,而特征编码联合使用的是 R-A 模型,两个模型的曲线方向完全是不一样的,对此他们提出了联合优化模型,将 R-A 和 2D 变成一个目标函数,通过求最优解就可实现联合优化。
第四个使能技术是 CNN 模型编码技术,能够实现多模型重用、模型压缩(差分编码)和模型更新等优势。
总结
高文院士总结到,现在的云视觉系统不是太有效,对此我们可以通过类似于像数字视网膜的新的概念和技术来使其变得更加有效,包括降低码率、减少延迟、提高准确率、降低云计算成本以及让低价值的视频数据转化为大数据等。
随着数字视网膜已实现 1.0 版本,下一步该如何走向 2.0 版本呢?
答案是:采用脉冲神经网络的思路来做数字视网膜 2.0。
参考:高文《数字视网膜与云视觉系统演进》
文章若有不当和不正确之处,还望理解与指出。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请联系博主删除。如有错误、疑问和侵权,欢迎评论留言联系作者,或者关注VX公众号:Rain21321,联系作者。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 10
10 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)