Qwen2.5-Omni-3B:全能 AI 震撼登场!视频音频图像文本全支持,本地运行无忧虑!
阿里云最新推出的Qwen2.5-Omni-3B是一款全能型AI模型,具备同时处理视频、音频、图像与文本的能力。尽管参数量仅为30亿,但其在本地设备上依然展现出强大的多模态性能。该模型已在Hugging Face平台正式发布,标志着小型化多模态AI系统迎来重要突破。Qwen2.5-Omni-3B标志着多模态人工智能向普及化迈出了重要一步。这款模型将视频、音频、图像和文本处理集成于一个仅3B参数的紧凑
前言:
阿里云最新推出的Qwen2.5-Omni-3B是一款全能型AI模型,具备同时处理视频、音频、图像与文本的能力。尽管参数量仅为30亿,但其在本地设备上依然展现出强大的多模态性能。
该模型已在Hugging Face平台正式发布,标志着小型化多模态AI系统迎来重要突破。
特性:
Qwen2.5-Omni-3B与普通语言模型有着本质的区别。它并非单一的文本处理工具,而是一个真正的多模态系统,能够同时处理文本、图像、音频和视频四种内容类型。
在文本处理方面,Qwen2.5-Omni-3B展现出了强大的语言理解能力。它能够理解和生成全面且丰富的语言内容,无论是复杂的学术论文还是日常对话,都能轻松应对。
在图像分析方面,Qwen2.5-Omni-3B同样表现出色。它能够精准识别图像中的物体和场景,并回答与视觉内容相关的问题。无论是识别照片中的物体,还是分析图像中的场景细节,它都能提供准确的答案。
在音频处理方面,Qwen2.5-Omni-3B能够进行高效的语音识别和转录。它不仅能准确识别语音内容,还能深入分析声音的特征和情感。无论是会议记录的转录,还是语音指令的识别,它都能轻松完成。
对于视频内容,Qwen2.5-Omni-3B能够描述动作和场景的变化,并进行时间推理。它不仅能理解视频中的视觉内容,还能分析动作的连续性和场景的变化,为用户提供更全面的视频分析。
这款模型最突出的特点是,尽管仅有3B参数,却实现了上述所有功能。这使得它能够在计算资源有限的环境中高效运行,展现出强大的适应性和实用性。无论是个人电脑还是小型服务器,都能轻松部署和使用Qwen2.5-Omni-3B,为用户带来强大的多模态处理能力。
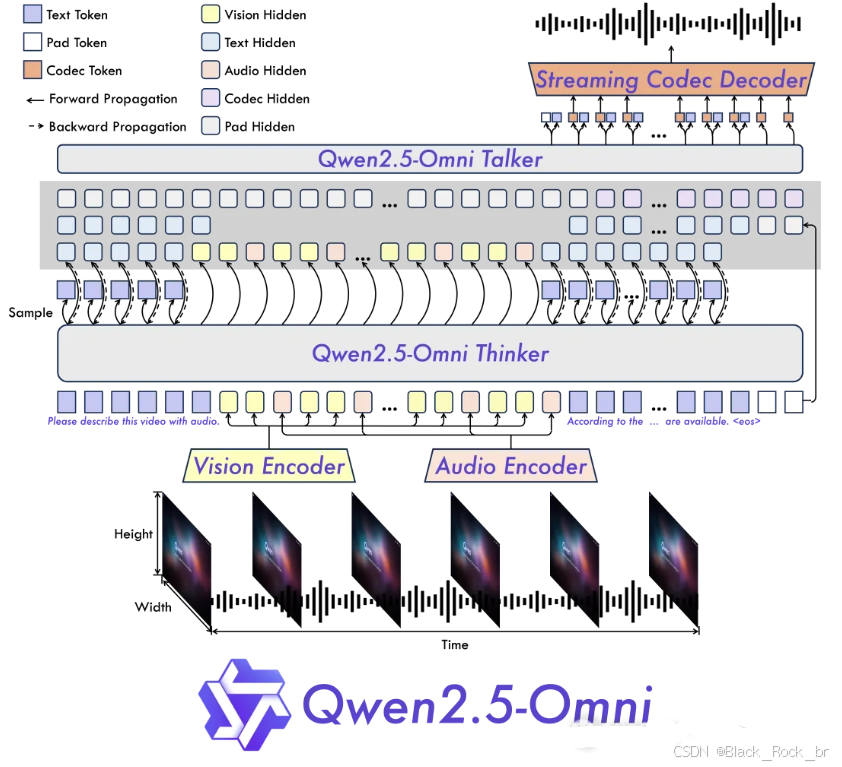
技术架构:
Qwen2.5-Omni-3B的技术架构基于Qwen 2.5模型系列,并在此基础上增加了专门的多模态处理组件,使其能够高效地处理文本、图像、音频和视频等多种类型的数据。
统一的Transformer骨干网络
Qwen2.5-Omni-3B采用了一个统一的Transformer骨干网络,作为基础的文本处理管道。这一骨干网络为模型提供了强大的文本理解和生成能力,能够处理各种复杂的语言任务。
视觉处理模块
模型配备了专门的视觉处理模块,用于提取和理解图像与视频帧的特征。这一模块能够精准地识别图像中的物体、场景,以及视频中的动作和场景变化,为模型提供了强大的视觉理解能力。
音频处理管道
Qwen2.5-Omni-3B还包含一个音频处理管道,能够将声波转换为可处理的嵌入向量。这一管道使得模型能够进行高效的语音识别和转录,以及对声音内容的深入分析。
跨模态注意力机制
为了实现不同模态之间的有效连接,Qwen2.5-Omni-3B引入了跨模态注意力机制。这一机制使得模型能够建立文本、图像、音频和视频之间的关联,实现多模态信息的融合和协同处理。
技术创新点
Qwen2.5-Omni-3B的技术创新主要体现在以下几个方面:
高效的参数共享
模型采用了高效的参数共享机制,将所有输入数据作为序列进行处理。这一机制不仅提高了模型的效率,还减少了计算资源的消耗,使得模型能够在有限的资源下实现强大的多模态处理能力。
投影层的使用
Qwen2.5-Omni-3B通过投影层将不同模态的特征映射到共享的嵌入空间。这一设计使得模型能够在一个统一的框架内处理多种模态的数据,进一步提升了多模态信息融合的效果。
通过这些技术架构和创新点,Qwen2.5-Omni-3B在多模态处理方面展现出了强大的性能和灵活性,为各种应用场景提供了高效、可靠的解决方案。
功能:
多模态能力
在视频理解领域,Qwen2.5-Omni-3B能够精准描述视频内容,准确识别动作,实时检测场景变化,进行高效的时间推理,还能针对视频内容回答各类问题。
在音频处理方面,它具备出色的语音识别和转录能力,能够精准识别说话者,深入理解音频场景,敏锐检测声音事件,还能基于音频内容回答问题。
在图像理解方面,它能够提供详细的图像描述,精准进行物体检测和识别,深入理解场景,高效完成视觉问答以及基于图像的推理。
在文本处理方面,它保持了强大的语言理解能力,能够生成丰富的内容,高效进行摘要,准确回答问题,完成高质量的翻译。
Qwen2.5-Omni-3B真正的力量在于其整合多模态信息的能力。它能够针对带音频的视频回答问题,精准描述文本与图像的关系,基于多模态输入生成文本,还能从混合媒体内容中创建连贯的叙述。
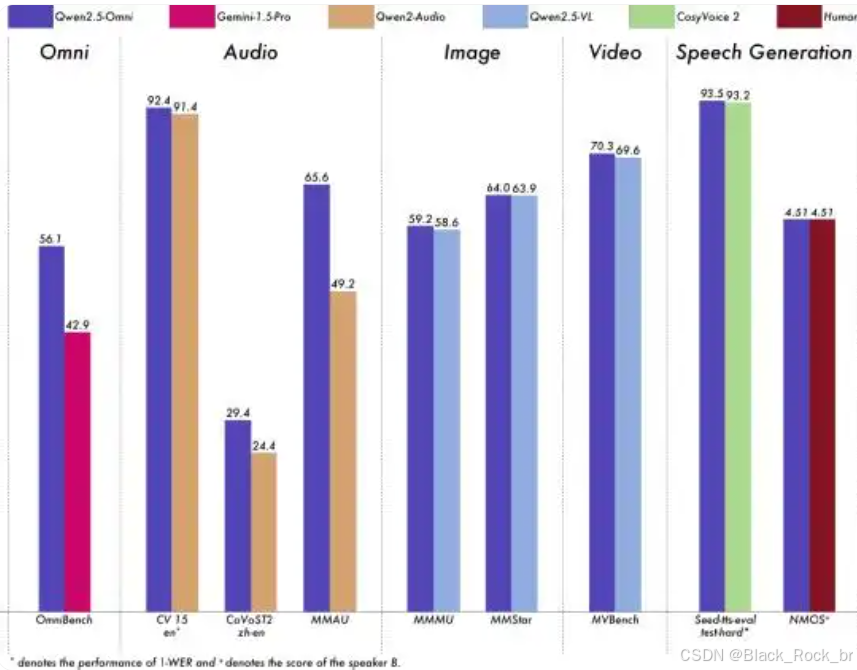
实际测试显示:
性能测试表明,该模型在多项基准任务中表现优异,展现出高效的处理能力,甚至在某些场景下超越了参数规模更大的模型。
本地部署
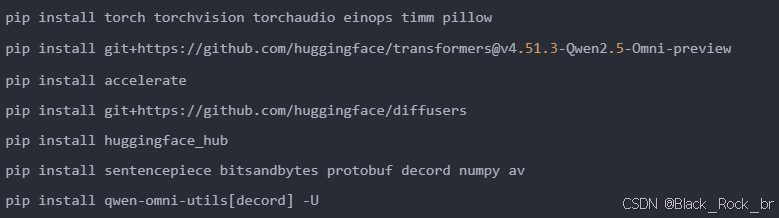
1:安装必要依赖
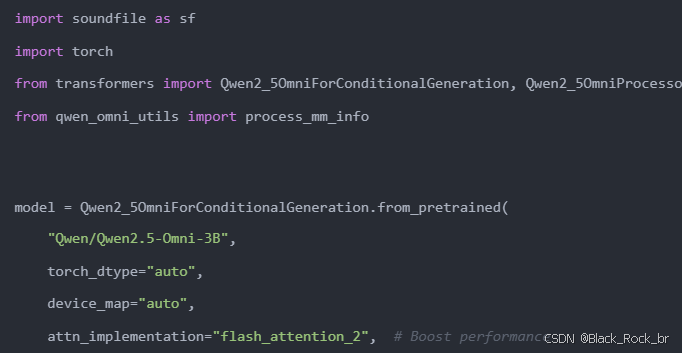
2:导入模块并加载模型
3:准备多模态对话
conversation = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
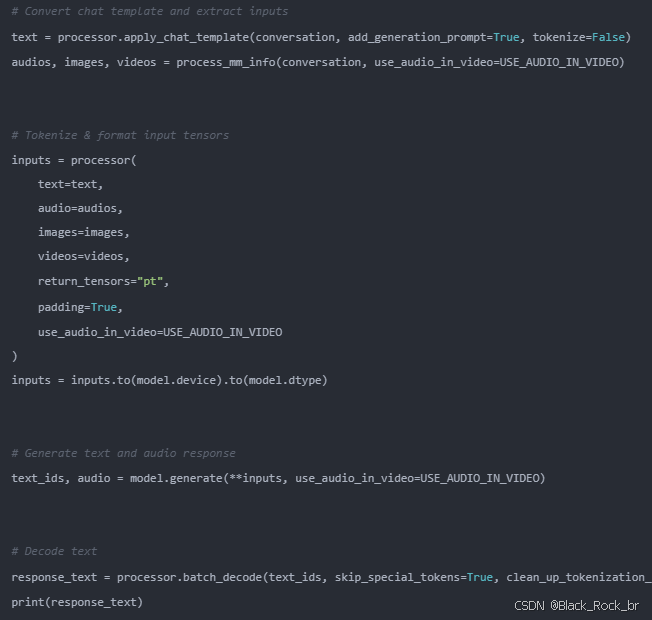
4:处理并运行推理
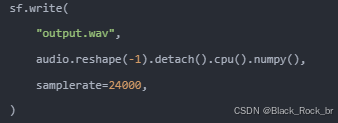
5:保存输出
各大厂商的多模态模型对比

结语
Qwen2.5-Omni-3B标志着多模态人工智能向普及化迈出了重要一步。这款模型将视频、音频、图像和文本处理集成于一个仅3B参数的紧凑模型中,实现了功能与实用性的平衡。
对于开发者、研究人员以及各类组织而言,Qwen2.5-Omni-3B提供了一种无需大量计算资源即可实现多模态AI的解决方案。其在Hugging Face平台上的可用性,进一步降低了使用门槛,使得更多人能够轻松利用这一强大的工具。
随着多模态人工智能的不断发展,像Qwen2.5-Omni-3B这样紧凑且功能强大的模型,将在各种日常应用中扮演关键角色。无论是构建内容审核系统、教育平台还是辅助工具,这一模型都提供了一个坚实而有力的基础。
在未来,我们期待看到Qwen2.5-Omni-3B在更多领域展现其潜力,为人工智能的普及和应用开辟新的道路。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 21
21 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)